Transformer 在这一领域中的一个巨大优势,是它具备 few-shot 和 zero-shot 学习能力。图像标注成本很高,而且很多场景里根本拿不到足够多的标签,比如癌症检测就是这样。能够用极少样本依然取得良好效果的图像分类或分割模型,是一个非常大的进步。这使得 Transformer 在"数据稀缺"这一关键难题下显得尤为有价值,而这正是传统基于卷积神经网络(CNN)的模型常常表现乏力的地方。
Transformer 显然已经彻底改变了 NLP。它接下来正在攻占的另一个领域,就是视觉任务。Vision Transformer(ViT)是一个里程碑,它清楚展示了 Transformer 在计算机视觉中的全部潜力。
在接下来的几个部分中,我会向你展示如何将 Transformer 用于图像分类、图像分割、实例分割和全景分割等视觉任务。我会解释你在处理图像时可能遇到的挑战、如何缓解这些问题,以及如何监控模型训练过程。
此外,我还会讨论不同损失函数对结果质量的影响。例如,在医学影像中,复合损失函数通常是最稳健的,因为它们更适合高度类别不平衡的分割任务。对损失函数做这种谨慎选择,能够显著提升模型性能,尤其是在癌症检测这类关键应用中。
不同视觉任务概览
在视觉领域中,有几个重要区分点,有助于理解计算机视觉中的各种应用和技术。本节我会区分最常见的几类任务:分类、图像分割、实例分割和全景分割。在后续章节中,我还会讲到目标检测、姿态估计、图像描述和视觉问答,因为这些内容更适合放到视频与多模态 Transformer 模型的语境下讨论。
分类
分类(classification)是指预测图像中某个物体所属的类别或类。这个任务会根据图像中占主导地位的对象或特征,为整张图像赋予一个标签。例如,在一个动物图像数据集中,分类模型可能会把每张图片归为"猫""狗""鸟"等类别。这里的核心目标,是把对象整体识别出来,而不关心它在图像中的具体位置,也不关心它的各个组成部分。
语义图像分割
语义图像分割(semantic image segmentation)会进一步深入到图像内部,把图像划分成多个不同的分段或区域,每个区域代表一种不同对象。它会对图像中的每一个像素进行分类。例如,在一张街景图中,不同像素可能被分类为"道路""汽车""行人"或"建筑物"。它的主要目标,是在像素层面理解图像,其中每个分割区域都对应一个类别标签。
实例分割
这种方法还会再往下走一层:它不仅把图像划分成多个分段或区域,甚至还会把同一类别的不同对象实例区分开来。也就是说,实例分割(instance segmentation)能够区分同一类别下的不同个体。在同样的街景图中,实例分割不仅会把像素标注成"汽车",还会把每一辆汽车彼此区分开。这让模型能够更细致地理解图像,因为它识别的是对象的独立实例。
全景分割
全景分割(panoptic segmentation)把实例分割和语义图像分割结合起来,从而提供对图像的完整理解。它不仅为图像中的每个像素赋予对象类别标签(例如"汽车""道路""行人"),还会区分这些对象的不同实例。这种方法能够对整个场景进行细粒度分割,同时连贯地表示出对象本身以及它们的独立实例。图 3-1 突出了语义分割、实例分割和全景分割之间的区别。

图 3-1. 左图展示的是语义图像分割,中图展示的是实例分割,右图展示的是全景分割,它明显把前两种分割方式结合成了一个更完整的方案。
现在你已经理解了这些图像任务之间的区别,接下来我们来看看 Transformer 是如何被设计成能够理解和处理图像的。在下一节中,你将学习 embeddings 和 tokenization------也就是让 Transformer 能有效处理各种视觉任务的基础机制------在视觉模型中是如何实现的。
视觉模型中的 Embedding 与 Tokenization
从 2011 年到 2020 年,卷积神经网络(CNN)一直主导着视觉模型的发展。这个阶段始于 GPU 与 CNN 的结合在 2011 到 2012 年间接连赢下多项竞赛。然而,卷积通常是在规则网格上操作的,这使得把 token 或 positional embedding 这类元素自然地集成进网络变得很困难。这个架构限制,随着 2020 年视觉 Transformer 的引入而被打破了。但视觉和语言到底有什么不同?为什么 token 和位置嵌入在视觉里必须采用不同的处理方式?
要回答这个问题,你首先需要理解语言和视觉在信息密度上的巨大差异。语言是人类生成的信号,具有很强的语义性,也有很高的信息密度。要训练一个模型去预测一句话中仅缺失的几个词,模型就必须对语言有相当深入的理解。
而图像则不同。图像是自然信号,具有很强的空间冗余性。图像中某个缺失 patch,往往可以根据周围 patch 进行重建,而不太需要对部件、对象和场景进行高层次理解。
这种差异直接决定了为什么 ViT 要使用 patch 来处理图像:它的目标是捕捉图像的全局上下文,而不是仅依赖局部像素之间的连续性。通过把图像切成 patch,ViT 可以像语言模型处理单词那样,把每个 patch 当作一个 token 来处理。这种方式让模型能够学习图像不同部分之间的关系,本质上相当于"切断"相邻像素之间的天然局部连续性,从而帮助模型从整体上更全面地理解图像。示例 3-1 展示了 ViT 如何把图像切成 patch。
示例 3-1. ViT 中的 Patch Embedding
ini
class PatchEmbedding(nn.Module):
def __init__(self, image_size=28, patch_size=7, channels=1, dim=64):
super().__init__()
assert image_size % patch_size == 0, """The image dimension must
be evenly divisible by the patch size, e.g., image_size=28, patch_size=7."""
num_patches = (image_size // patch_size) ** 2
patch_dim = channels * patch_size ** 2
self.patch_size = patch_size
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.patch_to_embedding = nn.Linear(patch_dim, dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
def forward(self, img):
p = self.patch_size
# Rearrange the image into patches
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)
x = self.patch_to_embedding(x)
# Add classification token and positional embedding
cls_tokens = self.cls_token.expand(img.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding
return x图像通过 einops 库中的 rearrange 函数被切分成多个 patch。
每个 patch 会被展平,并通过一个线性层映射成 patch embedding。
一个可学习的分类 token(cls_token)会被添加到 patch embedding 序列的前面。
位置嵌入会被创建并加到 patch embedding 上,以保留每个 patch 在图像中的位置信息。
我这里使用的是著名的 MNIST 手写数字数据集来演示这一过程。你也可以在本节对应的 notebook 中使用绘图函数自己试一试。你会得到图 3-2 所示的结果。
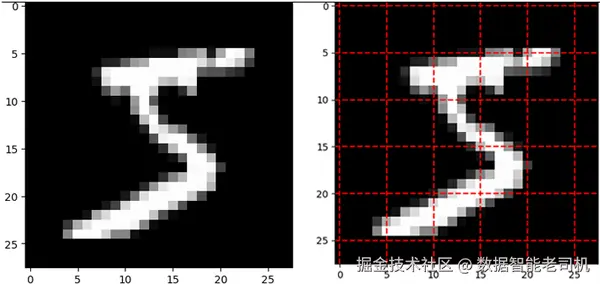
图 3-2. 左边是原始图像;右边带虚线的是切成 patch 之后的图像。
从处理方式上看,ViT 会把二维图像
x∈RH×W×C
重塑为一个由展平二维 patch 构成的序列
xp∈RN×(P2⋅C)
其中, (H,W) 表示原始图像的分辨率, C 表示通道数。Transformer 在所有层中都保持恒定的潜在向量维度 D,因此这些 patch 会先被展平,再通过一个可训练线性投影映射到 D 维空间中:
z0=xclass;xp1E;xp2E;⋯;xpNE+Epos,E∈R(P2⋅C)×D,Epos∈R(N+1)×D
和 BERT 中的 [class] token 类似,一个可学习的 embedding 会被附加到 patch embedding 序列前面也就是 ( z00=xclass),而 Transformer encoder 输出中该位置的状态 zL0会作为图像表示 y,即:
y=LN(zL0)
在预训练和微调阶段,都会有一个分类头挂在 zL0 上。在预训练阶段,这个分类头实现为一个带单隐层的 MLP;而在微调阶段,则是一个单层线性层。为了保留位置信息,模型会把标准的、可学习的一维位置嵌入加到 patch embedding 上。最终得到的 embedding 向量序列,就作为 encoder 的输入。
ViT 为 embedding 和 token 处理方式所引入的方法,至今仍然在视觉 Transformer 中被广泛使用。事实上,到目前为止,还没有广为人知的不采用 ViT 这套基本处理方式的 Transformer 视觉模型。图 3-3 展示了这一架构设置的整体视图。
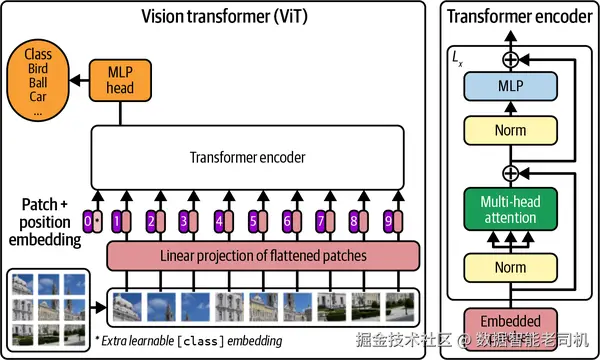
图 3-3. 一张图像会被切成固定大小的 patch,每个 patch 会被线性嵌入,然后再加上位置嵌入,最后把得到的向量序列送入标准 Transformer encoder。对于分类任务,还会额外在序列前加上一个可学习的"classification token"。图片改编自 Alexey Dosovitskiy 等人。
下一节会稍微绕开一下主线,先向你展示如何增强视觉模型的泛化能力,然后再继续深入使用视觉 Transformer。
提升视觉任务鲁棒性与有效性的关键策略
在做视觉任务时,底层数据起着决定性作用。重要的不只是数据的多样性,还有图像质量以及具体任务本身。比如,从卫星图像中分割屋顶,和检测癌症,本质上就是两类完全不同的问题。卫星图像通常覆盖范围大、分辨率变化明显,而且需要处理复杂背景;而医学图像则要求极高精度,通常也是高分辨率,以便捕捉细微细节。根据任务不同,你需要选择合适的损失函数、增强技术和正则化方法,才能取得最佳结果。因此,这一节的目标是给你提供一些思路和资源,帮助你开始做项目,并为你自己的实践提供灵感。为了让差异更清楚,我会用"屋顶分割"和"癌症检测"作为对比示例。
数据增强
标准方法通常会对图像做翻转、旋转、缩放等增强。这些方法能帮助模型更好地泛化,对诸如从卫星图像中分割屋顶这类任务来说,通常已经足够了。
但是到了癌症检测这类任务上,你就需要使用更高级的数据增强技术,比如弹性形变(elastic deformations)、随机裁剪和强度变化(intensity variations)。这些技术通过模拟真实医学图像中的变化形式,来帮助模型提升泛化能力。
正则化技术
常见的正则化技术对像屋顶分割这类任务可能很有效,但未必同样适用于癌症检测。
Dropout 可以防止过拟合,因为它会让模型不能过度依赖任何单一神经元。对于那些数据集规模不算特别大、而过拟合又是常见问题的任务来说,这种方法很有效。
L2 正则化(也叫 weight decay)会对模型权重平方和施加惩罚项。如果模型参数很多,这会特别有帮助,因为它能防止权重变得过大,从而减少过拟合,而这种情况在高分辨率图像分割任务中很常见。
Early stopping 也是一种有效的正则化技术。它的做法是监控模型在验证集上的表现,一旦性能不再提升就停止训练,以此避免过拟合。
损失函数
你应当选择那些更强调空间精度和边界精度的损失函数,比如 IoU loss 或 Dice Loss。它们特别适合处理大尺度、高分辨率图像,在这类图像中,主要挑战通常是如何在复杂背景中精确勾勒出屋顶边界。
不过,医学图像数据集往往高度类别不平衡:例如,癌变区域相对于健康组织来说是非常少见的。在这种情况下,通常会使用 Focal Loss 或 Compound Loss(Dice Loss 与 Cross-Entropy Loss 的组合)来处理不平衡问题,并让模型把学习重点放在那些少数类、困难样本上。
Focal Loss 是专门为稀有类别分类设计的,它在标准交叉熵损失中引入了一个调制项。这个调制项会降低那些已经被正确分类样本的损失权重,从而让模型更关注那些难以分类、容易出错的样本。
Dice Loss 则通过计算 Dice Coefficient 来衡量预测区域与真实区域之间的重叠程度。Dice Coefficient 的范围是 0 到 1,而 Dice Loss 就是 1 减去 Dice Coefficient。它会同时强调前景类和背景类的正确预测,并且由于它直接关注预测区域与真实区域的重叠程度,因此在处理类别不平衡时也很有效。
Dice Focal Loss 会特别强调分割边界,这有助于更精确地勾勒边界,因此在区分健康组织和癌变组织时尤其有帮助。
数据增强库
对于随机裁剪、翻转等数据增强任务,我推荐使用 torchvision.transforms。此外,像 Albumentations 和 Kornia 这样的库,也能高效完成多种增强操作。
正如你已经学到的,损失函数和正则化技术的选择,必须根据任务本身的具体特点和挑战进行定制。图像的性质、数据分布,以及对准确率和精度的具体要求,都会共同决定这些选择。这也说明,每个场景都需要一套针对性的处理策略。
Swin Transformer V2
自从 AlexNet 问世以来,网络架构变得越来越深、越来越大,极大推动了各种视觉任务的发展,并引领了计算机视觉中的深度学习浪潮,其中典型代表包括 VGG 和 ResNet。不过,尽管截至 2025 年写作时,CNN 架构的规模已经被扩展到了大约 10 亿参数,但模型变大并不一定会带来与之成比例的性能提升。
Swin Transformer V2 是一个拥有 30 亿参数的密集视觉模型。它的开发者必须解决若干问题。比如,为了解决大规模视觉模型训练时的不稳定性,他们引入了一种新的归一化配置,叫作 res-post-norm。在这种方法里,每个残差块的输出会在并回主分支之前先做归一化,以防止幅值不断累积;此外,他们还会每隔 6 个 Transformer block 再加入一层 layer normalization,以进一步稳定大模型训练。
为了稳定注意力值,他们使用了 scaled cosine attention,它计算的是像素对 i 和 j 的注意力 logit。你可以把这种方式和原始 self-attention 进行对比:原始 self-attention 中,像素对之间的相似度是通过 query 和 key 向量的点积来计算的。而在大型视觉模型里,尤其是在 res-post-norm 配置下,这往往会导致注意力图被少数几个像素对"支配"。Scaled cosine attention 的公式如下:
Sim(qi,kj)=τcos(qi,kj)+Bij
这里, Bij 是 i 和 j 之间的相对位置偏置, τ 是一个可学习的标量,其值大于 0.01,并且不会在不同 head 和层之间共享。由于余弦函数天然是归一化过的,因此它会带来更稳定的注意力值。
此外,Swin Transformer V2 还使用了一种对数间隔连续位置偏置(log-spaced continuous position bias,Log-CPB),用于处理低分辨率预训练与高分辨率微调之间窗口大小不一致的问题。更具体地说,连续相对位置偏置会在相对坐标上引入一个小型元网络:
B(Δx,Δy)=G(Δx,Δy)
这里, G 是一个小型网络,比如一个带 ReLU 激活的两层 MLP。ReLU 的机制是:当输入为正时,直接输出输入值;否则输出 0。它既能引入非线性,又具有较高计算效率。这个网络会为任意坐标生成偏置值,因此能够无缝迁移到不同窗口大小的微调任务上。为了高效推理,你还可以预先计算并存储这些偏置值。
此外,这个网络还会使用对数间隔坐标,来处理不同窗口尺寸之间所需的外推问题:
Δx^=sign(x)⋅log(1+∣Δx∣)
Δy^=sign(y)⋅log(1+∣Δy∣)
这里, Δx,Δy 是线性尺度坐标,而 Δx^,Δy^ 则是对数间隔坐标。
使用对数间隔坐标,可以显著降低相较于线性间隔坐标的外推比例,从而提升模型在不同窗口分辨率下的表现。这些改进共同增强了模型在不同窗口分辨率间迁移时的可扩展性和有效性,带来了更好的性能与更强的灵活性。图 3-4 展示了该架构。
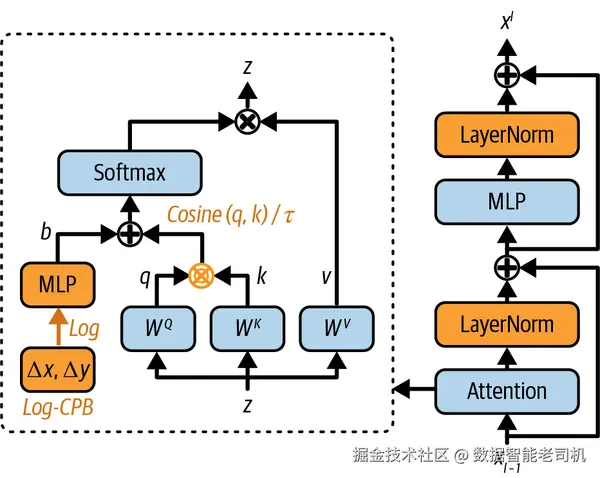
图 3-4. Swin Transformer V2 架构包含多项改进,以更好地扩展模型容量和窗口分辨率:包括 res-post-norm 配置、scaled cosine attention,以及 log-spaced continuous relative position bias。图片改编自 Ze Liu 等人(2022)。
使用 Swin Transformer V2 进行图像分类
现在理论基础已经铺垫完了,是时候看看 Swin Transformer V2 如何真正跑起来了。本节会一步步带你用它来做图像分类项目。我会使用 snacks 数据集,它包含 20 类不同的零食图像。你完全可以把它替换成任意其他图像分类数据集。
为了先了解数据集中有哪些特征,我们可以把标签打印出来:
css
print(dataset["train"].features['label'].names)输出会是:
css
['apple', 'banana', 'cake', 'candy', 'carrot', 'cookie', 'doughnut', 'grape','hot dog', 'ice cream', 'juice', 'muffin', 'orange', 'pineapple', 'popcorn','pretzel', 'salad', 'strawberry', 'waffle', 'watermelon']如果你想展示数据集中的一张图像,可以这样写:
css
dataset['test'][1]['image']它会显示出对应图像。

为了方便解码数据集中的 id 和 label,创建字典会很有用,如示例 3-2 所示。
示例 3-2. 创建 id 与 label 的映射字典
ini
labels = dataset["train"].features["label"].names
num_labels = len(dataset["train"].features["label"].names)
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = i
id2label[i] = label接着,我们来加载 image processor 和模型,如示例 3-3 所示。
示例 3-3. 初始化 processor 和 model
ini
MODEL_PATH = "microsoft/swinv2-tiny-patch4-window8-256"
image_processor = AutoImageProcessor.from_pretrained(MODEL_PATH)
model = AutoModelForImageClassification.from_pretrained(
MODEL_PATH,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes = True,
)在使用数据集训练模型之前,你必须先对数据做预处理,如示例 3-4 所示。
示例 3-4. 自定义图像预处理与数据集变换
python
class ImageProcessor:
def __init__(self, image_processor):
self.normalize = Normalize(mean=image_processor.image_mean,
std=image_processor.image_std)
if "height" in image_processor.size:
self.size =
(image_processor.size["height"],
image_processor.size["width"])
self.crop_size = self.size
self.max_size = None
elif "shortest_edge" in image_processor.size:
self.size = image_processor.size["shortest_edge"]
self.crop_size = (self.size, self.size)
self.max_size = image_processor.size.get("longest_edge")
self.transforms = Compose([
Resize(self.size),
CenterCrop(self.crop_size),
ToTensor(),
self.normalize,
])
def preprocess(self, example_batch):
example_batch["pixel_values"] = [
self.transforms(image.convert("RGB")) for image in example_batch["image"]
]
return example_batch
processor = ImageProcessor(image_processor)
train_ds.set_transform(processor.preprocess)
val_ds.set_transform(processor.preprocess)接下来,你可以定义训练参数,如示例 3-5 所示。
示例 3-5. 定义训练参数
ini
args = TrainingArguments(
f"{model_name}-finetuned-snacks",
remove_unused_columns=False,
evaluation_strategy = "epoch",
save_strategy = "epoch",
learning_rate=5e-5,
per_device_train_batch_size=BATCH_SIZE,
gradient_accumulation_steps=4,
per_device_eval_batch_size=BATCH_SIZE,
num_train_epochs=5,
warmup_ratio=0.2,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
)然后把这些参数传给 Trainer 类开始训练,如示例 3-6 所示。
示例 3-6. 初始化 Trainer 并开始训练
ini
trainer = Trainer(
model,
args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=image_processor,
compute_metrics=compute_metrics,
data_collator=collate_fn,
)
trainer.train()在这种配置下,模型最终达到了 91.41% 的准确率。若要评估结果,你可以这样做,如示例 3-7 所示。
示例 3-7. 评估结果
scss
trainer.evaluate()而在推理阶段,你可以直接使用 Hugging Face 的 pipeline 功能,如示例 3-8 所示。
示例 3-8. 使用 Hugging Face 图像分类 pipeline 做推理
ini
image_processor = AutoImageProcessor.from_pretrained(name)
model = AutoModelForImageClassification.from_pretrained(name)
pipe = pipeline("image-classification", model=model, image_processor=image_processor)
pipe(image)输出会是如下分类结果:
css
[{'label': 'apple', 'score': 0.9996001124382019}, {'label': 'watermelon', 'score': 8.05784366093576e-05}, {'label': 'banana', 'score': 7.75724183768034e-05}, {'label': 'juice', 'score': 5.8855093811871484e-05}, {'label': 'pineapple', 'score': 4.748155697598122e-05}]看起来模型确实正确地把图像中的零食识别成了苹果。
找到合适的标注工具
我自己花过不少时间寻找适合分割任务的标注工具。一个经验法则是,你要先想清楚:你是否需要标注工具能方便地集成进现有工作流,以及它是否提供完善的 Python SDK。除此之外,还要考虑会有多少人参与数据标注,以及你是否打算用这个工具构建反馈闭环------也就是先完成初始标注、再训练模型,然后让标注团队审核模型预测出来的 mask,并基于这些反馈再次训练模型。
对于第一种需求,我建议你看看 Segments.ai 的标注平台。对于后一种带反馈闭环的场景,可以考虑 Label Studio。Label Studio 是开源软件,支持多种安装方式,包括通过 Docker 部署。
现在你已经知道如何把 Transformer 用在图像分类任务上了,接下来我们进入下一节,继续把 Transformer 用到分割任务中。
Segment Anything
你已经知道,图像分割的任务是识别图像中哪些像素属于某个对象,因此它是计算机视觉中的核心任务之一。不过,开发一个高精度分割模型并不容易,因为它通常需要专业技术、AI 训练基础设施,以及大量经过精细标注、且属于特定领域的数据,而这些成本往往非常高。
这正是 Segment Anything Model(SAM)发挥作用的地方------它是一个用于图像分割的基础模型,而且可以像提示语言模型那样对它进行 prompt。这些 prompt 可以是边界框、点、文本,或者基础 mask。模型接着会基于图像和 prompt 输出相应的 mask。除了是一个"可提示的"图像分割模型之外,它在 zero-shot 分割任务上也表现非常出色。
SAM 包含三个组成部分:image encoder、灵活的 prompt encoder 和 mask decoder。它建立在不同的基于 Transformer 的视觉模型之上。例如,它的 image encoder 就受到 MAE(Masked Autoencoders Are Scalable Vision Learners)和做了少量改动的 ViT 的启发。
Prompt encoder 支持两类 prompt:稀疏 prompt(点、框、文本)和稠密 prompt(mask)。点和框会被表示为位置编码与对应 prompt 类型的可学习 embedding 的组合;而自由文本则通过 CLIP 的文本编码器来表示。稠密 prompt,例如 mask,则会通过卷积进行嵌入,并与图像 embedding 逐元素相加融合。
Mask decoder 会把 image embedding、prompt embedding 以及一个 output token 映射成 mask。它借鉴了此前的一些设计,使用的是一个改造过的 Transformer decoder block,后接一个动态 mask prediction head。这个 decoder block 会在 prompt 和 image embedding 之间双向执行 self-attention 与 cross-attention(即 prompt-to-image 和 image-to-prompt),以更新所有 embedding。经过两个 block 后,image embedding 会被上采样,同时 MLP 会把 output token 映射为一个动态线性分类器,用于计算图像每个位置属于前景 mask 的概率。图 3-5 展示了模型架构。
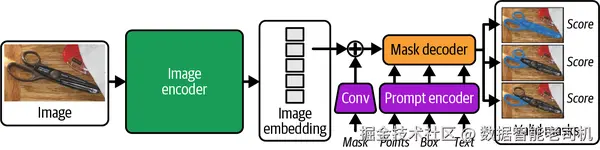
图 3-5. Segment Anything Model 概览。Image encoder 会生成图像 embedding,而这个 embedding 可以通过 prompt encoder 接受各种输入 prompt(mask、点、框、文本)进行查询。Mask decoder 再处理这些 embedding,输出对象 mask 以及对应的置信度分数。图片改编自 Alexander Kirillov 等人(2023)。
示例 3-9 展示了如何向模型输入一组二维点,以预测一个分割 mask。你提供的二维点越多,最终得到的 mask 通常越准确。
示例 3-9. 使用二维点通过 SAM 预测 mask
ini
input_points = [[[300, 250]]]
show_points_on_image(raw_image, input_points[0])
inputs = processor(raw_image, input_points=input_points,
return_tensors="pt").to(device)
inputs.pop("pixel_values", None)
inputs.update({"image_embeddings": image_embeddings})
with torch.no_grad(): outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(),
inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
scores = outputs.iou_scores正如 SAM 概览最后一部分所示,这段代码最终会输出如下分数:
lua
tensor([[[1.0003, 0.9940, 0.6576]]], device='cuda:0')然后,你就可以选取得分最高的结果,作为你分割任务中构建 mask 的基础。下面这段代码展示了如何把 mask 显示在图像上,如示例 3-10 所示。
示例 3-10. 在图像上展示 mask
ini
def show_masks_on_image(raw_image, masks, scores):
if len(masks.shape) == 4:
masks = masks.squeeze()
if scores.ndim > 0 and scores.shape[0] == 1:
scores = scores.squeeze()
image_array = np.array(raw_image)
nb_predictions = scores.shape[0] if scores.ndim > 0 else 1
fig, axes = plt.subplots(1, nb_predictions, figsize=(15, 5 * nb_predictions))
if nb_predictions == 1:
axes = [axes]
for i, mask in enumerate(masks):
mask = mask.cpu().detach().numpy()
contours, _ = cv2.findContours((mask * 255).astype(np.uint8),
cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
epsilon = 0.01 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
cv2.polylines(image_array, [approx], True, (255, 0, 0), 3)
axes[i].imshow(image_array)
if scores.ndim == 0:
score_text = f"{scores.item():.3f}"
elif scores.ndim > 0 and scores.numel() == 1:
score_text = f"{scores.item():.3f}"
elif scores.ndim > 0:
score_val = scores[i].item() if scores[i].numel() == 1 else scores[i]
score_text = f"{score_val:.3f}" if
isinstance(score_val, float) else "Multiple"
axes[i].set_title(f"Mask {i+1}, Score: {score_text}")
axes[i].axis("off")去掉 mask 中多余的维度。
去掉 score 中多余的维度。
把 mask tensor 转成 NumPy 数组。
在 mask 中查找轮廓。
把轮廓画到图像上。
这里我使用的是 OpenCV,这是一个开源计算机视觉库,用于提取 mask 的轮廓并绘制多边形边界。如果你想进一步优化分割结果,我建议你看看 segmentation refinement library。
SAM 的变体
SAM 已经衍生出了多个变体,它们可以帮助你更快地针对特定任务构建模型。其中有一个版本专门针对医学图像,而且代码是完全公开的。除此之外,还有一个 Python 包专门用于利用 SAM 对地理空间数据做分割。Grounding DINO 则致力于通过文本输入实现"检测一切并分割一切"。
HQ-SAM 在保留原始 promptable 设计、效率和 zero-shot 泛化能力的前提下,增强了对任意对象的精细分割能力。另一个变体叫 ClassWise-SAM-Adapter(CWSAM),它把性能很强的 SAM 适配到了卫星图像中的土地覆盖分类任务上。这个模型在灾后卫星图像分析等场景中会非常有用,比如对天气灾害后的受灾区域进行分类。
现在,是时候在下一节里亲自上手试试 SAM 了。
在自定义数据集上微调 SAM
这一节中,你将学习如何在自己的数据集上微调 SAM。我会展示如何创建 study 对象,并通过 Optuna 指定优化方向。此外,你还会把样本图像和 mask 记录到 Weights & Biases 中。这样你就可以在指定间隔下比较 ground truth mask 和模型预测 mask,也能够以另一种方式持续跟踪和改进模型性能。这里我会使用一个医学图像数据集,它的目标是帮助检测乳腺癌。
为 SAM 准备数据
理解如何正确准备数据非常重要。数据集中的每个样本都应该包含以下几个组成部分:
Pixel values
也就是已经格式化好、可以直接输入模型的图像数据。
Prompt
可以是 mask、点、边界框或文本,它们作为模型的输入提示。
Ground truth segmentation mask
用于验证的真实分割 mask。
示例 3-11 展示了一个函数,说明如何基于 ground truth segmentation 自动生成 bounding box prompt。
示例 3-11. 获取 bounding box
ini
def get_bounding_box(mask):
y_coords, x_coords = np.nonzero(mask > 0)
x_start, x_end = np.min(x_coords), np.max(x_coords)
y_start, y_end = np.min(y_coords), np.max(y_coords)
height, width = mask.shape
x_start = max(0, x_start - np.random.randint(0, 20))
x_end = min(width, x_end + np.random.randint(0, 20))
y_start = max(0, y_start - np.random.randint(0, 20))
y_end = min(height, y_end + np.random.randint(0, 20))
bounding_box = [x_start, y_start, x_end, y_end]
return bounding_box先找到 mask 中非零元素的索引。
确定 x 与 y 的最小和最大坐标。
对 bounding box 坐标施加随机扰动。随机扰动会对数据或参数引入小幅、随机的变化,以增强鲁棒性并降低过拟合风险。
生成最终的 bounding box。
接下来,为了真正构建数据集,你可以利用 PyTorch 的 Dataset 类,如示例 3-12 所示。
示例 3-12. 创建数据集
ini
class CustomDataset(Dataset):
def __init__(self, data, transformer):
self.data = data
self.transformer = transformer
def __len__(self):
return len(self.data)
def __getitem__(self, index):
data_item = self.data[index]
img = data_item["image"]
mask = np.array(data_item["label"])
bounding_box = extract_bounding_box(mask)
transformed_inputs = self.transformer(img,
input_boxes=[[bounding_box]], return_tensors="pt")
transformed_inputs = {key: val.squeeze(0) for key, val in
transformed_inputs.items()}
transformed_inputs["ground_truth_mask"] = mask
return transformed_inputs根据 mask 生成 bounding box。
将图像和 bounding box 处理为模型可用的输入。
去掉 transformer 自动添加的 batch 维度。
把 ground truth mask 一并放入返回结果中。
然后,你可以通过 PyTorch 的 DataLoader 类来从数据集中取 batch:
ini
train_dataloader = DataLoader(train_dataset, batch_size=2, shuffle=True)设置模型并接入 Weights & Biases
下一步需要加载 SAM 模型。为了确保梯度只作用于 mask decoder,你要冻结 vision encoder 和 prompt encoder 的参数,如示例 3-13 所示。
示例 3-13. 加载 SAM 并冻结视觉编码器与提示编码器
ini
model = SamModel.from_pretrained("facebook/sam-vit-base")
for param_name, parameter in model.named_parameters():
if param_name.startswith(
"vision_encoder") or param_name.startswith("prompt_encoder"):
parameter.requires_grad = False从 Hugging Face 加载 SAM。
确保只有 mask decoder 会参与梯度计算。
然后初始化一个新的 Weights & Biases 项目,如示例 3-14 所示。
示例 3-14. 初始化 Weights & Biases 项目
ini
wandb.init(project='image segmentation')准备超参数搜索
现在开始设置 Optuna 超参数调优,如示例 3-15 所示。
示例 3-15. 定义 Optuna objective 和训练循环
ini
def objective(trial):
lr = trial.suggest_float("lr", 1e-6, 1e-3, log=True)
weight_decay = trial.suggest_float("weight_decay", 0, 1e-3)
num_epochs = trial.suggest_int("num_epochs", 10, 50)
sigmoid = trial.suggest_categorical("sigmoid", [True, False])
squared_pred = trial.suggest_categorical("squared_pred", [True, False])
model.to(device)
optimizer = Adam(model.mask_decoder.parameters(), lr=lr,
weight_decay=weight_decay)
seg_loss = monai.losses.DiceFocalLoss(sigmoid=sigmoid,
squared_pred=squared_pred, reduction='mean')
model.train()
for epoch in range(num_epochs):
epoch_losses = []
for batch_idx, batch in enumerate(tqdm(train_dataloader)):
# Forward and backward passes
outputs = model(pixel_values=batch["pixel_values"].to(device),
input_boxes=batch["input_boxes"].to(device),
multimask_output=False)
predicted_masks = outputs.pred_masks.squeeze(1)
ground_truth_masks = batch["ground_truth_mask"].float().to(device)
loss = seg_loss(predicted_masks, ground_truth_masks.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_losses.append(loss.item())
trial.report(np.mean(epoch_losses), epoch)
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return np.mean(epoch_losses)为各个超参数建议候选值。
设置模型、优化器和损失函数。
根据中间结果进行 pruning。
定义好包含超参数空间的函数之后,就可以创建一个新的 study 来运行多个 trial,如示例 3-16 所示。
示例 3-16. 创建并运行 Optuna study
python
study = optuna.create_study(direction="minimize")
study.optimize(objective, n_trials=5)
print("Best trial:")
trial = study.best_trial
print(f" Value: {trial.value}")
print(" Params: ")
for key, value in trial.params.items():
print(f" {key}: {value}")创建 study 对象,并指定优化方向。
使用最佳超参数对 SAM 做微调
等超参数调优完成之后(通常需要大约 4 到 5 小时),你就可以直接使用最优参数来微调模型,如示例 3-17 所示。
示例 3-17. 使用最佳 trial 参数配置优化器和损失函数
ini
optimizer = Adam(model.mask_decoder.parameters(),
lr=trial.params.get("lr"),
weight_decay=trial.params.get("weight_decay"))
seg_loss = monai.losses.DiceFocalLoss(sigmoid=trial.params.get("sigmoid"),
squared_pred=trial.params.get("squared_pred"),
reduction='mean') 使用 trial.params.get("hyperparameter_name") 直接获取所需超参数。
使用 Dice Focal Loss,确保模型对分割边界给予更高关注,从而实现更准确的边界刻画。
有了优化器和损失函数之后,就可以开始真正微调模型了,如示例 3-18 所示。
示例 3-18. 使用筛选出的超参数微调 SAM 并记录结果
scss
num_epochs = trial.params.get("num_epochs")
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
model.train()
for epoch in range(num_epochs):
epoch_losses = []
for batch_idx, batch in enumerate(tqdm(train_dataloader)):
outputs = model(pixel_values=batch["pixel_values"].to(device),
input_boxes=batch["input_boxes"].to(device),
multimask_output=False)
predicted_masks = outputs.pred_masks.squeeze(1)
ground_truth_masks = batch["ground_truth_mask"].float().to(device)
loss = seg_loss(predicted_masks, ground_truth_masks.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_losses.append(loss.item())
if batch_idx % 5 == 0:
image_to_log = batch["pixel_values"][0].permute(1, 2, 0).cpu().numpy()
predicted_mask_to_log = predicted_masks[0].cpu().detach().numpy()
ground_truth_mask_to_log = ground_truth_masks[0].cpu().detach().numpy()
wandb.log({
"Input Image": wandb.Image(image_to_log, caption="Input Image"),
"Predicted Mask": wandb.Image(predicted_mask_to_log,
caption="Predicted Mask"),
"Ground Truth Mask": wandb.Image(ground_truth_mask_to_log,
caption="Ground Truth Mask")
}, commit=False)
wandb.log({'epoch': epoch, 'mean_loss': mean(epoch_losses)})
print(f'EPOCH: {epoch}')
print(f'Mean loss: {mean(epoch_losses)}')执行 forward pass。
计算 loss。
执行 backward pass(即根据 loss 计算梯度)。
执行优化步骤。
按照设定间隔,把样本图像和 mask 记录到 Weights & Biases 中。
从 batch 中选择第一个样本用于记录。
转换为 HWC(Height, Width, Channels)格式,方便 wandb 展示。
使用 wandb.log 记录,并通过 commit=False 实现累积记录。
在内层循环之外记录当前 epoch 的 mean loss。
记录到 Weights & Biases 后,你会得到两类图表:一类展示 mean loss,一类展示 epoch,如图 3-6 所示。
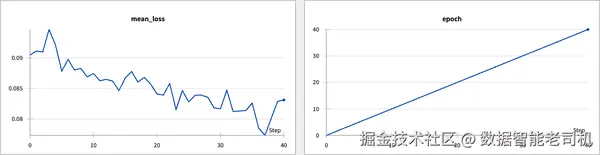
图 3-6. 训练过程中的平均损失与 epoch。
记录这些指标有很多好处。首先,跟踪 mean loss 和 epoch 可以帮助你监控训练进度,并及时发现潜在问题,比如过拟合或欠拟合。通过可视化这些指标,你就能更有根据地决定是否需要调整超参数或训练时长。
除了图表之外,你还可以把训练日志中的原图、预测 mask 和 ground truth mask 组合成一个面板,如图 3-7 所示。
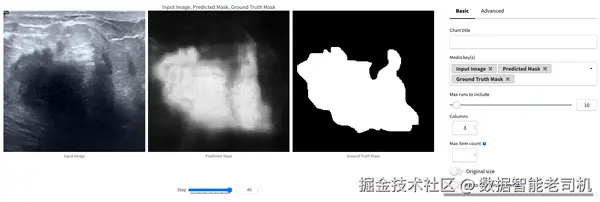
图 3-7. 这个面板可以让你直接逐个查看模型的预测结果。
这个组合面板让你能够从定性角度评估模型表现。通过直接比较预测结果和 ground truth,你可以更清楚地看到模型在哪些地方做得好,哪些地方还存在问题。这往往能为数据预处理、增强策略或损失函数设计带来新的改进思路。此外,逐条浏览不同样本的预测结果,也有助于验证模型在数据集不同样本上的表现是否稳定一致。
同时,你还可以很方便地基于这些日志数据生成报告,并分享给团队成员或其他相关方。
用 Segment Anything 处理图像与视频
尽管这一章主要关注的是图像任务,但我们也可以把视频看作图像序列。从这个角度看,那些能够同时泛化到图像和视频两种模态的模型,其实就是图像架构的自然延伸。Segment Anything Model 2(SAM 2)正是这样一个例子:它建立在我前一节介绍过的原始 SAM 架构之上,并把模型扩展到了时间维度,使它不仅能在图像上做 promptable segmentation,也能在视频帧之间执行分割。图 3-8 展示了 SAM 2 的架构。
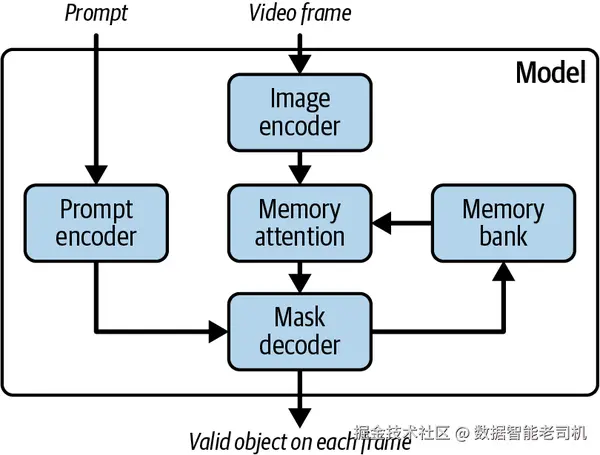
图 3-8. Segment Anything Model 2 架构。
SAM 2 的核心创新,是引入了一个叫 Promptable Visual Segmentation(PVS)的任务,它把图像和视频两种模态下的分割过程统一起来。在这个任务中,你可以在视频的任意一帧上给出一个 prompt,比如点击、边界框或 mask。模型会先为当前帧生成对应的分割 mask,然后再把这一信息沿时间维度传播,生成贯穿整段视频的一致分割结果。为了实现这一点,SAM 2 使用了一个带 memory 的 streaming transformer 架构。模型会一帧一帧地处理视频。对于每一帧,它会通过 memory attention 机制回看先前的预测结果和 prompt,从而维持时间一致性。这个 memory 系统由来自历史帧的空间记忆、包含纠错信息的 prompted frame memories,以及概括对象身份的 object pointers 构成。这些信息会被存储在固定大小的 memory queue 中,使模型即便在长视频序列上也能高效运行。
SAM 2 的核心组件与原始 SAM 很相似。它的 image encoder 基于一个分层 Transformer,并通过 masked autoencoding 目标进行训练。它会处理每一帧视频,并生成多尺度特征 embedding。Prompt encoder 则把用户输入转换为 embedding:稀疏 prompt 使用位置编码,稠密 prompt(例如 mask)使用卷积层。Mask decoder 接收图像特征、prompt embedding 以及 memory context,输出当前帧的分割 mask。这个 decoder 使用了与 SAM 中类似的 two-way attention block,同时细化 prompt 特征和图像特征。当对象存在歧义,或者只局部可见时,模型会预测多个候选 mask,并根据预测的 IoU 分数对它们进行排序。
SAM 2 还加入了一个 memory encoder,它会把预测结果和图像特征转换成适合存储的表示。这些 memory 条目之后会被 memory attention 模块调用,为后续帧提供上下文信息。当模型遇到由于遮挡或运动而看不到目标对象的帧时,它还能显式预测"对象不存在",从而避免生成错误的伪 mask。
不过理论讲得差不多了,下面我来展示你如何真正用 SAM 2 做视频分割。你可以在本书代码仓库中找到一个名为 segment_videos_with_sam2.ipynb 的 Jupyter notebook,其中包含完整代码。这里我只讲最关键的部分。
SAM 2 提供了四种模型规模,从轻量级的 sam2_hiera_tiny(3890 万参数)到更强大的 sam2_hiera_large(2.244 亿参数)不等。在下面的代码示例中,我会使用 sam2.1_hiera_large.pt,也就是大模型对应的 checkpoint。正确加载模型的方法如示例 3-19 所示。
示例 3-19. 加载 SAM 2
ini
sam2_checkpoint = "../checkpoints/sam2.1_hiera_large.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
sam2_model = build_sam2_video_predictor(model_cfg, sam2_checkpoint, device=device)我已经准备好了一段视频供你测试模型。你需要知道的一点是:在使用 SAM 2 之前,必须先把视频拆成一张张单独的图像。图 3-9 展示了这段视频的第一帧。

图 3-9. 视频的第一帧。
如果你想把视频拆成图像帧,可以使用 FFmpeg。FFmpeg 是一个多媒体框架,几乎可以处理任何视频格式,支持解码、编码、流处理和滤镜操作,并且可以运行在 Linux、macOS 和 Windows 上。这里我们会在 Google Colab 中运行它,也就是在 Linux 环境下使用,如示例 3-20 所示。
示例 3-20. 在 Linux 环境中运行
diff
!apt-get update
!apt-get install ffmpeg
!mkdir -p frames
!ffmpeg -i movie_players.mp4 -q:v 2 -start_number 0 frames/%05d.jpg这段代码会先安装 FFmpeg,然后创建一个新目录,并把视频转成 jpg 文件。
为了用 SAM 2 做分割,我们需要为视频初始化一个 inference state,用于交互式视频分割中的有状态推理。在初始化过程中,frames_path 目录下的所有 jpg 帧都会被加载,其像素数据会被保存在 inference_state = sam2_model.init_state(video_path=video_dir) 中。
为了让你在 Jupyter notebook 中更方便地从图像帧里选取对象,可以使用 Jupyter BBox Widget。要使用这个库,你需要先定义一个 object class,然后就可以方便地在图像帧上画边界框,并把它们转成 SAM 2 需要的点输入。示例 3-21 展示了这一过程。
示例 3-21. 使用 BBox Widget 方便地创建点
ini
OBJECT = ['ball']
widget = BBoxWidget(classes=OBJECT)
widget.image = encode_image("/content/frames/00000.jpg")
box = widget.bboxes[0] if widget.bboxes else default_box[0]
points = np.array([[box['x'], box['y']]], dtype=np.float32)
points把 box 转换成模型期望的 point 格式。
如果要把 point prompt 应用到所有视频帧上,你需要使用 propagate_in_video 生成器。它的每一次迭代都会返回 frame_idx(当前帧索引)、object_ids(检测到的对象 id)和 mask_logits。随后,这些 logit 值就可以通过 thresholding 转换成 mask。示例 3-22 展示了这一步的起始过程。
示例 3-22. 向 predictor 添加点
ini
ann_frame_idx = 0
ann_obj_id = 1
labels = np.array([1], np.int32)
_, out_obj_ids, out_mask_logits = sam2_model.add_new_points_or_box(
inference_state=inference_state,
frame_idx=ann_frame_idx,
obj_id=ann_obj_id,
points=points,
labels=labels,
)这里表示要交互的帧索引。
每个对象的唯一 id。
接下来,你就可以在各帧之间传播分割结果了,如示例 3-23 所示。
示例 3-23. 在视频中传播分割结果
css
video_segments = {}
for out_frame_idx, out_obj_ids,
out_mask_logits in sam2_model.propagate_in_video(inference_state):
video_segments[out_frame_idx] = {
out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
for i, out_obj_id in enumerate(out_obj_ids)
}它会保存每一帧对应的分割结果。
之后,你就可以从这些图像帧中选择若干帧进行可视化。视频中篮球在第 0 帧和第 120 帧的分割结果,分别展示在图 3-10 和图 3-11 中。

图 3-10. 带有已分割篮球的视频第 0 帧。

图 3-11. 带有已分割篮球的视频第 120 帧。
结果非常不错。即使篮球出现在其中一位球员身前,SAM 2 依然成功把它分割了出来。
不过,SAM 2 相比 SAM 的提升并不只是增加了视频分割功能而已。它在图像分割上的速度比 SAM 快 6 倍,并且要达到相同分割质量,只需要 1/3 的交互次数。为了达到这样的表现,模型在一个叫 SA-V 的大规模数据集上进行了训练。这个数据集包含来自超过 5 万个视频的 3500 多万个 mask。它是通过一种 model-in-the-loop 标注引擎构建出来的,该引擎结合了人工反馈与迭代式 prompting 来持续修正标注结果。
SAM 2 的集成生态
为了获得更顺滑的使用体验,你可以试试 SAM2 Studio。这是 Hugging Face 开发的一款原生 macOS 应用,能让图像分割过程变得又快又直观。像 Label Studio 这样的主流标注平台,也都已经内置支持 SAM 2。Label Studio 同时提供开源版和企业版。
凭借这种通用的视觉分割系统,SAM 2 非常适合增强现实(AR)、机器人、自主导航和视频编辑等真实世界应用。它既可以直接作为即插即用的分割方案,也可以针对特定领域任务进一步微调。
用概念提示分割视频和图像
SAM 3 引入了一种新的图像和视频分割方式:concept prompting。Segment Anything 系列模型已经经历了三代演进,每一代都建立在上一代的能力之上。由于这些能力是叠加而不是替换关系,这一章会把三代模型都讲到,帮助你看清它们如何衔接、彼此差异在哪里,以及在实际媒体工作流中应该如何使用。表 3-1 展示了这种演进关系。
表 3-1. SAM 模型的演化
| 能力/特性 | SAM 1 | SAM 2 | SAM 3 |
|---|---|---|---|
| 核心目的 | 通过单次点击分割任意对象 | 在图像/视频中分割并跟踪任意对象 | 借助文本或示例图像,检测、分割并跟踪任意类别实例 |
| 输入模态 | 点击 | 点击、框、mask prompt | 文本 prompt、示例图像、点击和后续引导 |
| 通过点击分割一个对象 | ✔ | ✔ | ✔ |
| 在视频中跟踪已分割对象 | ✘ | ✔ | ✔ |
| 通过后续点击细化预测 | ✔ | ✔ | ✔ |
| 通过文本检测并分割匹配实例 | ✘ | ✘ | ✔ |
| 通过视觉示例细化检测(prompt by example) | ✘ | ✘ | ✔ |
| 基于示例的概念匹配 | ✘ | ✘ | ✔ |
| 类别无关分割 | ✔ | ✔ | ✔(并且支持文本驱动、实例级检测) |
SAM 3 通过同时支持传统的 Promptable Visual Segmentation(PVS)任务,以及一种新的 Promptable Concept Segmentation(PCS)任务,对 SAM 2 做了泛化扩展。它可以接收名词短语、示例图像等 concept prompt,也可以接收点、框、mask 等 visual prompt,用来定义要在空间与时间上持续分割的对象。用户可以迭代式地添加 prompt,以细化目标、去掉误检,或者恢复漏检对象。
它的架构建立在 SAM 和 (M)DETR 之上,把一个 dual encoder-decoder detector 与 tracker 和 memory module 结合起来,用于视频处理。这些组件都运行在一个共享的 perception encoder(PE)骨干之上,该骨干负责对齐视觉与语言输入。图 3-12 展示了整体架构,以及 SAM 3 中新增的组件。
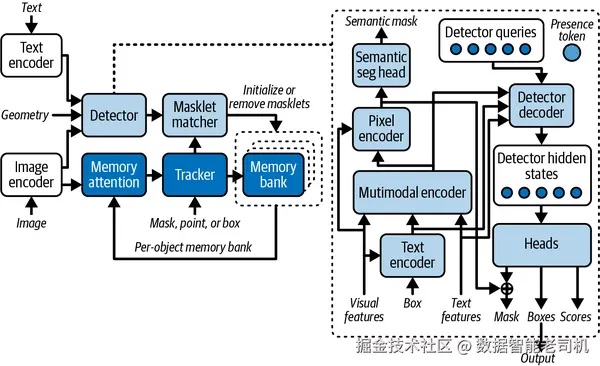
图 3-12. SAM 3 架构。浅灰色部分是新增组件,深灰色部分是 SAM 2 继承下来的组件,白色部分是 perception encoder 的组件。图片改编自 Nicolas Carion 等人(2025)。
下面这一节会更详细地解释各个组件,说明它们在整体系统中分别起什么作用,以及 SAM 3 是如何在 SAM 2 的基础上扩展出 PCS 能力的。
Detector 架构
这个 detector 采用了 DETR 风格的设计,会把图像特征和 prompt token 融合在一起,从而让目标检测能够被文本或示例输入所条件化。可学习 query 会对这些经过条件化处理的特征执行注意力,以完成对象分类和定位,同时预测对象是否存在以及边界框修正量。Mask head 和 semantic segmentation head 则会生成与 prompt 对齐的对象 mask 和像素级标签。
Presence token
Presence token 的作用,是把"识别对象是否存在"和"定位对象在哪里"这两件事分离开。它会先预测目标概念是否存在于图像中,再进入后续定位过程。这样做可以避免 detection query 同时承担全局理解和局部定位这两种负担,从而在概念模糊、稀疏出现时提升可靠性。
图像示例与交互性
Image exemplar 会提供一个 bounding box,以及正样本或负样本标签,用来引导检测;它既可以单独使用,也可以与文本 prompt 结合使用。它使模型能够检测所有匹配实例,而不仅仅是一个实例;同时,它还可以在交互式 refinement 阶段被动态加入,以修正 false positive 或 false negative。
Tracker 与视频架构
在视频场景下,SAM 3 会把 detector 与 tracker、memory module 结合起来,用于在不同帧之间维持一致的对象身份。模型会持续引入新检测结果,同时把已经跟踪的对象以前向传播的 masklet 形式延续下去,从而形成在时空上持续存在的 mask。
使用类似 SAM 2 的传播机制进行跟踪
传播模块会预测被跟踪对象的更新后 masklet 位置,其机制与 SAM 2 类似:它共享同一个 image encoder,并从 memory bank 中提取外观线索。Tracker 会基于历史上下文、用户 prompt 和 conditioning frame,逐帧更新 mask,而不需要每一帧都重新完整执行一次检测。
基于检测结果进行匹配与更新
模型会用基于 IoU 的匹配函数,把传播得到的 masklet 与当前检测结果对齐,从而维持对象身份一致。IoU 通过计算预测框与真实框的重叠程度来衡量目标检测效果。那些持续无法成功匹配的 masklet 会被抑制,而新的检测结果则会生成新的 masklet。为了纠正由遮挡或干扰物造成的漂移,高置信度检测结果还会周期性地重置 tracker。
使用视觉 prompt 进行实例细化
在初始分割完成后,用户可以继续通过正点击或负点击来细化 mask。这些 prompt 会引导 mask decoder 调整对象边界;在视频场景中,这种 refinement 还会沿时间轴传播,从而更新整个序列中对应的 masklet。
使用 SAM 3 非常直接。需要说明的是,这里我会省略一部分代码,但你可以在本书仓库对应 notebook 中找到完整实现。示例 3-24 演示了如何加载模型和 processor,并通过文本 prompt 分割对象。这里我让模型去选择图像中的猫。
示例 3-24. 使用 SAM 3 做图像分割
ini
model = Sam3Model.from_pretrained("facebook/sam3").to(device)
processor = Sam3Processor.from_pretrained("facebook/sam3")
image_path = "/content/cats_dog.jpeg"
image = Image.open(image_path).convert("RGB")
inputs = processor(images=image, text="cats",
return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_instance_segmentation(
outputs,
threshold=0.5,
mask_threshold=0.5,
target_sizes=inputs.get("original_sizes").tolist()
)[0]加载本地图像。
使用文本 prompt 做分割。
图 3-13 展示了图像以及 SAM 3 选出的 mask。

图 3-13. 叠加了 mask 的图像。
前面在讲 SAM 2 时,我给你展示了如何在视频中选取一个对象并把分割结果传播到整段视频。使用 SAM 3,你也可以做同样的事,只不过现在可以直接用 concept prompt,比如"ball"。为了演示 SAM 3 的使用方法,我们继续沿用前面那段篮球视频。示例 3-25 带你走过最重要的几个步骤。
示例 3-25. 使用 SAM 3 做视频分割
ini
model = Sam3VideoModel.from_pretrained(
"facebook/sam3").to(device, dtype=torch.bfloat16)
processor = Sam3VideoProcessor.from_pretrained("facebook/sam3")
video_url = "/content/movie_players.mp4"
video_frames, _ = load_video(video_url)
inference_session = processor.init_video_session(
video=video_frames,
inference_device=device,
processing_device="cpu",
video_storage_device="cpu",
dtype=torch.bfloat16,
)
text = "active ball"
inference_session = processor.add_text_prompt(
inference_session=inference_session,
text=text,
)
outputs_per_frame = {}
for model_outputs in model.propagate_in_video_iterator(
inference_session=inference_session, max_frame_num_to_track=50
):
processed_outputs = processor.postprocess_outputs(
inference_session, model_outputs)
outputs_per_frame[model_outputs.frame_idx] = processed_outputs
print(f"Processed {len(outputs_per_frame)} frames")
frame_idx = 0
frame_outputs = outputs_per_frame[frame_idx]
masks = frame_outputs["masks"]
frame = video_frames[frame_idx]
overlay = overlay_masks_on_frame(frame, masks, alpha=0.5)video_frames 是帧列表。
这里展示的是某一帧(例如第 0 帧)的可视化结果。
masks 的形状是 (num_objects, H, W)。
frame 可以是 PIL 图像,也可以是 NumPy 数组。
图 3-14 展示了其中一帧视频的分割结果。

图 3-14. 已分割的视频帧。
如果你更仔细地看这一帧,就会发现一个潜在问题:当你使用像 "ball" 这样过于简单的 prompt 时,模型会把它识别出的所有球都分割出来,包括背景中静静放着的那个球。如果你的真正目标只是两位球员正在使用的那个"活动中的球",模型是无法从这样一个极简 prompt 中自动推断出这种细微语义差别的。
不过,这个问题是可以处理的。只要不再停留在最基础的 prompt 层面,而是给模型更具体的指令,你就能更精细地引导模型完成分割。如果你想看更深入的做法,"Combining Capabilities: SAM 3 Agent" 那一节会进一步展示如何使用更丰富的 prompt,比如 "leftmost orange yarn ball" 这样的提示。
总结
在这一章中,你学习了视觉 Transformer 所带来的颠覆性影响,包括 Swin Transformer V2、Segment Anything Model,以及最新用于视频分割的 SAM 2。
你了解了 Swin Transformer V2 为了提升可扩展性和性能而做出的关键改动,包括引入 res-post-norm 配置、scaled cosine attention 和 log-spaced continuous position bias。这些创新分别解决了训练不稳定、注意力计算效率以及不同窗口大小适配等问题,从而带来了更好的模型表现。
接着,你看到了 SAM 如何通过 prompt 实现具备 zero-shot 能力的分割,以及 SAM 2 又是如何在此基础上把分割任务扩展到视频领域。借助带 memory 的 Transformer 架构和统一的 PVS 任务,SAM 2 能在帧间维持时间一致性,并支持实时处理。它显著提升了效率,既减少了交互次数,又加快了预测速度,因此非常适合 AR、机器人和视频编辑等任务。
SAM 3 则在这条演进路径上又向前迈出了一步,加入了 concept prompting。模型不再只能响应点击或边界框这类视觉提示,而是可以理解文本指令、示例图像以及复合 prompt,用来分割特定实例、类别,或者更抽象的语义概念。这使得 promptable visual segmentation 进一步扩展成了 promptable concept segmentation:由用户定义"要找什么",而模型则对齐语言、示例和视觉特征去完成执行。SAM 3 建立在 SAM 2 之上,但它不再只是简单交互式循环,而是引入了一个融合 prompt 与图像特征的 detector、一个将"存在判断"和"定位"分开的 presence token,以及一个用于在时间上维持对象身份的 tracker。
在整个章节中,你还使用了 Optuna 来做超参数调优,使用 Weights & Biases 来跟踪和可视化实验。这些工具能够显著简化你的开发流程,并为更高效的模型开发与评估提供支持。
在第 4 章中,我们依然会停留在图像领域,不过这次我们不再对图像进行分割或分类,而是根据 prompt 生成全新的图像。