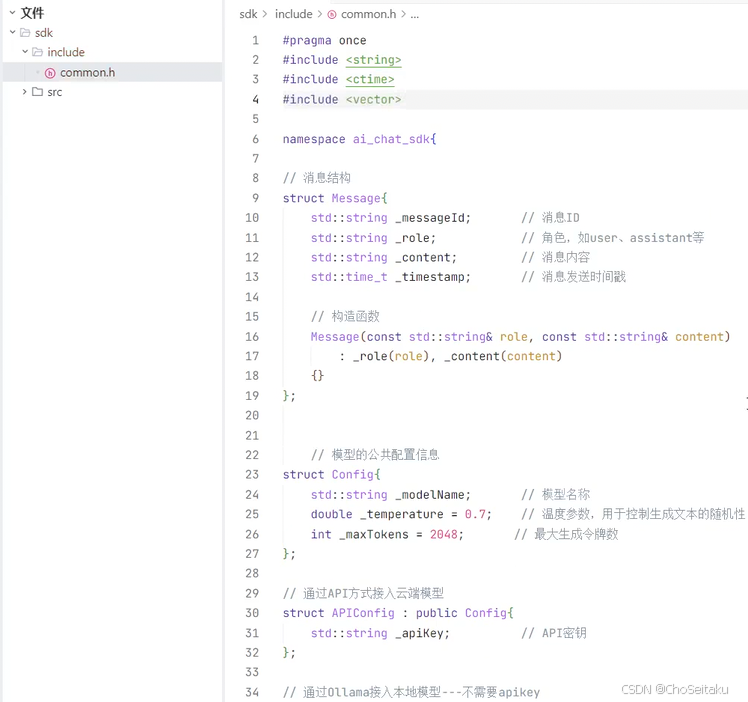
数据结构设计
虽然各个模型不同,但有⼀些公共的配置和描述信息,⽐如:
通过api调⽤模型时需要模型名称、温度值、最⼤tokens数、api key等;
在和模型聊天时,聊天信息需要管理;
每次开启和模型的新⼀轮对话,都是⼀次新的会话,将来可能需要实现会话管理。
这些数据在多个⽂件中都会⽤到,因此提前先将这些数据结构定义好,以⽅便后续使⽤

spdlog封装
C++中可以通过cout将信息打印到控制台,为什么还要封装⽇志库呢?
封装⽇志库有诸多优势:
- ⽇志级别管理
⽇志库通常⽀持多种⽇志级别(如TRACE、DEBUG、INFO、WARN、ERROR、FATAL等)。开发者可以根据需要设置不同的⽇志级别,以便在开发、测试和⽣产环境中灵活控制⽇志输出。
在开发阶段,可以将⽇志级别设置为DEBUG,输出详细的调试信息;在⽣产环境中,将⽇志级别设置为ERROR或WARNING,只记录关键的错误和警告信息,避免⽇志⽂件过⼤。
std::cout 没有内置的⽇志级别管理功能,所有输出都会被打印到控制台,⽆法根据上下⽂灵活控制输出内容。 - ⽇志格式化
⽇志库可以提供灵活的⽇志格式化功能,包括时间戳、⽇志级别、线程信息、⽂件名、⾏号等。如std::cout 输出的内容格式单⼀,没有内置的格式化功能,需要⼿动添加时间戳、⽂件名等信息,代码繁琐且容易出错。 - ⽇志存储管理
⽇志库可以将⽇志信息输出到多种⽬标,如控制台、⽂件、远程服务器等。同时,⽇志库通常⽀持⽇志⽂件的轮转、压缩和归档,⽅便⻓期存储和管理。
⽐如设置⽇志⽂件每天⾃动轮转,并在⽂件⼤⼩超过⼀定阈值时进⾏压缩归档。这有助于避免⽇志⽂件过⼤导致磁盘空间不⾜。
⽽ std::cout 只能将信息输出到控制台,⽆法直接⽀持⽇志⽂件的存储和管理功能。 - 线程安全
在多线程程序中,⽇志库通常提供了线程安全的机制,确保⽇志输出不会出现冲突或数据错乱。在多线程环境下,多个线程可能同时尝试写⼊⽇志。⽇志库通过锁或其他同步机制确保⽇志输出的线程安全。
std::cout 在多线程环境下可能会出现⽇志输出混乱的问题,需要开发者⼿动实现线程安全机制。 - 性能优势
⽇志库通常会进⾏性能优化,例如通过异步写⼊⽇志、缓冲机制等,减少⽇志输出对程序性能的影响。
std::cout 是同步操作,每次输出都会阻塞当前线程,可能对程序性能产⽣较⼤影响。
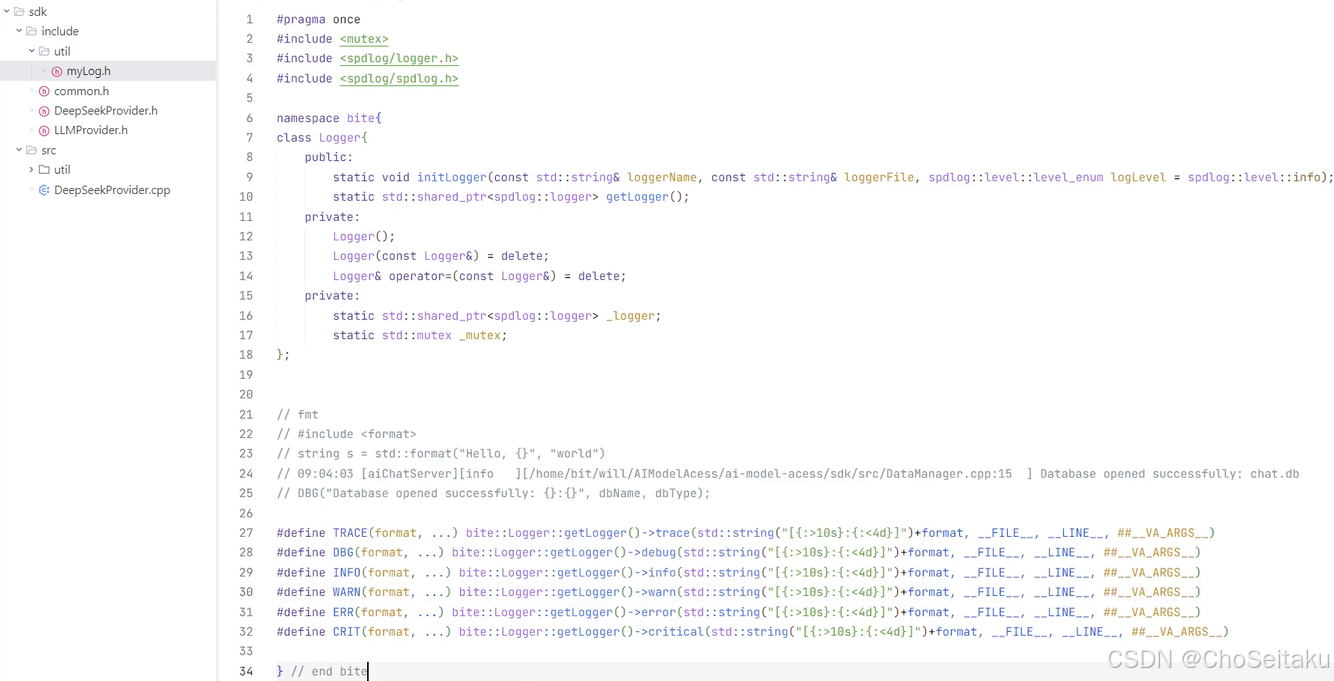
因此,本项⽬采⽤google的spdlog⽇志库进⾏⽇志管理,为了使⽤⽅便,对spdlog库采⽤单例模式进⾏简单封装。
日志定义 :
程序在运行过程中,需要将一些重要的信息记录下来,方便开发者、测试人员、运维人员了解程序运行时发生了什么事情。通常会将日志信息写入到控制台、文件、远程服务器中...
日志级别及说明:
- TRACE:最详细的跟踪信息,用于追踪程序执行流程。比如:函数进入和退出、变量的值、程序的执行路径
- DEBUG:调试信息,帮助开发人员理解程序运行的状态。比如:监控执行关键点、重要变量状态
- INFO:重要的运行信息,反应程序正常的状态。比如:系统启动成功、配置文件加载成功
- WARN:潜在的问题,但不影响程序的继续执行。比如:非关键性错误
- ERROR:程序运行出错,影响特定功能,但程序仍旧可以正常运行。比如:打开文件失败、数据库连接失败
- CRITICAL:严重错误,可能会导致系统崩溃,无法运行。比如:系统资源耗尽、数据损坏致命错误
日志级别优先级 :
TRACE < DEBUG < INFO < WARN < ERROR < CRITICAL
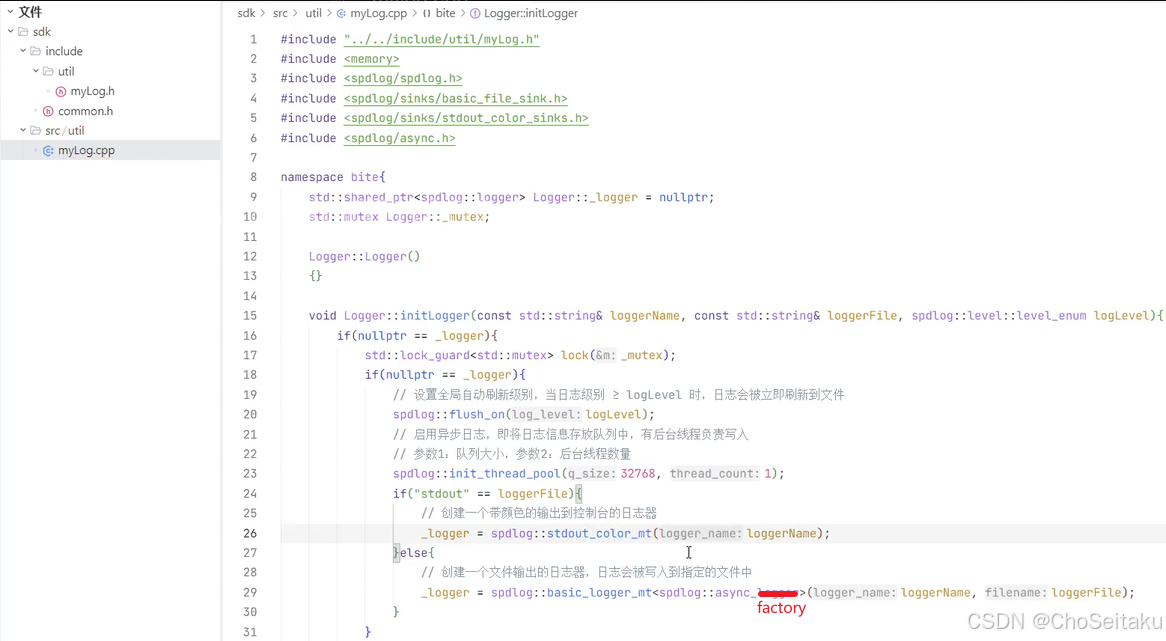
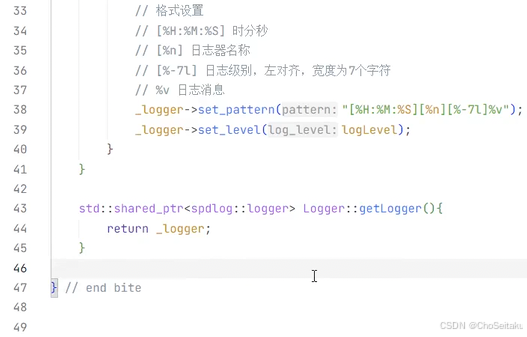
mylog.h
mylog.cpp
Provider实现
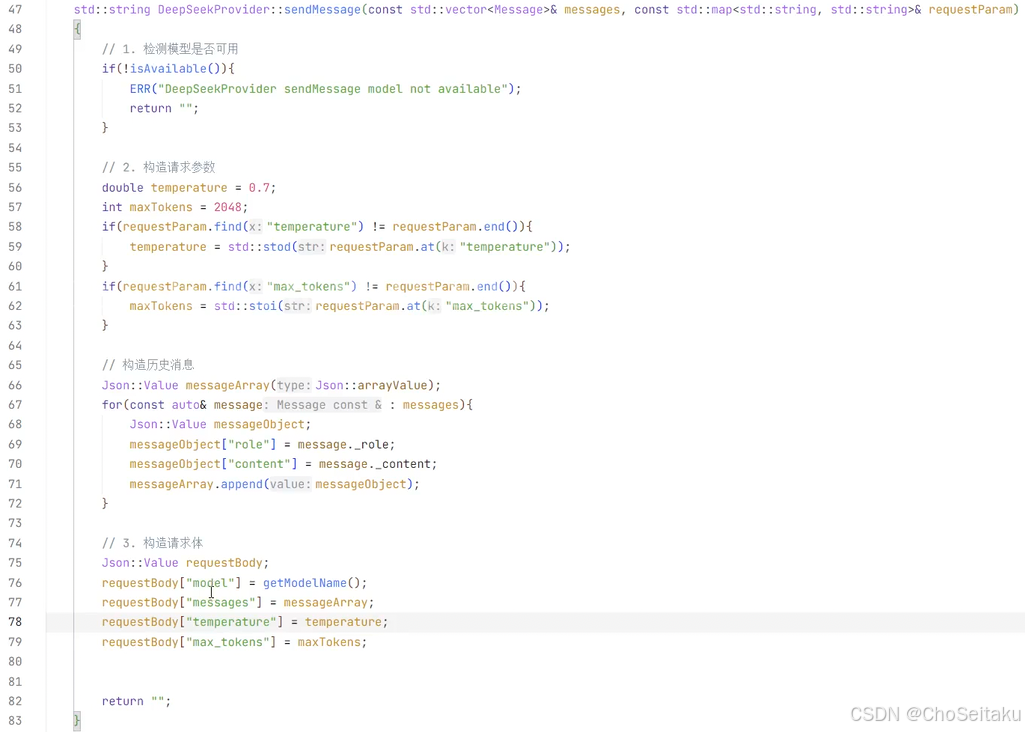
给模型发消息:
- 到官方去获取 api key; DONE
- 了解官方提供的给模型发消息的 API---deepseek
- 利用 API 给模型发消息
前面采用 apifox 工具给 deepseek-chat 模型发消息
现在需要在程序中自己写代码给模型发消息
策略模式
假设你现在要从宿舍去学校图书馆,但宿舍到图书馆之间有⼀段距离,你可以采⽤下属三⽅⽅式去:
- ⾛路(最节省钱,但慢)
- 骑⾃⾏⻋(中等速度,中等花销)
- 坐校内公交⻋(最快,但贵)
传统方式
c
if (今天没钱) {
⽤⾛路();
} else if (今天想省时间) {
⽤打⻋();
} else {
⽤⾃⾏⻋();
}策略方式
c
设置策略(打⻋)
执⾏策略()策略⽅式实现:
- 定义⼀个接⼝ TransportStrategy (出⾏策略)。
- 分别实现 WalkStrategy 、 BikeStrategy 、 TaxiStrategy 。
- 在运⾏时,你可以随时切换策略:
c
class TransportStrategy {
public:
virtual void go() = 0;
};
class WalkStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "⾛路去机房🚶"; }
};
class BikeStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "骑⻋去机房🚴"; }
};
class BusStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "打⻋去机房🚕"; }
};
class Student {
private:
TransportStrategy* strategy;
public:
void setStrategy(TransportStrategy* s) { strategy = s; }
void goToLab() { strategy->go(); }
};
int main(){
Student me;
me.setStrategy(new WalkStrategy());
me.goToLab(); // 输出: ⾛路去机房🚶
me.setStrategy(new BusStrategy());
me.goToLab(); // 输出: 打⻋去机房🚕
return 0;
}程序⾮常美观且灵活,在使⽤时只需和TransportStrategy打交道,不需要知道背后到底是WalkStrategy、BikeStrategy或BusStrategy。如果想更换模式,只需要更换⼀个具体的策略对象即可,程序基本不需要改动。
策略模式是设计模式的⼀种,它的核⼼思想是它定义了⼀些列算法,将每⼀个算法(或⾏为)封装起来,使它们可以相互替换,⽽不⽤再代码中写⼀堆if-else/switch来决定⽤哪个算法。即把"做事的⽅式"抽象出来,运⾏时根据需要选择哪种⽅式去执⾏。
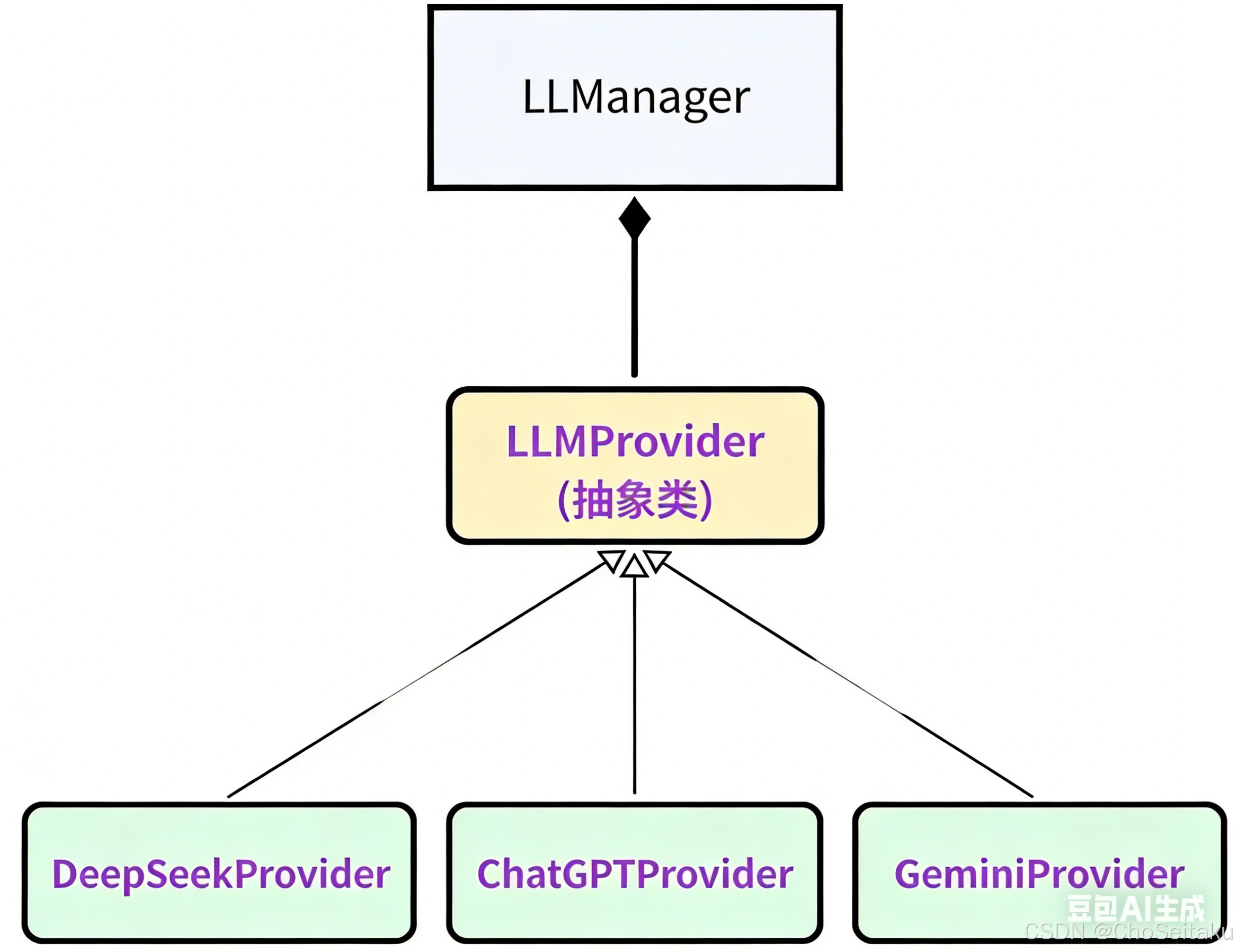
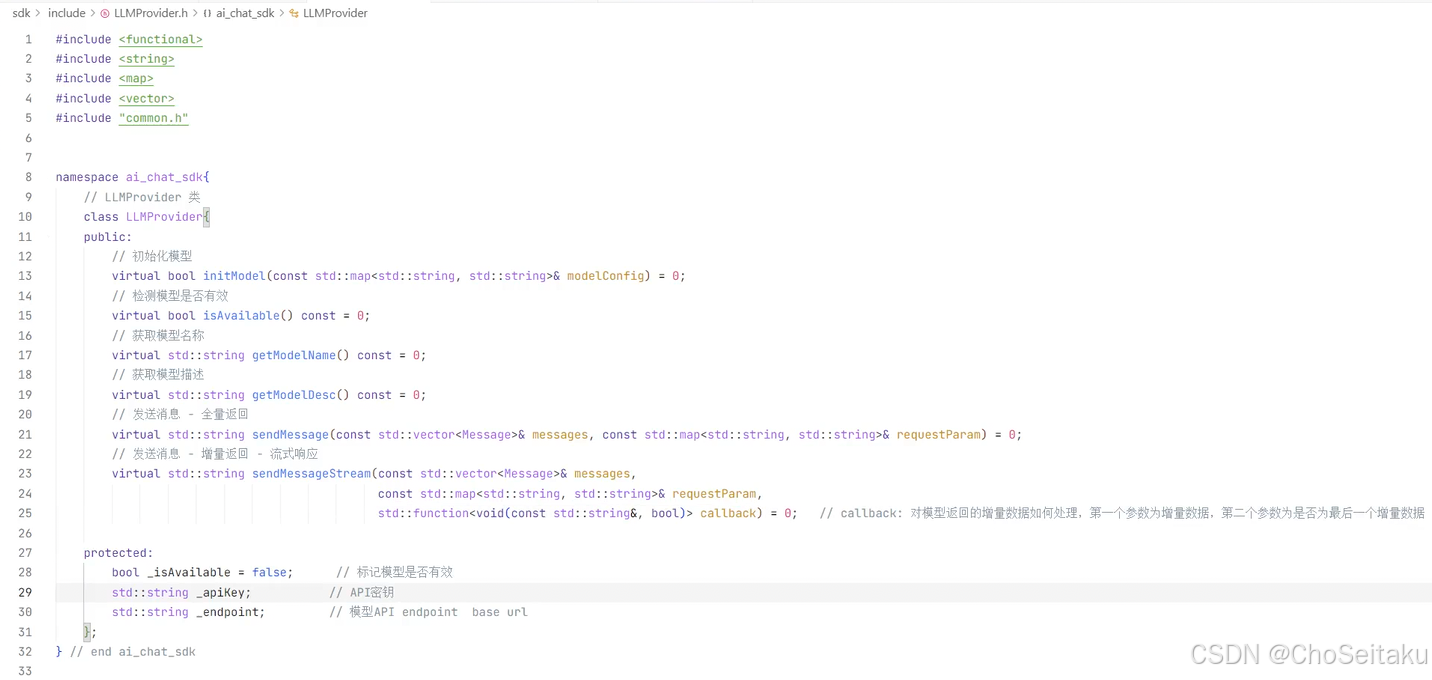
LLMProvider
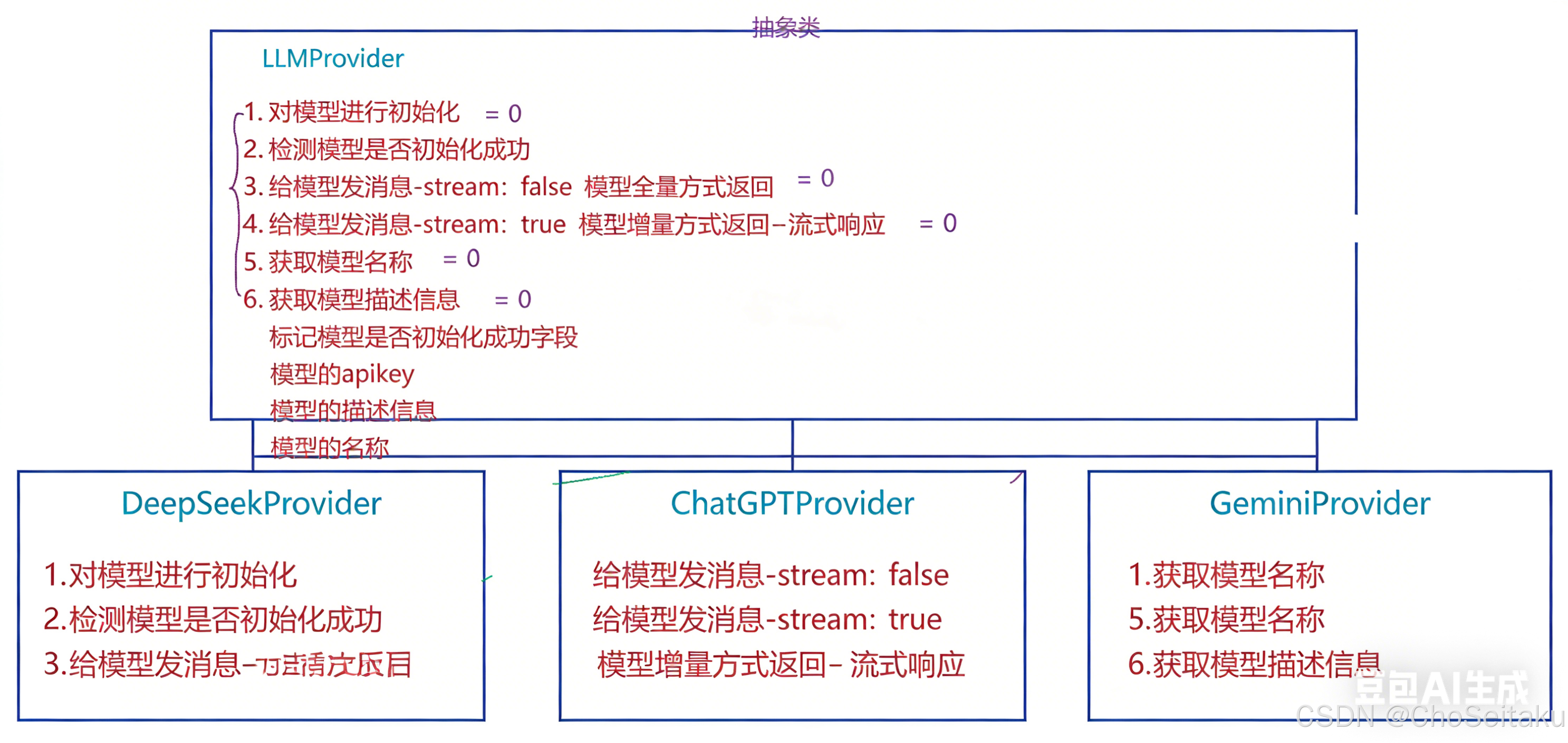
DeepSeekProvider、ChatGPTProvider、GeminiProvider 这三个类是实现与具体模型交互的类
而基类 LLMProvider 没有与任何模型建立关联,既然没有和任何模型建立关联,因此 LLMProvider 类就不应该实例化,
所以应该将 LLMProvider 设置成抽象类
后续会借助API的⽅式接⼊DeepSeek、ChatGPT、Gemini等⼤模型,每个⼤模型将来都需要:
a. 初始化
b. 检测模型是否有效
c. 发送消息给模型
d. 获取模型名称
e. 获取模型描述
f. 保存模型的有效状态、API Key、模型描述。
操作基本都是相同的,只是实现细节上稍微不同,因此借助策略模式将接⼊模块架构设计如下:
LLMProvider.h
DeepSeek接入封装
DeepSeek提供API
Base URL:https://api.deepseek.com
模型名称:deepseek-chat,实际指向DeepSeek-V3.1模型
DeepSeek的API兼容OPenAI,因此请求和响应参数基本与ChatGPT相同:
deepseek-chat模型的聊天补全接⼝设置如下:
请求URL POST /v1/chat/completions
请求头参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
| 请求体参数: |
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| model | string | 模型名称 |
| messages | array | 历史对话,内部为每个对话的 object,包含 role 和 content 两个字段 |
| temperature | string | 采样温度 |
| max_tokens | integer | 最大 tokens 数 |
| 【温度-temperature】 | ||
| 调整AI⽣成内容随机性的参数,温度值越⾼,AI回答越天⻢⾏空;温度越低,回答越保守靠谱。 | ||
| DeepSeek官⽹建议: |
| 温度 | 场景 |
|---|---|
| 0.0 | 代码生成 / 数学解题 |
| 1.0 | 数据抽取 / 分析 |
| 1.3 | 通用对话 |
| 1.3 | 翻译 |
| 1.5 | 创意类写作 / 诗歌创作 |
| 响应参数: |
c
{
"id":"8b1ca715-9270-429a-b40d-2a644f6e1d3f",
"object":"chat.completion",
"created":1754880537,
"model":"deepseek-chat",
"choices":[
{
"index":0,
"message":
{
"role":"assistant",
"content":"我是DeepSeek Chat,由深度求索公司(DeepSeek)开发的智能AI助⼿!✨ 我可以帮你解答问题、提供建议、整理信息,甚⾄陪你聊天。⽆论是学习、⼯作,还是⽇常⽣活中的⼩困惑,都可以来找我聊聊!😊 \n\n有什么我可以帮你的吗?"},
"logprobs":null,
"finish_reason":"stop"
}
],
"usage":{
"prompt_tokens":5,
"completion_tokens":63,
"total_tokens":68,
"prompt_tokens_details":{
"cached_tokens":0
},
"prompt_cache_hit_tokens":0,
"prompt_cache_miss_tokens":5
},
"system_fingerprint":"fp_8802369eaa_prod0623_fp8_kvcache"
}- ⽆状态服务原则:DeepSeek的API基于⽆状态设计,每次请求视为独⽴会话。若需维护对话连续性,必须由客⼾端主动管理并传递完整上下⽂。这与HTTP协议的⽆状态特性⼀致。
- 系统提⽰:若需保持⻆⾊设定,如始终以专家⾝份回答,每次请求必须包含系统级指令
- 对话历史:模型仅处理当前请求中的上下⽂,⽆法关联前序对话
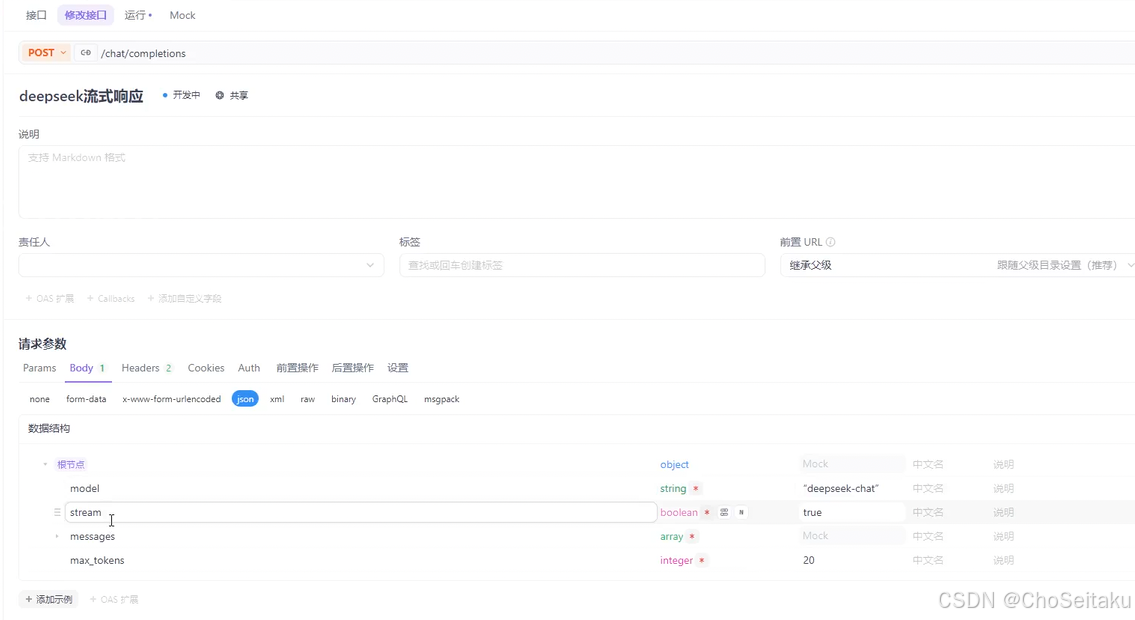
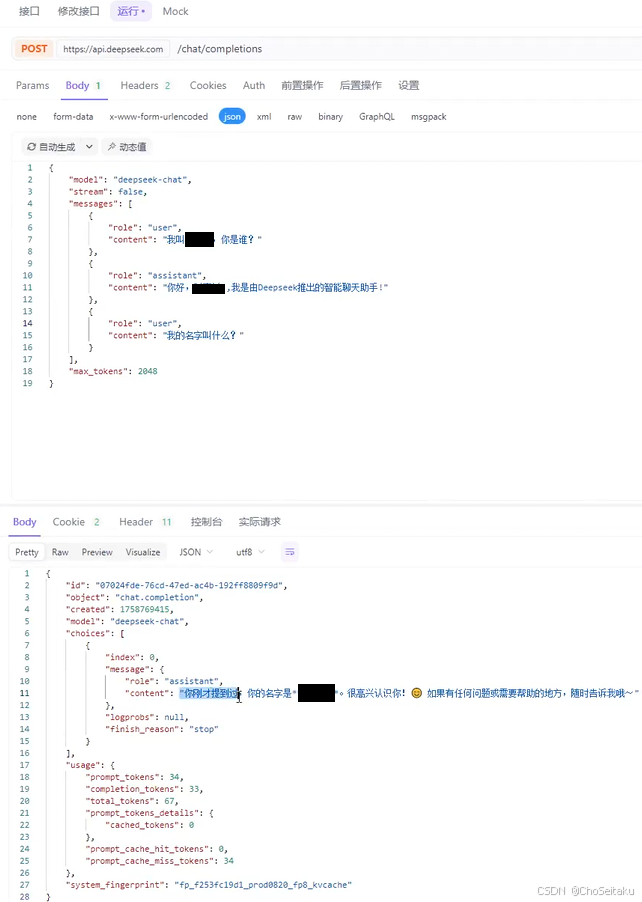
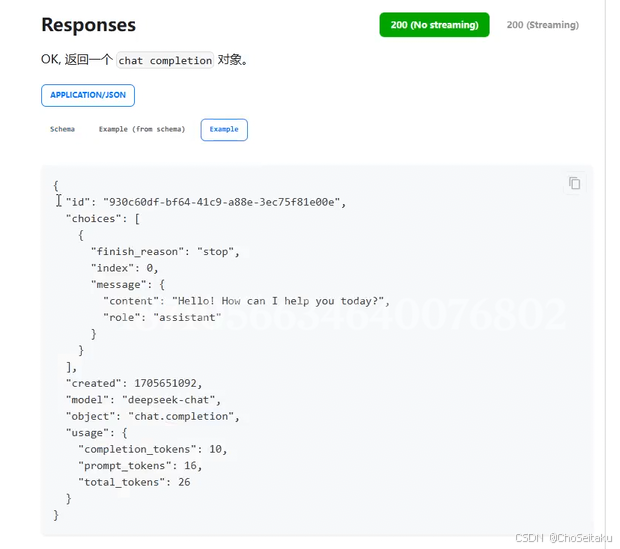
大模型初始化
在使⽤deepseek前,需要先配置好deepseek需要的⼀些参数信息,⽐如api-key、model、temperature、max_tokes等信息,否则⽆法正常使⽤deepseek的api。
DeepSeekProvider.h

DeepSeekProvider.cpp


发送消息-全量返回
在向⼤模型提问时,模型将回答⽂本⼀次性返回。
URL: /v1/chat/completions
参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| code | string | 是否成功 |
| msg | string | 结果描述 |
| data | double | 响应数据 |
| conversation_id | int | 会话 id |
| 响应格式: |
{
"id": "d41df5f7-046d-45a3-818c-512b990fff73",
"object": "chat.completion",
"created": 1756726494,
"model": "deepseek-chat",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "你的名字是你在注册时使⽤的称呼,或者你可以告诉我你希望我怎么称呼你?😊"
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 20,
"total_tokens": 29,
"prompt_tokens_details": {
"cached_tokens": 0
},
"prompt_cache_hit_tokens": 0,
"prompt_cache_miss_tokens": 9
},
"system_fingerprint": "fp_feb633d1f5_prod0820_fp8_kvcache"
}json 对象
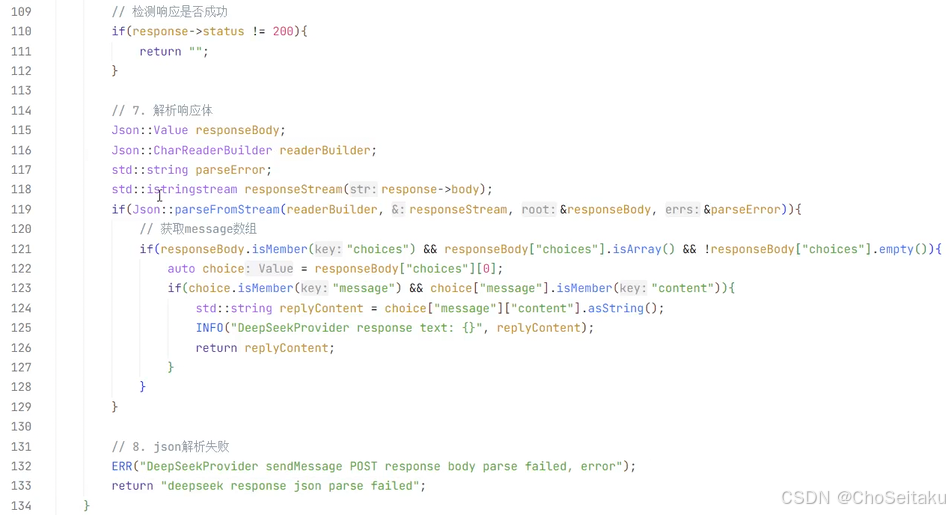
检测响应的 json 对象中是否包含 choices 字段
如果包含,再检测 choices 是否为数组
如果是数组,检测是否为空
取 choices 0 实际也是一个 json 对象 replyContent
top_p: 用于控制模型生成文本的随机性和多样性。
假设模型要生成下一词,候选词和他们的概率如下:
猫 0.3 狗 0.25 苹果 0.2 跑 0.15 的 0.1
假设:top_p = 0.8
- 将候选词按照概率进行降序排序:猫 0.3 狗 0.25 苹果 0.2 跑 0.15 的 0.1
- 从猫开始累积概率:猫 0.3 猫 0.3 + 狗 0.25=0.55 猫 0.3 + 狗 0.25 + 苹果 0.2=0.75 猫 0.3 + 狗 0.25 + 苹果 0.2 + 跑 0.15=0.9
- 概率池 {猫 狗 苹果} 0.75 < 0.8
- 模型会从 {猫 狗 苹果} 中选择下一个词
发送消息-全量返回测试
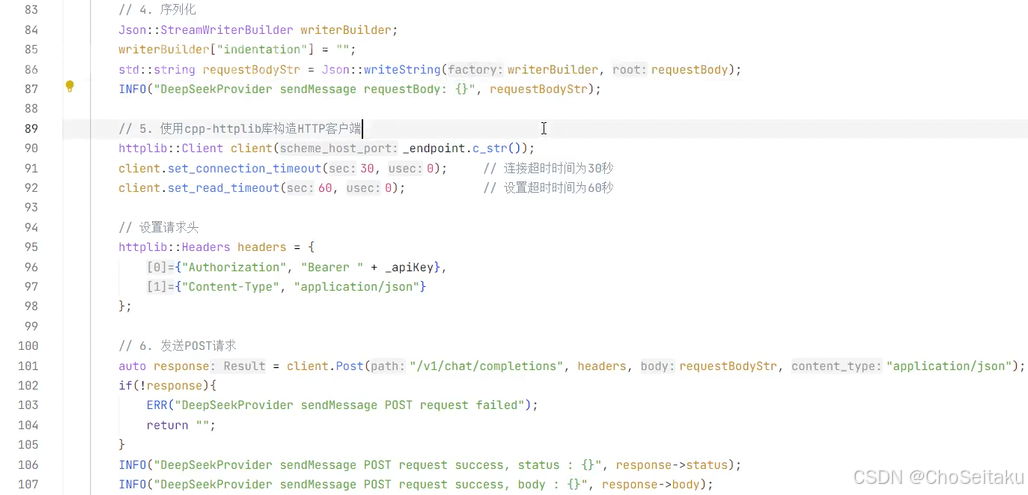
相对于 deepseek 的服务器来说,sdk 实际就是一个 http 客户端
发送消息的流程 (全量返回)
- 检测模型是否可用
- 构造请求参数:模型名称、消息列表、温度值、最大 token 数 ---json
- 对 json 对象进行序列化
- 创建 HTTP 客户端,设置请求头:content-type 认证方式
- 给模型发送请求,等待模型的回复
- 解析模型的响应结果 --- 反序列化:按照 deepseek 返回的 json 格式组织
- 返回模型发送的消息的内容
添加全局环境变量
- 打开bashrc文件
- 在文件中添加新的环境变量
- source使添加的环境变量生效
c
vim ~/.bashrc
# api key
export deepseek_apikey="你申请的deepseek的api key"
export chatgpt_apikey="你申请的chat gpt的api key"
export gemini_apikey="你申请的gemini的api key"
source ~/.bashrc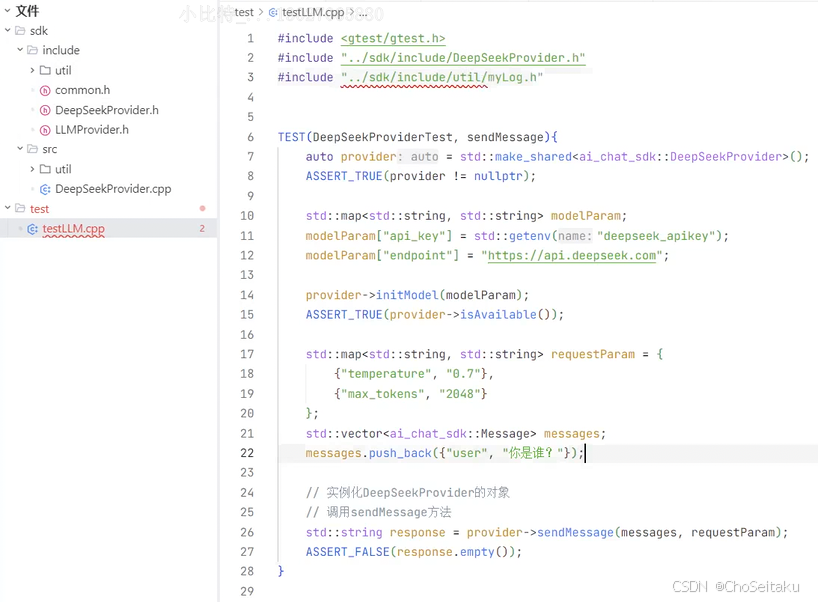
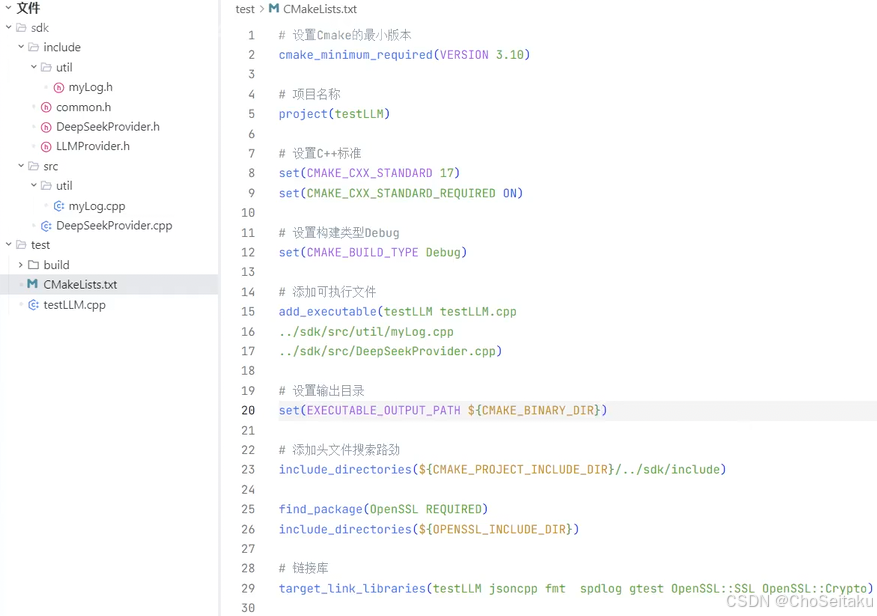


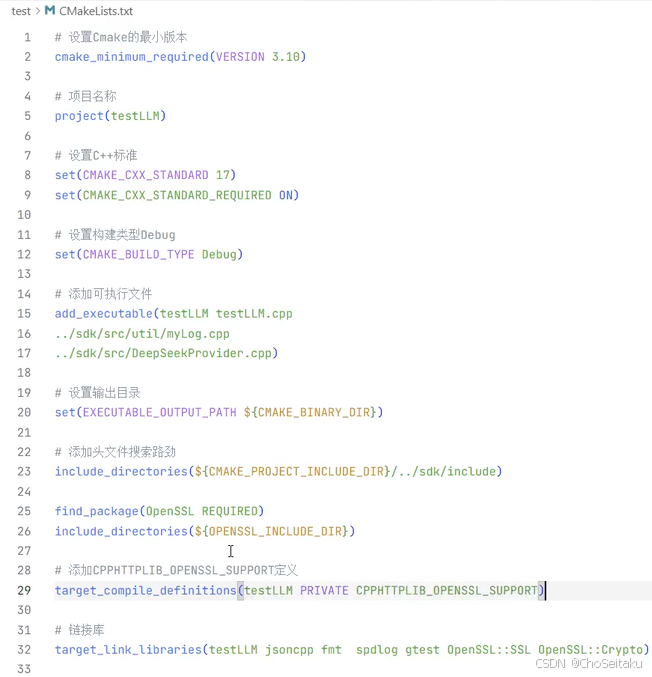
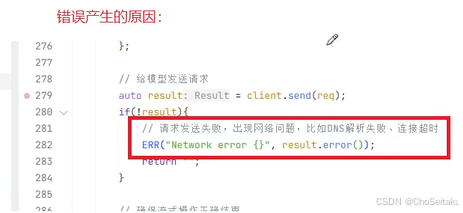
注意:httplib库默认使⽤http协议,⽽deepseek的官⽹链接使⽤https协议,因此在编译时需要链接OpenSSL开发库以⽀持SSL/TLS。否则在使⽤httplib创建http客⼾端时报错
将OpenSSL库配置到CMakeList.txt⽂件,否则编译时不会链接OpenSSL库
httplib.h

需要预定义宏

全量返回⽐较适合⽣成⽂档、数据报表之类,⽤⼾⼀次性拿到完整的数据⽂件。但对于聊天场景不是很友好,如果⼤模型⼀次回复内容较多,会让⽤⼾等待时间过⻓,体验不是很好。因此,⼀般聊天场景中,基本使⽤流式响应
流式响应
HTTP协议是严格的"请求-响应"模型,永远是客⼾端发起请求,服务器才能响应,服务器就像个"哑巴",它知道更多内容,但是它⽆法主动告诉你。这种⼀问⼀答的模式对于⼤部分⽹⻚浏览器、数据提交等场景已经⾜够了。
但是有些场景下,服务器需要主动向客⼾端推送⼀些实时数据,⽐如,在看体育直播时,服务器要及时将⽐赛分数、⾦球球员等信息推送给客⼾端;在多⼈在线游戏中,服务器需要实时同步玩家的操作和游戏状态;在使⽤导航类应⽤时,服务器需要实时推动导航信息等。
⼤佬们也发现这个问题了,在2004年的时候IanHickson就提出了SSE概念,Opera浏览器是第⼀个⽀持SSE的,2011年开始,⼀些主流浏览器(Chrome、Firefox、Safari)开始逐步⽀持SSE,2015年时SSE规范才正式成为W3C的标准。
SSE协议
SSE是Server Send Event的缩写,即服务器发送事件,是建⽴在HTTP协议之上的开发标准,允许服务器主动向客⼾端(如浏览器)推送实时数据。

SSE通过单⼀的持久连接实现数据的实时传输,客⼾端⽆需频繁发起请求。
SSE协议特点
- 单向通信:服务器可以主动推送数据到客⼾端,但客⼾端⽆法直接通过SSE向服务器发送数据
- 基于HTTP协议:SSE使⽤标准的HTTP协议,⽆需额外的协议或端⼝配置,兼容性好易于实现
- 轻量级:SSE的实现更简单,代码量少,适合简单的实时数据推送场景
- ⾃动重连:如果连接断开,浏览器会⾃动尝试重新连接,⽆需开发者⼿动处理重连逻辑
- ⽀持事件类型:服务器可以发送不同类型事件,客⼾端可以根据事件类型执⾏不同的操作
- ⽀持消息ID:每条消息可以包含⼀个唯⼀的ID,⽤于断线重连后恢复消息流
数据格式:
每个事件可以包含以下字段:
- data:消息内容(必须)
- event:事件类型(可选)
- id:消息ID(可选)
- retry:重连时间(可选,单位:毫秒)
c
data: Hello, world!
event: message
id: 123
retry: 10000
data: Another message每条消息以两个换⾏符 (\n\n) 结束,消息流传输完毕后会有专⻔的结束标记,不同实现结束标记不同,⽐如data:[DONE]。
向DeepSeek、ChatGPT、Gemini等⼤模型提问时,这些⼤模型并不是⼀次性将完整回答丢给⽤⼾,⽽是服务器边思考,边主动将思考结果吐(推送)给⽤⼾的,就和打字⼀样⼀点点输出,⽤⼾不需要⻓时间的等待,能及时看到服务器响应的结果,体验⽐较好,这种⽅式称为流式响应。SSE推出后实际不温不⽕,⼤模型爆⽕后,正式⼤模型场景的需要,SSE协议就爆⽕了。
websocket
WebSocket协议
SSE协议有⼀个缺陷就是单向传输,即数据只能由服务器给客⼾端推送,在新闻推送、股票⾏情、体育⽐分等场景是⽐较合适的,因为这些场景客⼾端⽆需给服务器发数据。
但有些场景SSE就束⼿⽆策了。⽐如:你在你们宿舍的微信群⾥发了⼀个消息"谁去⻝堂帮我捎个饭",服务器收到后需要"谁去⻝堂帮我捎个个饭"这条消息主动推送给群中其他⼈,其他⼈收到消息后,就需要发消息回应你⽽不是不闻不问。此处由舍友回复"滚犊⼦",那服务器收到后⼜要推送给其他⼈...
该场景中,不仅需要服务器主动给客⼾端推送消息,也需要客⼾端给服务器发送消息。这种场景下WebSocket协议就派上⽤场了。
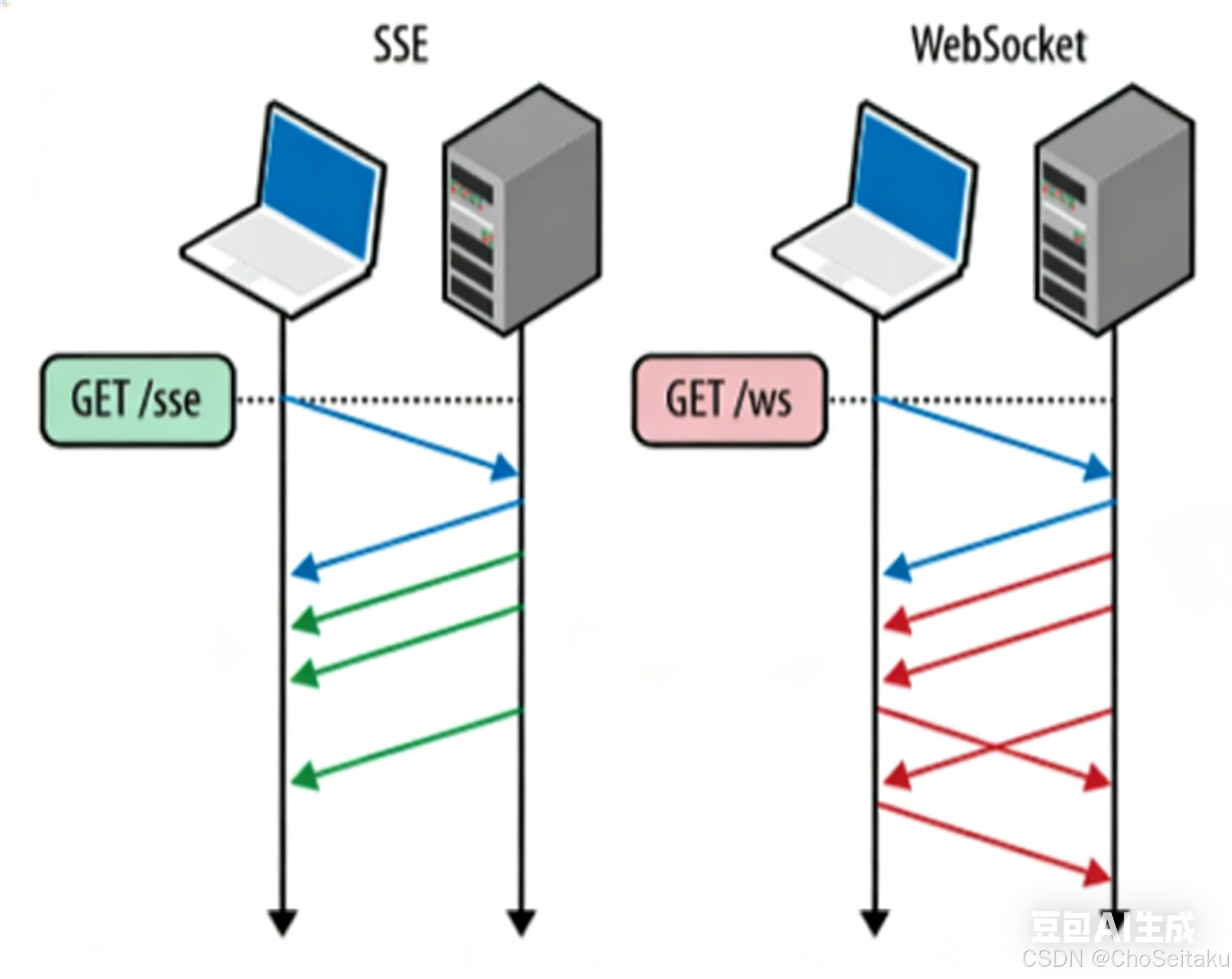
SSE与WebSocket区别
| 特性 | SSE | WebSocket |
|---|---|---|
| 通信方向 | 单向通道:服务器 → 客户端 | 双向通道:服务器 <=> 客户端 |
| 设计目的 | 服务器主动推送数据 (如新闻、状态更新) | 双向实时对话 (如聊天、游戏操作同步) |
| 协议 | HTTP | 独立的 TCP 协议,咱 HTTP 捂手后升级协议 (ws/wss) |
| 数据格式 | 纯文本 | 二进制或文本 |
| 自动重连 | 内置 | 较需要手动实现 |
| 使用场景 | 实时通知、日志流、LLM 响应等单向场景 | 实时聊天、多人在线游戏、实时交易等双向交互场景 |
| 为什么DeepSeek的助⼿消息使⽤SSE,不使⽤websocket? | ||
| 答:⼤模型的回复是服务器向客⼾端推送数据的单项数据流,在此期间客⼾端不需要给⼤模型服务器发送消息,⽽SSE刚好是服务器主动单项给客⼾端推送数据,并且实现简单⾼效,因此⼤模型回复通常都使⽤SSE协议。 |
HTTP普通响应体和流式响应体
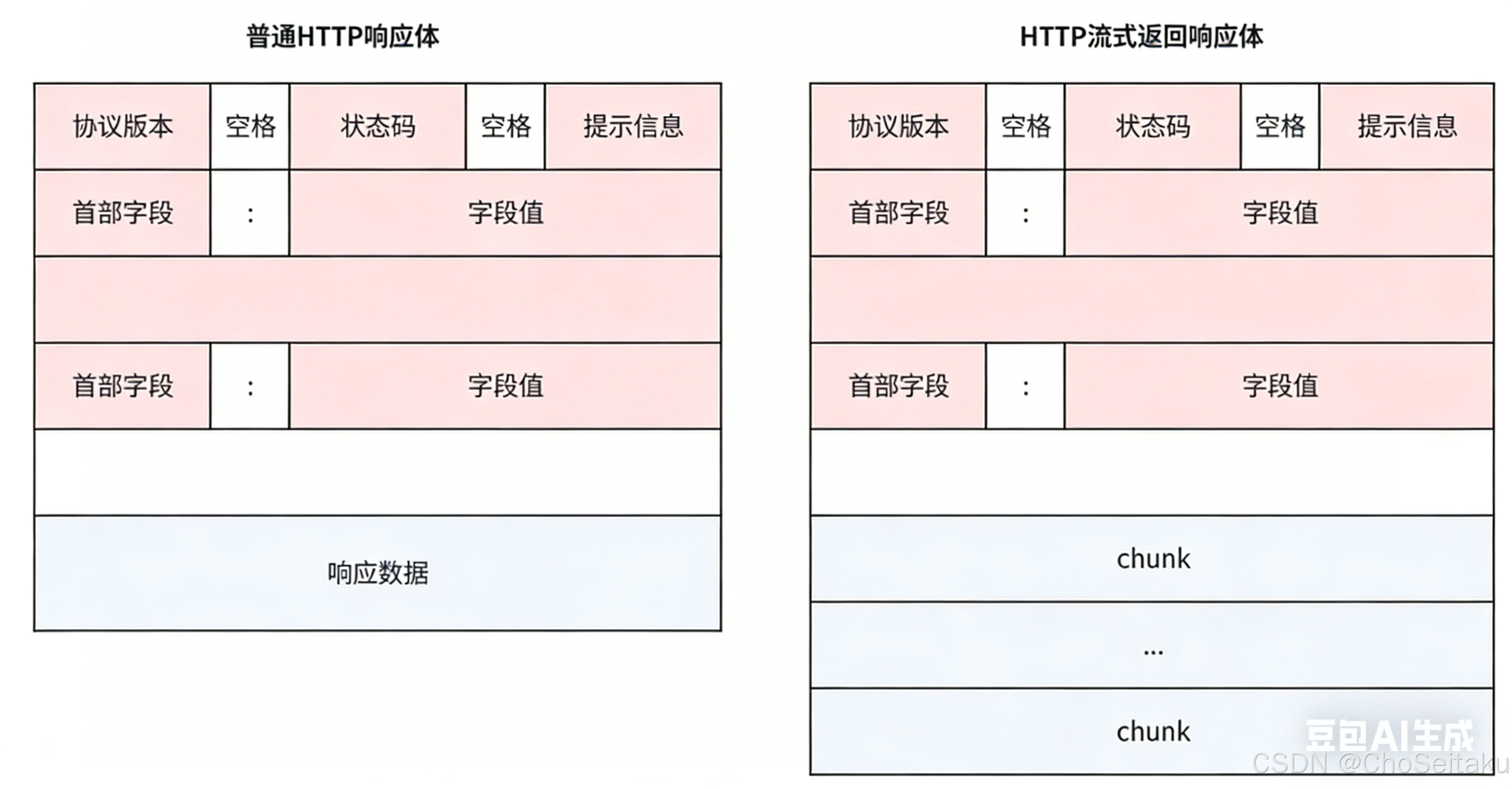
普通HTTP响应体中,⼀个响应包含⼀个响应头和⼀个响应体,
在HTTP流式返回响应体中,⼀个响应包含⼀个响应头和多个响应块。在流式返回时,会先返回响应头,然后在逐个返回各个响应体,因此在发送流式响应时,需要在请求参数中告知HTTP服务器,响应头和chunk该如何处理。
参数
在Httplib中,请求参数的定义(部分参数)如下:
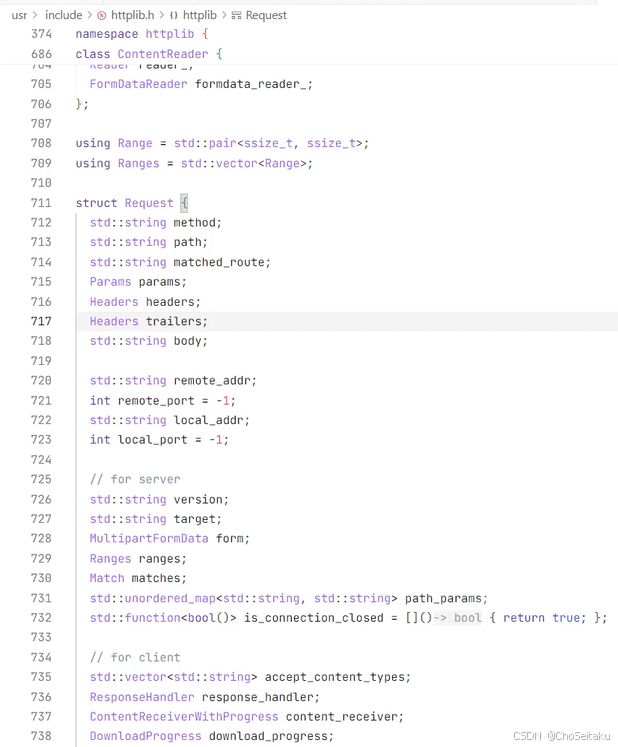
response_handler 为响应处理回调函数,实际类型为 std::function<void(const
Response&)> ,如果发起请求时设置该函数,当客⼾端收到完整的HTTP响应头和⼀些体(如果存在)后,会调⽤该函数,并传⼊构造好的Response对象。
content_recevier 内容接收回调函数,是处理流式处理响应的关键,类型为:
function<bool(const char* data, size_t len, uint64_t offset, uint64_t total)>
- data:指向当前接收到的数据块的指针
- len:当前数据块的⻓度
- offset:当前数据块在请求体中的偏移量
- total:请求体的总⻓度
- 返回值:true表⽰继续接收数据,false表⽰停⽌接收数据
设置该回调函数后,客⼾端不会等待整个响应体传输完再存到response.body中,⽽是每收到⼀⼩块数据就⽴刻调⽤该回调函数,处理实时数据,
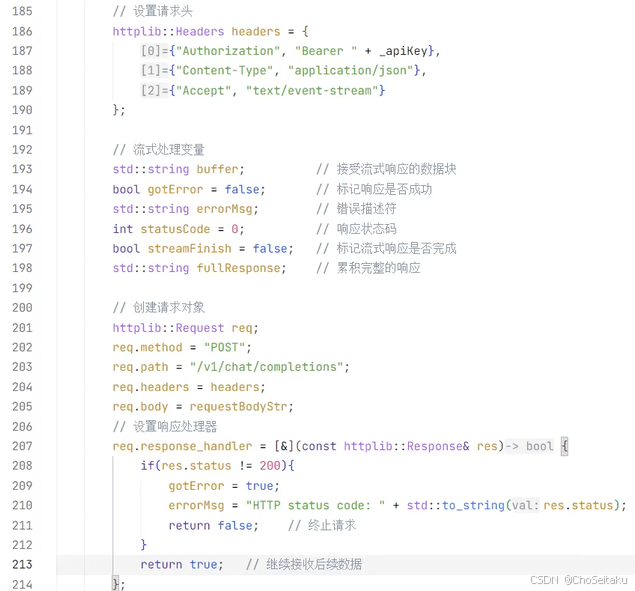
发送消息-流式返回
URL: /v1/chat/completions
| 字段名称 | 正确字段说明 |
|---|---|
| model | 调用的大模型名称(如gpt-3.5-turbo) |
| messages | 对话消息列表,包含用户提问、历史上下文 |
| temperature | 温度参数,控制生成内容的随机性(0-2 之间) |
| max_tokens | 生成内容的最大 token 数限制 |
| stream | 是否开启流式响应(SSE 逐字返回) |
DeepSeekProvider.cpp




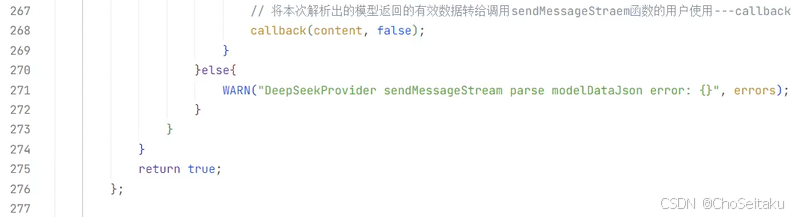


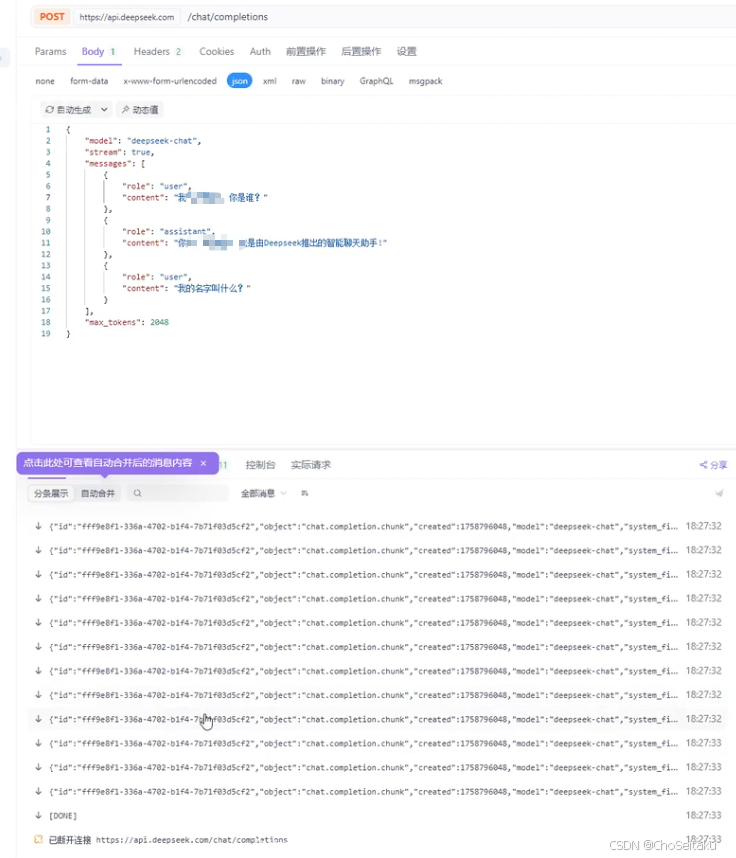
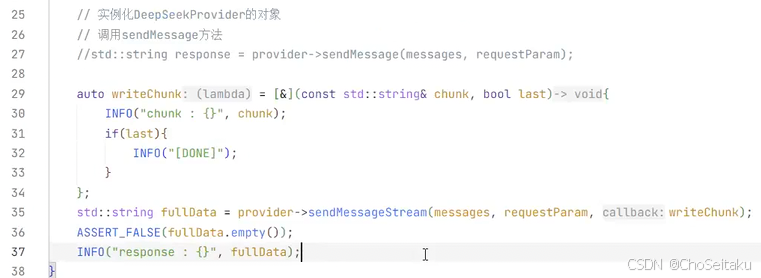
发送消息-流式返回测试
testLLM.cpp


enum class


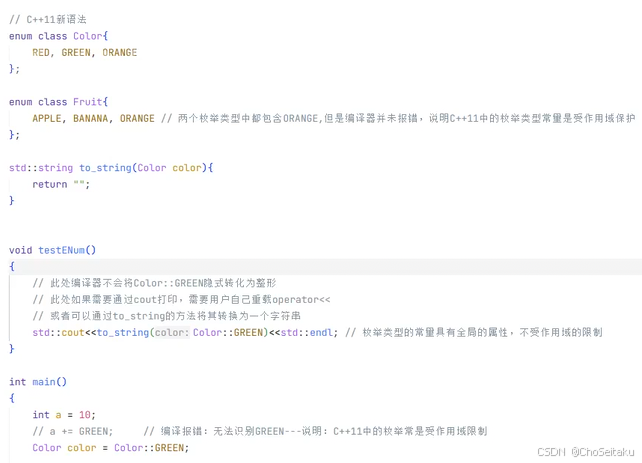
enum class,C++11新语法
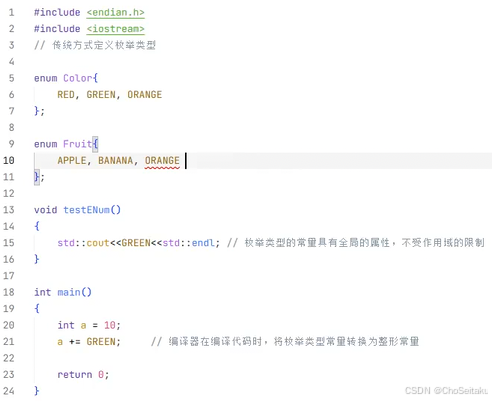
传统 enum 定义的枚举类型:
- 枚举类型中的枚举常量不受作用域的限制,一旦定义好之后,枚举常量就具有全局的属性
- 类型不安全,编译器会将其隐式转换为整形
在 C++11 中,通过 class 的方式定义枚举类型,可以解决上述两点不足