****论文题目:****MoECLIP: Patch-Specialized Experts for Zero-shot Anomaly Detection(零射异常检测补丁专家)
会议:CVPR2026
****摘要:****CLIP模型出色的泛化能力推动了最近零射击异常检测(Zero-Shot Anomaly Detection, ZSAD)的成功,用于检测未见类别的异常。ZSAD的核心挑战是在保留CLIP强大的泛化能力的同时,将模型专一化用于异常检测任务。试图解决这一挑战的现有方法都有补丁不可知论设计的基本限制,即整体性地处理所有补丁,而不考虑它们的独特特征。为了解决这一限制,我们提出了MoECLIP,一种用于ZSAD任务的混合专家(MoE)架构,它通过根据每个图像补丁的独特特征动态路由每个图像补丁到专门的低秩自适应(LoRA)专家来实现补丁级自适应。此外,为了防止LoRA专家之间的功能冗余,我们引入了(1)冻结正交特征分离(FOFS),它对输入特征空间进行正交分离,以迫使专家关注不同的信息;(2)利用单纯形等角紧框架(ETF)损失来调节专家输出以形成最大的等角表示。跨越工业和医疗领域的14个基准数据集的综合实验结果表明,MoECLIP优于现有的最先进的方法。
代码可在https://github.com/CoCoRessa/MoECLIP上获得。
MoECLIP:用混合专家架构解锁零样本异常检测的新范式
一、背景与动机
1.1 视觉异常检测的发展脉络
视觉异常检测(Visual Anomaly Detection, AD)旨在识别偏离正常模式的异常区域,在工业缺陷检测和医疗图像诊断中有着广泛的应用价值。由于异常样本天然稀缺,传统的无监督异常检测(UAD)范式只利用正常样本进行建模,但即便如此,它依然需要目标类别有充足的正常数据可供训练------这在很多数据稀缺的真实场景中仍然是一个重大瓶颈。
为此,**零样本异常检测(Zero-Shot Anomaly Detection, ZSAD)**应运而生。ZSAD 借助 CLIP(Contrastive Language-Image Pretraining)等视觉语言大模型(VLM)所蕴含的丰富视觉语义知识,在不依赖目标类别任何样本的前提下,实现对"未见类别"的异常检测。
1.2 CLIP-based ZSAD 的核心思路
如图 1(a) 所示,CLIP-based ZSAD 的基本原理是:将图像划分为若干 patch,计算各 patch 的图像嵌入与"正常/异常"文本嵌入之间的余弦相似度,相似度高者判为异常。
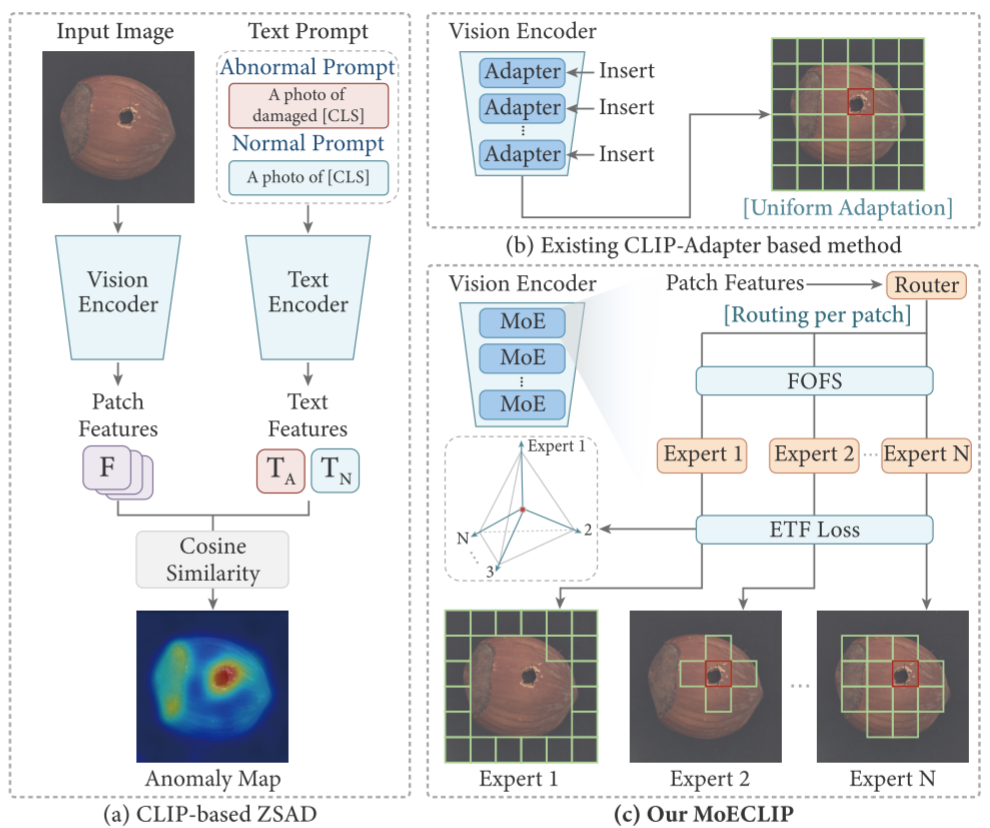
然而,CLIP 原本是为全局语义理解而预训练的,对局部异常的感知能力天然不足。因此,如何在保留 CLIP 强泛化能力的同时,将其针对异常检测任务进行专业化适配,是 ZSAD 领域的核心挑战。
二、现有方法的根本局限:Patch-Agnostic 设计
2.1 代表性方法回顾
围绕上述挑战,学界提出了多种适配策略:
- PromptAD / AnomalyCLIP:将 CLIP 的 QKV Attention 替换为 V-V Attention,引导模型关注局部区域
- April-GAN / CLIP-AD:引入线性适配器增强 patch 表示
- AdaCLIP / VCP-CLIP:采用混合 Prompt 学习方案提升文本与图像 patch 嵌入的对齐
- AA-CLIP:通过残差适配器与解耦损失,分阶段适配文本编码器和视觉编码器
- Bayes-PFL:从贝叶斯推理视角将文本 prompt 空间建模为可学习概率分布
2.2 共同的根本缺陷
尽管上述方法各有侧重,但它们增强图像 patch 表示的方式都存在同一个根本性的设计缺陷 ------如图 1(b) 所示,它们对图像中所有 patch 施加完全相同的变换(Uniform Adaptation),完全忽视了不同区域(物体主体、背景纹理、异常区域)在结构与语义上的本质差异。
这种 Patch-Agnostic(patch 无感知) 设计,从根本上限制了模型识别细粒度异常模式的能力。试想:一张工业零件图像中,背景区域与零件主体、与表面划痕,三者需要截然不同的"分析视角"------用同一套参数"一刀切"地处理显然是不合适的。
三、MoECLIP:Patch-Specialized 的混合专家架构
3.1 整体设计哲学
针对上述问题,本文提出 MoECLIP ,其核心思想(如图 1(c) 所示)是:将混合专家(Mixture-of-Experts, MoE) 架构集成到 CLIP 视觉编码器中,让每个图像 patch 根据自身的独特特征,动态路由到最适合处理它的专家,从而实现真正意义上的 patch 级别自适应。
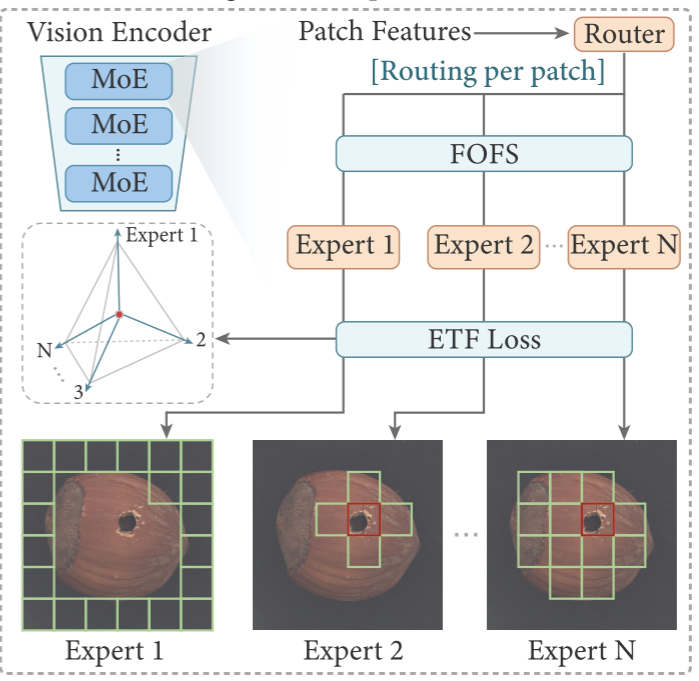
3.2 整体框架
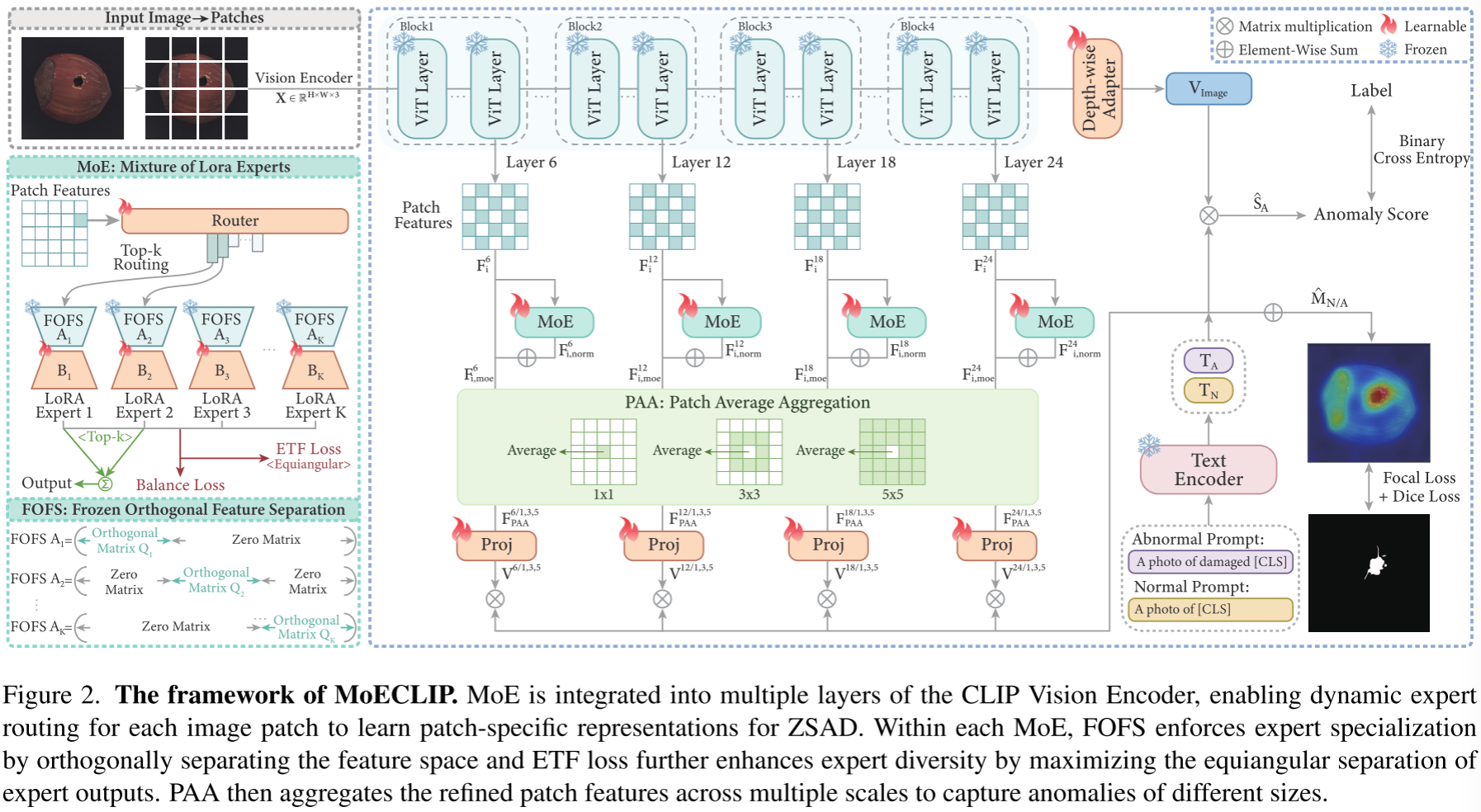
如图 2 所示,MoECLIP 的整体架构包含以下几个关键模块:
- 冻结的 CLIP 视觉编码器(ViT-L/14-336):所有预训练权重保持冻结,以保留 CLIP 的泛化能力
- 多层 MoE 模块:分别集成在 ViT 的第 6、12、18、24 层输出处,实现多层次的 patch 级特征适配
- FOFS(冻结正交特征分离):在专家输入端强制特征子空间正交分离
- ETF 损失:在专家输出端施加等角约束,进一步增强专家多样性
- PAA(Patch 平均聚合):多尺度聚合,捕捉不同大小的异常
- Depth-wise Adapter:轻量化特征精炼,用于图像级异常评分
四、核心技术详解
4.1 MoE-based 特征适配
MoE 模块中包含一个路由器(Router)和 K 个 LoRA 专家 。对于第 l 层的第 i 个 patch 特征 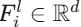 :
:
- 路由器计算各专家的路由分数,选出分数最高的 Top-k 个专家(本文 K=4,k=2)
- 对选中的专家进行归一化加权,计算专家输出的加权和
- 对 MoE 输出进行
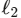 范数归一化,消除范数不匹配问题:
范数归一化,消除范数不匹配问题:
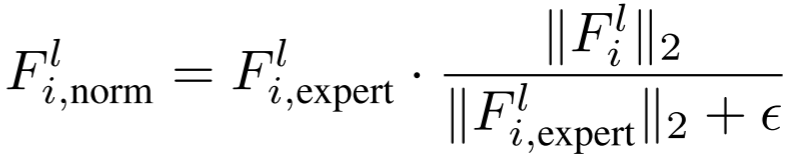
- 通过残差连接与原始特征融合:
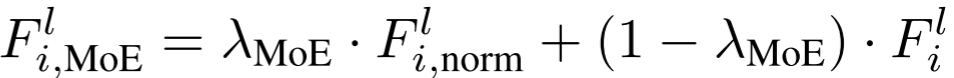
设计细节 :
说明模型主要依赖原始 CLIP 特征,仅用少量适配信号进行微调,这是有意为之------过度依赖适配特征会损害 CLIP 的泛化能力(消融实验中大于0.4后性能显著下降)。
4.2 冻结正交特征分离(FOFS)
FOFS 的核心思想是从初始化阶段就从结构上保证每个专家只能"看到"输入特征的不同子空间。
具体实现:将 d 维输入特征均分为 K 个不重叠子空间 ,第 n 个专家的 LoRA 下投影矩阵
,第 n 个专家的 LoRA 下投影矩阵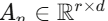 定义为:
定义为:
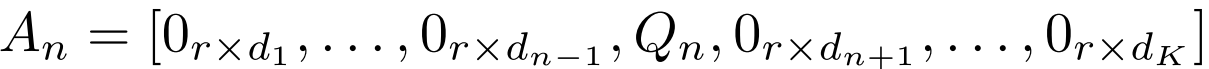
其中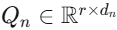 是通过 QR 分解得到的随机正交矩阵,其他位置全为零矩阵。这保证了
是通过 QR 分解得到的随机正交矩阵,其他位置全为零矩阵。这保证了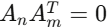 (对n≠m),即所有专家的输入投影互相正交。
(对n≠m),即所有专家的输入投影互相正交。
更关键的是:An 在训练过程中保持冻结。这一设计受到近期 LoRA 研究的启发------随机初始化的正交 A 矩阵可以达到与学习得到的 A 矩阵相当的性能,而冻结 A 矩阵则有助于防止过拟合并保留 CLIP 的泛化能力。
4.3 ETF 损失(Simplex Equiangular Tight Frame Loss)
即便 FOFS 在输入阶段强制了专家的信息分离,专家可学习的上投影矩阵 Bn 在训练中仍可能收敛到相似的特征空间,造成输出阶段的功能冗余。ETF 损失正是为此设计的。
理想的 ETF 结构要求 K 个向量的 Gram 矩阵满足:
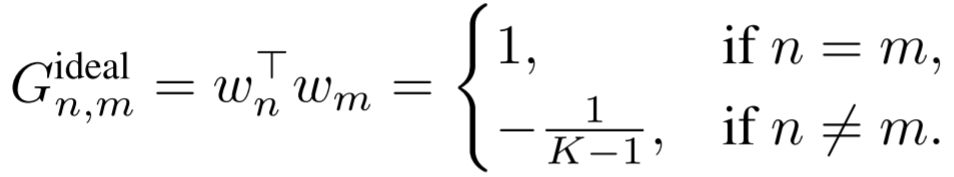
这意味着所有向量具有相同的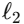 范数,且任意两向量之间的余弦相似度都等于
范数,且任意两向量之间的余弦相似度都等于 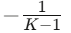 ,即在几何上实现最大程度的等角分离。
,即在几何上实现最大程度的等角分离。
ETF 损失通过最小化各 patch 的专家输出 Gram 矩阵与理想 ETF Gram 矩阵之间的 Frobenius 范数来实现这一目标:
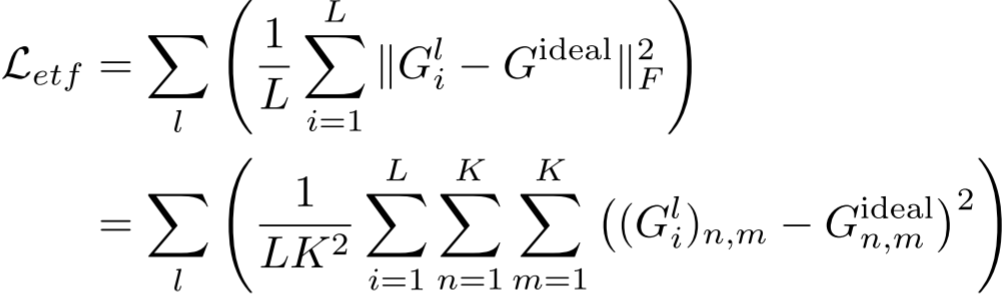
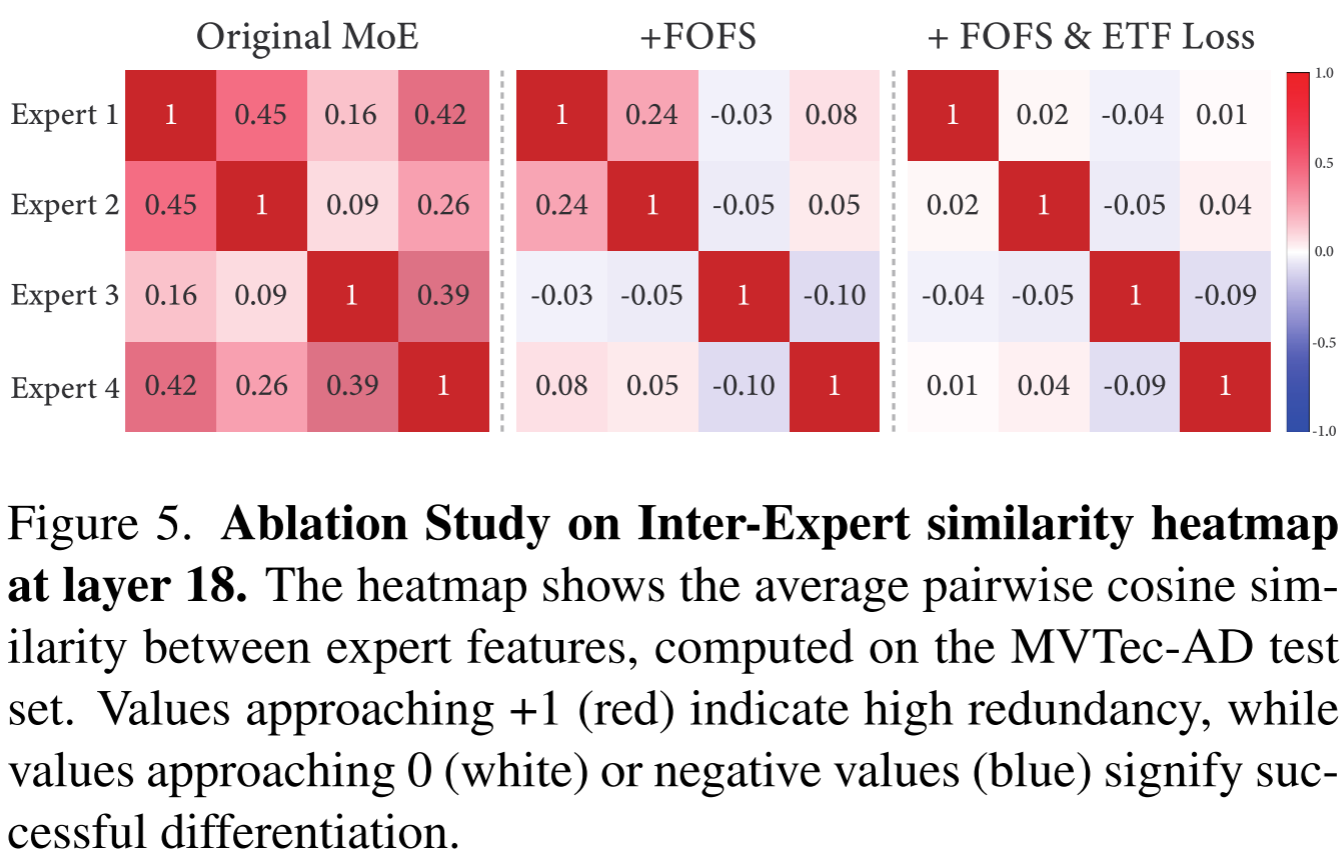
如图 5 中的消融实验所示,三种配置下专家间余弦相似度的变化清晰展示了各组件的作用:
- 原始 MoE(无 FOFS & ETF) :Expert 1 和 Expert 2 之间相似度高达 0.45,功能冗余严重
- 加入 FOFS :相似度降至 0.24,有所改善但仍有残余冗余
- 完整 MoECLIP(FOFS + ETF Loss) :相似度进一步降至 0.02,实现了近乎完全的功能分化
4.4 Patch 平均聚合(PAA)
CLIP 的 ViT 采用固定尺寸的 patch 划分,天然难以感知不同尺度的异常。PAA 模块对每个位置 (h,w) 的 patch 特征,计算以其为中心的s尺寸的滑动窗口内所有 patch 特征的平均值:
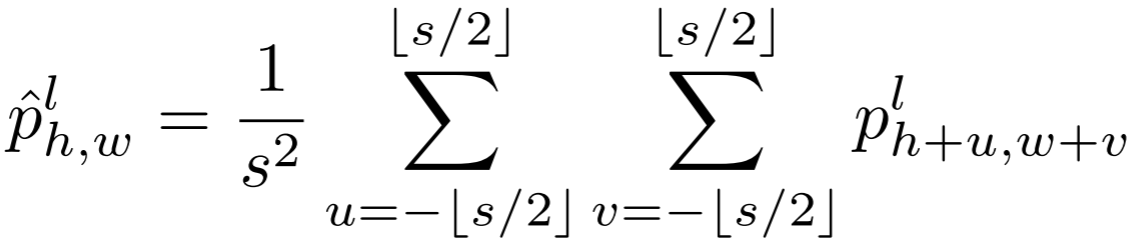
本文使用三种尺度1, 3, 5,分别捕捉精细局部信息(s=1)和更大上下文范围(s=3,5)。重要的是,PAA 在训练阶段就被使用,而非仅在推理阶段,这使模型在训练时就能获得多尺度感知能力。
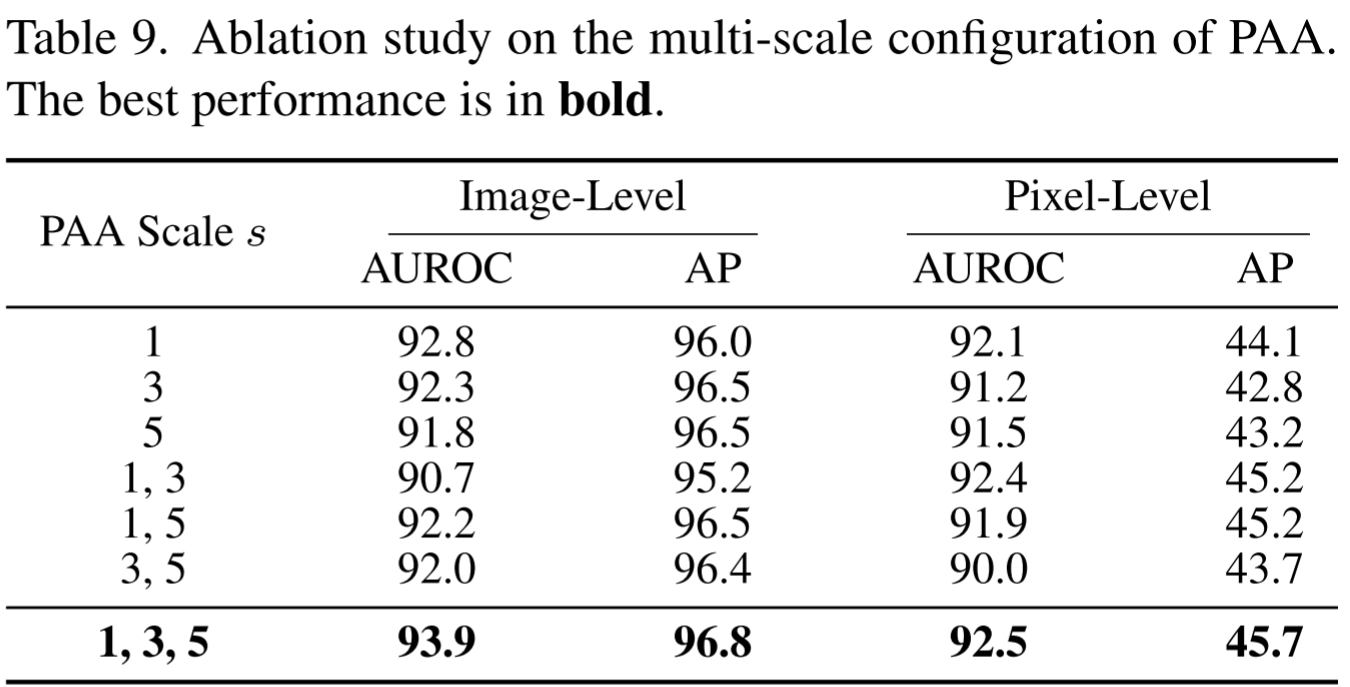
消融实验显示,单独使用 s=3 或 s=5 反而会损害性能(因过度平滑导致细节丢失),而三尺度组合1,3,5取得最优结果。
4.5 损失函数
总损失函数由四部分组成:
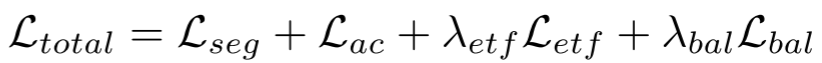
- Lseg:像素级异常分割损失(Focal Loss + Dice Loss),应对异常区域小、正负样本极不平衡的问题
- Lac:图像级异常分类损失(Binary Cross-Entropy)
- Letf:ETF 专家分化损失(权重0.01)
- Lbal:专家负载均衡损失(权重0.01),基于路由概率的变异系数平方,防止专家坍塌
五、专家专业化的可视化分析

图 3 对 MVTec-AD 榛子类别的可视化分析是本文最直观的证据之一。通过 Grad-CAM(梯度加权类激活映射)和路由决策可视化,可以清晰看到四个专家学习到了截然不同的功能角色:
| 专家 | 关注区域 | 路由特征 |
|---|---|---|
| Expert 1 | 异常区域及部分背景 | 对异常相关 patch 的 Top-1 选择 |
| Expert 2 | 物体主体 | 主要处理物体主体区域的 patch |
| Expert 3 | 背景区域 | 主要处理背景 patch |
| Expert 4 | 极少激活 | 在 MVTec-AD 上利用率极低 |
Expert 4 的低利用率并非冗余,而是数据集特异性的体现。如图 9 所示,在不同数据集(如 BTAD、RSDD 等)上,各专家的利用率分布截然不同,说明每个专家确实捕捉了独特的 patch 特征------Expert 4 仅在 MVTec-AD 上鲜少被激活,但在其他数据集上可能扮演关键角色,这对于面向未见类别的 ZSAD 任务的鲁棒泛化至关重要。
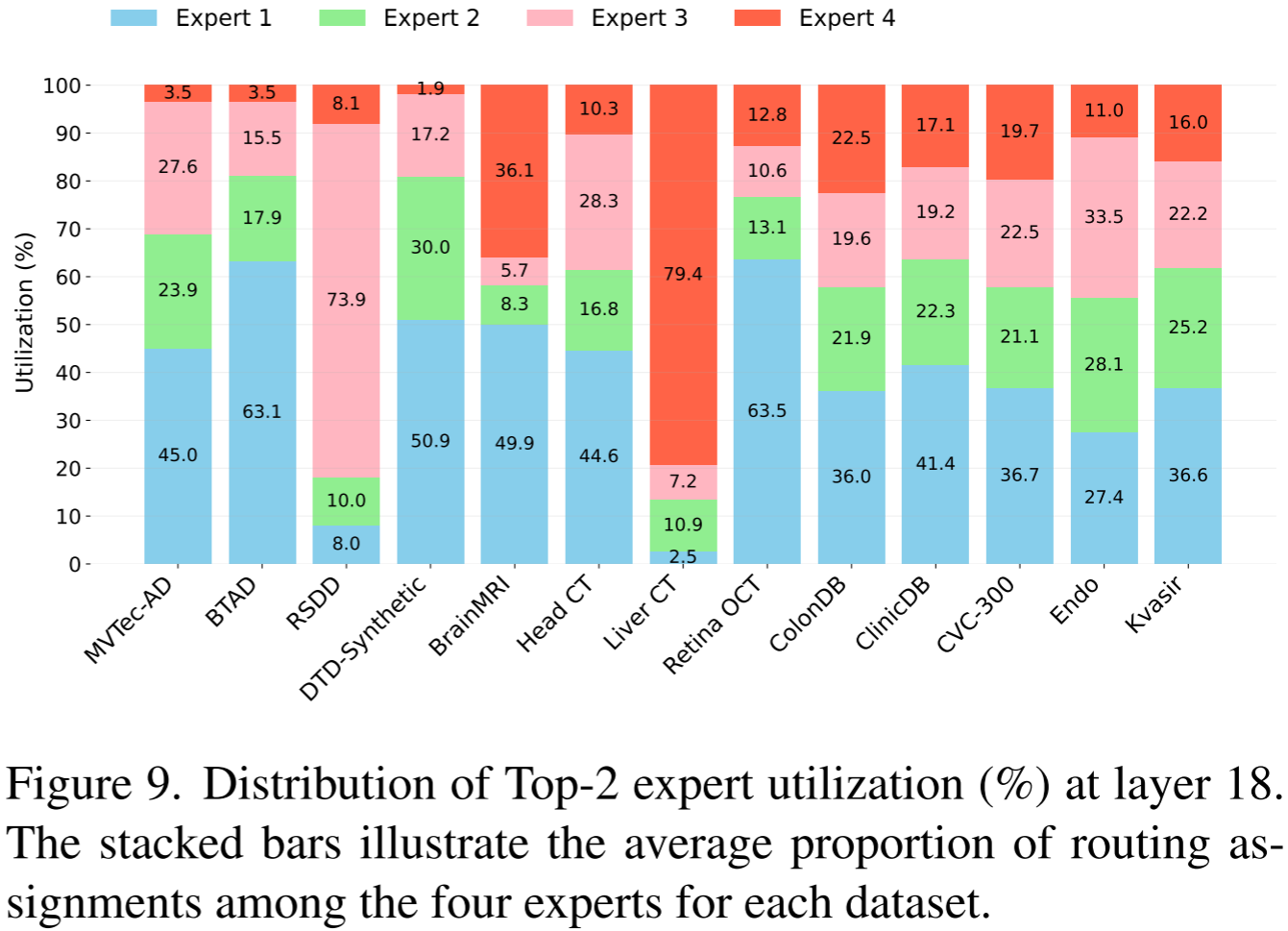
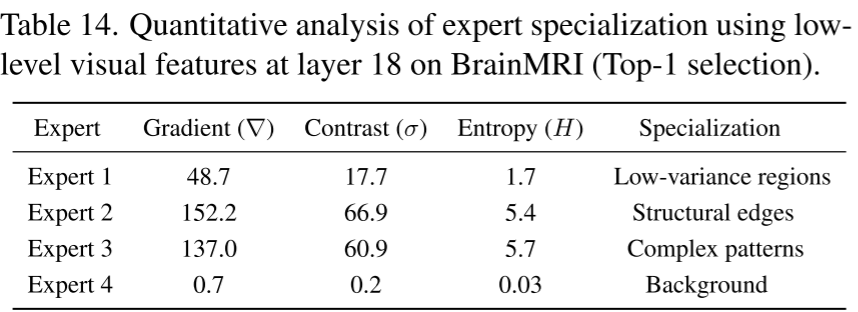
进一步地,表 14 从量化角度验证了专家在 BrainMRI 数据集上的功能分化:Expert 4 捕获近乎零信息量的背景(Gradient≈0.7,Entropy≈0.03),Expert 1 处理低方差的均匀区域,Expert 2 专注于强结构边缘(最高 Gradient=152.2),Expert 3 专注于高复杂度纹理模式(最高 Entropy=5.7)。
六、实验结果
6.1 实验设置
- 骨干网络:OpenCLIP ViT-L/14-336(OpenAI 预训练)
- 训练集:VisA(12类工业数据集),用于评估其余 13 个数据集;MVTec-AD 用作训练集时评估 VisA
- 测试集:14 个数据集,包括 5 个工业数据集(MVTec-AD, VisA, BTAD, RSDD, DTD-Synthetic)和 9 个医疗数据集(Brain MRI, Head CT, Liver CT, Retina OCT, 以及 5 个结肠息肉检测数据集)
- 评估指标:图像级 AUROC 和 AP(异常分类),像素级 AUROC 和 AP(异常分割)
- 训练配置:Adam 优化器,学习率 5\\times10\^{-4},20 个 epoch,2×NVIDIA Tesla V100 16GB
6.2 与 SOTA 方法的全面对比
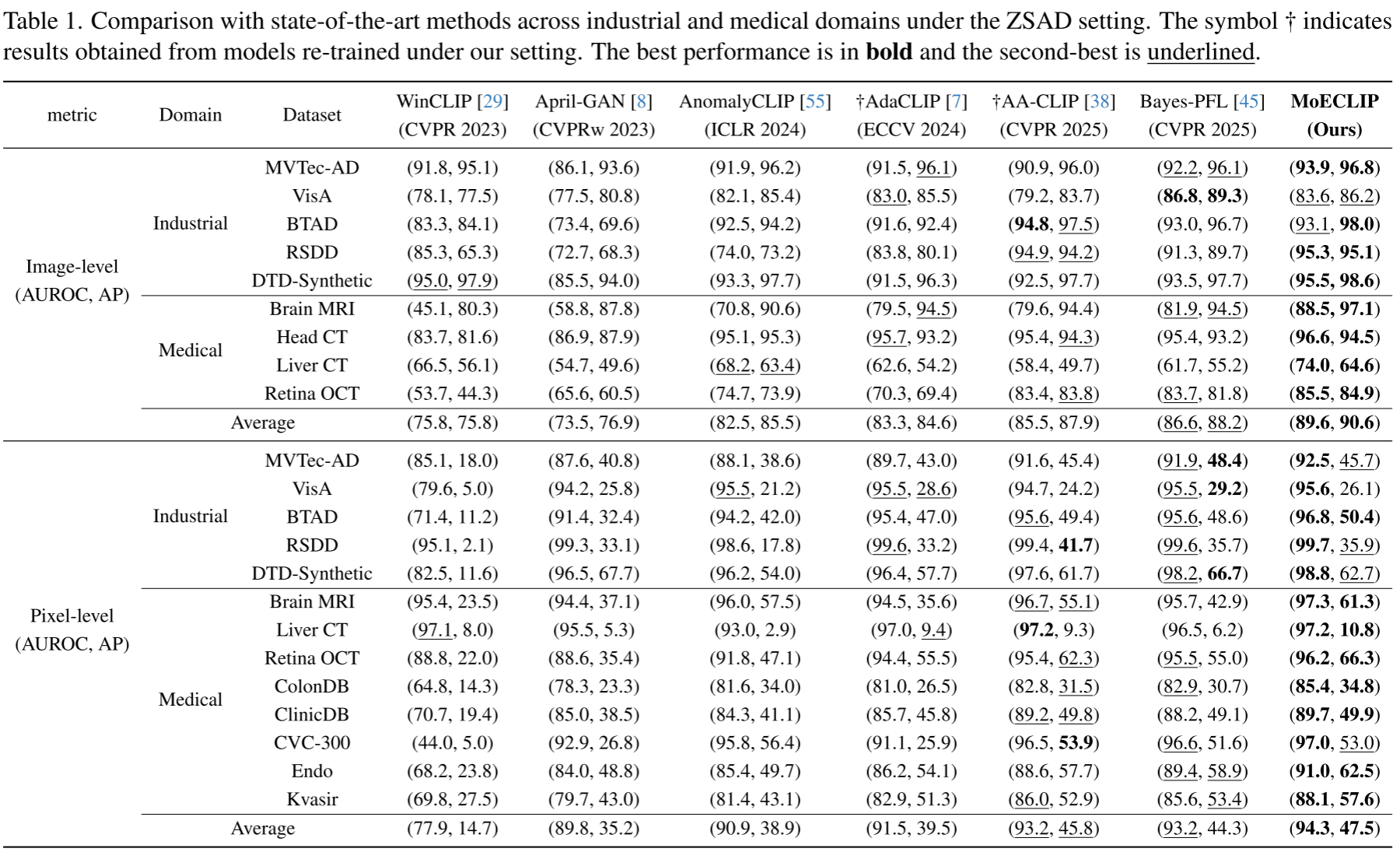
如表 1 所示,MoECLIP 在 14 个数据集的绝大多数指标上均达到最优:
图像级性能(AUROC / AP):
- 平均 AUROC:89.6% (vs 第二名 Bayes-PFL 的 86.6%,+3.0%)
- 平均 AP:90.6% (vs 第二名 88.2%,+2.4%)
像素级性能(AUROC / AP):
- 平均 AUROC:94.3% (vs 第二名 93.2%,+1.1%)
- 平均 AP:47.5% (vs 第二名 45.8%,+1.7%)
尤其值得关注的是医疗领域的性能,Brain MRI 图像级 AUROC 从 AA-CLIP 的 79.6% 大幅提升至 88.5%(+8.9%),体现了 patch 专业化专家在跨域泛化中的强大能力------这些专家仅在工业数据上训练,却能鲁棒地迁移到医疗领域。
6.3 消融实验
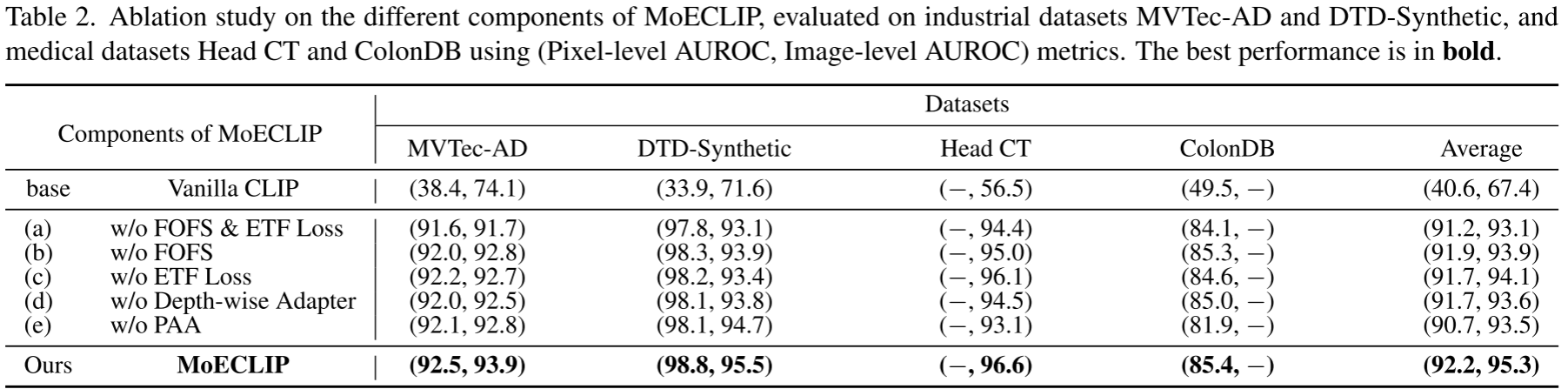
表 2 对 MoECLIP 各组件进行了系统性消融,关键结论如下:
-
MoE 本身的价值:即使没有 FOFS 和 ETF Loss(配置 a),相比 Vanilla CLIP 基线(Pixel-level AUROC 仅 40.6%),加入 MoE 后性能就飙升至 91.2%。这证明了 patch 级动态路由的根本价值。
-
FOFS 和 ETF Loss 的互补性:单独去掉 FOFS(配置 b)或 ETF Loss(配置 c),性能均有所下降,说明两者从输入和输出两端共同解决功能冗余问题,缺一不可。
-
PAA 对医疗领域的关键性:去掉 PAA(配置 e)后,ColonDB 的像素级 AUROC 从 85.4% 下降至 81.9%,说明多尺度上下文聚合对医疗图像异常检测尤为重要。
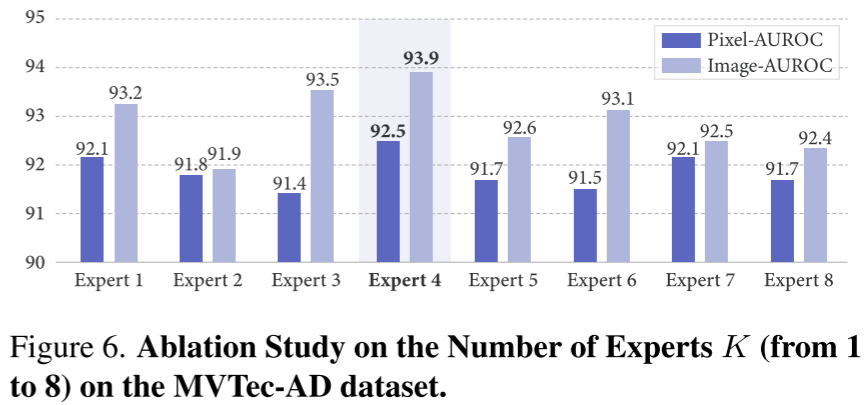
如图 6 所示,专家数量并非越多越好。K=4 时性能最优,专家过少(K=1,2)导致专业化不足,专家过多(K=6,7,8)则引入功能冗余,K=4 提供了最佳平衡点。
6.4 超参数分析
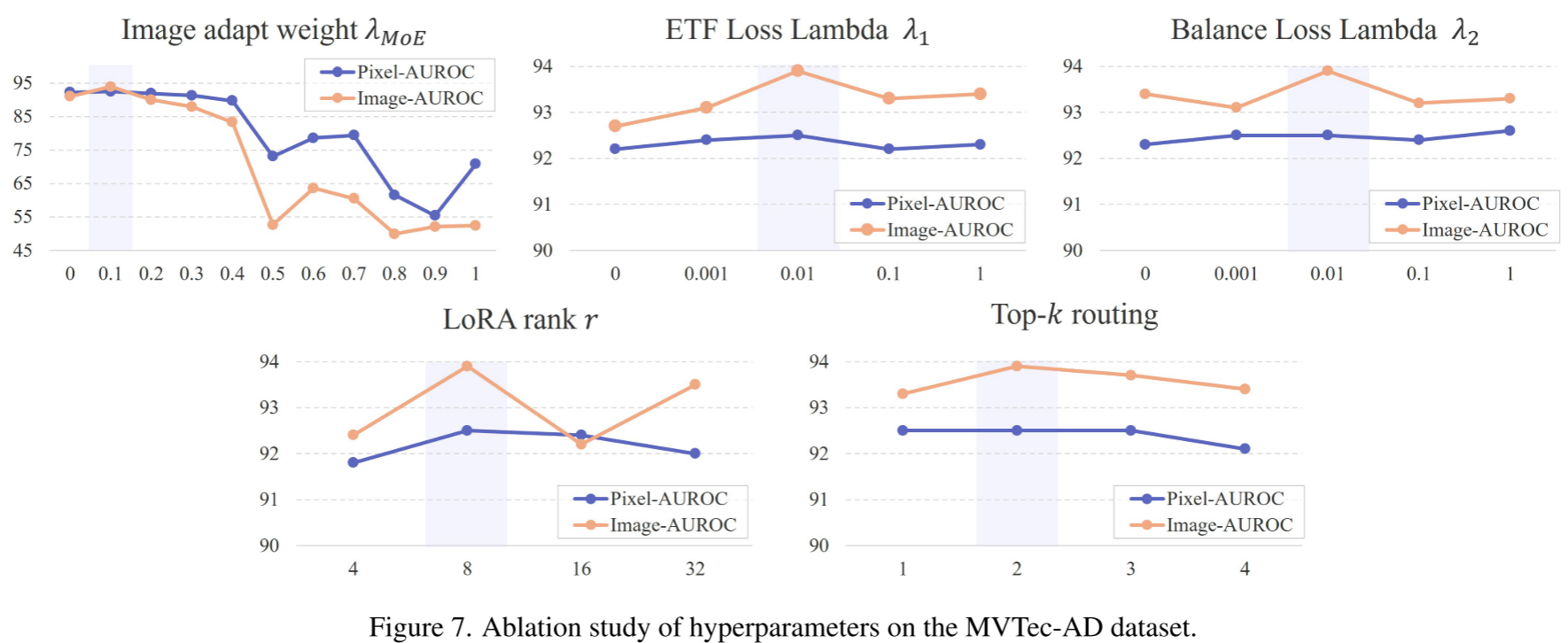
图 7 总结了关键超参数的影响:
- MoE:最优值为 0.1;超过 0.4 后性能急剧下降,验证了保留原始 CLIP 特征的重要性
- ETF/Balance Loss 权重:最优值均为 0.01,过小(无正则化)或过大(过度约束)均损害性能
- LoRA rank r:最优值为 8,更大的 rank 不带来提升反而增加过拟合风险
- Top-k routing:k=2 明显优于 k=1,3,4,是专业化程度与信息整合的最佳折衷
6.5 异常图可视化
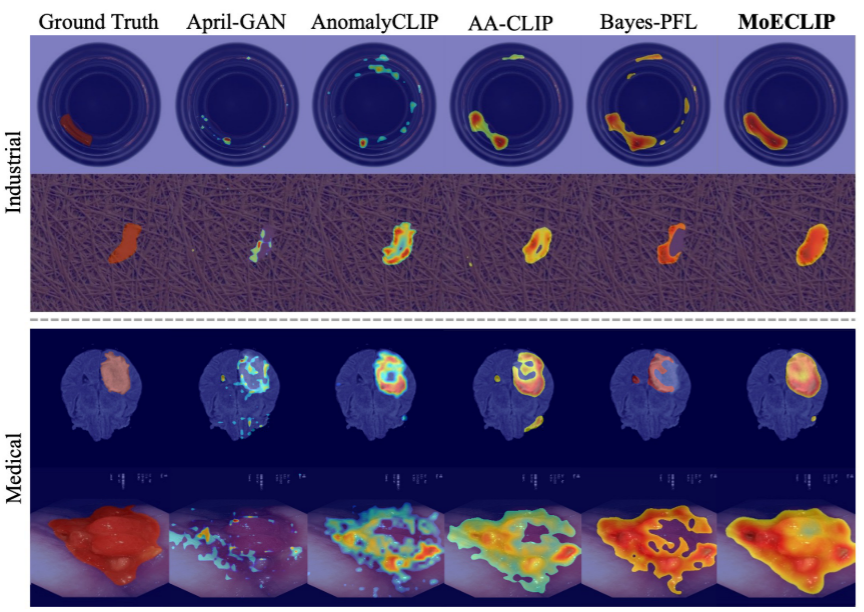
图 4 的可视化对比直观展示了 MoECLIP 的优势:相比其他方法,MoECLIP 产生的异常图在工业和医疗领域都更为精准,异常定位更精细,假阳性更少。
七、计算效率分析
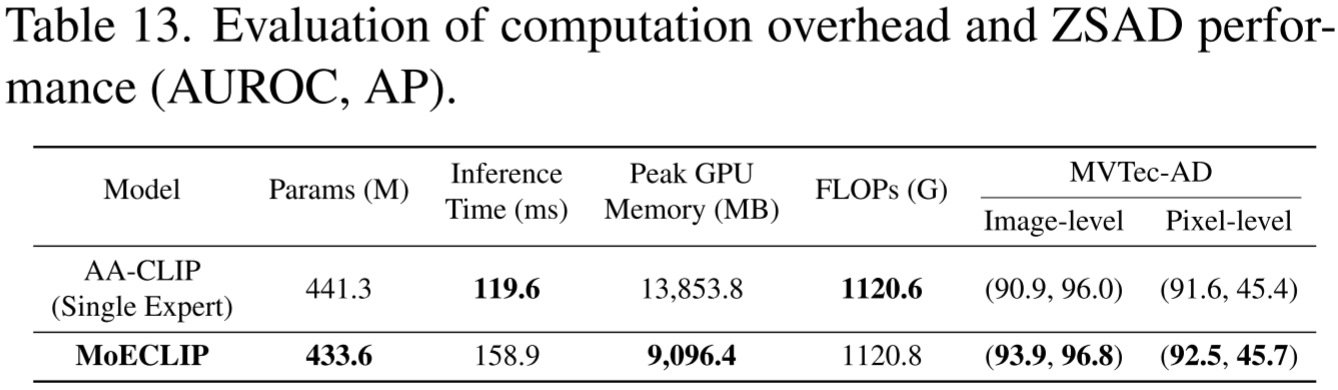
与最接近的竞争对手 AA-CLIP(单专家版本)相比,MoECLIP 展现出极具吸引力的计算特性:
| 指标 | AA-CLIP (Single Expert) | MoECLIP | 变化 |
|---|---|---|---|
| 参数量 | 441.3M | 433.6M | -1.7% |
| 推理时间 | 119.6ms | 158.9ms | +39ms |
| 峰值 GPU 内存 | 13,853.8MB | 9,096.4MB | -34.3% |
| FLOPs | 1120.6G | 1120.8G | ≈持平 |
| 图像级 AUROC | 90.9% | 93.9% | +3.0% |
| 像素级 AUROC | 91.6% | 92.5% | +0.9% |
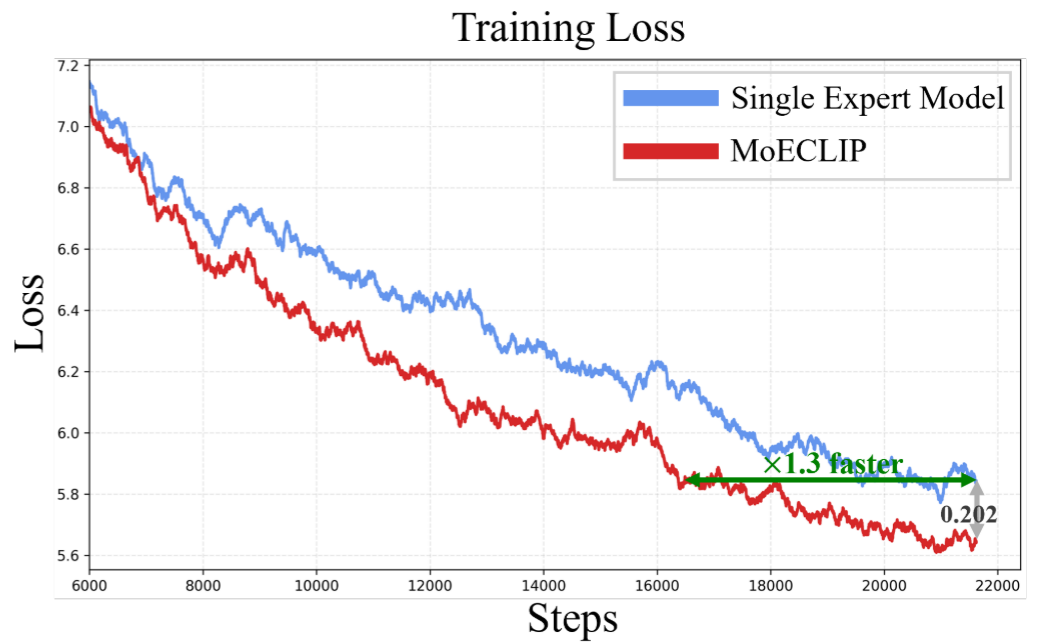
MoECLIP 通过轻量化的 LoRA 专家和稀疏 Top-k 路由,在减少参数量和峰值内存的同时,显著提升了性能,仅以约 39ms 的额外推理时间换取全面的性能提升。此外,MoECLIP 的训练收敛速度比单专家模型快 1.3 倍,这得益于 MoE 架构通过分解参数空间有效缓解了梯度冲突问题。
八、理论视角:MoE 为何适合 ZSAD?
本文在附录中给出了 MoE 适合 ZSAD 任务的理论分析。在单一网络中同时学习多样化的 patch 特征时,不同 patch 的梯度之间可能存在破坏性干扰(余弦相似度 < 0),阻碍模型收敛和泛化。
MoE 通过解耦参数空间,使每个专家的梯度更新仅由路由给它的 patch 决定:
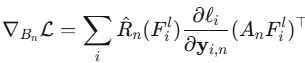
FOFS 进一步确保不同专家的梯度信号来自特征空间的不同维度,从根本上消除了梯度干扰。图 8 的训练损失曲线实验性地验证了这一点:MoECLIP 收敛速度比单专家模型快 1.3 倍。
九、局限性与未来工作
论文坦诚地指出了两个主要局限性:
-
文本特征适配未被充分探索:当前工作主要聚焦于视觉 patch 特征的适配,而如何与 MoECLIP 的图像端 MoE 架构协同设计更高效的文本特征适配策略,仍有探索空间。
-
缺乏异常解释性:MoECLIP 能生成高质量的异常定位图,但无法给出"为什么这个区域是异常的"这样的文字解释------这在医疗诊断等高风险场景中是明显不足。
未来方向:作者计划探索以多模态大语言模型(Multimodal LLM)替换现有 CLIP 骨干,期望构建能够生成文本解释的异常检测模型,并实现更强的语言-视觉协同泛化性能。
十、总结
MoECLIP 是一项围绕"每个 patch 应该被差异化对待"这一直觉出发的优雅工作。它的三个核心贡献相互协同:
- MoE 路由------打破 patch-agnostic 的枷锁,让不同区域的 patch 找到最合适的处理方式
- FOFS + ETF Loss------从输入和输出两端双管齐下,彻底解决 MoE 功能冗余的老大难问题
- PAA 多尺度聚合------在训练阶段就注入多尺度感知,显著提升对医疗图像等多尺度异常场景的适应性
在 14 个跨工业与医疗域的基准数据集上,MoECLIP 全面超越已有 SOTA 方法,图像级 AUROC 提升 3.0%,证明了 patch 级动态路由策略对 ZSAD 任务的根本性价值。更令人印象深刻的是,仅在工业数据上训练的 patch 专业化专家,无需任何领域特定调整,就能在医疗数据集上展现出强大的跨域泛化能力,这充分说明了专家专业化所提取的视觉特征具有跨域通用性。