一句话总结
每产出一个推理步骤就立刻转发下游,形成流水线并行,结果不仅更快,推理质量还更高
- 论文标题:Streaming Communication in Multi-Agent Reasoning
- 论文地址 :https://arxiv.org/abs/2606.05158
- 作者背景:香港科技大学广州、阿里巴巴、浙江大学、HKUST
- 项目主页 :https://zhenyangcs.github.io/StreamMA-website/
- 开源代码 :https://github.com/EnVision-Research/StreamMA
一、动机
多智能体推理是解决复杂任务的主流范式:把多个 Agent 组织成一张有向无环图(DAG),让它们分工、互相校验,效果往往比单个模型更好,Agent 越多收益越大。但几乎所有现有框架共享同一个通信假设:上游 Agent 必须把整段回复全部生成完,才交给下游。这种 "先生成、再传输" 的串行方式,带来两个代价:
- 慢: 下游只能干等着上游说完,端到端延迟随流水线深度线性增长
- 错误继承: 下游被迫读完上游的整段回复,包括那些靠后、质量不高的推理步骤,把错误原样继承了下来
前者大家都知道,但第二个代价少有人关注。这并不是危言耸听,已有研究反复验证确认过:长推理任务是真的存在误差累积的风险,早期步骤通常可靠,越往后越容易跑偏,CoT 准确率会在一个最优长度之后会持续退化。只要任务需要多步推理 ------ 如数学解题、代码推导、科学分析等 ------ 误差就会随着步骤增加不断累积。推理链越长,后期跑偏的概率越高。这是长链推理的结构性弱点
二、核心思路
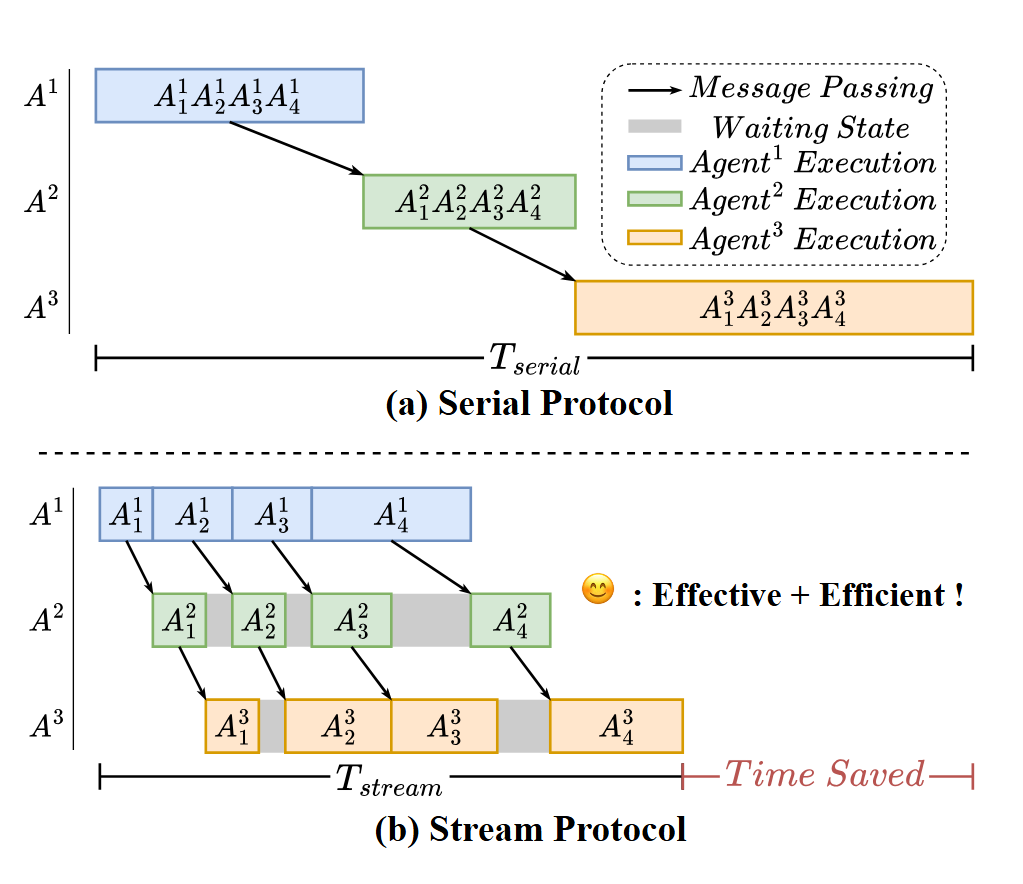
作者想法是,既然模型本身就支持流式输出,能不能在 Agent 协作时也做同样的事 ------ 上游每产出一个推理步骤,就立刻转发给下游,不等后面?这样一来多个 Agent 可以像流水线一样并发工作
但这显然会带来一个问题:下游看到的信息更少,信息缺失带来的损害可能更大
作者的解法是,不改变向下游传输的信息量,只调整到达的时序 ------ 串行模式是攒好答案后一次性全给,而流式则是一步一步逐渐到位
如此一来就能既解决串行模式太慢的问题,又让可靠的早期步骤优先到达,还避免了信息缺失。下游拿到可靠的开头后,会立刻基于它建立自己的独立推理轨迹。等后面那些质量较差的步骤陆续传来时,下游已经形成了自己的思路,此时晚到的错误步骤就像在一条已经定型的河流里丢了几块小石子,激不起多大水花,影响被大幅稀释
作者用一个干净的对照实验对 "推理链头部质量优于尾部" 这一观点做了验证。在一个简单的多 Agent 工作流中,分别在上游和下游推理轨迹中引入扰动,然后看最终任务准确率:
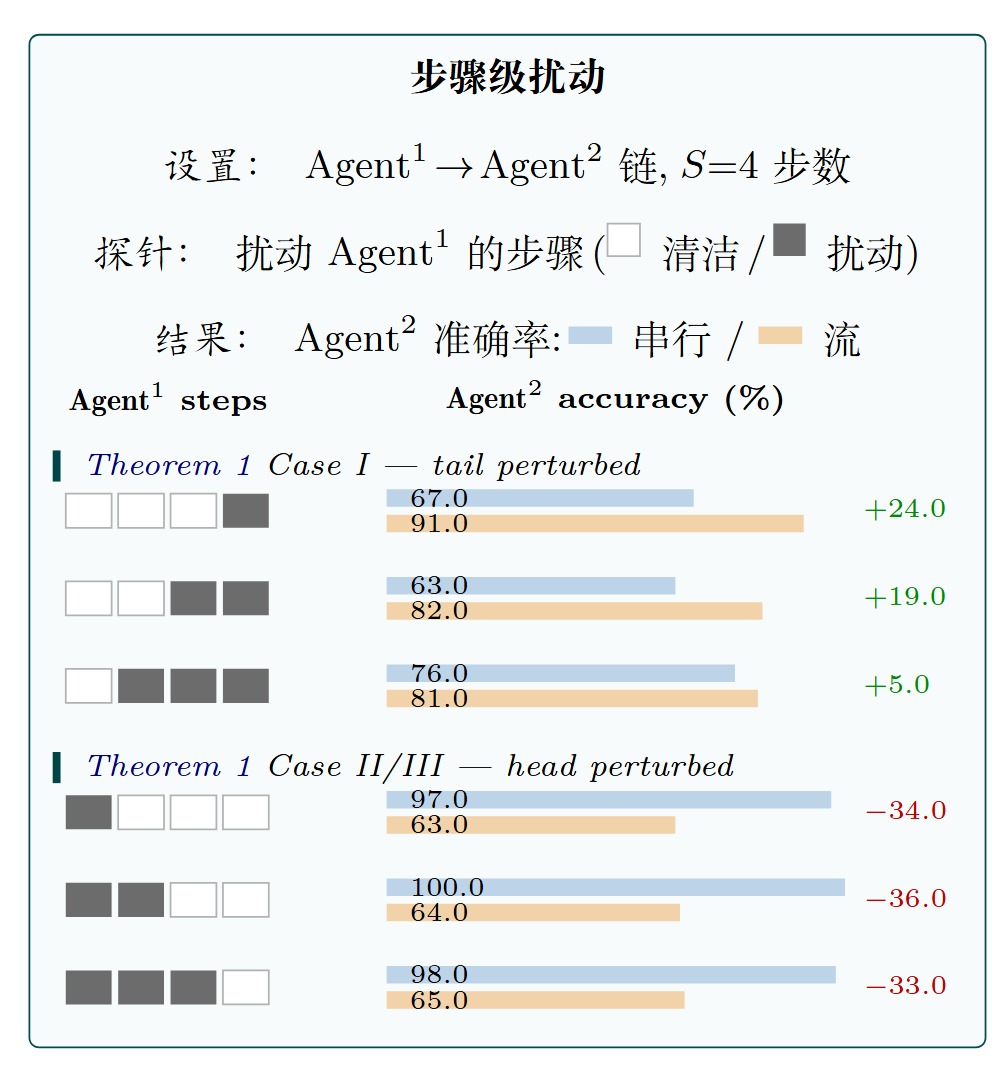
可见当只弄坏尾部时,产出结果几乎不受影响,但一旦破坏了开头部分,效果立马下降 30+
三、实现方案
StreamMA(流式多智能体)的工程改动非常小,工作流程为:
- 所有 Agent 并发启动,各自维护一个输入队列
- 每个 Agent 发起流式调用,逐步产出推理步骤;每产出一个完整步骤,立刻推给下游队列
- 下游处理第 s 步时,上游还在生成第 s+1 步
- 每个下游 Agent 被调用 S 次,先前的步骤自然形成共享前缀,通过缓存命中降低成本
整套协议完全沿用了串行的提示词和解码设置,只给下游系统提示加了一行 END_STEP 步骤分隔标记。唯一变化的是传输粒度,因此可以排除提示工程带来的干扰
更近一步地,这套方案还可以推广到任意 DAG 架构:把 query 广播给所有节点,但每个结点做完一步后按 DAG 关系把增量信息传达给下游即可
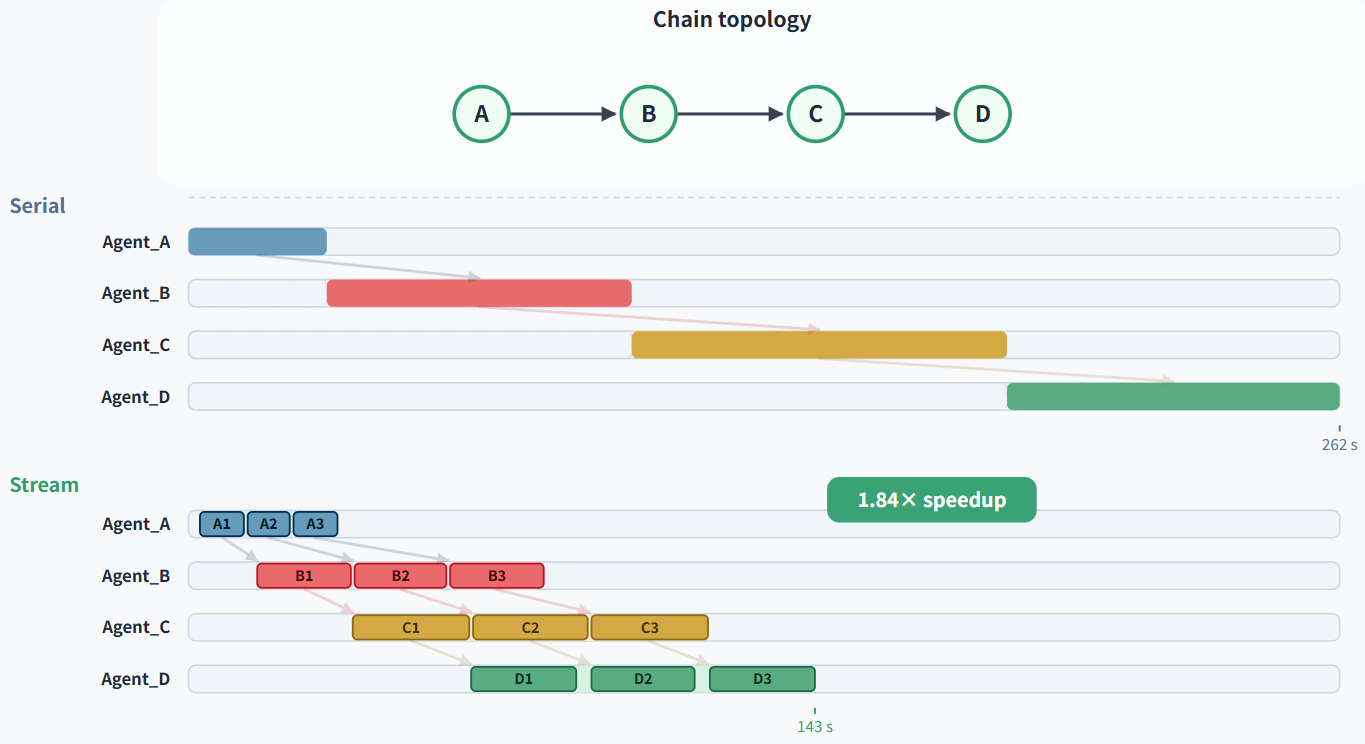
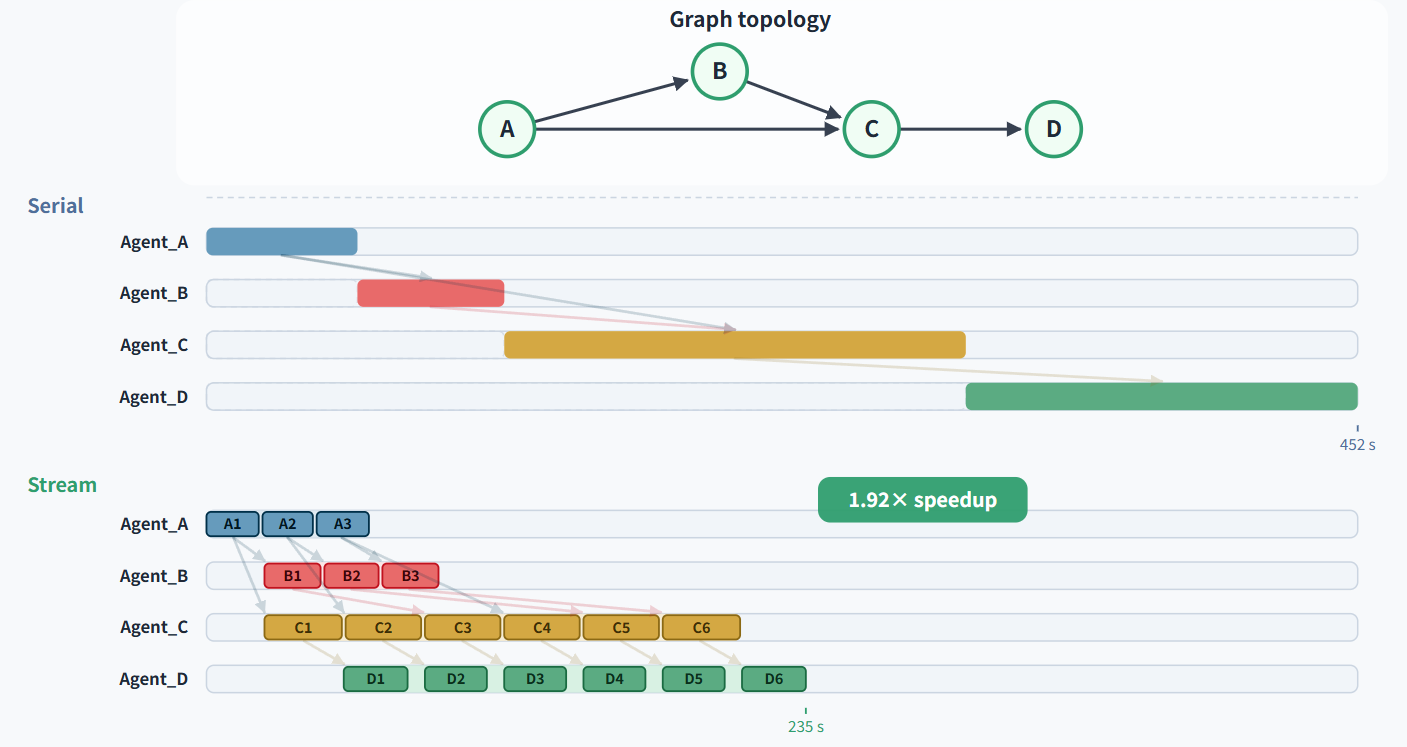
链式拓扑:
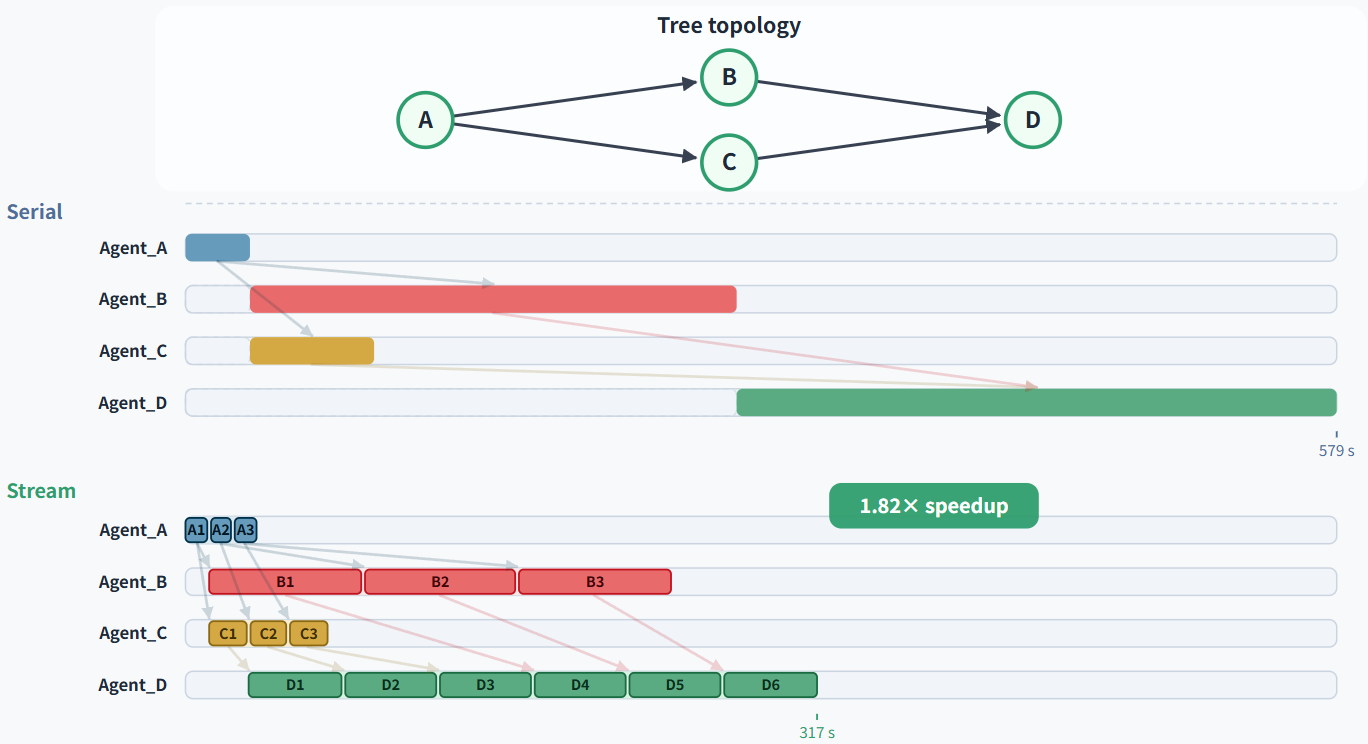
树形拓扑:
图结构:
作者还对流式多智能体方案的有效性与成本做了细致的理论分析,主要结论包括:
- 需要做长链推理的复杂任务,很容易出现 "开头可靠、结尾退化",此时流式方案能带来更高的准确性期望
- 如果耗时关系满足:缓存读取 ≫ 预填充 ≫ 解码,则流式方案的加速上界为 AS / (S+A-1),其中 A 为 Agent 数,S 为步骤数
- 只要解码价格远高于预填充价格(主流 API 现状),在使用了缓存复用的前提下,流式的总成本甚至低于串行
四、实验结果
4.1 准确性
实验覆盖 8 个基准(数学竞赛 AIME 2025/2026、HMMT 2026,研究生科学 GPQA-Diamond、HLE,代码推理 LiveCodeBench 三子任务),2 个前沿模型(Claude Opus 4.6-high、GPT-5.4-medium),3 种 DAG 拓扑(Chain、Tree、Graph)
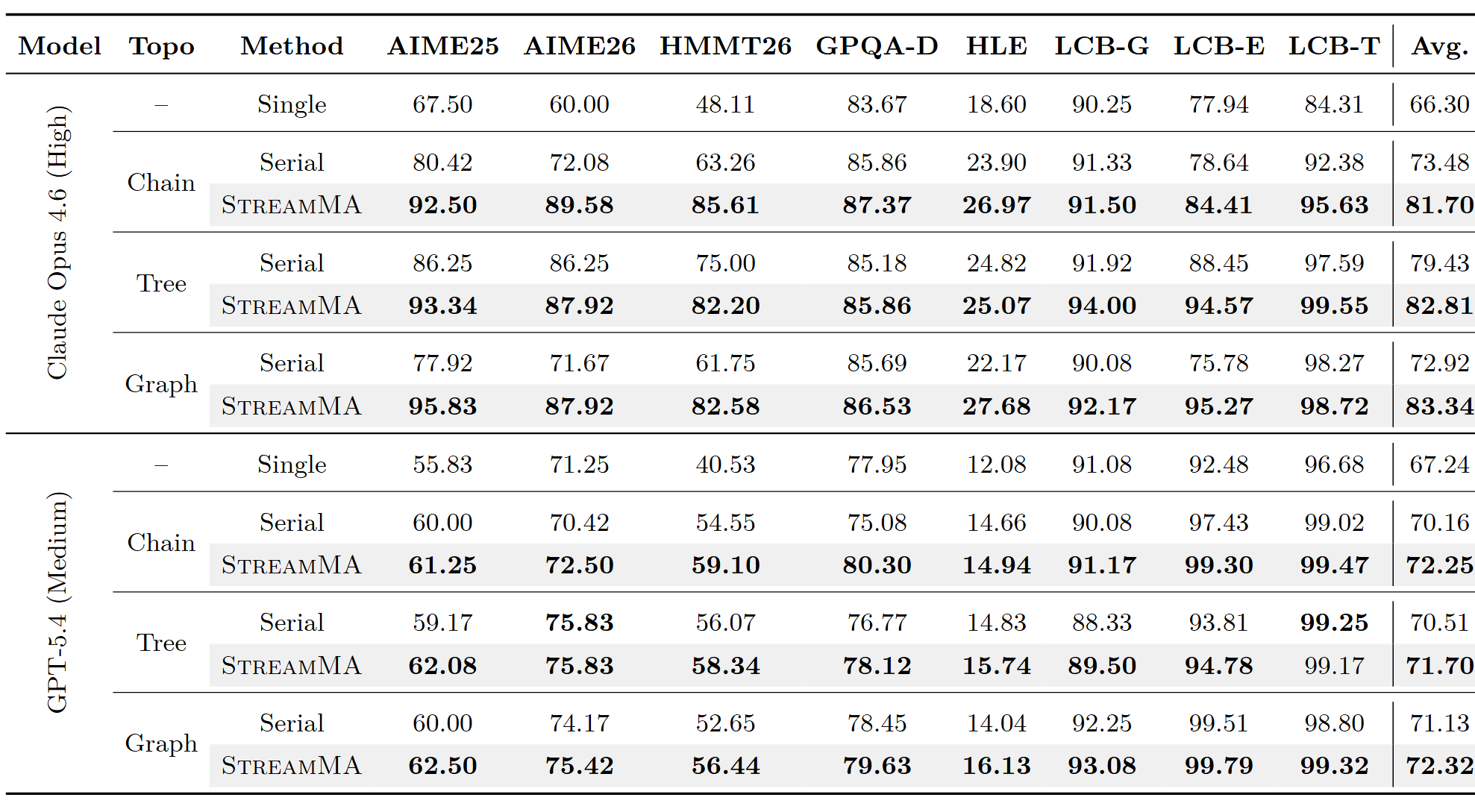
在所有拓扑的平均列上,StreamMA 全面超过 Serial 和 Single。Claude Opus 4.6 上平均 +7.3pp;GPT-5.4 上平均 +1.5pp
4.2 成本分析
以链式拓扑为例,使用 3 个 agent,每个 agent 生成 3 个推理步骤,同时跑 N 条链路然后投票得到最终结果,对比 N 条流式链路与 N 条 串行链路最终的成本-精度曲线:
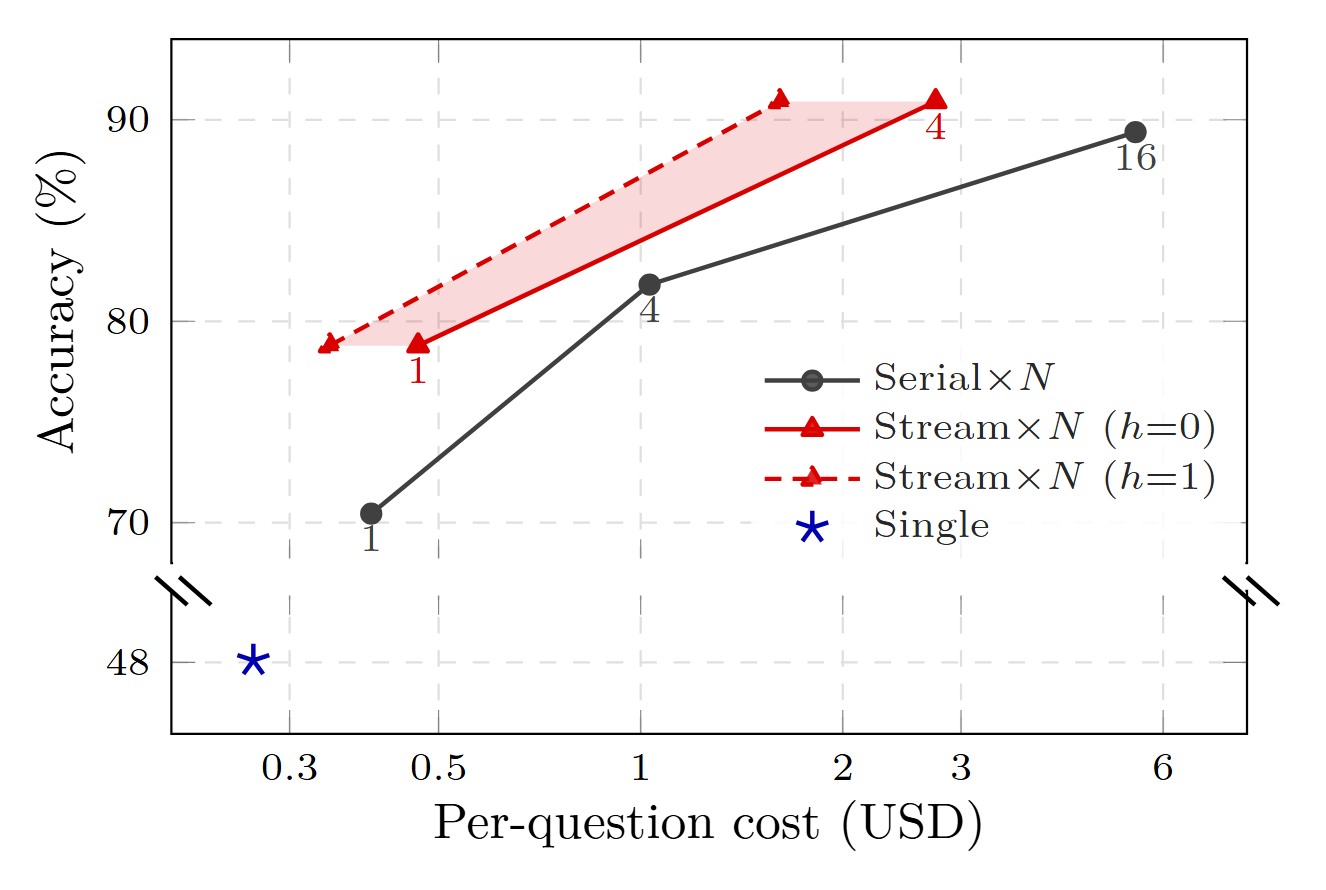
可见流式方案不仅实现了更高的准确率,成本显著降低,与之前的理论分析结论一致,达到了新的帕累托前沿
4.3 步骤级缩放定律
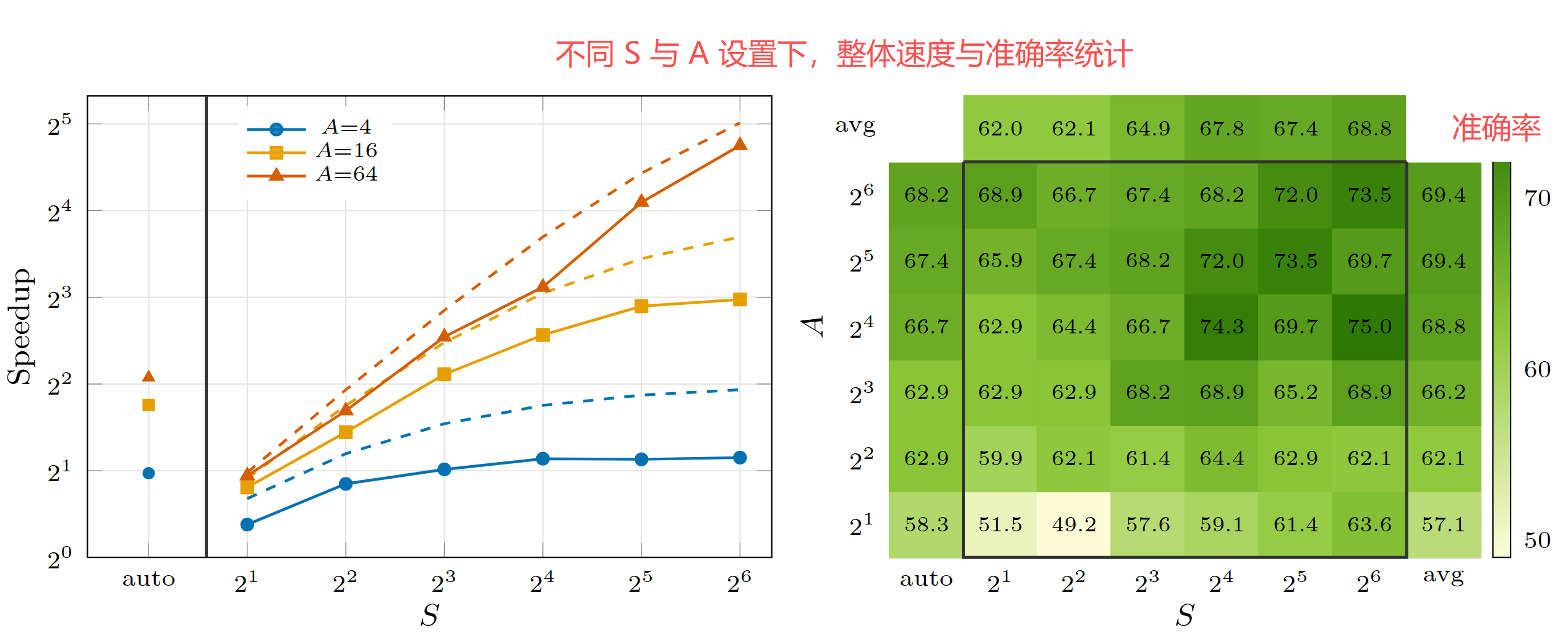
在 Agent 数固定为 A 的前提下,增加每个 Agent 的步骤数 S,效果和速度同时持续上升。这是一条与 "堆 Agent 数量" 正交的全新缩放定律(Scaling Law)
五、局限性
StreamMA 在步骤粒度上做流水线,适用于解可被步骤分解的任务,如数学、代码、科学场景,但无法分步的任务(开放式创意写作、单 token 分类)不在其列