昨天我们学习了Transform的简单架构,以及对他进行了一个简单的总结。
今天,我们学点啥呢?今天学的是LLM的通用能力,通过今天的学习,我们能够清除的直到LLM中的一些简单的概念,接下来。让雷欧带着大家进入知识的海洋吧!!
一、上下文窗口(Context Window)
首先,什么是上下文窗口,模型一次能"看到"和"记住"的最大文本长度。例如:你输入从前有座山,山里有座庙,庙里有个老和尚,老和尚给小和尚将故事说从前有座山,山里有座庙,庙里有个老和尚......但是,模型的上下文窗口有限,可能当读到第二次循环的时候,前面的东西它已经忘记了。
再说的形象一点,上下文窗口=模型的"工作记忆",就例如普通人的大脑一样,只能记住5±2岁的事情,超出这个记忆,再往前可能就记不住了。
有的小伙伴会问了,这有什么用呢?那用处可大了,如果说你现在给了大模型一段很长的话,但是模型的上下文窗口却很短,那是不是代表你的模型不能把这段文字全部读完,就会造成断章取义的情况出现,因此,后续面临的挑战就是要增加长度,目前的解决办法有,滑动窗口注意力,稀疏注意力,线性注意力,检索增强生成(RAG)等。
二、幻觉(Hallucination)
以我们人举例子,啥叫幻觉?就是我们的眼睛看见了现实中并不是真的出现在你眼前的人或是物,那我们迁移到大模型上面来,对于大模型来说,什么是幻觉呢?也就是模型生成了一个看似合理,但完全是胡编乱造的一个东西给你,这就叫幻觉。
幻觉的常见分类:事实性幻觉(大模型说针对某某研究,但实际上压根就没有这项研究),逻辑性幻觉(因为A所以B,但是A和B根本八竿子打不着)和文本幻觉(引用不存在的文献或者论文)。
我们搞懂了它是什么,那么我们就要知道,为什么会产生幻觉,究其根本原因,训练数据的局限性,模型的训练时间过早,并不知道最新的消息;其次就是概率预测的本质,它本质上是在预测下一个词最大概率可能是什么,但是,并没有以实际为基础;最后,就是上下文理解有偏差。
那么,该如何避免幻觉呢?欧迷们肯定也不想问大模型一个问题,给你回答的全是错误答案吧,主流有以下三种解决方案:
1.提供准确的上下文:相当于让模型的回答和上下文串联起来,建立关系;
2.使用RAG:让大模型基于相关事实来回答。不脱离实际;
3.提示工程引导,可以允许它说不会,但是不能胡编,这是底线。
三、涌现(Emergence / Emergent Abilities)
说实话,雷欧第一次看见这词,懵了,真懵了!!这是个什么玩意,后来,经过多方了解才知道,所谓的涌现,就是模型会表现出它本不会有的能力,也就是意外觉醒了新的能力,这在小模型是完全不会出现的。
涌现能力的具体表现
| 能力 | 小模型表现 | 大模型表现 |
|---|---|---|
| 数学推理 | 简单计算 | 复杂证明、多步计算 |
| 代码生成 | 片段代码 | 完整项目、调试修复 |
| 语言翻译 | 逐词翻译 | 意译、文化适配 |
| 逻辑推理 | 模式匹配 | 因果分析、归纳演绎 |
| 角色扮演 | 生硬回答 | 性格一致、情感理解 |
为啥会出现这种情况呢,按理说,不都是训练好的嘛?出现这个问题,主要是因为一下几种情况,首先,知识整合 ,小模型,知识冗余,碎片化,而大模型会将知识形成网络,从而触发新的理解;其次,是参数冗余 ,针对小模型来说,参数都是很重要,没有发挥的空间,但是如果存在冗余参数,那么就有空间能够发展新的能力;最后,就是**思维链涌现,**只有足够大的模型,才能形成内部推理链。
四、微调(Fine-tuning)
所谓微调,就是在预训练模型的基础上,针对他特定任务进行额外训练,通俗来说,微调就是把一个通才的模型变成专才的模型。
微调主要有以下几类,第一,全参数微调,优点是效果好,缺点是特别占用GPU资源,第二参数高效微调,只更新少量参数。
五、提示工程(Prompt Engineering)
我们每天和大模型交流的时候,发给他们的话其实就叫做提示词,提示工程的作用就是通过精心设计输入提示词,获得更好的输出结果。这是十分重要的,为什么呢?看看下面这个例子:
基础提问:
────────────────────────────────────────
用户:解释量子计算
模型:给出一个标准但普通的解释
优化后提问:
────────────────────────────────────────
用户:用通俗比喻解释量子计算,
假设受众是高中生,
先类比再用专业术语
结尾提醒可能的应用
模型:更结构化、更易懂、更有价值的回答
大家觉得哪一个,大模型会给你回答的更好呢,显而易见,肯定是第二个!!!
那么,该如何去写优秀的提示词呢,雷欧给大家几个小技巧:
1)明确角色:你是一个有10年经验的HR,从招聘角度告诉我怎么写简历更吸引人;
2)清晰格式要求:用以下格式总结:1. 核心观点(不超过20字)2. 3个关键细节 3. 对我的帮助";
3)提供上下文:我喜欢策略游戏,喜欢深度剧情,不喜欢太肝,推荐3款适合我的游戏;
4)分步骤引导:请分步骤思考:1. 分析排序算法的类型 2. 选择最合适的一种 3. 解释时间空间复杂度 4. 给出代码实现;
5)自我反思:请先假设代码有bug,列出所有可能的问题,然后逐个排除;
6)迭代优化:一直更新,直到你满意为止。
六、一句话概括
| 概念 | 定义 |
|---|---|
| 上下文窗口 | 模型一次能处理的文本长度(记忆容量) |
| 幻觉 | 模型生成看似正确但实际虚构的内容(已知局限) |
| 涌现 | 大模型超越临界点后突然出现的新能力(惊喜效果) |
| 微调 | 在预训练模型基础上针对特定任务训练(能力定制) |
| 提示工程 | 通过优化提问方式获得更好输出(激发潜能) |
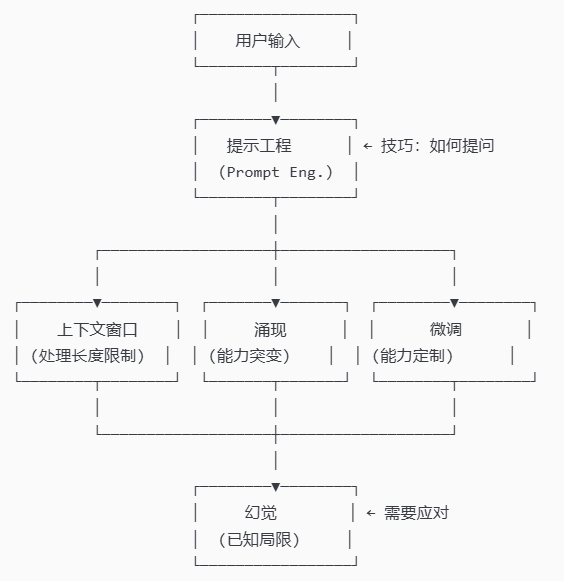
最后,一句话说清楚
LLM 的本质:一个在超大规模文本上训练的概率模型,它通过"预测下一个词"来生成内容,但在超过某个规模后会"涌现"出意想不到的能力。我们可以通过提示工程激发这些能力,通过微调定制专属模型,同时需要警惕幻觉问题,并在上下文窗口限制下工作。
今天到这里就结束了,我是程序员雷欧,我们下次再见......