试想一个场景,将mysql中的jrxd 数据库中的所有表导入到hive中的finance数据库中
一、准备工作
在hive中创建一个数据库: create database finance;
在mysql数据库,查询jrxd下的所有表名,复制到/root/tables.txt文件中
select table_name from information_schema.`TABLES` where table_schema = 'jrxd'
将其查询的内容,复制到table.txt中
channel_info
com_manager_info
dict_citys
dict_product
dict_provinces
drawal_address
drawal_apply
drawal_companys
loan_apply
loan_apply_credit_report
loan_apply_salary
loan_credit
repay_plan
repay_plan_item
repay_plan_item_his
user_det
user_md5
user_ocrlog
user_quota
users二、批量生成hive的建表语句
python 代码编写
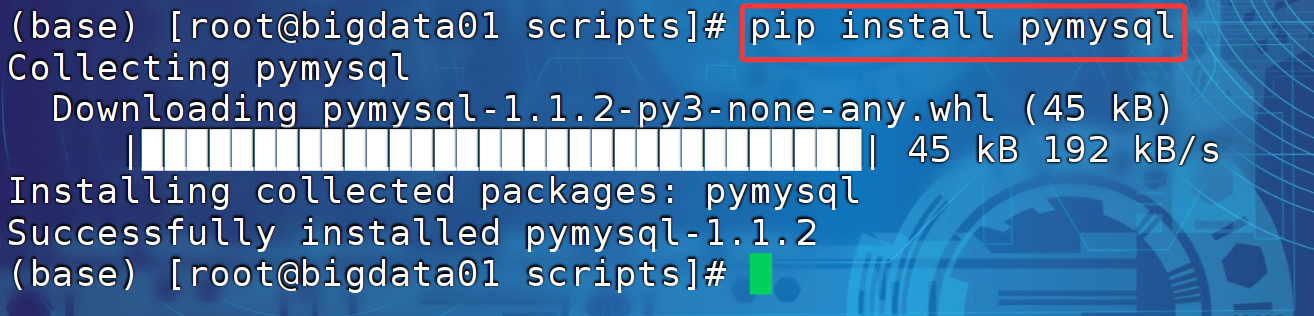
python 连接 mysql 需要 pymysql 的支持,所以需要先在 windows 上安装这个软件:
pip install pymysql
python
# 给定一个数据库的名字和表的名字,自动生成hive的建表语句
import sys
import pymysql
def getDBData(dbName, tableName):
# 查询mysql的元数据,根据数据库的名字和表的名字查询改表对应的字段和类型
# 连接数据库(指定charset避免中文乱码)
conn = pymysql.connect(
host='bigdata01',
user='root',
password='123456',
database='information_schema',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor # 返回字典格式,更易读
)
cursor = conn.cursor()
sql = """
SELECT column_name, data_type
FROM information_schema.`COLUMNS`
WHERE TABLE_SCHEMA = %s AND table_name = %s
ORDER BY ordinal_position # 按字段顺序排序
"""
# 执行sql语句
cursor.execute(sql, (dbName, tableName))
result=cursor.fetchall()
# 关键修复:统一将字典的key转为小写,兼容大小写场景
result_lower = []
for item in result:
lower_item = {k.lower(): v for k, v in item.items()}
result_lower.append(lower_item)
#print(result_lower)
"""
[{'column_name': 'id', 'data_type': 'bigint'}, {'column_name': 'name', 'data_type': 'varchar'},
{'column_name': 'channel_code', 'data_type': 'varchar'}, {'column_name': 'channel_type', 'data_type': 'varchar'},
{'column_name': 'channel_cus_fee', 'data_type': 'decimal'},
{'column_name': 'channel_perf_fee', 'data_type': 'decimal'},
{'column_name': 'updated_at', 'data_type': 'datetime'}, {'column_name': 'created_at', 'data_type': 'datetime'}]
"""
cursor.close()
conn.close()
return result_lower
# 完善MySQL到Hive的类型映射(覆盖更多场景,符合生产规范)
MYSQL_TO_HIVE_TYPE_MAPPING = {
# 整数类型
'tinyint': 'TINYINT',
'smallint': 'SMALLINT',
'int': 'INT',
'integer': 'INT',
'bigint': 'BIGINT',
'bit': 'BOOLEAN', # MySQL bit(1) 对应Hive布尔值
# 浮点/定点类型
'float': 'FLOAT',
'double': 'DOUBLE',
'decimal': 'DECIMAL', # 保留DECIMAL类型(金融场景不建议转STRING)
'numeric': 'DECIMAL',
# 字符串类型
'varchar': 'STRING',
'char': 'STRING',
'text': 'STRING',
'tinytext': 'STRING',
'mediumtext': 'STRING',
'longtext': 'STRING',
'enum': 'STRING',
'set': 'STRING',
# 日期时间类型
'date': 'DATE',
'datetime': 'STRING', # 避时区问题,建议存字符串
'timestamp': 'STRING',
'time': 'STRING',
'year': 'INT',
# 二进制类型
'binary': 'BINARY',
'varbinary': 'BINARY',
'blob': 'BINARY',
'tinyblob': 'BINARY',
'mediumblob': 'BINARY',
'longblob': 'BINARY',
# 其他类型
'boolean': 'BOOLEAN',
'bool': 'BOOLEAN'
}
def generateHiveCreateSql(dbName, tableName,field_info):
hive_columns = []
for tuple in field_info:
column_name = tuple['column_name']
data_type = tuple['data_type']
# 根据mysql的字段类型获取hive对应的字段类型
hive_type=MYSQL_TO_HIVE_TYPE_MAPPING.get(data_type, "string")
hive_columns.append(f"{column_name} {hive_type}")
print(",".join(hive_columns))
sql = f"""
CREATE TABLE IF NOT EXISTS ods_jrxd_{tableName} (
{','.join(hive_columns)}
)
COMMENT '{dbName}.{tableName}'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
"""
return sql
if __name__ == '__main__':
# 校验外部参数
if len(sys.argv) != 3:
print("请传入数据库的名字和表的名字")
dbName = sys.argv[1]
tableName = sys.argv[2]
print(dbName, tableName)
field_info=getDBData(dbName, tableName)
create_hive_table_sql=generateHiveCreateSql(dbName, tableName, field_info)
print(create_hive_table_sql)
with open("./hive_create_table.sql","a",encoding="utf-8") as f:
f.write(create_hive_table_sql)shell 代码:
#!/bin/bash
while read x1
do
python AutoCreateHiveSql.py jrxd $x1
done < /root/tables.txt将 python 代码,上传到 /home/scripts
运行脚本:
./datax_autosql_finance.sh
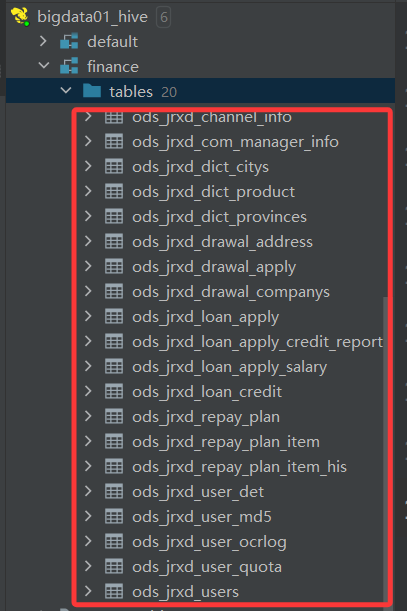
将 sql 语句粘贴到 hive 窗口运行即可
三、批量生成 datax 的 json 文件
编写一个python脚本,用于生成datax的json文件
`COLUMNS` 是一个视图,不是一个表
需要用到python的以下技术点
1)python读取mysql数据? spark_pro
2)知道mysql表的元数据在哪里?
select column_name ,data_type from information_schema.`COLUMNS` where TABLE_SCHEMA = 'spark_project' and table_name = 't_order'
3)一些函数的用法
4)文件的写入 IO流编写python代码
第一步:能够通过python读取mysql的数据库的表
import pymysql
def getDBData(dbName,tableName):
db_connection = pymysql.connect(
host="bigdata01",
port=3306,
user="root",
password="123456",
database='information_schema'
)
cursor = db_connection.cursor()
sql = f"select column_name ,data_type from information_schema.`COLUMNS` where TABLE_SCHEMA = '{dbName}' and table_name = '{tableName}' order by ordinal_position"
cursor.execute(sql)
result = cursor.fetchall()
cursor.close()
db_connection.close()
return result
if __name__ == '__main__':
result = getDBData("spark_project","oms_order")
print(result)第二步:使用json.dump将文件保存起来
第三步:拼接json文件
import json
import sys
import pymysql
def getDBData(dbName, tableName):
# 查询mysql的元数据,根据数据库的名字和表的名字查询改表对应的字段和类型
# 连接数据库(指定charset避免中文乱码)
conn = pymysql.connect(
host='bigdata01',
user='root',
password='123456',
database='information_schema',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor # 返回字典格式,更易读
)
cursor = conn.cursor()
sql = """
SELECT column_name, data_type
FROM information_schema.`COLUMNS`
WHERE TABLE_SCHEMA = %s AND table_name = %s
ORDER BY ordinal_position # 按字段顺序排序
"""
# 执行sql语句
cursor.execute(sql, (dbName, tableName))
result=cursor.fetchall()
return result
def getAllCloumnsName(result):
cloumnName=map(lambda x:x['COLUMN_NAME'],result)
list1=list(cloumnName)
#print(list1)
return ",".join(list1)
def getAllClumnsNameAndType(result):
# 获取列的名字和类型
mappings = {
'bigint': 'bigint',
'varchar': 'string',
'int': 'int',
'datetime': 'string',
'text': 'string',
'decimal': 'string',
'date': 'string',
'timestamp': 'string',
'varbinary': 'Bytes',
'double': 'double',
'time': 'Date'
}
list2=list(map(lambda x:{"name":x['COLUMN_NAME'],"type":mappings.get(x['DATA_TYPE'],'string')},result))
return list2
if __name__ == '__main__':
# 校验外部参数
if len(sys.argv) != 3:
print("请传入数据库的名字和表的名字")
dbName = sys.argv[1]
tableName = sys.argv[2]
result=getDBData(dbName,tableName)
print(result)
cloumn=getAllCloumnsName(result)
print(cloumn)
columnAndType=getAllClumnsNameAndType(result)
# 拼接json 数据
jsonData = {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"querySql": [
f"select {cloumn} from {tableName}"
],
"jdbcUrl": [
f"jdbc:mysql://bigdata01:3306/{dbName}"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://bigdata01:9820",
"fileType": "text",
"path": f"/user/hive/warehouse/finance.db/ods_jrxd_{tableName}",
"fileName": f"{tableName}",
"writeMode": "append",
"column":
columnAndType
,
"fieldDelimiter": ","
}
}
}
]
}
}
print(jsonData)
with open(f"./datax_json/{tableName}.json", "w") as f:
json.dump(jsonData, f)运行上述python脚本
python AutoCreateJson.py jrxd channel_info根据以上写法,我还要执行 20 次脚本,很累,耽误打游戏,于是编写了一个一 键 生成所有表的json的脚本:
在 /home/scripts 文件夹
bash
#/bin/bash
while read x1
do
python AutoCreateJson.py jrxd $x1
done < /root/tables.txt
bash
chmod 777 create_datax_json.sh
将AutoCreateJson.py 也放入到/home/scripts
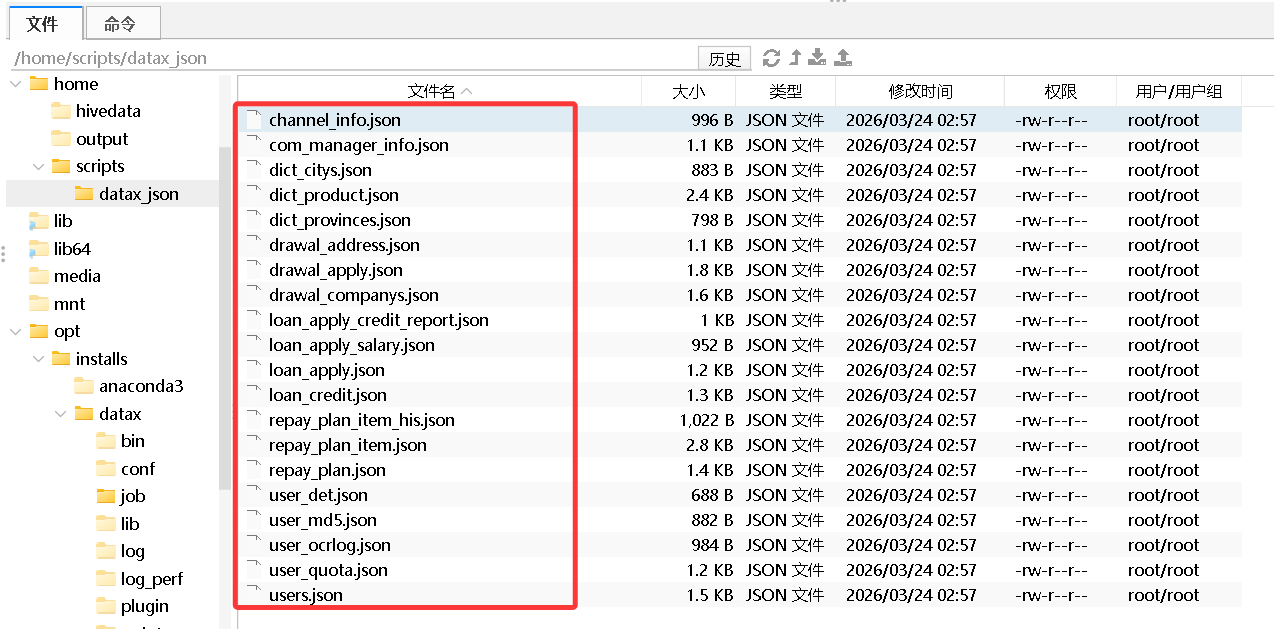
创建一个文件夹 mkdir -p /home/scripts/datax_json
继续执行 脚本 ./create_datax_json.sh成功如下图所示:
四、datax 导入业务库数据到ODS层
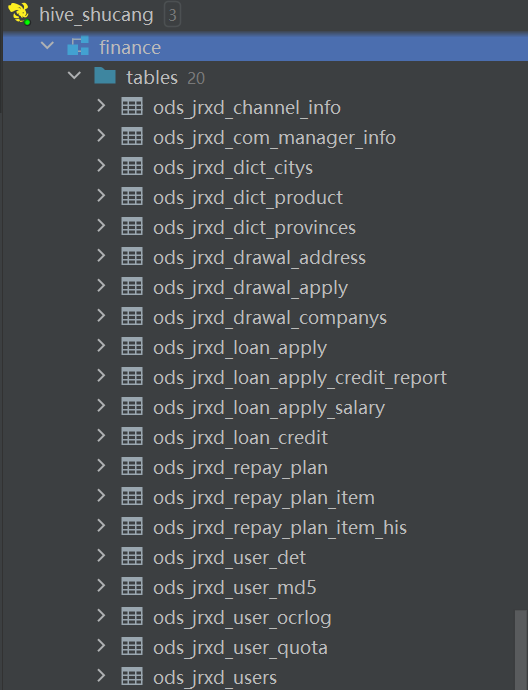
使用 AI 帮我们编写一个脚本:
提示词:
你是一个 shell 脚本高手,目前我的文件夹/home/scripts/datax_json 下有很多的 json 文件,编写一个脚本,获取该文件夹下的所有文件,并循环执行 datax.py 文件名 这样的命令
run_all_datax.sh
bash
#!/bin/bash
# 定义 JSON 文件所在目录
JSON_DIR="/home/scripts/datax_json"
# 定义 datax.py 的路径(请根据你实际路径修改!)
DATAX_PY="/opt/installs/datax/bin/datax.py"
echo "========================================"
echo "开始执行目录下所有 DataX 任务:$JSON_DIR"
echo "========================================"
# 循环遍历所有 .json 文件
for json_file in "$JSON_DIR"/*.json; do
# 如果目录里没有 json 文件,跳过
[ -e "$json_file" ] || continue
echo ""
echo "====> 正在执行:$json_file"
# 执行 DataX 命令
python "$DATAX_PY" "$json_file"
done
echo "========================================"
echo "所有任务执行完成!"
echo "========================================"chmod 777 run_all_datax.sh
因为我们之前已经测试过 channel_info 这个json文件了,所以为了防止数据插入重复,将该 文件删除
执行 脚本:
./run_all_datax.sh