前言
上篇文章《大模型训练全流程实战指南工具篇(九)------LLamaFactory大模型训练工具使用指南》 笔者详细介绍了 LLaMA Factory 的环境部署、数据集注册,并带大家跑通了一个完整的大模型微调流程。
但相信不少读者在实操过程中都会遇到这样的困惑:流程是跑通了,可面对配置文件中那些密密麻麻的参数,心里却完全没有底------它们到底在控制什么?调大调小会带来什么影响?为什么别人用的配置我照搬过来效果却差很多?
这正是笔者撰写大模型训练合集的初衷。笔者始终认为,学习大模型训练,不能只停留在"能跑通"的层面,更要知道"为什么这么设"。知其然,更要知其所以然,才能真正掌握这项技术,遇到问题时才能从容定位、灵活调优。
因此,本期文章笔者将系统讲解 LLaMA Factory 的训练方法与参数配置,通过万字长文、直观易懂的比喻帮助大家理解每个参数的作用,建立起从"流程可运行"到"训练稳定、效果可控"的完整认知。希望这篇文章能帮大家真正跨过大模型训练的门槛,一步步成长为能够独立把控训练全流程的高手!还等什么,接着往下看吧~
一、大模型训练方法
如果大家跟着上一篇文章《大模型训练全流程实战指南工具篇(九)------LLamaFactory大模型训练工具使用指南》完整操作下来,应该已经跑通了一个微调流程。但大家可能也注意到,笔者当时选用的是 LoRA 训练方法。为什么是 LoRA?它和其他方法有什么不同?
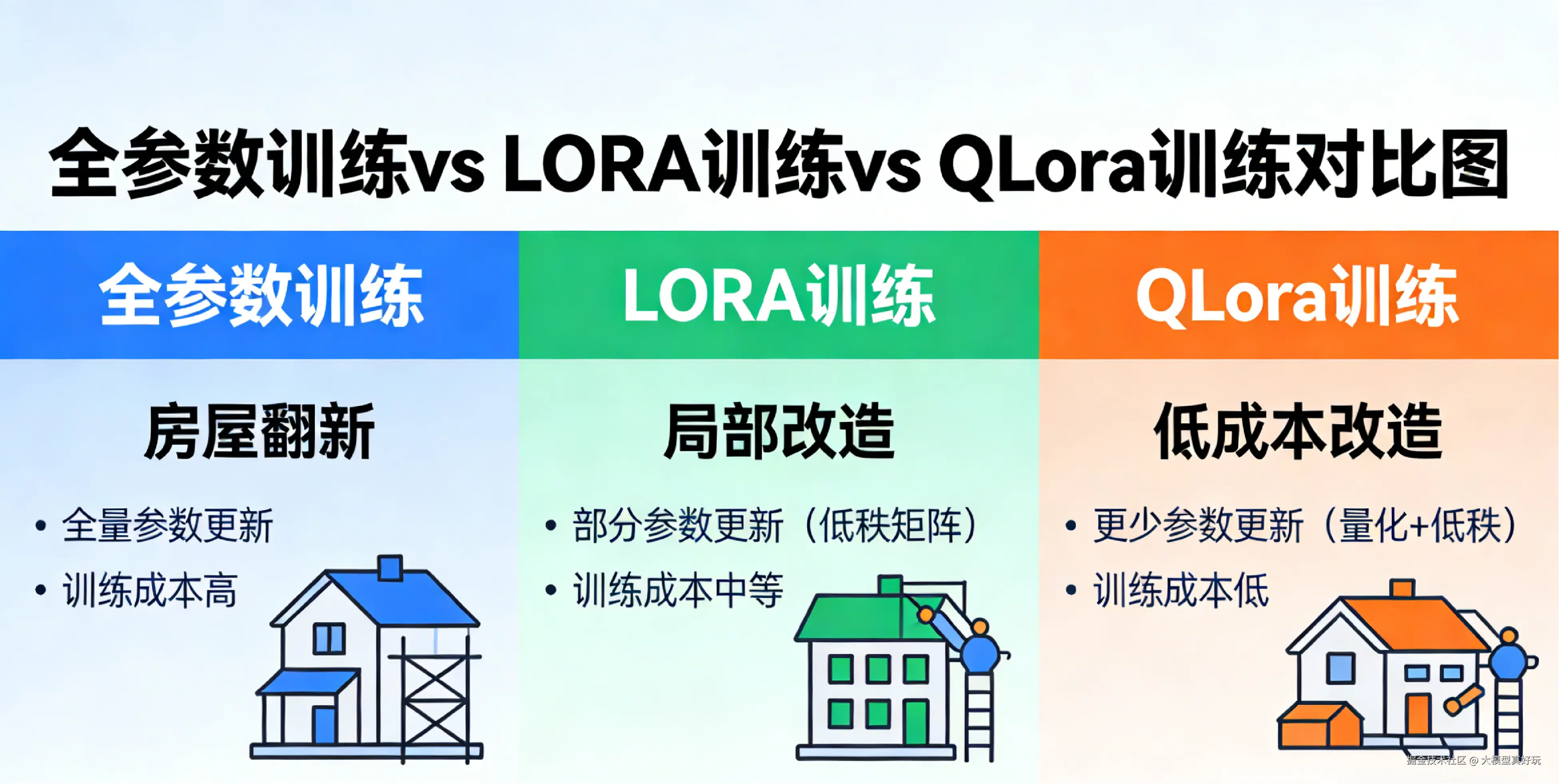
LLaMA Factory 支持多种训练方法,其中最具代表性的三种分别是:全量训练 、LoRA 训练 和 QLoRA 训练 。为了帮大家直观理解它们的区别,笔者这里把大模型比作一套房子,把大模型训练比作一次翻新改造。
1.1 全参数训练:给房子"全部翻新",但小心拆了承重墙
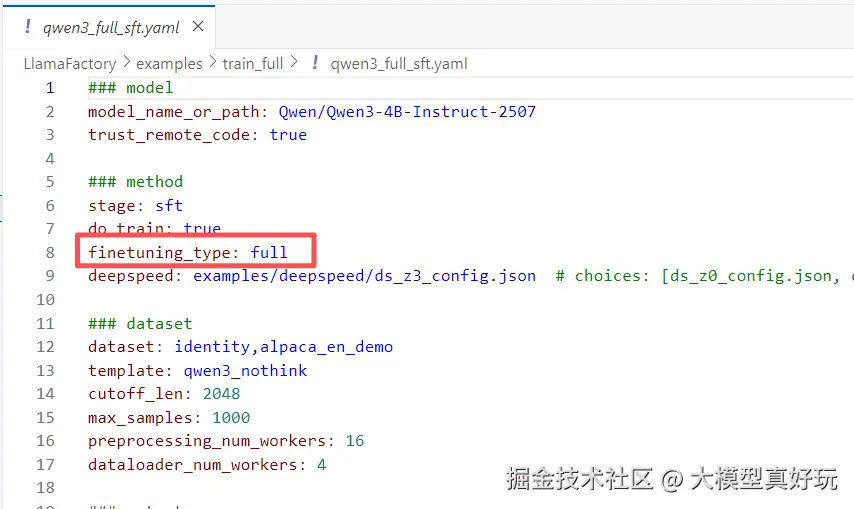
全参数训练最直接------加载预训练模型后,对所有层的所有参数进行梯度更新。相当于把房子从地基到墙面全部翻新一遍,理论上改造效果最好,但代价也最大。
首先是显存成本高。以 LLaMA-7B 模型为例,FP16 精度下模型本身占约 14GB 显存,加上 Adam 优化器需要维护动量和方差状态(额外约 28GB),再算上数据通信等开销,总显存轻松突破百 G,通常需要好几张 A100/H100 这样的高端显卡才能支撑。
其次是对数据质量要求极高。全参数训练就像一个激进的装修队,会改动房子的每一处结构。如果你的图纸(训练数据)不够详细(数据量少)或画错了(质量差),装修队就可能把原本牢固的承重墙拆掉,把好的水电结构改坏。
对应到模型上,这就是灾难性遗忘:为了强行拟合少量或低质数据,模型原有的通用知识(语言能力、推理能力)被大幅覆盖或破坏。结果往往是你的特定任务还没学好,模型原本会的能力(如写代码、做数学题)已经严重退化了。
因此,全参数训练是一把双刃剑 。它需要充足且高质量的标注数据 (通常建议上百万条甚至更多)和强大的算力做支撑。对资源有限、数据不多的初学者和中小企业来说,这条路往往风险大于收益。
1.2 LoRA 训练:给房子"局部改造",不拆承重墙也能焕然一新
与全参数训练的"大拆大建"不同,LoRA 选择了一条更克制的路径:不改动原始模型的任何参数,只在一旁加一个轻量级的"适配器" 。
这就像装修时,不动承重墙、不改水电结构,只是换了新家具、重新刷了墙面、调整了软装。房子的主体框架完好无损,但整体功能性和风格却精准地满足了你当下的需求。
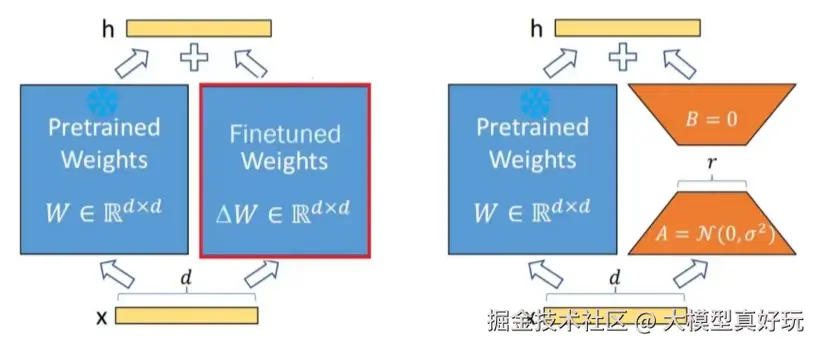
从数学上看,LoRA 把权重的变化量 ΔW 分解为两个低秩矩阵的乘积(A 和 B),通过这种方式"侧面"修改原参数,而原始参数始终保持不变(作为工程人员大家了解基本思想即可,可以不深究数学细节)。
比显存节省更重要的,是它对"图纸"------训练数据的宽容度。
全参数训练需要海量、高质量的"精准图纸",否则装修队会乱拆乱改。而 LoRA 因为原始模型的"骨架"完全冻结不动,只在表面做文章。即便你的图纸只有几百条、质量也未必完美,它也不会破坏模型原有的语言能力和推理能力。最多是"新家具没摆好"(训练效果不佳),不会出现"房子塌了"(能力崩塌)的情况。
这种"低风险、低成本"的特性,让 LoRA 成为中小企业、个人开发者和学术研究者入门大模型训练的最佳选择。 你不需要成千上万条标注数据,也不需要昂贵的 A100 集群,一块普通消费级显卡加上几千几万条精心整理的数据,就能让模型学会你想要的技能。
1.3 QLoRA 训练:更省成本的"局部改造",用"经济型材料"也能出精品
如果说 LoRA 是在不动主体结构的前提下换家具、刷墙面,那 QLoRA 则更进一步------它连家具都换成了"高性价比的环保材料"。
QLoRA 的核心创新在于将原始模型压缩到 4 位精度(NF4 量化) 。打个比方,全参数训练用的是实木梁柱,LoRA 用的是普通钢筋,而 QLoRA 用的是"高强度空心钢"------在保证结构强度的前提下,大幅降低材料重量和成本。量化技术进一步减少了训练时的显存占用(对量化技术有遗忘的读者,可回顾我前期的文章大模型训练全流程实战指南基础篇(三)------大模型本地部署实战(Vllm与Ollama))
但省钱不能以"房子塌了"为代价。
和 LoRA 一样,QLoRA 同样冻结了原始模型的"骨架" (基座模型参数),只训练旁边那小小的适配器。因此它对数据的宽容度依然极高:即便只有几百条数据、质量参差不齐,它也不会破坏模型原有的通用能力。最多是"新家具的款式没选对"(效果稍差),绝不会出现"承重墙被拆"的灾难性遗忘。
实测表明,QLoRA 在多数 NLP 任务上的表现能达到LORA训练的 95% 以上。这意味着,你只需要一张普通显卡、几百条数据,就能以极低的成本,安全、稳定地让大模型学会你想要的技能。
如果说 LoRA 是个人和小团队的"最优解",那 QLoRA 就是"极限性价比之选" ------它把大模型训练的门槛拉到了普通人触手可及的高度。
4 如何选择大模型训练方法?
了解了这三种典型方法后,如何选择其实已经比较清晰了。综合笔者的实战经验来看,我依然推荐 LoRA。
有粉丝可能会问:既然 QLoRA 更省资源,为什么不直接用它?综合实测经验,QLoRA 确实更省显存,但在某些对数值精度敏感的任务中可能出现轻微的性能退化。对绝大多数训练场景来说,LoRA 已经足够好用,且配置简单、调试方便。
结合中小企业、个人科研者的核心痛点,LoRA 的优势一目了然:
- 算力友好 :无需多块高端 GPU,一块 8--12GB 显存的消费级显卡(如 RTX 3060/4060/3090)即可完成 7B 模型的训练。
- 成本可控:可训练参数极少,训练周期短,云 GPU 成本大幅降低。
- 灵活切换 :可以为不同任务训练不同的 LoRA 权重(如客服、写作、编程),运行时按需加载,实现 "一基座,多专家" 的灵活部署。
- 易于分享与版本管理:LoRA 权重文件通常只有几十 MB,方便保存、分享和版本迭代。
- 推理无额外开销:训练完成后可将 LoRA 权重合并回原模型,部署时完全无性能损耗。
简单来说,LoRA 训练用最少的资源解决了"能不能训"的问题,同时保留了足够的灵活性和效果,是绝大多数个人和小团队入局大模型训练的最佳选择。
二、LLaMA Factory LoRA 配置文件详解
下面进入本章的核心内容:LLaMA Factory LoRA 配置文件详解 。通过上一章的介绍大家应该已经发现,用 LLaMA Factory 训练大模型其实非常简单------写好配置文件 test_qwen_sft.yaml,然后执行一条命令:
bash
llamafactory-cli train /workspace/test_sft/test_qwen_sft.yaml整体操作并不复杂,但真正考验功力的地方在于如何写好这份配置文件。本节笔者就用通俗易懂的语言,对上篇文章中使用过的训练参数进行逐一拆解,确保大家都能真正理解大模型训练的核心知识。
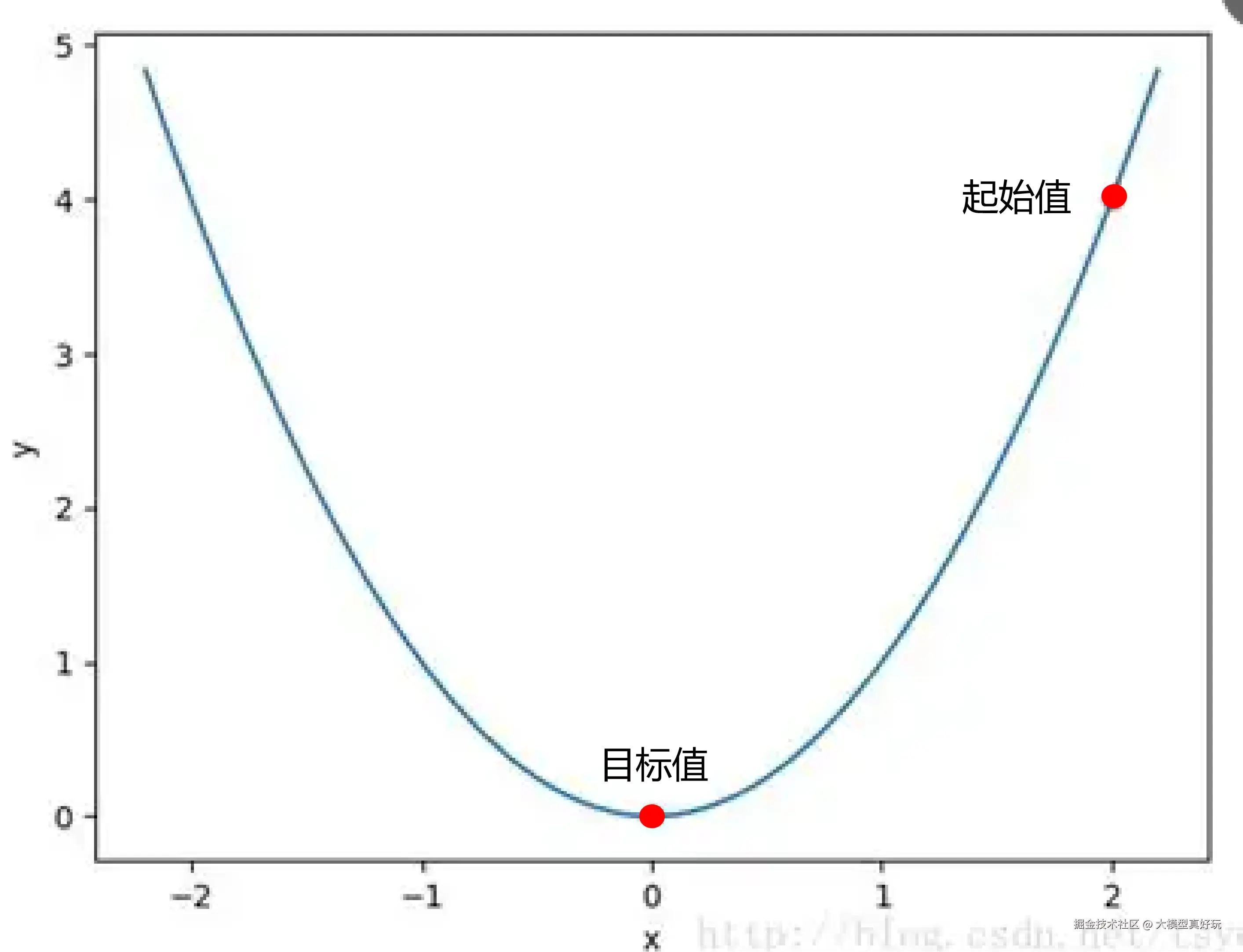
在深入参数之前,笔者先明确一个核心概念:大模型训练的本质,就是让模型学习用户提供的数据分布,使模型生成的内容与用户提供的数据越来越像 。那么,模型生成的内容和用户数据之间的差异,就需要一个量化指标来衡量------这个指标就是 loss。训练的目标,就是让 loss 尽可能降到最低。用一张图来形象表示,就是从起始点不断下降,靠近目标值。
如果大家跟着上篇文章实操过,应该会在模型保存目录 /workspace/test_sft/Qwen2_5_sft/ 下看到一个 trainer_log.jsonl 文件,里面就记录了每个步骤的 loss 值,用来判断模型的拟合情况。
有了这个概念笔者就可以开始逐一解析配置文件中的参数了。上篇文章使用的配置文件路径为 /workspace/test_sft/test_qwen_sft.yaml。
2.1 模型参数
yaml
### model
model_name_or_path: /workspace/Qwen2_5_0_5
trust_remote_code: true-
model_name_or_path:模型文件的本地存储路径,指定要训练的基础大模型位置。LLaMA Factory 会从这个路径读取原始模型参数。
-
trust_remote_code :是否信任模型的自定义代码。部分模型(如通义千问)需要加载自定义代码才能正常读取模型结构,因此需要设为
true。
2.2 训练方法相关参数
yaml
### method
stage: sft
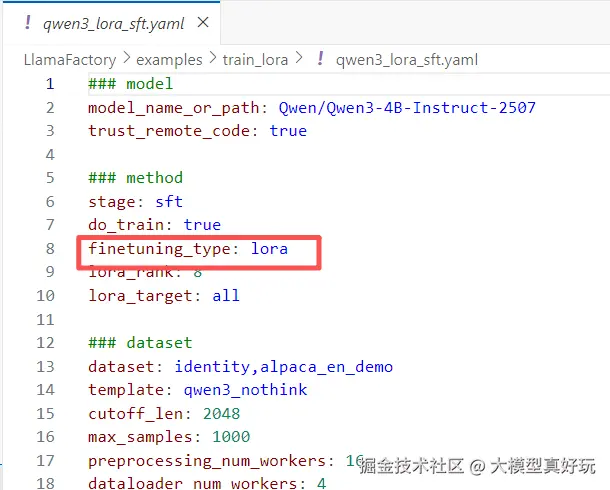
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all-
stage :表示训练阶段。
pt表示预训练(pre-training),sft表示指令微调(supervised fine-tuning)。这里指定为sft。 -
do_train :是否开启训练。设为
true启动训练流程,设为false则只验证配置不执行训练。 -
finetuning_type :微调类型。指定为
lora,表示采用 LoRA 微调模式,而非全参数微调或 QLoRA。
以上三个参数比较好理解,接下来三个参数与 LoRA 机制密切相关,笔者结合 LoRA 的原理来重点讲解。
先回顾一下 LoRA 的核心思想:通过引入一个轻量级的"适配器"来间接影响原模型参数,而原始参数本身保持不变。公式可以简化为:
h=W0x+rα×BAx
其中:
- W0 为基座模型冻结权重(原模型参数,不参与训练)
- BA 为低秩矩阵的乘积(可训练的新参数)
- r 为低秩矩阵的秩(lora_rank)
- α 为缩放因子(lora_alpha)
这个结构可以用下图直观表示:
对应到配置文件中,就是以下三个参数:
-
lora_rank (即公式中的 r):低秩矩阵的秩数。数值越大,适配器的表达能力越强,能处理更复杂的任务,但可训练参数增多,显存占用也相应增加;数值越小,资源消耗越低,适配能力稍弱。默认值为 8,推荐范围 4~64。
-
lora_alpha (即公式中的 α):可以理解为 LoRA 的"音量调节旋钮",控制低秩矩阵学到的特征对基座模型的影响强度。数值越大,适配器的影响越"激进";数值越小,模型越贴近基座模型的原生能力。一般设为
lora_rank的 1~2 倍(例如 rank=8 时 alpha=16),以保持缩放因子平衡。LLaMA Factory 默认将lora_alpha设为lora_rank的 2 倍。 -
lora_target :指定在模型的哪些层和结构上附加 LoRA 参数。笔者在之前的文章《大模型训练全流程实战指南基础篇(二)------大模型文件结构解读与原理解析》中讲过,大模型由不同层构成,不同层又通过注意力机制具备不同结构。通常情况下,直接设为
all匹配所有层是最简单的选择;如果需要精细控制,推荐优先在q_proj和v_proj上添加(查询投影层和值投影层),因为这两个位置对任务迁移最敏感。
通过公式和图示,LoRA 相关参数的配置逻辑是不是就清晰多了?
2.3 数据集配置
yaml
dataset: alpaca_zh_demo
template: qwen
cutoff_len: 2048
max_samples: 1000
preprocessing_num_workers: 16
dataloader_num_workers: 4-
dataset :指定训练所用的数据集。需要注意,自定义数据集需要在
dataset_info.json中预先注册,具体方法可参考上一篇文章。 -
template :大模型的对话模板,也就是文章《大模型训练全流程实战指南基础篇(二)------大模型文件结构解读与原理解析》中介绍过的
chat_template。LLaMA Factory 在后台处理时会自动将数据按照该模板组织成模型可接受的格式。 -
cutoff_len :最大截断长度。数据集中不同文本的长度不一,但模型的输入需要统一长度。该参数指定一个最大长度,超出部分被截断,不足部分用
<pad>填充。注意,单条数据不宜过长,否则会显著增加显存占用。对于 7B 模型,通用场景设为 2048 即可,长文本场景可设为 4096。 -
max_samples:训练使用的最大样本数。有时候并不需要把全部数据都用于训练,该参数可以限制实际使用的样本数量。
-
preprocessing_num_workers:数据预处理时的线程数。数据集需要与模板结合才能生成模型可用的输入,这个过程可以并行加速,该参数用来控制预处理线程数。
-
dataloader_num_workers:数据加载时的线程数。数据要先加载到内存才能快速喂给模型训练,该参数控制加载数据的线程数,可根据显存大小适当调整。
2.4 输出配置
yaml
output_dir: /workspace/test_sft/Qwen2_5_sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none-
output_dir:训练好的 LoRA 适配器保存路径。
-
logging_steps :日志打印的步数间隔。比如,如果一次传入 100 条数据,每一步梯度更新处理 10 条数据(具体与后面的
gradient_accumulation_steps相关),那么总共会有 10 步。每 10 步会在日志文件中记录一次 loss。 -
save_steps:模型保存的步数间隔。训练过程中不仅只在最后保存一次模型,为了防止意外中断或需要对比中间结果,建议定期保存检查点。该参数控制每多少步保存一次适配器。
-
overwrite_output_dir :如果输出目录不为空,是否覆盖目录内容。设为
true表示覆盖。 -
save_only_model :控制保存内容。
false表示保存完整断点(支持断点续训);true表示仅保存权重(用于推理)。 -
report_to:为了更直观地监控训练过程,可以将训练日志上传到一些公开平台(如 wandb、swanlab),实现远程实时查看。该参数用于配置这些平台的接入方式。
2.5 核心训练超参数(重要!)
大家常说,大模型训练工程师调参的过程就像太上老君炼仙丹,需要在不同参数的组合中反复尝试,才能炼出"最好的丹"。这些"不同参数的组合",指的就是核心训练超参数。可以说,超参数的设置是大模型训练工程师的看家本领。
为了让大家更直观地理解这些超参数,笔者依然用前面那张loss 下降图 来类比:大模型的训练,本质上就是从起始点不断下降、寻找最优 loss 的过程。虽然实际模型是一个极其高维的函数,远不止二维这么简单,但背后的思想是一致的------都是在寻找一个尽可能低的 loss 点。
首先来看看大模型训练相关的超参数配置:
yaml
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
num_train_epochs: 1.0
learning_rate: 1.0e-4
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null 参数一: per_device_train_batch_size
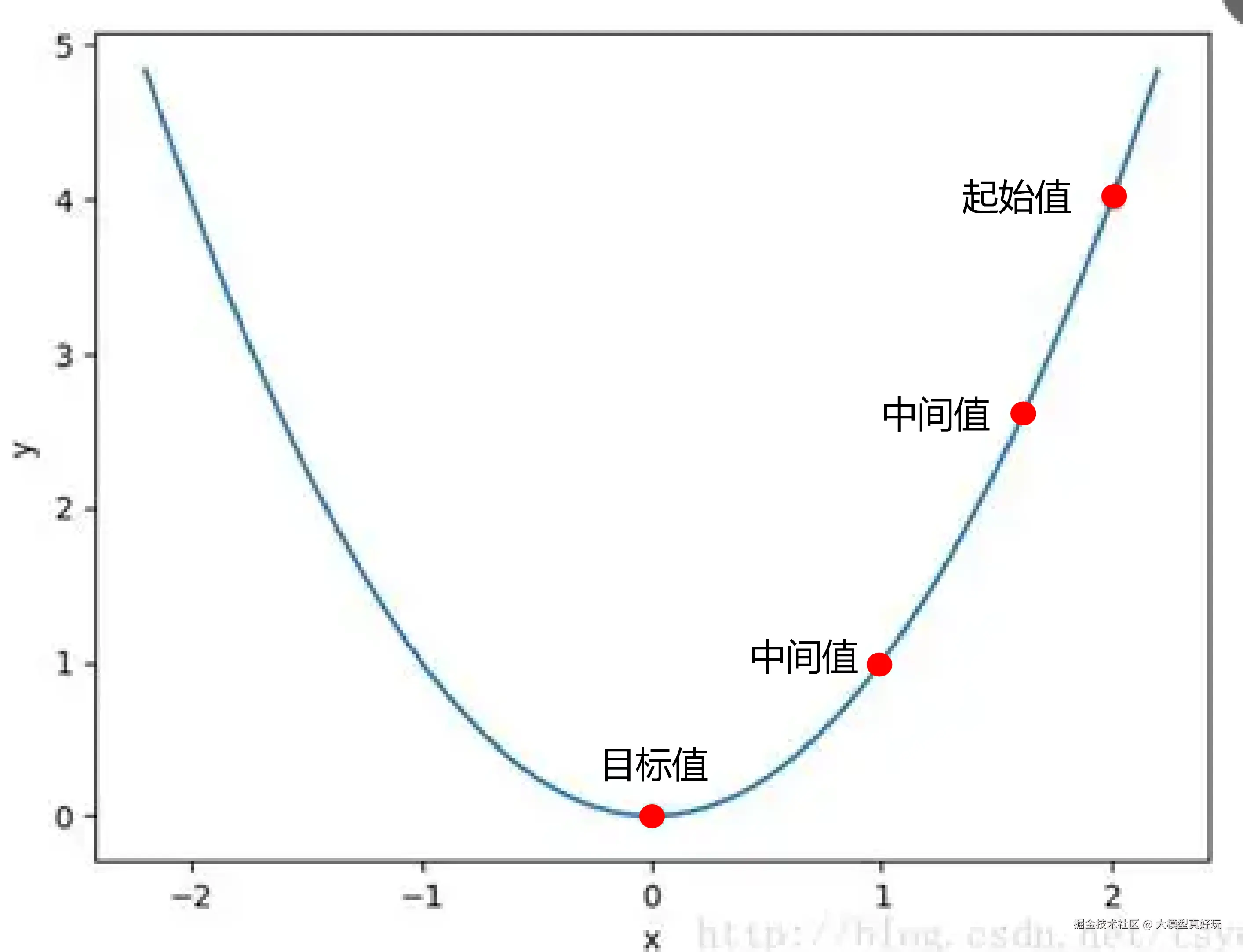
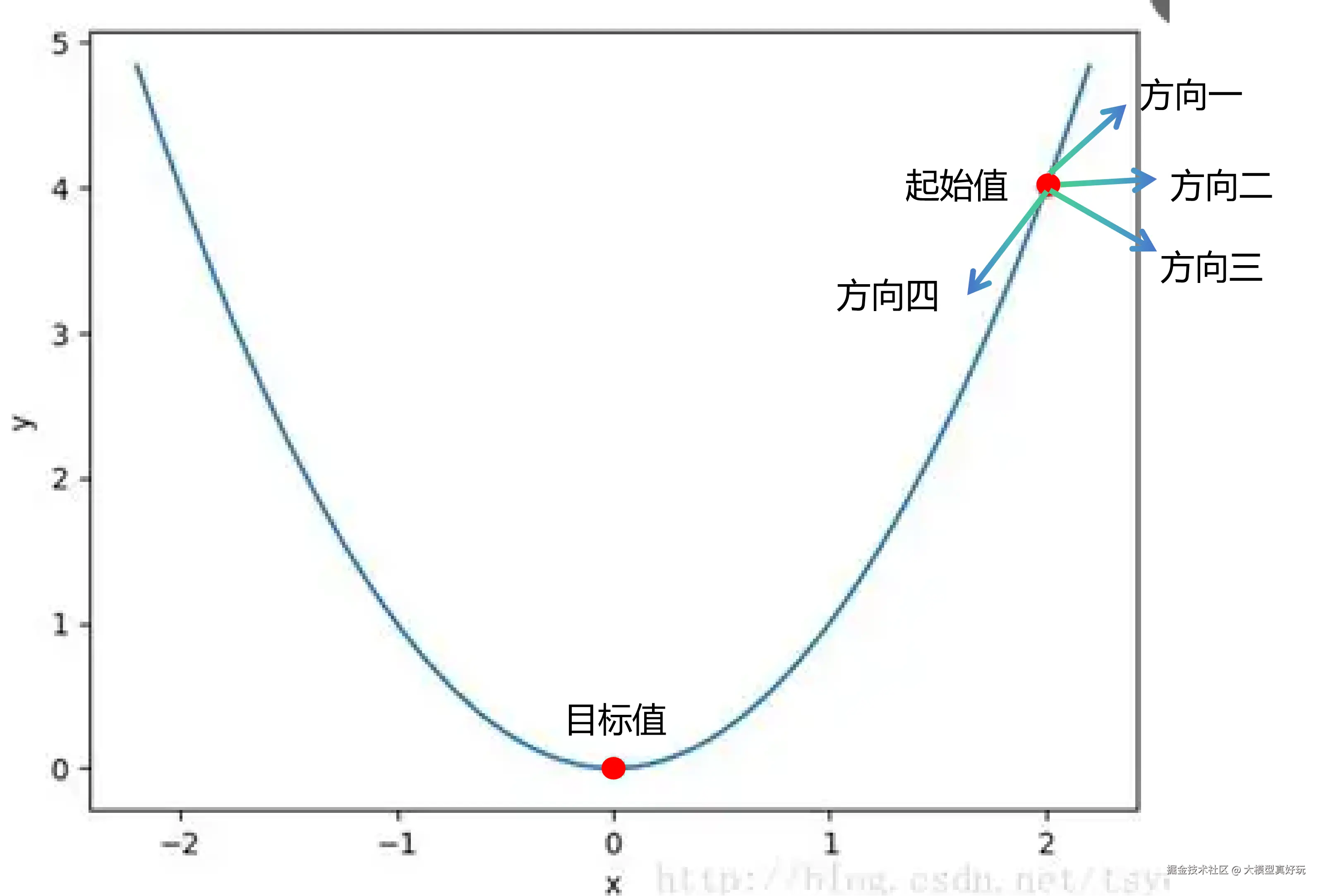
假设模型当前在起点位置,它该朝哪个方向走才能到达最优解?是方向一、方向二,还是方向三、方向四?显然,方向四才是正确的。那么,这个"方向四"是如何计算出来的?
简单来说,就是计算训练数据与当前模型 loss 之间的"斜率"(即梯度),从而确定下降方向。但训练数据量通常巨大,无法一次性全部计算。于是采用一个直观的方法:每次只拿一小部分数据来计算方向和步长,用局部趋势近似整体方向 。这个小批量的数据量,就是 per_device_train_batch_size。
参数二: gradient_accumulation_steps
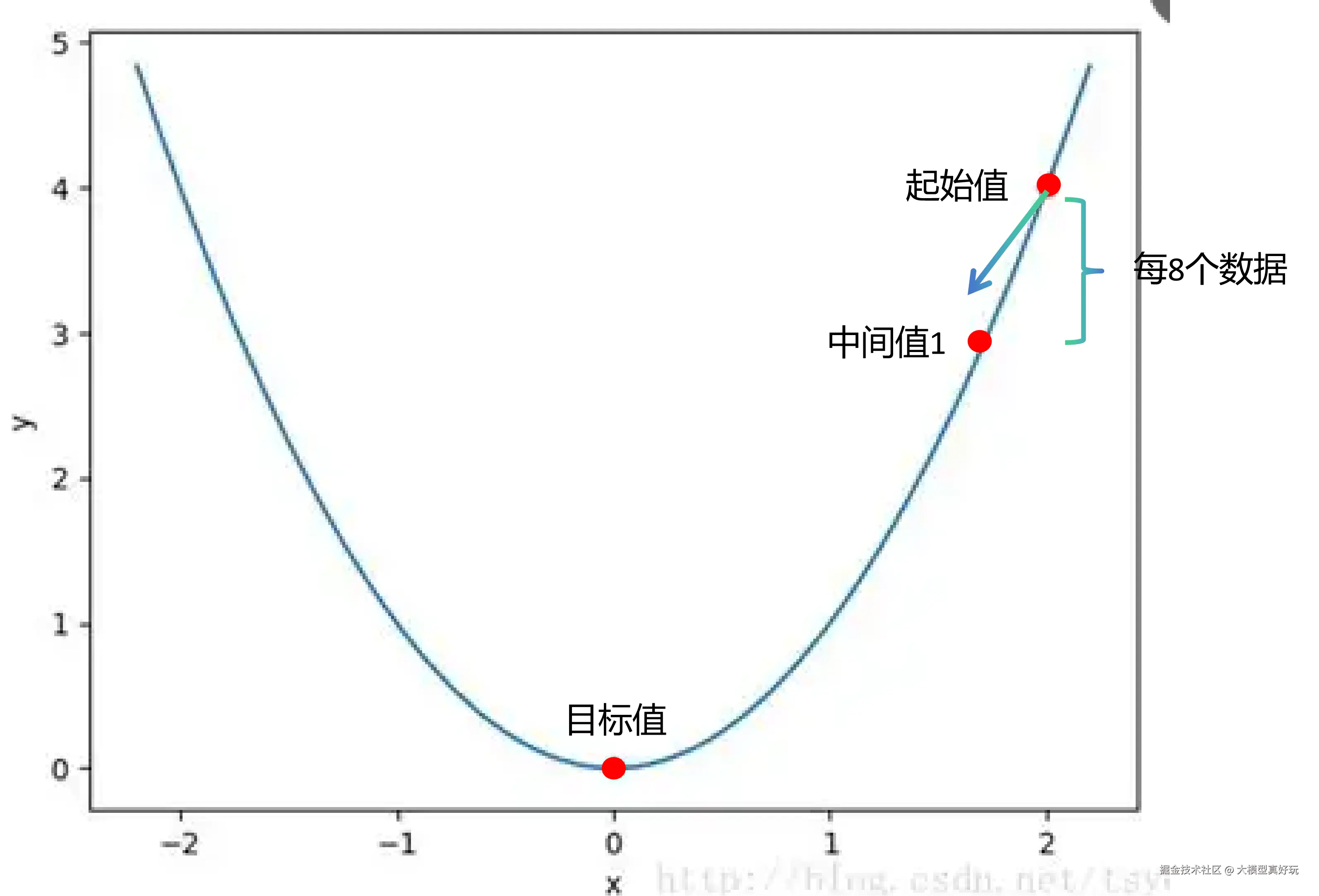
如果单批次数据量太小,每算一小批就更新一次权重可能过于"草率"。这时候可以累积多个批次的梯度,然后再统一更新一次 ,用小批次模拟大批次的效果。这就是 gradient_accumulation_steps 的作用。
有效批次大小 = 单卡批次大小 × 梯度累积步数 。以上面配置为例,1 × 8 = 8,相当于每处理 8 条数据才更新一次梯度。
参数三: num_train_epochs
这个参数很好理解------将全部训练数据完整训练多少遍。num_train_epochs 设为 1,表示所有数据只训练一轮。
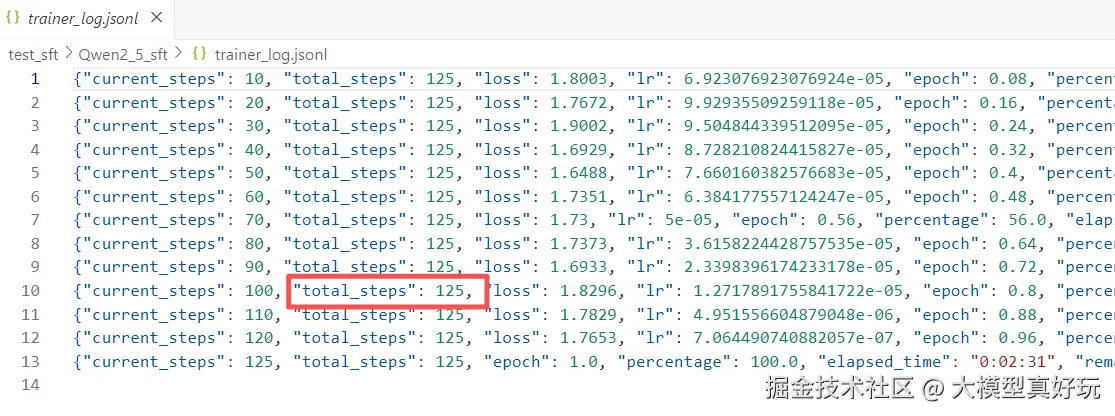
结合前面几个参数,大家来算一下训练的总步数。配置中 max_samples = 1000(取 1000 条数据),num_train_epochs = 1,有效批次大小为 1 × 8 = 8,因此总步数为:
(10001)/(18) = 125步
而 logging_steps 设为 10,表示每 10 步记录一次 loss。看看训练日志,是不是一目了然?
参数四: learning_rate
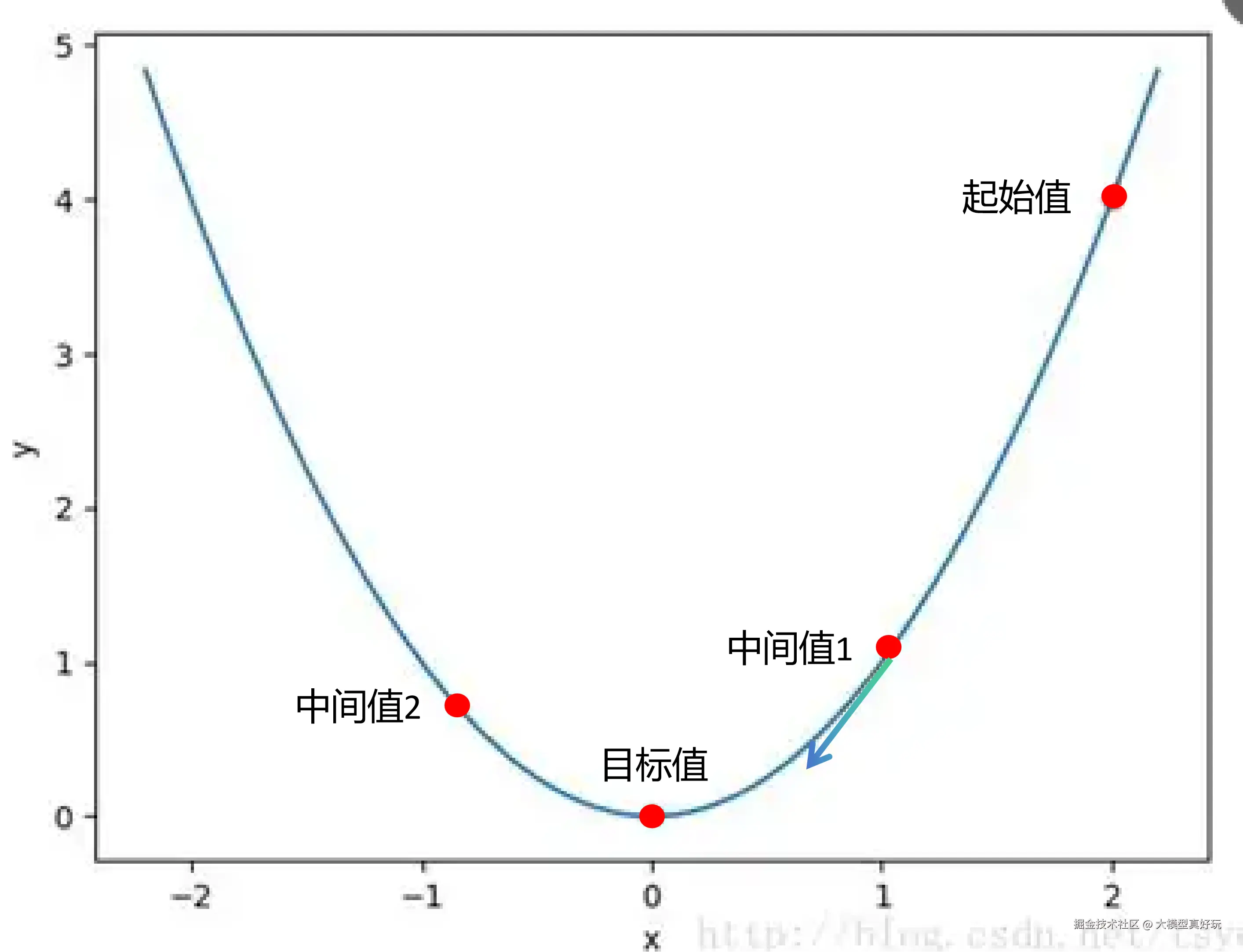
梯度下降不仅需要方向,还需要步幅。就像走路,方向对了,迈多大的步子决定了最终到达的位置。这时候有人可能会想:既然要快速下降,那把学习率设大一点不就好了?
其实不然。看下面这张图,如果当前在"中间值 1"的位置,学习率设置过大,一步就可能跨过最优解,直接跳到"中间值 2",反而错过了最低点。所以,学习率需要谨慎设置。
参数五: warmup_ratio 与 lr_scheduler_type
由于一开始不确定设置的学习率是否合适,通常会让学习率从一个很小的值逐渐上升到设定值 ,这个过程叫 warmup (相当于慢慢升温的过程,和谈恋爱一样)。warmup_ratio 表示 warmup 阶段占总训练步数的比例。例如总步数为 100,warmup_ratio = 0.1,那么前 10 步学习率从 0 线性增加到设定值。
而随着训练接近尾声,为了防止在最优解附近震荡,比如下图中就从中间值n直接跳到了中间值n+1, 然后反复横跳。要解决这个问题往往还需要让学习率逐渐衰减 。lr_scheduler_type 就是用来指定衰减策略的,LoRA 微调推荐使用 cosine(余弦退火),学习率会按照余弦曲线平滑下降。
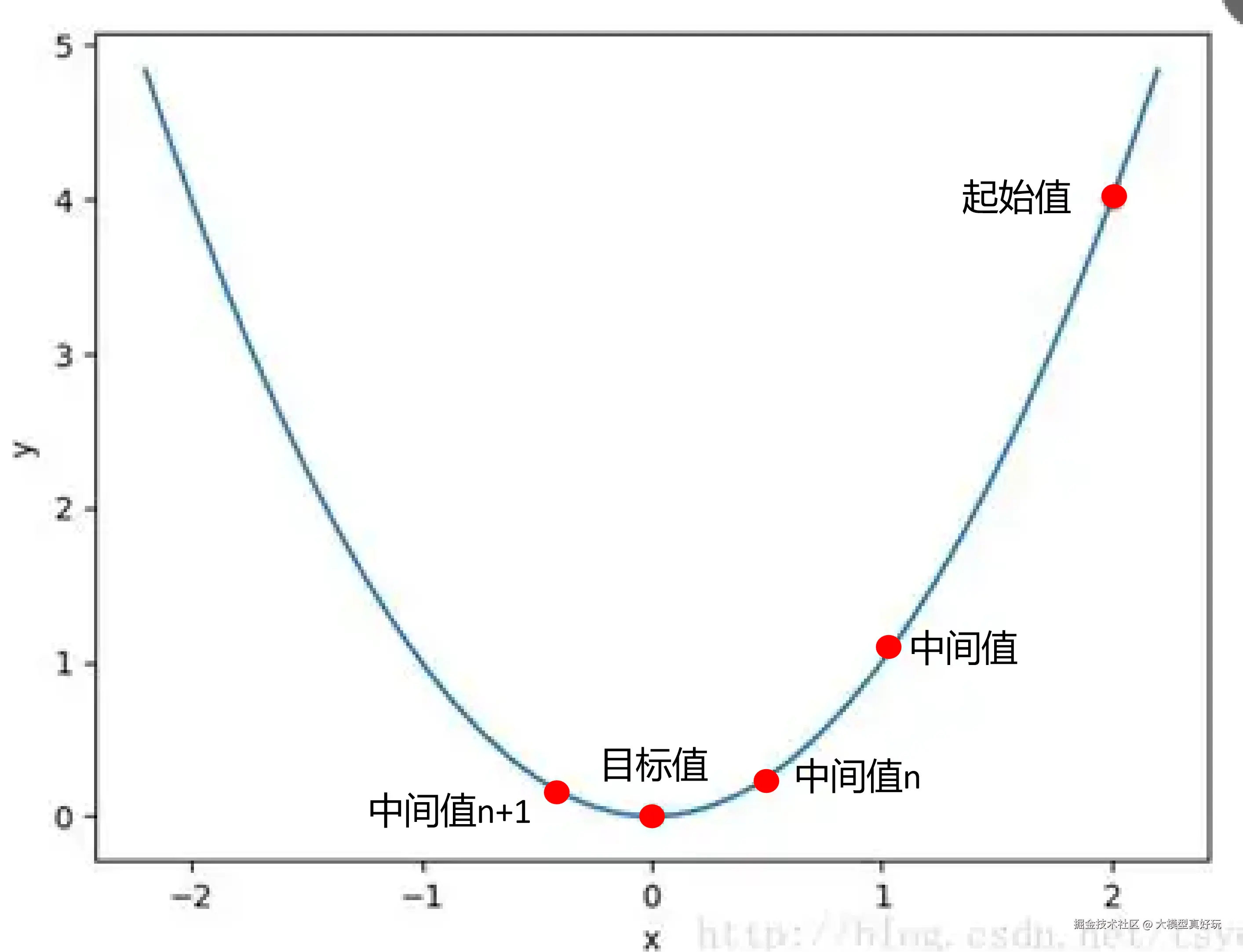
参数六: 其他参数
其它的参数就比较好理解了
-
bf16:混合精度训练开关。部分计算使用 BF16(16 位浮点数),仅在优化器更新时使用 FP32(32 位浮点数),对于每个参数都是32位浮点数表示的大模型可以有效降低显存占用。
-
ddp_timeout:分布式训练的超时时间。大模型训练耗时较长,设置一个较长的超时时间可以防止因网络波动等原因提前中断训练。
-
resume_from_checkpoint :断点续训的起点。如果训练意外中断,可以指定之前保存的检查点目录(通过
save_steps保存的中间结果)来恢复训练。设为null表示从头开始训练。
2.6 验证集配置
虽然在上一篇文章的配置文件中,验证集相关参数被笔者注释掉了。但在实际训练中,这部分配置非常必要。
试想一下,如果把所有数据都用来训练,然后计算 loss,就像让学生做的考试题全是平时练过的------考试时测不出真实水平。相反,如果用大部分数据训练(题海战术),留出一小部分数据作为验证集(模拟考试),用这部分数据来评估模型的 loss,才能更客观地反映模型的泛化能力。
yaml
# eval_dataset: alpaca_en_demo
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500-
eval_dataset :指定一个独立的验证集。该数据集同样需要在
dataset_info.json中预先注册。 -
val_size:如果不想单独准备验证集,也可以设置这个参数,从训练集中划出一部分数据作为验证集(0.1 表示划出 10%)。
-
per_device_eval_batch_size:评估时的批处理大小,用于加速评估过程。
-
eval_strategy 与 eval_steps :评估策略,
eval_strategy: steps表示按步数定期评估,eval_steps: 500表示每 500 步进行一次验证。
通过验证集配置,大家可以实时观察模型在"考试"中的表现,避免模型只会"背题"而不会"做题"。
三、LoRA 参数调优初步指南
经过前面两节的详细讲解,大家应该已经对每个参数的含义有了比较清晰的认识。但理论归理论,真正动手配置时,可能还是会纠结:这个值设多少合适?为什么别人用的配置我照搬却效果不好?
本节笔者先给出一个相对稳妥的参数设置建议,帮助大家快速上手。至于在什么场景下应该调整哪些参数、如何根据训练曲线进行针对性优化,笔者会在下期文章中结合实际工作案例详细展开(欢迎关注我的同名微信公众号 大模型真好玩,更多智能体开发和大模型训练教程会第一时间在公众号上发布)。
3.1 lora_rank 调优规则
lora_rank 决定了适配器的表达能力。数值越大,可训练参数越多,模型适配复杂任务的能力越强,但显存占用也相应增加。可以参考以下经验值:
- 7B 及以下模型:推荐 4--8,基线设为 8 即可覆盖大部分场景
- 13B 模型:推荐 8--16,可根据显存情况适当调整
- 显存紧张时:可降至 2--4,优先保证训练能够跑起来
- 任务复杂度高:可升至 16--32,提升模型对复杂模式的拟合能力
核心原则:先保证显存够用,再根据任务复杂度逐步提升 rank。
3.2 lora_alpha 调优规则
lora_alpha 控制适配器对基座模型的影响强度。它与 lora_rank 共同决定了公式中的缩放因子 rα,建议联动调整:
- 通用基线 : α=r(如
r=8时alpha=8),可以适配 90% 以上的常规微调场景 - 欠拟合时 :训练 loss 下降缓慢、验证效果不佳,可将 α 设为 2×r(如
r=8时alpha=16),增强微调力度 - 过拟合时 :训练 loss 持续走低但验证 loss 不降反升,可适当降低 α,削弱微调强度,保留基座模型的泛化能力
核心原则 :保持 rα 在 1~2 之间,既能保证训练稳定,又留出足够的调节空间。
3.3 learning_rate 调优规则
学习率是影响训练收敛速度和稳定性的关键参数。LoRA 微调通常比全参数微调可以使用稍高的学习率:
- 推荐范围 : 1×10−4 ~ 2×10−4
- loss 震荡或发散 :说明学习率偏高,建议适当降低(如降至 5×10−5)
- loss 下降极其缓慢 :说明学习率偏低,可尝试小幅提升(如升至 3×10−4)
核心原则:从小值开始试探,观察 loss 曲线再逐步调整。
3.4 批次组合调优(显存优先)
有效批次大小 = per_device_train_batch_size × gradient_accumulation_steps,建议目标有效批次不低于 8,以保证梯度估计的稳定性。
常见组合示例:
- 单卡批次 = 1,梯度累积 = 8 → 有效批次 = 8
- 单卡批次 = 1,梯度累积 = 16 → 有效批次 = 16
- 单卡批次 = 2,梯度累积 = 4 → 有效批次 = 8
如果显存不足,优先降低单卡批次大小,然后用梯度累积来补偿有效批次。
核心原则:在显存允许的范围内,优先保证有效批次足够,再考虑提升单卡批次以加快训练速度。
以上就是 LoRA 训练方法的核心参数配置指南。内容虽多,但每个参数的背后都有其设计逻辑。如果一次消化不完,可以收藏下来,在实际训练中对照着看。也欢迎大家在实际操作中遇到问题时,在评论区留言交流。
四、LLaMA Factory LoRA 合并参数详解
在上篇文章《大模型训练全流程实战指南工具篇(九)------LLaMAFactory大模型训练工具使用指南》中笔者曾提到,LoRA 训练出来的只是一个轻量级的"适配器",它本身并不能直接用于推理。需要将这个适配器与原始模型融合,才能得到一个完整的、可独立部署的模型。这个融合过程,就需要用到合并配置文件。
下面就是合并配置文件的示例(通常命名为 test_qwen_merge_sft.yaml):
yaml
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: /workspace/Qwen2_5_0_5
adapter_name_or_path: /workspace/test_sft/Qwen2_5_sft
template: qwen
trust_remote_code: true
### export
export_dir: /workspace/test_sft/Qwen2_5_sft_all
export_size: 5
export_device: cpu # choices: [cpu, auto]
export_legacy_format: false相比于训练配置文件,合并配置文件的参数要简洁得多,理解起来也相对容易。笔者逐项拆解。
4.1 模型定义部分
这部分用于指定"基础模型"和"要合并的适配器"。
-
model_name_or_path: /workspace/Qwen2_5_0_5这是基础模型的本地路径。合并操作会把 LoRA 适配器中学到的权重变化,注入到这个基础模型的对应层中。这里使用的是 Qwen2.5 0.5B 版本。
-
adapter_name_or_path: /workspace/test_sft/Qwen2_5_sft这是LoRA 适配器 的路径。使用 LLaMA Factory 进行微调后,保存的并不是一个完整的全量模型,而是一个很小的"补丁"文件包,通常包含
adapter_model.bin和adapter_config.json等文件。这个参数就是告诉工具:请把这个"补丁"合并到基础模型上。 -
template: qwen指定对话模板。不同模型家族(如 Qwen、Llama、Baichuan)使用的对话格式各不相同,包括 system、user、assistant 的角色标记和结束符都有差异。由于基础模型是 Qwen2.5,这里必须设置为
qwen,确保合并后的模型在调用聊天接口时格式正确。 -
trust_remote_code: true是否信任模型仓库中的自定义代码。对于一些非标准架构的模型(Qwen 系列就经常包含自定义的建模文件),加载时可能需要执行这些自定义代码才能正确读取模型结构。设置为
true可以避免因代码执行权限问题导致的加载失败。
4.2 导出部分
这部分定义了合并后模型的输出方式。
-
export_dir: /workspace/test_sft/Qwen2_5_sft_all合并后模型的输出目录。执行合并命令后,LoRA 适配器的权重会被计算并融合进基础模型,最终在这个目录下生成一个完整的、可独立部署的模型文件(如
model.safetensors或pytorch_model.bin)。你可以把这个目录当作一个全新的、可以直接用于推理的模型来使用。 -
export_size: 5单个模型文件的大小限制(单位:GB)。如果合并后的模型总大小超过这个值,导出程序会自动将模型权重拆分成多个分片文件。例如,模型总大小为 10GB,设置
export_size: 5后,会生成两个约 5GB 的文件(如model-00001-of-00002.safetensors)。这种分片机制可以绕过一些文件系统对大文件的限制,也是 Hugging Face 和 ModelScope 上常见的大模型分发方式。 -
export_device: cpu指定合并运算时使用的设备。
cpu:在 CPU 上进行合并。虽然速度较慢,但不会占用显存。如果你的显存不足以同时加载基础模型和 LoRA 适配器进行合并,建议使用 CPU。auto:自动选择可用设备(通常是 GPU)。合并速度更快,但需要确保显存足够容纳基础模型和计算过程中的临时数据。需要提醒的是,某些环境下使用auto可能会遇到兼容性问题,如果遇到奇怪的报错,可以尝试切回cpu。
-
export_legacy_format: false决定输出文件的格式。
false(推荐):使用 safetensors 格式。这是一种更安全、加载速度更快的模型存储格式,能有效避免因 pickle 反序列化带来的安全风险。目前主流的大模型仓库大多采用这种格式。true:使用传统的 bin 格式(pytorch_model.bin),适用于需要兼容旧代码的场景。
合并完成后,大家得到的就不再是一个"补丁"了,而是一个完整的、可以直接本地加载步数的独立模型。这个模型既保留了基础模型的通用能力,又融入了微调时学到的特定技能,可以随时用于推理或进一步部署。
五、总结
本文系统讲解了 LLaMA Factory 的核心训练参数,从全量训练、LoRA 到 QLoRA 的方法对比,到LORA配置文件中每一个参数的含义与调优建议,再到适配器的合并导出,通过形象的比喻和详尽的内容确保大家都能掌握大模型训练的参数,帮助大家真正理解大模型训练的"内功心法",从"能跑通"走向"效果好、可控"。下篇文章笔者将结合真实业务场景,深入讲解如何根据训练日志动态调整参数,手把手带大家学会炼出"最好的仙丹"的过程。欢迎持续关注!
除大模型训练外,笔者也在同步更新《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏,要说明该专栏适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 42 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。