用 API 中转站的人,心里大多压着四个问题:
- 模型有没有被偷梁换柱。我点的是 gpt-5.5,给我的真是它吗,还是偷偷换成了更便宜的小模型?
- 数据安全吗。我的代码、提示词、密钥,会不会在中间被记下来、被转走?
- 稳不稳。会不会动不动超时、限流、半路断流?
- 价格。便宜多少,便宜在哪,有没有藏着更贵的坑?
这些问题,光看中转站自己的宣传页是得不到答案的,广告谁都会写。于是我做了件更实在的事:写了一个评测工具 llm-gateway-eval(目前还在打磨,计划后面开源),把"中转站靠不靠谱"拆成能跑、有证据的测试,再拿它实测了一家叫微元算力(weytoken)的中转站。
这篇先讲这套评测怎么测、为什么这么测才可信,再讲 weytoken 实测下来什么样。有亮点,也有短板,都如实写。
一、先说测评原理
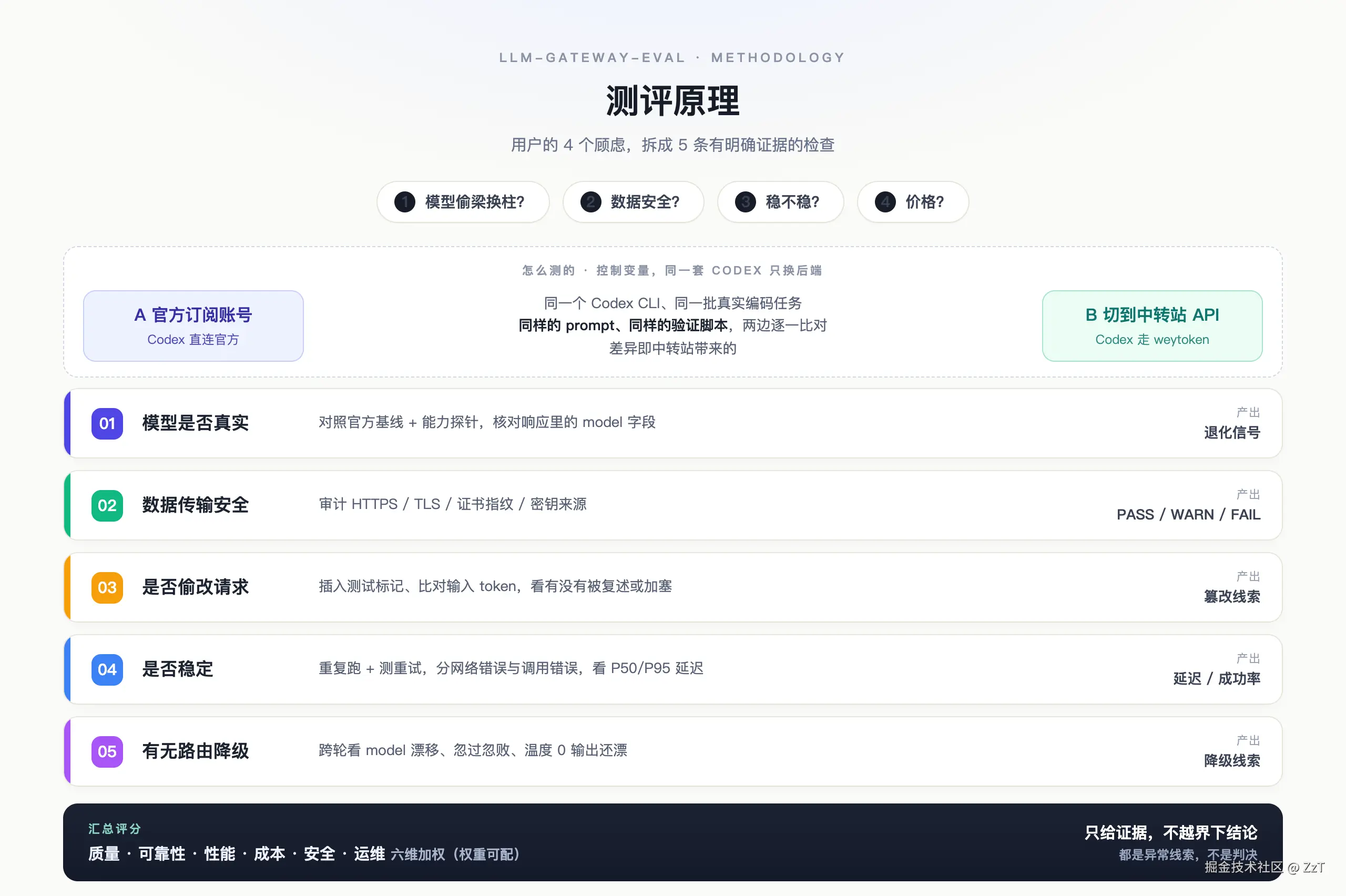
想法很简单:你把真实的代码、真金白银的调用交给一个中转站,它就不是"能回一句你好"就算靠谱的东西。该像对待任何一个你要长期依赖的服务那样,认真查一遍它有没有在中间偷工减料。
具体怎么跑?我用 Codex 当测试载体------它是个真在干活的编码 agent,会多步改代码、跑命令,而且产出能用脚本验证对错(过 / 不过),这比单纯比"两段文本谁更像"硬得多。一段能跑通验证的代码,骗不了人。
做法是控制变量的 A/B 对比。基线那侧,让 Codex 用官方订阅账号直连官方;测试那侧,只改一处------把后端 provider 切到中转站的 API,其余全不动:同一个 Codex、同一批真实编码任务(发票汇总、JSONL 事件、Markdown 目录、回文、重试调度)、同样的 prompt、同样的验证脚本、同样的重复次数。这样跑下来,两边在通过率、耗时、token 用量上的任何差异,就能干净地归到中转站这一层。下面五条检查,都是从这套对比里读出来的信号。
它把上面四个顾虑拆成五条可执行的检查线,每条都遵循同一个原则:只给证据,不越界下结论。这点后面会反复出现,也是我觉得它比"截图测评"靠谱的地方。
模型是不是真的? 没有任何一句 prompt 能"证明"模型身份,所以这里做的是异常检测,不是断案。它和官方直连基线跑同一批用例、同样的解码参数,比对结果差异;跟踪请求的 requested_model 和响应里的 model 字段是否对得上;跑一组能力探针(推理、编码、JSON/Schema 遵循、长上下文哨兵查找),看有没有明显的能力塌陷。对编码这种能解释的任务,它用"可执行验证"------让 Codex 真去改代码、跑验证脚本,比单纯比文本更硬。工具自己也写得很清楚:这能抓出可疑的退化和元数据不一致,但不能从密码学上证明上游就是那个模型。这种克制,是我愿意信它结论的前提。
数据传输安全吗? 底线是 HTTPS 加证书与主机名校验。它的 audit 会在线检查:非本地端点是否走 HTTPS、TLS 握手与主机名校验是否通过、证书有效期、DNS 解析、叶子证书的 SHA-256 指纹与颁发者,以及密钥是不是只从环境变量读、配置里有没有硬编码的凭证头。
它有没有偷改我的请求? 黑盒客户端没法证明网关从不加塞隐藏提示词,于是它插入一组测试标记来收集异常证据:不该被复述的假 API key、假邮箱,必须原样返回的系统完整性令牌,隐藏指令 JSON 探针,还有一个可选的外部 URL 标记(honeytoken),用来看数据有没有被带到带外去访问。再配合一个信号:同样的 prompt,如果网关那侧输入 token 明显高于官方基线,往往意味着被塞了隐藏提示词,或者被包了一层。
稳不稳? 稳定性靠重复请求,不是一次成功的冒烟。它会把每个用例跑多次、测重试行为,并把错误分两类统计:网络错误(超时、TLS、连接失败)和模型调用错误(429、4xx、5xx、响应畸形),再算 P50/P95/P99 延迟、tokens/s 和成功率。报告还建议在一天里不同时段各跑一轮。
有没有偷偷路由降级? 它收集一组黑盒信号:同一请求模型在多次运行里 model 值变了、官方比网关明显更容易通过某用例、同一用例忽过忽败、温度 0 下输出还在漂。这些都当线索,不当判决。
最后它把这些汇成一份带分数的报告,质量、可靠性、性能、成本、安全、运维六个维度加权打分,权重可配,成本归一化到"最便宜的非零方案得 100"。
我把原理摆出来不是为了显摆工具,是想说明一件事:下面对 weytoken 的判断,都来自这套有据可查的检查,不是凭感觉。
二、weytoken 实测
测试目标是 weytoken(官网 api.weytoken.com/ ),API 端点 https://api.weytoken.com/v1,主力跑的是 codex 分组里的 gpt-5.5。分四块说,该夸的夸,该提醒的提醒。
模型有没有被换:对比下来挑不出差
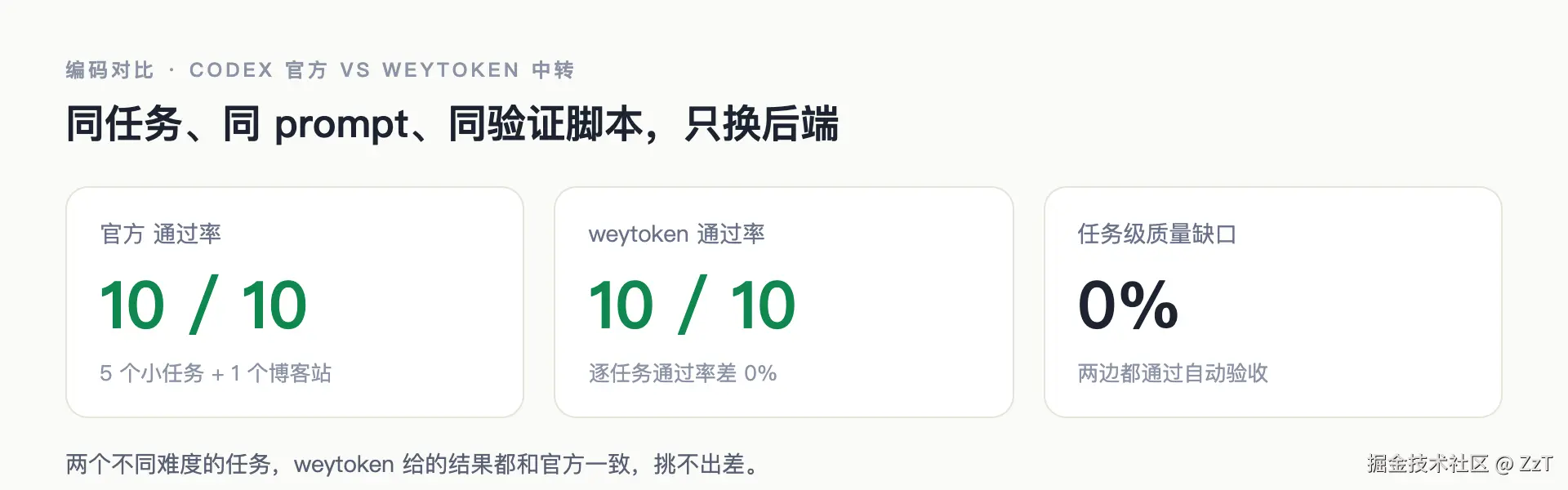
就用前面那套 A/B 对比,配对编码是其中最硬的一条线:5 个编码任务各跑 2 遍,官方一侧和 weytoken 一侧各 10 次。
结果是官方与 weytoken 两边都 10/10 全过,逐任务通过率差 0%,没有任务级别的质量缺口。
我又加了个更难的任务来验证:让 Codex 拿我自己写的几篇技术文章当数据,搭一个静态个人博客网站,配一套自动验收脚本(覆盖数据处理、文章排序、搜索与标签过滤、精选文章、阅读时间、响应式布局等)。官方、weytoken 各跑一遍,两边都通过验收,通过率还是 0% 差。"没质量缺口"这个信号,不止靠一个任务撑着,换个更复杂的活儿也立得住。
同一份 prompt 下,两边各自生成的首屏对比如下:
任务:用几篇真实技术文章当数据,搭一个静态个人博客,带自动验收脚本(数据处理、文章排序、搜索与标签过滤、精选、阅读时间、响应式布局)。
| prompt(网站任务) | 官方效果 | 中转效果 |
|---|---|---|
| 用几篇真实技术文章当数据,搭一个静态个人博客,带自动验收脚本(数据处理、文章排序、搜索与标签过滤、精选、阅读时间、响应式布局) |  |
 |
功能上都过了自动验收,设计取向却不一样:官方那版偏浅色、清爽,像规整的技术博客;weytoken 这版偏深色、杂志风,视觉记忆点更强、信息密度略低。这种差异更多是模型当次的发挥,不必过度解读------重点是两边都做出了能用、能过验收的站点。
两个任务、两种难度,在编码这类能验收对错的活儿上,weytoken 给的结果和官方一致,挑不出差。模型这块,至少从实际表现看是稳的。
数据安全:传输层扎实

传输配置审计 10 项全 PASS:走 HTTPS、TLS 1.3 握手通过、证书由 DigiCert 签发且在有效期内(到 2026 年 8 月)、主体是 api.weytoken.com、密钥只从环境变量读、没有硬编码的静态密钥头。传输这一层,达标。
至于内容层会不会被复述、被带外泄漏,这是更深一层的检查,需要专门的探针和退避节奏单独跑一轮,本篇先到传输层为止。真要送私密代码或客户数据上生产,这一层建议自己再认真做一遍。
稳定性:能稳定跑通,速度上有取舍
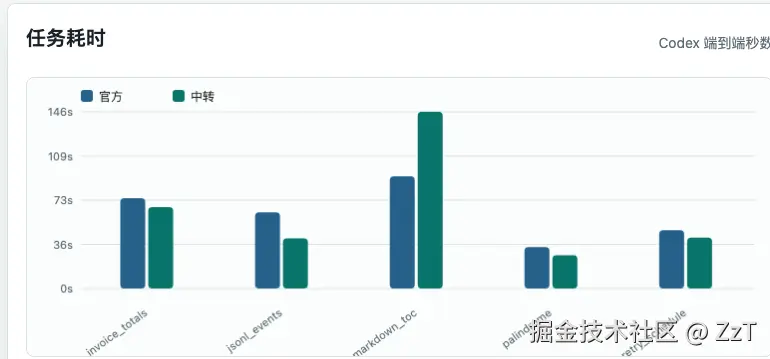
先说能跑通的:前面那批编码任务,加上后来的博客站任务,真实 Codex 会话全程经 weytoken 跑通、通过验收,没有中途断流。正常使用强度下,它是稳的。
代价主要在速度。还是博客那个任务,weytoken 跑完用了 484.94 秒,官方只用 273.67 秒,多花了两百多秒、约七成时间,期间消耗的 token 也更多。更长的任务更明显:那个功能更密的 dashboard,官方和 weytoken 两边都撞到了运行器 300 秒上限(官方 300s、weytoken 重试 360s),不过两边超时前都把产物做出来了,手动跑验收脚本都能过。所以稳定性这块的结论是:真实活儿能完成,但耗时开销实打实,任务越长越容易触顶,这一条要扣分。
要说明的是,这里说的是整个任务跑完的耗时,不是逐请求的微延迟。另外 weytoken 有每分钟 20 次的限流,这是防滥用的正常设计,高频调用要把它算进去。
价格:旗舰确实便宜,但不是样样都便宜
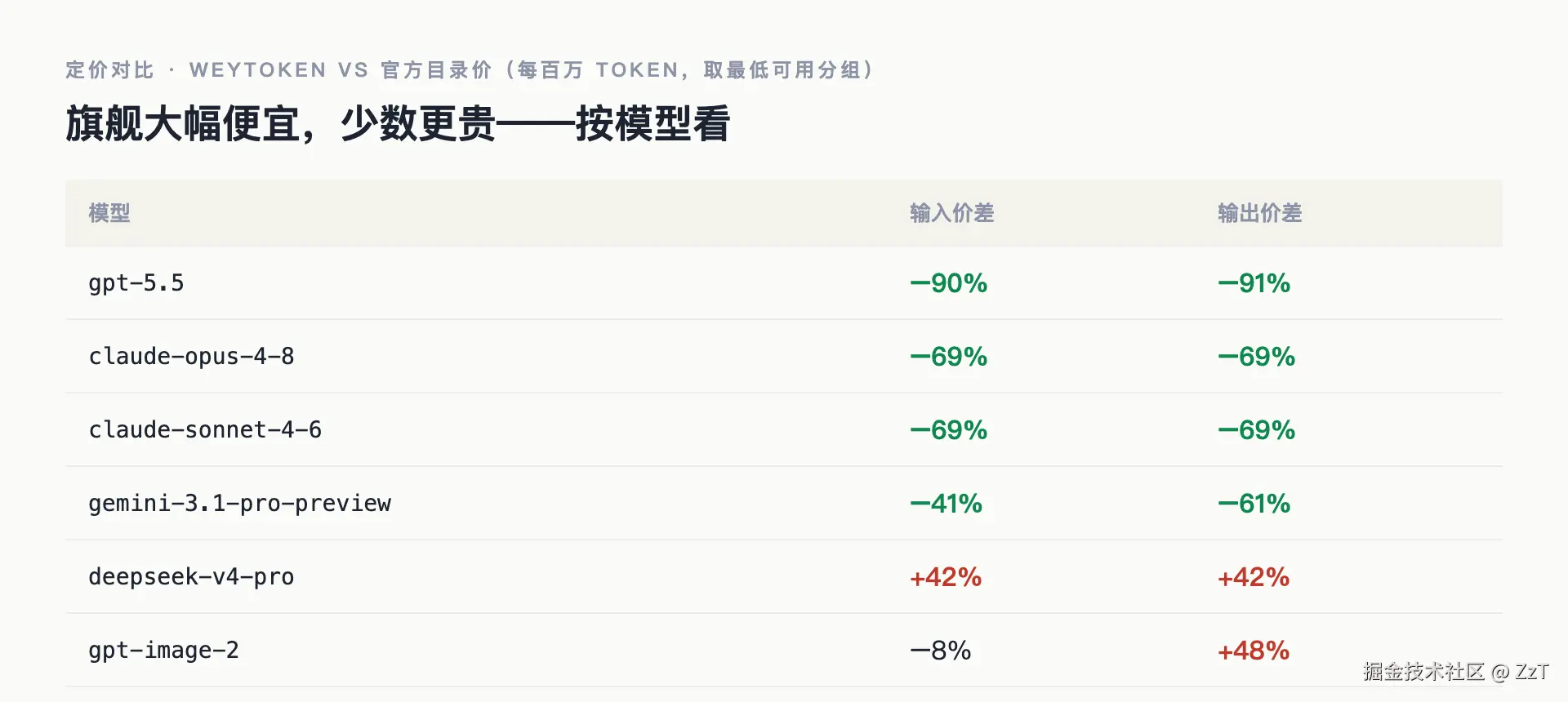
价格这块数据最干净。工具直接抓 weytoken 公开的 /api/pricing,按它前端同款公式算出每个模型的输入输出价(input = model_ratio × 2 × group_ratio,output = input × completion_ratio),再和官方目录价逐一对比,一共覆盖 37 个模型分组。
便宜的地方很猛,对比官方目录价、取最低可用分组:
gpt-5.5:输入 ¥2.4、输出 ¥19.2(每百万 token),相对官方约 −90%;claude-opus-4-8、claude-sonnet-4-6:约 −69%;gemini-3.1-pro-preview:输入 −41%、输出 −61%。
但不是全面便宜,有几个反而更贵:
deepseek-v4-pro:输入输出都比官方 +42%;gpt-image-2:输出价 +48%;gemini-2.5-flash、gemini-3-flash的部分价位也略高于官方。
所以"便宜"得落到具体模型上看。补两句口径:这里基于"最低可用分组"和工具内置的官方目录价,真实到手价取决于你所在的分组档位;而且这是按调用计费的口径,weytoken 另外还有周卡、月卡、季卡这类订阅,长期重度用的人要按自己的用量另算。
三、weytoken 企业功能
抛开评测单说能力盘子。模型覆盖挺全,Claude、GPT、Gemini、DeepSeek、通义千问、Kimi、智谱等 37 个左右,按 codex 专用、claude 专用、gemini 专用、图像生成等分组组织。
真正让我觉得"这是给团队用的",是它那套企业控制台。它不是把个人 key 简单包一层,而是围绕"可控、可审计、可管权限"做了一整套:
- 统一额度池加双层配额:企业层有总额度、已用、剩余和实时使用率;往下还能给每个成员设额度上限,给每个令牌设独立配额。花超不了,也能精确归因到人和 key。
- 模型级权限:能限定某个成员、某个令牌只能用哪些模型。不想让人随便调最贵的模型,这里就能卡。
- 角色权限(RBAC)和成员管理:邀请成员、分角色、看加入时间和状态,成员上限 50,令牌上限 100。
- IP 白名单:设置后,企业下所有令牌只能从白名单 IP 访问 API。这条对企业数据安全很实在,等于把 key 泄露的影响面摁住。
- 全量审计日志:谁、在什么时间、做了什么操作、对象是什么,都留痕,还能按操作类型筛。合规和事后追溯要的就是这个。
- 用量可观测和导出:消耗明细能按成员、模型、令牌拆,细到每次调用的提示、补全、缓存 token、消耗额度和单次耗时,还有平均 RPM/TPM 与成员排行,支持导出。
这几样组合起来,正好对应企业用中转站最担心的几件事:钱不可控、权限放养、出了事查不到。个人用户可能用不上,但对要给一个团队统一发 key、统一管账的人来说,这套是有意义的。
四、结论
把测下来的东西收一收:
- 模型真伪:两个不同难度的编码任务(5 个小任务 + 一个完整博客站),weytoken 都和官方一致、挑不出差。
- 数据安全:传输层(HTTPS、TLS 1.3、有效证书、不硬编码密钥)达标;内容层的更深检查留作专项。
- 稳定性:真实编码任务都能跑通、通过验收,速度上有取舍------博客任务比官方多花约七成时间(485s vs 274s),长任务两边都会撞运行器时限。
- 价格:旗舰模型尤其 gpt-5.5 和 Claude 系显著便宜,但少数模型更贵,按模型看。
- 企业能力:双层配额、模型级权限、IP 白名单、全量审计、用量可观测,面向团队管控这块做得扎实。
适合谁:想用上 Claude、GPT、Gemini 又在意成本、且能接受中转站固有"信任前提"的人,尤其是需要给团队统一管 key、管账、管权限的小团队。注意什么:上生产、或要送真实私密代码和客户数据之前,内容层泄漏这条建议自己用带退避的方式再测一轮,再叠加供应商的数据留存条款、计费对账这些合同层面的东西。黑盒评测能给你证据,但替代不了一纸契约。
这套测评工具还在打磨,计划后面开源。方法和用例这篇都摆出来了,等开源了,你大可自己拿它跑一遍验证。比起信我说的,这才是它存在的意义。