第8讲 为什么一个神经元不够?
一个神经元已经能够接收输入、完成加权计算,并给出一个分类判断。看起来,它已经具备了最基础的"分类能力"。但只要问题稍微复杂一点,这种结构就会很快碰到明显的能力边界。
问题并不在于神经元太少,而在于:单个神经元本质上只能学出一条线性的分类边界。
如果任务本身足够简单,一条线就能把不同类别分开,那么一个神经元已经足够有效;但只要数据中的规律不再是线性的,单个神经元就会很快失去表达能力。
1. 一个神经元本质上能做什么?
把一个神经元写成最简单的形式,它做的事情其实非常直接:
z = w_1x_1 + w_2x_2 + b
然后再配合一个阈值或激活方式,把结果变成输出。
如果只从几何角度去理解,这意味着:
一个神经元本质上是在输入空间里学习一条线性边界。
- 在二维平面里,它对应一条直线
- 在三维空间里,它对应一个平面
- 在更高维空间里,它对应一个超平面
因此,单个神经元擅长处理的问题通常具有共同特点:
- 类别边界比较规整
- 规律比较简单
- 可以用一条线性边界描述
只要问题本身满足这些条件,一个神经元已经足够完成分类。
2. 线性可分时,一个神经元已经足够
先看一个最简单的情形:两类样本可以被一条直线清楚地分开。
python
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
font_path = "..\..\\00-基础环境\simfang.ttf" # 请确认该路径下有 simfang.ttf 文件
font_prop = font_manager.FontProperties(fname=font_path)
plt.rcParams["font.family"] = font_prop.get_name()
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
class_0 = np.array([
[0, 0],
[1, 0],
[0, 1],
[1, 1]
])
class_1 = np.array([
[3, 3],
[4, 3],
[3, 4],
[4, 4]
])
plt.figure(figsize=(6, 6))
plt.scatter(class_0[:, 0], class_0[:, 1], color='tomato', s=100, label='Class 0')
plt.scatter(class_1[:, 0], class_1[:, 1], color='royalblue', s=100, label='Class 1')
# x_vals = np.linspace(-1, 5, 100)
# y_vals = x_vals
# plt.plot(x_vals, y_vals, 'k--', label='Linear Boundary')
plt.xlim(-1, 5)
plt.ylim(-1, 5)
plt.xlabel("x1")
plt.ylabel("x2")
plt.title("线性可分:一个神经元已经足够")
plt.legend()
plt.grid(alpha=0.3)
plt.show()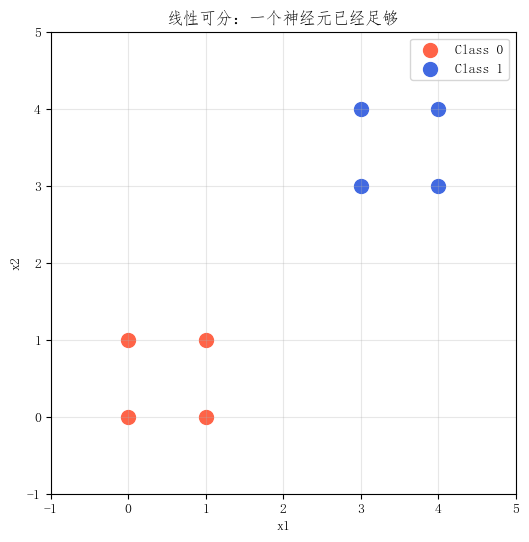
这个例子说明,一个神经元不是"能力太弱",而是在它适用的问题范围内,本来就已经足够有效。
真正的困难出现在:类别边界不再是一条直线的时候。
3. 圆形内外分类:为什么单个神经元难以处理这类问题?
为了把问题说得更直观,这里直接看一个非常具体的分类任务:
- 圆内部的点是一类
- 圆外部的点是另一类
这个规则并不复杂。因为只要看一个点离圆心的距离,就大致知道它属于哪一类:
- 距离小,属于圆内
- 距离大,属于圆外
从人的直觉看,这个问题并不难。
但这个例子恰好非常适合说明单个神经元的局限,因为它真正需要的边界不是直线,而是一条曲线。
先把这组数据画出来。
python
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
n_samples = 600
X = np.random.uniform(-2, 2, (n_samples, 2))
r = np.sqrt(X[:, 0] ** 2 + X[:, 1] ** 2)
y = (r > 1.0).astype(np.int64) # 圆外为1,圆内为0
plt.figure(figsize=(6, 6))
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='tomato', s=20, label='Inner Circle (Class 0)')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='royalblue', s=20, label='Outer Ring (Class 1)')
plt.title("圆形内外分类:原始数据分布")
plt.xlabel("x1")
plt.ylabel("x2")
plt.legend()
plt.axis("equal")
plt.grid(alpha=0.3)
plt.show()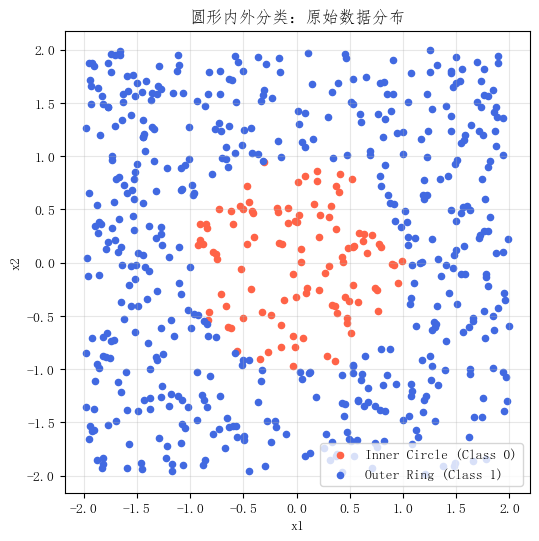
从图上看,这个任务本身非常直观:
- 中间的一团是一类
- 外面的一圈是另一类
这也恰好把问题暴露得非常清楚:
如果模型只能画一条直线,那么无论怎么画,都不可能把"中间的一团"和"外面的一圈"完整分开。
更本质的限制在于:
单个神经元不是不会训练,而是它只能表示线性边界。
4. 单层线性模型在这个问题上的局限
为了把这个结论说得更明确,可以先用一个最简单的线性模型试试这个任务。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_circles
# 生成环形数据(必须有!)
X, y = make_circles(n_samples=200, noise=0.05, factor=0.4, random_state=42)
# 训练线性模型
linear_model = LogisticRegression()
linear_model.fit(X, y)
# 构造网格,用于画决策边界
xx, yy = np.meshgrid(np.linspace(-2.5, 2.5, 300),
np.linspace(-2.5, 2.5, 300))
grid = np.c_[xx.ravel(), yy.ravel()]
probs = linear_model.predict_proba(grid)[:, 1].reshape(xx.shape)
plt.figure(figsize=(7, 6))
plt.contourf(xx, yy, probs, levels=50, cmap="coolwarm", alpha=0.6)
# ✅ 这里修复了语法错误!
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='tomato', s=50, label='Inner Circle (Class 0)')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='royalblue', s=50, label='Outer Ring (Class 1)')
plt.contour(xx, yy, probs, levels=[0.5], colors='black', linewidths=2)
plt.title("单层线性模型在圆形内外分类上的决策边界")
plt.xlabel("x1")
plt.ylabel("x2")
plt.legend()
plt.axis("equal")
plt.show()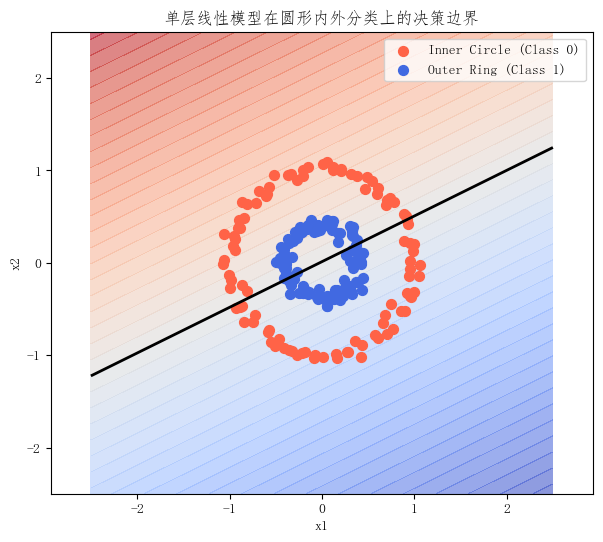
这张图会非常清楚地显示出:
单层线性模型最终学出来的,仍然只是一条近似直线的边界。它也许能把一部分样本分开,但不可能真正贴合"圆"这种结构。
这里的问题不是模型完全不会分类,而是:
它只能用错误的边界形式去逼近一个本来就不是线性的问题。
5. 多个神经元叠加后,能力为什么会发生变化?
圆形分类这个例子的重要性,不只是说明"单层线性模型学不出来",而是进一步揭示了一个更本质的事实:
多个神经元和多层结构的组合,可以开始逼近单个神经元无法表示的边界。
如果只用一个神经元,本质上只能学出一条线性边界。
但一旦引入多个神经元、隐藏层和非线性激活,模型就不再只能学一条线,而是能够把多个简单的线性变换一层层组合起来,逐步逼近更复杂的边界。
从这个角度看,多层网络的价值并不只是"层数更多",而是它让模型开始能够表示那些单个神经元无法表达的模式。圆形边界只是一个非常直观的例子。推广开来,现实中的很多问题本来就不是一个简单线性表达式能直接写清楚的,它们往往对应更复杂的曲线、分段结构,甚至更高维空间中的复杂几何形状。
因此,模型从单层走向多层,并不是为了"看起来更复杂",而是为了获得足够的表达能力,去处理这些更接近真实世界的问题。
6. 多层网络的能力从哪里开始变化?
多层网络真正带来的,不只是"层数变多",而是:
模型开始具备逐层构造更复杂表示的能力。
可以把这个过程理解成:
- 第一层先学一些简单边界
- 第二层再把这些简单边界组合起来
- 后面的层继续在已有表示上构造更复杂的模式
从表达能力的角度看,关键变化不在于"更深"本身,而在于:
模型终于不再只能做一次线性切分,而是可以把多个简单变换组合起来。
7. 最少需要多少层,这个问题该怎么理解?
看到这里,一个很自然的问题是:
那到底最少需要多少层?
这个问题本身是合理的,而且值得说明一下。
对于像"圆形内外分类"这样的任务,可以明确的是:
- 单层线性模型一定不够
- 只要加入至少一层隐藏层,并配合非线性激活,模型就开始具备表示更复杂边界的能力
至于从理论上"最少需要多少个隐藏单元、多少层才能精确表示某一种边界",这是更细的理论问题。放在入门阶段,更重要的不是先追求严格证明,而是先看清一个本质变化:
从没有隐藏层,到至少有一层隐藏层,模型的表达能力已经发生了变化。
也就是说,这里的重点不是先回答"到底两层还是三层最优",而是先理解:
单层不够,多层开始有能力。
8. 这段圆形分类代码到底在说明什么?
如果直接看代码,很容易把注意力放到"网络有几层、每层几个神经元"这些细节上。
但这篇文章更重要的事情,是先把问题讲清楚。
整个案例其实是在做一个非常直接的对比实验:
- 先构造一个"边界明显不是直线"的问题
- 再用单层线性模型试一次
- 最后用一个最小 MLP 再试一次
- 通过决策边界图比较两者的表达能力
所以这段代码的核心目标不是追求最优结果,而是为了把下面这个问题说明白:
单层模型为什么不够,而多层模型为什么开始有能力。
也正因为如此,这里不需要一开始就把层数、隐藏层宽度、全连接维度调到"最优"。这篇文章的重点不是网络调参,而是先把核心问题讲清楚:
- 单层为什么不够
- 多层为什么开始有能力
- 隐藏层和非线性为什么重要
只要这个问题先看清了,后面再去讨论更细的结构设置和隐藏层到底在学什么,就会顺很多。
9. 用一个最小 MLP 解决这个问题
下面这段完整代码,直接把"单层线性模型 vs 多层感知机 MLP"的对比放在一起。它的作用不是追求最优精度,而是把问题用图形方式讲透。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
import torch
import torch.nn as nn
import torch.optim as optim
# =========================
# 1. 生成圆形内外分类数据
# =========================
np.random.seed(42)
n_samples = 600
X = np.random.uniform(-2, 2, (n_samples, 2))
r = np.sqrt(X[:, 0] ** 2 + X[:, 1] ** 2)
y = (r > 1.0).astype(np.int64) # 圆外为1,圆内为0
# =========================
# 2. 先画原始数据
# =========================
plt.figure(figsize=(6, 6))
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='tomato', s=20, label='Inner Circle (Class 0)')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='royalblue', s=20, label='Outer Ring (Class 1)')
plt.title("圆形内外分类:原始数据分布")
plt.xlabel("x1")
plt.ylabel("x2")
plt.legend()
plt.axis("equal")
plt.grid(alpha=0.3)
plt.show()
# =========================
# 3. 定义画决策边界的函数
# =========================
def plot_decision_boundary(model, X, y, title, is_torch=False):
xx, yy = np.meshgrid(np.linspace(-2.5, 2.5, 300),
np.linspace(-2.5, 2.5, 300))
grid = np.c_[xx.ravel(), yy.ravel()]
if is_torch:
grid_tensor = torch.tensor(grid, dtype=torch.float32)
with torch.no_grad():
probs = model(grid_tensor).numpy().reshape(xx.shape)
else:
probs = model.predict_proba(grid)[:, 1].reshape(xx.shape)
plt.figure(figsize=(7, 6))
plt.contourf(xx, yy, probs, levels=50, cmap="coolwarm", alpha=0.6)
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='tomato', s=20, label='Inner Circle (Class 0)')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='royalblue', s=20, label='Outer Ring (Class 1)')
plt.contour(xx, yy, probs, levels=[0.5], colors='black', linewidths=2)
plt.title(title)
plt.xlabel("x1")
plt.ylabel("x2")
plt.legend()
plt.axis("equal")
plt.grid(alpha=0.3)
plt.show()
# =========================
# 4. 单层线性模型(逻辑回归)
# =========================
linear_model = LogisticRegression()
linear_model.fit(X, y)
plot_decision_boundary(
linear_model, X, y,
title="单层线性模型在圆形内外分类上的决策边界"
)
# =========================
# 5. 多层感知机 MLP
# =========================
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y.reshape(-1, 1), dtype=torch.float32)
class SimpleMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 16),
nn.ReLU(),
nn.Linear(16, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.net(x)
mlp = SimpleMLP()
criterion = nn.BCELoss()
optimizer = optim.Adam(mlp.parameters(), lr=0.01)
for epoch in range(1000):
optimizer.zero_grad()
outputs = mlp(X_tensor)
loss = criterion(outputs, y_tensor)
loss.backward()
optimizer.step()
if epoch % 200 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
plot_decision_boundary(
mlp, X, y,
title="多层感知机 MLP 在圆形内外分类上的决策边界",
is_torch=True
)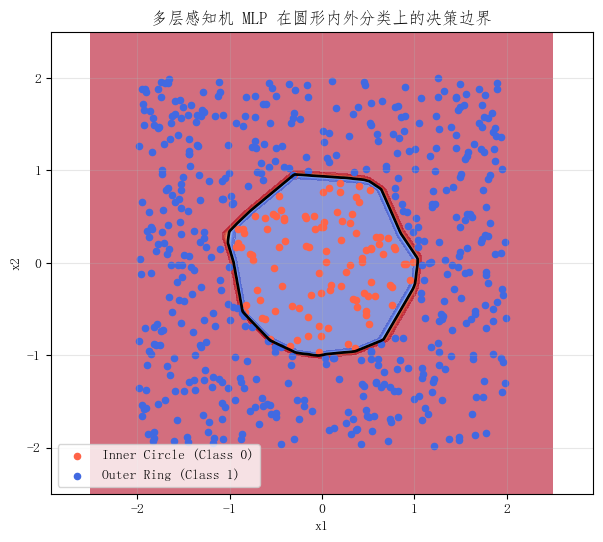
祖冲之点了个赞,他说过可以用多边形逼近圆形。就把多边形看成是多个线性边界的组合。这说明,多层模型为什么开始有能力,是因为它开始可以表示更复杂的线性关系。

这个实验最值得看的不是某个具体数字,而是最后那两张图:
- 单层模型只能给出一条线性边界
- MLP 学出来的边界开始接近圆形
这说明,多层感知机之所以更强,不是因为它"更大",而是因为它真正开始具备了更复杂的表达能力。
10. 最容易混淆的几个点
10.1 一个神经元不够,只是因为参数太少
不完全是。
更根本的问题不是参数数量,而是单个神经元本质上只能表示线性关系。
10.2 只要多加几个神经元,就一定能解决问题
不一定。
如果结构上仍然没有形成真正的多层非线性表示,模型能力未必会有本质变化。
10.3 多层网络只是"更大"的单层网络
不是。
多层网络的关键不只是更大,而是可以形成中间表示和更复杂的组合关系。
10.4 圆形内外分类只是一个特殊例子
不是。
它的重要性恰恰在于:这个问题足够直观,能非常清楚地把"单层线性边界为什么不够、多层为什么开始有能力"这件事表现出来。
11. 总结
单个神经元能够完成最基础的分类决策,但它本质上仍然只是一个线性分类器。
这意味着,一旦问题中的规律超出了线性边界所能表达的范围,它就会遇到非常明确的能力上限。
圆形内外分类这个案例很好地说明了这一点:
- 单层线性模型学不出圆形边界
- 多层感知机 MLP 借助隐藏层和非线性,开始有能力逼近这种更复杂的结构
如果把全文压缩成一句话,可以概括为:
一个神经元不够,不是因为它太小,而是因为它只能学出一条线性的判断边界。