文章目录
论文地址: https://arxiv.org/abs/2508.10104
github地址: https://github.com/facebookresearch/dinov3
实践
DINOv3权重申请与下载
在hugging face上申请,申请的时候最好瞎编一个美国人的信息,并使用美国的IP(因为我第一次申请的时候老老实实填写的真实信息,IP地址定位在新加坡,然后一会儿就被reject了)
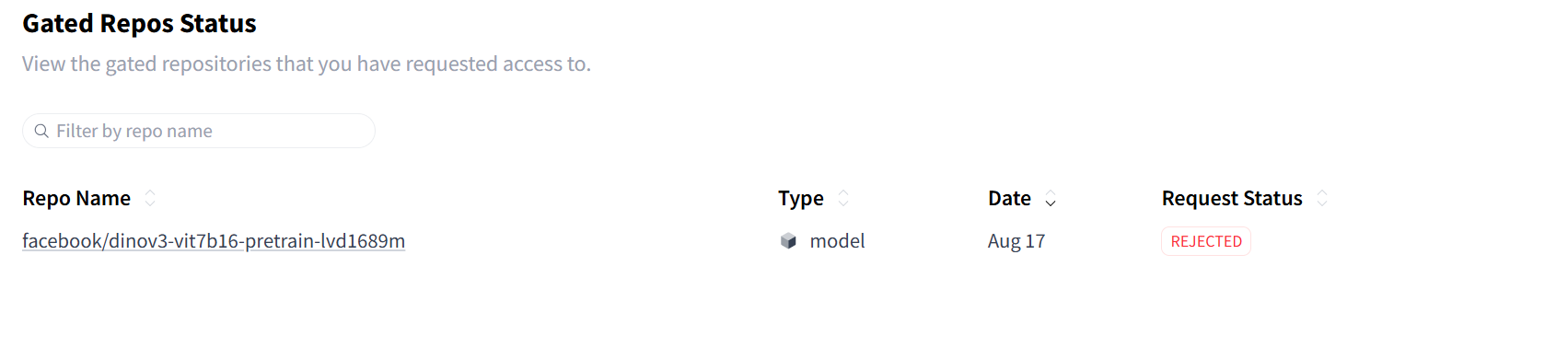
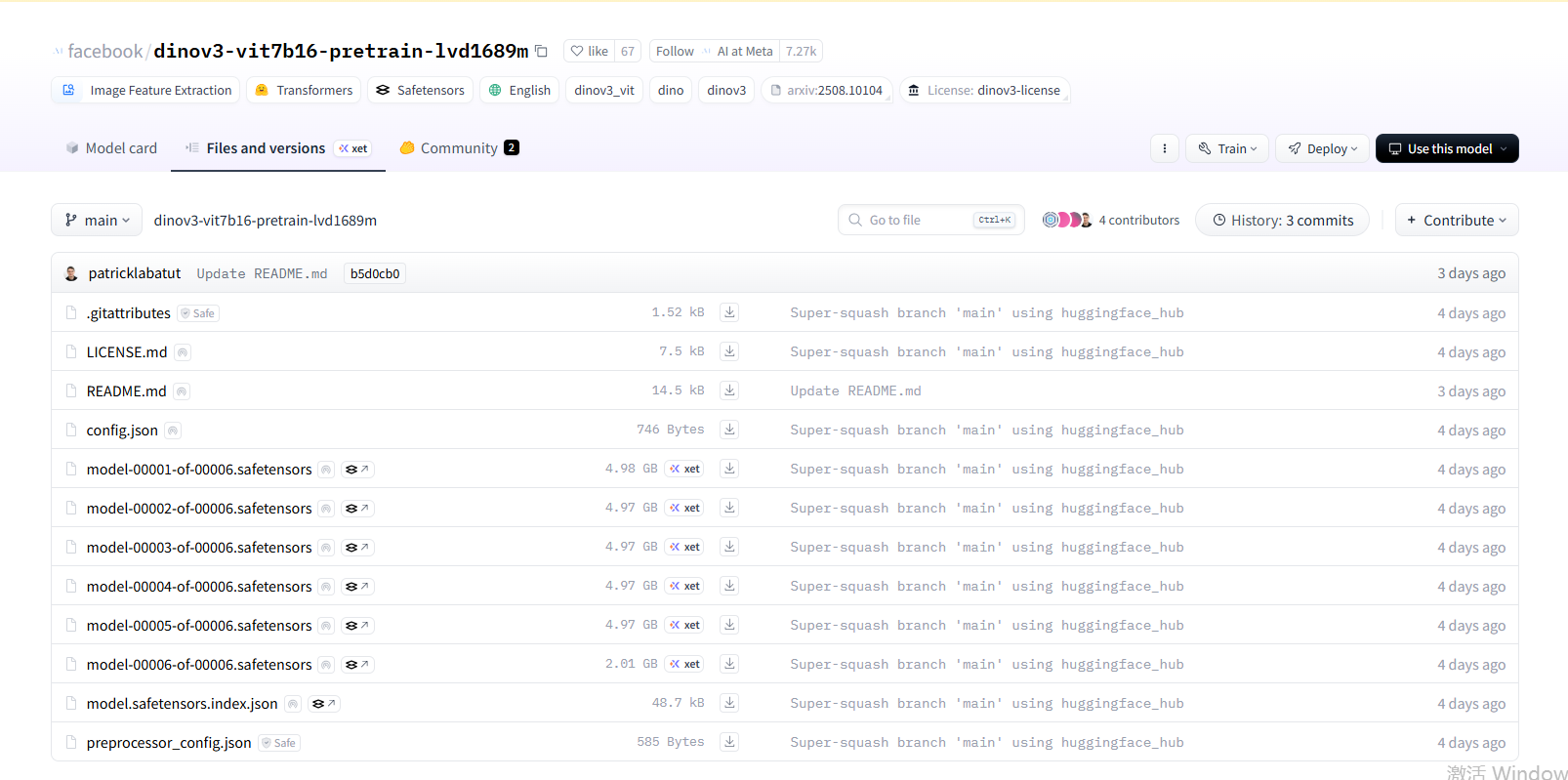
| 文件/目录 | 作用 |
|---|---|
config.json |
模型结构配置 |
model-00001-of-00006.safetensors ... model-00006-of-00006.safetensors |
权重分片(共 6 个) |
model.safetensors.index.json |
分片映射文件 |
preprocessor_config.json |
图像预处理参数 |
README.md / LICENSE.md / .gitattributes |
文档与版权信息 |
将以上文件下载之后存放在目录/data/xujianxia/dinov3-main/dinov3-vit7b16-pretrain-lvd1689m
测试模型加载和推理
官方readme中的一段测试代码(由于网络问题,已提前将测试图片和DINOv3模型权重下载到服务器,离线加载):
python
from transformers import pipeline
from transformers.image_utils import load_image
# url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
# image = load_image(url)
image = load_image("/data/xujianxia/dinov3-main/pipeline-cat-chonk.jpeg")
# feature_extractor = pipeline(
# model="facebook/dinov3-convnext-tiny-pretrain-lvd1689m",
# task="image-feature-extraction",
# )
feature_extractor = pipeline(
model="/data/xujianxia/dinov3-main/dinov3-vit7b16-pretrain-lvd1689m",
task="image-feature-extraction",
)
features = feature_extractor(image)运行以上代码,报错如下:
bash
/home/xujianxia/anaconda3/bin/conda run -n monai --no-capture-output python /home/xujianxia/.pycharm_helpers/pydev/pydevd.py --multiprocess --qt-support=auto --client localhost --port 34499 --file /data/xujianxia/dinov3-main/load_model.py
Connected to pydev debugger (build 251.26927.74)
Traceback (most recent call last):
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 1271, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 966, in __getitem__
raise KeyError(key)
KeyError: 'dinov3_vit'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/xujianxia/.pycharm_helpers/pydev/pydevd.py", line 1570, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File "/home/xujianxia/.pycharm_helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/data/xujianxia/dinov3-main/load_model.py", line 13, in <module>
feature_extractor = pipeline(
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/transformers/pipelines/__init__.py", line 909, in pipeline
config = AutoConfig.from_pretrained(
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 1273, in from_pretrained
python-BaseException
raise ValueError(
ValueError: The checkpoint you are trying to load has model type `dinov3_vit` but Transformers does not recognize this architecture. This could be because of an issue with the checkpoint, or because your version of Transformers is out of date.
You can update Transformers with the command `pip install --upgrade transformers`. If this does not work, and the checkpoint is very new, then there may not be a release version that supports this model yet. In this case, you can get the most up-to-date code by installing Transformers from source with the command `pip install git+https://github.com/huggingface/transformers.git`
^C
CondaError: KeyboardInterrupt
Process finished with exit code 1检查transformers版本是否最新,发现已经是最新版:
(monai) xujianxia@aa-SYS-4029GP-TRT:/data/xujianxia$ pip show transformers
Name: transformers
Version: 4.55.2
Summary: State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow
Home-page: https://github.com/huggingface/transformers
Author: The Hugging Face team (past and future) with the help of all our contributors (https://github.com/huggingface/transformers/graphs/contributors)
Author-email: transformers@huggingface.co
License: Apache 2.0 License
Location: /home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages
Requires: filelock, huggingface-hub, numpy, packaging, pyyaml, regex, requests, safetensors, tokenizers, tqdm
Required-by:
所以采用报错信息提供的第二种方案:pip install git+https://github.com/huggingface/transformers.git
hugging face也有老哥遇到该问题并通过直接从 GitHub 的主分支安装 transformers 库解决:
https://huggingface.co/facebook/dinov3-vitb16-pretrain-lvd1689m/discussions/1
报错原因:模型代码还没有正式发布到 PyPI(Python 的官方包仓库)
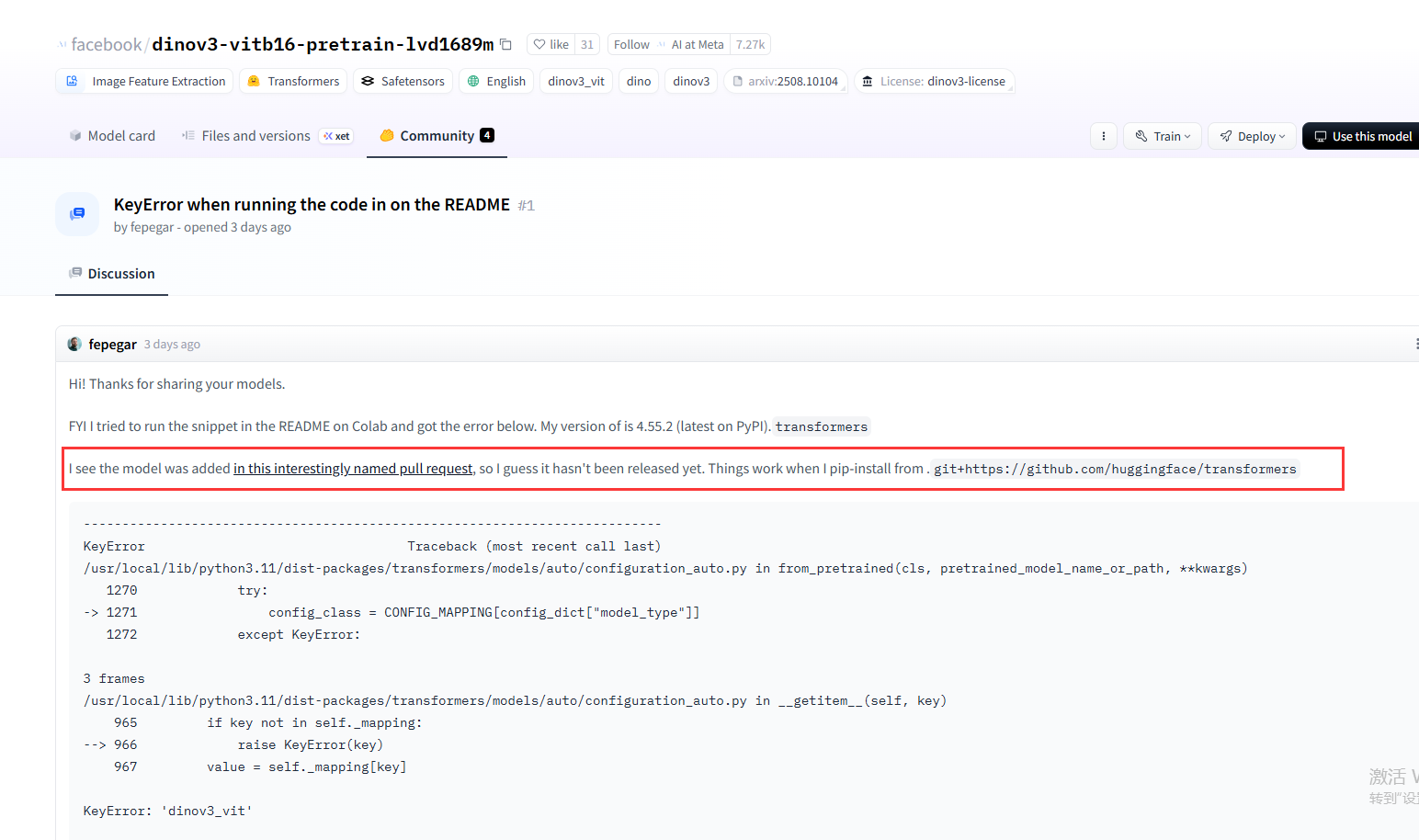
执行pip install git+https://github.com/huggingface/transformers.git后一直卡在这里,应该是网络原因:

所以采用离线安装的方案:
先去github上下载最新的transformers仓库得到transformers-main.zip传到服务器上,并解压。
bash
# 激活 conda 环境
conda activate monai
# 进入你解压后的文件夹(请根据你的实际路径修改)
cd /path/to/your/folder/transformers-main/
# 执行本地安装(推荐同时使用国内 PyPI 镜像加速依赖包的下载)
pip install . -i https://pypi.tuna.tsinghua.edu.cn/simple本地安装成功:
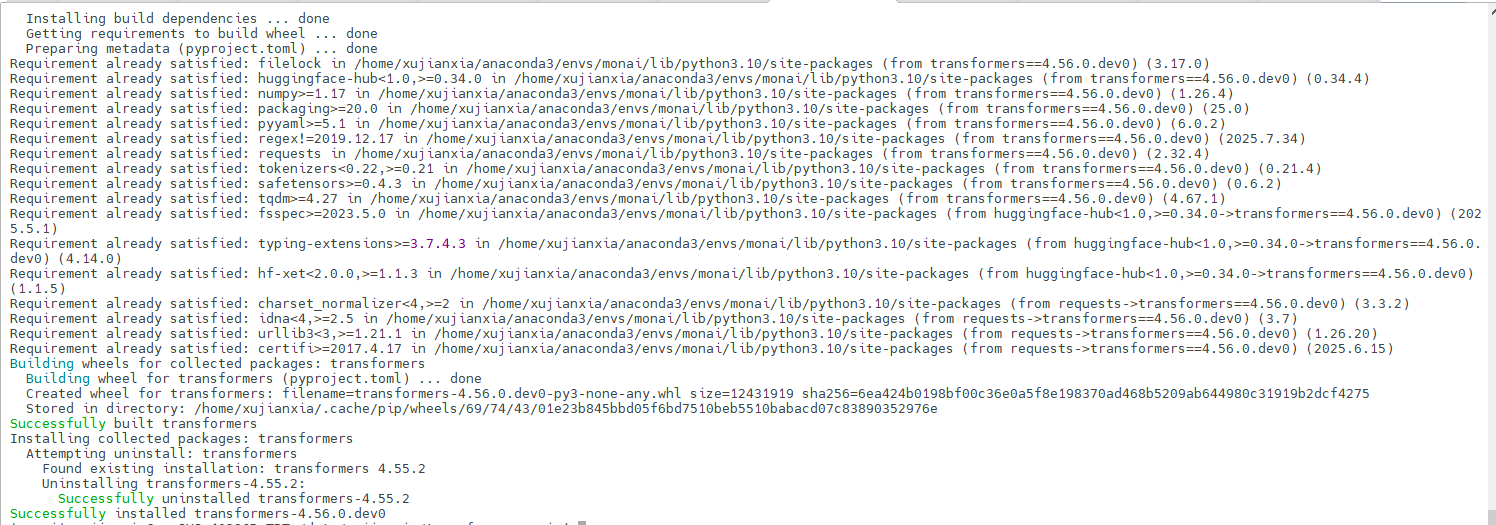
再次运行,又报错:
bash
/home/xujianxia/anaconda3/bin/conda run -n monai --no-capture-output python /data/xujianxia/dinov3-main/load_model.py
Loading checkpoint shards: 100%|██████████████████| 6/6 [00:00<00:00, 61.22it/s]
Device set to use cuda:0
Traceback (most recent call last):
File "/data/xujianxia/dinov3-main/load_model.py", line 13, in <module>
feature_extractor = pipeline(
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/transformers/pipelines/__init__.py", line 1210, in pipeline
return pipeline_class(model=model, framework=framework, task=task, **kwargs)
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1043, in __init__
self.model.to(self.device)
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/transformers/modeling_utils.py", line 4374, in to
return super().to(*args, **kwargs)
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1173, in to
return self._apply(convert)
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/torch/nn/modules/module.py", line 779, in _apply
module._apply(fn)
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/torch/nn/modules/module.py", line 779, in _apply
module._apply(fn)
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/torch/nn/modules/module.py", line 779, in _apply
module._apply(fn)
[Previous line repeated 1 more time]
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/torch/nn/modules/module.py", line 804, in _apply
param_applied = fn(param)
File "/home/xujianxia/anaconda3/envs/monai/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1159, in convert
return t.to(
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 128.00 MiB. GPU
ERROR conda.cli.main_run:execute(127): `conda run python /data/xujianxia/dinov3-main/load_model.py` failed. (See above for error)
Process finished with exit code 1因为我这里用的是dinov3-vit7b16-pretrain-lvd1689m(6,716M),源码中用的是dinov3-convnext-tiny-pretrain-lvd1689m(29M )。以下是作者提供的所有预训练模型list:
ViT models pretrained on web dataset (LVD-1689M):
| Model | Parameters | Pretraining Dataset | Download |
|---|---|---|---|
| ViT-S/16 distilled | 21M | LVD-1689M | link |
| ViT-S+/16 distilled | 29M | LVD-1689M | link |
| ViT-B/16 distilled | 86M | LVD-1689M | link |
| ViT-L/16 distilled | 300M | LVD-1689M | link |
| ViT-H+/16 distilled | 840M | LVD-1689M | link |
| ViT-7B/16 | 6,716M | LVD-1689M | link |
ConvNeXt models pretrained on web dataset (LVD-1689M):
| Model | Parameters | Pretraining Dataset | Download |
|---|---|---|---|
| ConvNeXt Tiny | 29M | LVD-1689M | link |
| ConvNeXt Small | 50M | LVD-1689M | link |
| ConvNeXt Base | 89M | LVD-1689M | link |
| ConvNeXt Large | 198M | LVD-1689M | link |
ViT models pretrained on satellite dataset (SAT-493M):
| Model | Parameters | Pretraining Dataset | Download |
|---|---|---|---|
| ViT-L/16 distilled | 300M | SAT-493M | link |
| ViT-7B/16 | 6,716M | SAT-493M | link |
为了快速验证,我选择降低模型精度:
python
feature_extractor = pipeline(
torch_dtype=torch.float16, # 添加这一行
model="/data/xujianxia/dinov3-main/dinov3-vit7b16-pretrain-lvd1689m",
task="image-feature-extraction",
)
成功将图片编码成features。