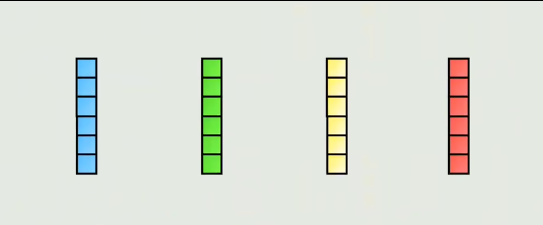
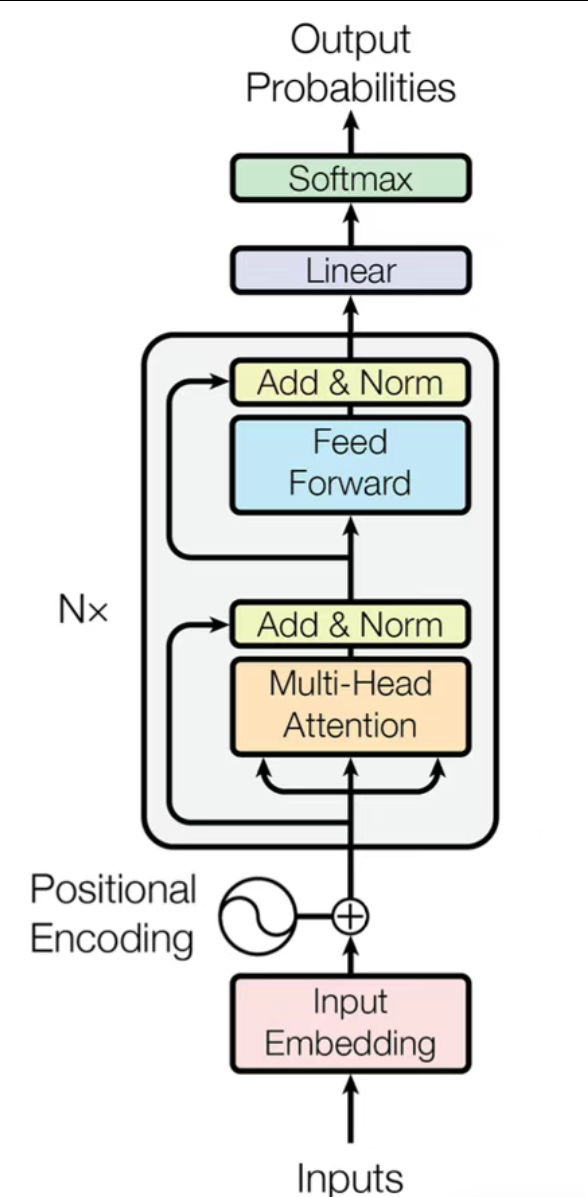
标准的Encoder Only类型的Transformer架构的示意图
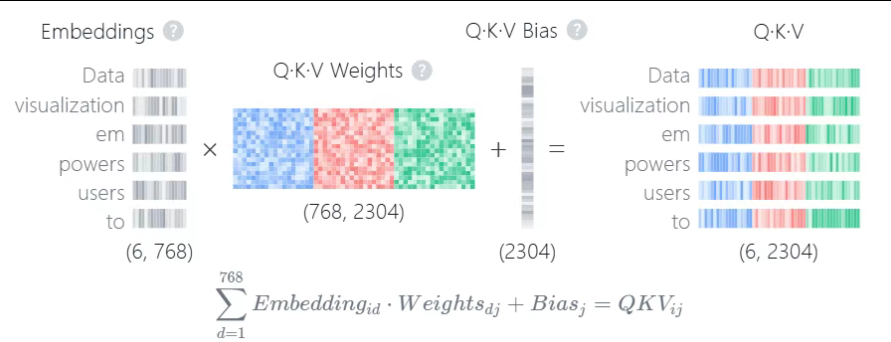
关于QKV矩阵

参考B站视频1(VIT)
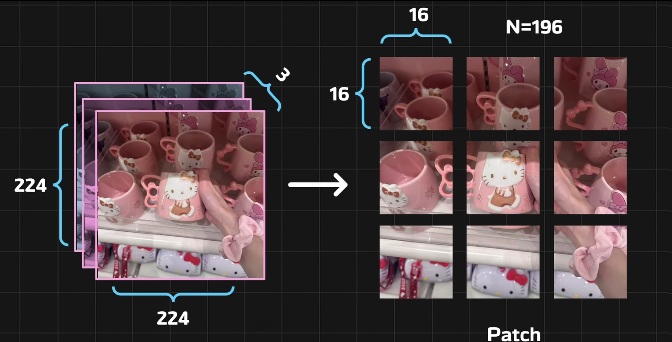
patchs切块
196块patchs
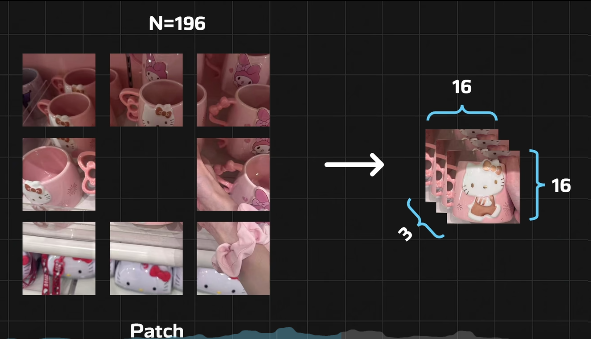
Flatten展平
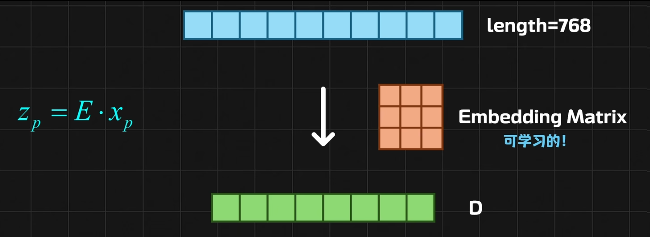
196个768维的向量
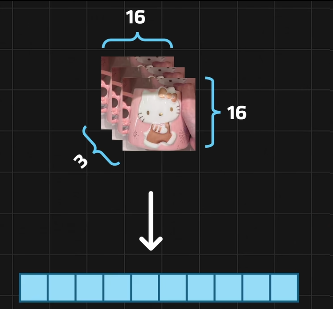
Linear Projection线性投射
196个N维的向量
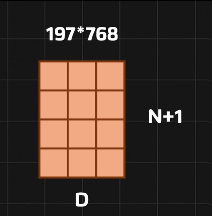
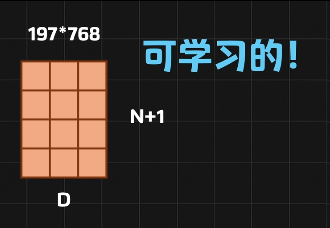
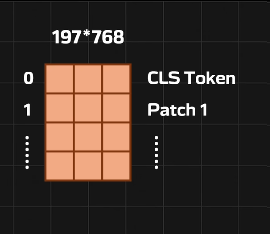
CLS Token
197个长度D的向量
序列长度就是分了多少块patch

假设这个D还是768,最终得到197个768维的被编码的Token

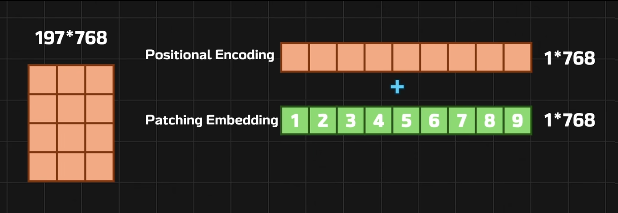
Positional Encoding加入位置编码

位置编码向量
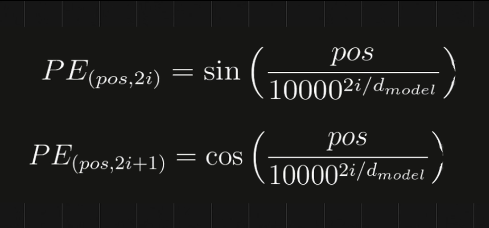
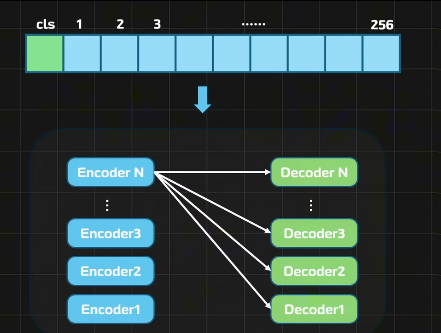
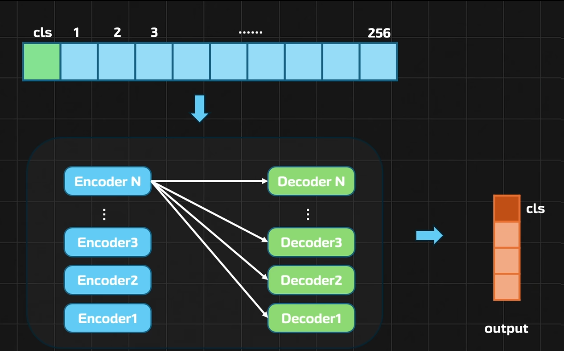

VIT改进
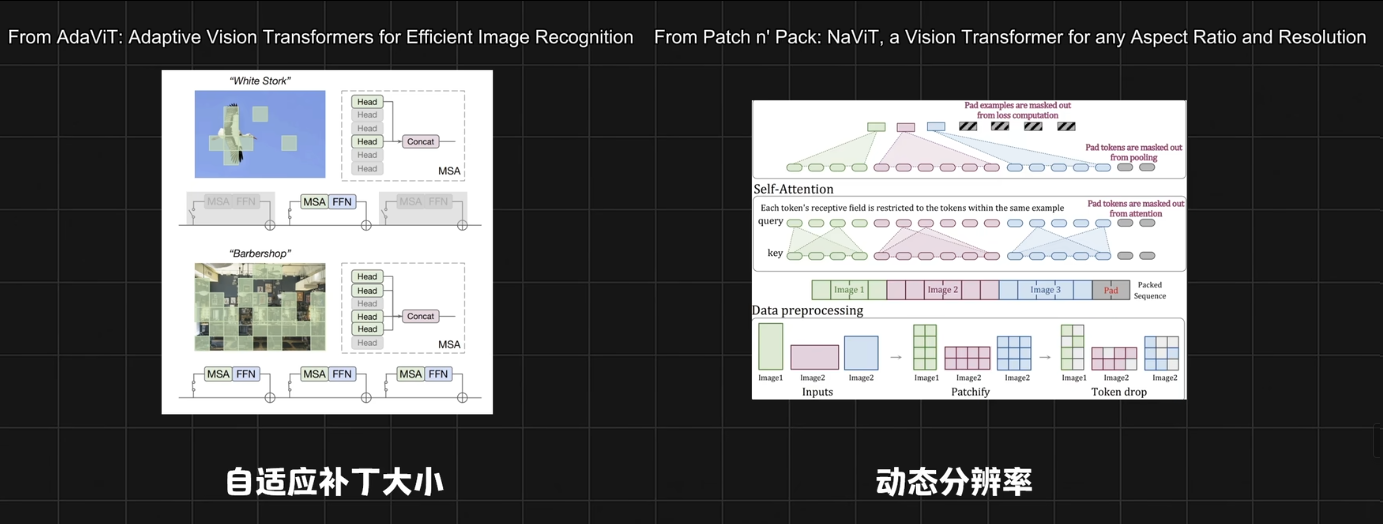
理解输入输出

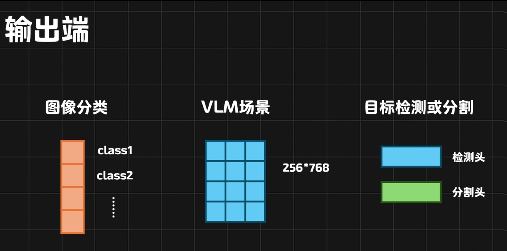
输出取决于任务要求
参考B站视频2(VIT)
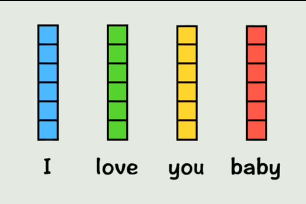
灰色代表位置编码,直接加进去得到新的
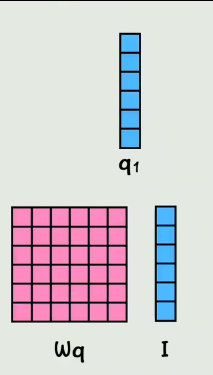
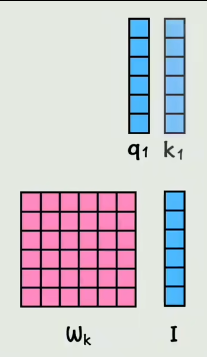
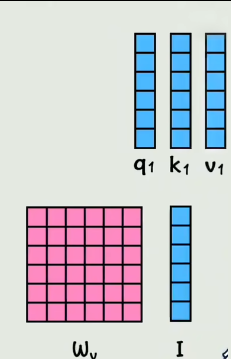
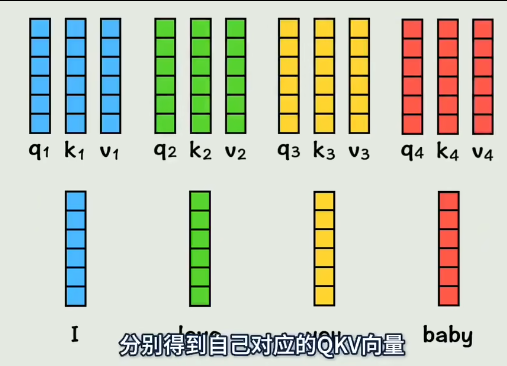
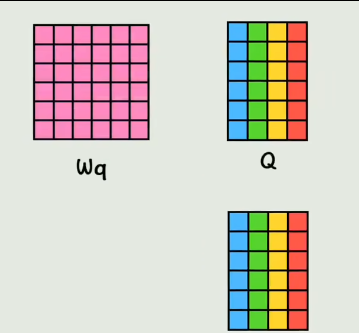
实际在GPU运算的时候,是通过拼接而成的大矩阵做乘法,不是像上边一样一个个乘
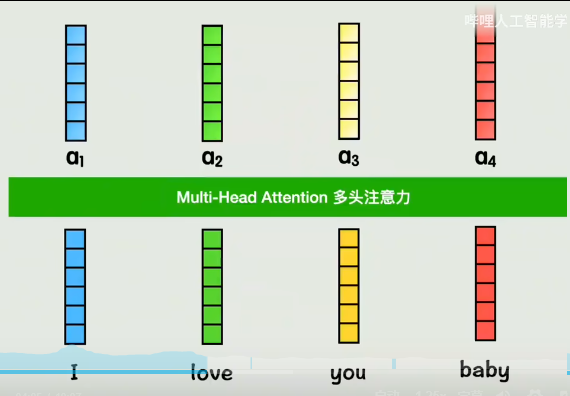
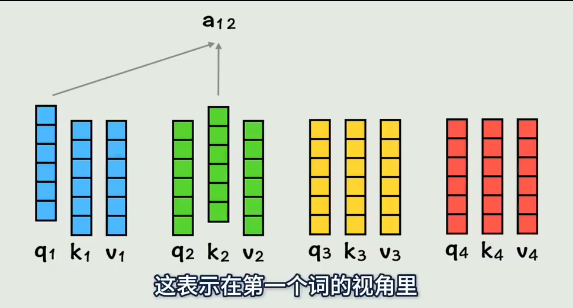
q1和k2做点积,表示:第一个词和第二个词的相似度是多少
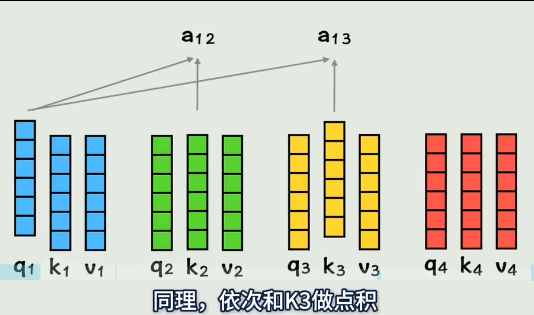
q1和k3做点积,表示:第一个词和第三个词的相似度是多少
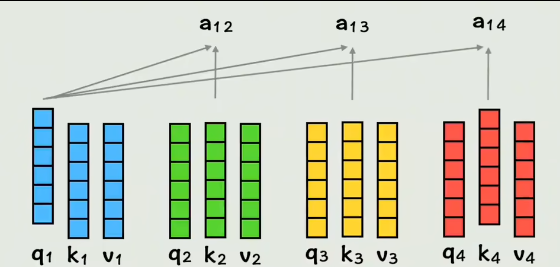
q1和k4做点积,表示:第一个词和第四个词的相似度是多少
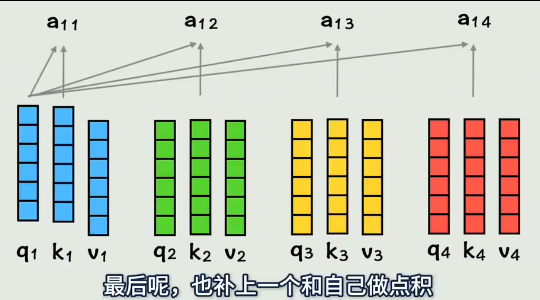
最后q1和自己也做个点积,表示和自己的相似度
拿到相似度系数之后,分别与V向量相乘,再相加
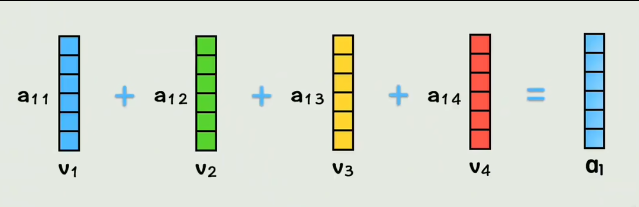
此时这个a1就表示,在第一个词的视角下,按照和它相似度大小,按权重,把每个词的词向量都加到了一块,这就把全部上下文信息都包含在第一个词中去了。
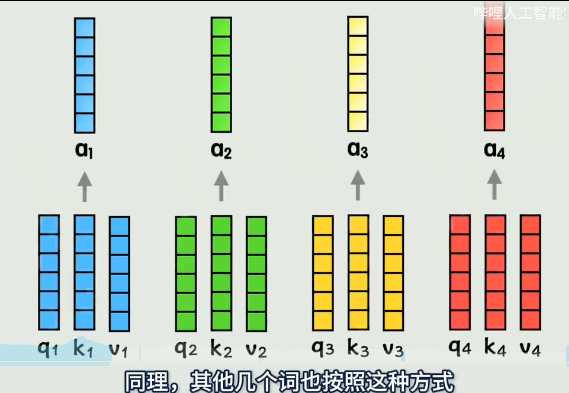
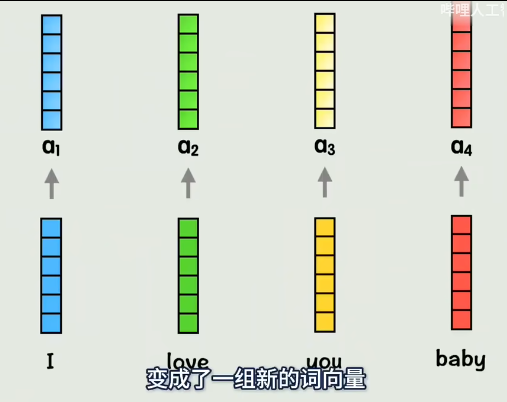
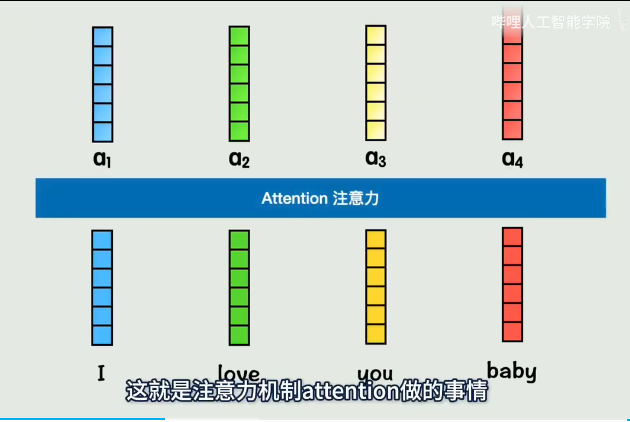
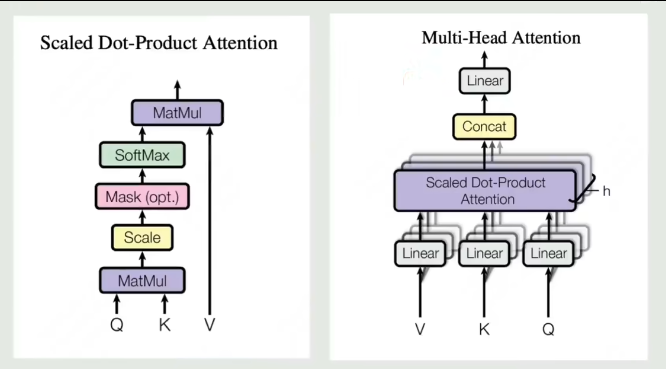
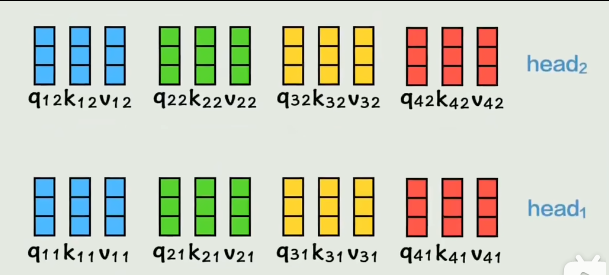
对于注意力机制来说,如果只通过一种计算方式计算一次,得到一组QKV,相关性灵活性会大大降低。
改进:
之前每个词计算一组QKV,现在在QKV基础上再经过2个权重矩阵变成2组QKV,给每个词2个学习机会,学习到不同的要计算相似度的QKV
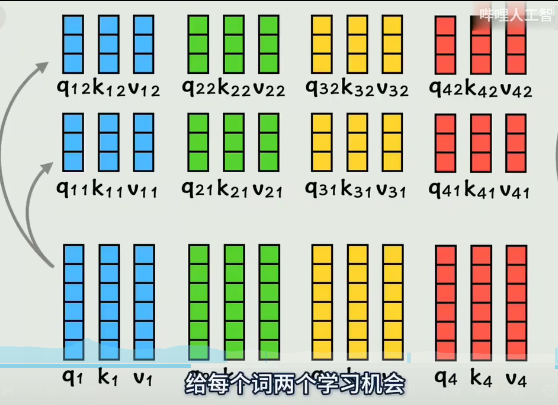
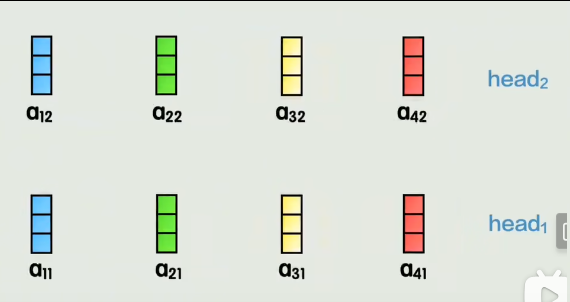
拼接