剪枝,形象得看,就是剪掉搜索树的分⽀,从⽽减⼩搜索树的规模,排除掉搜索树中没有必要的分⽀,优化时间复杂度。
在深度优先遍历中,有⼏种常⻅的剪枝⽅法:
- 排除等效冗余
如果在搜索过程中,通过某⼀个节点往下的若⼲分⽀中,存在最终结果等效的分⽀,那么就只需要搜索其中⼀条分⽀。 - 可⾏性剪枝
如果在搜索过程中,发现有⼀条分⽀是⽆论如何都拿不到最终解,此时就可以放弃这个分⽀,转⽽搜索其它的分⽀。 - 最优性剪枝
在最优化的问题中,如果在搜索过程中,发现某⼀个分⽀已经超过当前已经搜索过的最优解,那么这个分⽀往后的搜索,必定不会拿到最优解。此时应该停⽌搜索,转⽽搜索其它情况。 - 优化搜索顺序
在有些搜索问题中,搜索顺序是不影响最终结果的,此时搜索顺序的不同会影响搜索树的规模。因此,应当先选择⼀个搜索分⽀规模较⼩的搜索顺序,快速拿到⼀个最优解之后,⽤最优性剪枝剪掉别的分⽀。 - 记忆化搜索
记录每⼀个状态的搜索结果,当下⼀次搜索到这个状态时,直接找到之前记录过的搜索结果。记忆化搜索,有时也叫动态规划。
第一第二条在之前的DFS例题中经常出现,这篇主要介绍一下第三条和第四条
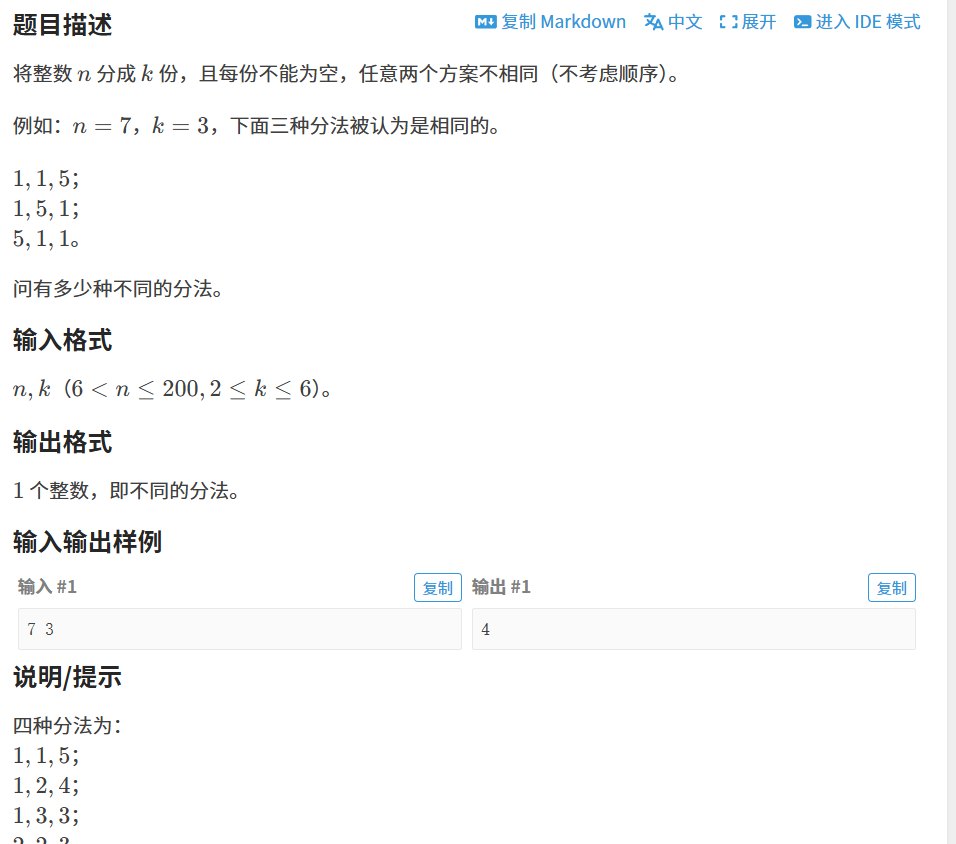
解题思路
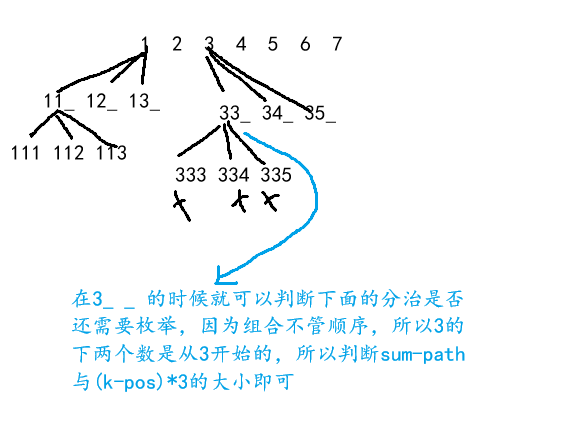
当我们填了pos 个坑时,此时总和是sum ,如果后续坑位全部都填上最⼩值都会超过sum 。说明我们之前填的数太⼤了,导致后⾯怎么填都会超过sum ,直接剪掉。
cpp
#include<iostream>
using namespace std;
int n, k;
int ret;
int path;
void dfs(int pos, int begin)
{
if (pos == k)
{
if (path == n)
{
ret++;
}
return;
}
//下次进入循环才能判断
//if ((n - path) < (k - pos) * begin)
//{
// return;
//}
for (int i = begin; i <= n; i++)
{
//未进入循环就可以判断
if ((n - path) < (k - pos) *i )
{
return;
}
path += i;
dfs(pos + 1, i);
path -= i;
}
}
int main()
{
cin >> n >> k;
dfs(0, 1);
cout << ret;
}注意
• 如果在进⼊递归之前剪枝,我们不会进⼊⾮法的递归函数中;
• 但是如果在进⼊递归之后剪枝,我们就会多进⼊很多不合法的递归函数中。
这里的dfs(0,1)从0开始是因为我们的判断条件在for循环里面,比如
进入dfs(0,3) ,判断时(n - path) < (k - pos) *i ,这里的k-pos应该是3,如果改成(1,1)则会判断错误
1.2P10483 小猫爬山
解题思路
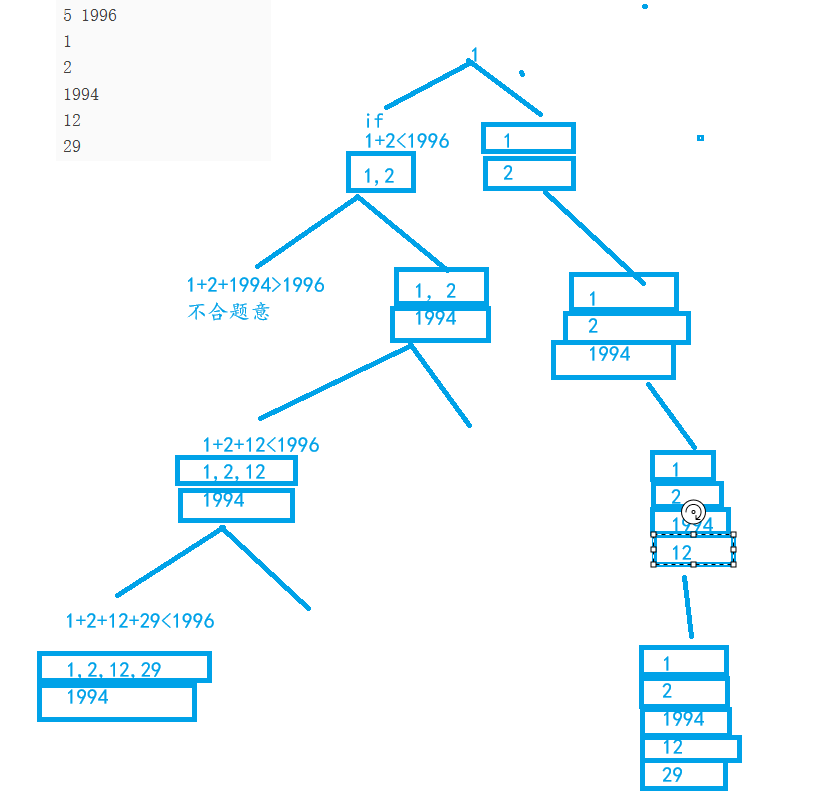
要加入一只小猫时先判断目前已有的车是否可以加上小猫而且不超重,
不行的话再单开一辆车。
• 优化枚举顺序⼀:从⼤到⼩安排每⼀只猫
重量较⼤的猫能够快速把缆⻋填满,较快得到⼀个最⼩值;
通过这个最⼩值,能够提前把分⽀较⼤的情况提前剪掉。
• 优化枚举策略⼆:先考虑把⼩猫放在已有的缆⻋上,然后考虑重新租⼀辆⻋
因为如果反着来,我们会先把缆⻋较⼤的情况枚举出来,这样就起不到剪枝的效果了。
cpp
#include<iostream>
#include <algorithm>
using namespace std;
int n, k, cnt,path;
const int N = 20;
int a[N];
int s[N];
int ret = N;
bool cmp(int a, int b)
{
return a > b;
}
void dfs(int pos)
{
//最优性剪枝
if (cnt >= ret) return;
if (pos > n)
{
ret = cnt;
return;
}
// 策略三:优化搜索顺序
// 先安排在已有的⻋辆上
for(int i =1;i<=cnt;i++)
{
// 策略⼀:可⾏性剪枝
if((s[i]+a[pos])>k)continue;
s[i] += a[pos];
dfs(pos + 1);
s[i] -= a[pos];
}
cnt++;
s[cnt] = a[pos];
dfs(pos + 1);
s[cnt] = 0;
cnt--;
}
int main()
{
cin >> n >> k;
for (int i = 1; i <= n; i++)
{
cin >> a[i];
}
// 策略三:优化搜索顺序
sort(a + 1, a + 1 + n, cmp);
dfs(1);
cout << ret;
}