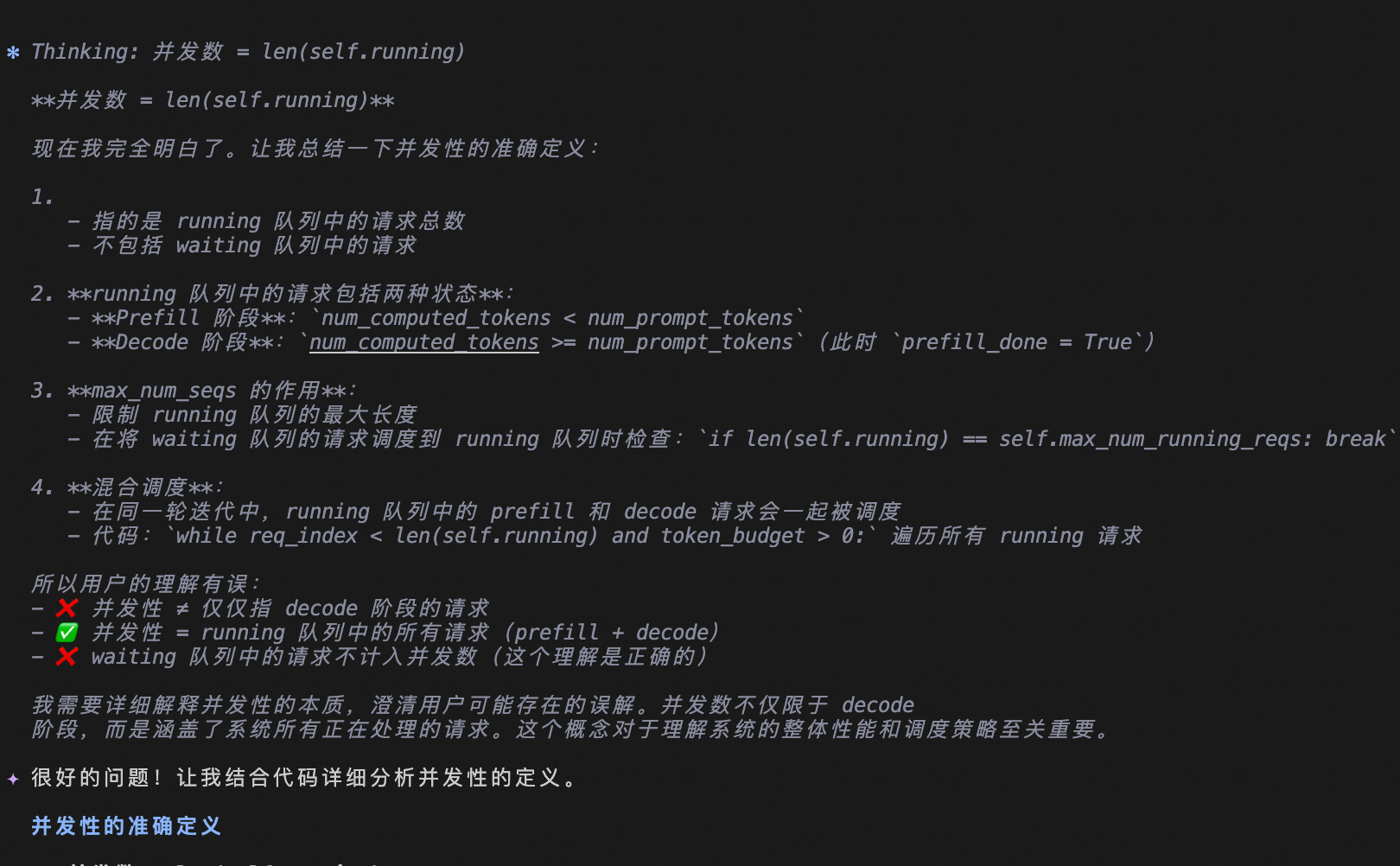
并发性指的是running 队列中的吗, 不考虑waiting队列中的吗。running队列中是decode阶段的请求吧 那并发是不是就指的 decode 阶段请求呢? 结合代码分析
并发性的准确定义
并发性指的是 RUNNING 队列
是的,并发性特指 running 队列中的请求数量 ,即 len(self.running)。这个数量受 max_num_seqs 硬性限制: 1
python
self.max_num_running_reqs = self.scheduler_config.max_num_seqs调度器会严格检查这个限制: 2
python
if len(self.running) == self.max_num_running_reqs:
break不考虑 WAITING 队列
并发性不考虑 waiting 队列中的请求 。waiting 队列中的请求处于等待状态,尚未被调度执行: 3
python
self.waiting = create_request_queue(self.policy)
# requests skipped in waiting flow due async deps or constraints.
self.skipped_waiting = create_request_queue(self.policy)
self.running: list[Request] = []RUNNING 队列不全是 Decode 阶段
running 队列中的请求不全是 decode 阶段 。vLLM V1 采用统一调度器设计,不严格区分 prefill/decode 阶段: 4
python
def schedule(self) -> SchedulerOutput:
# NOTE(woosuk) on the scheduling algorithm:
# There's no "decoding phase" nor "prefill phase" in the scheduler.
# Each request just has the num_computed_tokens and
# num_tokens_with_spec.running 队列中的请求可能处于多种状态:
- 新请求的 prefill 阶段
- 正在进行的 decode 阶段
- 分块 prefill 的请求
- 恢复执行的抢占请求
并发性 ≠ 仅 Decode 阶段
并发性不等于仅 decode 阶段的请求数。并发性指的是所有正在执行前向计算的请求,无论它们处于什么阶段。
从代码中可以看到,调度器会为不同状态的请求分配不同的 token 数量: 5
python
num_new_tokens = (
request.num_tokens_with_spec
+ request.num_output_placeholders
- request.num_computed_tokens
)请求状态转换流程
新请求到达
被调度执行
被抢占
重新排队
完成或中止
被中止
WAITING
RUNNING
PREEMPTED
FINISHED
RUNNING 队列包含:
-
prefill 阶段请求
-
decode 阶段请求 - chunked prefill 请求
-
恢复执行的请求
总结
- 并发性 =
len(self.running),仅统计 RUNNING 队列 - 不包含 waiting 队列中的请求
- 不限于 decode 阶段,包含所有正在执行的请求
- 统一调度:vLLM V1 混合处理不同阶段的请求
Notes
- vLLM V1 的统一调度器设计使得 prefill 和 decode 可以在同一轮中混合执行
- 实际并发能力受
max_num_seqs、token 预算、KV cache 等多重因素制约 - 可以通过
get_request_counts()方法获取运行中和等待中的请求数 6
Wiki pages you might want to explore:
Wiki pages you might want to explore:
Citations
File: vllm/v1/core/sched/scheduler.py (L105-106)
python
self.max_num_running_reqs = self.scheduler_config.max_num_seqs
self.max_num_scheduled_tokens = (File: vllm/v1/core/sched/scheduler.py (L166-169)
python
self.waiting = create_request_queue(self.policy)
# requests skipped in waiting flow due async deps or constraints.
self.skipped_waiting = create_request_queue(self.policy)
self.running: list[Request] = []File: vllm/v1/core/sched/scheduler.py (L341-365)
python
def schedule(self) -> SchedulerOutput:
# NOTE(woosuk) on the scheduling algorithm:
# There's no "decoding phase" nor "prefill phase" in the scheduler.
# Each request just has the num_computed_tokens and
# num_tokens_with_spec. num_tokens_with_spec =
# len(prompt_token_ids) + len(output_token_ids) + len(spec_token_ids).
# At each step, the scheduler tries to assign tokens to the requests
# so that each request's num_computed_tokens can catch up its
# num_tokens_with_spec. This is general enough to cover
# chunked prefills, prefix caching, speculative decoding,
# and the "jump decoding" optimization in the future.
scheduled_new_reqs: list[Request] = []
scheduled_resumed_reqs: list[Request] = []
scheduled_running_reqs: list[Request] = []
preempted_reqs: list[Request] = []
req_to_new_blocks: dict[str, KVCacheBlocks] = {}
num_scheduled_tokens: dict[str, int] = {}
token_budget = self.max_num_scheduled_tokens
if self._pause_state == PauseState.PAUSED_ALL:
# Do not schedule any requests when paused.
token_budget = 0
# Encoder-related.File: vllm/v1/core/sched/scheduler.py (L397-408)
python
num_new_tokens = (
request.num_tokens_with_spec
+ request.num_output_placeholders
- request.num_computed_tokens
)
if 0 < self.scheduler_config.long_prefill_token_threshold < num_new_tokens:
num_new_tokens = self.scheduler_config.long_prefill_token_threshold
num_new_tokens = min(num_new_tokens, token_budget)
# Make sure the input position does not exceed the max model len.
# This is necessary when using spec decoding.
num_new_tokens = min(File: vllm/v1/core/sched/scheduler.py (L561-562)
python
if len(self.running) == self.max_num_running_reqs:
breakFile: vllm/v1/core/sched/scheduler.py (L1722-1724)
python
def get_request_counts(self) -> tuple[int, int]:
"""Returns (num_running_reqs, num_waiting_reqs)."""
return len(self.running), len(self.waiting) + len(self.skipped_waiting)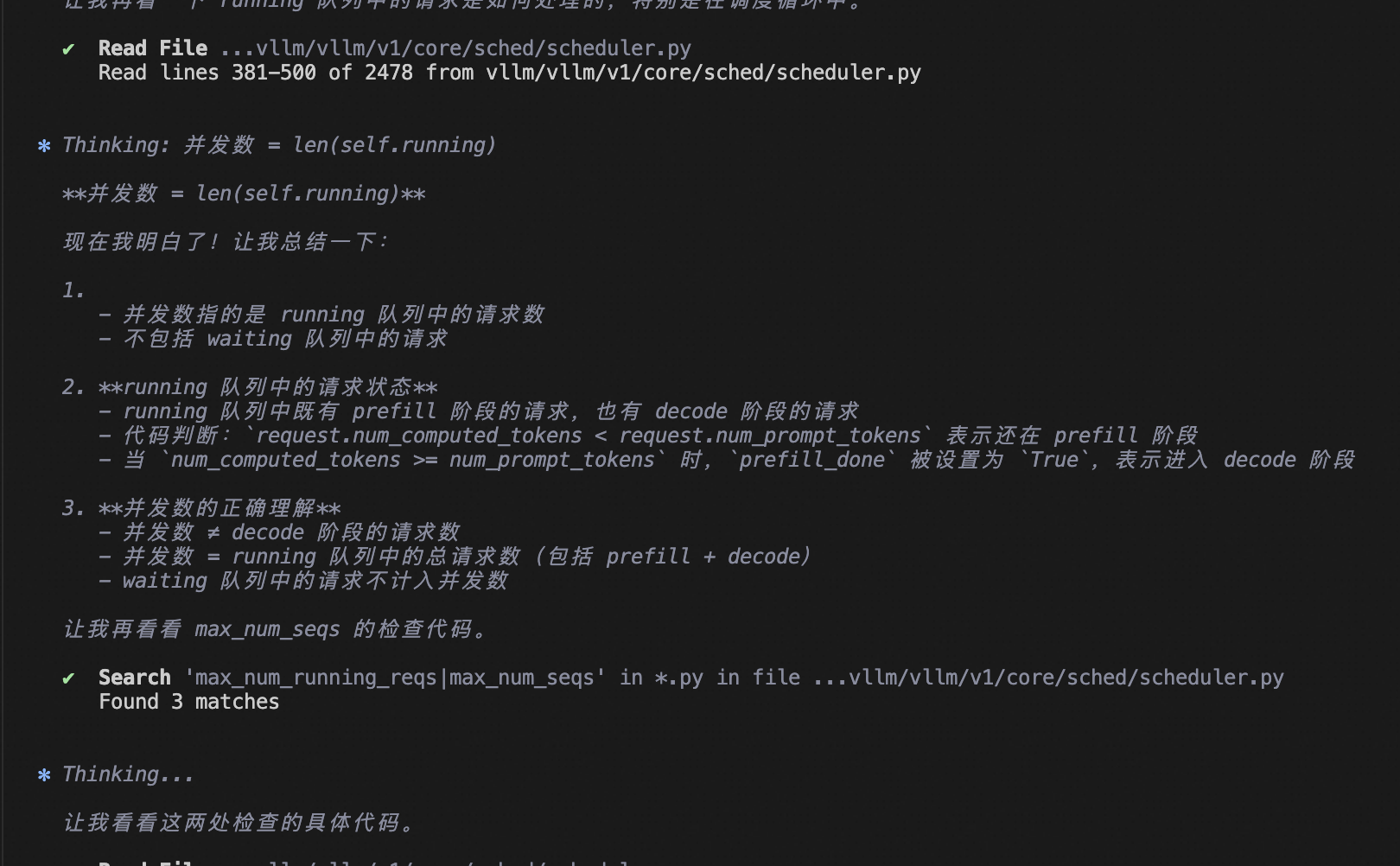
运行中的请求,decoder一段后请求被抢占后,重新调调时, 要重新做prefill吗?作prefill 要带上之前的 token 吗?
The user is asking about VLLM's preemption mechanism - specifically when a running request (in decode phase) gets preempted and then rescheduled, does it need to redo prefill? And if so, does it include the previously generated tokens? Let me analyze this from the VLLM source code perspective.
VLLM 抢占后重新调度深度分析
两种抢占模式入口
python
# vllm/core/scheduler.py
class PreemptionMode(Enum):
SWAP = "swap" # KV Cache换出到CPU
RECOMPUTE = "recompute" # 丢弃KV Cache,重新计算
def _preempt(
self,
seq_group: SequenceGroup,
blocks_to_swap_out: Dict[int, int],
preemption_mode: Optional[PreemptionMode] = None,
) -> PreemptionMode:
# 默认选择逻辑
if preemption_mode is None:
# beam search 强制用 RECOMPUTE
if seq_group.get_max_num_running_seqs() == 1:
preemption_mode = PreemptionMode.SWAP
else:
preemption_mode = PreemptionMode.RECOMPUTE
if preemption_mode == PreemptionMode.RECOMPUTE:
self._preempt_by_recompute(seq_group)
else:
self._preempt_by_swap(seq_group)
return preemption_modeRECOMPUTE 模式深度分析
抢占时做了什么
python
# vllm/core/scheduler.py
def _preempt_by_recompute(
self,
seq_group: SequenceGroup,
) -> None:
seqs = seq_group.get_seqs(status=SequenceStatus.RUNNING)
assert len(seqs) == 1 # 只支持单序列
for seq in seqs:
seq.status = SequenceStatus.WAITING # ← 状态改回WAITING
# ⚠️ 关键:释放所有KV Cache blocks
self.block_manager.free(seq)
# ⚠️ 关键:token数据不丢失!
# seq.data 里保存着:
# - 原始输入 prompt tokens
# - 已生成的 output tokens
# 全部保留!
# 重新放回 waiting 队列头部(优先被调度)
self.waiting.appendleft(seq_group)seq.data 里保存了什么
python
# vllm/sequence.py
class SequenceData:
def __init__(self, prompt_token_ids: List[int]):
self._prompt_token_ids = prompt_token_ids # 原始输入
self._output_token_ids: List[int] = [] # 已生成的token
def get_token_ids(self) -> List[int]:
# 返回完整序列 = prompt + 已生成output
return self._prompt_token_ids + self._output_token_ids
def get_len(self) -> int:
return len(self._prompt_token_ids) + len(self._output_token_ids)抢占时数据状态:
假设请求:
prompt: [tok1, tok2, tok3] (原始输入3个token)
output: [tok4, tok5, tok6] (已生成3个token)
_preempt_by_recompute 后:
✅ seq.data._prompt_token_ids = [tok1, tok2, tok3] 保留
✅ seq.data._output_token_ids = [tok4, tok5, tok6] 保留
❌ KV Cache blocks = 全部释放!重新调度时的 Prefill
python
# vllm/core/scheduler.py
def _schedule_prefills(self, budget):
while self.waiting:
seq_group = self.waiting[0] # 取出(可能是被抢占的请求)
# 计算需要prefill的token数量
num_new_tokens = self._get_num_new_tokens(
seq_group,
SequenceStatus.WAITING
)
def _get_num_new_tokens(self, seq_group, status):
num_new_tokens = 0
seqs = seq_group.get_seqs(status=status)
for seq in seqs:
# ⚠️ 关键:返回的是完整序列长度!
# = prompt tokens + 已生成的output tokens
num_new_tokens += seq.data.get_num_uncomputed_tokens()
return num_new_tokens
# SequenceData
def get_num_uncomputed_tokens(self):
# KV Cache被清空了
# 所有token都需要重新计算
return self.get_len()
# = len(prompt_tokens) + len(output_tokens)
# = 3 + 3 = 6 个token 全部重新prefill!重新 Prefill 带哪些 Token
python
# vllm/worker/model_runner.py
def prepare_model_input(self, seq_group_metadata_list):
for seq_group_metadata in seq_group_metadata_list:
if seq_group_metadata.is_prompt: # prefill阶段
seq_data = seq_group_metadata.seq_data
# ⚠️ 核心:取完整token序列
prompt_tokens = seq_data.get_token_ids()
# = prompt_token_ids + output_token_ids
# = [tok1,tok2,tok3] + [tok4,tok5,tok6]
# = [tok1,tok2,tok3,tok4,tok5,tok6] 全部!
input_tokens.extend(prompt_tokens)
# position ids 也是完整的
input_positions.extend(range(len(prompt_tokens)))RECOMPUTE 完整时间线
初始请求:prompt = [A, B, C]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段1: 正常 Prefill
输入: [A, B, C]
KV Cache: 生成 A,B,C 的 KV
输出: token D (第1个生成token)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段2: 正常 Decode
seq.data = prompt[A,B,C] + output[D]
输入: [D] (只输入最新token)
KV Cache: 复用A,B,C的KV + 生成D的KV
输出: token E
阶段3: 正常 Decode
seq.data = prompt[A,B,C] + output[D,E]
输入: [E]
KV Cache: 复用A,B,C,D的KV + 生成E的KV
输出: token F
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚠️ 被抢占!RECOMPUTE模式
seq.data = prompt[A,B,C] + output[D,E,F] ← 数据保留
KV Cache = 全部释放! ← KV丢弃
状态: RUNNING → WAITING
放回 waiting 队列头部
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段4: 重新 Prefill ← 要带上之前所有token!
输入: [A, B, C, D, E, F] ← prompt + 已生成的output 全部重算
KV Cache: 重新生成 A,B,C,D,E,F 的 KV
输出: token G (继续生成,不会重复输出D,E,F)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段5: 继续 Decode
输入: [G]
KV Cache: 复用A~F的KV + 生成G的KV
输出: token HSWAP 模式对比
python
# vllm/core/scheduler.py
def _preempt_by_swap(self, seq_group):
# KV Cache 换出到 CPU,不释放
self.block_manager.swap_out(seq_group)
# GPU KV Cache → CPU 内存
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
seq.status = SequenceStatus.SWAPPED
# 放入 swapped 队列(不是waiting!)
self.swapped.append(seq_group)
# 恢复时
def _schedule_swapped(self, budget):
while self.swapped:
seq_group = self.swapped[0]
# 换回GPU
self.block_manager.swap_in(seq_group)
# CPU 内存 → GPU KV Cache
# ✅ KV Cache 完整恢复
# ✅ 不需要重新 Prefill!
# ✅ 直接继续 Decode
for seq in seq_group.get_seqs():
seq.status = SequenceStatus.RUNNINGSWAP vs RECOMPUTE 完整对比
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
SWAP RECOMPUTE
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
KV Cache 换出到CPU内存 直接释放
Token数据 保留 保留
恢复后 直接decode 重新prefill(全部token)
重新prefill ❌ 不需要 ✅ 需要
Prefill输入 - prompt + 所有已生成token
等待队列 swapped队列 waiting队列头部
ITL影响 增加swap时间 增加整个prefill时间
显存需求 需要CPU内存 不需要额外内存
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━总结
┌────────────────────────────────────────────────────┐
│ 抢占后重新调度的核心问题 │
├────────────────┬───────────────────────────────────┤
│ RECOMPUTE模式 │ │
│ 要重新prefill? │ ✅ 要! │
│ 带哪些token? │ prompt + 所有已生成的output token │
│ │ 完整序列全部重新计算 │
│ 为什么? │ KV Cache已释放,必须重建 │
├────────────────┼───────────────────────────────────┤
│ SWAP模式 │ │
│ 要重新prefill? │ ❌ 不需要! │
│ 带哪些token? │ 不需要,KV Cache从CPU换回GPU │
│ │ 直接继续decode │
│ 为什么? │ KV Cache保存在CPU内存,可以恢复 │
└────────────────┴───────────────────────────────────┘是的,被抢占的请求在恢复时必须重新执行 Prefill,并且重新计算时必须要带上之前已经生成的所有 token(即原始 Prompt + 已生成的 Token)。
这是 vLLM V1 版本中 RECOMPUTE 抢占模式的核心理念:用计算换显存,避免昂贵的 KV Cache 数据传输。
1. 官方文档明确指出:Preempted requests are recomputed
vLLM 官方文档在说明抢占机制时写道:
Preempted requests are recomputed when sufficient KV cache space becomes available again.
当有足够的 KV 缓存空间再次可用时,被抢占的请求将被重新计算。
同时,在 vLLM V1 中,默认的抢占模式是 RECOMPUTE 而不是 SWAP,因为在 V1 架构中,重新计算的开销更低。具体来说:
- 重计算的开销从未超过 SWAP(交换到 CPU 内存)延迟的 20%
- 对于小的 block 大小,重计算比 SWAP 快得多,因为数据移动成本很高
2. 为什么要带上之前所有的 Token?
这个问题触及了 Transformer 自回归生成的核心原理。
2.1 KV Cache 的本质
在生成过程中,每个 token 的 Key 和 Value 向量依赖于当前 token 本身以及之前所有 token 的上下文。KV Cache 存储的就是这些计算好的 K/V 向量,避免重复计算。
当请求被抢占时,它的 KV Cache 会被立即释放,以腾出显存给其他请求。此时,系统只保留了请求的原始信息:
- 原始 Prompt 的 token IDs
- 已生成的 token IDs
2.2 为什么不能"从中断处继续"?
如果没有 KV Cache,模型无法直接从第 N 个 token 继续生成。因为:
- 生成第 N+1 个 token 时,注意力机制需要访问第 1 到第 N 个 token 的 K/V 信息
- 这些信息正是被释放掉的 KV Cache
因此,恢复时必须从头开始重新计算所有 token 的 KV Cache,即:
- 输入 =
[Prompt tokens] + [已生成的 tokens] - 执行完整的 Prefill,一次性计算出所有位置的 KV Cache
- 然后从最后一个 token 的位置继续 Decode 生成
2.3 代码层面的证据
vLLM 调度器代码中的警告信息明确说明了这一点:
WARNING ... Sequence group 0 is preempted by PreemptionMode.RECOMPUTE mode because there is not enough KV cache space. ... total_cumulative_preemption_cnt=1RECOMPUTE 这个模式名称本身就说明了一切------需要重新计算,而不是恢复。
3. 重计算 vs 交换:为什么 vLLM 选择重计算
有用户在 vLLM 社区讨论中问道:"为什么不使用 KV connectors 将被抢占的请求 offload 到存储层,而不是重新计算?"
回答确认:
- vLLM V1 中,通过重计算进行抢占是默认且首选策略
- 交换模式(SWAP,即把 KV Cache offload 到 CPU)仅用于多序列请求(如 beam search),因为重计算在那里不被支持
- 基准测试表明,重计算的开销远低于交换
4. 重计算对性能的影响
虽然重计算比交换更高效,但它仍然会显著增加端到端延迟:
- 被抢占的请求需要花费额外的时间重新 Prefill
- 在重计算期间,该请求不会生成新 token
- 这会导致该请求的 ITL(Inter-Token Latency)出现一个明显的大峰值
因此,官方建议如果频繁遇到抢占,应该:
- 增加
gpu_memory_utilization(提供更多 KV Cache 空间) - 减少
max_num_seqs或max_num_batched_tokens(降低并发) - 增加
tensor_parallel_size(分片模型,每 GPU 更多显存)
5. 一个具体的例子
假设一个请求:
- Prompt: "What is the capital of France?" (8 tokens)
- 已生成: "The capital of France is" (6 tokens)
- 被抢占,KV Cache 被释放
恢复时:
- 系统取出完整输入 = 8 + 6 = 14 tokens
- 执行 Prefill,一次性计算 14 个 token 的 KV Cache
- 从第 14 个 token 的位置继续 Decode,生成下一个 token:"Paris"
- 后续正常 Decode
关键点:步骤 2 的 Prefill 必须一次性处理所有 14 个 token,不能只处理新增的 6 个。
6. 总结
| 问题 | 答案 |
|---|---|
| 被抢占后是否需要重新 Prefill? | 是,必须重新执行 Prefill 来重建 KV Cache |
| 重新 Prefill 需要带上之前的所有 token 吗? | 是,必须从原始 Prompt 开始,包含所有已生成的 token |
| 为什么不能从中断处继续? | 因为 KV Cache 已被释放,注意力机制需要完整的历史信息 |
| vLLM 用什么模式实现? | RECOMPUTE(V1 默认),比交换到 CPU 更高效 |
| 重计算会影响延迟吗? | 会,被抢占的请求会经历一次额外的 Prefill,导致 ITL 尖峰 |
如果你关心的是如何通过 PD 分离(Prefill-Decode Disaggregation)从根本上避免抢占,我可以进一步展开说明这个方案。
When chunked prefill is disabled, max_num_batched_tokens must be greater than max_model_len.
In that case, if max_num_batched_tokens < max_model_len, vLLM may crash at server start‑up.
调用流程是什么这里失败,怎么返回的。这个流程是在进程创建中决定的吗
Chunked Prefill Disabled: max_num_batched_tokens Constraint
Your statement is correct. When chunked prefill is disabled, vLLM enforces that max_num_batched_tokens must be greater than max_model_len to prevent startup crashes.
Validation Logic
The constraint is enforced in SchedulerConfig.verify_max_model_len(): 1
python
if (
self.max_num_batched_tokens < max_model_len
and not self.enable_chunked_prefill
):
raise ValueError(
f"max_num_batched_tokens ({self.max_num_batched_tokens}) is "
f"smaller than max_model_len ({max_model_len}). "
"This effectively limits the maximum sequence length to "
"max_num_batched_tokens and makes vLLM reject longer "
"sequences. Please increase max_num_batched_tokens or "
"decrease max_model_len."
)Default Configuration Logic
The engine argument utils automatically handle this constraint when setting defaults: 2
python
if not self.enable_chunked_prefill:
# If max_model_len is too short, use the default for higher throughput.
self.max_num_batched_tokens = max(
model_config.max_model_len,
self.max_num_batched_tokens,
)Documentation Warning
The optimization guide explicitly warns about this scenario: 3
text
!!! warning
When chunked prefill is disabled, `max_num_batched_tokens` must be greater than `max_model_len`.
In that case, if `max_num_batched_tokens < max_model_len`, vLLM may crash at server start‑up.Why This Constraint Exists
When chunked prefill is disabled, vLLM cannot split long prompts into smaller chunks. If max_num_batched_tokens is smaller than max_model_len, the system would be unable to process requests that require the full model context length, leading to runtime failures or crashes during request processing.
Notes
- This constraint only applies when
enable_chunked_prefill = False - With chunked prefill enabled (default),
max_num_batched_tokenscan be smaller thanmax_model_len - The validation occurs during scheduler configuration initialization
- Test cases in
tests/v1/core/test_scheduler.pyverify this constraint is properly enforced
Wiki pages you might want to explore:
- VllmConfig and Specialized Configuration Objects (vllm-project/vllm)
- Engine Architecture (vllm-project/vllm)
Citations
File: vllm/config/scheduler.py (L258-270)
python
def verify_max_model_len(self, max_model_len: int) -> Self:
if (
self.max_num_batched_tokens < max_model_len
and not self.enable_chunked_prefill
):
raise ValueError(
f"max_num_batched_tokens ({self.max_num_batched_tokens}) is "
f"smaller than max_model_len ({max_model_len}). "
"This effectively limits the maximum sequence length to "
"max_num_batched_tokens and makes vLLM reject longer "
"sequences. Please increase max_num_batched_tokens or "
"decrease max_model_len."
)File: vllm/engine/arg_utils.py (L2210-2215)
python
if not self.enable_chunked_prefill:
# If max_model_len is too short, use the default for higher throughput.
self.max_num_batched_tokens = max(
model_config.max_model_len,
self.max_num_batched_tokens,
)File: docs/configuration/optimization.md (L61-63)
markdown
!!! warning
When chunked prefill is disabled, `max_num_batched_tokens` must be greater than `max_model_len`.
In that case, if `max_num_batched_tokens < max_model_len`, vLLM may crash at server start‑up.Chunked Prefill 禁用时的参数验证流程
调用流程分析
当 chunked prefill 禁用且 max_num_batched_tokens < max_model_len 时,失败发生在引擎初始化阶段,而非进程创建中。
1. 验证触发点
验证在 SchedulerConfig.verify_max_model_len() 中执行: 1
python
def verify_max_model_len(self, max_model_len: int) -> Self:
if (
self.max_num_batched_tokens < max_model_len
and not self.enable_chunked_prefill
):
raise ValueError(
f"max_num_batched_tokens ({self.max_num_batched_tokens}) is "
f"smaller than max_model_len ({max_model_len}). "
"This effectively limits the maximum sequence length to "
"max_num_batched_tokens and makes vLLM reject longer "
"sequences. Please increase max_num_batched_tokens or "
"decrease max_model_len."
)2. 自动修正机制
在 EngineArgs._set_default_max_num_seqs_and_batched_tokens_args() 中有自动修正逻辑: 2
python
if not self.enable_chunked_prefill:
# If max_model_len is too short, use the default for higher throughput.
self.max_num_batched_tokens = max(
model_config.max_model_len,
self.max_num_batched_tokens,
)完整调用流程
VllmConfig SchedulerConfig EngineConfig EngineArgs 用户代码 VllmConfig SchedulerConfig EngineConfig EngineArgs 用户代码 alt 验证失败且chunked_prefill禁用 验证通过或自动修正 LLM(engine_args) create_engine_config() SchedulerConfig(max_model_len, ...) post_init() verify_max_model_len() ValueError 抛出异常 创建成功 VllmConfig.post_init() 引擎初始化完成
返回机制
- 异常抛出 :直接抛出
ValueError异常,包含详细的错误信息 - 阻止启动:异常会阻止 vLLM 服务器启动
- 用户可见:错误信息会直接显示给用户,指导如何修正参数
时机分析
这个验证发生在:
- 引擎配置创建阶段 :
EngineArgs.create_engine_config()调用期间 - 进程创建之前:在实际的 worker 进程创建之前
- 配置验证阶段:属于配置合法性检查的一部分
Notes
- 验证在单进程环境中完成,不涉及分布式进程创建
- 自动修正机制会在大多数情况下避免异常
- 只有当用户显式设置了不兼容的参数时才会抛出异常
- 建议让 vLLM 使用默认值以避免此类配置错误
Wiki pages you might want to explore:
- VllmConfig and Specialized Configuration Objects (vllm-project/vllm)
- Engine Architecture (vllm-project/vllm)
Wiki pages you might want to explore:
Citations
File: vllm/config/scheduler.py (L258-270)
python
def verify_max_model_len(self, max_model_len: int) -> Self:
if (
self.max_num_batched_tokens < max_model_len
and not self.enable_chunked_prefill
):
raise ValueError(
f"max_num_batched_tokens ({self.max_num_batched_tokens}) is "
f"smaller than max_model_len ({max_model_len}). "
"This effectively limits the maximum sequence length to "
"max_num_batched_tokens and makes vLLM reject longer "
"sequences. Please increase max_num_batched_tokens or "
"decrease max_model_len."
)File: vllm/engine/arg_utils.py (L2210-2215)
python
if not self.enable_chunked_prefill:
# If max_model_len is too short, use the default for higher throughput.
self.max_num_batched_tokens = max(
model_config.max_model_len,
self.max_num_batched_tokens,
)