过去两年,大家最喜欢聊的是 Prompt Engineering。怎么写提示词、怎么加 Role、怎么做 Few-shot......这套东西当然重要。但如果你最近在看 OpenAI、Anthropic 这些一线团队的工程文章,会发现一个明显的变化:他们聊的,已经不只是 Prompt 了。
2026 年,AI 应用的形态真的变了。过去你主要是在"问模型一个问题",现在你更像是在"让一个 Agent 连续干活"。一旦任务从一次回答变成连续执行,很多问题就不是一句 Prompt 能解决的了。
今天这篇文章,我想把 Harness Engineering 这个新概念讲清楚。它不是换个新词继续卷概念,而是 AI 工程重心转移的真实信号。
01 为什么 Prompt 不够了?
先说结论:Prompt Engineering 没过时,它依然是基本功。 模型第一步能不能听懂你在说什么,还是取决于 Prompt。
但问题是,今天的 AI 应用已经不是 2023 年的形态了。
以前你让模型"回答一个问题",现在你让它:先理解任务→拆步骤→搜索资料→调用工具→读文件→修改内容→检查结果→最后交付。
这时候,真正卡住系统的,往往不是 Prompt 写得不够漂亮,而是另外几件事:
- 该给它什么资料?
- 哪些历史该保留?
- 哪些工具结果该丢掉?
- 当前状态怎么记录?
- 失败后怎么恢复?
- 结果怎么评估?
一个 Coding Agent 接到任务后,如果 Prompt 写得很好,但它拿不到 Repo 结构、不知道哪些文件相关、看不到测试报错......它能干好吗?很难。
这就是 LLM 的结构性局限:
| 局限 | 表现 |
|---|---|
| 无状态 | 对话结束就忘记 |
| 只能生成文字 | 无法操控外部世界 |
| 上下文窗口限制 | 不能无限处理信息 |
| 输出概率性 | 同样的输入可能不同输出 |
Prompt 解决的是"怎么说",但解决不了这些结构性问题。所以行业才会开始从 Prompt Engineering 往 Context Engineering 走,再往 Harness Engineering 走。

02 Harness Engineering 是什么?
有个很形象的比喻:马与挽具。
马有力量,但需要挽具。
LLM 有能力,但需要 Harness。
马再强壮,没有挽具也拉不动车。LLM 再强大,没有系统约束也无法稳定完成任务。Harness 不是优化 Prompt 的技巧,而是让 LLM 能力稳定输出的"系统性挽具"。

如果把 AI 工程分成三层,关系是这样的:
| 层级 | 解决的核心问题 | 典型对象 |
|---|---|---|
| Prompt Engineering | 怎么说 | 单轮任务 |
| Context Engineering | 给什么 | 长上下文任务 |
| Harness Engineering | 怎么持续做 | Agent / 工作流 |
- Prompt 负责讲任务
- Context 负责喂信息
- Harness 负责让系统稳定运转
Harness 不是一句 Prompt,也不只是一包 Context。Harness 是整台机器。
03 四层架构:Harness 是怎么工作的?
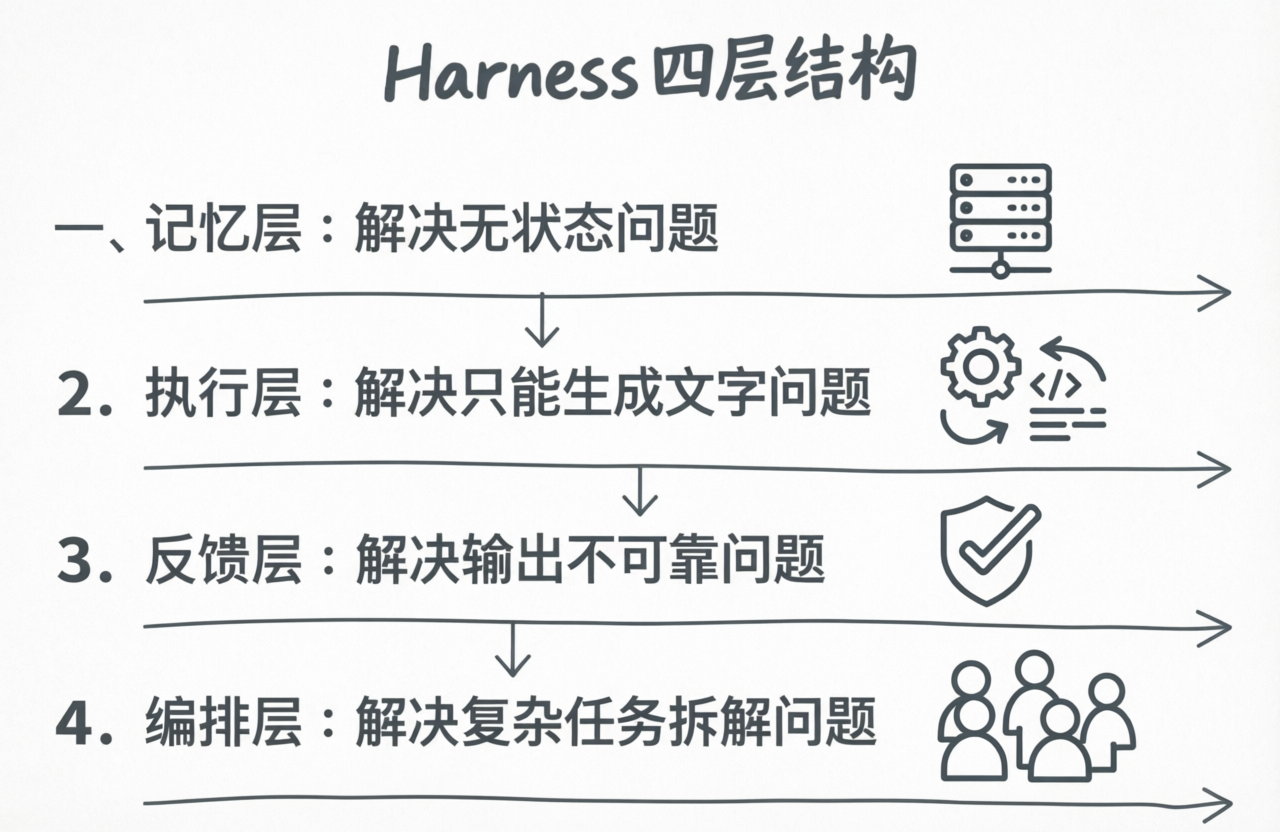
Harness Engineering 的核心,可以拆成四层结构:
第一层:记忆层------解决"健忘症"
LLM 对话结束就忘记,这是无状态问题。记忆层要做的是结构化存储关键信息。
比如 Claude 的 CLAUDE.md 文件,把项目规范、代码约定、常见问题都写进去。Agent 每次启动时自动读取,相当于有了"长期记忆"。
但记忆不是越多越好。真正的记忆工程要做的是:
- 保留关键历史
- 压缩冗余内容
- 清掉过时结果
- 把真正重要的东西留在窗口里
第二层:执行层------突破"只会说话"限制
LLM 只能生成文字,无法操控外部世界。执行层要赋予它操作外部世界的能力。
比如:
- 搜索
- 文件读取
- Shell 命令
- 浏览器操作
- 数据库查询
工具不是"附加能力",它本身就是上下文的一部分。因为模型得知道:有哪些工具、每个工具是干什么的、什么情况下该用哪个。
第三层:反馈层(核心)------建立确定性验证机制
这是 Harness 最核心的一层。
LLM 输出是概率性的,同样的输入可能不同输出。反馈层要做的是将人工 Review 的小时级反馈压缩至秒级。
在代码领域,这个闭环天然存在:
- 模型生成代码
- 编译器/测试立刻验证
- 失败→重试/回滚
- 成功→继续下一步
Anthropic 在内部评测里给过一组数据:在他们那套 Multi-Agent Research 系统里,优化 Tool Description 后,后续 Agent 的任务完成时间下降了 40%。
反馈层的核心价值:把人的判断力固化进系统。
第四层:编排层------拆解复杂任务
复杂任务不是一步能完成的。编排层要做的是任务拆解和多 Agent 协同。
比如一个 Research Agent 做行业调研:
- 子 Agent A 负责搜索
- 子 Agent B 负责整理
- 子 Agent C 负责验证
- 主 Agent 负责统筹和交付
Anthropic 在内部 Research Eval 上的数据:多 Agent 比单 Agent 高出 90.2%。
04 为什么代码领域先行?
你会发现,Harness Engineering 的讨论最早、最密集的都是 Coding Agent。为什么?
因为代码验证天然确定------编译器不讲情面。
这使"概率性生成 + 确定性验证"闭环可以高速运转:
模型生成代码 → 编译器验证 → 测试运行 → 反馈结果 → 修正重试其他领域就没这么友好。比如写文章、做设计、出方案,很难有自动化的"编译器"来验证对错。所以代码领域成了 Harness Engineering 的试验田和突破口。
但这不代表其他领域不能用。核心思路是一样的:找到你领域的"编译器",建立确定性验证机制。
05 实践精髓:普通团队现在该怎么做?
我的建议是,不要一上来就学那些很玄的"大一统 Agent 框架"。先把基础链路做稳。

1. 渐进式信息披露
避免信息过载。不是把所有文档、所有历史、所有工具一股脑塞进上下文。那叫上下文污染,不叫 Context Engineering。
对的时机,把对的信息交给模型。
2. 沙箱隔离
独立沙箱大胆试错。Agent 执行命令、修改文件、调用工具,都应该在隔离环境中进行。出错了可以回滚,不会污染生产环境。
3. 仓库即真理
规范写入代码而非口头传达。比如把项目约定写成 CONTRIBUTING.md、CLAUDE.md,Agent 自动读取。规则变成可执行的代码,不靠人情。
4. 机械化约束
规则自动执行,不靠人情。哪些动作能自动做,哪些动作必须人工确认,要提前定义好。
比如:读文件通常可以自动做,但删除文件、联网下载、发消息,很多时候就不能放开。
5. 上 Eval、日志和人工 Review 闭环
不做这些,你永远不知道自己是在调系统,还是在碰运气。
你得看得见 Agent 在干什么:它用了哪些工具、做了哪些决定、卡在了哪里、为什么失败。
06 工程师的新使命
最后说一个更重要的变化:工程师角色的转变。
过去工程师的核心工作是写代码。现在,越来越多的工程师要转向设计验证系统。
| 过去 | 现在 |
|---|---|
| 写代码 | 设计系统 |
| 调逻辑 | 调架构 |
| 修 Bug | 设计恢复机制 |
| 写文档 | 固化规则到系统 |
Harness Engineering 的本质:把人的判断力固化进系统,变成可持续运转的基础设施。
这不是说写代码不重要了,而是说,当模型能写代码的时候,工程师的价值就往上移了一层------从执行者变成系统设计者。
07 写在最后
如果把这篇文章再压缩成一句话,那就是:
Prompt Engineering 解决的是"怎么说"
Context Engineering 解决的是"给什么"
Harness Engineering 解决的是"怎么让它持续做下去"
过去大家在调一句 Prompt,现在大家开始调一整套 Agent 运行系统。
这不是因为 Prompt 不重要了,而是因为 AI 应用已经从"回答问题"走到了"连续执行任务"的阶段。
真正的变化,不是概念变多了,而是工程重心变了。