相关文章地址:
Grounding DINO:https://arxiv.org/abs/2303.05499
Grounding DINO 1.5:https://arxiv.org/abs/2405.10300
Grounding DINO 1.6:https://visincept.com/blog/6/
DINO-X:https://arxiv.org/abs/2411.14347
项目页面:
Grounding DINO:https://github.com/IDEA-Research/GroundingDINO
Grounding DINO 1.5:https://github.com/IDEA-Research/Grounding-DINO-1.5-API
Grounding DINO 1.6:见 Grounding DINO 1.5
DINO-X:https://github.com/IDEA-Research/DINO-X-API
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
[0. 引言](#0. 引言)
[1. Grounding DINO 1.5:性能与效率的双轨突破](#1. Grounding DINO 1.5:性能与效率的双轨突破)
[1.1 Grounding DINO 1.5 Pro:早融合的潜力与平衡](#1.1 Grounding DINO 1.5 Pro:早融合的潜力与平衡)
[1.2 Grounding DINO 1.5 Edge:面向边缘的高效设计](#1.2 Grounding DINO 1.5 Edge:面向边缘的高效设计)
[1.3 训练数据:Grounding-20M](#1.3 训练数据:Grounding-20M)
[1.4 评估:零样本迁移与微调性能](#1.4 评估:零样本迁移与微调性能)
[2. Grounding DINO 1.6:数据扩容与提示微调](#2. Grounding DINO 1.6:数据扩容与提示微调)
[2.1 更强的 Pro 版本:数据驱动](#2.1 更强的 Pro 版本:数据驱动)
[2.2 Edge 版本再优化:特征与查询的精简](#2.2 Edge 版本再优化:特征与查询的精简)
[2.3 监督提示微调(SPT):面向场景的轻量定制](#2.3 监督提示微调(SPT):面向场景的轻量定制)
[3. DINO-X:从检测走向统一视觉感知](#3. DINO-X:从检测走向统一视觉感知)
[3.1 模型架构:多提示输入与多任务输出](#3.1 模型架构:多提示输入与多任务输出)
[3.2 两阶段训练策略](#3.2 两阶段训练策略)
[3.3 数据规模:Grounding-100M](#3.3 数据规模:Grounding-100M)
[3.4 核心性能表现](#3.4 核心性能表现)
[3.5 Edge 版本升级](#3.5 Edge 版本升级)
[4. 架构演进总结](#4. 架构演进总结)
[5. 总结](#5. 总结)
0. 引言
开放集目标检测(Open-Set Object Detection)的目标是让模型能够检测出任意类别的物体,而不局限于训练集中出现的类别。近年来,随着视觉-语言预训练的发展,目标检测正逐步从 "闭集" 走向 "开放世界"。
(2024|ECCV|清华 & IDEA,特征融合,子句级文本特征,特征增强)Grounding DINO:将 DINO 与基于实例的预训练结合以实现开集目标检测
这一演进的技术源头,可以追溯到 Grounding DINO 的提出。Grounding DINO 首次将 DETR 系列检测器与 grounded pre-training 深度结合,通过 紧耦合的多模态融合架构,实现了开放集检测能力的突破。
在此基础之上,IDEA Research 持续深耕,先后发布了 Grounding DINO 1.5 (性能与效率双轨突破)、Grounding DINO 1.6 (数据扩容与提示微调),以及最新的 DINO-X(统一视觉感知模型)。
本文不局限于整体性能对比,而是 聚焦模型架构与改进细节,从 Grounding DINO 的源头设计出发,逐代解读每一代模型在结构、训练策略、数据构建上的演进逻辑。
1. Grounding DINO 1.5:性能与效率的双轨突破
Grounding DINO 1.5 系列包含两个核心模型:
-
Grounding DINO 1.5 Pro:面向高性能场景,追求更强的泛化能力
-
Grounding DINO 1.5 Edge:面向边缘设备,追求高效推理
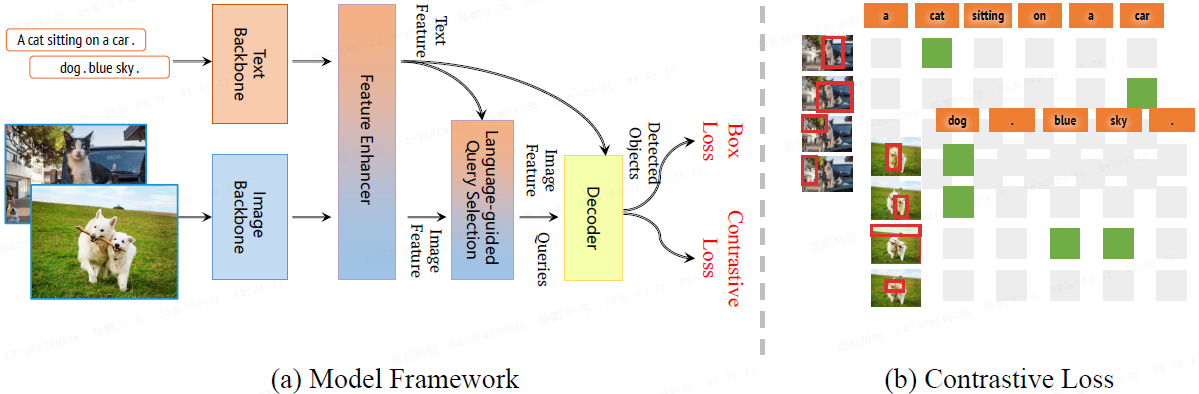
1.1 Grounding DINO 1.5 Pro:早融合的潜力与平衡
模型架构 :Pro 版本沿用了 Grounding DINO 的 双编码器-单解码器 结构,但将视觉骨干网络从 Swin Transformer 升级为 ViT-L,利用了其纯 Transformer 设计在训练与推理优化上的优势。
早融合 vs 晚融合 :一个关键设计点是 特征融合时机。
-
早融合 :在解码器(Decoder)之前就通过交叉注意力进行图文交互。这种方式能够提高检测召回率(recall)与框精度(precision),但容易引入幻觉(预测不存在的物体)。
-
晚融合:仅在损失计算阶段融合图文特征,鲁棒性更强,但对齐难度更高,召回率偏低。
Grounding DINO 1.5 Pro 保留早融合架构 ,但通过 增加训练中的负样本比例来抑制幻觉,在性能与鲁棒性之间取得了更好的平衡。
1.2 Grounding DINO 1.5 Edge:面向边缘的高效设计
Grounding DINO 利用多尺度图像特征和强计算特征增强器来实现更快的训练和更出色的性能,但这种方法并不适用于现实应用场景中的实时情况。
对于需要在边缘部署的 Edge 版本,其核心目标是 降低计算成本,同时保留开放集检测能力。
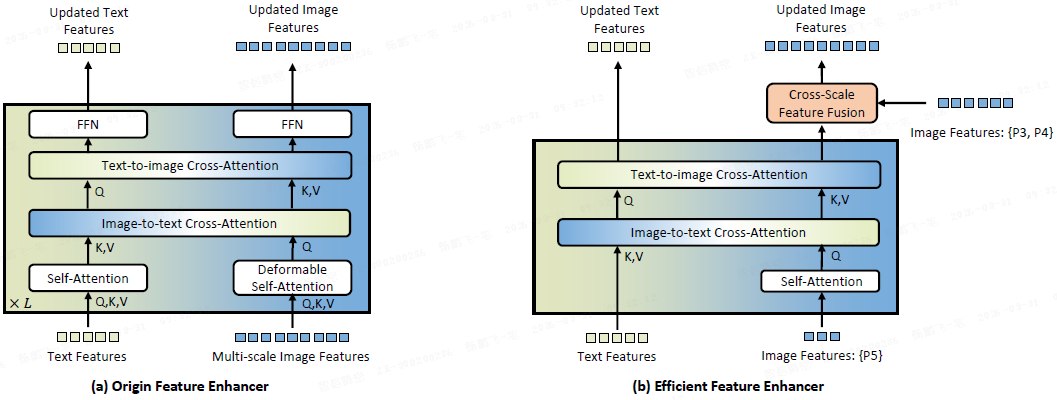
高效特征增强器:
-
多尺度特征裁剪:仅使用高层特征(P5)进行跨模态融合。研究表明,低层特征缺乏语义信息且计算开销大,裁剪后显著减少需处理的 token 数量。
-
注意力替换 :将 deformable self-attention 替换为 vanilla self-attention,更易于边缘 GPU 部署。
-
跨尺度融合:引入跨尺度特征融合模块,将低层特征(P3、P4)的信息以更轻量的方式引入,弥补语义信息损失。
骨干网络与部署:
- Edge 版本采用 EfficientViT-L1 作为图像骨干,支持快速多尺度特征提取。
- 在 NVIDIA Orin NX 上,640×640 输入下推理速度超过 10 FPS,满足了实时性要求。
1.3 训练数据:Grounding-20M
为了支撑两个模型的训练,团队构建了 Grounding-20M 数据集,包含 20M带有 grounding 标注的图像,覆盖了丰富的检测场景,并通过精细的标注流程与后处理规则保证了数据质量。
1.4 评估:零样本迁移与微调性能
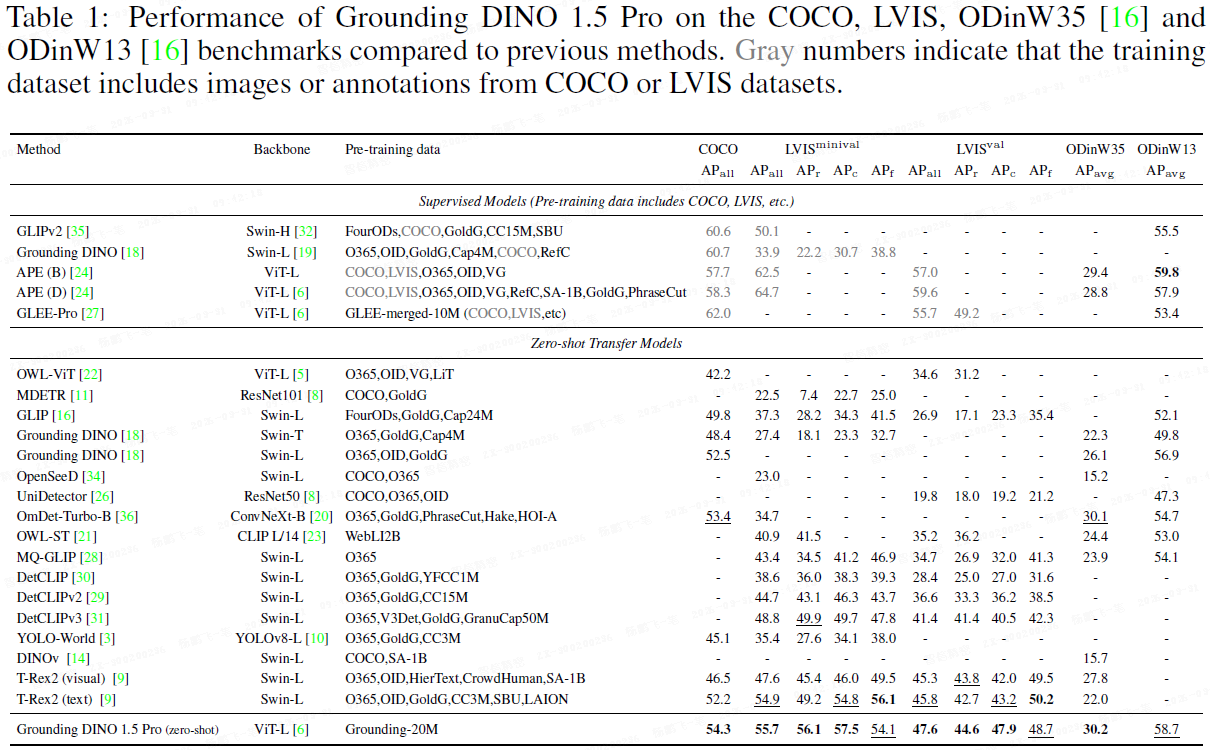
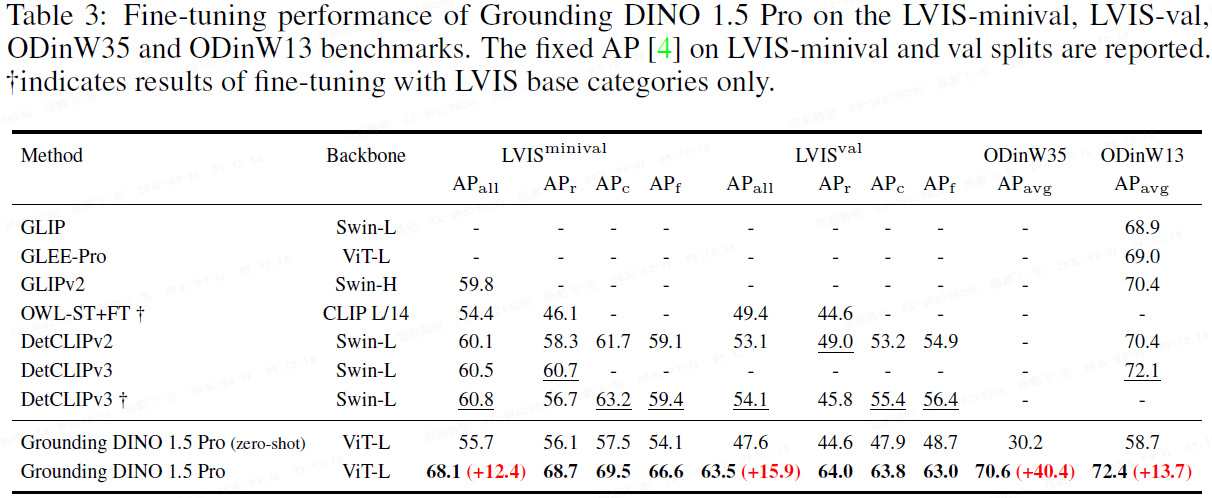
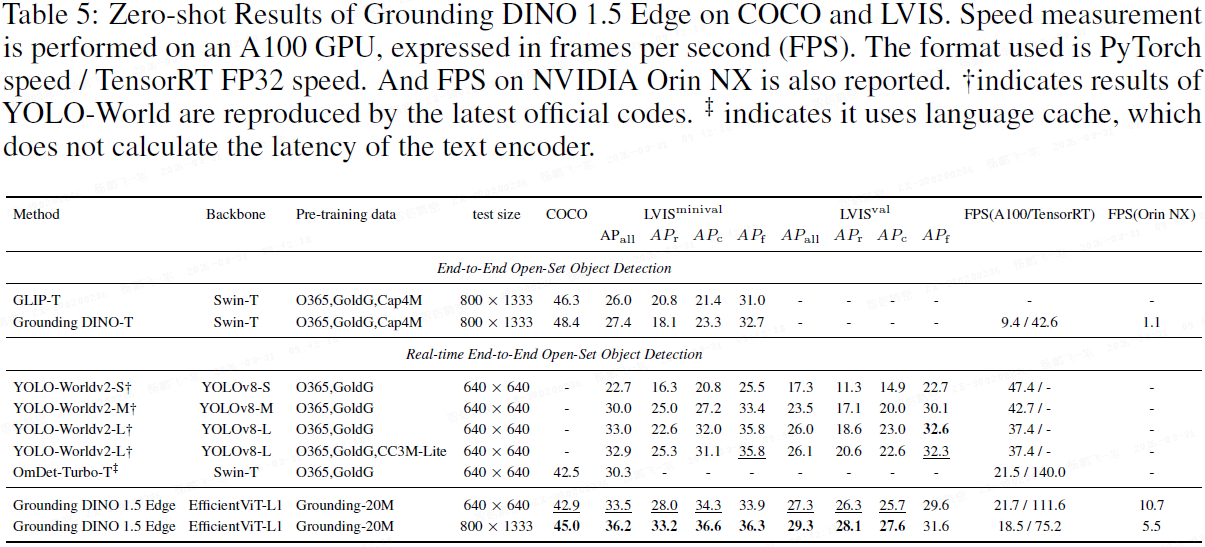
2. Grounding DINO 1.6:数据扩容与提示微调
在 1.5 的基础上,Grounding DINO 1.6 系列进一步提升了性能与实用性。
2.1 更强的 Pro 版本:数据驱动
Pro 版本的训练数据从 20M 扩展到 Grounding-30M,数据质量同步提升。
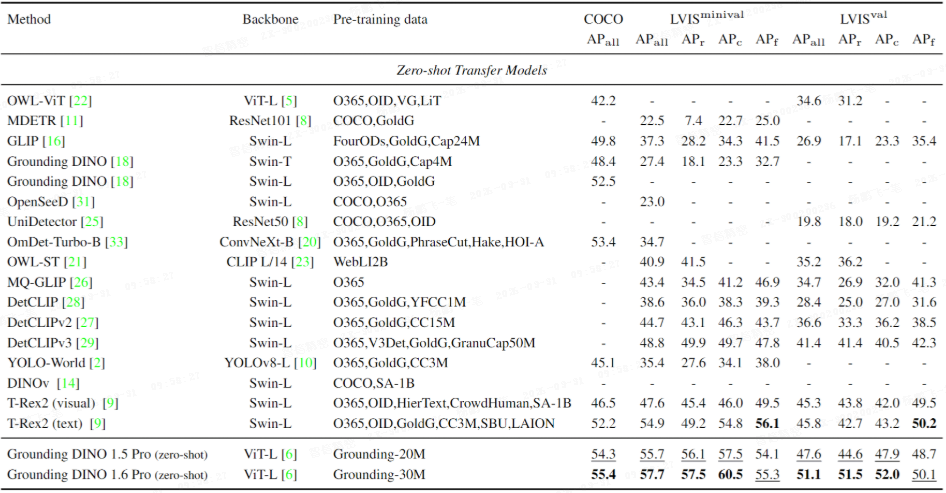
在零样本评测中,1.6 Pro 相比 1.5 Pro 在 COCO、LVIS-minival、LVIS-val 上分别提升 +1.1、+2.0、+3.5 AP,尤其在 LVIS rare 类别上提升显著。
2.2 Edge 版本再优化:特征与查询的精简
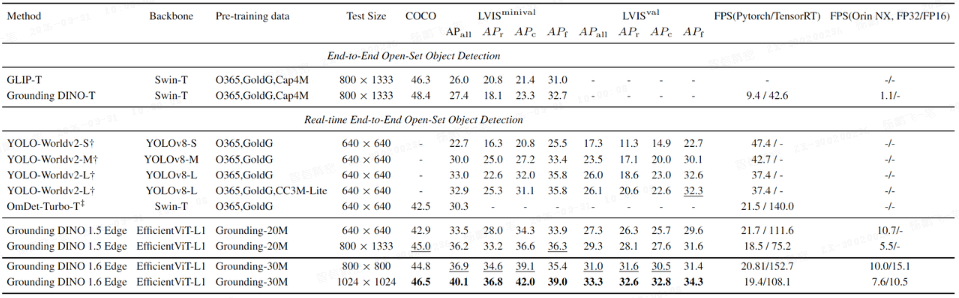
1.6 Edge 在 1.5 Edge 基础上进一步优化:
-
特征层级精简:移除 P3,仅使用 P4、P5、P6 特征
-
查询数量缩减:从 900 减少到 300,贴合实际场景中单图目标数不超过 300 的分布
-
去噪策略增强:去噪数(DN)从 100 增加到 300,加快收敛
-
FP16 支持 :在 NVIDIA Orin NX 上实现 FP16 推理,800×800 输入下达到 14 FPS,相比 1.5 Edge(640×640 下 10 FPS)提升 40%
在视觉检测模型中,P3、P4、P5、P6 指的是多尺度特征金字塔 (Feature Pyramid Network, FPN)中的不同层级。它们来源于骨干网络(如 Swin Transformer、EfficientViT)不同阶段的输出,分别对应不同的 下采样倍数 和 语义抽象程度。
以下是这些特征层的具体定义与特点:
1)特征层定义
-
P3 :下采样倍率为 8 倍(即特征图尺寸为原图的 1/8)。它拥有最高的空间分辨率,包含丰富的 细节信息 (如边缘、纹理),但 语义信息较弱,计算成本也最高。
-
P4:下采样倍率为 16 倍。在空间细节与语义信息之间起到平衡作用。
-
P5 :下采样倍率为 32 倍。分辨率较低,但具有更强的 语义信息(能判断 "这是什么物体"),是开放集检测中最常用的特征层。
-
P6 :下采样倍率为 64 倍(通常通过在 P5 基础上增加一个卷积层得到)。主要为了扩大感受野,专门用于检测极大的物体,或为深层 Transformer 提供全局上下文。
2)为何在边缘模型中侧重 P4、P5、P6?
在 Grounding DINO 1.5 Edge 及后续的 DINO-X Edge 中,为了在 NVIDIA Orin NX 等边缘设备上实现实时推理,模型采取了 "移除 P3,仅使用 P4、P5、P6" 的优化策略,原因如下:
-
计算效率 :P3 的 token 数量是 P4 的 4 倍、P5 的 16 倍。移除 P3 可以大幅减少特征增强器(Feature Enhancer)和 Transformer 解码器需要处理的序列长度,这是提升 FPS(从 10 FPS 到 20 FPS)的关键。
-
语义充足 :在开放集检测中,模型主要依赖 语义信息来识别文本提示对应的物体。P3 虽然细节丰富,但缺乏高层语义,对识别 "未见过的类别" 帮助有限。P5 和 P6 经过深层网络提取,语义更丰富,更适合跨模态对齐。
-
跨尺度融合 :虽然移除了 P3,但 Edge 版本引入了跨尺度特征融合模块。它通过 P4 和 P5 的上下采样来"模拟"低层细节特征,在不引入 P3 巨大计算量的前提下,尽可能保留了小目标的检测能力。
2.3 监督提示微调(SPT):面向场景的轻量定制
SPT 是一种 **仅更新提示嵌入(prompt embeddings)**的微调方法,适用于少量标注样本的场景。
-
核心思想:将传统 "文本提示" 转化为 "视觉提示",通过少量标注图像学习一个最优提示向量,在推理时替代文本输入。
-
效果验证:在 LVIS 划分的 12 个行业场景中,SPT+GD1.6 的检测精度显著优于 YOLOv8;尤其在训练样本极少时,SPT 优势更加明显。
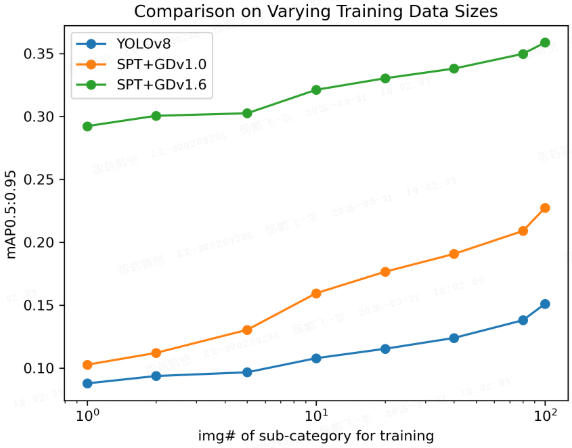
3. DINO-X:从检测走向统一视觉感知
DINO-X 是 IDEA Research 最新发布的统一视觉模型,不仅在检测能力上再创新高,还集成了分割、姿态估计、区域理解等多种能力。
3.1 模型架构:多提示输入与多任务输出
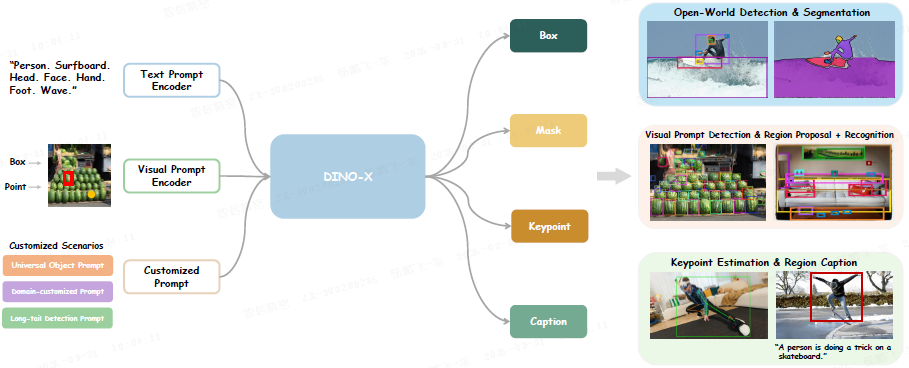
DINO-X Pro 模型架构
**1)核心架构:**与 Grounding DINO 1.5 相似,使用了一个预训练的 ViT 模型作为其主要的视觉骨干网络,并在特征提取阶段采用了深度早期融合策略。
**2)多模态输入:**与 Grounding DINO 1.5 不同,为了进一步增强模型对长尾对象的检测能力,在 DINO-X Pro 的输入阶段扩大了提示支持范围。
-
文本提示:传统开放集检测
-
视觉提示:通过点或框的示例指定目标,适用于小样本或难以文本描述的场景
-
定制化提示:通过提示微调等方法学习定制化提示嵌入
-
无提示检测:通过通用目标提示(universal object prompt),无需任何输入即可检测图像中的所有物体
**3)文本编码器:**与使用 BERT(仅在文本数据上训练)的 Grounding DINO 和 Grounding DINO 1.5 不同,DINO-X Pro 使用在多模态数据上训练的 CLIP 编码器
4)视觉提示编码器:沿用 T-Rex2 的设计,支持框和点形式的视觉提示,通过可变形交叉注意力提取多尺度特征。
**5)多任务输出:**输入图像与提示融合后,送入不同任务头:
-
框头:采用语言引导的查询选择,经 Transformer 解码器与 MLP 预测边界框,使用 L1、G-IoU 和对比损失。
-
掩码头:融合 1/4 和 1/8 分辨率特征构建像素嵌入图,与查询点积生成掩码,仅对采样点计算掩码损失。
-
关键点头:将检测结果扩展为关键点查询,经可变形解码器预测位置与可见性,支持人体(17 点)和手部(21 点)。
-
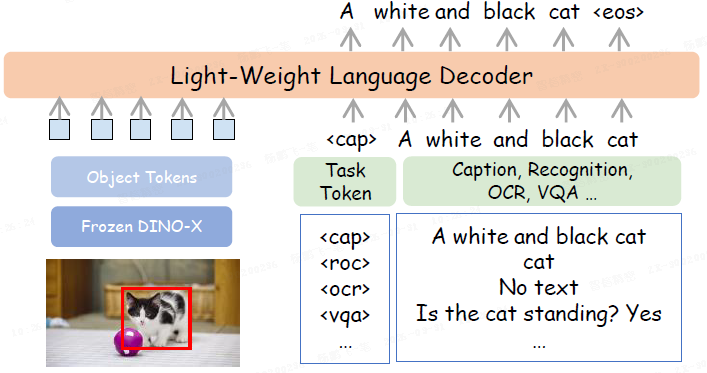
语言头:轻量生成式模型,利用 RoIAlign 提取区域特征,结合可学习任务 token,自回归完成区域识别、描述、VQA 等任务(如下图所示)。
3.2 两阶段训练策略
为平衡多任务训练难度与核心检测能力,DINO-X 采用了两阶段训练:
-
第一阶段 :联合训练文本提示检测、视觉提示检测、分割任务。这一阶段使用 Grounding-100M 数据集,确保核心接地能力的强大。
-
第二阶段:冻结骨干网络,分别训练关键点头和语言头。这种方式保证了新增任务不会影响基础检测性能,同时验证了大规模接地预训练可以作为 "物体中心模型" 的坚实基础。
3.3 数据规模:Grounding-100M
DINO-X 的预训练数据扩展至 100M 图像,涵盖:
-
网页图像与 grounding 标注
-
通过 SAM/SAM2 生成的伪掩码(用于分割头训练)
-
超过 1000 万条区域理解数据(识别、描述、OCR、区域 QA)
3.4 核心性能表现
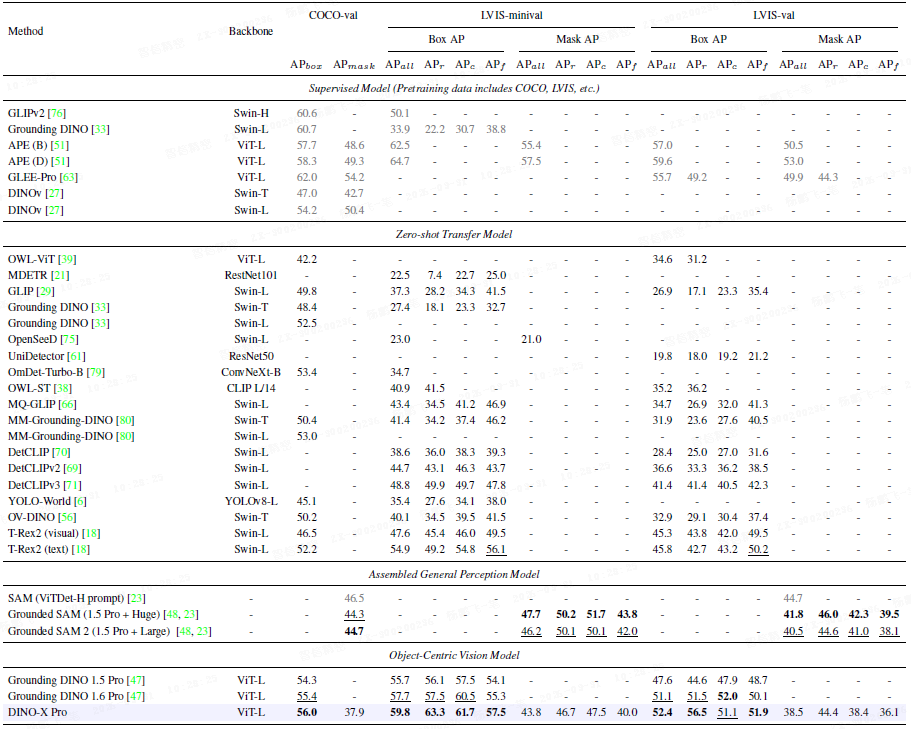
在 LVIS rare 类别上,DINO-X Pro 达到 63.3 AP(minival),相比 GD 1.6 Pro 提升 5.8 AP,展现了极强的长尾目标检测能力。
3.5 Edge 版本升级
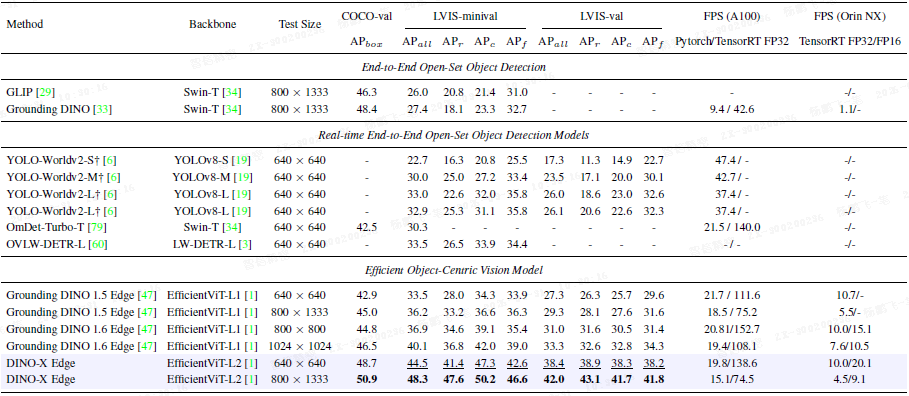
DINO-X Edge 在 1.6 Edge 基础上进一步优化:
-
更强的文本编码器:基于 CLIP,提升区域级图文对齐能力,且不增加推理延迟
-
知识蒸馏:从 Pro 模型进行特征级与响应级蒸馏,增强零样本能力
-
FP16 优化 :推理速度提升至 20.1 FPS(640×640),相比 1.6 Edge 提升 33%
4. 架构演进总结
| 版本 | 核心模型 | 视觉骨干 | 融合策略 | 关键架构创新 | 边缘性能 |
|---|---|---|---|---|---|
| Grounding DINO | --- | Swin-T/L | 早融合(neck + query + decoder) | 开创性提出三阶段紧耦合融合、子句级文本特征 | --- |
| Grounding DINO 1.5 | Pro / Edge | ViT-L / EfficientViT-L1 | 早融合(Pro) | 高效特征增强器(Edge)、负样本平衡 | 10+ FPS (640) |
| Grounding DINO 1.6 | Pro / Edge | 同上 | 同上 | 特征层级精简、查询缩减、SPT | 14 FPS (800) |
| DINO-X | Pro / Edge | ViT-L / EfficientViT-L2 | 多提示输入 | CLIP 文本编码器、四任务头、无提示检测、蒸馏(Edge) | 20 FPS (640) |
从架构视角来看,技术演进呈现出三条清晰的主线:
-
融合策略的深化:Grounding DINO 开创性地在 neck、query 初始化、decoder 三个阶段都引入跨模态融合,实现了 "紧耦合" 设计;后续版本在早融合框架下不断优化平衡点,DINO-X 则进一步扩展为多提示输入的灵活架构,并实现无提示检测。
-
边缘部署的极致优化:从 Grounding DINO 1.5 Edge 的高效特征增强器,到 1.6 Edge 的特征层级精简与查询缩减,再到 DINO-X Edge 的知识蒸馏与 FP16 优化,不断刷新边缘设备上的性能-速度边界。
-
任务能力的横向扩展:从 Grounding DINO 专注于检测任务,到 1.5 系列区分 Pro/Edge 双轨,再到 DINO-X 全面覆盖分割、姿态、区域理解,向 "统一视觉感知模型" 演进。
5. 总结
开放集目标检测正从一个 "学术任务" 逐步走向 "工业级基础能力"。从 Grounding DINO 到 DINO-X 的演进,展现了 开创性架构 + 数据驱动 + 多任务融合的清晰路径。
其中,以下几个架构设计思路尤其值得关注:
-
Grounding DINO 的三阶段紧耦合融合 :在 neck、query 初始化、decoder 三个层级都引入跨模态交互,为后续所有版本奠定了 "早融合" 的技术基调。其提出的 子句级文本特征(通过注意力掩码隔离无关类别)也为开放集检测的文本编码提供了更优方案。
-
早融合 + 负样本平衡:在 1.5 Pro 中通过增加负样本比例抑制幻觉,为多模态模型平衡性能与鲁棒性提供了可复用的经验。
-
SPT 提示微调:展示了 "轻量定制" 在工业场景中的巨大潜力,仅更新提示嵌入即可适应新场景。
-
DINO-X 的两阶段训练:先训练核心接地能力,再冻结骨干扩展新任务,为构建 "物体中心" 的统一视觉模型提供了可行范式。
-
边缘模型的多轮迭代:从 1.5 Edge 的高效特征增强器,到 1.6 Edge 的特征与查询精简,再到 DINO-X Edge 的蒸馏与 FP16 优化,证明高效不等于简单裁剪,而是通过架构与蒸馏的协同优化实现。