1. 研究背景
在量化交易领域,准确识别当前及未来的"市场结构"是策略能否获利的关键。传统的趋势过滤工具(如均线、通道)往往在行情转换期表现滞后。本文将探讨如何通过机器学习中的随机森林(Random Forest)模型,结合 Zorro 回测框架与 R 语言的高级计算能力,构建一个能够预测未来市场结构的分类模型。
本文不仅涵盖了底层的技术实现逻辑,还将通过"基准策略"与"机器学习策略"的对比实验,客观评估机器学习在实际交易中的增量价值。
2. 通用机器学习模型架构
2.1 工作原理与交互流程
在 Zorro 框架下,机器学习任务通常通过 adviseLong(NEURAL) 函数驱动,并利用 neural 桥函数与外部 R 脚本进行高效交互。其核心工作流如下:
adviseLong(NEURAL):主入口函数,触发外部机器学习模型的训练与预测任务。neural桥函数:负责 C 与 R 语言之间的数据传递与状态同步。- 自定义 R 脚本:利用 R 丰富的统计包(如
ranger)执行具体的模型训练、预测及序列化操作。
2.2 Neural 函数的状态管理
neural 函数根据当前策略的生命周期,通过不同的 Status 参数执行相应的操作:
- NEURAL_INIT :在
INITRUN后调用,用于初始化 R 运行环境及加载机器学习库。 - NEURAL_EXIT :在
EXITRUN后执行,负责清理内存与释放资源。 - NEURAL_TRAIN:在 WFO 训练周期结束时触发,执行模型拟合。
- NEURAL_PREDICT :在测试或交易模式下,调用
advise生成实时预测。 - NEURAL_SAVE / NEURAL_LOAD:负责将训练好的模型持久化到本地,并在回测/实盘开始前重新加载。
2.3 R 脚本接口规范
用户需要实现一个与策略同名的 .r 文件,其中包含以下标准接口:
neural.init():初始化包环境。neural.train(model, XY):接收特征矩阵XY(最后一列为目标变量),执行模型训练。neural.save(filename)/neural.load(filename):模型的保存与读取。neural.predict(model, X):基于特征向量X输出预测类别。
3. 特征工程与目标变量
3.1 目标变量:未来市场结构
我们的研究目标是预测未来 24 小时(4 小时图,未来 6 根 K 线)的市场结构。
为了量化市场状态,我们采用以下逻辑定义目标变量:
- 基准趋势:应用低通滤波器(Lowpass Filter)对收盘价进行平滑,识别长期趋势线。
- 动态通道 :根据 ATR 计算趋势线的波动通道。
- 三类标签 :
- +1 (看涨):趋势线上升且价格突破通道上轨。
- -1 (看跌):趋势线下降且价格跌破通道下轨。
- 0 (震荡):不满足上述条件的其余状态。
3.2 特征选择
为了多维度描述市场行为,我们选择了 5 个互补性指标作为模型的输入特征:
| 指标 | 类型 | 公式 |
|---|---|---|
| AtrRatio | 波动率 | ATR(20)/ATR(100) |
| Distance2Trend | 趋势 | Price/Lowpass(Price,200) - 1 |
| FractalDimension | 市场状态 | FractalDimension(Price,50) |
| MACDHistogram | 动能加速度 | MACD(12,26,9) |
| AroonOscillator | 市场微观结构 | AroonOsc(200) |
4. 随机森林分类模型
我们选择 ranger 包来实现随机森林,因其在处理大规模数据集时具有极高的计算效率。
r
library(ranger)
# 定义全局日志文件路径(Zorro 调用 R 时,工作目录通常是 Zorro 根目录)
LOG_FILE <<- "Log/R_ml_rf_v1.log"
# -----------------------------------------------------------------------
# 自定义日志函数
# -----------------------------------------------------------------------
write_log = function(...) {
# 格式化时间戳 and 消息
msg <- sprintf(...)
timestamp <- format(Sys.time(), "%Y-%m-%d %H:%M:%S")
out_str <- sprintf("[%s] %s\n", timestamp, msg)
# 追加写入文件 (如果文件或 Log 目录不存在,只需确保 Zorro/Log 文件夹存在即可)
cat(out_str, file = LOG_FILE, append = TRUE)
# 同时打印到控制台(可选)
# cat(out_str)
}
# -----------------------------------------------------------------------
# 初始化函数
# -----------------------------------------------------------------------
neural.init = function() {
# 设置随机数种子
set.seed(42)
# 初始化全局模型列表
Models <<- vector("list")
write_log("[NEW ZORRO RUN]")
write_log("Ranger (Random Forest) 初始化成功. 全局模型列表已建立.")
}
# -----------------------------------------------------------------------
# 训练函数
# -----------------------------------------------------------------------
neural.train = function(model_id, XY) {
colnames(XY)[ncol(XY)] <- "target"
XY$target <- factor(XY$target, levels = c(-1, 0, 1))
# 记录训练开始及样本量
write_log("开始训练模型 ID: %d, 样本总数: %d", model_id, nrow(XY))
# 统计目标变量的分布 (排查是否缺乏某类样本)
dist_table <- table(XY$target)
dist_str <- paste(names(dist_table), dist_table, sep=":", collapse=" | ")
write_log("模型 ID: %d 类别分布: [ %s ]", model_id, dist_str)
# 调用 ranger 训练模型
rf_model <- ranger(
formula = target ~ .,
data = XY,
num.trees = 500,
mtry = 2,
importance = "impurity",
probability = FALSE,
min.node.size = 50
)
# 记录模型的 OOB 错误率
oob_err <- rf_model$prediction.error * 100
write_log("模型 ID: %d 训练完成, OOB 错误率: %.2f%%", model_id, oob_err)
# 记录特征重要性 (对于分析哪些指标有效非常有帮助)
imp <- sort(rf_model$variable.importance, decreasing = TRUE)
imp_str <- paste(names(imp), round(imp, 4), sep="=", collapse=", ")
write_log("模型 ID: %d 特征重要性排序: %s", model_id, imp_str)
Models[[model_id]] <<- rf_model
}
# -----------------------------------------------------------------------
# 预测函数
# 注意:严禁在此处使用 write_log,否则高频 I/O 会导致回测极度缓慢
# -----------------------------------------------------------------------
neural.predict = function(model_id, X) {
X_df <- as.data.frame(t(X))
colnames(X_df) <- paste0("V", 1:ncol(X_df))
rf_model <- Models[[model_id]]
pred_obj <- predict(rf_model, data = X_df)
pred_class <- pred_obj$predictions[1]
return(as.numeric(as.character(pred_class)))
}
# -----------------------------------------------------------------------
# 保存模型函数
# -----------------------------------------------------------------------
neural.save = function(name) {
save(Models, file = name)
write_log("WFO 周期结束. 模型已保存至: %s", name)
}
# -----------------------------------------------------------------------
# 读取模型函数
# -----------------------------------------------------------------------
neural.load = function(name) {
load(name, envir = .GlobalEnv)
write_log("开始测试/实盘. 成功加载模型文件: %s", name)
}5. 交易策略
我们将 BTCUSDT 的 4 小时数据作为样本(2018-2025年),通过 WFO(Walk-Forward Optimization)将其划分为 10 轮滚动训练集/测试集。策略在训练集上学习市场结构,并在测试集中生成预测信号。
5.1 策略脚本代码
c
/*
使用随机森林模型预测市场结构。
*/
#include <profile.c>
#include <utils.c>
#include <myindicators.c>
#include <r.h>
void tradeStrategy() {
// ==================== 计算指标 ====================
vars Prices = series(price());
vars Trends = series(LowPass(Prices,200));
vars Dist2Trends = series(Prices[0]/Trends[0]-1);
vars Regimes = series(FractalDimension(Prices,50));
MACD(Prices,12,26,9);
vars Moms = series(rMACDHist);
var ATR100 = ATR(100);
vars VolaRatios = series(ATR(20)/ATR100);
vars Aroons = series(AroonOsc(200));
int StPeriod = 10;
var StFactor = 3;
vars Supertrends = series(supertrend(StFactor, StPeriod));
// ==================== 目标变量 ====================
var ChannelUpper = Trends[0]+1.*ATR100;
var ChannelLower = Trends[0]-1.*ATR100;
var Target = 0;
if(rising(Trends) && Prices[0] > ChannelUpper) {
Target = 1;
} else if (falling(Trends) && Prices[0] < ChannelLower) {
Target = -1;
}
// ==================== 机器学习 ====================
int Offset = ifelse(Train, 6, 0);
var Prediction = adviseLong(NEURAL, Target,
Dist2Trends[Offset],
Regimes[Offset],
Moms[Offset],
VolaRatios[Offset],
Aroons[Offset]);
// ==================== 交易逻辑 ====================
if(!Train) {
bool LongEntry = Prediction > 0 && priceC() > Supertrends[0];
bool LongExit = Prediction < 0 || priceC() < Supertrends[0];
bool ShortEntry = Prediction < 0 && priceC() < Supertrends[0];
bool ShortExit = Prediction > 0 || priceC() > Supertrends[0];
if(NumOpenLong > 0 && LongExit) exitLong();
if(NumOpenShort > 0 && ShortExit) exitShort();
if(NumOpenLong == 0 && LongEntry) enterLong();
if(NumOpenShort == 0 && ShortEntry) enterShort();
}
// ==================== 图表 ====================
if(Test && !is(LOOKBACK)) {
// plot("Dist2Trend", Dist2Trends, NEW, RED);
// plot("Regime", Regimes, NEW, RED);
// plot("MACDHist", Moms, NEW, RED);
// plot("VolaRatio", VolaRatios, NEW, RED);
// plot("AroonOsc", Aroons, NEW, RED);
plot("ChannelUpper", ChannelUpper, MAIN|BAND1, GREY);
plot("ChannelLower", ChannelLower, MAIN|BAND2, GREEN+TRANSP);
plot2("Supertrend", Supertrends[0], MAIN, priceC()>Supertrends[0], GREEN, RED);
plot("Prediction", Prediction, NEW|BARS, GREEN+TRANSP);
}
}
function run() {
// --------------------------------------------------------- //
// Zorro 设置
// --------------------------------------------------------- //
// 日志
set(LOGFILE);
Verbose = 3;
// 图表
set(PLOTNOW);
setf(PlotMode,PL_DIFF);
PlotScale = 8;
PlotHeight2 = 320;
// 训练
set(RULES);
setf(TrainMode,TRADES);
DataSplit = 85;
NumWFOCycles = 10;
// NumCores = 0;
// k线生成规则,7*24小时交易
resf(BarMode,BR_WEEKEND);
StartWeek = 0;
EndWeek = 62359;
StartMarket = 0;
EndMarket = 2359;
BarPeriod = 240;
BarZone = UTC;
BarOffset = 0;
TickFix = 60000;
if(Live) TickFix = 0;
// 测试样本
StartDate = 20180101;
EndDate = 20251230;
LookBack = 5000;
// 下一根k线开盘时进场/平仓
Fill = 3;
// 固定头寸
Lots = 100;
// --------------------------------------------------------- //
// 策略逻辑
// --------------------------------------------------------- //
asset("BTCUSDT");
Leverage = 5;
MarginCost = priceClose()*LotAmount/Leverage;
tradeStrategy();
}6. 回测结果分析
6.1 训练日志
根据训练日志,随机森林在训练集上的表现极其稳健,平均 OOB(袋外)错误率仅为 15% 左右,表明模型对历史数据的市场结构具有极强的解释力。
c
[2026-03-31 16:43:19] [NEW ZORRO RUN]
[2026-03-31 16:43:19] Ranger (Random Forest) 初始化成功. 全局模型列表已建立.
[2026-03-31 16:43:19] 开始训练模型 ID: 1, 样本总数: 6771
[2026-03-31 16:43:19] 模型 ID: 1 类别分布: [ -1:2044 | 0:2159 | 1:2568 ]
[2026-03-31 16:43:22] 模型 ID: 1 训练完成, OOB 错误率: 15.20%
[2026-03-31 16:43:22] 模型 ID: 1 特征重要性排序: V1=2016.4813, V5=477.1938, V4=313.6185, V2=238.2223, V3=227.21676.2 预测结果可视化
在样本外数据中,模型生成的标签能够较好地捕捉趋势:
- +1:精准识别上升大趋势。
- -1:识别明显的下跌波段。
- 0:识别趋势放缓或震荡。
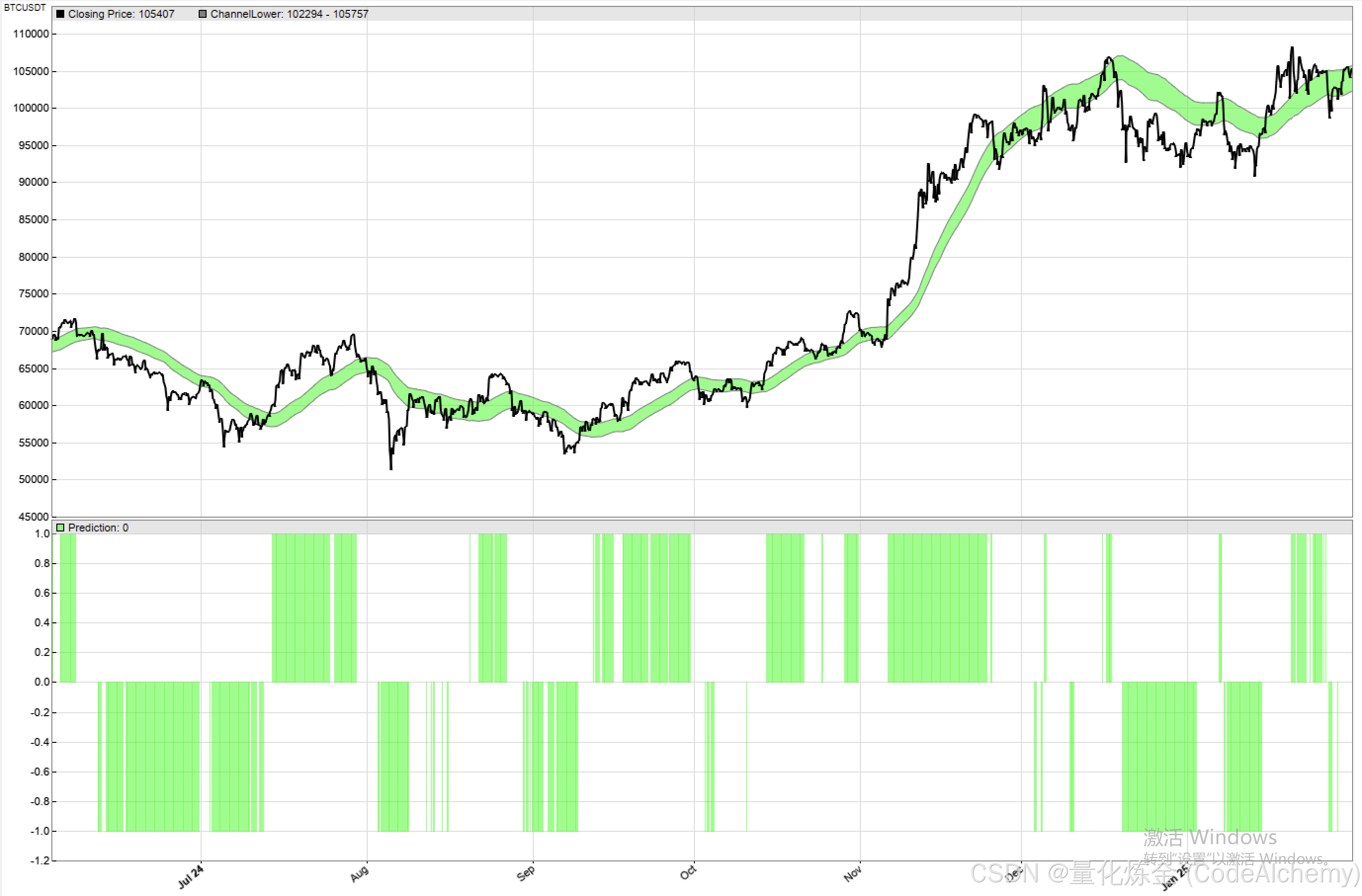
然而在宽幅震荡行情中,预测类别会出现频繁的跳跃,这意味着单纯将模型预测作为择时信号可能并不可靠。
6.3 对照实验
为了评估机器学习的增量价值,我们将"机器学习策略"与"基于过滤器的基准策略"进行了对比分析。
基准策略
- 使用趋势线通道划分市场结构(跟定义目标变量的算法相同)
- 趋势线上升且价格高于通道上轨,上涨趋势
- 趋势线下降且价格低于通过下轨,下跌趋势
- 其余状态记为震荡状态
- 上涨趋势 且 超级趋势看涨,做多
- 市场结构转为下跌 或 超级趋势转为看空,多头平仓
- 下跌趋势 且 超级趋势看空,做空
- 市场结构转为上涨 或 超级趋势转为看涨,空头平仓
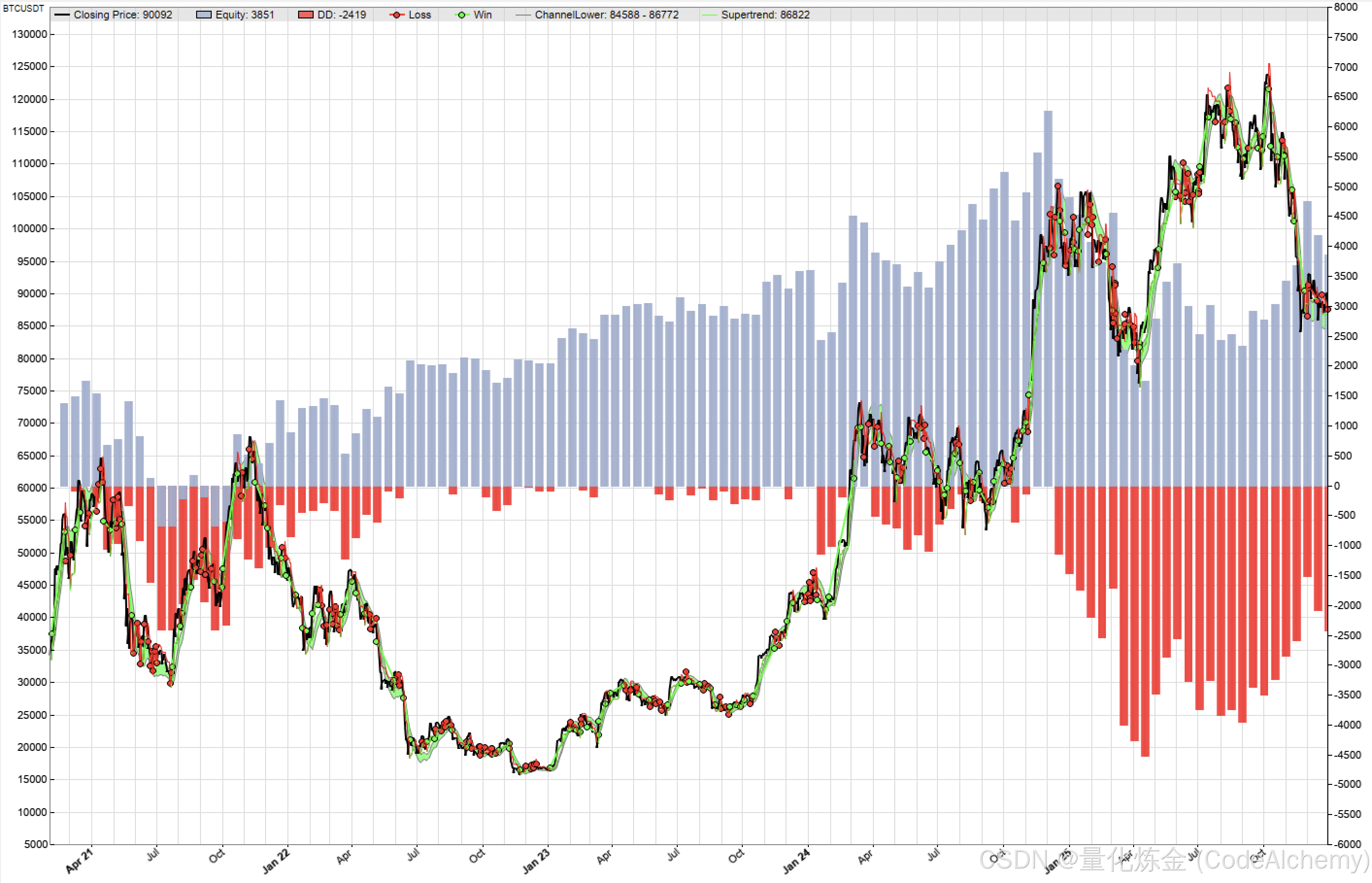
机器学习策略
- 构建随机森林模型,预测未来一天的市场结构,作为市场结构滤波器
- 市场结构看涨 且 超级趋势看涨,做多
- 超级趋势从上涨转为下跌 或 市场结构看空,多头平仓
- 市场结构看空 且 超级趋势看空,做空
- 超级趋势从下跌转为上涨 或 市场结构看涨,空头平仓
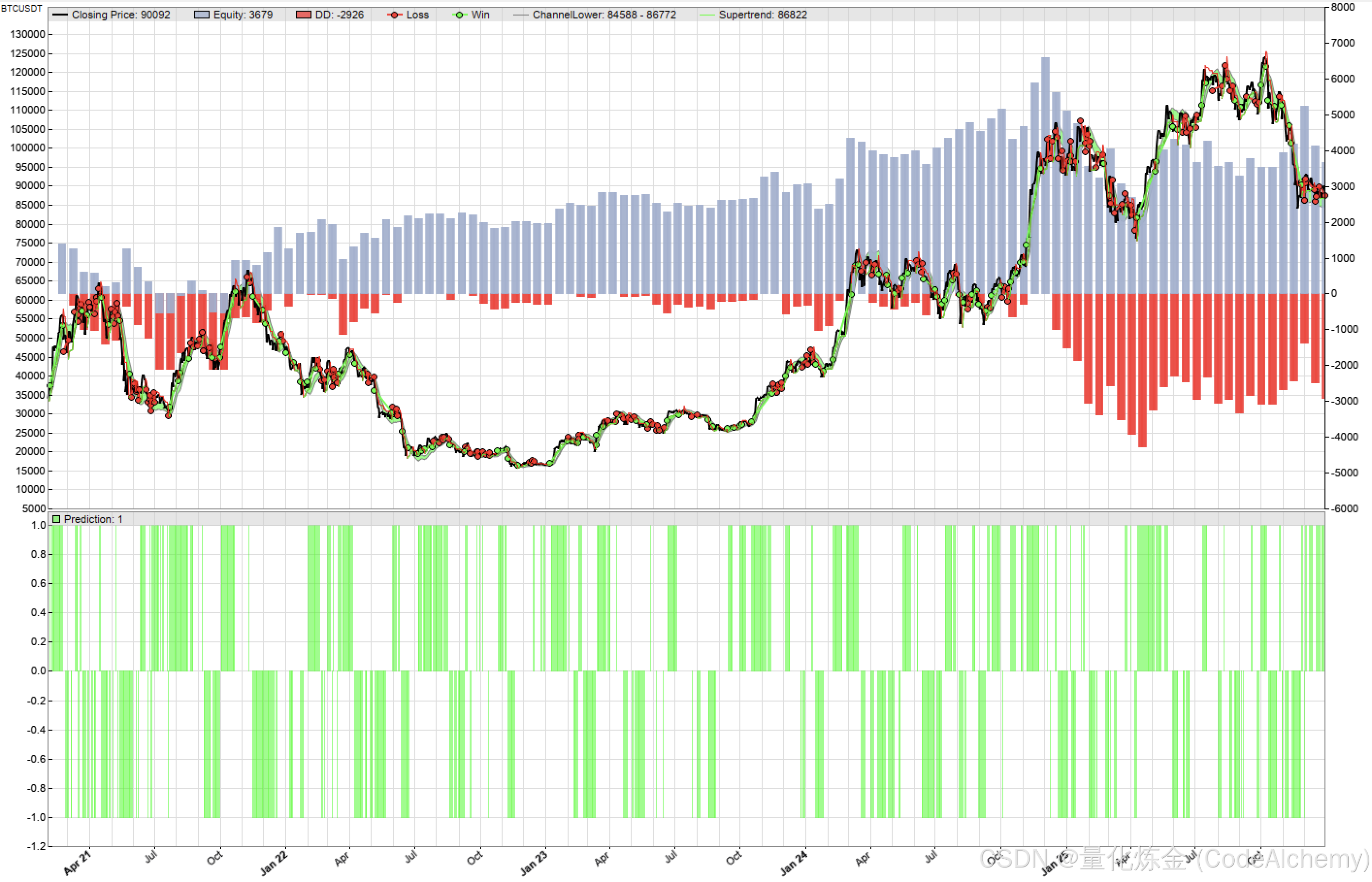
策略表现对比:
| 业绩指标 | 基准策略 | 机器学习策略 |
|---|---|---|
| 最大回撤 | 81% | 73.5% |
| 最长回撤周数 | 25 | 28 |
| 交易次数 | 169 | 163 |
| 年均交易次数 | 35 | 34 |
| 胜率 | 38% | 36% |
| 最长连续亏损 | 7 | 11 |
| 年收益率 | 12% | 12% |
| 盈利因子 | 1.17 | 1.17 |
| PRR | 0.93 | 0.93 |
| 夏普比率 | 0.29 | 0.28 |
| R2 | 40% | 37% |
| 多头盈利因子 | 1.57 | 1.61 |
| 空头盈利因子 | 0.82 | 0.82 |
7. 结论与反思
- 机器学习策略与基准策略的综合表现(盈利因子均为1.17)几乎一致。这意味着在目前的特征工程和目标设定下,随机森林并没有提供显著优于传统线性过滤器的预测能力。
- 在 2023 年底的上涨行情中,市场出现短暂回调,模型误判为趋势转折并连续做空导致 3 次止损,而基准策略仅止损 1 次。
- 在宽幅震荡转趋势的临界点,随机森林的反应往往慢于基于规则的基准策略。
最初的设想是通过机器学习更精准地识别市场结构,但实验证明,随机森林在宽幅震荡或趋势中的次级回调阶段容易产生错误信号。简单地将分类结果作为开关,可能会导致策略在关键转折点表现得比传统方法更为保守且滞后。
8. 优化方向
为了进一步提升模型实战能力,我们可以从三个方向入手:
- 概率择时:不使用类别标签,而是输出多类别概率,通过设定概率阈值(如 P(+1)>0.65P(+1) > 0.65P(+1)>0.65)来提高交易信号的确定性。
- 特征优化:引入链上指标、资金费率或市场广度数据,提升特征对市场转折点的预测精度。
- 模型迭代:尝试预测能力更强的模型,如 XGBoost 和神经网络。