当你要搭建一个Agent系统时,第一道选择题就是:用哪个框架?
选错了,后面全是坑。选对了,事半功倍。
一、开篇:Agent框架选型的"决策瘫痪"困境
"GPT-4 API我调通了,但要搭建一个真正的Agent系统,该用哪个框架?"
这是2026年技术团队面临的高频问题。根据Gartner 2025年Q4的数据,企业级Agent项目失败率高达62%,其中框架选型失误贡献了38%的失败原因------要么选了过于复杂的框架导致开发周期失控,要么选了能力不足的框架在关键场景卡死。
更矛盾的是:Agent框架市场正经历"供给过剩"与"选择困难"的双重挤压。GitHub上Star数超过1万的Agent框架已超过20个,LangChain突破10万Star,AutoGen、CrewAI、MetaGPT等后起之秀各占山头。开发者面临的不是"有没有框架可用",而是"框架太多,根本选不过来"。
问题的本质是:每个框架都在试图解决不同的问题。
- LangChain想做"AI应用的瑞士军刀"
- AutoGen想做"多Agent协作的标准答案"
- OpenClaw想做"桌面级Agent的操作系统"
- CrewAI想做"团队协作的角色扮演"
- MetaGPT想做"AI驱动的软件公司"
它们的目标不同,设计哲学不同,适用场景也不同。不存在一个"万能最优解",只有"特定场景下的最佳选择"。
本文将通过三维对比框架(架构深度、生态成熟度、场景匹配度)、5个Mermaid架构图、2个企业级实战案例,为你提供一套可复用的Agent框架选型决策模型。
二、框架全景图:2026年主流Agent框架分类
先用一张图看清整个战场:
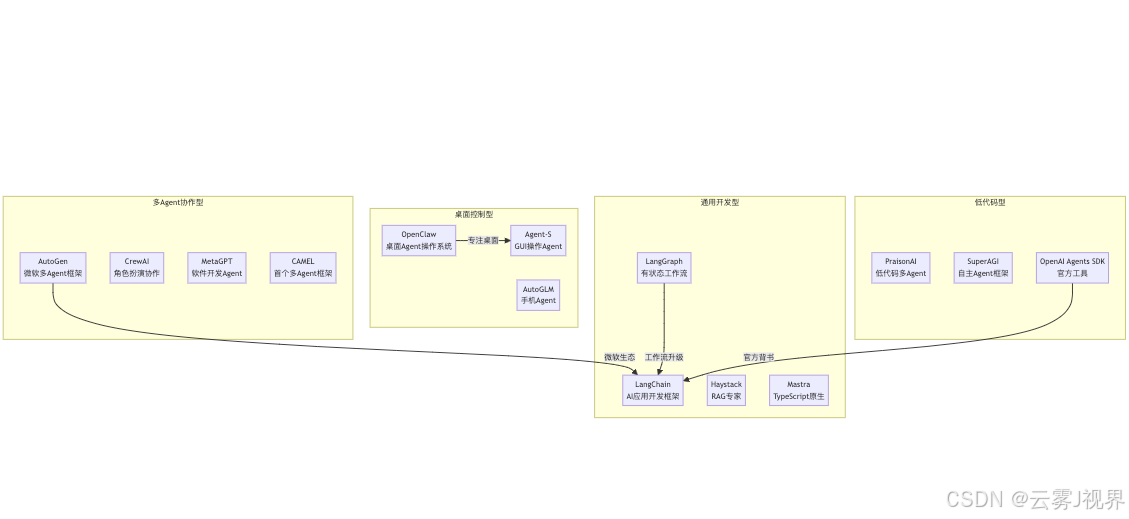
2.1 框架分类的本质逻辑
框架分类不是简单的"标签划分",而是技术架构与商业定位的双重选择。以下表格揭示了每类框架的核心价值主张与设计取舍:
| 类型 | 核心价值 | 代表框架 | 技术边界 | 商业模式 |
|---|---|---|---|---|
| 桌面控制型 | Agent能直接操作你的电脑/手机 | OpenClaw, Agent-S, AutoGLM | 需要本地执行环境,难以云端部署 | 企业私有化部署 |
| 多Agent协作型 | 多个Agent分工协作完成复杂任务 | AutoGen, CrewAI, MetaGPT | 协调开销高,简单任务过重 | 云端API调用 |
| 通用开发型 | 构建AI应用的底层基础设施 | LangChain, LangGraph, Haystack | 学习曲线陡峭,组装成本高 | 开源+SaaS服务 |
| 低代码型 | 降低门槛,快速上手 | PraisonAI, OpenAI Agents SDK | 能力边界受限,定制性差 | 订阅制 |
你的第一步:先想清楚你要做什么类型的Agent。
三、三大主角深度对比:OpenClaw vs LangChain vs AutoGen
本节将从架构设计、核心能力、适用场景三个维度,对三大主流框架进行深度对比。每项对比均包含数据支撑与代码示例。
3.1 OpenClaw:桌面Agent的操作系统
一句话定位: 让Agent像人一样操作你的电脑。
架构深度解析
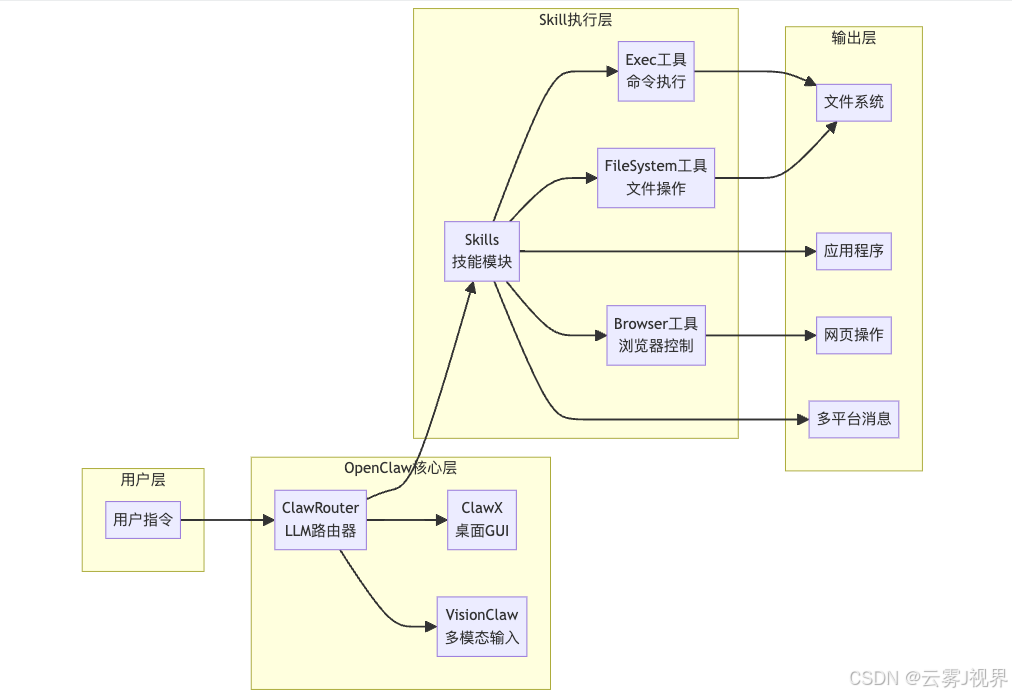
核心特性对比
| 特性 | 说明 | 技术实现 |
|---|---|---|
| 桌面控制 | 直接操作文件系统、应用程序、浏览器 | Exec工具 + Shell命令 |
| 多模态支持 | VisionClaw支持智能眼镜、图像输入 | 多模态LLM + 图像编码 |
| Skill系统 | 模块化技能,可自定义开发 | YAML配置 + Python实现 |
| LLM路由 | ClawRouter智能选择最优模型 | 成本-质量权衡算法 |
| 多平台集成 | Telegram、Discord、WhatsApp、飞书等 | Webhook + API适配 |
实战代码示例:自定义Skill开发
python
# OpenClaw Skill 开发示例:自动化报告生成
from openclaw import Skill, Tool, Parameter
class ReportGeneratorSkill(Skill):
"""自动从数据源拉取数据并生成报告"""
name = "report_generator"
description = "从指定数据源拉取数据,生成格式化报告"
parameters = [
Parameter(
name="data_source",
type="string",
description="数据源路径或URL",
required=True
),
Parameter(
name="report_type",
type="string",
description="报告类型:daily/weekly/monthly",
required=True
)
]
tools = [
Tool(name="exec", description="执行Shell命令"),
Tool(name="browser", description="浏览器操作"),
Tool(name="filesystem", description="文件系统操作")
]
async def execute(self, context):
# Step 1: 拉取数据
data = await self.pull_data(context.params["data_source"])
# Step 2: 数据分析
analysis = await self.analyze_data(data, context.params["report_type"])
# Step 3: 生成报告
report = await self.generate_report(analysis)
# Step 4: 保存到指定位置
await self.tools.filesystem.write(
path=f"~/reports/{context.params['report_type']}_{context.date}.md",
content=report
)
return {"status": "success", "report_path": f"~/reports/{context.params['report_type']}_{context.date}.md"}
async def pull_data(self, source):
# 实现数据拉取逻辑
pass
async def analyze_data(self, data, report_type):
# 实现数据分析逻辑
pass
async def generate_report(self, analysis):
# 实现报告生成逻辑
pass
# 注册Skill
from openclaw import ClawRouter
router = ClawRouter()
router.register_skill(ReportGeneratorSkill())适用场景分析
| 场景 | 适用度 | 理由 |
|---|---|---|
| 自动化办公流程 | ⭐⭐⭐⭐⭐ | 桌面控制是原生能力 |
| 浏览器自动化 | ⭐⭐⭐⭐⭐ | Browser工具深度集成 |
| 桌面应用集成 | ⭐⭐⭐⭐⭐ | Exec工具支持任意命令 |
| 多模态应用 | ⭐⭐⭐⭐ | VisionClaw支持图像输入 |
| 纯云端部署 | ⭐⭐ | 需要本地执行环境 |
| 大规模分布式Agent集群 | ⭐⭐ | 设计为单机为主 |
| 简单问答类Agent | ⭐ | 功能过剩 |
3.2 LangChain:AI应用的瑞士军刀
一句话定位: 构建AI应用的基础设施,什么都能做,但需要你自己组装。
架构深度解析
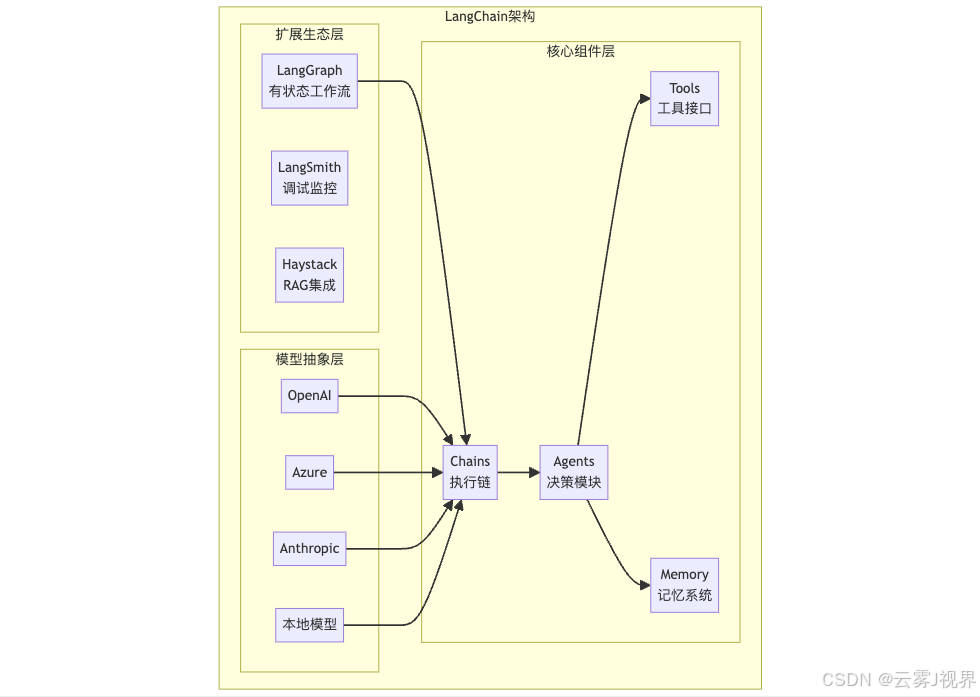
核心特性对比
| 特性 | 说明 | 技术实现 |
|---|---|---|
| Chain机制 | 将多个步骤串联成执行流程 | LCEL(LangChain Expression Language) |
| Tool接口 | 标准化的工具调用协议 | Function Calling + 自定义Tool |
| Memory系统 | 多种记忆策略 | BufferMemory、SummaryMemory、EntityMemory |
| 模型抽象 | 统一接口支持多种LLM | BaseLLM抽象类 |
| 生态丰富 | LangGraph、LangSmith等扩展 | 模块化设计 |
实战代码示例:RAG系统构建
python
# LangChain RAG系统构建示例
from langchain import LangChain
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.document_loaders import DirectoryLoader
# Step 1: 加载文档
loader = DirectoryLoader("./documents", glob="**/*.md")
documents = loader.load()
# Step 2: 文档分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
splits = text_splitter.split_documents(documents)
# Step 3: 构建向量存储
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
persist_directory="./chroma_db"
)
# Step 4: 构建RAG链
qa_chain = RetrievalQA.from_chain_type(
llm=LangChain.get_llm("gpt-4"),
chain_type="stuff",
retriever=vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 5, "fetch_k": 10}
),
return_source_documents=True
)
# Step 5: 执行查询
def query_with_sources(question: str):
result = qa_chain({"query": question})
return {
"answer": result["result"],
"sources": [doc.metadata["source"] for doc in result["source_documents"]]
}
# 使用示例
response = query_with_sources("什么是OpenClaw的核心架构?")
print(f"回答:{response['answer']}")
print(f"来源:{response['sources']}")适用场景分析
| 场景 | 适用度 | 理由 |
|---|---|---|
| RAG问答系统 | ⭐⭐⭐⭐⭐ | RAG是LangChain的强项 |
| 多步骤工作流 | ⭐⭐⭐⭐ | Chain机制灵活 |
| 工具调用类Agent | ⭐⭐⭐⭐ | Tool接口标准化 |
| 快速原型验证 | ⭐⭐⭐⭐ | 组件丰富,组装灵活 |
| 需要桌面控制 | ⭐ | 没有本地执行能力 |
| 复杂多Agent协作 | ⭐⭐ | 需要LangGraph补充 |
| 追求极简开发 | ⭐⭐ | 组装成本较高 |
3.3 AutoGen:微软的多Agent协作标准
一句话定位: 让多个Agent像团队一样协作。
架构深度解析
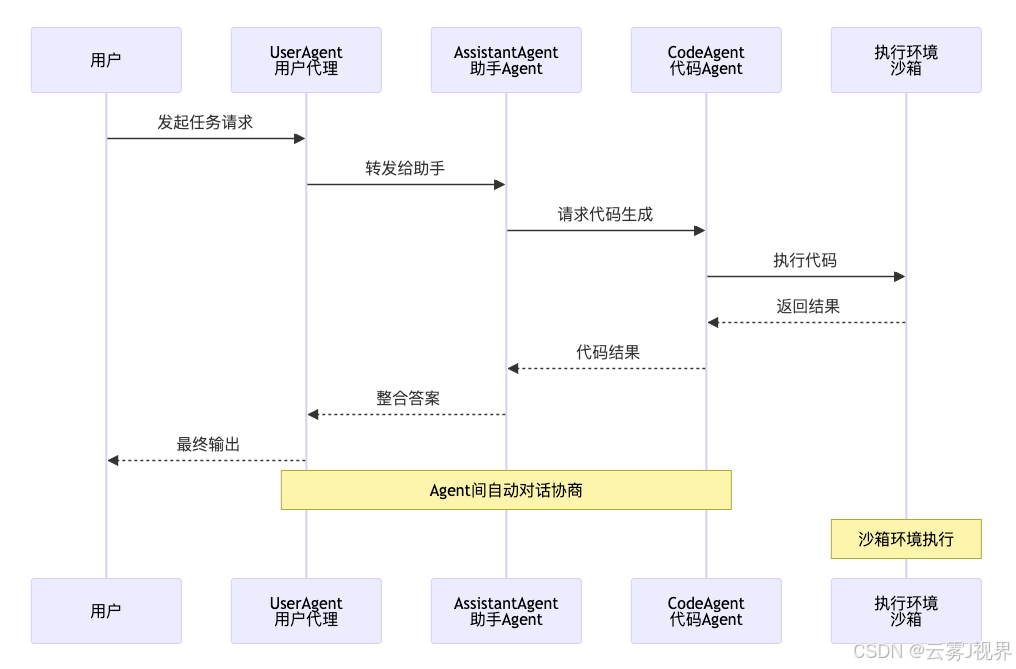
核心特性对比
| 特性 | 说明 | 技术实现 |
|---|---|---|
| 多Agent对话 | Agent间自动协商、分工、协作 | 对话协议 + 角色定义 |
| 角色定义 | 每个Agent有明确的角色和能力 | Agent基类 + 配置文件 |
| 代码执行 | 内置沙箱环境执行生成代码 | Docker容器隔离 |
| 人机协作 | 支持人类介入对话流程 | HumanInput模式 |
| 微软生态 | 与Azure、Teams等深度集成 | Azure OpenAI + Teams Bot |
实战代码示例:多Agent协作系统
python
# AutoGen多Agent协作示例:代码审查系统
import autogen
from autogen import AssistantAgent, UserProxyAgent, GroupChat
# 配置LLM
config_list = [
{
"model": "gpt-4",
"api_key": "your-api-key"
}
]
# 定义Agent角色
code_reviewer = AssistantAgent(
name="CodeReviewer",
system_message="""你是一位资深代码审查专家。
你的职责是:
1. 检查代码质量(可读性、可维护性、性能)
2. 发现潜在bug和安全漏洞
3. 提出改进建议
请以专业、客观的态度进行审查。""",
llm_config={"config_list": config_list}
)
security_expert = AssistantAgent(
name="SecurityExpert",
system_message="""你是一位安全专家。
你的职责是:
1. 检查SQL注入、XSS等常见漏洞
2. 验证输入验证和数据清洗
3. 检查权限控制和敏感数据处理
请从安全角度提出建议。""",
llm_config={"config_list": config_list}
)
performance_expert = AssistantAgent(
name="PerformanceExpert",
system_message="""你是一位性能优化专家。
你的职责是:
1. 分析算法复杂度
2. 检查内存泄漏风险
3. 提出性能优化建议
请从性能角度提出建议。""",
llm_config={"config_list": config_list}
)
user_proxy = UserProxyAgent(
name="User",
human_input_mode="NEVER",
max_consecutive_auto_reply=10,
code_execution_config={"work_dir": "coding"}
)
# 创建群聊
groupchat = GroupChat(
agents=[user_proxy, code_reviewer, security_expert, performance_expert],
messages=[],
max_round=20
)
manager = autogen.GroupChatManager(
groupchat=groupchat,
llm_config={"config_list": config_list}
)
# 执行代码审查
code_to_review = '''
def process_user_input(user_input):
query = f"SELECT * FROM users WHERE name = '{user_input}'"
result = db.execute(query)
return result
'''
user_proxy.initiate_chat(
manager,
message=f"请审查以下代码:\n```python\n{code_to_review}\n```"
)适用场景分析
| 场景 | 适用度 | 理由 |
|---|---|---|
| 复杂任务分解 | ⭐⭐⭐⭐⭐ | 多Agent对话是核心能力 |
| 代码生成与验证 | ⭐⭐⭐⭐⭐ | 生成→执行→反馈闭环 |
| 研究型Agent | ⭐⭐⭐⭐⭐ | 对话式探索、方案迭代 |
| 微软生态集成 | ⭐⭐⭐⭐⭐ | Azure、Teams深度集成 |
| 单Agent简单任务 | ⭐ | 协作机制过剩 |
| 桌面本地控制 | ⭐ | 设计为云端为主 |
| 需要确定性流程 | ⭐⭐ | 对话模式不可控性高 |
四、选型决策矩阵:如何做选择?
4.1 四维度评估框架
基于微软Azure团队的真实实践,我们提炼出Agent框架选型的四维度评估框架:
| 维度 | 说明 | 权重 | 评估方法 |
|---|---|---|---|
| 场景匹配度 | 你的需求是否在框架的核心场景内 | 40% | 对照框架核心场景清单 |
| 上手成本 | 学习曲线、文档质量、社区活跃度 | 25% | 官方文档评分 + GitHub Issue响应时间 |
| 扩展能力 | 未来需求变化时的适配空间 | 20% | 插件生态 + 自定义能力 |
| 生态成熟度 | 组件丰富度、稳定性、长期维护 | 15% | Star数 + Release频率 + 贡献者数 |
4.2 典型场景选型建议
| 你的需求 | 推荐框架 | 理由 | 备选方案 |
|---|---|---|---|
| 自动化桌面操作 | OpenClaw | 桌面控制是其核心定位 | Agent-S(更轻量) |
| RAG问答系统 | LangChain + Haystack | RAG是LangChain的强项 | Haystack(专注RAG) |
| 多Agent协作研究 | AutoGen | 多Agent对话是AutoGen的本质 | CrewAI(角色分工更清晰) |
| 软件自动开发 | MetaGPT | 专为软件开发流程设计 | AutoGen + 代码Agent |
| 团队角色协作 | CrewAI | 角色扮演+任务分配模式 | AutoGen(更通用) |
| 低代码快速上手 | PraisonAI | 低代码,门槛最低 | OpenAI Agents SDK(官方支持) |
| 官方背书追求 | OpenAI Agents SDK | OpenAI官方工具 | LangChain(生态更成熟) |
4.3 选型决策流程图
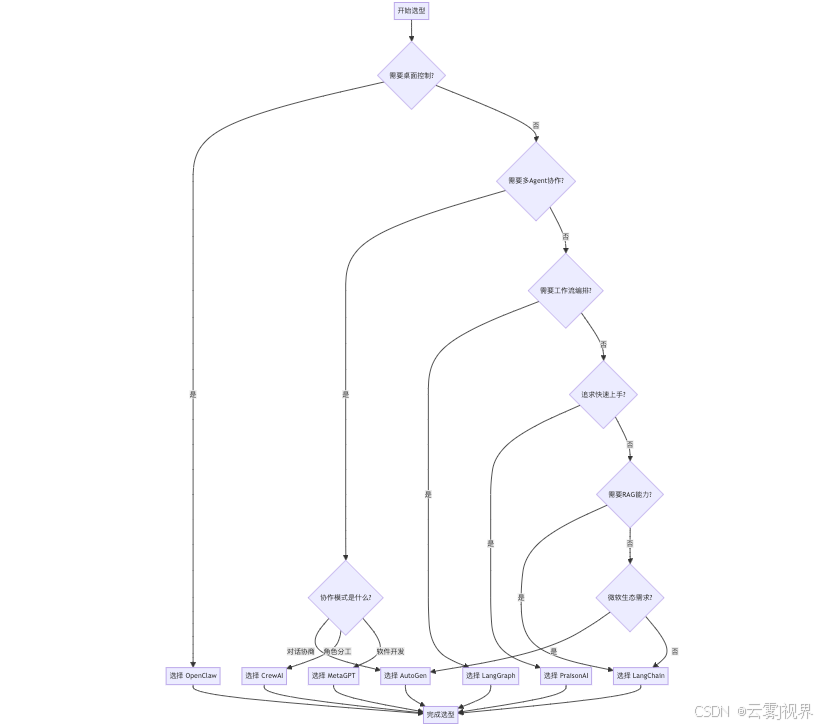
五、企业级实战案例
案例1:某硬件公司的自动化测试Agent系统
背景与挑战
某头部硬件公司测试团队面临困境:
- 每次新产品发布前,需要人工执行300+项测试用例
- 测试报告生成耗时8小时,且格式不统一
- 测试数据分散在多个系统中,难以追溯
选型决策
经过四维度评估:
- 场景匹配度:OpenClaw得分9/10(桌面控制+浏览器自动化)
- 上手成本:OpenClaw得分7/10(文档较新,但社区活跃)
- 扩展能力:OpenClaw得分8/10(Skill系统灵活)
- 生态成熟度:OpenClaw得分6/10(相对较新)
最终选择:OpenClaw
实施成果
python
# 自动化测试Skill配置
skills:
- name: hardware_test_runner
description: 自动执行硬件测试用例
tools:
- exec # 执行测试命令
- browser # 操作测试管理平台
- filesystem # 读取/写入测试报告
workflow:
- step: pull_test_cases
tool: browser
action: 登录测试平台,拉取待执行用例
- step: execute_tests
tool: exec
action: 逐个执行测试命令
- step: collect_results
tool: filesystem
action: 汇总测试结果到报告
- step: notify_team
tool: feishu
action: 发送测试报告到飞书群量化效果:
- 测试执行时间:从8小时缩短至45分钟
- 测试报告生成:全自动,格式统一
- 问题追溯:数据集中存储,可追溯
案例2:某互联网公司的智能客服Agent系统
背景与挑战
某互联网公司客服团队面临困境:
- 日均咨询量10万+,人工客服响应慢
- 知识库更新滞后,客服回答不一致
- 客服培训周期长,新人上手慢
选型决策
经过四维度评估:
- 场景匹配度:LangChain得分9/10(RAG能力强)
- 上手成本:LangChain得分6/10(学习曲线陡峭)
- 扩展能力:LangChain得分9/10(生态丰富)
- 生态成熟度:LangChain得分9/10(Star超10万)
最终选择:LangChain + Haystack
实施成果
python
# 智能客服RAG系统架构
class CustomerServiceRAG:
def __init__(self, knowledge_base_path):
self.vectorstore = Chroma(
persist_directory=knowledge_base_path,
embedding_function=OpenAIEmbeddings()
)
self.llm = ChatOpenAI(model="gpt-4")
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 3}
)
)
def answer(self, question, user_context=None):
# 构建完整上下文
full_context = f"用户信息:{user_context}\n问题:{question}" if user_context else question
# 执行RAG查询
result = self.qa_chain({"query": full_context})
return {
"answer": result["result"],
"confidence": self._calculate_confidence(result),
"sources": [doc.metadata for doc in result.get("source_documents", [])]
}
def _calculate_confidence(self, result):
# 基于检索相关性计算置信度
pass量化效果:
- 首次响应时间:从5分钟缩短至10秒
- 问题解决率:从65%提升至85%
- 客服培训周期:从2周缩短至3天
六、2026年趋势展望
6.1 Agent框架的演进方向
| 趋势 | 说明 | 代表框架 |
|---|---|---|
| 桌面化 | Agent从云端走向本地,直接操作用户设备 | OpenClaw, Agent-S |
| 多模态 | 文本→图像→语音→视频,输入输出全面扩展 | VisionClaw, GPT-4V |
| 低代码化 | 降低开发门槛,非程序员也能搭建Agent | PraisonAI, OpenAI Agents SDK |
| 标准化 | Tool协议、Agent通信协议趋于统一 | Model Context Protocol |
| 商业化 | 从开源玩具到企业级生产力工具 | LangSmith, Azure AI |
6.2 框架生存预测(2027年)
| 框架 | 预测地位 | 理由 |
|---|---|---|
| OpenClaw | 桌面Agent领域领先者 | 先发优势 + 专注定位 |
| LangChain | AI应用基础设施地位稳固 | 生态壁垒 + 企业采用 |
| AutoGen | 多Agent协作标杆 | 微软背书 + 学术影响力 |
| OpenAI Agents SDK | 快速追赶者 | 官方流量入口 |
| CrewAI | 中小团队协作场景有差异化价值 | 角色扮演模式独特 |
| MetaGPT | 软件开发场景有独特定位 | 但受众有限 |
七、结论:选型的本质
框架选型的本质不是"哪个更好",而是"哪个更适合你的场景"。
核心决策逻辑:
- 先定义需求:你要解决什么问题?
- 匹配场景:哪个框架的核心场景覆盖你的需求?
- 评估成本:你的团队能承受多大的学习曲线?
- 考虑扩展:未来需求变化时框架能否适配?
- 检查生态:社区活跃度、文档质量、长期维护?
记住一个原则:不要为了用框架而用框架。
简单任务直接用API,复杂任务才需要框架。框架的价值是降低复杂度,不是增加复杂度。
附录:快速参考卡片
| 框架 | GitHub Star | 核心场景 | 上手难度 | 推荐指数 |
|---|---|---|---|---|
| OpenClaw | 10,000+ | 桌面控制 | 中 | ⭐⭐⭐⭐ |
| LangChain | 100,000+ | AI应用开发 | 中高 | ⭐⭐⭐⭐⭐ |
| AutoGen | 35,000+ | 多Agent协作 | 中 | ⭐⭐⭐⭐ |
| CrewAI | 30,000+ | 团队角色协作 | 低 | ⭐⭐⭐⭐ |
| MetaGPT | 45,000+ | 软件开发 | 中高 | ⭐⭐⭐ |
| LangGraph | 10,000+ | 有状态工作流 | 中高 | ⭐⭐⭐⭐ |
| PraisonAI | 10,000+ | 低代码多Agent | 低 | ⭐⭐⭐ |
| OpenAI Agents SDK | 官方 | 官方Agent工具 | 低 | ⭐⭐⭐⭐ |
一句话总结:
- 要操作电脑 → OpenClaw
- 要多Agent协作 → AutoGen
- 要通用AI开发 → LangChain
- 要快速上手 → PraisonAI
- 要官方背书 → OpenAI Agents SDK
选对框架,事半功倍。选错框架,步步踩坑。