什么是React模式?
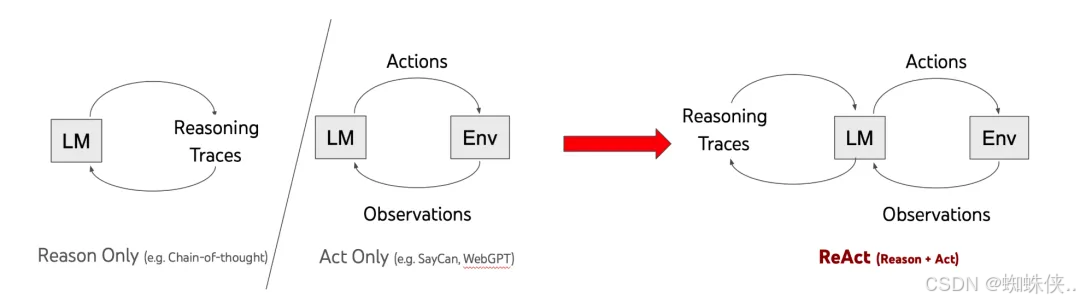
ReAct(Reasoning + Acting)是当前 AI Agent 理论中最具基础性和代表性的范式
1、ReAct-LLM
通俗理解:
让 AI 在整体目标的指引下"走一步看一步"。它打破了一次性规划全部流程的局限,通过动态的交替循环边思考边验证。例如在排查线上服务变慢的故障时(后文会举例详细介绍),AI 不会死板地执行预设脚本,而是先查询监控指标,观察到 CPU 飙升及慢 SQL 告警后,再动态决定去深挖数据库日志定位全表扫描问题,最后基于真实的排查结果通知负责人。这种顺藤摸瓜的过程,生成了更可靠、可追踪且能动态纠错的任务解决轨迹。
2、运作流程:
这是一个基于反馈闭环的交替过程,主要包含以下三个核心步骤(Reasoning -> Acting -> Observation),循环往复直至任务完成或触发终止条件:
-
思考(Reasoning):LLM 分析当前上下文,生成内部推理过程,决定采取何种行动。这类似于 CoT 提示,但更注重行动导向。例如,模型可能会输出:"任务是查找最新天气。我需要调用天气 API,因为我的知识截止于训练数据。"
-
行动(Acting):根据推理结果,与外部环境交互,如调用 API 或搜索网络。这可以通过工具调用实现,例如执行"search_web(query='当前北京天气')"或"call_api(endpoint='/weather')"。
-
观察(Observation):获取外部环境对行动的反馈结果,作为新输入传递给 LLM,触发新一轮思考。例如,如果行动返回"北京天气:晴,25°C",模型会观察此信息,并推理下一步(如"基于天气,建议穿短袖")。
3、优缺点分析:
-
优势:显著减少幻觉(引入外部真实数据验证)、提升复杂任务的成功率、具备极高的可解释性与可调试性(完整的推理轨迹清晰可见)。
-
局限性:多轮循环迭代会导致系统整体响应延迟增加,同时其表现高度依赖所集成的外部工具和 Skills 的质量与稳定性。
ReAct 是怎么实现的?
1、ReAct 的落地实现主要依赖以下五个核心组件协同工作:
-
历史上下文(History):Agent 维护一个统一的交互日志,涵盖以往的推理步骤、执行动作以及反馈观察。这为 LLM 提供了即时"记忆"机制,确保决策时能回顾先前事件,从而规避冗余步骤或无限循环风险。
-
实时环境输入( Real-time Environment Input ):包括 Agent 当前捕获的外部变量,如系统警报信号或用户即时反馈。这些补充数据融入上下文,帮助 LLM 准确评估现状并调整策略。
-
模型推理模块( LLM Reasoning Module):作为 ReAct 的核心引擎,处理逻辑分析与规划。每次迭代中,LLM 整合历史记录、环境输入及任务目标,输出行动方案。
-
执行工具集与技能库(Tools & Skills):充当 Agent 的操作接口,与外部实体互动。其中原子工具(Tools)处理单一操作(如数据库查询、邮件发送);技能(Skills)则是对多个相关工具的编排封装,提供面向特定业务场景的可复用能力模块(如"故障诊断技能"、"竞品分析技能")。两者共同构成 Agent 的行动能力边界。
-
反馈观察机制(Feedback Observation):行动完成后,从环境中采集的实际响应,包括成功输出、错误提示或无结果状态。这一信息将被追加至历史上下文中,成为后续推理的可靠基础。
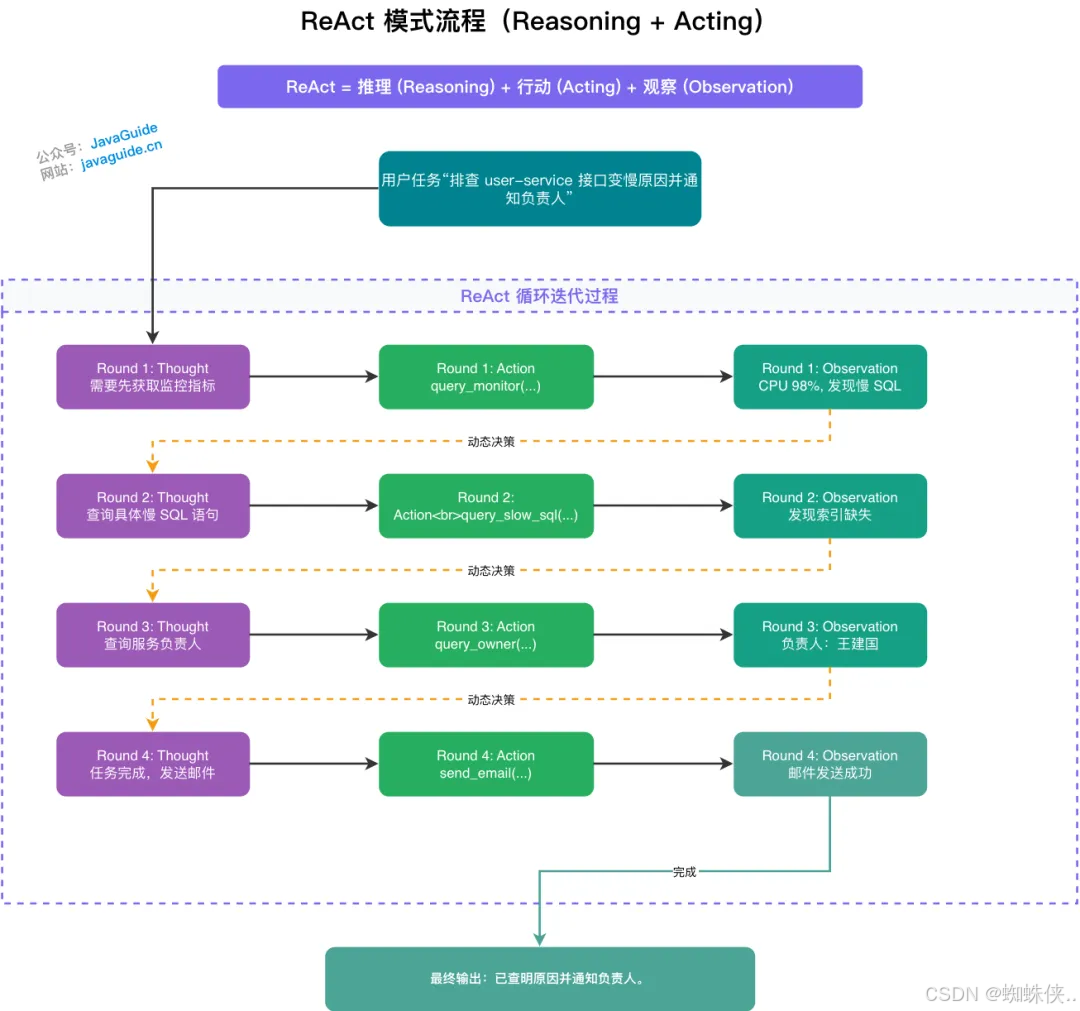
2、这里以上面提到的例子来展示一下执行流程(采用逐轮叙述形式,便于追踪动态变化):
3、ReAct 模式流程
Round 1
-
历史上下文:空
-
实时环境输入:空
-
核心 Prompt:
已知:当前历史上下文:{历史上下文} 实时环境输入:{实时环境输入} 用户目标:"排查 user-service 变慢原因并通知负责人" 请做出下一步的决策,你必须最少使用一个工具来实现该决策。 -
执行工具:
query_monitor查询 user-service 早上的监控指标 -
观察结果:CPU 飙升至 98%,伴随大量慢 SQL 告警。
Round 2
-
历史上下文:已获取监控指标(CPU 飙升,有慢 SQL)
-
执行工具:
query_slow_sql查询慢 SQL 日志 -
观察结果:发现语句未命中索引,导致全表扫描。
Round 3
-
历史上下文:监控指标 + 日志结论(全表扫描)
-
执行工具:
query_owner查询 user-service 负责人 -
观察结果:负责人为王建国,邮箱
wangjianguo@company.com。
Round 4
-
历史上下文:监控指标 + 日志结论 + 负责人信息
-
执行工具:
send_email向负责人发送排查报告 -
观察结果:邮件发送成功。
4、从底层来看,驱动 Agent Loop 运转的核心是一套动态组装的 Prompt:
已知: 当前历史上下文:&{历史上下文} 实时环境输入:&{实时环境输入} 用户目标:"排查 user-service 变慢原因并通知负责人" 请做出下一步的决策: (你可以选择调用工具或 Skill,或者在任务完成时直接输出最终结果)
最终输出:"已查明 user-service 接口变慢原因是由于慢 SQL 未命中索引导致全表扫描,已向负责人王建国发送了详细排查邮件。"
项目中如何实际体现React?(例)
任务: "帮我排查一下今天早上 user-service 接口变慢的原因,并把排查结果发给该服务的负责人。"
用 ReAct 的方式,AI 会经历如下动态博弈的过程:
-
思考 (Thought): 用户要求排查接口变慢,我需要先获取
user-service今天早上的监控指标或告警信息。 -
行动 (Action): 调用监控查询工具
query_monitor(service="user-service", time="morning") -
观察 (Observation): 返回数据表明,9:00-9:30 期间 CPU 利用率飙升至 98%,同时伴随大量慢 SQL 告警。
-
思考 (Thought): 既然有慢 SQL 告警,说明数据库查询可能存在瓶颈。我需要去日志系统查询具体的慢 SQL 语句是什么。(注意:这一步是动态决定的,如果上一步发现是 内存 OOM ,现在的行动就会变成查 Heap Dump)
-
行动 (Action): 调用日志查询工具
query_slow_sql(service="user-service", time="09:00-09:30") -
观察 (Observation): 获取到慢 SQL:
SELECT * FROM users WHERE age > 20 ORDER BY created_at DESC,并发现该查询没有命中索引,导致全表扫描。 -
思考 (Thought): 根本原因已经找到(全表扫描导致 CPU 飙升)。接下来我需要找到
user-service的负责人是谁,以便发送报告。 -
行动 (Action): 调用企业通讯录工具
query_service_owner(service="user-service") -
观察 (Observation): 查出负责人是"王建国",邮箱是
wangjianguo@company.com。 -
思考 (Thought): 我现在收集齐了故障原因和联系人信息,可以组织排查报告并发送邮件了。
-
行动 (Action): 调用邮件发送工具
send_email(to="``wangjianguo@company.com``", subject="user-service 故障排查", body="发现由于缺少索引导致慢查询...") -
观察 (Observation): 返回结果:邮件发送成功。
-
思考 (Thought): 任务已全部闭环完成,可以向用户输出最终答复了。
-
行动 (Action): 结束循环,用自然语言回复用户:"已查明原因是缺少索引导致的慢 SQL,并已向负责人王建国发送了邮件。"
如果采用非 ReAct 的模式(比如让 AI 一开始就写好计划),AI 可能会死板地执行"查日志 -> 找人 -> 发邮件"。但如果故障原因不在日志里,而在网络配置里,静态计划就会彻底崩溃。
在这个例子中,第 4 步的决定完全依赖于第 3 步的观察结果。ReAct 让 Agent 拥有了像人类工程师一样顺藤摸瓜、根据证据修正排查方向的能力。这是单纯的链式调用(Chain)无法做到的。
💡 延伸思考 :在更成熟的 Agent 系统中,上述步骤 2、5 中对监控和日志的联合查询,可以被封装为一个名为 diagnose_service_performance 的 Skill------它内部自动编排"查监控 + 查慢 SQL + 分析瓶颈"三个工具的调用序列,并返回一份结构化的诊断摘要。Agent 在推理时只需调用这一个 Skill,而不必每次都拆解成多个独立步骤,既降低了上下文占用,也提升了在同类故障场景下的复用效率。这正是 Skills 作为 Tools 高阶封装形态的核心价值所在。