国产系统部署(麒麟)
国产系统注意事项
1.先确认 Python 环境:
bash
bash
# 查看 Python 版本(需要 3.8+)
python3 --version
# 查看 pip3 是否已安装
pip3 --version如果显示 -bash: pip3: command not found,先安装 pip3:
bash
bash
sudo yum install -y python3-pip2 升级 Python 3.8+
1.检查系统架构(重要)
首先确认你的系统架构,这会影响后续下载哪个源码包:
bash
uname -m输出可能是:
-
x86_64:Intel/AMD 64位架构 -
aarch64:ARM 64位架构(飞腾、鲲鹏处理器)
本系统是x86_64
2.安装编译依赖下载 Python 3.8 源码解压并编译安装
bash
# 1. 安装编译依赖-说明:这些依赖确保 Python 编译后能正常使用 pip、SSL、压缩等功能。
sudo yum install -y gcc make zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel xz-devel wget
# 2. 下载源码
cd /usr/local/src
sudo wget https://www.python.org/ftp/python/3.8.18/Python-3.8.18.tgz
# 3. 解压并编译
sudo tar -xzf Python-3.8.18.tgz
cd Python-3.8.18
sudo ./configure --prefix=/usr/local/python3.8 --enable-optimizations
sudo make -j$(nproc)
sudo make altinstall
# 4. 创建软链接
sudo ln -sf /usr/local/python3.8/bin/python3.8 /usr/bin/python3.8
sudo ln -sf /usr/local/python3.8/bin/pip3.8 /usr/bin/pip3.8
# 5. 验证
python3.8 --version为什么用
altinstall? 这样安装后,Python 3.8 的可执行文件是/usr/local/python3.8/bin/python3.8,不会覆盖系统自带的python3(可能是 3.7),避免破坏系统工具。
⚠️ 注意 :切换默认 python3 可能会影响依赖 Python 3.7 的系统工具(如 yum)。建议保留系统默认,使用python3.8命令专门运行 FunASR。
1. 安装 whisper
bash
bash
# 使用 python3.8 安装
python3.8 -m pip install openai-whisper
2. 创建服务
bash
bash
cat > whisper_server.py << 'EOF'
#!/usr/bin/env python3
import json
import tempfile
import os
from http.server import HTTPServer, BaseHTTPRequestHandler
import cgi
import sys
print("正在加载 Whisper...")
sys.stdout.flush()
try:
import whisper
print("Whisper 导入成功")
print("正在加载模型...")
model = whisper.load_model("base")
print("模型加载完成!")
except Exception as e:
print(f"加载失败: {e}")
sys.exit(1)
class Handler(BaseHTTPRequestHandler):
def do_GET(self):
if self.path == '/health':
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps({"status": "ok"}).encode())
else:
self.send_response(404)
self.end_headers()
def do_POST(self):
if self.path == '/recognition':
try:
form = cgi.FieldStorage(
fp=self.rfile,
headers=self.headers,
environ={'REQUEST_METHOD': 'POST'}
)
if 'audio' not in form:
self.send_error(400, "No audio file")
return
file_item = form['audio']
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as tmp:
tmp.write(file_item.file.read())
tmp_path = tmp.name
# 识别
result = model.transcribe(tmp_path, language="zh")
os.unlink(tmp_path)
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
response = json.dumps({"code": 0, "text": result["text"]})
self.wfile.write(response.encode())
except Exception as e:
self.send_response(500)
self.end_headers()
self.wfile.write(json.dumps({"code": 1, "msg": str(e)}).encode())
else:
self.send_response(404)
self.end_headers()
if __name__ == "__main__":
port = 8000
server = HTTPServer(('0.0.0.0', port), Handler)
print(f"✅ HTTP 服务启动成功!")
print(f"📍 地址: http://0.0.0.0:{port}")
print(f"✅ 健康检查: http://localhost:{port}/health")
print(f"✅ 识别接口: POST http://localhost:{port}/recognition")
print("\n按 Ctrl+C 停止服务")
sys.stdout.flush()
server.serve_forever()
EOF
python3 whisper_server.py
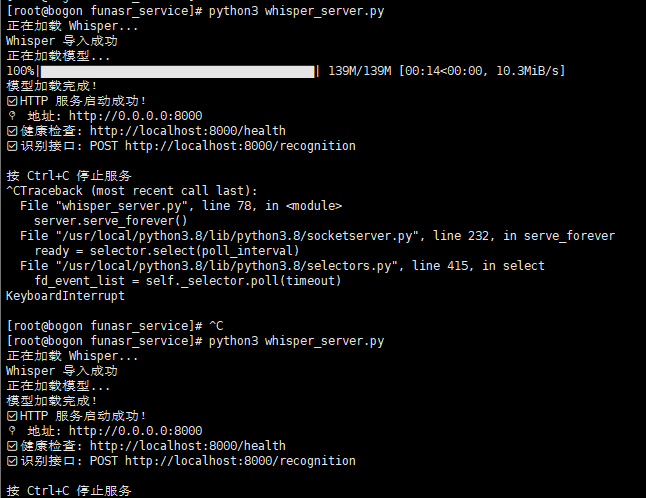
如果失败安装 ffmpeg
bash
# 安装 ffmpeg(解决音频处理问题)
yum install ffmpeg -y
# 或
apt install ffmpeg -y
# 重新安装 whisper
python3 -m pip install --upgrade openai-whisper安装 ffmpeg失败,使用 Python 音频处理
修改服务代码,不依赖 ffmpeg:
bash
bash
cat > no_ffmpeg_server.py << 'EOF'
#!/usr/bin/env python3
import json
import tempfile
import os
import wave
import numpy as np
from http.server import HTTPServer, BaseHTTPRequestHandler
import cgi
import sys
import io
print("正在加载 Whisper...")
sys.stdout.flush()
try:
import whisper
print("Whisper 导入成功")
print("正在加载模型...")
model = whisper.load_model("base")
print("模型加载完成!")
except Exception as e:
print(f"加载失败: {e}")
traceback.print_exc()
sys.exit(1)
def convert_to_wav(audio_data):
"""尝试将音频数据转换为 wav 格式"""
try:
# 如果已经是 wav,直接返回
if audio_data[:4] == b'RIFF':
return audio_data
# 尝试用 soundfile 处理
try:
import soundfile as sf
import io
data, sr = sf.read(io.BytesIO(audio_data))
with io.BytesIO() as buf:
sf.write(buf, data, sr, format='wav')
return buf.getvalue()
except:
pass
# 如果都失败,返回原始数据
return audio_data
except:
return audio_data
class Handler(BaseHTTPRequestHandler):
def send_cors_headers(self):
self.send_header('Access-Control-Allow-Origin', '*')
self.send_header('Access-Control-Allow-Methods', 'GET, POST, OPTIONS')
self.send_header('Access-Control-Allow-Headers', 'Content-Type')
def do_OPTIONS(self):
self.send_response(200)
self.send_cors_headers()
self.end_headers()
def do_GET(self):
if self.path == '/health':
self.send_response(200)
self.send_cors_headers()
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps({"status": "ok"}).encode())
else:
self.send_response(404)
self.end_headers()
def do_POST(self):
if self.path == '/recognition':
try:
form = cgi.FieldStorage(
fp=self.rfile,
headers=self.headers,
environ={'REQUEST_METHOD': 'POST'}
)
if 'audio' not in form:
self.send_error(400, "No audio file")
return
file_item = form['audio']
audio_data = file_item.file.read()
print(f"收到音频,大小: {len(audio_data)} 字节")
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as tmp:
tmp.write(audio_data)
tmp_path = tmp.name
# 识别
result = model.transcribe(tmp_path, language="zh")
os.unlink(tmp_path)
print(f"识别结果: {result['text'][:50]}...")
self.send_response(200)
self.send_cors_headers()
self.send_header('Content-type', 'application/json')
self.end_headers()
response = json.dumps({"code": 0, "text": result["text"]})
self.wfile.write(response.encode())
except Exception as e:
print(f"错误: {e}")
import traceback
traceback.print_exc()
self.send_response(500)
self.send_cors_headers()
self.end_headers()
self.wfile.write(json.dumps({"code": 1, "msg": str(e)}).encode())
else:
self.send_response(404)
self.end_headers()
if __name__ == "__main__":
port = 8000
server = HTTPServer(('0.0.0.0', port), Handler)
print(f"✅ HTTP 服务启动成功!")
print(f"📍 地址: http://0.0.0.0:{port}")
print(f"✅ 健康检查: http://localhost:{port}/health")
print(f"✅ 识别接口: POST http://localhost:{port}/recognition")
print("\n按 Ctrl+C 停止服务")
sys.stdout.flush()
server.serve_forever()
EOF
python3 no_ffmpeg_server.py识别结果显示的是繁体中文,这是因为 Whisper 模型默认输出的文字格式。如果你需要简体中文,可以添加转换。
✅ 添加繁转简功能
安装 opencc 完整繁转简
bash
bash
# 使用 python3 -m pip 安装
python3 -m pip install opencc-python-reimplemented
# 如果网络慢,使用国内镜像
python3 -m pip install opencc-python-reimplemented -i https://pypi.tuna.tsinghua.edu.cn/simple📝 更新服务代码
bash
bash
cat > final_server.py << 'EOF'
#!/usr/bin/env python3
import json
import tempfile
import os
from http.server import HTTPServer, BaseHTTPRequestHandler
import cgi
import sys
print("正在加载 Whisper...")
sys.stdout.flush()
try:
import whisper
print("Whisper 导入成功")
print("正在加载模型...")
model = whisper.load_model("base")
print("模型加载完成!")
except Exception as e:
print(f"加载失败: {e}")
sys.exit(1)
# 尝试导入 opencc
try:
from opencc import OpenCC
cc = OpenCC('t2s') # 繁体转简体
print("OpenCC 加载成功,将自动转换繁体到简体")
except:
cc = None
print("OpenCC 未安装,将使用简单转换")
# 简单繁转简映射(备用)
def simple_convert(text):
mapping = {
'沒': '没', '應': '应', '該': '该', '讓': '让', '們': '们', '這': '这',
'個': '个', '為': '为', '會': '会', '對': '对', '於': '于', '從': '从',
'來': '来', '說': '说', '話': '话', '電': '电', '腦': '脑', '機': '机',
'體': '体', '國': '国', '際': '际', '關': '关', '係': '系', '開': '开',
'門': '门', '問': '问', '題': '题', '點': '点', '時': '时', '間': '间',
'長': '长', '短': '短', '高': '高', '低': '低', '熱': '热', '愛': '爱',
'學': '学', '習': '习', '書': '书', '寫': '写', '讀': '读', '聽': '听',
'視': '视', '頻': '频', '資': '资', '訊': '讯', '網': '网', '路': '路'
}
for trad, simp in mapping.items():
text = text.replace(trad, simp)
return text
def to_simplified(text):
if cc:
return cc.convert(text)
else:
return simple_convert(text)
class Handler(BaseHTTPRequestHandler):
def send_cors_headers(self):
self.send_header('Access-Control-Allow-Origin', '*')
self.send_header('Access-Control-Allow-Methods', 'GET, POST, OPTIONS')
self.send_header('Access-Control-Allow-Headers', 'Content-Type')
def do_OPTIONS(self):
self.send_response(200)
self.send_cors_headers()
self.end_headers()
def do_GET(self):
if self.path == '/health':
self.send_response(200)
self.send_cors_headers()
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps({"status": "ok"}).encode())
else:
self.send_response(404)
self.end_headers()
def do_POST(self):
if self.path == '/recognition':
try:
form = cgi.FieldStorage(
fp=self.rfile,
headers=self.headers,
environ={'REQUEST_METHOD': 'POST'}
)
if 'audio' not in form:
self.send_error(400, "No audio file")
return
file_item = form['audio']
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as tmp:
tmp.write(file_item.file.read())
tmp_path = tmp.name
result = model.transcribe(tmp_path, language="zh")
os.unlink(tmp_path)
text = to_simplified(result["text"])
print(f"识别: {text[:50]}...")
self.send_response(200)
self.send_cors_headers()
self.send_header('Content-type', 'application/json')
self.end_headers()
response = json.dumps({"code": 0, "text": text})
self.wfile.write(response.encode())
except Exception as e:
print(f"错误: {e}")
self.send_response(500)
self.send_cors_headers()
self.end_headers()
self.wfile.write(json.dumps({"code": 1, "msg": str(e)}).encode())
else:
self.send_response(404)
self.end_headers()
if __name__ == "__main__":
port = 8000
server = HTTPServer(('0.0.0.0', port), Handler)
print(f"✅ HTTP 服务启动成功!")
print(f"📍 地址: http://0.0.0.0:{port}")
print(f"✅ 健康检查: http://localhost:{port}/health")
print(f"✅ 识别接口: POST http://localhost:{port}/recognition")
print("\n按 Ctrl+C 停止服务")
sys.stdout.flush()
server.serve_forever()
EOF
python3 final_server.py语音识别不准确
语音识别不准确是常见问题,可能有以下几个原因和解决方案:
🔍 原因分析
| 原因 | 说明 | 解决方案 |
|---|---|---|
| 音频质量 | 背景噪音、说话距离远 | 使用降噪麦克风,靠近说话 |
| 采样率 | Whisper 需要 16kHz | 前端录音设置采样率 |
| 模型大小 | base 模型准确率有限 | 升级到 larger 模型 |
| 语言设置 | 未指定中文 | 设置 language="zh" |
| 发音问题 | 方言、口音 | 使用更大的模型 |
✅ 解决方案
1. 升级 Whisper 模型
python
# 使用更大的模型(准确率更高)
model = whisper.load_model("medium") # 或 "large"| 模型 | 大小 | 准确率 | 速度 |
|---|---|---|---|
| tiny | 39MB | 一般 | 最快 |
| base | 74MB | 较好 | 快 |
| small | 244MB | 好 | 中等 |
| medium | 769MB | 很好 | 慢 |
| large | 1.5GB | 最好 | 最慢 |
修改服务代码
bash
bash
cat > accurate_server.py << 'EOF'
#!/usr/bin/env python3
import json
import tempfile
import os
from http.server import HTTPServer, BaseHTTPRequestHandler
import cgi
import sys
import wave
import numpy as np
print("正在加载 Whisper medium 模型...")
sys.stdout.flush()
try:
import whisper
# 使用 medium 模型,准确率更高
model = whisper.load_model("medium")
print("模型加载完成!")
except Exception as e:
print(f"加载失败: {e}")
sys.exit(1)
# 繁转简
try:
from opencc import OpenCC
cc = OpenCC('t2s')
except:
cc = None
def to_simplified(text):
if cc:
return cc.convert(text)
# 简单转换
mapping = {'沒': '没', '應': '应', '該': '该', '讓': '让', '們': '们', '這': '这', '個': '个'}
for t, s in mapping.items():
text = text.replace(t, s)
return text
class Handler(BaseHTTPRequestHandler):
def send_cors_headers(self):
self.send_header('Access-Control-Allow-Origin', '*')
self.send_header('Access-Control-Allow-Methods', 'GET, POST, OPTIONS')
self.send_header('Access-Control-Allow-Headers', 'Content-Type')
def do_OPTIONS(self):
self.send_response(200)
self.send_cors_headers()
self.end_headers()
def do_GET(self):
if self.path == '/health':
self.send_response(200)
self.send_cors_headers()
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps({"status": "ok"}).encode())
else:
self.send_response(404)
self.end_headers()
def do_POST(self):
if self.path == '/recognition':
try:
form = cgi.FieldStorage(
fp=self.rfile,
headers=self.headers,
environ={'REQUEST_METHOD': 'POST'}
)
if 'audio' not in form:
self.send_error(400, "No audio file")
return
file_item = form['audio']
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as tmp:
tmp.write(file_item.file.read())
tmp_path = tmp.name
# 使用更高的参数提升准确率
result = model.transcribe(
tmp_path,
language="zh",
task="transcribe",
temperature=0,
best_of=5, # 尝试5次取最佳
beam_size=5, # 束搜索宽度
patience=2.0,
condition_on_previous_text=True,
compression_ratio_threshold=2.4,
logprob_threshold=-1.0,
no_speech_threshold=0.6
)
os.unlink(tmp_path)
text = to_simplified(result["text"])
print(f"识别: {text[:80]}...")
self.send_response(200)
self.send_cors_headers()
self.send_header('Content-type', 'application/json')
self.end_headers()
response = json.dumps({"code": 0, "text": text})
self.wfile.write(response.encode())
except Exception as e:
print(f"错误: {e}")
self.send_response(500)
self.send_cors_headers()
self.end_headers()
self.wfile.write(json.dumps({"code": 1, "msg": str(e)}).encode())
else:
self.send_response(404)
self.end_headers()
if __name__ == "__main__":
port = 8000
server = HTTPServer(('0.0.0.0', port), Handler)
print(f"✅ HTTP 服务启动成功!")
print(f"📍 地址: http://0.0.0.0:{port}")
print(f"✅ 使用模型: medium (更高准确率)")
print("按 Ctrl+C 停止服务")
server.serve_forever()
EOF
python3 accurate_server.py前端优化:提升录音质量
修改 Vue 组件的录音参数:
typescript
// 获取高质量音频
const stream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: 16000, // 16kHz 采样率
channelCount: 1, // 单声道
echoCancellation: true, // 回声消除
noiseSuppression: true, // 噪声抑制
autoGainControl: true // 自动增益
}
});