一、什么是聚类
在工程问题中,我们经常会遇到这样一种情况:手里有一批数据,但这些数据没有标签。也就是说,我们知道"它们长什么样",却不知道"它们分别属于哪一类"。
这时候,聚类就是一个非常有用的方法。
聚类(Clustering)是无监督学习中的一类核心方法。它的目标不是像分类那样去预测一个已有类别,而是根据数据之间的相似性,自动把相近的数据划分到同一组中。换句话说,聚类试图做到"类内相似、类间差异大"。
从直观上看,聚类做的事情是:
- 相互接近的数据点,归为同一类;
- 相互差异较大的数据点,分到不同类;
- 最终形成若干个具有内部一致性的"簇"。
例如,在工业场景中:
- 一批振动信号可能自然分成"正常状态""轻微异常""严重故障"几个簇;
- 一批产品测量数据可能分成"合格品""边界品""异常品";
- 一批传感器工作状态可能分成"稳定工况""过渡工况""失稳工况"。
所以,聚类的本质可以理解为:从无标签数据中自动发现隐藏结构。
二、为什么工程应用中需要聚类
很多工程人员第一次接触机器学习时,往往先接触分类和回归,因为这两类问题更直观。但在真实工程现场,很多时候并没有现成的标签,或者标签获取成本很高,这时聚类就很重要。
工程中常见的几个现实问题是:
1. 数据没有标签
例如大量采集到的声学、振动、温度、电流、图像数据,往往只有原始记录,没有"故障类型"或"状态类别"的人工标注。
2. 数据模式复杂,人工难以直接分组
当数据维度高、样本量大时,仅靠经验很难发现其中隐藏的结构关系。
3. 需要先做探索,再做建模
很多工程建模不是一开始就进入监督学习,而是先通过聚类看看数据中是否天然存在几种运行模式,再决定后续是做分类、识别还是预警。
4. 需要进行异常发现
有时目标并不是把每个样本准确分类,而是先找出"和大多数不一样"的那部分数据。聚类常常能作为异常检测的前一步。
因此,在工程上,聚类通常不是"为了聚类而聚类",而是作为一个数据理解、状态划分、模式发现、异常筛查的工具。
三、聚类的核心思想
聚类要成立,首先要解决一个问题:什么叫"相似"?
通常,聚类通过"距离"或"相似度"来衡量样本之间的关系。最常见的是欧氏距离。
1. 欧氏距离
对于两个样本点
它们的欧氏距离定义为:
距离越小,说明两个样本越接近;距离越大,说明差异越明显。
不过在工程中要特别注意:不同特征的量纲可能不同。例如一个特征是温度,单位是 ℃;另一个特征是振动幅值,单位是 mm/s。如果直接计算距离,数值大的特征会"支配"结果。因此,聚类之前通常需要做标准化处理。
四、聚类前为什么要做数据预处理
很多工程人员在实际使用聚类时,效果不好,往往不是算法本身的问题,而是数据预处理没有做好。
1. 特征标准化
最常见的是 Z-score 标准化:
其中:
- x 是原始特征值;
- μ 是该特征的均值;
- σ 是该特征的标准差。
经过标准化后,不同特征的尺度会统一,避免某一个量纲特别大的特征压制其他特征。
2. 特征选择
工程数据中有些特征可能无效、重复,甚至是噪声。如果把这些特征直接送入聚类,结果往往会变差。因此,聚类前应尽量保留:
- 物理意义明确的特征;
- 与状态变化相关的特征;
- 重复性好、鲁棒性好的特征。
3. 异常值处理
少量极端异常点可能严重影响某些聚类方法,尤其是 K-means 这类基于均值的方法。因此,在正式聚类之前,常常需要先对明显异常值进行清洗或单独分析(后续出一期针对异常值处理的博客)。
五、常见聚类方法
工程应用中最常见的聚类方法主要有三类:
- K-means 聚类;
- 层次聚类;
- DBSCAN 密度聚类。
下面分别介绍。
六、K-means 聚类
6.1 基本思想
K-means 是最经典、最常用的聚类方法之一。它的思想很直接:
- 先假设数据要分成 K 类;
- 随机初始化 K 个聚类中心;
- 把每个样本分配给最近的中心;
- 更新每一类的中心;
- 重复上述过程,直到聚类结果不再明显变化。
它本质上是在不断优化"每个样本到所属聚类中心的距离总和"。
6.2 目标函数
K-means 的优化目标通常写成:
其中:
- K 为簇的数量;
- Ck 表示第 k 个簇;
- μk 表示第 k 个簇的中心;
表示样本到簇中心的平方距离。
6.3 聚类中心更新
每个簇的中心是该簇样本的均值:
这也是 K-means 名字中 "means" 的来源。
6.4 K-means 的优缺点
优点
- 原理简单,容易实现;
- 计算速度快,适合大样本;
- 对球状、分离较好的簇效果较好。
缺点
- 需要提前指定 K;
- 对初始中心敏感;
- 对异常值敏感;
- 对非球状簇、密度不均匀的数据效果不好。
所以在工程中,K-means 通常适合做第一轮快速探索,但不一定适合所有数据。
七、层次聚类
7.1 基本思想
层次聚类(Hierarchical Clustering)不需要一开始就指定具体分多少类,而是通过逐步合并或逐步拆分样本,构建出一个层级结构。
最常见的是凝聚型层次聚类:
- 起初每个样本都是一个独立簇;
- 每一步合并最相近的两个簇;
- 不断重复,直到所有样本并成一个大簇。
最终常用树状图(dendrogram)表示聚类过程。
层次聚类 = 从"每个点单独成类"开始,不断把最近的两个簇合并,最终得到一棵聚类树。
这样最后会形成一个树状结构。你想分 2 类,就在高一点的位置切一刀;你想分 3 类,就在低一点的位置切一刀。
7.2 簇间距离的定义
层次聚类的关键在于:两个簇之间的距离怎么定义。常见方式有:
(1)单链接
取两个簇中最近样本之间的距离:
(2)全链接
取两个簇中最远样本之间的距离:
(3)平均链接
取两个簇中所有样本两两距离的平均值:
7.3 层次聚类的特点
优点
- 不必一开始指定簇数;
- 能直观展示数据之间的层级关系;
- 对小样本分析很有帮助。
缺点
- 样本量大时计算开销较大;
- 一旦合并,通常不可回退;
- 对噪声和距离定义比较敏感。
在工程中,层次聚类很适合做小样本状态分析、工况分组、实验数据探索。
八、DBSCAN 密度聚类
8.1 基本思想
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类方法。它不再依赖"簇中心",而是认为:
- 在高密度区域中的样本,属于同一个簇;
- 远离高密度区域的点,可能是噪声点或离群点。
这非常适合工程中存在异常点、形状复杂的数据。
8.2 两个核心参数
DBSCAN 主要依赖两个参数:
- ε :邻域半径;
- MinPts:一个点在 ε 邻域内至少需要包含的点数。
如果某个点在其 ε 邻域内的样本数不少于 MinPts,那么它就是一个核心点。
可以表示为:
若满足:
则 xi 为核心点。
8.3 DBSCAN 的优缺点
优点
- 不需要预先指定簇数;
- 能识别任意形状的簇;
- 能自动识别噪声点;
- 对异常检测很有价值。
缺点
- 参数 ε 和 MinPts 不易选;
- 对不同密度的数据不够稳定;
对于工程人员来说,DBSCAN 最大的价值往往在于:既能聚类,又能找异常点。
九、怎么评价聚类结果好不好
聚类和分类不同,很多时候没有标准答案。因此,聚类效果评价本身就是一个重要问题。
9.1 轮廓系数
轮廓系数(Silhouette Coefficient)是很常见的内部评价指标。
对于样本 i,定义:
- a(i):样本 i 与同簇其他样本的平均距离;
- b(i):样本 i 与最近其他簇样本的平均距离。
则轮廓系数为:
其取值范围一般在 −1,1 之间:
- 越接近 1,说明聚类效果越好;
- 接近 0,说明样本处于边界附近;
- 小于 0,说明样本可能被分错了。
9.2 工程上更关心什么
虽然数学指标有帮助,但在工程上,更重要的是以下几个问题:
- 聚出来的类是否有明确物理意义?
- 同一簇中的样本是否真的对应相近工况?
- 不同簇是否能映射到不同运行状态或缺陷类型?
- 聚类结果是否稳定、可复现?
- 换一批数据后,分簇规律是否还能保持?
所以,工程聚类评价不能只看指标,还要结合机理解释和业务价值。
十、聚类在工程中的典型应用
10.1 设备运行状态划分
在旋转机械、电机、泵、压缩机、轴承等设备中,经常会采集振动、噪声、电流、温度等信号。很多时候并不知道设备到底有几种状态,这时聚类可以先把数据自动分组。
例如,可以提取以下特征:
- 均值;
- 均方根值;
- 峰值;
- 峭度;
- 频谱主峰;
- 带宽;
- 小波能量分布等。
然后对这些特征做聚类,往往能得到:
- 正常工况簇;
- 负载变化簇;
- 轻微异常簇;
- 明显故障簇。
在实际项目中,这一步往往是后续故障诊断的基础。
10.2 故障模式发现
有时工程人员只知道"设备不正常",但并不知道异常具体可以分成几种类型。聚类可以帮助发现潜在故障模式。
例如,对一批故障振动信号进行聚类后,可能自然分成:
- 偏心类;
- 不平衡类;
- 松动类;
- 轴承局部损伤类。
这时聚类就起到了"从数据中发现故障谱系"的作用。
10.3 工艺过程分段
在制造和检测过程中,很多信号并不是全程稳定的,而是随着时间经历多个阶段。比如:
- 升温阶段;
- 稳态阶段;
- 冷却阶段;
- 异常波动阶段。
如果把不同时间窗口提取成特征点,再做聚类,往往能自动识别这些工艺阶段。这对于工艺监控、过程诊断、质量追溯都很有帮助。
10.4 产品质量分组
在质量检测中,产品参数往往不是简单地"合格/不合格"两类,而可能存在:
- 合格品;
- 边缘品;
- 风险品;
- 明显异常品。
聚类可以先对检测数据进行分组,帮助工程人员理解质量分布,再进一步制定判定阈值或分类规则。
十一、工程中使用聚类的一个基本流程
对于工程场景,聚类通常建议按下面的流程来做。
第一步:明确目标
先想清楚,你是要:
- 发现运行状态;
- 识别故障模式;
- 做异常筛查;
- 做样本预分组;
- 还是做工艺阶段划分。
目标不同,聚类策略会不同。
第二步:构造合适特征
聚类一般不直接对原始信号做,而是对特征做。工程上尽量选:
- 有物理意义;
- 稳定性好;
- 区分能力强;
- 与目标状态相关的特征。
第三步:标准化与降维
必要时进行标准化、主成分分析(PCA)等处理,以减少噪声和冗余。
第四步:选择聚类算法
- 数据比较规整:优先试 K-means;
- 样本量不大,想看层级关系:可试层次聚类;
- 可能有异常点、簇形状复杂:可试 DBSCAN。
第五步:结果解释
这是工程应用最关键的一步。不能只停留在"分成了几 类",而要解释:
- 每一类的特征差异是什么;
- 对应的物理状态是什么;
- 是否和工况记录、实验现象、检测结果一致。
十二、工程应用中容易踩的坑
12.1 盲目把聚类当成分类
聚类得到的是"数据分组",不一定天然对应"真实类别"。聚类结果需要结合机理解释,不能机械地把簇编号当成故障标签。
12.2 特征没有物理意义
如果输入的特征只是随便凑的,聚类结果往往没有解释价值。工程聚类最怕"数学上分得开,物理上讲不通"。
12.3 忽略标准化
量纲不统一时,聚类结果很容易失真,这是非常常见的问题。
12.4 过度依赖二维可视化
很多人看到二维降维图中分成几团,就认为聚类很好。但降维可能会损失信息,不能完全代替定量分析。
12.5 只做一次结果
聚类本身可能受参数、初始化和样本波动影响。工程中建议多次重复验证,看结果是否稳定。
十三、工程中怎么理解聚类
对于工程应用来说,可以把聚类理解成下面这句话:
聚类不是直接告诉你答案,而是帮助你从混乱数据中先看出结构。
它通常回答的是:
- 数据里是不是天然存在几种模式?
- 哪些样本彼此接近?
- 哪些样本明显偏离主群体?
- 当前数据是否能分成几个具有工程意义的状态区间?
所以聚类更像是一个"探索工具"和"分析工具",而不是最终结论本身。
十四、matlab仿真
Matlab
clc;
clear;
close all;
%% 1. 构造二维样本数据
% 构造三簇二维数据,并加入少量噪声点
rng(1); % 固定随机种子,保证结果可复现
n1 = 80;
n2 = 80;
n3 = 80;
cluster1 = randn(n1,2) * 0.5 + [2, 2];
cluster2 = randn(n2,2) * 0.6 + [7, 3];
cluster3 = randn(n3,2) * 0.5 + [4, 7];
noise = [10*rand(15,1), 10*rand(15,1)];
X = [cluster1; cluster2; cluster3; noise];
%% 2. 原始数据可视化
figure('Name','原始数据','Color','w');
scatter(X(:,1), X(:,2), 36, 'k', 'filled');
title('原始二维样本数据');
xlabel('x');
ylabel('y');
grid on;
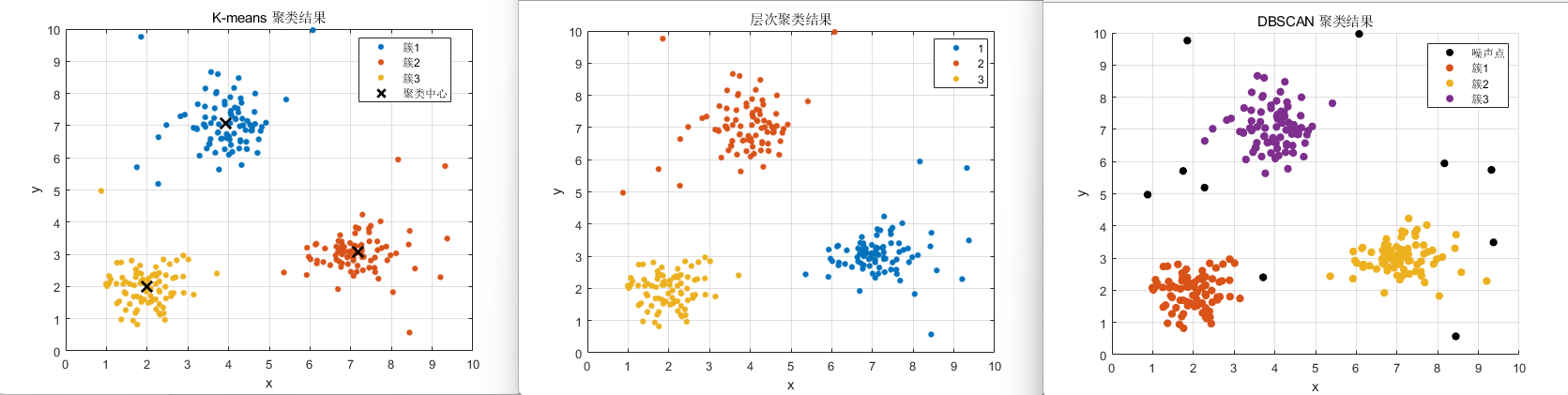
%% 3. K-means 聚类
% 指定聚成 3 类
K = 3;
[idx_kmeans, C] = kmeans(X, K, 'Replicates', 10);
figure('Name','K-means 聚类结果','Color','w');
gscatter(X(:,1), X(:,2), idx_kmeans);
hold on;
plot(C(:,1), C(:,2), 'kx', 'LineWidth', 2, 'MarkerSize', 12);
title('K-means 聚类结果');
xlabel('x');
ylabel('y');
legend('簇1','簇2','簇3','聚类中心');
grid on;
%% 4. 层次聚类
% 先计算样本间欧氏距离,再进行层次聚类
Z = linkage(X, 'ward'); % 采用 Ward 方法
idx_hier = cluster(Z, 'maxclust', 3); % 划分为 3 类
figure('Name','层次聚类结果','Color','w');
gscatter(X(:,1), X(:,2), idx_hier);
title('层次聚类结果');
xlabel('x');
ylabel('y');
grid on;
%% 5. 层次聚类树状图
figure('Name','层次聚类树状图','Color','w');
dendrogram(Z, 0);
title('层次聚类树状图');
xlabel('样本编号');
ylabel('距离');
%% 6. DBSCAN 聚类
% epsilon: 邻域半径
% MinPts: 最小点数
epsilon = 0.8;
MinPts = 6;
idx_dbscan = dbscan(X, epsilon, MinPts);
figure('Name','DBSCAN 聚类结果','Color','w');
% DBSCAN 中,标签 -1 表示噪声点
unique_labels = unique(idx_dbscan);
hold on;
for i = 1:length(unique_labels)
label = unique_labels(i);
if label == -1
scatter(X(idx_dbscan==label,1), X(idx_dbscan==label,2), ...
40, 'k', 'filled', 'DisplayName', '噪声点');
else
scatter(X(idx_dbscan==label,1), X(idx_dbscan==label,2), ...
40, 'filled', 'DisplayName', ['簇' num2str(label)]);
end
end
hold off;
title('DBSCAN 聚类结果');
xlabel('x');
ylabel('y');
legend('show');
grid on;结果:
十四、总结
聚类是无监督学习中的基本方法,其核心思想是根据样本之间的相似性,把数据自动划分为若干簇。对于工程应用而言,聚类最大的价值不在于算法本身多复杂,而在于它能够帮助我们在没有标签的情况下发现数据结构、划分运行状态、识别潜在故障模式,并为后续的诊断、分类和预警建模打下基础。
实际应用时,真正决定聚类质量的,往往不是选了哪个"最先进"的算法,而是以下几点:
- 特征是否合理;
- 数据是否经过规范预处理;
- 结果是否具有物理意义;
- 是否能和工程场景闭环验证。
如果把这几点做好,聚类就不仅是一个机器学习概念,而会成为一个非常实用的工程分析工具。
后续我将继续更新机器学习与信号处理的知识,欢迎大家关注。