本次实战深入探索Spark单机版环境的核心功能。首先运行SparkPi示例程序计算圆周率,验证集群计算能力;随后启动spark-shell进入交互式环境,完成等差数列求和、九九乘法表打印等基础任务。重点通过Scala代码操作RDD,演示了从文本文件和集合创建RDD的方法,实践了filter转化操作筛选数据,以及first、collect、foreach、saveAsTextFile等行动操作获取和保存结果,全面展示了Spark的数据处理流程和RDD编程模型。
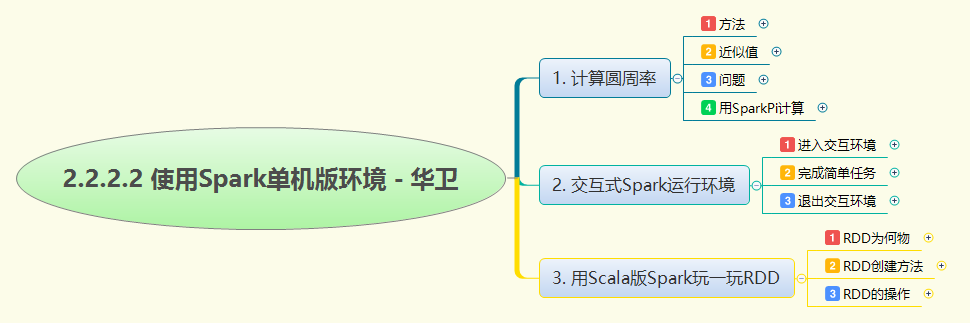
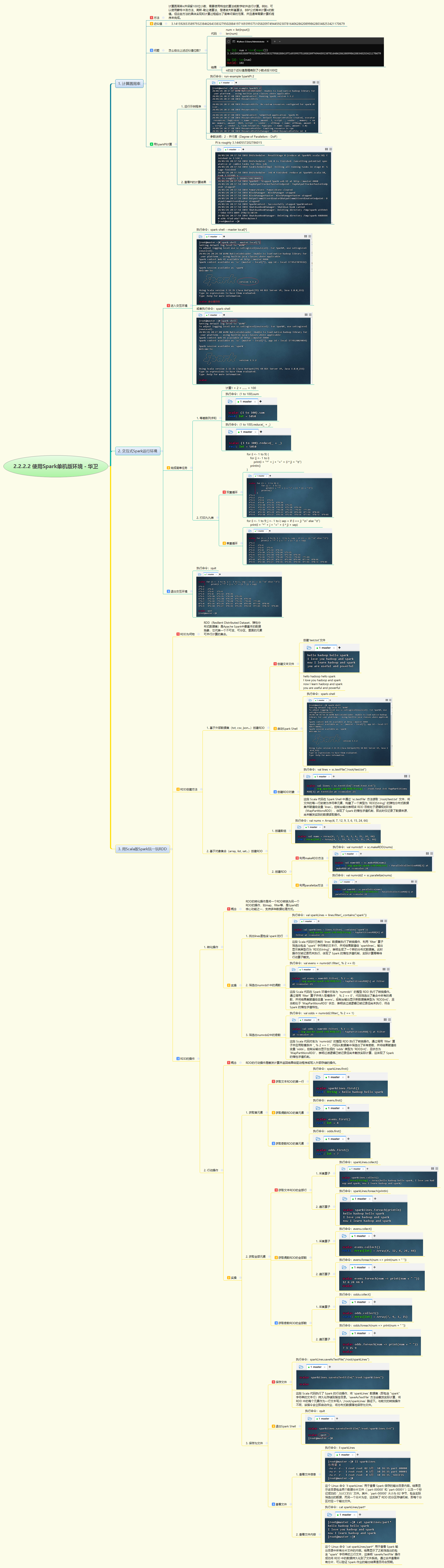
本次实战深入探索Spark单机版环境的核心功能。首先运行SparkPi示例程序计算圆周率,验证集群计算能力;随后启动spark-shell进入交互式环境,完成等差数列求和、九九乘法表打印等基础任务。重点通过Scala代码操作RDD,演示了从文本文件和集合创建RDD的方法,实践了filter转化操作筛选数据,以及first、collect、foreach、saveAsTextFile等行动操作获取和保存结果,全面展示了Spark的数据处理流程和RDD编程模型。