在电商、在线旅游等高频搜索驱动的业务架构中,MySQL 凭借其事务处理能力成为核心数据持久化的首选,而 Elasticsearch (ES) 则以其卓越的全文检索性能支撑起复杂的搜索需求。这种"MySQL + ES"的混合架构虽然强大,但也引入了一个经典难题:如何保障两个异构数据源之间的数据一致性?
本文将结合在线旅游平台酒店搜索的实际业务场景,深度剖析业界通用的四种数据同步方案,从实现原理、优缺点权衡到选型建议,为你提供一份详尽的技术决策指南。
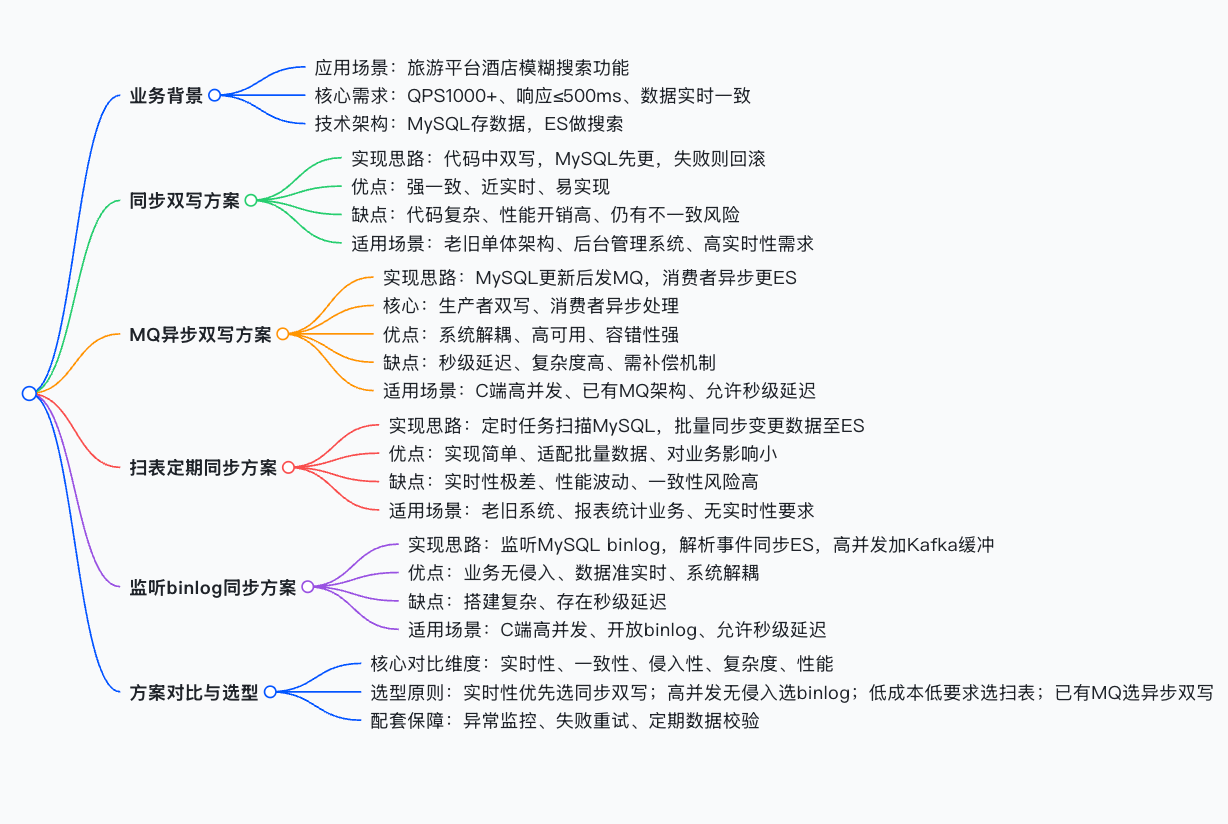
一、业务背景与核心挑战
以某在线旅游平台春季大促为例,业务端需要上线酒店模糊搜索功能,支持按目的地、名称、房型及价格区间进行多维度检索。
- 性能指标 :需支撑大促期间约 1000 QPS 的搜索并发量,且响应时间需控制在 500ms 以内。
- 一致性指标 :用户在 MySQL 端看到的酒店状态(如售罄、价格变动)必须在 ES 搜索结果中实时同步,避免"搜得到但订不了"的体验断层。
基于此,我们需要在实时性 、系统复杂度 与业务侵入性之间找到最佳平衡点。
二、四大主流方案深度剖析
1. 同步双写方案:简单粗暴的强一致性尝试
- 实现原理 这是最直观的方案。在业务代码中,当事务提交时,先更新 MySQL,紧接着同步调用 ES 接口进行更新。如果 ES 写入失败,则抛出异常触发事务回滚,以此保证两端数据的一致性。
- 核心优缺点
- 优点:
- 强一致性:理论上保证了 MySQL 与 ES 的数据实时同步,无延迟。
- 实现简单:无需引入中间件,仅需在业务层添加几行代码。
- 缺点:
- 高耦合与性能瓶颈:ES 的写入耗时直接影响主业务流程,若 ES 响应慢,会拖垮整个系统。
- 可靠性风险:网络抖动可能导致"MySQL 成功、ES 失败"且回滚失效的极端情况。
- 适用场景
- 老旧单体架构,引入中间件成本过高。
- 用户量极少、对实时性要求极高的后台管理系统。
2. MQ 异步双写方案:高并发下的解耦之道
- 实现原理 引入消息队列(如 Kafka、RocketMQ)作为缓冲。业务代码在更新 MySQL 后,发送一条变更消息到 MQ 即可直接返回;下游独立的消费者服务监听 MQ,异步消费消息并更新 ES。
- 核心优缺点
- 优点:
- 系统解耦:业务主流程与搜索同步流程完全剥离,互不影响。
- 削峰填谷:MQ 能缓冲突发流量,保护 ES 不被高并发写入击垮。
- 高可用性:消息持久化机制保证了即使 ES 宕机,数据也不会丢失,待恢复后可继续消费。
- 缺点:
- 延迟增加 :异步处理导致数据同步存在秒级延迟。
- 复杂度提升:需处理消息丢失、重复消费(需实现幂等性)及顺序消费等问题。
- 适用场景
- C 端高并发系统,允许秒级数据延迟。
- 架构中已部署 MQ 中间件,且对系统吞吐量有较高要求的场景。
3. 扫表定期同步方案:低成本的批量兜底
- 实现原理 不依赖实时触发,而是通过定时任务(如 XXL-JOB),周期性扫描 MySQL 表 (通常基于
update_time字段),拉取变更数据并批量同步至 ES。 - 核心优缺点
- 优点:
- 极低侵入性:几乎不需要修改业务代码。
- 实现简单:开发成本低,适合批量数据迁移或初始化。
- 缺点:
- 实时性极差:同步频率取决于定时任务周期(分钟级甚至小时级)。
- 数据库压力:全量或增量扫描会对 MySQL 造成查询压力。
- 适用场景
- 非核心业务,如报表统计、数据归档。
- 老旧系统改造困难,且对数据实时性不敏感的场景。
4. 监听 Binlog 方案:无侵入的准实时同步(推荐)
- 实现原理 利用 MySQL 的 Binlog(二进制日志) 记录所有数据变更。通过 Canal 、Debezium 等工具伪装成 MySQL Slave 节点,实时订阅并解析 Binlog,将数据变更投递到 MQ 或直接写入 ES。
- 核心优缺点
- 优点:
- 业务零侵入:同步逻辑完全独立于业务代码,业务方无感知。
- 高可靠性与实时性:基于日志的流式处理,延迟通常在毫秒至秒级,且不会漏掉任何变更。
- 缺点:
- 运维复杂度高:需额外部署 Canal/Debezium 及 Zookeeper/Kafka 等组件,架构链路变长。
- 适用场景
- 互联网公司、大型分布式系统。
- 对数据一致性要求高,且希望业务代码保持纯净的场景。
三、方案选型对比矩阵
为了更直观地辅助决策,我们将四种方案在关键维度上进行对比:
| 方案维度 | 同步双写 | MQ 异步双写 | 扫表定期同步 | 监听 Binlog |
|---|---|---|---|---|
| 实时性 | 极高(实时) | 高(秒级延迟) | 低(分钟/小时级) | 高(准实时) |
| 一致性 | 强一致 | 最终一致 | 最终一致 | 最终一致 |
| 业务侵入性 | 高(代码耦合) | 中(需发 MQ 消息) | 低 | 无(完全解耦) |
| 系统复杂度 | 低 | 中高 | 低 | 高 |
| 性能影响 | 高(阻塞主流程) | 低(异步非阻塞) | 中(扫描占用 IO) | 低(独立进程) |
四、技术选型决策建议
在实际架构设计中,没有绝对的"银弹",只有最适合的方案:
- 追求极致实时性且业务简单 :若系统规模小,且无法容忍延迟,可选择 同步双写,但需做好异常补偿。
- 高并发与架构解耦 :对于大多数互联网 C 端应用,MQ 异步双写 是兼顾性能与可靠性的主流选择。
- 追求架构优雅与零侵入 :如果团队具备运维能力,监听 Binlog(Canal/Debezium) 是最理想的方案,它能彻底将搜索业务从核心交易链路中剥离。
- 老旧系统低成本改造 :对于无法修改代码的遗留系统,扫表同步 是唯一的可行路径。
五、总结
保障 MySQL 与 ES 的数据一致性,本质上是在 CAP 理论 中寻找平衡点。无论选择哪种方案,都建议配套建设 数据校验与修复机制(如定期比对两端数据指纹),以应对网络抖动、系统故障带来的极端不一致情况,从而构建一个健壮、高可用的搜索中台。