写在前面:为什么要学这个?
在分布式系统中,消息队列(Message Queue,MQ)是绕不开的基础组件。但面对 RabbitMQ、Kafka、RocketMQ 三大主流方案,很多人的困惑是:
"它们不都是收发消息的吗?有啥区别?我到底该选哪个?"本篇笔记的目标就是彻底回答这三个问题。
一、为什么要用 MQ?
在讨论选哪个之前,先想清楚为什么要用。
1.1 一个让你秒懂的类比
想象你要给朋友送一份礼物:
markdown
😤 没有 MQ(同步)
你 ──亲自上门──▶ 朋友(正在洗澡)
↓
你在门口死等...(阻塞)
😎 有了 MQ(异步)
你 ──丢进快递驿站──▶ [驿站] ──拿到回执──▶ 你回家打游戏
朋友忙完自己来取(解耦 + 异步)这个类比藏着 MQ 最核心的两个价值:调用方不阻塞、双方不直接依赖。
1.2 MQ 的三大核心价值
🔗 价值一:解耦
没有 MQ 的世界,服务之间强依赖:
rust
┌──▶ 库存服务
│
订单服务 ──直接调用──┼──▶ 积分服务 ← 任何一个挂了,订单服务受影响
│
└──▶ 通知服务引入 MQ 之后:
rust
┌──订阅──▶ 库存服务
│
订单服务 ──发消息──▶ [MQ] ────┼──订阅──▶ 积分服务 ← 互不认识,随意扩展
│
└──订阅──▶ 通知服务上游只管发消息,下游谁想消费谁来订阅。新增一个服务,上游代码零改动。
⚡ 价值二:异步提速
同步场景下,用户下单需要等所有步骤完成:
rust
下单请求
│
├─ 写订单数据库 50ms
├─ 发短信通知 200ms ← 这些都是非核心步骤
├─ 写审计日志 100ms 却让用户白白等待
└─ 发放优惠券 150ms
↓
用户等待总计:500ms 😤引入 MQ 之后:
rust
下单请求
│
├─ 写订单数据库 50ms ← 只等核心步骤
└─ 发消息到 MQ 5ms
↓
立即返回:55ms 😊
后台异步消费:发短信 / 写日志 / 发优惠券...🌊 价值三:削峰填谷
大促时的流量洪峰,会直接压垮数据库:
rust
正常时段:1,000 请求/秒 ──▶ 数据库(能扛)✅
大促瞬间:100,000 请求/秒 ──▶ 数据库(直接宕机)💥
引入 MQ:
100,000 请求/秒 ──▶ [MQ 蓄水池] ──▶ 数据库
快速写入 慢慢消化 1,000/秒匀速消费 ✅MQ 就像水库的大坝:上游洪峰来了先蓄水,下游按需放水,永远不会被淹。
1.3 小结:什么时候不需要 MQ?
引入 MQ 也有代价:系统复杂度上升、需要保障消息可靠性、多了一个需要运维的组件。
| 适合引入 MQ | 不适合引入 MQ |
|---|---|
| 有明显的流量峰谷差异 | 调用链路简单,无峰值压力 |
| 多个下游需要同一份数据 | 强依赖实时返回结果 |
| 存在耗时的非核心操作 | 团队没有 MQ 运维能力 |
二、认识三位主角
2.1 RabbitMQ --- 精细化路由专家
rust
诞生:2007 年 语言:Erlang 协议:AMQP
定位:企业级消息中间件最核心的设计:Exchange(交换机)
RabbitMQ 不像其他 MQ 那样生产者直接往队列里塞消息,它多了一层 Exchange:
css
生产者
│
▼
Exchange(交换机)──路由规则──▶ Queue A ──▶ 消费者 A
──▶ Queue B ──▶ 消费者 B
──▶ Queue C ──▶ 消费者 CExchange 有三种核心模式:
| 模式 | 路由规则 | 类比 | 典型场景 |
|---|---|---|---|
| Direct | 精确匹配路由键 | 精准快递上门 | 指定服务处理 |
| Fanout | 广播给所有队列 | 全员广播通知 | 系统公告推送 |
| Topic | 通配符匹配(*、#) | 按标签订阅杂志 | 多维度消息分类 |
其他亮点:
rust
死信队列(DLX):消息处理失败后自动转入"死信区",便于排查
管理界面:自带可视化 Web 控制台,运维极友好
Spring AMQP:Spring 原生支持,Java 项目集成极快2.2 Kafka --- 高吞吐量日志存储怪物
rust
诞生:2011 年(LinkedIn) 语言:Scala/Java 协议:自研
定位:分布式流处理平台Kafka 的设计哲学与众不同:
其他 MQ 把消息视为"一封信",处理后即删除。 Kafka 把消息视为"日志流",持久保存,可重复读。为什么 Kafka 这么快?三大底层技术:
rust
① 顺序写磁盘
随机写:磁头到处跑 ──▶ 慢(寻道时间长)
顺序写:一路追加 ──▶ 快(接近内存速度)
② 零拷贝(Zero-Copy)
传统方式:磁盘 → 内核缓冲区 → 用户态 → Socket 缓冲区 → 网卡(4次拷贝)
零拷贝: 磁盘 ──────────────────────────────────────▶ 网卡(2次拷贝)
利用 Linux sendfile() 系统调用,绕过用户态
③ 页缓存(Page Cache)
写入时先写 OS 内存缓存,由操作系统异步刷盘
读取时优先命中内存,极大减少磁盘 IOKafka 的存储模型:Partition(分区)
sql
Topic: order-events
├── Partition 0 [0, 1, 2, 3, ...] ──▶ Consumer A
├── Partition 1 [0, 1, 2, 3, ...] ──▶ Consumer B
└── Partition 2 [0, 1, 2, 3, ...] ──▶ Consumer C
↑
每条消息有唯一 Offset(偏移量),消费者自己记录消费到哪里✅ 优势:多消费者并行消费不同分区,吞吐量线性扩展
⚠️ 注意:分区数量不是越多越好,过多会导致顺序写退化
2.3 RocketMQ --- 金融级全能战士
rust
诞生:2012 年(阿里巴巴) 语言:Java 协议:自研
定位:金融级分布式消息中间件RocketMQ 的底气来自哪里?
每年双 11,万亿级消息量的实战考验。它不是在实验室里设计的,是从生产环境里"打"出来的。它在 Kafka 高性能的基础上,额外增加了大量业务特性:
| 特性 | 解决什么问题 | 典型场景 |
|---|---|---|
| 事务消息 | 分布式事务一致性 | 下单 + 扣库存原子操作 |
| 延迟消息 | 定时触发业务逻辑 | 下单 30 分钟未付款自动关闭 |
| 消息回溯 | 按时间重新消费 | 故障恢复,重跑历史数据 |
| 死信队列 | 消费失败兜底 | 人工介入处理异常消息 |
| 消费过滤 | 精细化消息分发 | 按 Tag 过滤,减少无效消费 |
RocketMQ 的存储模型:CommitLog
markdown
所有 Topic 消息
│
▼
CommitLog(一个顺序追加的大文件)
│
▼
ConsumeQueue(每个 Topic/Queue 对应一个索引文件)
│ 记录消息在 CommitLog 中的偏移量
▼
消费者通过 ConsumeQueue 快速定位消息💡 与 Kafka 的核心区别: Kafka 每个 Partition 是独立文件(多文件写入), RocketMQ 所有消息写进同一个 CommitLog(单文件顺序写), 在分区/队列数量很多时,RocketMQ 的磁盘 IO 性能更稳定。
三、深度对比 --- 一张表看清差异
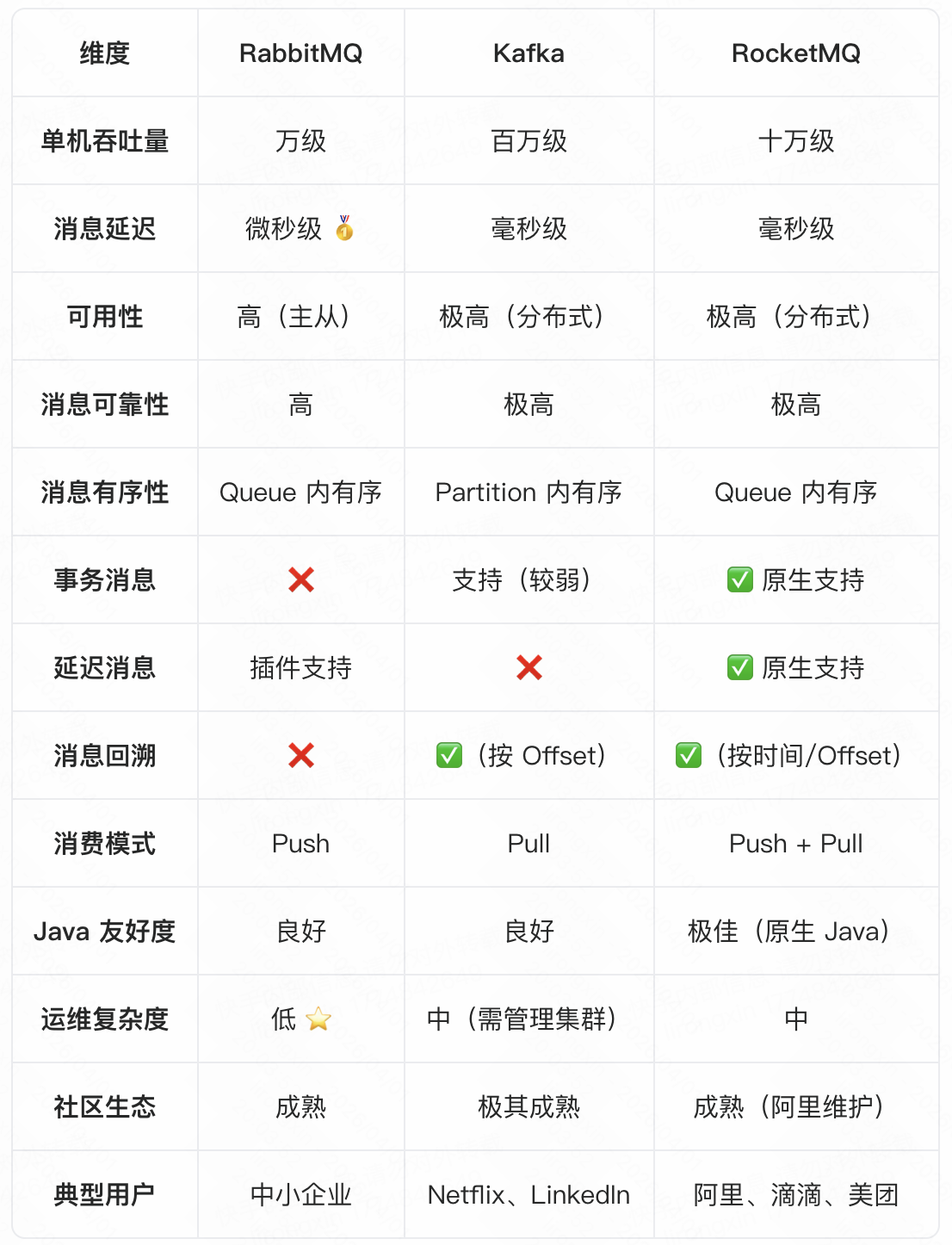
四、选型决策 --- 该选谁?
4.1 决策树:30 秒快速定位
markdown
你的核心诉求是什么?
│
├─ 📊 海量数据 / 日志采集 / 流式计算 / 大数据对接
│ └──▶ ✅ Kafka
│
├─ 🛒 电商 / 支付 / 金融 / 需要事务 & 延迟消息
│ └──▶ ✅ RocketMQ
│
├─ 🔀 灵活路由 / 微服务解耦 / 中小体量 / 快速上手
│ └──▶ ✅ RabbitMQ
│
└─ 🤔 以上都沾边?
└──▶ 继续往下看 👇4.2 典型场景深度拆解
🛒 场景一:电商订单系统
业务背景:
rust
用户下单
├── 扣减库存(必须和下单保持事务一致性)
├── 发送下单成功短信(非核心,异步即可)
├── 发放优惠券(非核心,异步即可)
└── 30 分钟未付款,自动关闭订单(延迟任务)需求分析:
| 需求点 | 所需 MQ 特性 |
|---|---|
| 下单 + 扣库存一致性 | 事务消息 |
| 异步发短信/优惠券 | 基础消息发送 |
| 30 分钟自动关单 | 延迟消息 |
| 消息不能丢 | 高可靠性 |
结论:✅ RocketMQ
java
// 延迟消息示例:下单后发送 30 分钟延迟消息
Message message = new Message("order-close-topic",
JSON.toJSONBytes(orderCloseEvent));
// RocketMQ 支持 18 个延迟级别
// 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
message.setDelayTimeLevel(16); // 第16级 = 30分钟
producer.send(message);
// 30 分钟后消费者才能收到这条消息
java
// 事务消息示例:下单和扣库存的分布式事务
TransactionMQProducer producer = new TransactionMQProducer("order-group");
producer.setTransactionListener(new TransactionListener() {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
try {
// 执行本地事务:写订单数据库
orderService.createOrder(arg);
return LocalTransactionState.COMMIT_MESSAGE; // 本地事务成功,提交消息
} catch (Exception e) {
return LocalTransactionState.ROLLBACK_MESSAGE; // 本地事务失败,回滚消息
}
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// Broker 回查:检查本地事务是否成功
boolean success = orderService.checkOrder(msg.getTransactionId());
return success ? LocalTransactionState.COMMIT_MESSAGE
: LocalTransactionState.ROLLBACK_MESSAGE;
}
});📊 场景二:日志采集与实时分析平台
业务背景:
java
全公司 50 个微服务
├── 每秒产生约 50 万条访问日志
├── 需要实时统计 PV/UV、错误率
├── 对接 Flink 做用户行为分析
└── 日志需要保留 7 天(用于故障回溯)需求分析:
| 需求点 | 所需 MQ 特性 |
|---|---|
| 50 万条/秒写入 | 极高吞吐量 |
| 对接 Flink/Spark | 流处理生态 |
| 保留 7 天 | 消息持久化 + 回溯 |
| 多个消费方 | Consumer Group 隔离 |
结论:✅ Kafka
sql
日志采集架构:
各微服务
│ Logback Appender / Filebeat
▼
Kafka(Topic: app-logs,12 个 Partition)
│
├──▶ Consumer Group A(Flink 实时分析)
│ └── 实时大屏、告警
│
├──▶ Consumer Group B(写入 Elasticsearch)
│ └── 日志检索平台
│
└──▶ Consumer Group C(写入 HDFS)
└── 离线数仓、报表💡 Kafka 的 Consumer Group 机制: 同一条消息,不同的消费组各消费一次、互不干扰。 这是 Kafka 在日志场景中碾压其他 MQ 的核心优势之一。
😴场景三:微服务事件总线
业务背景:
java
一个中台系统,管理 20 个微服务
├── 用户注册事件 → 发给「积分服务」「邮件服务」
├── 订单状态变更 → 根据状态发给不同服务
│ ├── 已支付 → 发给「物流服务」
│ ├── 已取消 → 发给「退款服务」
│ └── 已完成 → 发给「评价服务」「积分服务」
└── 消息量不大(峰值 < 1万/秒),但路由逻辑复杂需求分析:
| 需求点 | 所需 MQ 特性 |
|---|---|
| 按订单状态路由到不同服务 | 灵活路由机制 |
| 一条消息多个服务同时消费 | 多队列绑定 |
| 路由规则随业务迭代频繁变化 | 路由规则可配置、扩展零侵入 |
| 团队规模小,运维资源有限 | 部署简单、管理界面友好 |
结论:✅ RabbitMQ
java
事件总线架构:
各微服务
│ Spring AMQP
▼
RabbitMQ(Topic Exchange: platform.events)
│
├──▶ user.register ──▶ queue.points.user ──▶ 积分服务
│ ──▶ queue.email.user ──▶ 邮件服务
│
├──▶ order.paid ──▶ queue.logistics ──▶ 物流服务
│
├──▶ order.cancel ──▶ queue.refund ──▶ 退款服务
│
├──▶ order.done ──▶ queue.review ──▶ 评价服务
│ ──▶ queue.points.order ──▶ 积分服务
│
└──▶ order.* ──▶ queue.audit ──▶ 审计服务(全量接收)💡 RabbitMQ 的 Topic Exchange 机制:生产者只管按路由键发消息,下游服务自行声明队列并绑定感兴趣的路由键。新增一个消费方,上游代码零改动。这是它在微服务事件路由场景中优于 Kafka 和 RocketMQ 的核心原因。
五、避坑指南
无论选哪种 MQ,以下三个坑都必须提前应对。
坑一:消息丢失 📭
java
丢失可能发生在三个环节:
生产者 ──[①]──▶ MQ Broker ──[②]──▶ 消费者
[③磁盘]| 环节 | 解决方案 |
|---|---|
| ① 生产者 → Broker | 开启生产者 Confirm 机制 + 失败重试 |
| ② Broker 存储 | 开启消息持久化(刷盘策略) |
| ③ Broker → 消费者 | 关闭自动 Ack,改为手动 Ack,处理成功后再确认 |
坑二:重复消费 🔁
原因链路:
java
消费者处理成功 → 发送 Ack → 网络抖动 → Ack 丢失
→ Broker 认为未消费 → 重新投递 → 重复消费!核心原则:消费端必须保证幂等性
java
// 方案一:数据库唯一键约束(自动去重)
INSERT IGNORE INTO order_log (msg_id, ...) VALUES (?, ...)
// 方案二:Redis 记录已处理 ID
if (redis.setNX("msg:" + msgId, "1", 24h)) {
// 处理业务逻辑
} else {
// 已处理,直接跳过
}坑三:消息积压 📦
定位原因:
java
生产速度 >> 消费速度 → 队列持续堆积| 解决策略 | 适用情况 |
|---|---|
| 水平扩展消费者实例 | 消费者处理能力不足 |
| 优化消费逻辑(批量处理、异步化) | 单条消费耗时过长 |
| 临时扩大分区/队列数 | 需要提高并发消费上限 |
| 紧急降级(丢弃非核心消息) | 极端情况,保核心链路 |
⚠️ 提前预防:上线前用压测评估消费速率,配置积压告警阈值(如队列深度 > 1w 触发报警)。
六、总结
三句话记住三个 MQ。
| MQ | 定位 | 一句话 |
|---|---|---|
| RabbitMQ | 🔪 瑞士军刀 | 精致灵活,中小业务的万能选手 |
| Kafka | 🚚 重型卡车 | 力大无穷,大数据海洋的基础设施 |
| RocketMQ | 🎖️ 特种兵 | 身经百战,电商金融的首选利器 |
选型口诀
java
大数据管道选 Kafka,
电商金融选 RocketMQ,
小巧灵活选 Rabbit。避坑三件套
java
消息不丢 → 持久化 + 手动 Ack + 生产者重试
不重复消费 → 消费端幂等(Redis / 数据库唯一键)
不积压 → 压测评估 + 扩消费者 + 积压告警