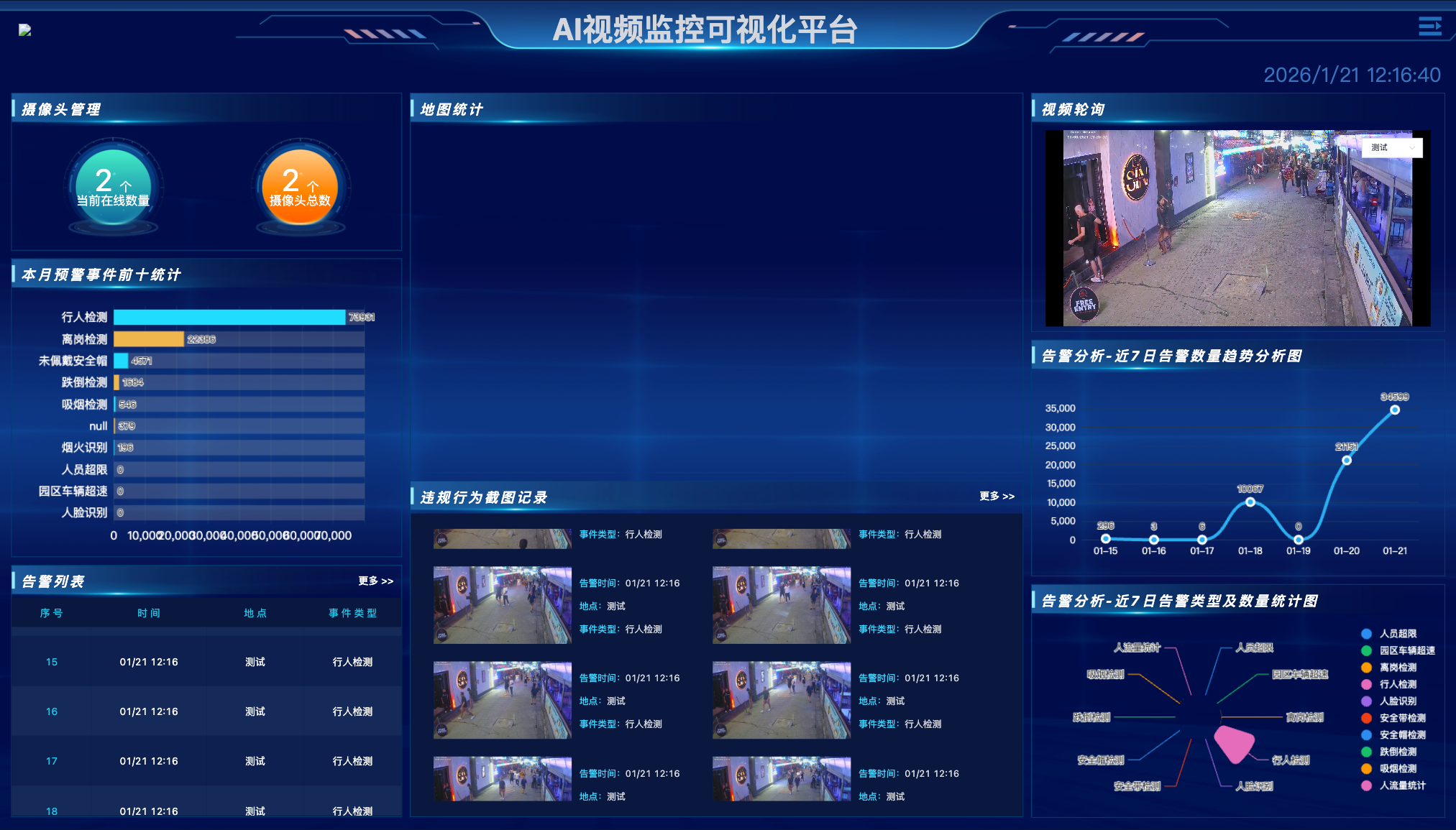
引言:算力碎片化时代的"异构"挑战
在 AI 落地安防的深水区,架构师面临的最大挑战不再是算法模型的精度,而是算力底座的碎片化。项目现场往往呈现出复杂的"万国牌"局面:总部机房可能部署着 NVIDIA A100 的 x86 服务器用于离线训练,而前端边缘节点则使用着华为昇腾、瑞芯微、算能等不同厂商的 ARM 芯片用于实时推理。
传统的视频管理平台通常绑定特定的硬件厂商,导致企业在私有化部署时,不得不为了软件去采购昂贵的特定硬件,或者为了现有硬件去重写底层代码。这不仅造成了巨大的资源浪费,更让开发成本居高不下。
本文将深度解析 YiheCode Server 的底层架构。这套系统如何通过全硬件适配 与异构计算调度 ,打通 x86 与 ARM 的壁垒,实现对多品牌 GPU/NPU 的统一纳管,从而兑现"减少 95% 开发成本"的承诺?
一、 底层架构:硬件抽象层与指令集解耦
YiheCode Server 的核心设计理念是**"硬件与应用解耦"。系统并没有将算法逻辑硬编码在特定的 CUDA 或特定 NPU 的 SDK 中,而是构建了一套硬件抽象层(Hardware Abstraction Layer, HAL)**。
这套架构允许平台在不修改上层业务代码的情况下,动态适配不同的底层算力。无论是基于 x86 指令集的高性能服务器,还是基于 ARM 指令集的低功耗边缘盒子,都能通过统一的接口与平台进行交互。
1.1 跨平台指令集支持矩阵
系统通过容器化与交叉编译技术,实现了对主流芯片架构的全覆盖:
| 硬件类型 | 指令集架构 | 适用场景 | 部署模式 |
|---|---|---|---|
| 云端/中心端 | x86_64 | 大规模视频流汇聚、高复杂度算法推理(如 ReID)。 | Docker/K8s 集群部署,支持 NVIDIA GPU 直通。 |
| 边缘端 | ARM64 | 前端实时分析、低延迟告警、带宽节省。 | 物理机或轻量级容器,适配昇腾、瑞芯微、算能等 NPU。 |
| 混合环境 | Hybrid | 复杂组网,中心调度边缘算力。 | 分布式 ZLMediaKit 节点 + 边缘推理 Agent。 |
二、 异构计算调度:GPU 与 NPU 的统一纳管
YiheCode Server 的边缘平台 模块是实现异构计算的核心。它不仅仅是一个视频流管理工具,更是一个算力资源调度器 。

2.1 边缘盒子的算力指纹识别
当一个边缘盒子(计算节点)注册到平台时,系统会通过心跳机制获取该节点的"算力指纹",包括:
- 芯片类型 (Chipset):自动识别是 NVIDIA、昇腾还是瑞芯微。
- 算力负载 (Load):实时监控 CPU、内存及 NPU 利用率。
- 算法兼容性 (Support Models):识别该节点支持的模型格式(TensorRT, OM, RKNN 等)。
伪代码:边缘节点心跳与算力上报
python
class EdgeNodeAgent:
def report_heartbeat(self):
# 1. 采集系统信息
hardware_info = {
"arch": self.get_arch(), # x86_64 or aarch64
"chipset": self.detect_chipset(), # e.g., "Rockchip_RK3588"
"cuda_available": self.check_cuda(),
"npu_driver": self.check_npu_driver()
}
# 2. 采集实时负载
metrics = {
"cpu_percent": psutil.cpu_percent(),
"memory_mb": psutil.virtual_memory().used / 1024 / 1024,
"gpu_npu_load": self.get_accelerator_load() # 通用加速卡负载
}
# 3. 上报至中心管理服务
requests.post(
f"{CENTER_URL}/api/v1/nodes/{self.node_id}/heartbeat",
json={"hardware": hardware_info, "metrics": metrics}
)2.2 智能算法的"一次配置,处处运行"
在算法商城中,模型是与硬件解耦的。开发者只需上传标准的模型文件(如 ONNX 或各厂商编译后的格式),平台会根据目标节点的硬件指纹,自动分发匹配的模型版本。
- 场景示例 :
- 当你在界面上选择"烟火检测"算法并分配给"NVIDIA 服务器"时,平台下发 TensorRT 引擎。
- 当分配给"瑞芯微盒子"时,平台自动下发 RKNN 模型。
- 开发者无需关心底层差异,只需关注业务逻辑。
三、 流媒体架构:基于 ZLMediaKit 的分布式组网
硬件适配仅仅是第一步,海量视频流的传输与处理才是性能的试金石。YiheCode Server 采用了 ZLMediaKit 作为流媒体底座,并设计了独特的节点分配策略,以适应异构网络环境。
3.1 动态节点分配算法
系统内置了负载均衡算法,用于决定视频流拉取到哪个 ZLMediaKit 节点:
- 亲和性调度 (Affinity):优先将摄像头流拉取到与其在同一网段的边缘 ZLM 节点,减少核心交换机带宽压力。
- 算力感知调度 (Awareness):如果边缘节点算力不足(如 NPU 满载),系统会自动将流推送到中心 x86 服务器进行软件解码或 CPU 推理。
配置文件示例 (application.yml):
yaml
zlm:
# 节点选择策略
node-selection-strategy: "load-balanced"
# 负载权重配置 (CPU权重较低,NPU权重最高)
load-factor:
cpu: 0.3
memory: 0.2
npu: 0.5 # NPU算力是调度的关键指标
# 亲和性设置
affinity:
enabled: true
# 同 CIDR 网段优先级 +1
local-network-priority: 1 3.2 异构环境下的编解码优化
针对 x86 和 ARM 对硬件编解码支持的不同,平台采用了自适应策略:
- x86 环境:优先使用 NVIDIA NVENC/NVDEC 进行 H.265/H.264 的硬解硬编,降低 CPU 占用。
- ARM 环境:利用瑞芯微/昇腾内置的 VPU 进行解码,若遇到不支持的编码格式(如某些特殊的 H.265),则自动降级为 FFmpeg 软解。
四、 总结
YiheCode Server 通过异构计算架构 ,成功解决了企业级 AI 视频应用中"硬件不统一"的顽疾。
它利用硬件抽象层 屏蔽了 x86 与 ARM 的差异,利用边缘调度器实现了对多品牌 GPU/NPU 的统一纳管。这种架构使得企业无需为了软件而更换现有硬件,无论是老旧的 x86 服务器,还是新采购的 ARM 边缘盒子,都能在这个平台上发挥价值。
对于寻求私有化部署 、降本增效的技术决策者来说,这套架构提供了一种"软硬解耦"的最佳实践方案,真正实现了"一套代码,跑在所有硬件上"。
架构师建议 :
在进行大规模部署前,建议先在边缘节点安装
docker和npu-driver。如果您的边缘设备是 ARM 架构,请确保在编译边缘 Agent 时指定GOARM=7或GOARCH=arm64。对于算法模型,建议先在单路流环境下测试 NPU 的推理延迟(RT),确保满足实时性要求。