目录
[1.1 基本概念](#1.1 基本概念)
[1.2 三者关系](#1.2 三者关系)
[1.3 算法的学习方式](#1.3 算法的学习方式)
[1.4 人工智能发展三要素](#1.4 人工智能发展三要素)
[1.5 应用领域](#1.5 应用领域)
[3.1 有监督学习](#3.1 有监督学习)
[3.1.1 分类问题](#3.1.1 分类问题)
[3.1.2 回归问题](#3.1.2 回归问题)
[3.2 无监督学习](#3.2 无监督学习)
[3.2 半监督学习](#3.2 半监督学习)
[3.4 强化学习](#3.4 强化学习)
[4.1 获取数据](#4.1 获取数据)
[4.2 数据基本处理](#4.2 数据基本处理)
[4.3 特征工程](#4.3 特征工程)
[4.4 模型训练](#4.4 模型训练)
[4.5 模型评估](#4.5 模型评估)
一、AI、ML、DL概述
1.1 基本概念
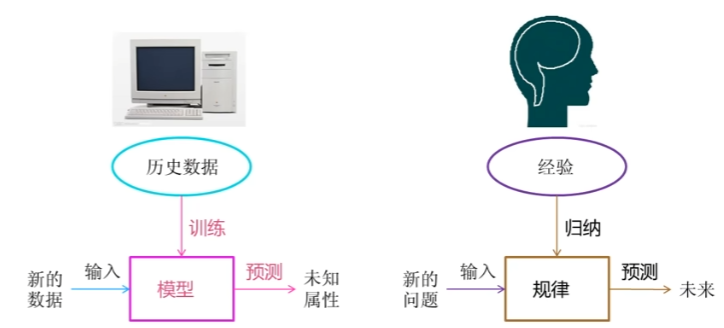
人工智能(AI Artificial Intelligence):用计算机模拟人脑,让计算机像人类一样理性的思考和行动。
机器学习 (ML Machine Learning):赋予计算机学习能力 而 不需要明确编程的研究领域,让机器从数据中自动学习规律,而不是依靠人类写死规则。可以解决靠人写规则太复杂、靠数据能找到规律的问题。
深度学习 (DL Deap Learning):使用多层神经网络(模拟人脑神经元结构)进行机器学习。
1.2 三者关系
三者关系:机器学习是人工智能的一个分支,是实现人工智能的途径。深度学习是实现机器学习的一种技术。
1.3 算法的学习方式
基于规则的学习:程序员根据经验手动if-else进行规则书写(传统编程方式)
但是很多东西无法书写规则,无法用规则学习的方式来解决问题
基于模型的学习:从数据中自动学习规律(机器学习)
1.4 人工智能发展三要素
人工智能发展的三大核心要素是:数据、算力、算法
1.5 应用领域
常见领域有:计算机视觉CV、自然语言处理NLP、语音技术、 推荐系统 、医疗与生物信息学等。
**计算机视觉CV:**对人看到的东西进行理解,让机器看懂图像/视频,如:人脸识别、图像识别、医学影像诊断、自动驾驶等。
**自然语言处理NLP:**对人交流的东西进行理解,让机器理解/生成文本,如:翻译、聊天机器人、文本摘要、情感分析等。
**推荐系统:**如:电商商品推荐、短视频 / 音乐推荐、信息流个性化推荐。
二、机器学习常用术语
样本(sample):数据集中的一条数据。比如一个学生的所有数据
特征(feature) :用于描述样本的属性或变量。一个特征通常是一列数据,有一个对应的名字:特征名
标签/目标值:模型要预测的目标值(答案)
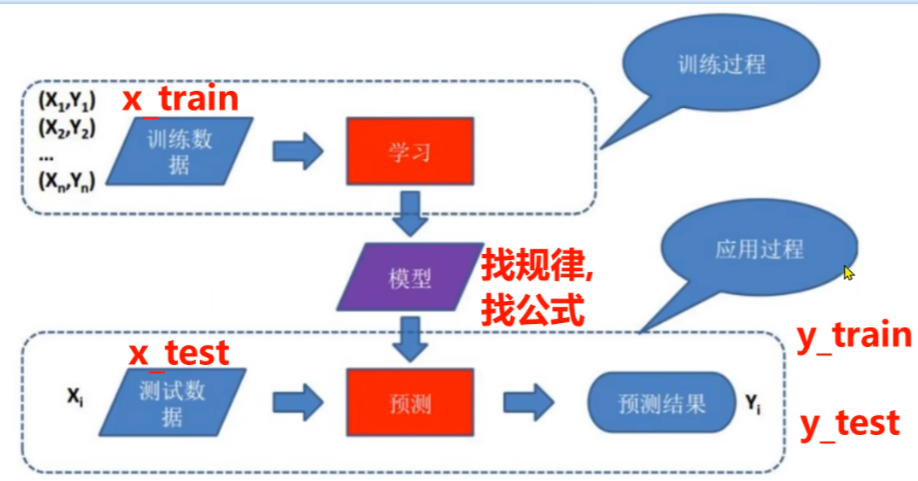
数据集:多个样本组成数据集,是训练集和测试集的总和,二者比例一般是8:2或者7:3
训练集:用于训练模型的数据。
测试集:模型完全没见过的数据,用于最终评估
待更新,每遇到新名词就添加
三、机器学习算法分类
3.1 有监督学习
有监督学习:利用带有标签的训练数据,学习输入到输出的映射关系,目的是让模型对新的未知数据做出预测。
特点 :有 特征、有标签
常见算法:线性回归、逻辑回归、决策树、朴素贝叶斯、K近邻算法 等
3.1.1 分类问题
标签值是不连续/离散的,比如薪资:低、中、高
目的:判断属于哪一类
分类种类:二分类、多分类(3个及以上的分类)
3.1.2 回归问题
标签值是连续的,如房价
目的:预测一个具体数值
3.2 无监督学习
**无监督学习:**在没有标签、没有标准答案的数据中,根据样本的相似性进行聚类,发现内部的结构、规律。
特点 :有 特征、无标签
常见算法:K均值聚类、主成分分析、t-分布邻域嵌入等
3.2 半监督学习
半监督学习: 让专家标注少量数据,用少量带标签的数据训练一个模型,用模型套用大量没标签的数据,通过询问 领域专家分类结果 与 模型分类结果 做对比。
**优点:**降低专家标注成本
3.4 强化学习
**强化学习:**智能体通过与环境交互,以试错的方式学习策略,靠奖励学最优决策。是机器学习的一个重要分支。
常见算法:Q学习、深度强化学习等
四、建模流程
4.1 获取数据
搜索与完成机器学习相关的数据集,获得经验数据、图像数据、文本数据等
4.2 数据基本处理
数据缺失值处理、异常值处理等
4.3 特征工程
利用专业背景知识和技巧处理数据,对数据特征进行提取、转成向量,让模型达到最好的效果。
2.2 和2.3一般是建模过程中耗时、耗经历最多的
子任务:
1、特征提取:从原始数据中提取与任务相关的特征,构成特征向量,会改变原数据
2、特征预处理:因量纲/单位问题,不同特征对模型的影响也不同
3、特征降维:将数据的维度降低
4、特征选择:选择与任务相关的特征集合子集,不会改变原数据。
5、特征组合:把多个特征合并成一个特征
4.4 模型训练
选择合适的算法对模型进行训练,如线性回归、逻辑回归等
4.5 模型评估
若评估效果好 就上线服务,评估效果不好就重复上述步骤。
五、模型拟合问题
拟合:用来表示模型对样本点的拟合情况
过拟合:模型在训练集表现好 、测试集表现差
过拟合原因:模型过于复杂、数据少或训练过度,解决方法是加数据、降复杂度等
欠拟合:模型在训练集表现差 、测试集表现差
欠拟合原因:模型过于简单、特征不足,解决方法是加特征、提高模型复杂度。
泛化:是模型在新数据集(非训练数据)上表现的好坏
奥卡姆剃刀原则:对于两个具有相同泛化误差模型,较简单的模型 优先于 较复杂的模型
六、机器学习开发环境
基于Python的scikit-learn库,简单高效的数据挖掘和数据分析工具
下载方法:以管理员身份打开命令行,输入
XML
pip install scikit-learn等待下好即可,如图:

官网:https://scikit-learn.org/stable/
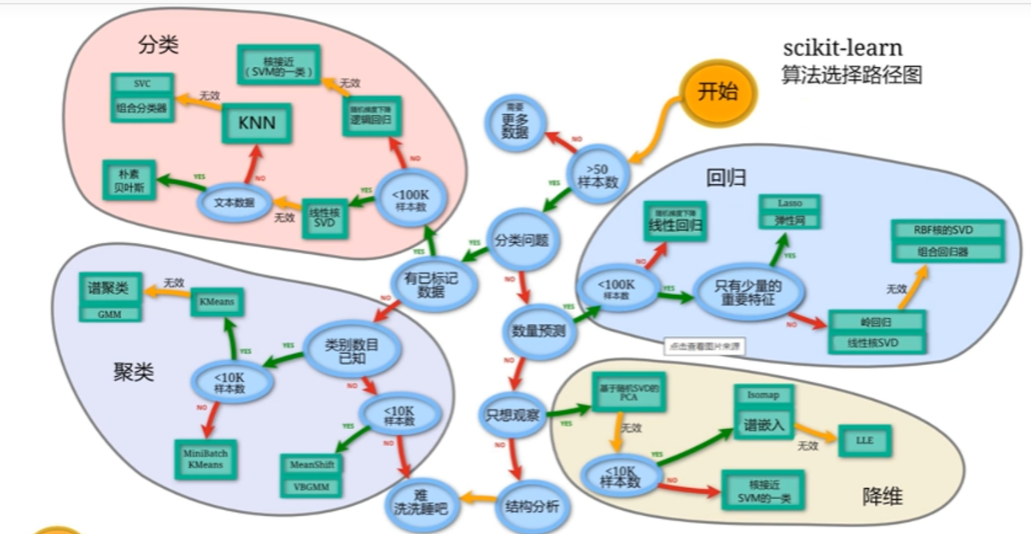
算法选择路径图: