摘要
本文介绍了线性回归的基本原理与应用。线性回归是一种监督学习算法,用于建模自变量与因变量之间的线性关系。文章从一元线性回归入手,以身高预测体重为例,说明了最小二乘法的核心思想------通过最小化预测误差的平方和来找到最佳拟合直线。进而扩展到多元线性回归,给出其矩阵表示形式。此外,文章还展示了基于scikit-learn的线性回归API使用方法,并详细解释了损失函数的概念,包括均方误差(MSE)与平均绝对误差(MAE)。本文为理解回归类问题奠定了数学基础。
Abstract
This article introduces the basic principles and applications of linear regression, a supervised learning algorithm for modeling linear relationships between independent variables and a dependent variable. Starting with simple linear regression, it uses height-weight prediction as an example to illustrate the core idea of the least squares method---finding the best-fitting line by minimizing the sum of squared prediction errors. The article then extends to multiple linear regression and presents its matrix representation. Furthermore, it demonstrates the use of scikit-learn's linear regression API and explains loss functions in detail, including Mean Squared Error (MSE) and Mean Absolute Error (MAE). This article lays a mathematical foundation for understanding regression problems.
一.线性回归简介
1.一元线性回归
线性回归是机器学习中一种用于建模自变量(特征)与因变量(目标)之间线性关系的监督学习算法。其核心思想是找到一条最佳拟合直线(在多元情况下是一个平面或超平面),使得所有样本点到该直线的垂直距离(即预测误差)的平方和最小,这种方法通常被称为"最小二乘法"。通过这条直线,我们可以根据输入的自变量数值来预测因变量的数值。
以身高预测体重为例,假设我们收集了100个人的身高和体重数据。首先,我们将身高作为自变量(x轴),体重作为因变量(y轴),每个样本对应坐标系中的一个点。线性回归模型会尝试找到一条形式为y=wx+b的直线(其中w是斜率也是权重,代表身高每增加1厘米时体重的平均变化量;b是截距也是偏置,代表身高为零时的理论体重)。通过最小化所有样本点的真实体重与直线上预测体重之间的误差平方和。算法计算出最优的w和b。如下图:
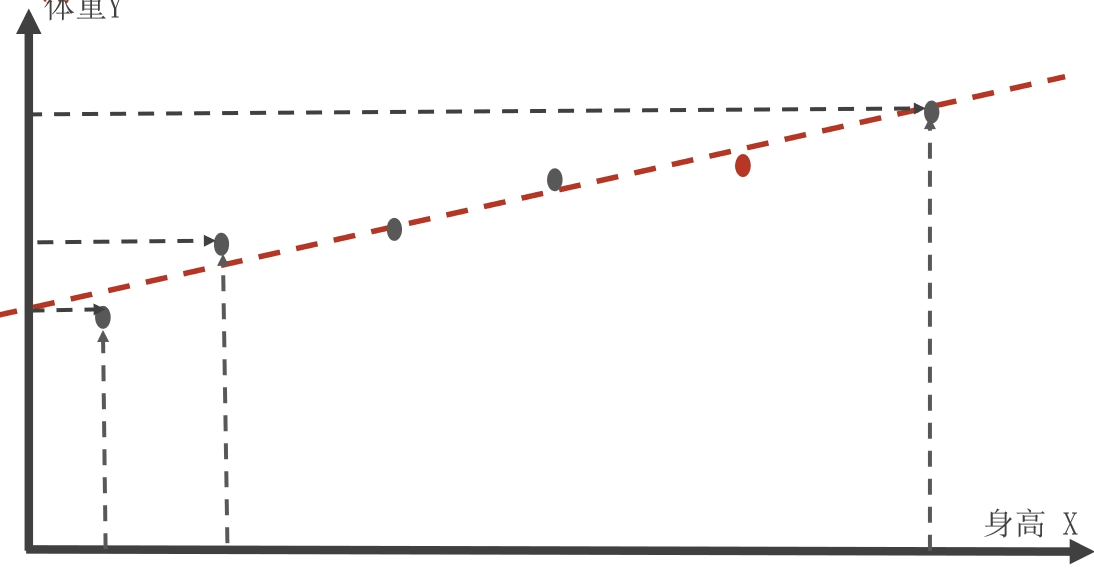
例如,通过最小二乘法最终得到的直线可能是"y= 0.75x-50"。这意味着,有了身高就可以算出体重,当遇到一个身高175厘米的新个体时,模型会预测其体重约为0.75×175−50=81.25公斤。当然,实际体重可能因肌肉量、骨骼密度等因素在81公斤上下波动,但线性回归抓住了身高与体重之间的总体趋势------正相关关系,即身高越高,体重通常越大。这个简单模型可以用于健康评估、服装尺码推荐等场景,不过需要注意,如果数据呈现出非线性特征(如儿童期与成年期生长规律不同),线性回归的效果就会受限,需要考虑更复杂的模型。
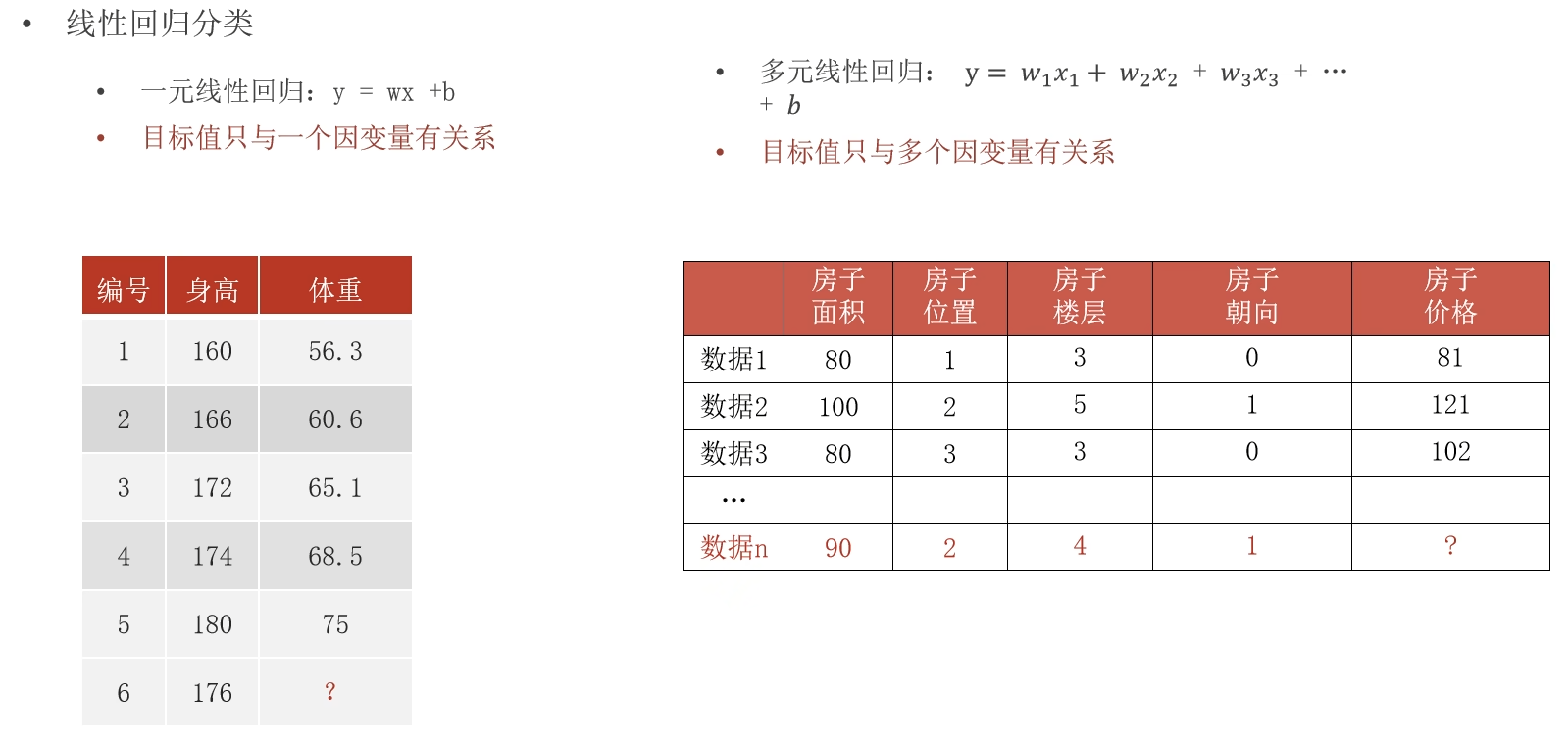
2.多元线性回归
上面说明的是一元线性回归,而多元线性回归与一元线性回归原理差不多,只是多元参考的因素变多了,其线性回归的模型找到的回归线为。对这个数学公式,进行简化,可以将
看成是两个矩阵相乘,其中
可以看作是矩阵
。
可以看作
,从而这个数学公式可以写成
。
所以上面一元与多元线性回归关系对照如下:
二.线性回归API与损失函数
1.线性回归API
通过前面的身高与体重的关系来简单的运用下线性回归的API。
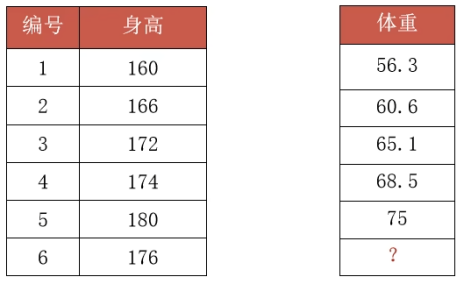
具体代码如下,其中模型参数cofe_与intercept_分别是斜率与截距:
python
# 导包
from sklearn.linear_model import LinearRegression
# 1.准备数据
x_train = [[160], [166], [172], [174], [180]]
y_train = [56.3, 60.6, 65.1, 68.5, 75]
x_test = [[176]]
# 2.数据预处理
# 3.特征工程
# 4.训练模型
# 4.1创建模型对象
estimator = LinearRegression()
# 4.2具体的训练动作
estimator.fit(x_train, y_train)
# 由于是线性回归,我们可以查看下权重w,以及截距b
print(f'权重:{estimator.coef_}') # 0.92942177
print(f'截距:{estimator.intercept_}') # -93.27346938775517
# 5.模型预测
y_pre = estimator.predict(x_test)
print(f'预测值:{y_pre}')最后得到的结果如下:
权重:0.92942177
截距:-93.27346938775517
预测值:70.3047619
2.损失函数
对于API如何得出上面的结果,我们现在来仔细分析一下。将前面已知的五个身高与体重的数据点在坐标图上显示出来,其中黑点表示真实值。如图中有三条预测的线性回归线,如何判断哪条回归线更好呢?
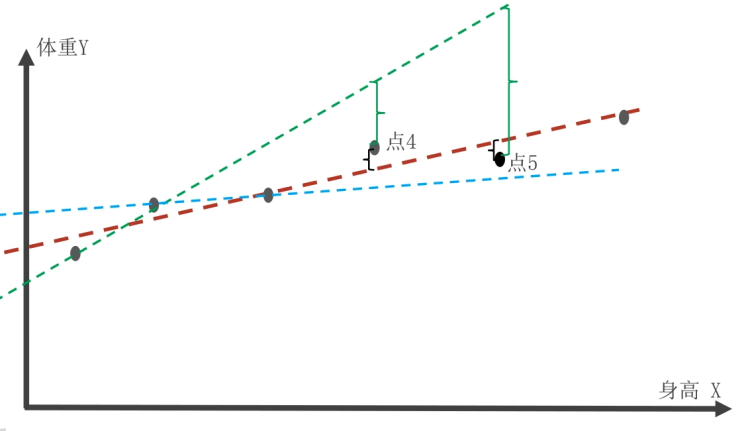
这就需要看每个真实值在这三条回归线上对应的预测值,与原真实值之间的差距(即误差)。误差越小,对应回归线的拟合效果就越好。从图中可以看出,红色的线更好地拟合了所有的点,也就是误差最小,误差之和最小。

因此,衡量每个样本预测值与真实值之间差距的函数,就是之前提到的损失函数。但是,真实值减预测值得到的误差有正有负,为了避免正负抵消,我们可以取该差值的平方。以前面身高与体重的误差和为例,损失函数可表示为:
这个方法就是前面提到的最小二乘法。这时,只要求得一对w与b的值,使得损失函数最小,便可以得到最终的结果,从而根据已知的身高预测其对应的大致体重。
如果将上述求和结果再除以样本总数,则就是均方误差(Mean-Square Error,MSE),具体公式为:
其中表示预测值,
表示真实值。
如果将取差值的平方改为取绝对值,并且求和后再除以样本总数,则就是平均绝对误差(Mean Absolute Error,MAE),具体公式如下:
总结
本文系统讲解了线性回归的核心概念与数学原理。从一元线性回归的直观例子出发,阐述了最小二乘法如何通过最小化误差平方和确定最佳拟合直线,并明确了权重与截距的几何意义。进而推广到多元线性回归,以矩阵形式简化表示。文中还通过代码示例展示了scikit-learn中LinearRegression的使用,并深入分析了损失函数------均方误差与平均绝对误差的公式及其作用。线性回归作为机器学习中最基础的回归算法,理解其原理对后续学习更复杂的回归与分类模型具有重要意义。