一、脑海中的两个声音
作为一名测试开发工程师,除了日场的业务需求测试,自己还承担了一些测试工具平台的开发维护工作。
在这个AI技术飞速发展的时代,我常常在想两个问题:
如果我具备代码能力,开发这个平台能让AI做什么?
如果我代码能力有限,该怎么结合AI完成这个平台?
这两个问题一直萦绕在我脑海。直到最近,一个需求的出现,让我有机会同时回答这两个问题------用两种完全不同的视角,去审视同一段开发旅程。
二、机会这不就来了
2.1 需求背景
保单指挥中心平台是一个面向保险业务全生命周期管理的统一数据查询平台。该平台通过整合互联网、商家险、延保、履约理赔、计费、供应链等多条业务线的数据,为业务人员提供基于保单维度的统一视图和快速检索能力。平台一期上线后,我们紧接着需要迭代一个重要需求:
记录所有用户的查询操作,支持数据追踪和性能监控
听起来简单,但细想下来,问题不少:
•记录哪些信息?用户、时间、参数、响应?
•怎么记录才不影响主业务性能?
•数据存哪里?存多久?
•如何设计才能方便后续扩展?
2.2 两种视角的起点
在正式开始之前,我将会用两种不同的视角来审视这个需求:
视角A:具备代码能力
"我知道AOP可以实现切面拦截,异步处理可以避免阻塞主流程,设计模式要遵循单一职责...具体怎么落地,提供我的想法,让AI来帮我完成。"
视角B:代码能力有限
"我不太懂AOP是什么,异步线程池怎么配置,甚至不确定这个需求该用什么技术方案...但我知道要解决什么问题。"
无论哪种视角,最终的目标都是一样的:交付一个可用的、可扩展的查询记录功能。两种视角的路径,注定不同。
三、同样的终点,不同的路
3.1 当你具备代码能力时
3.1.1 你是架构师,AI是执行者
作为一名熟练的测试开发,我对代码并不陌生。我知道要做什么,但我更想知道:AI能帮我做到什么程度?
于是我尝试了一个大胆的方式:
我只提供平台架构和需求背景,代码和技术方案全交给AI。
我的输入:
css
【项目背景】
保单指挥中心平台 - 保险业务全生命周期管理的统一数据查询平台
技术架构:前后端分离
前端:Vue 技术栈
后端:DongBoot 框架,双服务架构
【服务架构】
| 服务 | 定位 | 核心职责 |
|------|------|----------|
| 服务A (API Gateway Service) | 网关层 | 前端接口统一入口、请求参数校验与转换、响应数据格式化、统一异常处理、API文档管理 |
| 服务B (Business Service) | 业务层 | 业务逻辑编排、多业务线数据聚合、外部接口调用管理、业务规则执行、业务异常处理 |
【需求描述】
实现查询轨迹记录功能,需满足以下要求:
1. 记录内容
用户 ERP
查询类型
请求 URI
请求参数
响应数据
耗时
2. 技术约束
异步处理,不影响主业务性能
保证数据完整性
3. 决策要求
请先决策日志记录应该在哪一层进行(服务A/服务B/两层结合),说明决策依据及优缺点分析,经我确认后再完成技术方案设计。
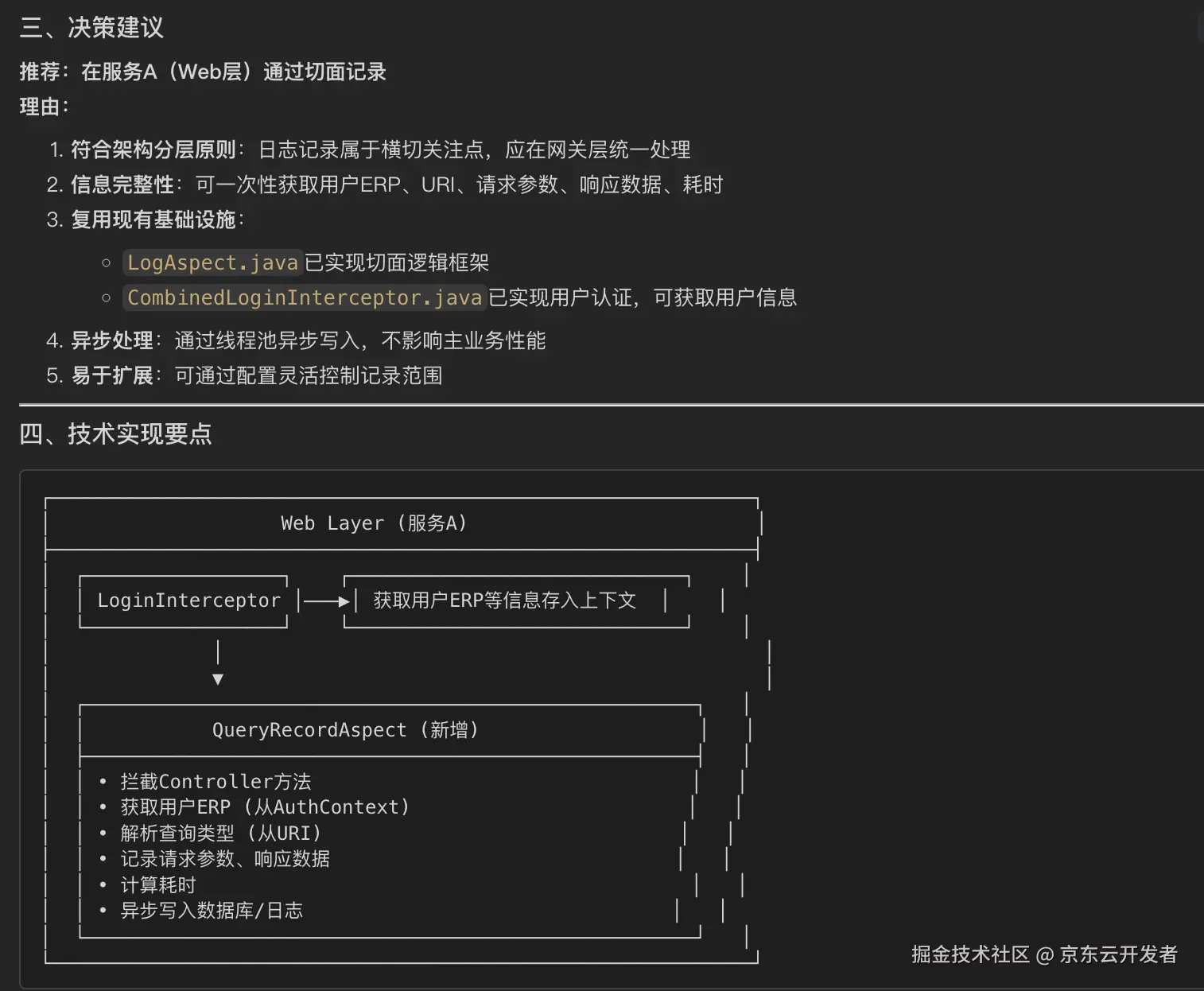
明确在哪一层实现后,之后在项目A中,完成技术方案设计,并根据技术方案微调后的结果由AI全自主生成代码。
3.1.2 你的价值在哪里?
既然AI能生成方案,那我的价值是什么?
判断力和决策力。
当AI给出方案后,我需要判断:
•这个设计是否符合我们的技术规范?
•异步线程池的参数是否合理?
•是否考虑了异常情况?
•是否有安全风险?
比如,AI最初生成的方案中,客户端IP获取只考虑了X-Forwarded-For头,我要求补充X-Real-IP和Proxy-Client-IP的处理。
这就是具备代码能力的优势:你能看懂AI的输出,能发现问题,能引导改进。
3.2 当你代码能力有限时
3.2.1 你是产品经理,AI是技术顾问
如果换一个视角呢?假设我对AOP、线程池这些概念比较模糊,我会怎么做?
我会把问题翻译成业务语言,让AI帮我找技术方案。
我的输入:
css
【项目背景】
保单指挥中心平台 - 保险业务全生命周期管理的统一数据查询平台
技术架构:前后端分离
前端:Vue 技术栈
后端:DongBoot 框架,双服务架构
【服务角色说明】
| 服务 | 角色 | 想象成 |
|------|------|--------|
| 服务A (API Gateway Service) | 前台接待 | 像公司前台,负责接待客户、登记信息、转交请求 |
| 服务B (Business Service) | 业务专员 | 像业务部门,负责处理具体业务、查询数据、给出结果 |
【业务需求】我
们需要一个**"查询留痕"功能**,就像银行的柜台业务记录仪:
每次用户查询时,自动记录:
谁查的(用户ERP)
查什么(查询类型)
从哪查的(请求URI)
查了什么条件(请求参数)
查到什么结果(响应数据)
查了多久(耗时)
【核心诉求】
不影响客户体验 - 记录过程不能让用户感觉变慢
就像银行办业务时,监控录像在后台自动录制,不会让客户等待
记录不能丢 - 数据要可靠保存
就像监控录像不能因为断电就丢失
不知道在哪记录 - 请帮我判断应该在前台记录,还是在业务部门记录,或者两边配合?
【请帮我分析】
请用通俗易懂的语言告诉我:
应该在哪个服务实现这个记录功能?
为什么选择这里?
各个方案的优缺点是什么?
等确认后,再给出具体的技术实现方案。请避免使用太多技术术语,用业务场景来类比说明。AI的输出:

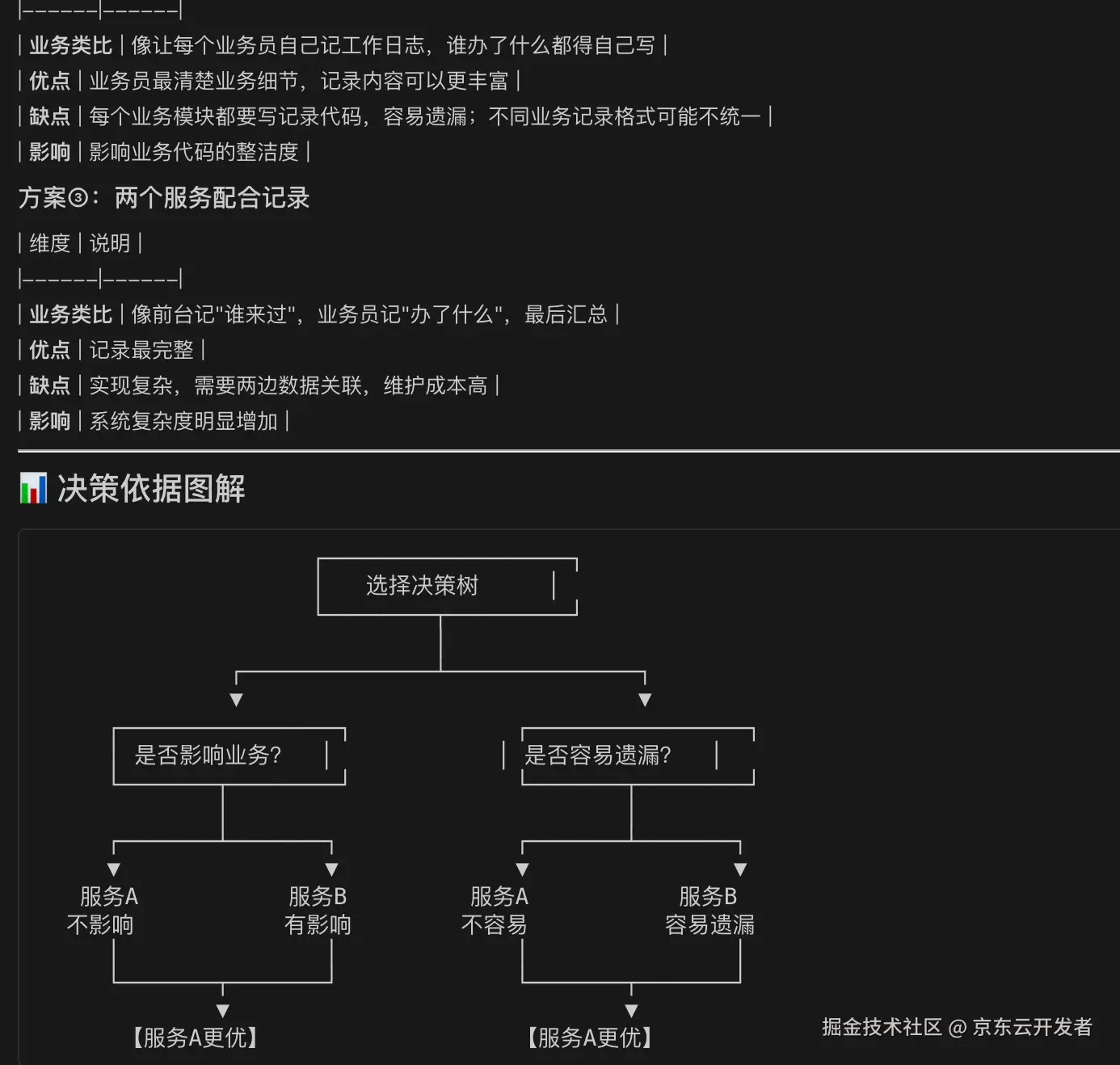

发现没有,在这种思路下,AI开始"教学"了!它在解释技术概念,在选择方案,在帮你理清思路。
3.2.2 你的价值在哪里?
需求翻译和验收判断。
虽然你不太懂技术细节,但你清楚地知道:
•这个功能要解决什么问题?
•怎样才算"做得好"?
•有没有遗漏的场景?
比如,你可能会问AI:
"如果记录失败了,会影响用户查询吗?" "响应数据特别大怎么办?" "数据要保存多久?"
这些问题,来自于你对业务的熟悉,而不是对技术的熟悉。
3.3 两种路径的交汇
无论哪种视角,最终都指向了同一个结果:
人负责定义问题和验收结果,AI负责寻找方案和执行实现。
区别只在于:
•具备代码能力的人,可以更精确地引导AI,更高效地验收代码
•代码能力有限的人,需要更多依赖AI的解释和建议,但依然可以做出正确的决策
四、AI出手了
4.1 架构设计:AI的思路
基于需求背景和工程架构,AI给出的技术方案如下:
scss
┌─────────────────────────────────────────────────────────────┐
│ 前端层 (Vue) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 保单查询 │ │ 理赔查询 │ │ 签约查询 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────┬───────────────────────────────────┘
│ HTTP/HTTPS
┌─────────────────────────▼───────────────────────────────────┐
│ 服务A (网关层) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ QueryRecordAspect │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ 请求拦截 │ │ 响应记录 │ │ 异常处理 │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │
│ └─────────────────────────┬───────────────────────────┘ │
└───────────────────────────┼─────────────────────────────────┘
│ @RecordQuery
┌───────────────────────────▼─────────────────────────────────┐
│ QueryRecordService │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 参数转换 │ │ 异步保存 │ │ 错误处理 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└───────────────────────────┬─────────────────────────────────┘
│ MyBatis
┌───────────────────────────▼─────────────────────────────────┐
│ 数据库 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ query_record 表 │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ 用户ERP │ │ 查询类型 │ │ 请求URI │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ 响应数据 │ │ 耗时(ms) │ │ 查询状态 │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘这个设计的核心思路:
1.AOP切面拦截:通过注解标记需要记录的方法,零侵入式实现
2.异步处理:独立线程池处理记录保存,不阻塞主业务
3.分层设计:BO/DO分离,符合DDD思想
4.2 代码实现:AI的输出
4.2.1 表结构设计与实体类定义
kotlin
@Data
public class QueryRecordDO {
//具体的字段
}4.2.2 注解定义
less
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface RecordQuery {
QueryType queryType(); // 查询类型
boolean async() default true; // 是否异步
boolean recordResponse() default true; // 是否记录响应
int maxResponseLength() default 10000; // 响应数据最大长度
}4.2.3 切面实现
less
@Aspect
@Component
@Order(2)
public class QueryRecordAspect {
@Autowired
private QueryRecordService queryRecordService;
@Around("@annotation(com.jd...RecordQuery)")
public Object recordQuery(ProceedingJoinPoint joinPoint) throws Throwable {
// 获取注解配置
RecordQuery recordQuery = signature.getMethod().getAnnotation(RecordQuery.class);
// 创建记录对象
QueryRecordBO queryRecordBO = createQueryRecordBO(joinPoint, recordQuery, request);
long startTime = System.currentTimeMillis();
try {
// 执行目标方法
result = joinPoint.proceed();
// 记录成功信息
queryRecordBO.setQueryStatus("SUCCESS");
queryRecordBO.setDuration(System.currentTimeMillis() - startTime);
return result;
} catch (Exception e) {
// 记录失败信息
queryRecordBO.setQueryStatus("FAILED");
queryRecordBO.setErrorMessage(getErrorMessage(e));
throw e;
} finally {
// 异步保存记录(不影响主流程)
queryRecordService.saveQueryRecordAsync(queryRecordBO);
}
}
}4.2.4 异步处理配置
less
@Configuration
@EnableAsync
public class AsyncConfig {
@Bean("queryRecordExecutor")
public Executor queryRecordExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5); // 核心线程数
executor.setMaxPoolSize(10); // 最大线程数
executor.setQueueCapacity(1000); // 队列容量
executor.setThreadNamePrefix("QueryRecord-");
executor.setRejectedExecutionHandler(new CallerRunsPolicy());
return executor;
}
}4.2.5 业务接入
Controller层只需要添加一个注解:
less
@PostMapping("/query")
@ResponseBody
@RecordQuery(queryType = QueryType.POLICY_MATCH, recordResponse = true)
public Result<List<PolicyVo>> query(@RequestBody PolicyParamVo policyParamVo) {
return policyDomainService.queryPolicyCommand(policyParamVo);
}就这样,查询记录功能自动生效。
4.3 两种视角的实现差异
当你具备代码能力时
你可以对AI输出的代码进行code review:
typescript
// 你发现:客户端IP获取不够完善
private String getClientIp(HttpServletRequest request) {
String ip = request.getHeader("X-Forwarded-For");
// 只考虑了一种情况,需要补充
}可以要求AI改进:
"需要考虑多层代理的情况,补充X-Real-IP和Proxy-Client-IP的处理"
AI调整后的代码:
ini
private String getClientIp(HttpServletRequest request) {
String ip = request.getHeader("X-Forwarded-For");
if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("X-Real-IP");
}
if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("Proxy-Client-IP");
}
if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("WL-Proxy-Client-IP");
}
if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {
ip = request.getRemoteAddr();
}
// 多IP情况取第一个
if (ip != null && ip.contains(",")) {
ip = ip.substring(0, ip.indexOf(",")).trim();
}
return ip;
}当你代码能力有限时
你可能看不懂这段代码在做什么,但你会关注:
"如果记录失败了怎么办?用户查询会受影响吗?"
AI解释:
"不会。代码使用了try-catch-finally结构,即使记录失败也会捕获异常并打印日志,不会影响主业务流程。同时采用了异步处理,记录操作在独立线程中执行。"
你继续追问:
"那如果记录的数据特别大呢?比如响应有好几MB?"
AI回应:
"代码中有maxResponseLength配置,默认10000字符,超过会自动截断。您也可以根据需要调整这个参数。"
通过这样的对话,即使不懂代码细节,你也能确保业务需求被满足。
五、交给时间去检验
5.1 最终成果
功能已完成上线,实现了以下能力:
完整记录:所有查询操作自动记录,包括用户、参数、响应、耗时等
高性能:异步处理,对主业务零影响
易扩展:新增查询类型只需添加枚举值和注解
易维护:代码结构清晰,符合分层架构
5.2 架构优势
整个功能的扩展性体现在:
1.新增查询类型:只需在QueryType枚举中添加,然后在Controller方法上加注解
2.调整记录策略:通过注解参数控制是否异步、是否记录响应、最大长度
typescript
// 新增一个查询类型,只需两步:
// 1. 枚举定义
YB_CUSTOM("YB_CUSTOM", "查询XXX业务定制化信息");
// 2. 注解使用
@RecordQuery(queryType = QueryType.YB_CUSTOM, recordResponse = true)
public Result<YBOrderInfoDTO> queryYbCustomInfo(...) { }5.3 自测过程
作为测试开发,自测是我的专业领域。我设计了以下测试场景:
| 场景 | 预期结果 | 实际结果 |
|---|---|---|
| 正常查询 | 记录成功,状态SUCCESS | ✅ 通过 |
| 查询异常 | 记录成功,状态FAILED,记录错误信息 | ✅ 通过 |
| 大响应数据 | 自动截断,不影响存储 | ✅ 通过 |
| 高并发查询 | 异步处理,主业务响应时间无明显变化 | ✅ 通过 |
| 用户未登录 | ERP记录为unknown | ✅ 通过 |
六、人,还是关键
6.1 两种路径的对比
| 维度 | 具备代码能力 | 代码能力有限 |
|---|---|---|
| 技术方案理解 | 能快速理解并评估 | 需要AI解释概念 |
| 代码质量把控 | 能发现潜在问题 | 依赖AI主动提示 |
| 沟通方式 | 技术语言为主 | 业务语言为主 |
| 验收方式 | 代码审查+功能测试 | 场景提问+功能测试 |
| 核心价值 | 架构把控+技术决策 | 需求翻译+业务验收 |
6.2 测试开发的独特优势
这次实践让我意识到,作为测试开发岗位,我们有两个独特的优势:
1. 测试思维
我们知道如何设计测试用例,知道哪些边界条件需要考虑:
•异常情况怎么处理?
•大数据量怎么办?
•并发场景怎么保障?
这些思维习惯,让我们在与AI的对话中,能够提出更有价值的问题。
2. 质量把控
我们熟悉验收标准,知道什么叫做"做好了":
•功能是否完整?
•性能是否达标?
•异常是否兜底?
这让我们能够有效评估AI的输出是否满足要求。
6.3 AI时代的测试开发定位
这次实践后,我对测试开发的新定位有了新的思考:不是被AI替代,而是与AI协作。
我们不需要成为比开发更懂代码的人,但我们需要:
1.懂业务:清楚要解决什么问题
2.懂验收:知道怎样才算做好
3.懂协作:能引导AI产出我们需要的方案
七、起点,不是终点
7.1 两种声音的答案
回到文章开头的那两个问题:
如果我具备代码能力,开发这个平台能让AI做什么?
AI可以做技术方案设计、代码生成、代码审查。我负责架构决策、质量把控、自试验收。
如果我代码能力有限,该怎么结合AI完成这个平台?
我用业务语言描述需求,让AI翻译成技术方案。我用场景化问题验证方案,让AI补充边界处理。虽然沟通成本更高,但依然能交付。
7.2 给测试开发的建议
如果你也是测试开发,正在考虑如何拥抱AI时代,我的建议是:不必焦虑于"代码不如开发",因为你本来就擅长别的东西。
测试开发的核心竞争力,从来不是比开发更会写代码,而是:
•比开发更懂测试
•比测试更懂技术
•比产品更懂落地
在AI时代,这三点依然有效,甚至更重要了。
懂测试:你知道如何验证AI的输出是否正确
懂技术:你能理解AI的建议并做出判断
懂落地:你知道从需求到上线的完整链路
7.3 结语
这篇文章的标题提到了"两条路线,一个答案",因为无论是代码高手还是代码新手,在AI时代都能找到自己的路径。区别只在于:
•有人走在"技术驱动"的轨道上,用代码能力引导AI
•有人走在"业务驱动"的轨道上,用业务思维引导AI
但最终,两条轨道都会交汇在同一个终点:交付价值。
AI不会取代你,它只是在你的工具箱里,又添了一把好用的锤子。至于怎么用这把锤子,取决你想打造什么。
说了这么多,最后想聊聊心态。
和AI打交道久了,我越来越觉得,AI就像一把双刃剑------用好了是神兵利器,用不好也可能伤到自己。保持热爱,因为它真的很强大;保持敬畏,因为它不是万能的。
热爱让我们愿意去探索、去尝试、去相信"也许可以试试";敬畏让我们在关键时刻保持清醒,不盲从、不迷信、不让AI替我们做决定。
这篇文章记录的是一次真实的AI新范式实践,如果这篇文章对你有启发,欢迎交流讨论。AI时代,我们一起探索。