Spark 任务提交模式
在 EMR 上,传统上 Spark 作业通过 spark-submit 提交到 YARN,有两种 deploy mode:
cluster 模式(EMR 默认/推荐):用户 SSH 到 Primary 节点 → spark-submit --deploy-mode cluster → YARN 分配容器运行 Driver + Executors
- Driver 运行在 YARN 容器中(集群某个节点上)
- 提交后客户端可以断开,作业继续运行
- 适合生产批处理作业
client 模式:用户 SSH 到 Primary 节点 → spark-submit --deploy-mode client → Driver 在 Primary 节点运行,Executors 在 YARN 容器中
- Driver 运行在提交命令的那台机器上(通常是 Primary 节点)
- 客户端断开则作业失败
- 适合交互式调试(spark-shell、pyspark REPL)
两种模式的共同点:用户都需要 SSH 到 EMR 集群(或拥有完整 Spark + Hadoop 配置的机器),才能提交作业。
Spark Connect 模式
Apache Spark Connect 是 Spark 3.4 引入的客户端-服务端架构,它将 Spark 的执行引擎与客户端应用彻底解耦。
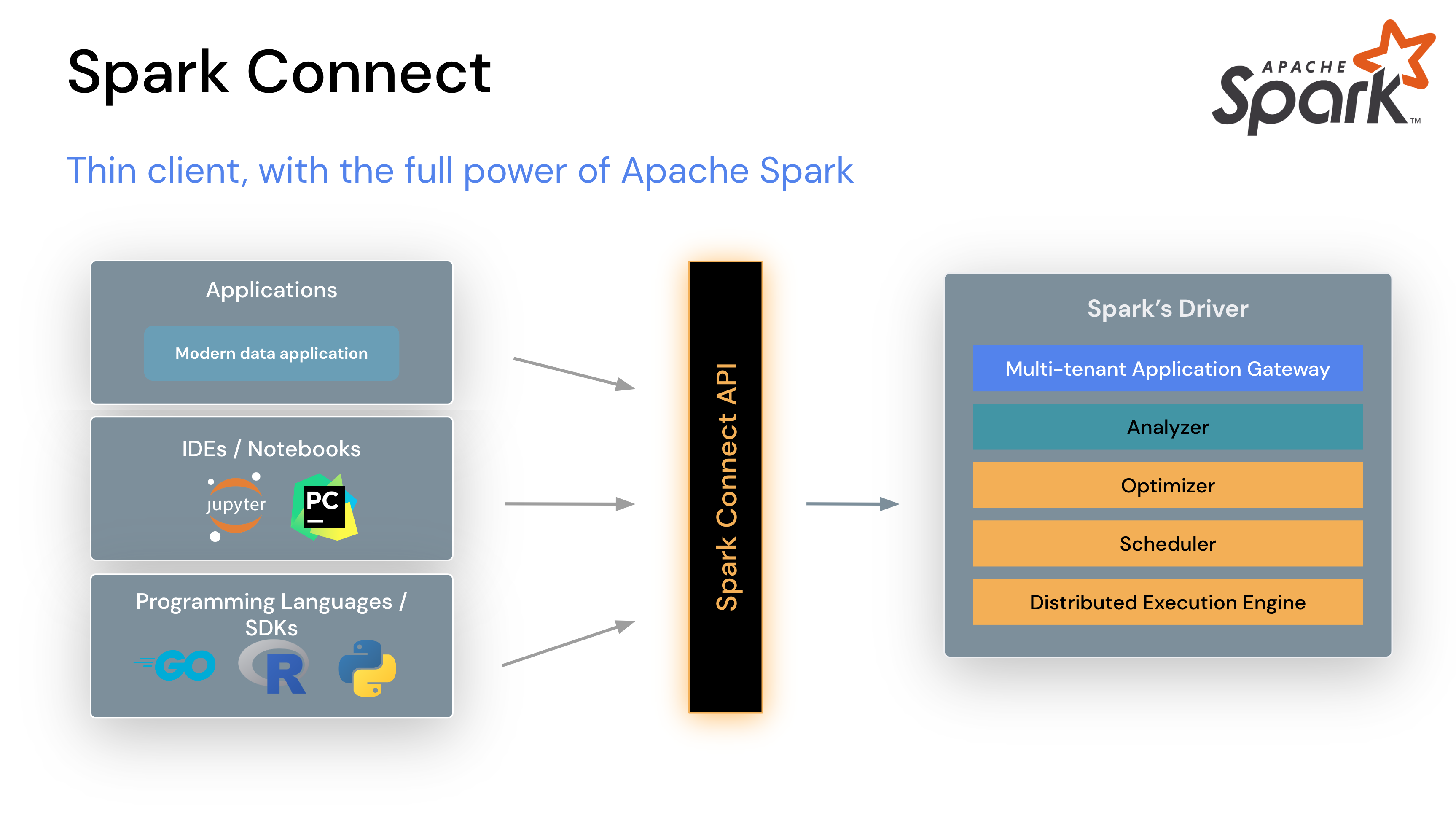
客户端只需要一个轻量的 gRPC 客户端库(pip install pyspark[connect]),不需要 JVM,不需要 SSH 到集群,不需要配置 YARN/HDFS 访问。
| 维度 | YARN cluster mode | YARN client mode | Spark Connect |
|---|---|---|---|
| Driver 位置 | YARN 容器(集群节点) | 提交机器(通常 Primary) | Spark Connect Server(Primary) |
| 提交方式 | spark-submit | spark-submit / spark-shell | 远程 gRPC 调用 |
| 客户端需要什么 | 完整 Spark + Hadoop 配置 | 完整 Spark + Hadoop 配置 | 仅 pyspark-client(无需 JVM) |
| 能否从外部机器提交 | 需要配置 YARN/HDFS 全部网络端口 | 需要配置 YARN/HDFS 全部网络端口 | 只需访问 15002 端口 |
| 交互式开发 | 不支持 | 需要 SSH 到集群 | 本地 IDE 直接写代码 |
| 客户端断开影响 | 无影响 | 作业失败 | 作业失败(会话级别) |
Spark Connect 消除了客户端对 Spark/Hadoop 完整环境的依赖,让远程交互式开发变得像调用 API 一样简单。Spark Connect 工作原理如下
gRPC
(序列化的逻辑计划 / Protobuf)
直接调用 Spark Core API
Apache Arrow 编码
结果流式返回
Arrow 列式数据流
(零拷贝反序列化为 DataFrame)
客户端
(pyspark-client)
Spark Connect Server
(Primary 节点,内嵌于 Spark)
Spark Core
Catalyst 优化器
YARN Executors
- 客户端将 DataFrame 操作转换为未解析的逻辑查询计划(Unresolved Logical Plan)
- 使用 Protocol Buffers 编码,通过 gRPC 发送到 Spark Connect Server(默认端口 15002)
- Server 端将逻辑计划交给 Spark Core 进行优化和执行
- 结果以 Apache Arrow 编码的行批次流式返回客户端
Spark Connect 与 Apache Livy 的对比
Spark Connect 和 Apache Livy 都解决"从远程客户端提交 Spark 作业"的问题,但架构原理完全不同。
Livy 的工作原理
Livy 是一个 REST API 代理服务,本身不执行任何 Spark 逻辑:
HTTP REST
POST /sessions
POST /statements
(提交代码文本)
spark-submit
(为每个 session 启动独立 Driver)
JSON 结果
(客户端轮询获取)
客户端
(Jupyter / curl / 应用)
Livy Server
(JVM 进程,Primary 节点)
YARN ResourceManager
Spark Driver
(独立 JVM 容器)
Spark Executors
工作流程:
- 客户端发送
POST /sessions创建一个 Session,Livy 在 YARN 上启动一个独立的 Spark Driver JVM - 客户端发送
POST /sessions/{id}/statements提交代码片段(Python/Scala/R 源码文本) - Livy 将代码文本转发给对应的 Driver 执行
- 客户端轮询
GET /sessions/{id}/statements/{id}获取结果(JSON 格式) - 结果以 JSON 文本返回,客户端自行解析
每个用户 Session 对应一个独立的 Spark Driver JVM 进程。 10 个用户就有 10 个 Driver 占用集群资源。
此外,在 Jupyter 中使用 Livy 需要 sparkmagic 内核作为封装层:
Jupyter Cell 代码
sparkmagic
(封装 HTTP 调用)
Livy REST API
Spark Driver
集群 Executors
Spark Connect 的工作原理
Spark Connect 是 Spark 原生的客户端-服务端协议
① gRPC 发送序列化逻辑计划
(Protobuf 编码,非代码文本)
② 直接调用 Spark Core API
③ 生成物理计划并执行
④ 执行结果
⑤ Apache Arrow 流式返回
(零拷贝反序列化为 DataFrame)
客户端 (pyspark-client)
DataFrame API 调用
Spark Connect Server
(Primary 节点,内嵌于 Spark)
Spark Core / Catalyst 优化器
YARN Executors
工作流程:
- 客户端的 DataFrame API 调用被转换为未解析的逻辑查询计划(AST 级别的操作描述)
- 使用 Protocol Buffers 序列化,通过 gRPC 流式发送到 Server
- Server 端直接将逻辑计划交给 Spark Catalyst 优化器,生成物理执行计划
- 执行结果以 Apache Arrow 列式格式流式返回(不需要轮询)
- 客户端零拷贝反序列化为 Pandas/Spark DataFrame
所有客户端共享同一个 Spark Connect Server 进程, Server 内部通过 Session 隔离实现多租户。
核心区别总结以及如何选择?
- Livy:已有 EMR 集群且 Spark < 3.4;需要提交任意代码(非 DataFrame API);已有 sparkmagic 工作流
- Spark Connect:新项目;Spark 3.4+;追求低延迟交互式开发;需要从多种环境(IDE/CI/微服务)接入
| 维度 | Apache Livy | Spark Connect |
|---|---|---|
| 传输内容 | 代码文本(字符串) | 序列化的逻辑计划(Protobuf) |
| 协议 | HTTP REST + JSON | gRPC + Protobuf + Arrow |
| 资源模型 | 每个 Session 一个独立 Driver JVM | 多客户端共享一个 Server 进程 |
| 结果获取 | 客户端轮询 + JSON 文本 | 服务端流式推送 + Arrow 列式编码 |
| 版本耦合 | Driver 版本 = 集群 Spark 版本 | 客户端和服务端可以不同版本 |
| 客户端依赖 | sparkmagic + 配置 Livy 地址 | pip install pyspark[connect] |
| 安全模型 | 代码在服务端执行(可执行任意代码) | 只能执行 DataFrame/SQL 操作(受限 API) |
| 性能 | 高延迟(HTTP 轮询 + JSON 序列化开销) | 低延迟(gRPC 流式 + Arrow 零拷贝) |
| 容错 | 客户端崩溃不影响 Driver | 客户端断开,Session 可配置超时保留 |
| Spark 原生 | 第三方项目(Apache Incubator 已退役) | Spark 官方内置组件 |
spark connect的适用场景如下
- 从本地 IDE 直接调试远程 Spark 作业
- Jupyter Notebook 远程提交(替代 Livy + sparkmagic)
- CI/CD 流水线中的 Spark 任务提交
- 微服务架构中嵌入 Spark 查询能力
测试步骤
环境架构如下,客户端通过vpc peering连接spark connect server,实际生产环境中可以将其通过负载均衡器暴露并连接
EMR VPC (192.168.0.0/16)
Client VPC (172.31.0.0/16)
EMR Cluster
gRPC :15002
(Protobuf + Arrow)
Spark Core / YARN
VPC Peering
EC2 (client)
172.31.x.x
pyspark-client
Primary Node
192.168.x.x
Spark Connect Server
Port 15002
Core Node
Spark Executors
准备 Bootstrap 脚本
Bootstrap 脚本在 EMR 集群启动时执行,仅在 Primary 节点上启动 Spark Connect Server。
bash
#!/bin/bash
if grep isMaster /mnt/var/lib/info/instance.json | grep false;
then
echo "This is not master node, do nothing."
exit 0
fi
echo "This is master, continuing to execute script"
SPARK_HOME=/usr/lib/spark
SPARK_VERSION=$(spark-submit --version 2>&1 | grep "version" | head -1 | awk '{print $NF}' | grep -oE '[0-9]+\.[0-9]+\.[0-9]+')
SCALA_VERSION=$(spark-submit --version 2>&1 | grep -o "Scala version [0-9.]*" | awk '{print $3}' | grep -oE '[0-9]+\.[0-9]+')
echo "Spark version ${SPARK_VERSION} running with scala ${SCALA_VERSION}"
nohup sudo "${SPARK_HOME}"/sbin/start-connect-server.sh --packages org.apache.spark:spark-connect_"${SCALA_VERSION}":"${SPARK_VERSION}" > /tmp/spark-connect.log 2>&1 &关键点: 必须使用
nohup ... &后台运行。如果前台运行,start-connect-server.sh会阻塞 bootstrap 过程,导致 EMR 无法完成初始化,集群报错BOOTSTRAP_FAILURE: after bootstrap actions were run Elastic MapReduce could not contact the instance。
Bootstrap 脚本最终调用的是 Spark 自带的 /usr/lib/spark/sbin/start-connect-server.sh,其核心内容如下:
bash
#!/usr/bin/env bash
set -o posix
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
# 指定要启动的 Java 主类
CLASS="org.apache.spark.sql.connect.service.SparkConnectServer"
# 加载 Spark 环境变量(JAVA_HOME、SPARK_CONF_DIR 等)
. "${SPARK_HOME}/bin/load-spark-env.sh"
# 通过 spark-daemon.sh 以守护进程方式提交
exec "${SPARK_HOME}"/sbin/spark-daemon.sh submit $CLASS 1 --name "Spark Connect server" "$@"通过 spark-daemon.sh 以守护进程方式执行 spark-submit,启动 SparkConnectServer 这个 JVM 主类。该主类启动后会:
- 创建一个 gRPC Server ,默认监听 15002 端口
- 注册
SparkConnectServicegRPC 服务端点 - 内部持有
SparkSession,接收客户端发来的逻辑计划并交给 Spark Core 执行
此外,--packages org.apache.spark:spark-connect_"${SCALA_VERSION}":"${SPARK_VERSION}" 参数让 spark-submit 自动从 Maven 仓库下载 Spark Connect 模块的依赖 jar(包含 gRPC Server 和 Protobuf 相关类)。
将BA脚本上传到 S3
bash
aws s3 cp start-spark-connect.sh s3://<YOUR_BUCKET>/spark-connect/start-spark-connect.sh创建 EMR 集群
bash
aws emr create-cluster \
--name 'spark-connect-test' \
--applications Name=Spark \
--release-label emr-7.12.0 \
--service-role EMR_DefaultRole_V2 \
--tags for-use-with-amazon-emr-managed-policies=true \
--ec2-attributes InstanceProfile=EMR_EC2_DefaultRole,SubnetId=<SUBNET_ID>,EmrManagedMasterSecurityGroup=<MASTER_SG>,EmrManagedSlaveSecurityGroup=<SLAVE_SG>,KeyName=<KEY_NAME>,AdditionalMasterSecurityGroups=<ADDITIONAL_SG>,AdditionalSlaveSecurityGroups=<ADDITIONAL_SG> \
--instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m5.xlarge InstanceGroupType=CORE,InstanceCount=1,InstanceType=m5.xlarge \
--bootstrap-actions Path=s3://<YOUR_BUCKET>/spark-connect/start-spark-connect.sh \
--query ClusterId --output text关键点: 使用
AmazonEMRServicePolicy_v2策略的 service role 时,集群,子网和安全组必须 添加标签for-use-with-amazon-emr-managed-policies=true,否则会报Service role has insufficient EC2 permissions。
集群状态
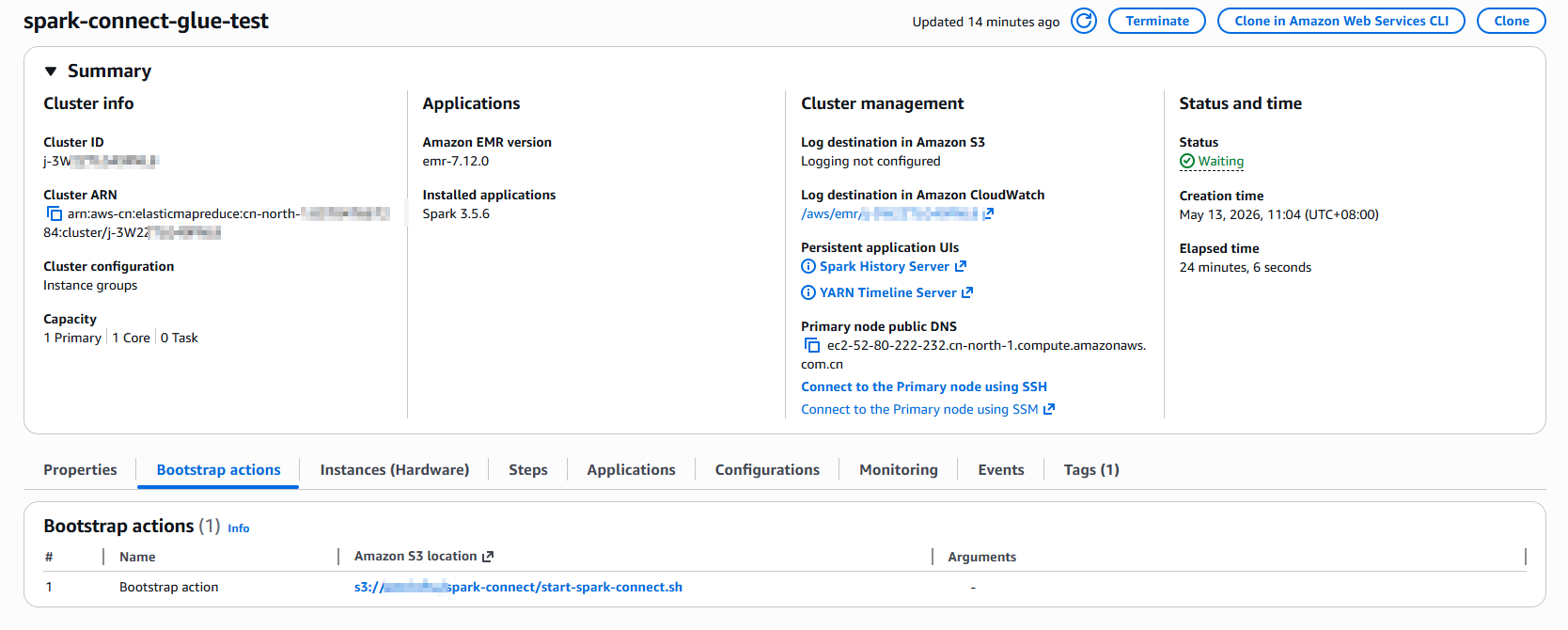
验证端口连通性
bash
$ nc -zv 192.168.x.x 15002
Ncat: Version 7.93 ( https://nmap.org/ncat )
Ncat: Connected to 192.168.x.x:15002.
Ncat: 0 bytes sent, 0 bytes received in 0.01 seconds.客户端配置
pyspark[connect] 会安装 grpcio、protobuf、pyarrow 等 Spark Connect 客户端所需的依赖。不需要完整的 Spark 安装或 JVM。
bash
cd /home/ec2-user/workspace/spark-connect
python3 -m venv venv
source venv/bin/activate
pip install 'pyspark[connect]==3.5.6'查询 Glue Data Catalog
Spark Connect 也可以直接查询 AWS Glue Data Catalog 中注册的表,前提是 EMR 集群配置了 Glue 作为 Hive Metastore,且 Spark Connect Server 启动时启用了 Hive 支持。
集群配置(创建时通过 --configurations 指定):
json
[{
"Classification": "spark-hive-site",
"Properties": {
"hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
}
}]Bootstrap 脚本中需要加上 --conf spark.sql.catalogImplementation=hive:
bash
nohup sudo "${SPARK_HOME}"/sbin/start-connect-server.sh \
--packages org.apache.spark:spark-connect_"${SCALA_VERSION}":"${SPARK_VERSION}" \
--conf spark.sql.catalogImplementation=hive \
> /tmp/spark-connect.log 2>&1 &测试代码如下,连接字符串格式:sc://<host>:<port>,其中 sc:// 是 Spark Connect 协议前缀。
python
from pyspark.sql import SparkSession
spark = SparkSession.builder.remote('sc://<EMR_PRIMARY_IP>:15002').getOrCreate()
# 1. 查看 Glue Catalog 中的所有数据库
spark.sql('SHOW DATABASES').show(truncate=False)
# 2. 查看 default 数据库中的表
spark.sql('SHOW TABLES IN default').show(truncate=False)
# 3. 查询 S3 上的数据
spark.sql('SELECT * FROM default.sourcetable').show(truncate=False)
# 4. 查看表结构
spark.sql('DESCRIBE default.sourcetable').show(truncate=False)
spark.stop()
print('SUCCESS')执行结果:
=== GLUE Databases ===
+------------------------+
|namespace |
+------------------------+
|company |
|default |
+---------+---------------------------------------------------------+-----------+
|namespace|tableName |isTemporary|
+---------+---------------------------------------------------------+-----------+
|default |apache_logs |false |
|default |cloudtrail_logs_aws_cloudtrail_logs_xxxxxxxxxxxx_77130b10|false |
|default |cloudtrail_logs_aws_cloudtrail_logs_xxxxxxxxxxxx_f9edbc78|false |
|default |cloudtrail_logs_pp |false |
|default |mock_person_table |false |
|default |movie_reviews |false |
|default |sourcetable |false |
|default |sourcetable1 |false |
+---------+---------------------------------------------------------+-----------+
+----------+-------------------+---+-------------+
|c1 |c2 |c3 |c4 |
+----------+-------------------+---+-------------+
|1234567890|2024-08-17 20:15:00|1 |example_value|
+----------+-------------------+---+-------------+
+-----------------------+---------+-------+
|col_name |data_type|comment|
+-----------------------+---------+-------+
|c1 |bigint |NULL |
|c2 |timestamp|NULL |
|c3 |int |NULL |
|c4 |string |NULL |
|# Partition Information| | |
|# col_name |data_type|comment|
|c4 |string |NULL |
+-----------------------+---------+-------+
SUCCESS通过 Spark Connect,客户端可以像使用本地数据库一样查询 Glue Catalog 中注册的所有表,数据实际存储在 S3 上,由 EMR 集群负责读取和计算。
参考资料