《扩散模型原理:从起源到发展》:第三章 基于分数的视角:从 EBMs 到 NCSN
专著:The Principles of Diffusion Models
上一章:【扩散模型原理】(二)Variational Perspective: From VAEs to DDPMs
Score-Based Perspective: From EBMs to NCSN
在前面的章节中,我们追溯了扩散模型的变分起源,并展示了它们如何在变分自编码器(VAE)框架中自然产生。现在,我们转向第二种同样基础的视角:基于能量的模型(Energy Based Models, EBMs)。EBM 通过能量地形(energy landscape)来表示分布 ------ 在数据分布处能量较低,而在其他区域能量较高。采样过程通常依赖于朗之万动力学(Langevin dynamics),该方法通过遵循该景观的梯度将样本移向高密度区域。这个梯度场被称为分数函数(score function),它指向概率更高的方向。
核心观察结果是:仅需知道分数函数就足以完成生成任务:它可以将样本移向高概率区域,而无需计算难以处理的归一化常数。基于分数的扩散模型正是直接建立在这一思想之上。它们不再仅关注干净数据分布,而是考虑一系列高斯噪声扰动的分布 ------ 这些分布的分数函数更容易被近似。学习这些分数函数会得到一族向量场,它们逐步引导带噪样本回归到真实数据分布,从而将生成任务转化为渐进式的去噪过程。
3.1 基于能量的模型(Energy-Based Models)
对于已经熟悉基于能量模型(EBMs)的读者,本节旨在作为简洁的回顾,并为衔接至扩散模型的基于分数视角搭建桥梁。
3.1.1 用能量函数建模概率分布(Modeling Probability Distributions Using Energy Functions)
设 x ∈ R D \mathbf{x} \in \mathbb{R}^D x∈RD 表示一个数据点。EBMs 通过一个由参数 ϕ ϕ ϕ 定义的能量函数 E ϕ ( x ) E_{\phi}(\mathbf{x}) Eϕ(x) 来确定概率密度 ------ 该函数为更高概率的配置分配更低的能量。由此得到的分布定义如下:
p ϕ ( x ) : = exp ( − E ϕ ( x ) ) Z ϕ , Z ϕ : = ∫ R D exp ( − E ϕ ( x ) ) d x , p_{\phi}(\mathbf{x}) := \frac{\exp(-E_{\phi}(\mathbf{x}))}{Z_{\phi}}, \quad Z_{\phi} := \int_{\mathbb{R}^D} \exp(-E_{\phi}(\mathbf{x})) d\mathbf{x}, pϕ(x):=Zϕexp(−Eϕ(x)),Zϕ:=∫RDexp(−Eϕ(x))dx, 其中 Z ϕ Z_{\phi} Zϕ 被称为配分函数 (partition function),用于确保分布的归一化:
∫ R D p ϕ ( x ) d x = 1. \int_{\mathbb{R}^D} p_{\phi}(\mathbf{x}) d\mathbf{x} = 1. ∫RDpϕ(x)dx=1.
能量函数 是一个"可能性打分器",对于好的数据,能量低,对于差的数据,能量高,定义:能量越低,对应的概率就越高;
配分函数是一个"归一化计算器",把所有的分子值加起来(积分),作为分母除一下;
在该视角下,能量越低的点对应概率越高,这很像一个球滚入山谷的过程。配分函数 Z ϕ Z_{\phi} Zϕ 确保了所有概率之和为 1,因此只有能量的相对值具有实际意义。例如,对所有能量加上一个常数,会使分子和分母同时乘以同一个系数,从而保持分布不变。
此外,由于配分函数 Z ϕ Z_{\phi} Zϕ 强制要求概率总和为 1,因此从数学上可以推导出:**区域内能量的降低会增加该区域的概率,而其互补区域的概率会相应降低。**因此,EBMs 遵循严格的全局权衡机制:将一个山谷挖得更深,必然会导致其他山谷变浅,且概率质量会重新分布在整个空间中,而非独立地分配给每个区域。
**Figure 3.1 | EBM 训练示意图:**该模型在"不良"数据点(红色箭头)处降低密度(提升能量),在"良好"数据点(绿色箭头)处提升密度(降低能量);
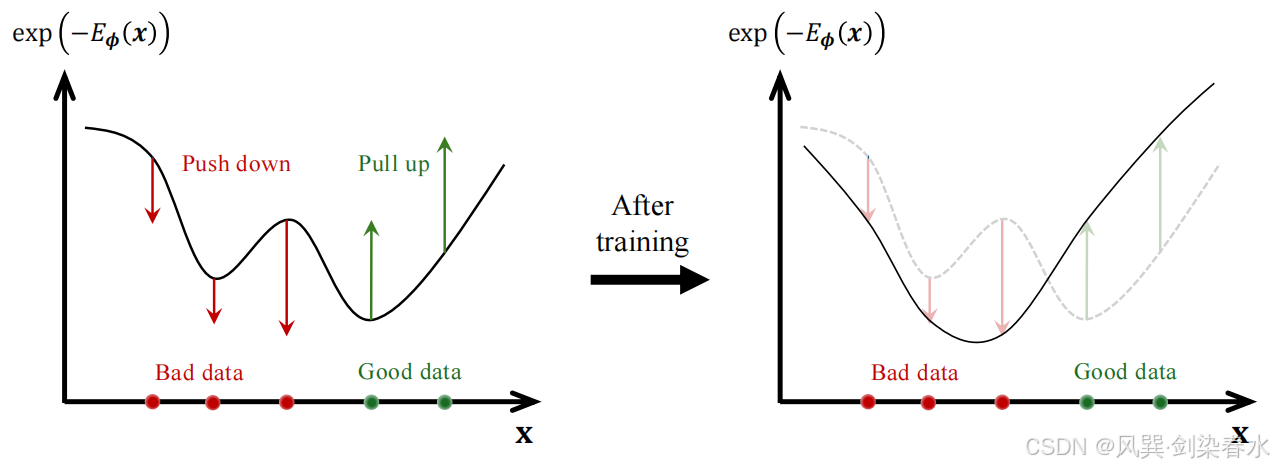
EBM 最大似然训练的挑战。 原则上,基于 EBMs 可通过最大似然法进行训练,这种方法自然地平衡了对数据的拟合与全局正则化(参考公式 (1.1.2)):
L M L E ( ϕ ) = E p d a t a ( x ) log exp ( − E ϕ ( x ) ) Z ϕ = − E p d a t a E ϕ ( x ) ⏟ loweres energy of data − log ∫ exp ( − E ϕ ( x ) ) d x ⏟ global regularization , (3.1.1) \begin{aligned} \mathcal{L}{MLE}(\phi) &= \mathbb{E}{p_{data}(\mathbf{x})}\left\\log \\frac{\\exp(-E_{\\phi}(\\mathbf{x}))}{Z_{\\phi}}\\right \tag{3.1.1} \\ &= -\underbrace{\mathbb{E}{p{data}}E_{\\phi}(\\mathbf{x})}{\text{loweres energy of data}} - \underbrace{\log \int \exp(-E{\phi}(\mathbf{x})) d\mathbf{x}}{\text{global regularization}}, \end{aligned} LMLE(ϕ)=Epdata(x)logZϕexp(−Eϕ(x))=−loweres energy of data EpdataEϕ(x)−global regularization log∫exp(−Eϕ(x))dx,(3.1.1) 其中 Z ϕ = ∫ exp ( − E ϕ ( x ) ) d x Z{\phi} = \int \exp(-E_{\phi}(\mathbf{x})) d\mathbf{x} Zϕ=∫exp(−Eϕ(x))dx。第一项降低了真实数据的能量,而第二项通过配分函数强制实现了分布的归一化。
想象你在修一个游泳池(这代表概率分布 p ϕ ( x ) p_{\phi}(\mathbf{x}) pϕ(x) ):
第一项(降低数据能量):你拿着铲子,在真数据点所在的位置挖坑(降低能量)。这样水(概率)就会流到这里。
第二项(归一化约束):你不能只挖坑不管挖出来的土扔哪了。你要确保整个游泳池的边界是合理的,水不会溢出来。这要求你放眼整个院子(整个数据空间),计算一下把土堆在哪,才能保证坑里刚好能存住水,院子里其他地方又不会堆成山。
挑战在于: 这个院子太大了(高维空间),你根本没法一眼看到整个院子的地形。你挖了一个坑,但不知道院墙在哪,也不知道土扔得够不够远。
然而,在高维空间中,计算 log Z ϕ \text{log}Z_{\phi} logZϕ 及其梯度是难处理的,因为这需要计算模型分布下的期望。这促使人们研究替代目标函数:要么近似该项(例如对比散度,contrastive divergence,Hinton, 2002),要么通过 分数匹配(score matching) 完全规避该项。
对比散度:既然我没法看遍全世界,那我就在附近看看;
从真实数据出发,稍微做一点扰动,生成一些"比较像但又不完全真"的样本。然后要求模型不仅要降低真实数据的能量,还要提高这些附近样本的能量。
分数匹配:既然算 Z ϕ Z_{\phi} Zϕ 太麻烦,那我干脆绕过它;我不直接学能量了,而是学能量 E ϕ ( x ) E_{\phi}(\mathbf{x}) Eϕ(x) 的梯度(也就是指向低能量方向的箭头)。
在下文中,我们将首先在 3.1.2 节引入分数函数(score function)的概念,在 3.1.3 节介绍分数匹配作为一种可规避配分函数的易处理训练目标,随后在 3.1.4 节讨论朗之万动力学(Langevin dynamics)作为结合分数函数的实用采样方法。
3.1.2 动机:分数是什么?(Motivation: What Is the Score?)
对于定义在 R D \mathbb{R}^D RD 上的密度 p ( x ) p(x) p(x),分数函数(score function)是对数密度的梯度:
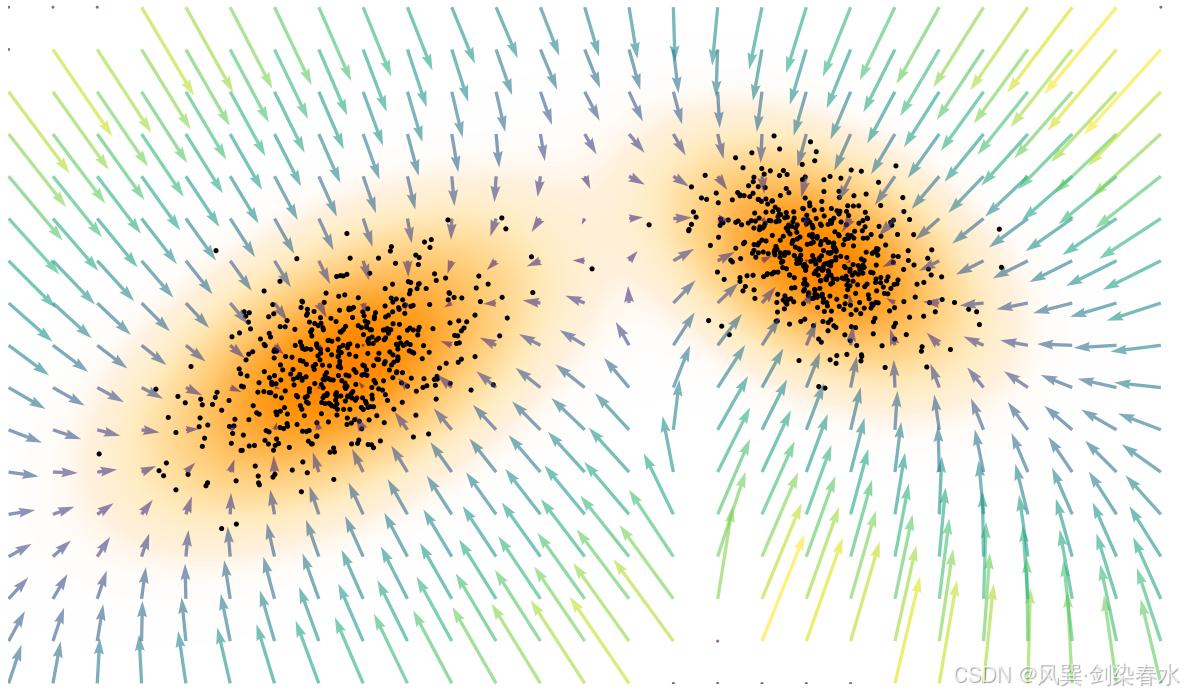
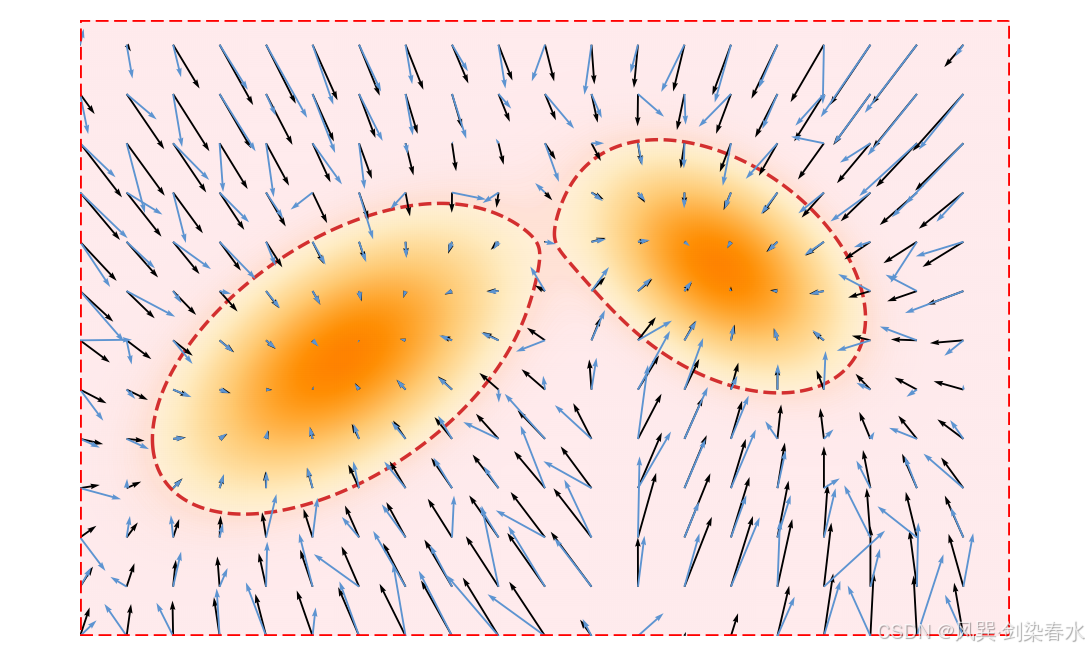
s ( x ) : = ∇ x log p ( x ) , s : R D → R D . \mathbf{s}(\mathbf{x}) := \nabla_{\mathbf{x}} \log p(\mathbf{x}), \quad \mathbf{s}: \mathbb{R}^D \to \mathbb{R}^D. s(x):=∇xlogp(x),s:RD→RD. 直观上,分数函数构成了一个向量场,指向概率更高的区域,为数据最可能出现的位置提供了局部引导(参考图 3.2)。
**Figure 3.2 | 分数向量场示意图:**分数向量场 ∇ x log p ( x ) \nabla_{\mathbf{x}} \log p(\mathbf{x}) ∇xlogp(x) 表示密度递增的方向;
为什么要对分数(Scores)进行建模而非密度(Densities)?
1. 摆脱归一化常数的束缚
许多分布仅通过未归一化密度 p ~ ( x ) \tilde{p}(\mathbf{x}) p~(x) 定义(例如 EBMs 中的 exp ( − E ϕ ( x ) ) \exp(-E_{\phi}(\mathbf{x})) exp(−Eϕ(x))),即:
p ( x ) = p ~ ( x ) Z , Z = ∫ p ~ ( x ) d x . p(\mathbf{x}) = \frac{\tilde{p}(\mathbf{x})}{Z}, \quad Z = \int \tilde{p}(\mathbf{x}) d\mathbf{x}. p(x)=Zp~(x),Z=∫p~(x)dx. 虽然计算归一化常数 Z Z Z 通常是难处理的,但分数仅取决于未归一化密度 p ~ \tilde{p} p~:
∇ x log p ( x ) = ∇ x log p ~ ( x ) − ∇ x log Z ⏟ = 0 = ∇ x log p ~ ( x ) , (3.1.2) \nabla_{\mathbf{x}} \log p(\mathbf{x}) = \nabla_{\mathbf{x}} \log \tilde{p}(\mathbf{x}) - \underbrace{\nabla_{\mathbf{x}} \log Z}{=0} = \nabla{\mathbf{x}} \log \tilde{p}(\mathbf{x}), \tag{3.1.2} ∇xlogp(x)=∇xlogp~(x)−=0 ∇xlogZ=∇xlogp~(x),(3.1.2) 由于 Z Z Z 是关于 x \mathbf{x} x 的常数,上式中 log Z \text{log}Z logZ 的梯度为 0 0 0。因此,这种方式完全规避了配分函数的计算。
2. 完整的表征能力
分数函数能够完整地表征底层分布。由于它是对数密度的梯度,因此密度可以通过以下方式恢复(至多差一个常数):
log p ( x ) = log p ( x 0 ) + ∫ 0 1 s ( x 0 + t ( x − x 0 ) ) ⊤ ( x − x 0 ) d t , \log p(\mathbf{x}) = \log p(\mathbf{x}_0) + \int_0^1 \mathbf{s}(\mathbf{x}_0 + t(\mathbf{x} - \mathbf{x}_0))^{\top} (\mathbf{x} - \mathbf{x}_0) dt, logp(x)=logp(x0)+∫01s(x0+t(x−x0))⊤(x−x0)dt, 其中 x 0 \mathbf{x}_0 x0 是参考点,且 log p ( x 0 ) \text{log} p(\mathbf{x}_0) logp(x0) 通过归一化确定。因此,对分数进行建模与直接建模 p ( x ) p(\mathbf{x}) p(x) 具有同等的表达能力,且在生成式建模中通常更易于处理。(已知 A 点,通过梯度不断积分去感知 B 点)
3.1.3 通过分数匹配训练 EBMs(Training EBMs via Score Matching)
在 EBMs 中,密度定义为 p ϕ ( x ) = exp ( − E ϕ ( x ) ) Z ϕ p_{\phi}(\mathbf{x}) = \frac{\exp(-E_{\phi}(\mathbf{x}))}{Z_{\phi}} pϕ(x)=Zϕexp(−Eϕ(x))。最大似然训练需要计算配分函数 Z ϕ Z_{\phi} Zϕ,但这通常是难处理的。一个关键观察是:模型分数 p ϕ p_{\phi} pϕ 可简化为 − ∇ x E ϕ ( x ) −∇\mathbf{x}E_ϕ(\mathbf{x}) −∇xEϕ(x)------ 此形式与 Z ϕ Z{\phi} Zϕ 无关(参考公式 (3.1.2))。
分数匹配利用了 "分数仅依赖于能量函数" 这一特性。它不再拟合归一化后的概率,而是通过对齐模型分数与(未知的)数据分数来训练 EBMs:
L S M ( ϕ ) = 1 2 E p d a t a ( x ) ∥ ∇ x log p ϕ ( x ) − ∇ x log p d a t a ( x ) ∥ 2 2 . (3.1.3) \mathcal{L}{SM}(\phi) = \frac{1}{2} \mathbb{E}{p_{data}(\mathbf{x})} \left \\left\\\| \\nabla_{\\mathbf{x}} \\log p_{\\phi}(\\mathbf{x}) - \\nabla_{\\mathbf{x}} \\log p_{data}(\\mathbf{x}) \\right\\\|_2\^2 \\right. \tag{3.1.3} LSM(ϕ)=21Epdata(x)∥∇xlogpϕ(x)−∇xlogpdata(x)∥22.(3.1.3) 尽管数据分数无法直接获取,但通过分部积分 可得到一个等价表达式(改写目标函数) ------ 该表达式仅涉及能量及其导数(更多细节详见命题 3.2.1):
L S M ( ϕ ) = E p d a t a ( x ) Tr ( ∇ x 2 E ϕ ( x ) ) + 1 2 ∥ ∇ x E ϕ ( x ) ∥ 2 2 + C , \mathcal{L}{SM}(\phi) = \mathbb{E}{p_{data}(\mathbf{x})} \left \\text{Tr}\\left( \\nabla_{\\mathbf{x}}\^2 E_{\\phi}(\\mathbf{x}) \\right) + \\frac{1}{2} \\left\\\| \\nabla_{\\mathbf{x}} E_{\\phi}(\\mathbf{x}) \\right\\\|_2\^2 \\right + C, LSM(ϕ)=Epdata(x)Tr(∇x2Eϕ(x))+21∥∇xEϕ(x)∥22+C, 其中 ∇ x 2 E ϕ ( x ) ∇_\mathbf{x}^2E_ϕ(\mathbf{x}) ∇x2Eϕ(x) 是 E ϕ E_ϕ Eϕ 的海森矩阵(Hessian), C C C 是与 ϕ ϕ ϕ 无关的常数。
该公式的吸引力在于它消除了对配分函数的依赖 ,并且避免了在训练过程中从模型中进行采样 。其主要缺点是需要计算二阶导数 (也很麻烦啊) ------ 在高维空间中,这在计算上往往是不现实的。我们将在本章后续部分重新探讨解决这一局限性的方法。
3.1.4 带分数函数的朗之万采样(Langevin Sampling with Score Functions)
对于由能量函数 E ϕ ( x ) E_{\phi}(\mathbf{x}) Eϕ(x) 定义的 EBMs,可通过朗之万动力学(Langevin dynamics)实现采样。我们将首先介绍离散时间的朗之万更新规则,随后阐述其连续时间极限形式 ------ 随机微分方程(SDE)。最后,我们将探讨朗之万动力学能够高效探索复杂能量地形背后的物理直觉。
**Figure 3.3 | 朗之万采样示意图:**通过分数函数 ∇ x log p ϕ ( x ) \nabla_{\mathbf{x}} \log p_{\phi}(\mathbf{x}) ∇xlogpϕ(x) 引导轨迹向高密度区域移动,该过程由方程 (3.1.5) 中的更新实现(箭头指示);
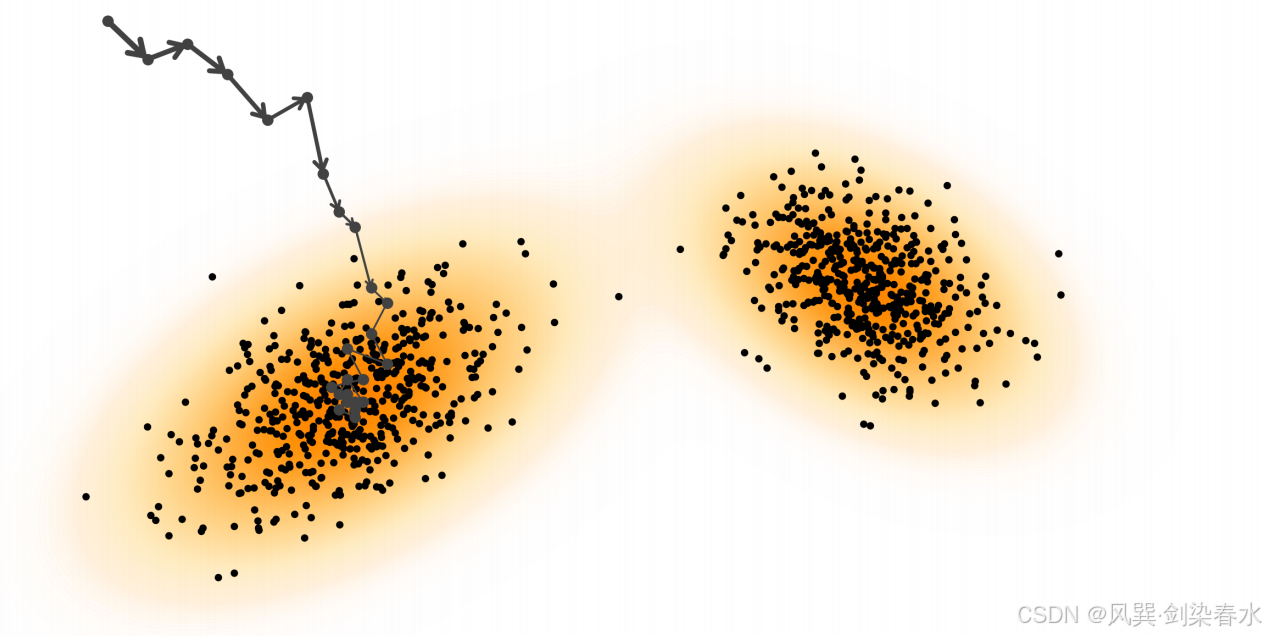
离散时间朗之万动力学。 离散时间的朗之万更新规则为:
x n + 1 = x n − η ∇ x E ϕ ( x n ) + 2 η ϵ n , n = 0 , 1 , 2 , ... , (3.1.4) \mathbf{x}{n+1} = \mathbf{x}n - \eta \nabla{\mathbf{x}} E{\phi}(\mathbf{x}_n) + \sqrt{2\eta} \boldsymbol{\epsilon}_n, \quad n = 0, 1, 2, \dots, \tag{3.1.4} xn+1=xn−η∇xEϕ(xn)+2η ϵn,n=0,1,2,...,(3.1.4) 其中 x 0 \mathbf{x}_0 x0 由某种分布(通常为高斯分布)初始化, η > 0 \eta>0 η>0 是步长,且 ϵ n ∼ N ( 0 , I ) \boldsymbol{\epsilon}_n \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) ϵn∼N(0,I) 代表高斯噪声。通过引入随机性,该噪声使得采样能够突破局部最小值的束缚进行探索。
由于分数函数可计算为:
∇ x log p ϕ ( x ) = − ∇ x E ϕ ( x ) . \nabla_{\mathbf{x}} \log p_{\phi}(\mathbf{x}) = -\nabla_{\mathbf{x}} E_{\phi}(\mathbf{x}). ∇xlogpϕ(x)=−∇xEϕ(x). 上述更新规则可等价表述为:
x n + 1 = x n + η ∇ x log p ϕ ( x n ) + 2 η ϵ n , (3.1.5) \mathbf{x}{n+1} = \mathbf{x}n + \eta \nabla{\mathbf{x}} \log p{\phi}(\mathbf{x}_n) + \sqrt{2\eta} \boldsymbol{\epsilon}_n, \tag{3.1.5} xn+1=xn+η∇xlogpϕ(xn)+2η ϵn,(3.1.5)
每一步 = 顺着能量下降的方向走一小步,同时加上一点随机扰动,避免陷入局部最优。
连续时间朗之万动力学。 当步长 η η η 趋近于 0 0 0 时,离散朗之万更新自然收敛到一个连续时间过程,该过程由朗之万随机微分方程(Langevin Stochastic Differential Equation, SDE) 描述:
d x ( t ) = ∇ x log p ϕ ( x ( t ) ) d t + 2 d w ( t ) , (3.1.6) d\mathbf{x}(t) = \nabla_{\mathbf{x}} \log p_{\phi}(\mathbf{x}(t)) dt + \sqrt{2} d\mathbf{w}(t), \tag{3.1.6} dx(t)=∇xlogpϕ(x(t))dt+2 dw(t),(3.1.6) 其中 w ( t ) \mathbf{w}(t) w(t) 表示标准布朗运动(也称为维纳过程)。需要注意的是,公式 (3.1.4) 中的离散更新规则是该连续 SDE 的欧拉 - 丸山(Euler--Maruyama)离散化。
在标准正则性假设下(例如, p ϕ ∝ e − E ϕ p_{\phi} \propto e^{-E_{\phi}} pϕ∝e−Eϕ,且 E ϕ E_ϕ Eϕ 是具有约束性且足够光滑的函数),当 t → ∞ t→∞ t→∞ 时, x ( t ) \mathbf{x}(t) x(t) 的分布会以指数速度收敛到 p ϕ p_ϕ pϕ;因此我们可以通过模拟(求解)SDE 方程 (3.1.6) 来进行采样。
每一瞬间,位置的变化由两部分组成:漂移项 (朝着概率密度增加的方向滑动)和扩散项(随机的抖动)
为何使用朗之万采样? 理解朗之万采样的一种自然视角是借助物理学:能量函数 E ϕ ( x ) E_ϕ(\mathbf{x}) Eϕ(x) 定义了一个势能地形,决定了粒子的行为。根据牛顿动力学,粒子在该能量导出的力场下运动由常微分方程(ODE)描述:
d x ( t ) = − ∇ x E ϕ ( x ( t ) ) d t , d\mathbf{x}(t) = -\nabla_{\mathbf{x}} E_{\phi}(\mathbf{x}(t)) dt, dx(t)=−∇xEϕ(x(t))dt, 它确定性地将粒子推向能量函数的局部极小值点。然而,这种确定性动力学容易陷入局部极小值,无法充分探索完整的数据分布。
为克服这一局限,朗之万动力学引入了随机扰动,得到如下随机微分方程(SDE):
d x ( t ) = − ∇ x E ϕ ( x ( t ) ) d t + 2 d w ( t ) ⏟ injected noise , d\mathbf{x}(t) = -\nabla_{\mathbf{x}} E_{\phi}(\mathbf{x}(t)) dt + \underbrace{\sqrt{2} d\mathbf{w}(t)}{\text{injected noise}}, dx(t)=−∇xEϕ(x(t))dt+injected noise 2 dw(t), 其中 w ( t ) \mathbf{w}(t) w(t) 是标准布朗运动。噪声项使粒子能够跨越能量势垒,从而逃离局部极小值,让轨迹成为一个平稳分布收敛于玻尔兹曼分布的随机过程:
p ϕ ( x ) ∝ e − E ϕ ( x ) . p{\phi}(\mathbf{x}) \propto e^{-E_{\phi}(\mathbf{x})}. pϕ(x)∝e−Eϕ(x). 从这一视角看,EBMs 可被视为学习一个力场,将样本推向高概率区域。朗之万采样对 EBMs 尤其有用,因为它提供了一种无需显式计算配分函数即可从模型分布 p ϕ ( x ) p_{\phi}(\mathbf{x}) pϕ(x) 中生成样本的实用方法。通过迭代执行朗之万更新,即可得到近似目标分布的样本。
朗之万采样的固有挑战。 朗之万动力学作为一种广泛使用的基于马尔可夫链蒙特卡洛(MCMC)的采样器,在高维空间中存在严重的局限性。其效率对步长 η η η、噪声尺度以及精准近似目标分布所需的迭代次数的选择高度敏感。
这种低效率的核心在于 "混合时间"(mixing time)过长 :在包含多个孤立峰的复杂数据分布中,朗之万采样通常需要极长的时间才能在高概率区域之间跃迁。随着维度的增加,这一问题会显著恶化,导致收敛速度慢得令人难以承受。
我们可以将采样过程想象为在一片广阔且崎岖的景观中探索 ------ 这里有许多相距遥远的 "山谷",每个山谷对应一种不同的数据模式。依赖于局部随机更新的朗之万动力学难以高效地穿越这些山谷。因此,它通常无法捕捉到分布的完整多样性。
这种低效率暗示了我们需要更具结构化且带有引导性的采样方法,这类方法比纯粹的随机探索更能有效导航复杂的数据流形。
当数据分布很复杂(比如图像数据集),包含多种不同类型时,朗之万采样可能只能采到它一开始附近的那几种模式,而很难采到所有模式,最终结果就会"无法捕捉到分布的完整多样性"------比如明明有猫、狗、车三种图片,它可能只采出了猫和狗,车的那部分从来没逛到过。
3.2 从基于能量到基于分数的生成模型(From Energy-Based to Score-Based Generative Models)
EBMs 表明,生成过程仅依赖于分数函数------ 它指向更高概率的区域 ------ 而非完整的归一化密度。尽管分数匹配 规避了配分函数 的计算,但通过能量进行训练仍需要计算代价高昂的二阶导数。核心思想是:由于朗之万动力学采样仅需要分数函数,我们可以直接用神经网络来学习它。这种从建模能量到建模分数的转变,构成了基于分数的生成模型的基础。
**Figure 3.4 | 分数匹配示意图:**神经网络分数 s ϕ ( x ) \mathbf{s}_ϕ(\mathbf{x}) sϕ(x) 以均方误差损失为目标,训练以匹配真实分数 s ( x ) \mathbf{s}(\mathbf{x}) s(x)。二者均以向量场的形式呈现;
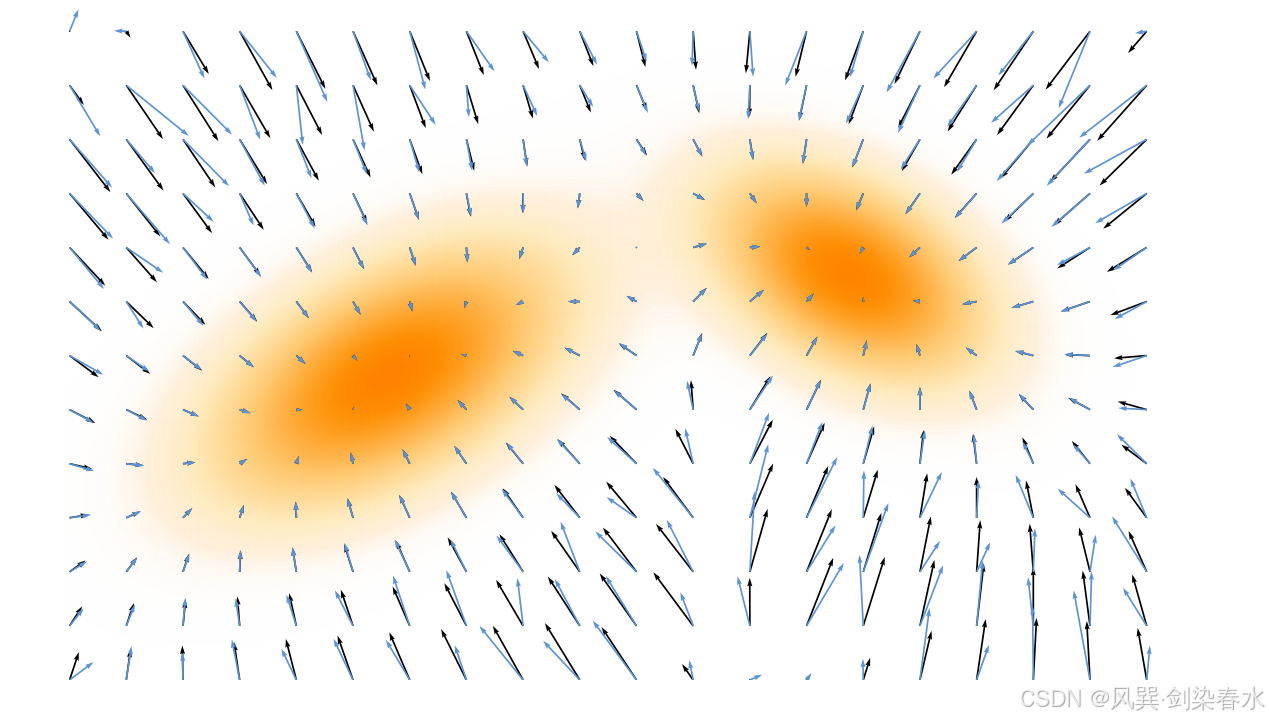
3.2.1 分数匹配训练(Training with Score Matching)
分数匹配。 为了从 p d a t a p_{data} pdata 的样本中近似分数函数 s ( x ) = ∇ x log p data ( x ) \mathbf{s}(\mathbf{x}) = \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) s(x)=∇xlogpdata(x),我们将其直接近似为一个由神经网络参数化的向量场 s ϕ ( x ) \mathbf{s}ϕ(\mathbf{x}) sϕ(x)(见图 3.4):
s ϕ ( x ) ≈ s ( x ) . \mathbf{s}{\phi}(\mathbf{x}) \approx \mathbf{s}(\mathbf{x}). sϕ(x)≈s(x). 分数匹配通过最小化真实分数与估计分数之间的均方误差(MSE)来拟合该向量场:
L SM ( ϕ ) : = 1 2 E x ∼ p data ∥ s ϕ ( x ) − s ( x ) ∥ 2 2 . (3.2.1) \mathcal{L}{\text{SM}}(\phi) := \frac{1}{2} \mathbb{E}{\mathbf{x} \sim p_{\text{data}}}\left \\\|\\mathbf{s}_{\\phi}(\\mathbf{x}) - \\mathbf{s}(\\mathbf{x})\\\|_2\^2 \\right. \tag{3.2.1} LSM(ϕ):=21Ex∼pdata∥sϕ(x)−s(x)∥22.(3.2.1)
可计算的分数匹配。 乍看之下,这个目标函数似乎不可行 ------ 因为作为回归目标的真实分数 s ( x ) \mathbf{s}(\mathbf{x}) s(x) 是未知的。幸运的是,Hyvärinen 和 Dayan(2005)证明,通过分部积分 可以得到一个等价的目标函数,该函数仅依赖于模型 s ϕ \mathbf{s}_ϕ sϕ 和数据样本,而无需访问真实分数。我们将在下面的命题中陈述这一关键结论。

利用公式 (3.2.2) 中的等价目标函数,我们仅从 p d a t a p_{data} pdata 的观测样本中训练分数模型 s ϕ ( x ) \mathbf{s}_ϕ(\mathbf{x}) sϕ(x),从而无需再依赖真实的分数函数。
公式 (3.2.2) 的直观含义。 我们可以直接从分数匹配的两个组成项来理解替代分数匹配目标 L ~ SM ( ϕ ) \widetilde{\mathcal{L}}_{\text{SM}}(\phi) L SM(ϕ)。
(1)范数项: 1 2 ∥ s ϕ ( x ) ∥ 2 \frac{1}{2}\|\mathbf{s}{\phi}(\mathbf{x})\|^2 21∥sϕ(x)∥2 会抑制 p d a t a p{data} pdata 较大区域内的分数,使这些区域成为平稳点;
(2)散度项: Tr ( ∇ x s ϕ ( x ) ) \text{Tr}(\nabla_{\mathbf{x}} \mathbf{s}_{\phi}(\mathbf{x})) Tr(∇xsϕ(x)) 倾向于取负值,因此这些平稳点会充当吸引力汇(attractive sinks);
二者共同作用,将高密度区域塑造为分数场中稳定且收敛的点。我们将在下文对此进行详细解释。
范数项直观理解: 数据点通常位于高概率区域,在这些地方概率密度达到局部最大值,其梯度(分数)应该接近于零(就像山顶上坡度为零)。所以这项惩罚在数据点上分数太大的情况,迫使模型把数据点"压平"。
散度项直观理解: 散度衡量向量场的"汇聚"或"发散"程度。如果散度为负,表示向量场在该点附近是汇聚的------周围点被吸引向该点。在真实数据分布中,高概率区域(如众数)是"吸引子",周围的点会沿着分数方向流向它们。因此,让散度为负就相当于让数据点成为吸引中心,使分数场指向数据点。
来自幅值项的平稳性。 由于 L ~ SM ( ϕ ) \widetilde{\mathcal{L}}{\text{SM}}(\phi) L SM(ϕ) 中的期望是在 p d a t a p{data} pdata 下取的,因此 p d a t a ( x ) p_{data}(\mathbf{x}) pdata(x) 较大的区域(即高数据密度区域)对损失的贡献最大。幅值项 1 2 ∥ s ϕ ( x ) ∥ 2 \frac{1}{2}\|\mathbf{s}_{\phi}(\mathbf{x})\|^2 21∥sϕ(x)∥2 会驱使 s ϕ ( x ) \mathbf{s}_ϕ(\mathbf{x}) sϕ(x) 在这些高概率区域趋近于 0 0 0,也就是说,这些位置会成为平稳点。
当向量场(近似)为梯度场时的凹性。 散度项 Tr ( ∇ x s ϕ ( x ) ) \text{Tr}(\nabla_{\mathbf{x}} \mathbf{s}_{\phi}(\mathbf{x})) Tr(∇xsϕ(x)) 会促使向量场在高数据密度区域呈现负散度。负散度意味着附近的向量会汇聚而非发散,因此该区域内的平稳点会充当汇(sink):邻近的轨迹会被向内牵引。
为精确说明这一点,假设 s ϕ = ∇ x u \mathbf{s}{\phi} = \nabla{\mathbf{x}} u sϕ=∇xu(其中 u : R D → R u:\mathbb{R}^D→\mathbb{R} u:RD→R 是标量函数),这在匹配对数密度时是很自然的设定(真实的分数本身就是对数概率密度的梯度)。此时 ∇ x s ϕ = ∇ x 2 u \nabla_{\mathbf{x}} \mathbf{s}{\phi} = \nabla{\mathbf{x}}^2 u ∇xsϕ=∇x2u(即海森矩阵),而 ∇ ⋅ s ϕ ( x ) = Tr ( ∇ x 2 u ( x ) ) \nabla \cdot \mathbf{s}{\phi}(\mathbf{x}) = \text{Tr}(\nabla{\mathbf{x}}^2 u(\mathbf{x})) ∇⋅sϕ(x)=Tr(∇x2u(x))(即散度)。(梯度场的散度就是 u u u 的拉普拉斯算子,即海森矩阵的迹)
在平稳点 x ⋆ \mathbf{x}\star x⋆ 处, s ϕ ( x ⋆ ) = ∇ x u ( x ⋆ ) = 0 \mathbf{s}ϕ(\mathbf{x}\star)=\nabla{\mathbf{x}} u(\mathbf{x}\star)=0 sϕ(x⋆)=∇xu(x⋆)=0,对 u ( x ) u(\mathbf{x}) u(x) 做二阶泰勒展开可得:
u ( x ) = u ( x ⋆ ) + 1 2 ( x − x ⋆ ) ⊤ ∇ x 2 u ( x ⋆ ) ( x − x ⋆ ) + o ( ∥ x − x ⋆ ∥ 2 ) . u(\mathbf{x}) = u(\mathbf{x}\star) + \frac{1}{2} (\mathbf{x} - \mathbf{x}\star)^\top \nabla{\mathbf{x}}^2 u(\mathbf{x}\star) (\mathbf{x} - \mathbf{x}\star) + o(\|\mathbf{x} - \mathbf{x}\star\|^2). u(x)=u(x⋆)+21(x−x⋆)⊤∇x2u(x⋆)(x−x⋆)+o(∥x−x⋆∥2). 若海森矩阵 ∇ x 2 u ( x ⋆ ) \nabla{\mathbf{x}}^2 u(\mathbf{x}\star) ∇x2u(x⋆) 是负定矩阵的,则 u u u 在 x ⋆ \mathbf{x}\star x⋆ 处局部凹,且对数密度在此处取得严格局部极大值。由于海森矩阵的所有特征值均为负,其迹也必然为负: Tr ( ∇ x 2 u ( x ⋆ ) < 0 \text{Tr}(\nabla_{\mathbf{x}}^2 u(\mathbf{x}\star)<0 Tr(∇x2u(x⋆)<0。因此,学习到的向量场具有负散度,平稳点是汇:微小扰动会被收缩回 x ⋆ \mathbf{x}\star x⋆。
3.2.2 朗之万动力学采样(Sampling with Langevin Dynamics)
通过最小化公式 (3.2.2) 完成训练后,分数模型 s ϕ × ( x ) \mathbf{s}{\phi^\times}(\mathbf{x}) sϕ×(x) 可替代朗之万动力学中的理想分数用于采样:
x n + 1 = x n + η s ϕ × ( x n ) + 2 η ϵ n , ϵ n ∼ N ( 0 , I ) , (3.2.3) \mathbf{x}{n+1} = \mathbf{x}n + \eta \mathbf{s}{\phi^\times}(\mathbf{x}_n) + \sqrt{2\eta} \boldsymbol{\epsilon}_n, \quad \boldsymbol{\epsilon}_n \sim \mathcal{N}(\mathbf{0}, \mathbf{I}), \tag{3.2.3} xn+1=xn+ηsϕ×(xn)+2η ϵn,ϵn∼N(0,I),(3.2.3) 其中 n = 0 , 1 , 2 , ... , n=0,1,2,..., n=0,1,2,..., 初始状态为 x 0 \mathbf{x}0 x0。与 EBM 场景下的公式 (3.1.6) 一致,该递推式正是连续时间朗之万随机微分方程 的欧拉 - 丸山(Euler--Maruyama)离散化:
d x ( t ) = s ϕ × ( x ( t ) ) d t + 2 d w ( t ) , d\mathbf{x}(t) = \mathbf{s}{\phi^\times}(\mathbf{x}(t)) dt + \sqrt{2} d\mathbf{w}(t), dx(t)=sϕ×(x(t))dt+2 dw(t), 初始化为 x 0 \mathbf{x}_0 x0。因此,在步长趋近于 0 0 0 的极限下,离散形式与连续形式等价。在实际应用中,既可以运行离散采样器,也可以直接模拟随机微分方程。
3.2.3 序言:基于分数的生成模型(Prologue: Score-Based Generative Models)
在本章剩余部分,我们将探讨分数函数在现代扩散模型中的基础性作用。分数函数最初是为了实现 EBMs 的高效训练而提出,如今已演变为新一代生成模型的核心组件。在此基础上,我们将探究分数函数如何指导基于分数的扩散模型 的理论构建与实际实现,为通过随机过程进行数据生成提供一套严谨的框架。
3.3 去噪分数匹配(Denoising Score Matching)
3.3.1 动机(Motivation)
尽管公式 (3.2.2) 中的替代目标函数:
L ~ SM ( ϕ ) = E x ∼ p data Tr ( ∇ x s ϕ ( x ) ) + 1 2 ∥ s ϕ ( x ) ∥ 2 2 \widetilde{\mathcal{L}}{\text{SM}}(\phi) = \mathbb{E}{\mathbf{x} \sim p_{\text{data}}}\left \\text{Tr}\\left(\\nabla_{\\mathbf{x}} \\mathbf{s}_{\\phi}(\\mathbf{x})\\right) + \\frac{1}{2}\\\|\\mathbf{s}_{\\phi}(\\mathbf{x})\\\|_2\^2 \\right L SM(ϕ)=Ex∼pdataTr(∇xsϕ(x))+21∥sϕ(x)∥22 更易于计算,但它仍需要计算雅可比矩阵的迹 Tr ( ∇ x s ϕ ( x ) ) \text{Tr}\left(\nabla_{\mathbf{x}} \mathbf{s}_{\phi}(\mathbf{x})\right) Tr(∇xsϕ(x)),其最坏情况下的复杂度为 O ( D 2 ) \mathcal{O}(D^2) O(D2)。这种复杂度限制了它在高维数据上的可扩展性。
为解决这一问题,切片分数匹配(sliced score matching)(Song et al., 2020b)用基于随机投影的随机估计替代了迹项。我们将在下文简要概述其核心思想。
切片分数匹配与哈钦森估计器(Hutchinson's Estimator)。 切片分数匹配通过对随机 "切片" 方向上的方向导数取平均,来替代分数匹配中的迹项。 令 u ∈ R D u∈\mathbb{R}^D u∈RD 为各向同性随机向量(例如拉德马赫分布或标准高斯分布),满足 E u = 0 \mathbb{E}u=0 Eu=0 且 E u u ⊤ = I \mathbb{E}uu\^⊤=\mathbf{I} Euu⊤=I。根据哈钦森恒等式:
Tr ( A ) = E u u ⊤ A u , 且 E u ( u ⊤ s ϕ ( x ) ) 2 = ∥ s ϕ ( x ) ∥ 2 2 , \text{Tr}(\mathbf{A}) = \mathbb{E}{\mathbf{u}}\\mathbf{u}\^\\top \\mathbf{A} \\mathbf{u}, \quad \text{且} \quad \mathbb{E}{\mathbf{u}}\left(\\mathbf{u}\^\\top \\mathbf{s}_{\\phi}(\\mathbf{x}))\^2\\right = \|\mathbf{s}{\phi}(\mathbf{x})\|2^2, Tr(A)=Euu⊤Au,且Eu(u⊤sϕ(x))2=∥sϕ(x)∥22, 我们可以得到精确形式:
L ~ SM ( ϕ ) = E x , u u ⊤ ( ∇ x s ϕ ( x ) ) u + 1 2 ( u ⊤ s ϕ ( x ) ) 2 . \widetilde{\mathcal{L}}{\text{SM}}(\phi) = \mathbb{E}{\mathbf{x},\mathbf{u}}\left \\mathbf{u}\^\\top \\left(\\nabla_{\\mathbf{x}} \\mathbf{s}_{\\phi}(\\mathbf{x})\\right) \\mathbf{u} + \\frac{1}{2}\\left(\\mathbf{u}\^\\top \\mathbf{s}_{\\phi}(\\mathbf{x})\\right)\^2 \\right. L SM(ϕ)=Ex,uu⊤(∇xsϕ(x))u+21(u⊤sϕ(x))2.
**第一项:**可以理解为"沿着方向 u u u 看分数场的变化,再把这个变化投影回 u u u 方向"。它近似于散度在该方向上的"贡献"。
**第二项:**则是"分数在方向 u u u 上的投影的平方",相当于原来范数项在该方向上的分解。两项合起来,就是"在随机方向 u u u 上"的局部分数匹配目标。对足够多的随机方向取平均,就能恢复原始目标。
该目标函数可通过自动微分高效计算,使用雅可比向量积(JVP)或向量雅可比积(VJP)操作,而非显式计算大型雅可比矩阵或海森矩阵。对 K K K 个随机探针取平均可得到无偏估计器,其方差为 O ( 1 / K ) \mathcal{O}(1/K) O(1/K);方向项 u ⊤ ( ∇ x s ϕ ) u \mathbf{u}^\top \left(\nabla_{\mathbf{x}} \mathbf{s}_{\phi}\right) \mathbf{u} u⊤(∇xsϕ)u 可通过 JVP/VJP 高效计算,无需显式构建雅可比矩阵。直观来说,这意味着我们仅在随机方向上检查模型行为:将投影后的分数推向更高数据密度区域,从而使数据点在期望意义下成为平稳点。
想象在一片复杂的地形(对应分数场)上,想测量每个点的"陡峭程度"在所有方向上的平均值(也就是散度)。如果每个点都要测量所有方向(比如东、南、西、北、东北......),工作量巨大。
切片分数匹配 的做法是:在每个点随机扔出几根"探针"(即随机方向 u u u),只测量探针方向上的变化,然后把多次测量的结果平均。虽然每次只测一个方向,但平均下来就能逼近真实的全方向平均值。而且探针的方向是随机均匀的,所以估计是无偏的。
从切片分数匹配到去噪分数匹配。 切片分数匹配规避了雅可比矩阵计算,但仍依赖原始数据分布。这使其较为脆弱:对于分布在低维流形上的图像数据,分数 ∇ x log p data ( x ) \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) ∇xlogpdata(x) 可能未定义或不稳定,且该方法仅在观测点约束向量场,对其邻域的控制较弱。此外,它还存在随机探针引入的方差和重复 JVP/VJP 计算的开销问题。
我们在此重点介绍一种更鲁棒的替代方案:去噪分数匹配(Denoising Score Matching, DSM)(Vincent, 2011),它提供了一套严谨且可扩展的解决方案。
3.3.2 训练(Training)
让我们回顾公式 (3.2.1) 中的分数匹配(SM)损失:
L SM ( ϕ ) = 1 2 E x ∼ p data ( x ) ∥ s ϕ ( x ) − ∇ x log p data ( x ) ∥ 2 2 , \mathcal{L}{\text{SM}}(\phi) = \frac{1}{2}\mathbb{E}{\mathbf{x} \sim p_{\text{data}}(\mathbf{x})}\left \\\|\\mathbf{s}_{\\phi}(\\mathbf{x}) - \\nabla_{\\mathbf{x}} \\log p_{\\text{data}}(\\mathbf{x})\\\|_2\^2 \\right, LSM(ϕ)=21Ex∼pdata(x)∥sϕ(x)−∇xlogpdata(x)∥22, 问题的核心在于难以处理的项 ∇ x log p data ( x ) \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) ∇xlogpdata(x)。
Vincent 的条件化解决方案。 为克服 ∇ x log p data ( x ) \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) ∇xlogpdata(x) 的不可计算性,Vincent 提出通过已知条件分布 p σ ( x ~ ∣ x ) p_σ(\tilde{\mathbf{x}}∣\mathbf{x}) pσ(x~∣x)(尺度为 σ σ σ)向数据 x ∼ p d a t a \mathbf{x}∼p_{data} x∼pdata 注入噪声。神经网络 s ϕ ( x ~ ; σ ) \mathbf{s}ϕ(\tilde{\mathbf{x}};σ) sϕ(x~;σ) 被训练以近似边际扰动分布的分数:
p σ ( x ~ ) = ∫ p σ ( x ~ ∣ x ) p data ( x ) d x p{\sigma}(\tilde{\mathbf{x}}) = \int p_{\sigma}(\tilde{\mathbf{x}}|\mathbf{x}) p_{\text{data}}(\mathbf{x}) d\mathbf{x} pσ(x~)=∫pσ(x~∣x)pdata(x)dx 通过最小化以下损失实现:
L SM ( ϕ ; σ ) : = 1 2 E x ~ ∼ p σ ∥ s ϕ ( x \~ ; σ ) − ∇ x \~ log p σ ( x \~ ) ∥ 2 2 . (3.3.1) \mathcal{L}{\text{SM}}(\phi; \sigma) := \frac{1}{2}\mathbb{E}{\tilde{\mathbf{x}} \sim p_{\sigma}}\left \\\|\\mathbf{s}_{\\phi}(\\tilde{\\mathbf{x}}; \\sigma) - \\nabla_{\\tilde{\\mathbf{x}}} \\log p_{\\sigma}(\\tilde{\\mathbf{x}})\\\|_2\^2 \\right. \tag{3.3.1} LSM(ϕ;σ):=21Ex~∼pσ∥sϕ(x\~;σ)−∇x\~logpσ(x\~)∥22.(3.3.1) 尽管 ∇ x ~ log p σ ( x ~ ) \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma}(\tilde{\mathbf{x}}) ∇x~logpσ(x~) 通常难以计算,但 Vincent 证明:以 x ∼ p d a t a \mathbf{x}∼p_{data} x∼pdata 为条件可以得到一个等价且可计算的目标函数 ------去噪分数匹配(DSM)损失:
L DSM ( ϕ ; σ ) : = 1 2 E x ∼ p data , x ~ ∼ p σ ( ⋅ ∣ x ) ∥ s ϕ ( x \~ ; σ ) − ∇ x \~ log p σ ( x \~ ∣ x ) ∥ 2 2 . (3.3.2) \mathcal{L}{\text{DSM}}(\phi; \sigma) := \frac{1}{2}\mathbb{E}{\mathbf{x} \sim p_{\text{data}},\, \tilde{\mathbf{x}} \sim p_{\sigma}(\cdot|\mathbf{x})}\left \\\|\\mathbf{s}_{\\phi}(\\tilde{\\mathbf{x}}; \\sigma) - \\nabla_{\\tilde{\\mathbf{x}}} \\log p_{\\sigma}(\\tilde{\\mathbf{x}}\|\\mathbf{x})\\\|_2\^2 \\right. \tag{3.3.2} LDSM(ϕ;σ):=21Ex∼pdata,x~∼pσ(⋅∣x)∥sϕ(x\~;σ)−∇x\~logpσ(x\~∣x)∥22.(3.3.2) 公式 (3.3.2) 的最优极小化子 s ∗ s^∗ s∗ 满足:
s ∗ ( x ~ ; σ ) = ∇ x ~ log p σ ( x ~ ) , \mathbf{s}^*(\tilde{\mathbf{x}}; \sigma) = \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma}(\tilde{\mathbf{x}}), s∗(x~;σ)=∇x~logpσ(x~), 这同时也是公式 (3.3.1) 的最优解。
去噪分数匹配的核心思想是: **用一个已知的条件分数(从加噪过程中得到)作为目标,来间接学习加噪后分布的分数,从而绕过对原始数据分布的未知分数的直接依赖。**这一技巧为后来的扩散模型(其中需要学习多个噪声尺度下的分数)铺平了道路。
通俗理解: 想象你想知道一座山(数据分布)的坡度,但山被迷雾笼罩,你无法直接看到整个山体(无法计算真实分数)。Vincent 的方法是这样的:(1)你往山上扔一些烟雾弹(加噪声),让山变得模糊一些,形成一个新的、稍微模糊的山形 p σ p_{\sigma} pσ;
(2)虽然你仍然不知道模糊山的整体坡度,但你知道每个烟雾弹的扩散规律(条件分布 p σ ( x ~ ∣ x ) p_σ(\tilde{\mathbf{x}}∣\mathbf{x}) pσ(x~∣x)),因此你可以通过测量烟雾从原始点扩散到周围某点的"偏移量"来推断该点的局部坡度。
(3)最后,你得到的是模糊山的坡度,但当烟雾很淡( σ σ σ 很小)时,它和真实山的坡度几乎没有差别。
例如,当 p σ ( x ~ ∣ x ) p_σ(\tilde{\mathbf{x}}∣\mathbf{x}) pσ(x~∣x) 是方差为 σ 2 σ^2 σ2 的高斯噪声时:
p σ ( x ~ ∣ x ) = N ( x ~ ; x , σ 2 I ) , p_{\sigma}(\tilde{\mathbf{x}}|\mathbf{x}) = \mathcal{N}(\tilde{\mathbf{x}}; \mathbf{x}, \sigma^2 \mathbf{I}), pσ(x~∣x)=N(x~;x,σ2I), 梯度 ∇ x ~ log p σ ( x ~ ) \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma}(\tilde{\mathbf{x}}) ∇x~logpσ(x~) 具有闭式解(见公式 (3.3.4)),这使得回归目标变得显式且计算上可处理。
此外,当 σ ≈ 0 σ≈0 σ≈0 时, p σ ( x ~ ) ≈ p d a t a ( x ) p_σ(\tilde{\mathbf{x}})≈p_{data}(\mathbf{x}) pσ(x~)≈pdata(x),且
s ∗ ( x ~ ; σ ) = ∇ x ~ log p σ ( x ~ ) ≈ ∇ x log p data ( x ) , \mathbf{s}^*(\tilde{\mathbf{x}}; \sigma) = \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma}(\tilde{\mathbf{x}}) \approx \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}), s∗(x~;σ)=∇x~logpσ(x~)≈∇xlogpdata(x), 这表明学习到的分数近似于原始数据的分数,从而可用于生成任务。
我们将在以下定理中形式化 L SM \mathcal{L}{\text{SM}} LSM 与 L DSM \mathcal{L}{\text{DSM}} LDSM 之间的梯度等价性:

该定理与扩散模型(DDPM)中的定理 2.2.1 类似,共同阐明了一个核心共享原理:
洞察 3.3.1:条件化技术(Conditioning Technique)
条件化技术同样出现在 DDPM 中扩散模型的变分视角(见定理 2.2.1):以数据点 x \mathbf{x} x 为条件,可将一个难以处理的损失函数转化为蒙特卡洛(Monte Carlo)估计可处理的形式。在基于流的视角(例如流匹配(Flow Matching))中,我们将看到类似的思想(详见 5.2 节)。
**Figure 3.5 | 利用条件技术演示 DSM:**通过向数据分布 p data p_{\text{data}} pdata 中注入小幅度加性高斯噪声 N ( 0 , σ 2 I ) \mathcal{N}(\mathbf{0}, \sigma^2\mathbf{I}) N(0,σ2I) 对其进行扰动,得到的条件分布 p σ ( x ~ ∣ x ) = N ( x ~ ; x , σ 2 I ) p_\sigma(\tilde{\mathbf{x}}|\mathbf{x}) = \mathcal{N}(\tilde{\mathbf{x}}; \mathbf{x}, \sigma^2\mathbf{I}) pσ(x~∣x)=N(x~;x,σ2I) 具有闭式得分函数;

特例:加性高斯噪声。 现在考虑常见的加性高斯噪声场景:向每个数据点 x ∼ p d a t a \mathbf{x}∼p_{data} x∼pdata 加入方差为 σ 2 σ^2 σ2 的高斯噪声 N ( 0 , σ 2 I ) \mathcal{N}(\mathbf{0},σ^2\mathbf{I}) N(0,σ2I):
x ~ = x + σ ϵ , ϵ ∼ N ( 0 , I ) , \tilde{\mathbf{x}} = \mathbf{x} + \sigma \boldsymbol{\epsilon}, \quad \boldsymbol{\epsilon} \sim \mathcal{N}(0, \mathbf{I}), x~=x+σϵ,ϵ∼N(0,I), 因此被污染的数据 x ~ \tilde{\mathbf{x}} x~ 服从条件分布:
p σ ( x ~ ∣ x ) = N ( x ~ ; x , σ 2 I ) . p_{\sigma}(\tilde{\mathbf{x}}|\mathbf{x}) = \mathcal{N}(\tilde{\mathbf{x}}; \mathbf{x}, \sigma^2 \mathbf{I}). pσ(x~∣x)=N(x~;x,σ2I). 在该设定下,条件分数具有解析形式:
∇ x ~ log p σ ( x ~ ∣ x ) = x − x ~ σ 2 . \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma}(\tilde{\mathbf{x}}|\mathbf{x}) = \frac{\mathbf{x} - \tilde{\mathbf{x}}}{\sigma^2}. ∇x~logpσ(x~∣x)=σ2x−x~.
对 x ~ \tilde{\mathbf{x}} x~ 求梯度,这个形式极其简单:它就是噪声向量除以方差的相反数,或者说,是"从加噪样本指向原始干净样本的方向"除以方差。
因此,去噪分数匹配(DSM)损失可简化为(带入 x ~ = x + σ ϵ \tilde{\mathbf{x}}=\mathbf{x}+\sigma \boldsymbol{\epsilon} x~=x+σϵ):
L DSM ( ϕ ; σ ) = 1 2 E x , x ~ ∣ x ∥ s ϕ ( x \~ ; σ ) − x − x \~ σ 2 ∥ 2 2 = 1 2 E x , ϵ ∥ s ϕ ( x + σ ϵ ; σ ) + ϵ σ ∥ 2 2 . (3.3.4) \begin{aligned} \mathcal{L}{\text{DSM}}(\phi; \sigma) &= \frac{1}{2}\mathbb{E}{\mathbf{x},\tilde{\mathbf{x}}|\mathbf{x}}\left \\left\\\| \\mathbf{s}_{\\phi}(\\tilde{\\mathbf{x}}; \\sigma) - \\frac{\\mathbf{x} - \\tilde{\\mathbf{x}}}{\\sigma\^2} \\right\\\|_2\^2 \\right \\ &= \frac{1}{2}\mathbb{E}_{\mathbf{x},\boldsymbol{\epsilon}}\left \\left\\\| \\mathbf{s}_{\\phi}(\\mathbf{x} + \\sigma \\boldsymbol{\\epsilon}; \\sigma) + \\frac{\\boldsymbol{\\epsilon}}{\\sigma} \\right\\\|_2\^2 \\right. \tag{3.3.4} \end{aligned} LDSM(ϕ;σ)=21Ex,x~∣x sϕ(x\~;σ)−σ2x−x\~ 22=21Ex,ϵ sϕ(x+σϵ;σ)+σϵ 22.(3.3.4) 其中 ϵ ∼ N ( 0 , I ) ϵ∼\mathcal{N}(\mathbf{0},\mathbf{I}) ϵ∼N(0,I)。该目标函数构成了(基于分数的)扩散模型的核心。
当噪声水平 σ σ σ 很小时,高斯平滑后的边际分布 p σ = p data ∗ N ( 0 , σ 2 I ) p_{\sigma} = p_{\text{data}} * \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I}) pσ=pdata∗N(0,σ2I),因此二者的高密度区域与分数函数几乎一致: ∇ x ~ log p σ ( x ~ ) ≈ ∇ x log p data ( x ) \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma}(\tilde{\mathbf{x}}) \approx \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) ∇x~logpσ(x~)≈∇xlogpdata(x)。因此,沿带噪分数方向 ∇ x ~ log p σ \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma} ∇x~logpσ 迈出一小步,会将带噪样本推向干净分布中几乎相同的高似然区域,这与 3.2.1 节中总结的分数匹配直觉是一致的。
相比之下,当 σ σ σ 较大时,平滑操作会 "过度简化" 分布形态: p σ p_σ pσ 会抹平局部模态,其分数函数主要将样本向全局质量中心牵引(可理解为向均值收缩),从而产生粗糙的去噪效果,甚至可能导致过度平滑。不过在实际应用中,去噪分数匹配(DSM)通常假设注入的噪声是微小且温和的。
模型的任务是从带噪样本中"预测"出所加的噪声 ϵ \epsilon ϵ (或等价的分数)。
噪声尺度 σ \sigma σ 控制着模型学习到的分布的平滑程度:小噪声保留细节,大噪声只学全局结构。
为了更清晰地理解该目标函数为何天然对应 "去噪" 过程,我们将在 3.3.4 节和 3.3.5 节中进一步展开讨论。
3.3.3 采样(Sampling)
一旦在噪声水平 σ σ σ 下训练好了分数模型 s ϕ × ( x ~ ; σ ) \mathbf{s}{\phi^\times}(\tilde{\mathbf{x}}; \sigma) sϕ×(x~;σ),我们就可以在朗之万动力学采样中,用学到的模型替换真实分数来生成样本。更新规则为:
x ~ n + 1 = x ~ n + η s ϕ × ( x ~ n ; σ ) ⏟ ≈ ∇ x ~ log p σ ( x ~ n ) + 2 η ϵ n , ϵ n ∼ N ( 0 , I ) , (3.3.5) \tilde{\mathbf{x}}{n+1} = \tilde{\mathbf{x}}n + \eta \underbrace{\mathbf{s}{\phi^\times}(\tilde{\mathbf{x}}n; \sigma)}{\approx \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma}(\tilde{\mathbf{x}}_n)} + \sqrt{2\eta} \boldsymbol{\epsilon}_n, \quad \boldsymbol{\epsilon}_n \sim \mathcal{N}(\mathbf{0}, \mathbf{I}), \tag{3.3.5} x~n+1=x~n+η≈∇x~logpσ(x~n) sϕ×(x~n;σ)+2η ϵn,ϵn∼N(0,I),(3.3.5) 迭代次数 n = 0 , 1 , 2 , ... , n=0,1,2,..., n=0,1,2,..., 初始值为 x ~ 0 \tilde{\mathbf{x}}_0 x~0。若 σ σ σ 足够小,经过足够多次迭代后, x ~ n \tilde{\mathbf{x}}n x~n 即可近似来自 p d a t a p{data} pdata 的样本。
噪声注入的优势。 此外,与公式 (3.2.1) 中的原始分数匹配相比,注入高斯噪声以构建 p σ p_σ pσ(例如公式 3.3.4)提供了两个关键优势(Song and Ermon, 2019):
定义良好的梯度: 噪声将数据从其低维流形中扰动开,使得分布 p σ p_σ pσ 在 R D \mathbb{R}^D RD 中具有全支撑集(full support)。因此,分数函数 ∇ x ~ log p σ ( x ~ ) \nabla_{\tilde{\mathbf{x}}} \log p_{\sigma}(\tilde{\mathbf{x}}) ∇x~logpσ(x~) 在各处都是定义良好的。
改进的覆盖范围: 噪声平滑了各模态之间的稀疏区域,提升了训练信号的质量,并促进朗之万动力学更高效地穿越低密度区域。
3.3.4 DSM 去噪原理:Tweedie 公式(Why DSM is Denoising: Tweedie's Formula)
我们从 Tweedie 公式(Efron, 2011)开始,该公式为仅从带噪观测值中去噪提供了严谨的理论基础。具体而言,它表明:给定未知信号 x ∼ p d a t a \mathbf{x}∼p_{data} x∼pdata 产生的单个高斯污染观测 x ~ ∼ N ( ⋅ ; α x , σ 2 I ) \tilde{\mathbf{x}} \sim \mathcal{N}(\cdot; \alpha \mathbf{x}, \sigma^2 \mathbf{I}) x~∼N(⋅;αx,σ2I),去噪估计量(即给定 x ~ \tilde{\mathbf{x}} x~ 时所有合理干净信号的均值)可通过将 x ~ \tilde{\mathbf{x}} x~ 沿其含噪边缘分布的得分函数 ∇ x ~ log p σ ( x ~ ) \nabla_{\tilde{\mathbf{x}}} \log p_\sigma(\tilde{\mathbf{x}}) ∇x~logpσ(x~) 的方向、以步长 σ 2 σ^2 σ2 进行偏移得到,其中含噪边缘分布定义为: p σ ( x ~ ) : = ∫ N ( x ~ ; α x 0 , σ 2 I ) p data ( x ) d x . p_\sigma(\tilde{\mathbf{x}}) := \int \mathcal{N}(\tilde{\mathbf{x}}; \alpha \mathbf{x}0, \sigma^2 \mathbf{I}) p{\text{data}}(\mathbf{x}) \, d\mathbf{x}. pσ(x~):=∫N(x~;αx0,σ2I)pdata(x)dx. 我们将在下文正式提出该命题:

Tweedie 公式在扩散模型中发挥着核心作用,这类模型如 DDPM 会引入多层噪声。该公式可通过得分函数,从含噪观测中估计干净样本,从而在得分预测与去噪器之间建立起根本性的联系:
E x ∣ x \~ ⏟ denoiser estimated from x ~ = 1 α ( x ~ + σ 2 ∇ x ~ log p σ ( x ~ ) ) . \underbrace{\mathbb{E}\left\\mathbf{x}\|\\tilde{\\mathbf{x}}\\right}{\text{denoiser estimated from } \tilde{\mathbf{x}}} = \frac{1}{\alpha} \left( \tilde{\mathbf{x}} + \sigma^2 \nabla{\tilde{\mathbf{x}}} \log p_\sigma(\tilde{\mathbf{x}}) \right). denoiser estimated from x~ Ex∣x\~=α1(x~+σ2∇x~logpσ(x~)). 具体而言,对含噪对数似然函数执行一次步长为 σ 2 σ^2 σ2 的梯度上升,即可得到去噪估计量(即条件期望下的干净信号)。这使得 DSM 训练与去噪过程紧密关联:若通过 DSM 训练得到 s ϕ ( x ~ ) ≈ ∇ x ~ log p σ ( x ~ ) \mathbf{s}\phi(\tilde{\mathbf{x}}) \approx \nabla{\tilde{\mathbf{x}}} \log p_\sigma(\tilde{\mathbf{x}}) sϕ(x~)≈∇x~logpσ(x~),则: 1 α ( x ~ + σ 2 s ϕ ( x ~ ) ) \frac{1}{\alpha} \left( \tilde{\mathbf{x}} + \sigma^2 \mathbf{s}_\phi(\tilde{\mathbf{x}}) \right) α1(x~+σ2sϕ(x~))即为对应的去噪器。
Tweedie 公式就是一个"一步降噪公式": 最优降噪结果 = 带噪观测 + 噪声强度 × 带噪数据的得分函数
(可选)高阶 Tweedie 公式。 经典 Tweedie 公式通过梯度 ∇ x ~ log p ( x ~ ) \nabla_{\tilde{\mathbf{x}}} \log p(\tilde{\mathbf{x}}) ∇x~logp(x~) 来表示后验均值 E x 0 ∣ x \~ \mathbb{E}\\mathbf{x}_0\|\\tilde{\\mathbf{x}} Ex0∣x\~。其高阶扩展形式(Meng et al., 2021a)则通过 log p ( x ~ ) \log p(\tilde{\mathbf{x}}) logp(x~) 的高阶导数,来表示后验协方差 与更高阶累积量。
带对数归一化项 λ ( x ~ ) λ(\tilde{\mathbf{x}}) λ(x~) 的指数族设定。 假设在给定隐式自然参数 η ∈ R D \boldsymbol{\eta} \in \mathbb{R}^D η∈RD 的条件下, x ~ \tilde{\mathbf{x}} x~ 的条件分布属于自然指数族(高斯分布是指数族的一个特例),其形式为:
q σ ( x ~ ∣ η ) = exp ( η ⊤ x ~ − ψ ( η ) ) q 0 ( x ~ ) q_\sigma(\tilde{\mathbf{x}}|\boldsymbol{\eta}) = \exp(\boldsymbol{\eta}^\top \tilde{\mathbf{x}} - \psi(\boldsymbol{\eta}))\, q_0(\tilde{\mathbf{x}}) qσ(x~∣η)=exp(η⊤x~−ψ(η))q0(x~) 其中 q 0 ( x ~ ) q_0(\tilde{\mathbf{x}}) q0(x~) 为基测度,即与 η η η 无关的部分;对于方差为 σ 2 I σ^2\mathbf{I} σ2I 的加性高斯噪声,其表达式为 ( 2 π σ 2 ) − D / 2 exp ( − ∥ x ~ ∥ 2 / 2 σ 2 ) (2\pi\sigma^2)^{-D/2} \exp(-\|\tilde{\mathbf{x}}\|^2/2\sigma^2) (2πσ2)−D/2exp(−∥x~∥2/2σ2)。设 p ( η ) p(\boldsymbol{\eta}) p(η) 为隐式自然参数的预设分布,可将其视为重参数化后的干净数据分布(对于高斯位置模型, η = x / σ 2 \boldsymbol{\eta}=x/σ^2 η=x/σ2)。观测到的含噪边缘分布为:
p σ ( x ~ ) = ∫ q σ ( x ~ ∣ η ) p ( η ) d η p_\sigma(\tilde{\mathbf{x}}) = \int q_\sigma(\tilde{\mathbf{x}}|\boldsymbol{\eta})\, p(\boldsymbol{\eta})\, \mathrm{d}\boldsymbol{\eta} pσ(x~)=∫qσ(x~∣η)p(η)dη定义关于 x ~ \tilde{\mathbf{x}} x~ 的对数配分函数(对数归一化项)为:
λ ( x ~ ) : = log p σ ( x ~ ) − log q 0 ( x ~ ) \lambda(\tilde{\mathbf{x}}) := \log p_\sigma(\tilde{\mathbf{x}}) - \log q_0(\tilde{\mathbf{x}}) λ(x~):=logpσ(x~)−logq0(x~)则在给定 x ~ \tilde{\mathbf{x}} x~ 时, η \boldsymbol{\eta} η 的后验分布为:
p ( η ∣ x ~ ) ∝ exp ( η ⊤ x ~ − ψ ( η ) − λ ( x ~ ) ) p ( η ) p(\boldsymbol{\eta}|\tilde{\mathbf{x}}) \propto \exp(\boldsymbol{\eta}^\top \tilde{\mathbf{x}} - \psi(\boldsymbol{\eta}) - \lambda(\tilde{\mathbf{x}}))\, p(\boldsymbol{\eta}) p(η∣x~)∝exp(η⊤x~−ψ(η)−λ(x~))p(η)这表明,作为 x ~ \tilde{\mathbf{x}} x~ 的函数,该后验分布具有指数族形式,其自然参数为 x ~ \tilde{\mathbf{x}} x~,充分统计量为 η \boldsymbol{\eta} η,对数配分函数为 λ ( x ~ ) λ(\tilde{\mathbf{x}}) λ(x~)。
高阶 Tweedie 公式扩展了什么
我们不仅能得到均值,还能得到协方差(不确定性)、偏度(分布不对称性)等更高阶的统计量。
这些高阶信息可以从带噪数据分布的对数密度的二阶、三阶等更高阶导数中计算出来。
比如:
一阶导数告诉你往哪里走(方向)
二阶导数告诉你这条路有多"陡峭"(确定性程度)
三阶导数告诉你这个陡峭变化是否对称(偏斜)
所以在去噪任务中,高阶 Tweedie 公式能让我们知道:不仅恢复一个干净信号,还能知道这个恢复有多可靠。
在指数族噪声的设定下,带噪数据分布的对数密度的各阶导数,直接给出了后验分布(给定观测时干净信号的不确定性)的各阶统计量。
λ λ λ 的导数生成后验累积量。 这里遵循两个简单规则。首先是归一化:对任意 x ~ \tilde{\mathbf{x}} x~,有: ∫ exp ( η ⊤ x ~ − ψ ( η ) − λ ( x ~ ) ) p ( η ) d η = 1 \int \exp(\boldsymbol{\eta}^\top \tilde{\mathbf{x}} - \psi(\boldsymbol{\eta}) - \lambda(\tilde{\mathbf{x}})) p(\boldsymbol{\eta}) \, \mathrm{d}\boldsymbol{\eta} = 1 ∫exp(η⊤x~−ψ(η)−λ(x~))p(η)dη=1对该恒等式关于 x ~ \tilde{\mathbf{x}} x~ 求导,会从指数项中引出 η \boldsymbol{\eta} η 的幂次以及 λ ( x ~ ) λ(\tilde{\mathbf{x}}) λ(x~) 的导数;令结果为零,即可得到 λ λ λ 的导数与 η \boldsymbol{\eta} η 的后验矩之间的等式关系。其次是指数族的标准性质:对数配分函数是充分统计量的累积量生成函数。因此有: ∇ x ~ λ ( x ~ ) = E η ∣ x \~ , ∇ x ~ 2 λ ( x ~ ) = C o v η ∣ x \~ , ∇ x ~ ( k ) λ ( x ~ ) = κ k ( η ∣ x ~ ) ( k ≥ 3 ) \nabla_{\tilde{\mathbf{x}}} \lambda(\tilde{\mathbf{x}}) = \mathbb{E}\\boldsymbol{\\eta}\|\\tilde{\\mathbf{x}}, \quad \nabla_{\tilde{\mathbf{x}}}^2 \lambda(\tilde{\mathbf{x}}) = \mathrm{Cov}\\boldsymbol{\\eta}\|\\tilde{\\mathbf{x}}, \quad \nabla_{\tilde{\mathbf{x}}}^{(k)} \lambda(\tilde{\mathbf{x}}) = \kappa_k(\boldsymbol{\eta}|\tilde{\mathbf{x}}) \quad (k \geq 3) ∇x~λ(x~)=Eη∣x\~,∇x~2λ(x~)=Covη∣x\~,∇x~(k)λ(x~)=κk(η∣x~)(k≥3)其中 κ k \kappa_k κk 是给定 x ~ \tilde{\mathbf{x}} x~ 时随机向量 η \boldsymbol{\eta} η 的 k k k 阶条件累积量,可通过标准的矩 - 累积量关系得到。
这些就是高阶特威迪公式。将其特例化到 η = x / σ 2 \boldsymbol{\eta} = \mathbf{x}/\sigma^2 η=x/σ2 的高斯位置模型,可得到以 log p σ ( x ~ ) \log p_\sigma(\tilde{\mathbf{x}}) logpσ(x~) 的导数表示的常见形式: E x ∣ x \~ = x ~ + σ 2 ∇ x ~ log p σ ( x ~ ) , C o v x ∣ x \~ = σ 2 I + σ 4 ∇ x ~ 2 log p σ ( x ~ ) \mathbb{E}\\mathbf{x}\|\\tilde{\\mathbf{x}} = \tilde{\mathbf{x}} + \sigma^2 \nabla_{\tilde{\mathbf{x}}} \log p_\sigma(\tilde{\mathbf{x}}), \quad \quad \mathrm{Cov}\\mathbf{x}\|\\tilde{\\mathbf{x}} = \sigma^2 \mathbf{I} + \sigma^4 \nabla_{\tilde{\mathbf{x}}}^2 \log p_\sigma(\tilde{\mathbf{x}}) Ex∣x\~=x~+σ2∇x~logpσ(x~),Covx∣x\~=σ2I+σ4∇x~2logpσ(x~)且更高阶累积量与 log p σ ( x ~ ) \log p_\sigma(\tilde{\mathbf{x}}) logpσ(x~) 的更高阶导数成比例。
已有多项研究探索了训练神经网络来估计高阶得分(Meng et al., 2021a; Lu et al., 2022a; Lai et al., 2023a)。相比之下,本文的目标是阐明它们与统计量之间的关系,方法学细节请读者参考上述文献。
3.3.5 (可选)DSM 去噪原理:SURE(Why DSM is Denoising: SURE)
SURE(斯坦因无偏风险估计器)。 概括而言,斯坦因无偏风险估计器(Stein's Unbiased Risk Estimator, 简称 SURE)是一种无需知晓干净信号即可估计去噪器 D \mathbf{D} D 的均方误差(Mean Squared Error, MSE)的技术。换言之,当仅能获得含噪数据时,SURE 为去噪器的选择或训练提供了一种可行途径。
为清晰起见,我们考虑加性高斯噪声设定: x ~ = x + σ ϵ , ϵ ∼ N ( 0 , I ) \tilde{\mathbf{x}} = \mathbf{x} + \sigma \boldsymbol{\epsilon}, \quad \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) x~=x+σϵ,ϵ∼N(0,I)其中 x ∈ R D \mathbf{x} \in \mathbb{R}^D x∈RD 为未知的干净信号, x ~ \tilde{\mathbf{x}} x~ 为观测到的含噪版本。去噪器指任意(弱可微的)映射 D : R D → R D \mathbf{D}: \mathbb{R}^D \to \mathbb{R}^D D:RD→RD,其输出为 x \mathbf{x} x 的估计值 D ( x ~ ) \mathbf{D}(\tilde{\mathbf{x}}) D(x~)。
衡量去噪器性能的自然指标为条件均方误差(conditional MSE): R ( D ; x ) : = E x ~ ∣ x ∥ D ( x \~ ) − x ∥ 2 2 ∣ x R(\mathbf{D}; \mathbf{x}) := \mathbb{E}{\tilde{\mathbf{x}}|\mathbf{x}} \left \\\|\\mathbf{D}(\\tilde{\\mathbf{x}}) - \\mathbf{x}\\\|_2\^2 \\mid \\mathbf{x} \\right R(D;x):=Ex~∣x∥D(x\~)−x∥22∣x该量依赖于未知的真实信号 x \mathbf{x} x,因此无法直接计算。然而,斯坦因恒等式(参见附录 D.2.4)给出了如下可观测的替代量: SURE ( D ; x ~ ) = ∥ D ( x ~ ) − x ~ ∥ 2 2 + 2 σ 2 ∇ x ~ ⋅ D ( x ~ ) − D σ 2 , (3.3.7) \text{SURE}(\mathbf{D}; \tilde{\mathbf{x}}) = \|\mathbf{D}(\tilde{\mathbf{x}}) - \tilde{\mathbf{x}}\|2^2 + 2\sigma^2 \nabla{\tilde{\mathbf{x}}} \cdot \mathbf{D}(\tilde{\mathbf{x}}) - D\sigma^2, \tag{3.3.7} SURE(D;x~)=∥D(x~)−x~∥22+2σ2∇x~⋅D(x~)−Dσ2,(3.3.7)其中 ∇ x ~ ⋅ D \nabla{\tilde{\mathbf{x}}} \cdot \mathbf{D} ∇x~⋅D 表示 D \mathbf{D} D 的散度。需要强调的是, SURE ( D ; x ~ ) \text{SURE}(\mathbf{D};\tilde{\mathbf{x}}) SURE(D;x~) 的计算仅需含噪观测 x ~ \tilde{\mathbf{x}} x~,而无需干净信号 x \mathbf{x} x。
直观来看, SURE \text{SURE} SURE 由两个相互补充的部分构成。项 ∥ D ( x ~ ) − x ~ ∥ 2 \|\mathbf{D}(\tilde{\mathbf{x}}) - \tilde{\mathbf{x}}\|^2 ∥D(x~)−x~∥2 衡量了去噪器的输出与含噪输入之间的距离;由于 x ~ \tilde{\mathbf{x}} x~ 本身已被噪声污染,仅用该项会低估真实误差。散度项 则起到校正作用:它刻画了去噪器对输入微小扰动的敏感度,有效补偿了噪声引入的方差。
重要的是,对于任意固定但未知的 x \mathbf{x} x,有: E x ~ ∣ x SURE ( D ; x + σ ϵ ) ∣ x = R ( D ; x ) \mathbb{E}{\tilde{\mathbf{x}}|\mathbf{x}} \left \\text{SURE}(\\mathbf{D}; \\mathbf{x} + \\sigma \\boldsymbol{\\epsilon}) \\mid \\mathbf{x} \\right = R(\mathbf{D}; \mathbf{x}) Ex~∣xSURE(D;x+σϵ)∣x=R(D;x)其中期望是对高斯噪声 ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) ϵ∼N(0,I) 取的。因此,最小化 SURE \text{SURE} SURE(在期望意义下或经验上)等价于最小化真实均方误差,且整个过程仅依赖含噪数据。在实际应用中,对 x ∼ p data \mathbf{x} \sim p{\text{data}} x∼pdata 与污染噪声 ϵ \boldsymbol{\epsilon} ϵ 同时取 SURE \text{SURE} SURE 的平均,可得到全局均方误差风险的无偏估计。
与 Tweedie 公式及贝叶斯最优性的联系。 记 p σ ( x ~ ) = ( p data ∗ N ( 0 , σ 2 I ) ) ( x ~ ) p_\sigma(\tilde{\mathbf{x}}) = (p_{\text{data}} * \mathcal{N}(\mathbf{0}, \sigma^2\mathbf{I}))(\tilde{\mathbf{x}}) pσ(x~)=(pdata∗N(0,σ2I))(x~) 为本节所讨论的含噪边缘分布。
SURE \text{SURE} SURE 是在给定 x \mathbf{x} x 的条件下,关于噪声的均方误差的无偏估计器: E x ~ ∣ x SURE ( D ; x \~ ) = E x ~ ∣ x ∥ D ( x \~ ) − x ∥ 2 \mathbb{E}{\tilde{\mathbf{x}}|\mathbf{x}}\\text{SURE}(\\mathbf{D}; \\tilde{\\mathbf{x}}) = \mathbb{E}{\tilde{\mathbf{x}}|\mathbf{x}}\\\|\\mathbf{D}(\\tilde{\\mathbf{x}}) - \\mathbf{x}\\\|\^2 Ex~∣xSURE(D;x\~)=Ex~∣x∥D(x\~)−x∥2因此,根据全期望定律(塔性质),最小化期望 SURE \text{SURE} SURE 等价于最小化贝叶斯风险 E ( x , x ~ ) ∥ D ( x \~ ) − x ∥ 2 = E x ~ E x ∣ x \~ \[ ∥ D ( x \~ ) − x ∥ 2 ] \mathbb{E}{(\mathbf{x},\tilde{\mathbf{x}})}\\\|\\mathbf{D}(\\tilde{\\mathbf{x}}) - \\mathbf{x}\\\|\^2 = \mathbb{E}{\tilde{\mathbf{x}}}\\mathbb{E}_{\\mathbf{x}\|\\tilde{\\mathbf{x}}}\[\\\|\\mathbf{D}(\\tilde{\\mathbf{x}}) - \\mathbf{x}\\\|\^2] E(x,x~)∥D(x\~)−x∥2=Ex~Ex∣x\~\[∥D(x\~)−x∥2]。该分解可导出逐点优化问题:对几乎所有 x ~ \tilde{\mathbf{x}} x~ , D ∗ ( x ~ ) = arg min z E x ∣ x ~ ∥ z − x ∥ 2 = E x ∣ x \~ \mathbf{D}^*(\tilde{\mathbf{x}}) = \arg\min_{\mathbf{z}} \mathbb{E}{\mathbf{x}|\tilde{\mathbf{x}}}\\\|\\mathbf{z} - \\mathbf{x}\\\|\^2 = \mathbb{E}\\mathbf{x}\|\\tilde{\\mathbf{x}} D∗(x~)=argzminEx∣x~∥z−x∥2=Ex∣x\~因此, SURE \text{SURE} SURE 最优去噪器与 3.3.4 节中的贝叶斯估计器完全一致,且由 Tweedie 恒等式可得: D ∗ ( x ~ ) = E x ∣ x \~ = x ~ + σ 2 ∇ x ~ log p σ ( x ~ ) . (3.3.8) \mathbf{D}^*(\tilde{\mathbf{x}}) = \mathbb{E}\\mathbf{x}\|\\tilde{\\mathbf{x}} = \tilde{\mathbf{x}} + \sigma^2 \nabla{\tilde{\mathbf{x}}} \log p_\sigma(\tilde{\mathbf{x}}). \tag{3.3.8} D∗(x~)=Ex∣x\~=x~+σ2∇x~logpσ(x~).(3.3.8)
Stein 的无偏风险估计(SURE)与贝叶斯最优估计(后验均值)是等价的,并且它们都可以通过 Tweedie 公式统一表达。
(1)SURE 让我们可以在不知道真实 x \mathbf{x} x 的情况下,用带噪数据 x ~ \tilde{\mathbf{x}} x~ 去估计并最小化均方误差;
(2)最小化 SURE 等价于最小化贝叶斯风险;
(3)贝叶斯风险的最小化器是后验均值 E x ∣ x \~ \mathbb{E}\\mathbf{x}\|\\tilde{\\mathbf{x}} Ex∣x\~;
(4)Tweedie 公式把后验均值表达为 x ~ + σ 2 ∇ x ~ log p σ ( x ~ ) \tilde{\mathbf{x}} + \sigma^2 \nabla_{\tilde{\mathbf{x}}} \log p_\sigma(\tilde{\mathbf{x}}) x~+σ2∇x~logpσ(x~);
SURE \text{SURE} SURE 与得分匹配的关系。 式 (3.3.8) 中的恒等式启发我们通过得分场对去噪器 D \mathbf{D} D 进行参数化: D ( x ~ ) = x ~ + σ 2 s ϕ ( x ~ ; σ ) , \mathbf{D}(\tilde{\mathbf{x}}) = \tilde{\mathbf{x}} + \sigma^2 \mathbf{s}\phi(\tilde{\mathbf{x}}; \sigma), D(x~)=x~+σ2sϕ(x~;σ),其中 s ϕ ( ⋅ ; σ ) \mathbf{s}\phi(⋅;σ) sϕ(⋅;σ) 用于近似含噪得分 ∇ x ~ log p σ ( ⋅ ) \nabla_{\tilde{\mathbf{x}}} \log p_\sigma(\cdot) ∇x~logpσ(⋅)。将 D ( x ~ ) = x ~ + σ 2 s ϕ ( x ~ ; σ ) \mathbf{D}(\tilde{\mathbf{x}}) = \tilde{\mathbf{x}} + \sigma^2 \mathbf{s}\phi(\tilde{\mathbf{x}}; \sigma) D(x~)=x~+σ2sϕ(x~;σ) 代入式 (3.3.7),可得: 1 2 σ 4 SURE ( D ; x ~ ) = T r ( ∇ x ~ s ϕ ( x ~ ; σ ) ) + 1 2 ∥ s ϕ ( x ~ ; σ ) ∥ 2 2 + c o n s t ( σ ) . \frac{1}{2\sigma^4} \text{SURE}(\mathbf{D}; \tilde{\mathbf{x}}) = \mathrm{Tr}\left(\nabla{\tilde{\mathbf{x}}} \mathbf{s}\phi(\tilde{\mathbf{x}}; \sigma)\right) + \frac{1}{2} \left\|\mathbf{s}\phi(\tilde{\mathbf{x}}; \sigma)\right\|2^2 + \mathrm{const}(\sigma). 2σ41SURE(D;x~)=Tr(∇x~sϕ(x~;σ))+21∥sϕ(x~;σ)∥22+const(σ).因此,对 x ~ ∼ p σ \tilde{\mathbf{x}} \sim p\sigma x~∼pσ 取期望后,最小化 SURE \text{SURE} SURE(在附加常数意义下)等价于最小化噪声水平 σ σ σ 下的 Hyvärinen 替代得分匹配目标函数,且该期望在 p σ p_σ pσ 下计算(参见式 (3.2.2))。由此可知,两个目标函数具有相同的极小值点,即式 (3.3.8) 所给出的去噪器。
3.3.6 (可选)广义分数匹配(Generalized Score Matching)
动机。 经典得分匹配、去噪得分匹配及其高阶变体,其目标均为针对某一密度 p p p,估计 L p ( x ) p ( x ) \frac{\mathcal{L} p(\mathbf{x})}{p(\mathbf{x})} p(x)Lp(x)。其中 L \mathcal{L} L 为作用于密度的线性算子。在经典情形下,取 L = ∇ x \mathcal{L}=∇\mathbf{x} L=∇x,则有: ∇ x log p ( x ) = ∇ x p ( x ) p ( x ) \nabla{\mathbf{x}} \log p(\mathbf{x}) = \frac{\nabla_{\mathbf{x}} p(\mathbf{x})}{p(\mathbf{x})} ∇xlogp(x)=p(x)∇xp(x)这种 L p p \frac{\mathcal{L} p}{p} pLp 的结构可通过分部积分消去归一化常数,从而得到仅依赖于 p p p 的样本与学习到的场 s ϕ \mathbf{s}_ϕ sϕ 的可处理目标函数。这一视角为广义得分匹配框架提供了理论动机。
广义 Fisher 散度。 设 p p p 为数据分布, q q q 为任意模型分布。针对作用于 x \mathbf{x} x 标量函数的线性算子 L \mathcal{L} L,定义广义 Fisher 散度为: D L ( p ∥ q ) : = ∫ p ( x ) ∥ L p ( x ) p ( x ) − L q ( x ) q ( x ) ∥ 2 2 d x ~ . \mathcal{D}{\mathcal{L}}(p \parallel q) := \int p(\mathbf{x}) \left\| \frac{\mathcal{L} p(\mathbf{x})}{p(\mathbf{x})} - \frac{\mathcal{L} q(\mathbf{x})}{q(\mathbf{x})} \right\|2^2 \, \mathrm{d}\tilde{\mathbf{x}}. DL(p∥q):=∫p(x) p(x)Lp(x)−q(x)Lq(x) 22dx~.若 L \mathcal{L} L 满足完备性(complete),即 L p 1 p 1 = L p 2 p 2 a.e. 则 p 1 = p 2 a.e. \frac{\mathcal{L} p_1}{p_1} = \frac{\mathcal{L} p_2}{p_2} \text{ a.e.} \quad \text{则} \quad p_1 = p_2 \text{ a.e.} p1Lp1=p2Lp2 a.e.则p1=p2 a.e.则 D L ( p ∥ q ) = 0 \mathcal{D}{\mathcal{L}}(p \parallel q)=0 DL(p∥q)=0 可唯一确定 q = p q=p q=p。当取 L = ∇ x ~ \mathcal{L} = \nabla{\tilde{\mathbf{x}}} L=∇x~ 时,该定义退化为经典 Fisher 散度(参见公式 (1.1.3))。
得分参数化。 在实际应用中,我们并不对归一化密度 q q q 进行建模。相反,我们直接参数化向量场 s ϕ ( x ) \mathbf{s}ϕ(\mathbf{x}) sϕ(x),以近似广义得分 L p ( x ) p ( x ) \frac{\mathcal{L} p(\mathbf{x})}{p(\mathbf{x})} p(x)Lp(x)。考虑如下目标: D L ( p ∥ s ϕ ) : = E x ∼ p ∥ s ϕ ( x ) − L p ( x ) p ( x ) ∥ 2 2 . \mathcal{D}{\mathcal{L}}(p \parallel \mathbf{s}\phi) := \mathbb{E}{\mathbf{x} \sim p} \left \\left\\\| \\mathbf{s}_\\phi(\\mathbf{x}) - \\frac{\\mathcal{L} p(\\mathbf{x})}{p(\\mathbf{x})} \\right\\\|_2\^2 \\right. DL(p∥sϕ):=Ex∼p sϕ(x)−p(x)Lp(x) 22.尽管 L p ( x ) p ( x ) \frac{\mathcal{L} p(\mathbf{x})}{p(\mathbf{x})} p(x)Lp(x) 是未知的,但 "分部积分" 技巧可使损失函数仅依赖于 s ϕ \mathbf{s}ϕ sϕ。设 L † \mathcal{L}^† L† 为 L \mathcal{L} L 的伴随算子,其定义为: ∫ ( L f ) ⊤ g = ∫ f ( L † g ) for all test functions f , g \int (\mathcal{L} f)^\top g = \int f (\mathcal{L}^\dagger g) \quad \text{for all test functions } f, g ∫(Lf)⊤g=∫f(L†g)for all test functions f,g在边界项消失的情况下,该恒等式从形式上实现了将算子 L \mathcal{L} L "移动" 至积分号的另一侧。展开平方项并应用该恒等式,即可得到可计算的目标函数: L GSM ( ϕ ) = E x ∼ p 1 2 ∥ s ϕ ( x ) ∥ 2 2 − ( L † s ϕ ) ( x ) + const , \mathcal{L}{\text{GSM}}(\phi) = \mathbb{E}_{\mathbf{x} \sim p} \left \\frac{1}{2} \\\|\\mathbf{s}_\\phi(\\mathbf{x})\\\|_2\^2 - (\\mathcal{L}\^\\dagger \\mathbf{s}_\\phi)(\\mathbf{x}) \\right + \text{const}, LGSM(ϕ)=Ex∼p21∥sϕ(x)∥22−(L†sϕ)(x)+const,其中常数项与参数 ϕ ϕ ϕ 无关。我们仅通过期望来使用分布 p p p,因此广义得分匹配损失可由训练数据得到经验估计,这与经典得分匹配的情形完全一致。
当取 L = ∇ \mathcal{L} = \nabla L=∇ 时,其伴随算子为 L † = − ∇ ⋅ \mathcal{L}^\dagger = -\nabla \cdot L†=−∇⋅,由此可还原出式 (3.2.2) 中 Hyvärinen 得分匹配的目标函数 E p 1 2 ∥ s ϕ ∥ 2 2 + ∇ ⋅ s ϕ \mathbb{E}_p\left\\frac{1}{2}\\\|\\mathbf{s}_\\phi\\\|_2\^2 + \\nabla \\cdot \\mathbf{s}_\\phi\\right Ep21∥sϕ∥22+∇⋅sϕ。
广义得分匹配通过分部积分技巧 ,将不可计算的损失转化为只依赖于数据和候选场及其导数的可计算损失,从而让我们能够从样本中学习任意线性微分算子作用在密度上的广义得分。经典得分匹配(学习 ∇ log p ∇\text{log} p ∇logp)是它的一个特例。
算子示例。
1. 经典得分匹配。 考虑线性算子 L = ∇ x \mathcal{L}=∇\mathbf{x} L=∇x,则广义得分退化为经典得分函数: L p ( x ) p ( x ) = ∇ x log p ( x ) \frac{\mathcal{L} p(\mathbf{x})}{p(\mathbf{x})} = \nabla{\mathbf{x}} \log p(\mathbf{x}) p(x)Lp(x)=∇xlogp(x)
2. 去噪得分匹配。 针对加性高斯噪声设定,定义如下算子: ( L f ) ( x ~ ) = x ~ f ( x ~ ) + σ 2 ∇ x ~ f ( x ~ ) (\mathcal{L} f)(\tilde{\mathbf{x}}) = \tilde{\mathbf{x}} f(\tilde{\mathbf{x}}) + \sigma^2 \nabla_{\tilde{\mathbf{x}}} f(\tilde{\mathbf{x}}) (Lf)(x~)=x~f(x~)+σ2∇x~f(x~)于是有 L p σ ( x ~ ) p σ ( x ~ ) = x ~ + σ 2 ∇ x ~ log p σ ( x ~ ) = E x 0 ∣ x \~ \frac{\mathcal{L} p_\sigma(\tilde{\mathbf{x}})}{p_\sigma(\tilde{\mathbf{x}})} = \tilde{\mathbf{x}} + \sigma^2 \nabla_{\tilde{\mathbf{x}}} \log p_\sigma(\tilde{\mathbf{x}}) = \mathbb{E}\\mathbf{x}_0\|\\tilde{\\mathbf{x}} pσ(x~)Lpσ(x~)=x~+σ2∇x~logpσ(x~)=Ex0∣x\~其中, p σ ( x ~ ) : = ∫ N ( x ~ ; α x 0 , σ 2 I ) p data ( x ) d x p_\sigma(\tilde{\mathbf{x}}) := \int \mathcal{N}(\tilde{\mathbf{x}}; \alpha \mathbf{x}0, \sigma^2 \mathbf{I}) p{\text{data}}(\mathbf{x}) \, \mathrm{d}\mathbf{x} pσ(x~):=∫N(x~;αx0,σ2I)pdata(x)dx 且 x ~ = x + σ ϵ \tilde{\mathbf{x}} = \mathbf{x} + \sigma \boldsymbol{\epsilon} x~=x+σϵ. 上式正是 Tweedie 恒等式。利用该算子最小化广义得分匹配损失 L GSM \mathcal{L}_{\text{GSM}} LGSM,可训练模型 s ϕ \mathbf{s}_ϕ sϕ 以逼近去噪器,从而还原出去噪得分匹配目标。
3. 高阶目标。 在算子 L \mathcal{L} L 中堆叠导数项,可得到 ∇ 2 log p ∇^2\text{log}p ∇2logp 及更高阶导数,它们与后验协方差和更高阶累积量相对应。

扩展与应用场景。 广义得分匹配(Generalized Score Matching)的应用范围不仅限于连续变量,还可扩展至离散场景,包括语言建模等领域(Meng et al., 2022; Lou et al., 2024)。该框架同样为受得分思想启发的训练方法提供了理论动机,可导出去噪风格的损失目标。这种基于算子的视角统一了多种目标函数,使其能够从数据中进行经验估计,并为通过适当选择线性算子 L \mathcal{L} L 来设计损失函数提供了通用原则。
3.4 多噪声级去噪评分匹配(Multi-Noise Levels of Denoising Score Matching (NCSN))
3.4.1 动机(Motivation)
向数据分布中添加单一固定方差的高斯噪声,可在一定程度上对分布进行平滑,但仅在单一噪声水平上训练基于得分的模型会带来关键局限性:
(1)在注入噪声水平较低时,由于低密度区域的梯度消失,朗之万动力学难以遍历多峰分布中的各个模态;
(2)与之相对,在高噪声水平下,采样过程会变得更简单,但模型仅能捕捉到粗粒度结构,最终生成的样本会出现模糊、缺乏精细细节的问题;
(3)此外,朗之万动力学在高维空间中可能收敛缓慢,甚至完全失效。由于其依赖对数密度的梯度提供引导,不佳的初始化(尤其是在平台区域或鞍点附近)会阻碍采样过程的探索,或导致采样器陷入单一模态而无法跳出;
**Figure 3.6 | 得分匹配误差示意图(重访图 3.4):**红色区域表示低密度区域,由于样本覆盖有限,该区域的得分估计可能存在误差;而高密度区域通常能得到更准确的估计;
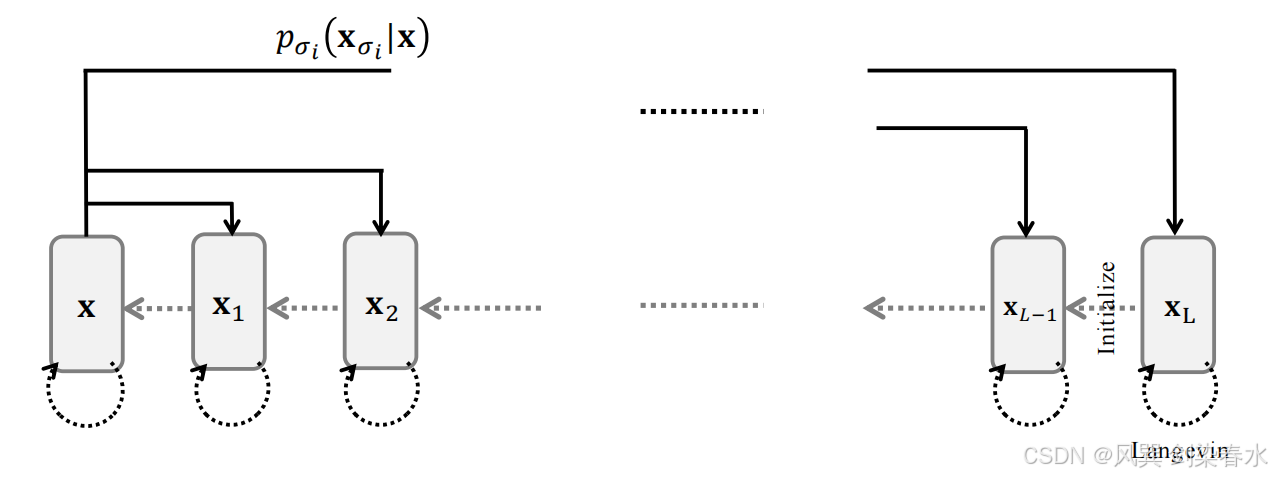
为解决上述挑战,Song 与 Ermon(2019)提出向数据分布中注入多尺度高斯噪声,并联合训练噪声条件得分网络(NCSN),以估计一系列噪声尺度下的得分函数。在生成阶段,采用 噪声退火(noise-annealed) 的朗之万动力学:从高噪声水平开始,实现对分布的粗粒度探索,再逐步向低噪声水平细化,以恢复精细细节。
**Figure 3.7 | NCSN 示意图:**前向过程通过多尺度加性高斯噪声 p σ ( x σ ∣ x ) p_\sigma(\mathbf{x}_\sigma|\mathbf{x}) pσ(xσ∣x) 对数据进行扰动。生成过程通过在每个噪声水平执行朗之万采样实现,将当前噪声水平的采样结果作为下一个更低方差水平的采样初始化;
3.4.2 训练(Training)
为克服单噪声水平训练的基于得分模型的局限性,Song 与 Ermon(2019)提出向数据分布中添加多尺度高斯噪声。具体而言,选取长度为 L L L 的噪声水平序列 { σ i } i = 1 L \{\sigma_i\}_{i=1}^L {σi}i=1L,满足 0 < σ 1 < σ 2 < ⋯ < σ L 0 < \sigma_1 < \sigma_2 < \dots < \sigma_L 0<σ1<σ2<⋯<σL其中 σ 1 σ_1 σ1 足够小以保留数据的大部分精细细节, σ L σ_L σL 足够大以充分平滑分布,从而简化训练难度。
每个含噪样本由对干净数据点 x ∼ p d a t a \mathbf{x}∼p_{data} x∼pdata 进行扰动构造: x σ = x + σ ϵ \mathbf{x}_\sigma = \mathbf{x} + \sigma \boldsymbol{\epsilon} xσ=x+σϵ,其中 ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0},\mathbf{I}) ϵ∼N(0,I)。由此定义:
扰动核(Perturbation Kernel): p σ ( x σ ∣ x ) : = N ( x σ ; x , σ 2 I ) p_\sigma(\mathbf{x}\sigma|\mathbf{x}) := \mathcal{N}(\mathbf{x}\sigma; \mathbf{x}, \sigma^2\mathbf{I}) pσ(xσ∣x):=N(xσ;x,σ2I)该核在每个噪声水平 σ σ σ 下引出
边缘分布(Marginal Distribution): p σ ( x σ ) = ∫ p σ ( x σ ∣ x ) p data ( x ) d x p_\sigma(\mathbf{x}\sigma) = \int p\sigma(\mathbf{x}\sigma|\mathbf{x}) p{\text{data}}(\mathbf{x}) \, \mathrm{d}\mathbf{x} pσ(xσ)=∫pσ(xσ∣x)pdata(x)dx即经高斯平滑后的数据分布。
NCSN 的训练目标。 目标是训练噪声条件得分网络 s ϕ ( x , σ ) \mathbf{s}\phi(\mathbf{x}, \sigma) sϕ(x,σ),以对所有 σ ∈ { σ i } i = 1 L σ∈\{\sigma_i\}{i=1}^L σ∈{σi}i=1L 估计得分函数 ∇ x log p σ ( x ) \nabla_{\mathbf{x}} \log p_\sigma(\mathbf{x}) ∇xlogpσ(x)。这一目标通过在所有噪声水平上最小化去噪得分匹配(DSM)损失实现: L NCSN ( ϕ ) : = ∑ i = 1 L λ ( σ i ) L DSM ( ϕ ; σ i ) , (3.4.1) \mathcal{L}{\text{NCSN}}(\phi) := \sum{i=1}^L \lambda(\sigma_i) \mathcal{L}{\text{DSM}}(\phi; \sigma_i), \tag{3.4.1} LNCSN(ϕ):=i=1∑Lλ(σi)LDSM(ϕ;σi),(3.4.1)其中 L DSM ( ϕ ; σ ) = 1 2 E x ∼ p data ( x ) , x ~ ∼ p σ ( x ~ ∣ x ) ∥ s ϕ ( x \~ , σ ) − ( x − x \~ σ 2 ) ∥ 2 2 \mathcal{L}{\text{DSM}}(\phi; \sigma) = \frac{1}{2} \mathbb{E}{\mathbf{x} \sim p{\text{data}}(\mathbf{x}), \tilde{\mathbf{x}} \sim p_\sigma(\tilde{\mathbf{x}}|\mathbf{x})} \left \\left\\\| \\mathbf{s}_\\phi(\\tilde{\\mathbf{x}}, \\sigma) - \\left( \\frac{\\mathbf{x} - \\tilde{\\mathbf{x}}}{\\sigma\^2} \\right) \\right\\\|_2\^2 \\right LDSM(ϕ;σ)=21Ex∼pdata(x),x~∼pσ(x~∣x) sϕ(x\~,σ)−(σ2x−x\~) 22且 λ ( σ i ) > 0 \lambda(\sigma_i) > 0 λ(σi)>0 为各尺度的加权函数。
最小化该目标可得到得分模型 s ∗ ( x , σ ) \mathbf{s}^*(\mathbf{x}, \sigma) s∗(x,σ),该模型能在每个噪声水平上还原真实得分: s ∗ ( ⋅ , σ ) = ∇ x log p σ ( ⋅ ) , for all σ ∈ { σ i } i = 1 L \mathbf{s}^*(\cdot, \sigma) = \nabla_{\mathbf{x}} \log p_\sigma(\cdot), \quad \text{for all } \sigma \in \{\sigma_i\}_{i=1}^L s∗(⋅,σ)=∇xlogpσ(⋅),for all σ∈{σi}i=1L其本质为 DSM 最小化(参见定理 3.3.1)。
与 DDPM 损失的关系。 设 x σ = x + σ ϵ \mathbf{x}\sigma = \mathbf{x} + \sigma \boldsymbol{\epsilon} xσ=x+σϵ,其中 ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) ϵ∼N(0,I),并记 p σ p_σ pσ 为边缘分布。根据 Tweedie 公式,有 ∇ x σ log p σ ( x σ ) = − 1 σ E ϵ ∣ x σ \nabla{\mathbf{x}\sigma} \log p\sigma(\mathbf{x}\sigma) = -\frac{1}{\sigma} \mathbb{E}\\boldsymbol{\\epsilon} \| \\mathbf{x}_\\sigma ∇xσlogpσ(xσ)=−σ1Eϵ∣xσ因此,NCSN 的最优解为真实得分 s ∗ ( x σ , σ ) = ∇ x σ log p σ ( x σ ) \mathbf{s}^*(\mathbf{x}\sigma, \sigma) = \nabla_{\mathbf{x}\sigma} \log p\sigma(\mathbf{x}\sigma) s∗(xσ,σ)=∇xσlogpσ(xσ),而 DDPM 损失公式 (2.2.10) 下的贝叶斯最优噪声预测器为 ϵ ∗ ( x σ , σ ) = E ϵ ∣ x σ \boldsymbol{\epsilon}^*(\mathbf{x}\sigma, \sigma) = \mathbb{E}\\boldsymbol{\\epsilon} \| \\mathbf{x}_\\sigma ϵ∗(xσ,σ)=Eϵ∣xσ。二者通过以下关系完全等价: s ∗ ( x σ , σ ) = − 1 σ ϵ ∗ ( x σ , σ ) , ϵ ∗ ( x σ , σ ) = − σ s ∗ ( x σ , σ ) \mathbf{s}^*(\mathbf{x}\sigma, \sigma) = -\frac{1}{\sigma} \boldsymbol{\epsilon}^*(\mathbf{x}\sigma, \sigma), \quad \boldsymbol{\epsilon}^*(\mathbf{x}\sigma, \sigma) = -\sigma \mathbf{s}^*(\mathbf{x}\sigma, \sigma) s∗(xσ,σ)=−σ1ϵ∗(xσ,σ),ϵ∗(xσ,σ)=−σs∗(xσ,σ)在带有离散索引 i i i 的 DDPM 扰动公式 (2.2.9)
x i = α ˉ i x 0 + 1 − α ˉ i 2 ϵ \mathbf{x}_i = \bar{\alpha}_i \mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_i^2}\boldsymbol{\epsilon} xi=αˉix0+1−αˉi2 ϵ中,同样的关系可给出 s ∗ ( x i , i ) = − 1 σ i E ϵ ∣ x i \mathbf{s}^*(\mathbf{x}_i, i) = -\frac{1}{\sigma_i} \mathbb{E}\\boldsymbol{\\epsilon} \| \\mathbf{x}_i s∗(xi,i)=−σi1Eϵ∣xi因此最小化公式 (2.2.10) 可学习出关于 ϵ \boldsymbol{\epsilon} ϵ 的条件去噪器,这是噪声水平 i i i 下真实得分的一种缩放重参数化形式。
我们将在第 6 章系统比较并总结这种参数化等价性。
DDPM 的噪声预测器与 NCSN 的得分函数只差一个负号和噪声标准差的倒数,两者通过 Tweedie 公式等价。因此,训练一个噪声预测网络,就等于在训练一个经过缩放的得分网络。
3.4.3 采样(Sampling)
在获得多个噪声水平下训练好的得分网络 s ϕ × ( ⋅ , σ 1 ) , s ϕ × ( ⋅ , σ 2 ) , ... , s ϕ × ( ⋅ , σ L − 1 ) , s ϕ × ( ⋅ , σ L ) \mathbf{s}{\phi^\times}(\cdot, \sigma_1), \quad \mathbf{s}{\phi^\times}(\cdot, \sigma_2), \quad \dots,\quad \mathbf{s}{\phi^\times}(\cdot, \sigma{L-1}),\quad \mathbf{s}_{\phi^\times}(\cdot, \sigma_L) sϕ×(⋅,σ1),sϕ×(⋅,σ2),...,sϕ×(⋅,σL−1),sϕ×(⋅,σL)后,采用退火朗之万动力学采样过程通过从高噪声水平 σ L σ_L σL 向低噪声水平 σ 1 ≈ 0 σ_1≈0 σ1≈0 逐步去噪来生成数据。
从高斯噪声 x σ L ∼ N ( 0 , I ) \mathbf{x}^{\sigma_L} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) xσL∼N(0,I) 开始,该算法在每个噪声水平 σ ℓ σ_ℓ σℓ 应用朗之万动力学,以近似从扰动分布 p σ ℓ ( x ) p_{\sigma_\ell}(\mathbf{x}) pσℓ(x) 中采样。将水平 σ ℓ σ_ℓ σℓ 处的输出作为下一个更低噪声水平 σ ℓ − 1 σ_{ℓ−1} σℓ−1 处更好的初始化。
在每个水平,朗之万动力学执行如下迭代更新: x ~ n + 1 = x ~ n + η ℓ s ϕ × ( x ~ n , σ ℓ ) + 2 η ℓ ϵ n , ϵ n ∼ N ( 0 , I ) \tilde{\mathbf{x}}{n+1} = \tilde{\mathbf{x}}n + \eta\ell \mathbf{s}{\phi^\times}(\tilde{\mathbf{x}}n, \sigma\ell) + \sqrt{2\eta_\ell} \boldsymbol{\epsilon}_n, \quad \boldsymbol{\epsilon}n \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) x~n+1=x~n+ηℓsϕ×(x~n,σℓ)+2ηℓ ϵn,ϵn∼N(0,I)从 x ~ 0 : = x σ ℓ \tilde{\mathbf{x}}0:=\mathbf{x}^{σ_ℓ} x~0:=xσℓ 开始。步长通常按噪声水平进行缩放:
η ℓ = δ ⋅ σ ℓ 2 σ 1 2 for some fixed δ > 0. \eta\ell = \delta \cdot \frac{\sigma\ell^2}{\sigma_1^2} \quad \text{for some fixed} \quad δ > 0. ηℓ=δ⋅σ12σℓ2for some fixedδ>0.该噪声退火细化过程一直持续到最低噪声水平 σ 1 σ_1 σ1,并得到最终样本 x σ 1 \mathbf{x}^{σ_1} xσ1。通过将前一水平的输出作为下一水平更好的初始化,该策略实现了更有效的探索,并提升了对复杂数据分布的覆盖度。
算法 1 总结了该过程。

NCSN 的采样速度瓶颈。 NCSN 通过在噪声尺度 { σ i } i = 1 L \{\sigma_i\}{i=1}^L {σi}i=1L 上执行退火 MCMC(通常为朗之万动力学)生成样本。对于每个尺度 σ i σ_i σi,算法执行 K K K 次迭代更新,形式为 "利用得分 s ϕ × ( x ~ n , σ i ) \mathbf{s}{\phi^\times}(\tilde{\mathbf{x}}_n, \sigma_i) sϕ×(x~n,σi) 更新 x ~ n \tilde{\mathbf{x}}_n x~n 并叠加微小随机扰动",每次更新都需要执行一次得分网络的前向传播。有两个因素导致必须采用较大的 L × K L×K L×K:
(i) 局部准确性与稳定性: 学习到的得分仅在微小扰动下可靠,因此每个噪声水平都需要采用小步长和大量迭代,以避免偏差或不稳定性;
(ii) 高维空间中的慢混合: 局部 MCMC 移动在探索多峰、高维目标分布时效率低下,需要大量迭代才能到达典型数据区域;
由于更新过程严格串行(每次迭代依赖于前一次迭代的结果),且每次更新都需要一次高成本的网络评估,整体计算复杂度为 O ( L K ) \mathcal{O}(LK) O(LK) 次串行网络前向传播,导致采样过程在计算上非常缓慢。
3.5 NCSN 与 DDPM 的比较研究(Summary: A Comparative View of NCSN and DDPM)
对比。 我们首先在图 3.7 中对比 NCSN 与 DDPM 的图模型,其关键异同总结于表 3.1。
Table 3.1 | NCSN 与 DDPM 的对比:

共同瓶颈。 尽管二者的公式化表述不同,NCSN 与 DDPM 均依赖于密集的时间离散化。这带来了一个关键局限:采样通常需要数百甚至数千次迭代,导致生成过程缓慢且计算开销巨大。
问题 3.5.1
如何加速扩散模型的采样?
我们将在第 9 章和第 10 章重新探讨这一挑战。
3.6 结语(Closing Remarks)
本章描绘了扩散模型的第二条主要路径,其起点是根植于 能量基模型(Energy-Based Models, EBMs) 的基于得分的视角。我们首先识别出 EBMs 的核心挑战 ------ 难以处理的配分函数 ------ 并引入了得分函数 ∇ x log p ( x ) \nabla_{\mathbf{x}} \log p(\mathbf{x}) ∇xlogp(x) 作为一种能够完全规避这一问题的强大工具。
我们的研究历程从经典得分匹配延伸至其扩展性更强、鲁棒性更优的变体 ------去噪得分匹配(Denoising Score Matching, DSM)。通过 DSM,我们阐明了如何利用噪声对数据进行扰动,从而构建出可处理的训练目标;再次利用条件化策略,我们得以创建一个简单的回归任务目标。此外,我们通过 Tweedie 公式建立了得分估计与去噪行为之间的深层联系,该公式揭示了从含噪观测中估计干净信号所需的精确方向。
随后,这一原理从单一噪声尺度推广至连续尺度,形成了噪声条件得分网络(Noise Conditional Score Networks, NCSN)。NCSN 学习一个针对多噪声尺度条件化的单一得分模型,并通过退火朗之万动力学生成样本。在探索的尾声,我们发现:尽管起源不同,但从变分视角出发的 NCSN 与 DDPM 却有着惊人相似的结构,并且共享一个共同的瓶颈:缓慢的、串行的采样过程。
这种收敛并非偶然,它暗示着一个更深层、统一的数学结构。这些离散时间模型的局限性,促使我们需要一个更通用的框架。在下一章中,我们将迈出这关键的一步:
(1)转向连续时间视角: 证明 DDPM 与 NCSN 都可以被优雅地统一为 随机微分方程(Stochastic Differential Equation, SDE) 所描述的单一、强大过程的不同离散化形式。
(2)Score SDE 框架: 该框架将形式化地连接变分视角与基于得分的视角,将生成问题重构为求解微分方程的问题。
这一统一视角不仅将带来深刻的理论清晰度,还将解锁一类全新的先进数值方法,以应对采样缓慢这一根本性挑战。
下一章:【扩散模型原理】(四)Diffusion Models Today: Score SDE Framework