论文题目:Geometric deep learning on graphs and manifolds using mixture model CNNs(基于混合模型cnn的图形和流形的几何深度学习)
会议:CVPR2016
摘要:深度学习在几个领域取得了显著的性能突破,其中最显著的是语音识别、自然语言处理和计算机视觉。特别是卷积神经网络(CNN)架构目前在各种图像分析任务(如物体检测和识别)上产生了最先进的性能。到目前为止,大多数深度学习研究都集中在处理1D, 2D或3D欧几里得结构数据,如声学信号,图像或视频。最近,人们对几何深度学习越来越感兴趣,试图将深度学习方法推广到非欧几里得结构化数据,如图和流形,并在网络分析、计算社会科学或计算机图形学领域有各种应用。在本文中,我们提出了一个统一的框架,允许将cnn架构推广到非欧几里得域(图和流形),并学习局部、平稳和组合任务特定的特征。我们表明,以前在文献中提出的各种非欧几里得CNN方法可以被视为我们框架的特定实例。我们在图像、图形和三维形状分析领域的标准任务上测试了所提出的方法,并表明它始终优于以前的方法。
深入理解MoNet - 统一图与流形上的几何深度学习
引言
你是否曾经思考过:CNN为什么在图像识别上如此成功,却难以直接应用到社交网络分析或3D形状理解上?答案在于数据的几何结构。今天要介绍的这篇CVPR 2016论文提出了MoNet框架,优雅地将深度学习扩展到非欧几里得域,并统一了多种看似不同的几何深度学习方法。
问题背景:欧几里得 vs 非欧几里得
传统CNN的舒适区
传统卷积神经网络(CNN)处理的数据通常具有规则的网格结构:
- 图像:2D像素网格
- 音频:1D时间序列
- 视频:3D时空网格
这些数据的共同特点是欧几里得结构 - 每个位置的邻域关系是固定且规则的。
现实世界的挑战
但现实中大量数据并不满足这个假设:
🌐 社交网络 :用户之间的关系是不规则的图结构
🧬 分子结构 :原子连接形成复杂的图
🎭 3D形状 :人体、动物等3D模型是流形结构
🧠 大脑网络:神经元连接模式
这些数据无法直接用传统CNN处理,因为它们缺乏规则的网格结构。
现有方法的困境
在MoNet之前,研究者们提出了两类主要方法:
1. 谱方法(Spectral Methods)
核心思想:利用图拉普拉斯矩阵的特征分解定义"傅里叶变换"
代表方法:
- Spectral CNN (Bruna et al., 2013)
- ChebNet (Defferrard et al., 2016)
- GCN (Kipf & Welling, 2016)
致命缺陷:
问题:每个图有自己独特的特征基
结果:在图A上训练的模型无法应用到图B
类比:就像用英语训练的模型无法理解中文2. 空间方法(Spatial Methods)
核心思想:直接在空间域定义局部卷积操作
代表方法:
- GCNN (Masci et al., 2015) - 使用测地极坐标
- ACNN (Boscaini et al., 2016) - 使用各向异性热核
局限性:手工设计的固定patch提取方式,灵活性受限
MoNet的创新:可学习的几何卷积
核心洞察
MoNet的关键创新是将patch算子参数化,让网络自己学习如何提取局部特征。
三个关键组件
1. 伪坐标(Pseudo-coordinates)
对于中心点x和邻域点y,定义一个d维向量u(x,y)描述它们的关系。
例子:
- 图像:u = 像素坐标差 (Δx, Δy)
- 图:u = (deg(x), deg(y)) 节点度
- 流形:u = (ρ, θ) 测地极坐标
2. 可学习的权重函数
使用高斯混合模型(GMM):
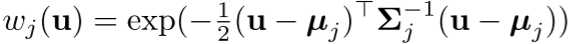
其中μ_j(均值)和Σ_j(协方差)是可学习参数!
3. Patch算子
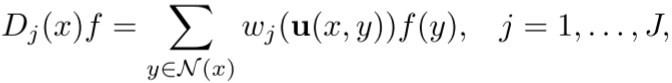
这个算子提取x点周围的"patch",权重由学习到的高斯核决定。
统一的卷积定义
最终的卷积操作:
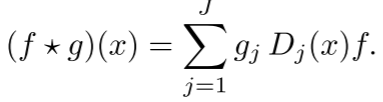
这个简洁的公式统一了所有几何深度学习方法!
理论贡献:统一视角
MoNet最优雅的地方在于它展示了现有方法都是特殊情况:

| 方法 | 伪坐标 u(x,y) | 权重函数 w_j(u) |
|---|---|---|
| CNN | 欧几里得坐标差 | δ(u - ūⱼ) |
| GCNN | 测地极坐标 (ρ,θ) | 固定高斯核 |
| ACNN | 测地极坐标 (ρ,θ) | 各向异性高斯核 |
| GCN | (deg(x), deg(y)) | 三角核 |
| DCNN | 随机游走概率 | 恒等函数 |
| MoNet | 任意选择 | 可学习的GMM |
这就像发现了一个"大统一理论"!
实验验证:理论到实践
实验1:MNIST图表示
设置:将MNIST图像表示为superpixel邻接图
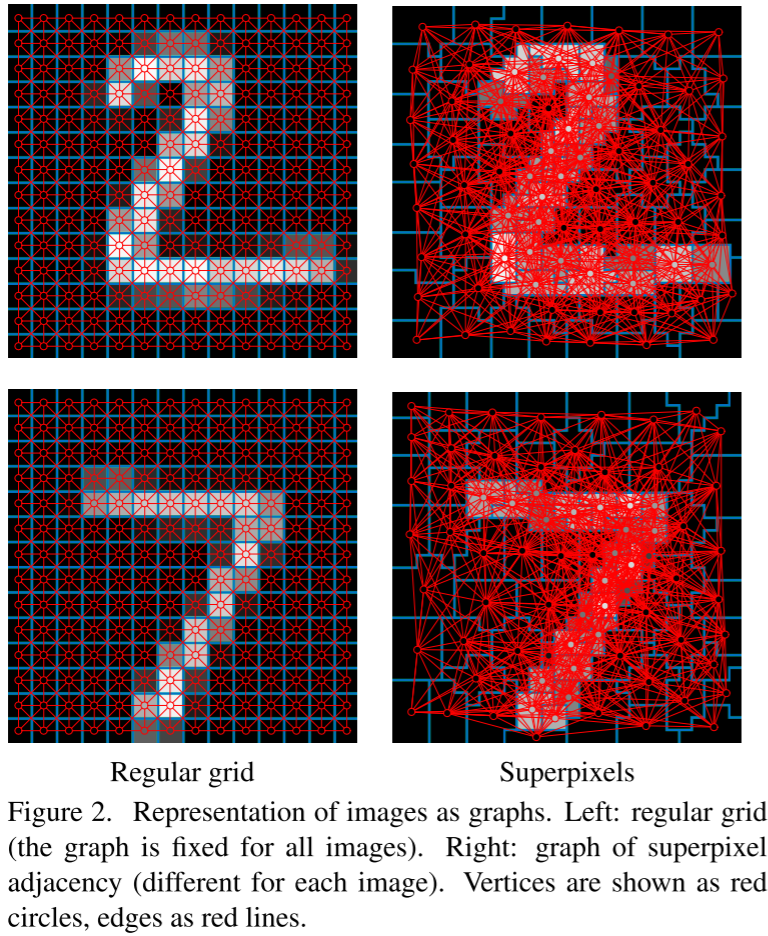
关键问题:每张图像是不同的图结构!
结果:

ChebNet(谱方法):
- 300超像素:88.05% ❌
- 150超像素:80.94% ❌
- 75超像素:75.62% ❌ (性能崩溃!)
MoNet(我们的方法):
- 300超像素:97.30% ✓
- 150超像素:96.75% ✓
- 75超像素:91.11% ✓ (保持稳定!)解释:谱方法因为每个图的特征基不同而失败,MoNet的空间域方法不受影响。
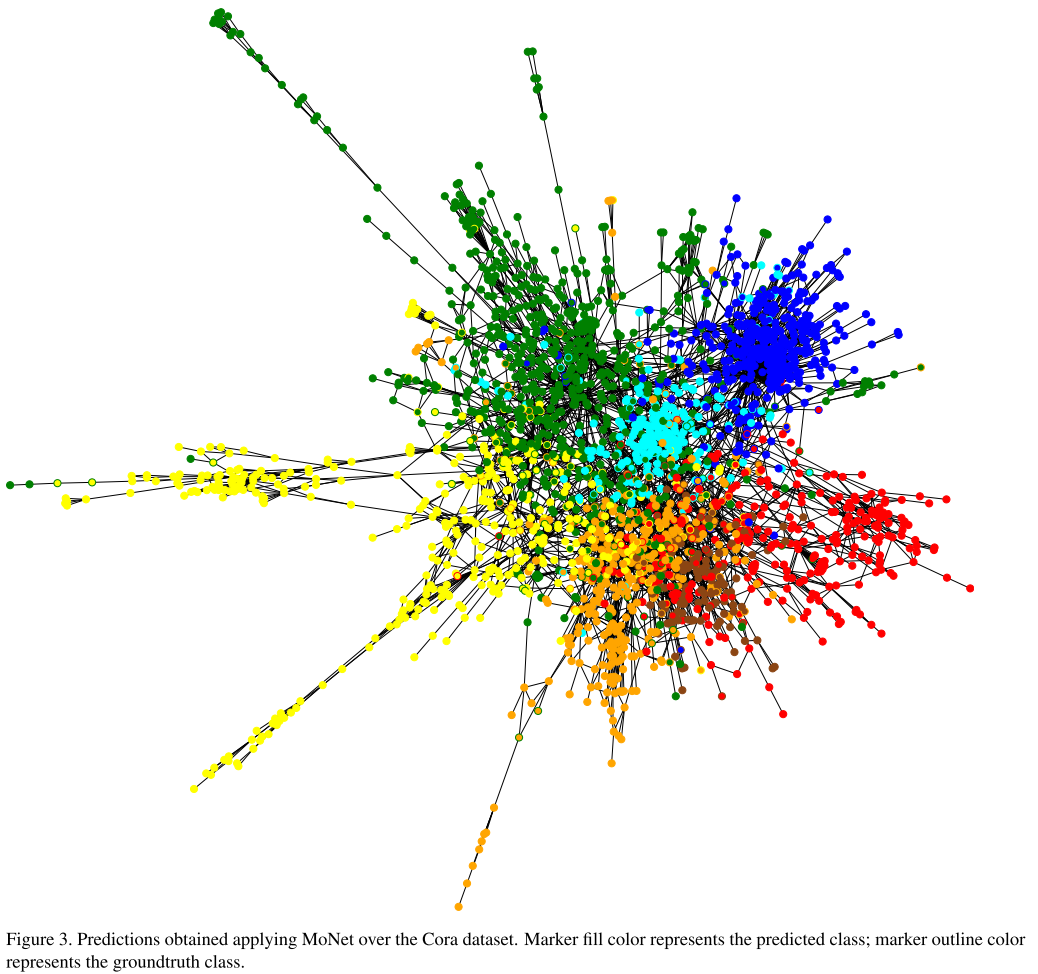
实验2:引文网络节点分类
数据集:Cora(2708篇论文)、PubMed(19717篇论文)
任务:根据论文内容和引用关系分类
结果:
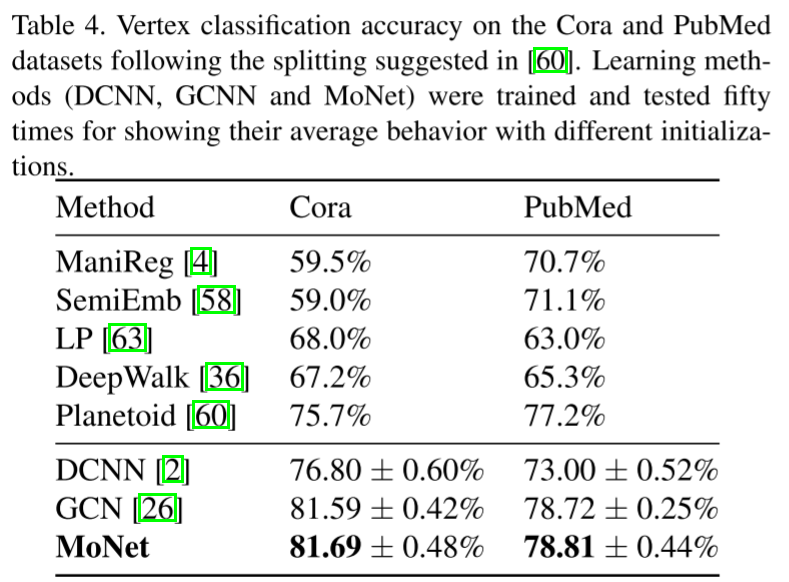
| 方法 | Cora | PubMed |
|---|---|---|
| GCN | 81.59% | 78.72% |
| MoNet | 81.69% | 78.81% |
虽然提升看似不大,但要知道训练集只有每类20个样本!
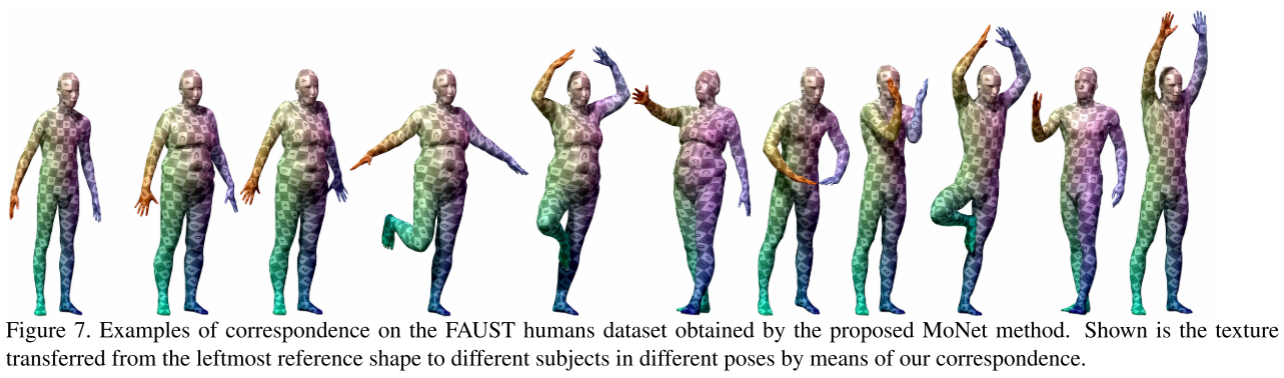
实验3:3D形状对应
任务:在不同姿势的人体模型间建立对应关系
数据集:FAUST(100个人体网格)
结果亮点:
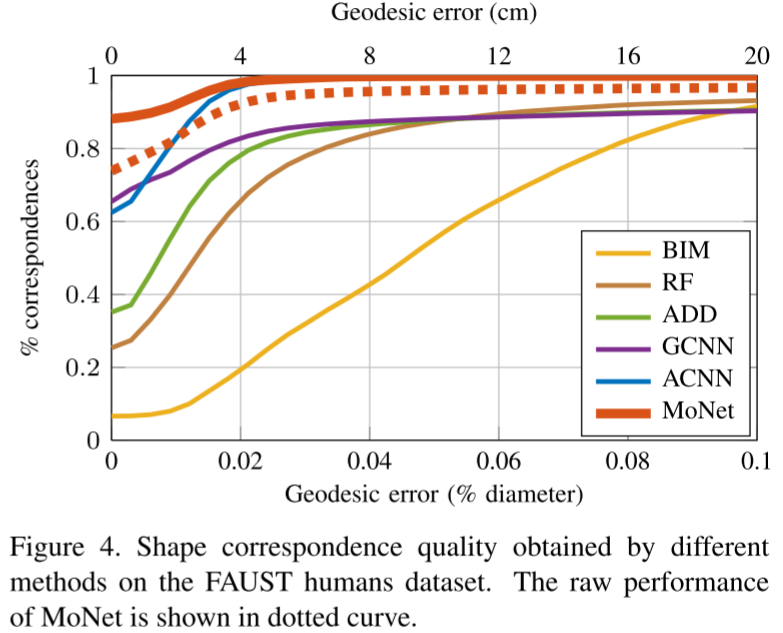
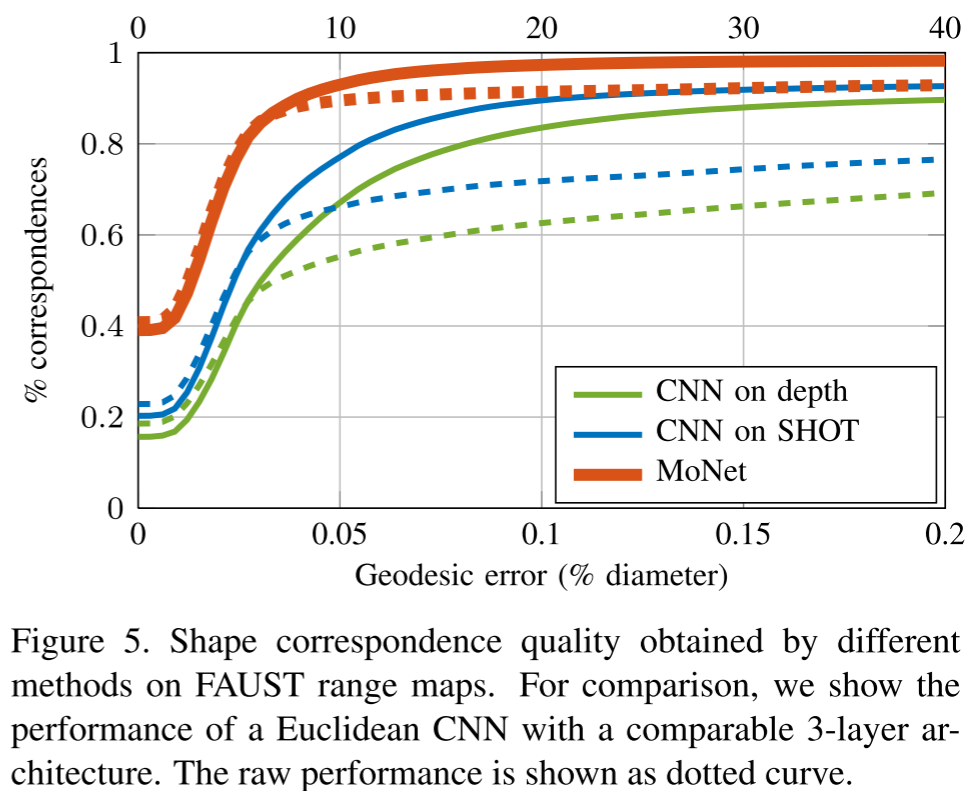
- 90%的点完全正确匹配
- 99%的点误差<4cm
- 大幅超越所有baseline
可视化展示了MoNet学到的对应关系几乎完美!

深入理解:为什么MoNet有效?
1. 灵活性
通过学习高斯核的均值和协方差,MoNet可以自适应地调整:
- 感受野大小(通过协方差)
- 方向敏感性(通过协方差矩阵的非对角元素)
- 多尺度特征(通过多个高斯核)
2. 泛化能力
空间域定义使得:
- 同一模型可应用于不同的图
- 学到的特征具有几何意义
- 不依赖于特定的特征基
3. 可解释性
学到的高斯核可以可视化:
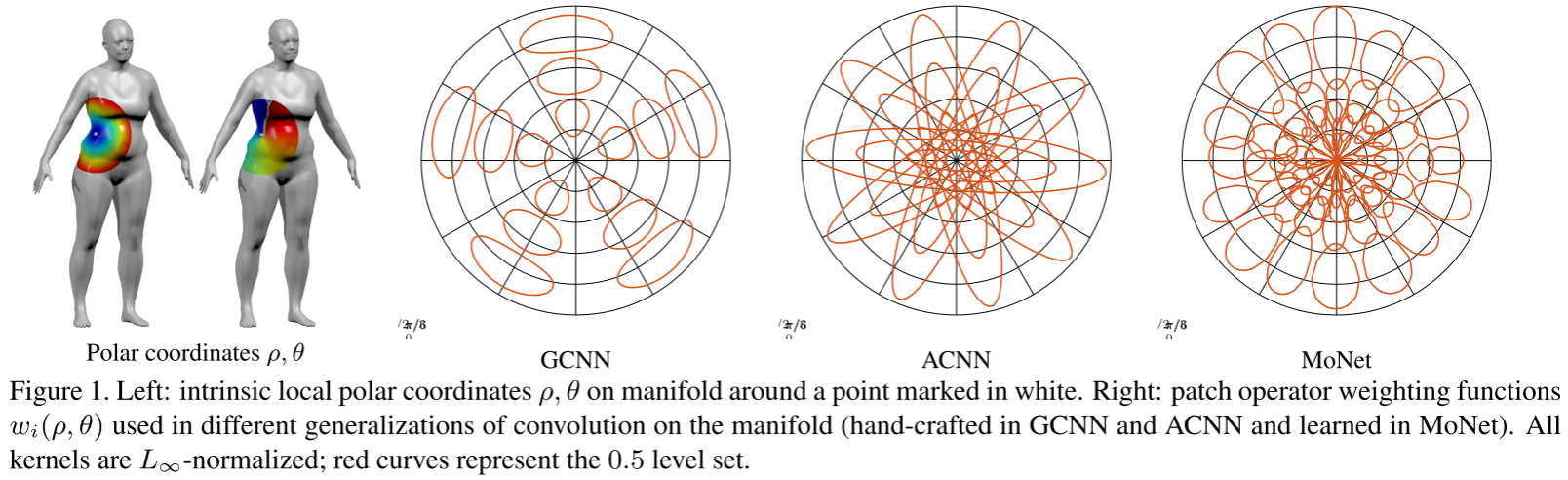
- GCNN/ACNN使用固定的径向/各向异性核
- MoNet学习任意形状的核,更灵活
实现要点
如果你想实现MoNet,关键步骤:
# 1. 定义伪坐标
def compute_pseudo_coords(x, y):
# 例如:使用测地极坐标
rho = geodesic_distance(x, y)
theta = angular_coordinate(x, y)
return [rho, theta]
# 2. 可学习的高斯核
class GaussianKernel(nn.Module):
def __init__(self, dim):
self.mu = nn.Parameter(torch.randn(dim))
self.sigma = nn.Parameter(torch.eye(dim))
def forward(self, u):
diff = u - self.mu
return torch.exp(-0.5 * diff @ self.sigma.inverse() @ diff)
# 3. Patch算子
def patch_operator(x, features, gaussian_kernels):
result = []
for kernel in gaussian_kernels:
weighted_sum = 0
for y in neighbors(x):
u = compute_pseudo_coords(x, y)
weight = kernel(u)
weighted_sum += weight * features[y]
result.append(weighted_sum)
return result局限与未来方向
当前局限
- 计算开销:需要计算邻域内所有点对的伪坐标
- 超参数:高斯核数量J需要手工选择
- 正则化:小数据集上需要仔细调参避免过拟合
未来方向
- 更复杂的权重函数:可以在GMM基础上加入非线性变换
- 自适应邻域:动态调整每个点的邻域大小
- 注意力机制:结合attention学习更灵活的权重
对后续研究的影响
MoNet发表后,启发了大量后续工作:
🔹 Graph Attention Networks (GAT) :将注意力机制引入图神经网络
🔹 PointNet++ :在点云上的层次化特征学习
🔹 GraphSAINT :大规模图的采样训练方法
🔹 Geometric GNN:更多几何先验的融入
结论
MoNet论文的价值不仅在于提出了一个性能优秀的模型,更在于:
✨ 统一视角 :揭示了看似不同方法的内在联系
✨ 理论贡献 :提供了设计几何深度学习方法的一般框架
✨ 实践指导:展示了如何在不同类型数据上应用统一原理
这篇论文是几何深度学习领域的里程碑,它告诉我们:好的理论框架能够统一现象、指导实践、启发创新。
你对几何深度学习感兴趣吗?欢迎在评论区讨论! 🚀