文件系统中最核心的数据结构就是 inode和 file descriptor,inode 代表一个文件的对象,不依赖于文件名,通过自身的编号进行区分,这里的编号就是一个整数。文件描述符 file descriptor 也简称 fd,主要与用户进程进行交互。
分层结构
xv6系统对文件做了以下分层,从底向上分别是磁盘disk,缓存buffer cache,日志层logging,用于同步的inode cache然后在往上就是目录文件名以及文件描述符了,如下图所示。
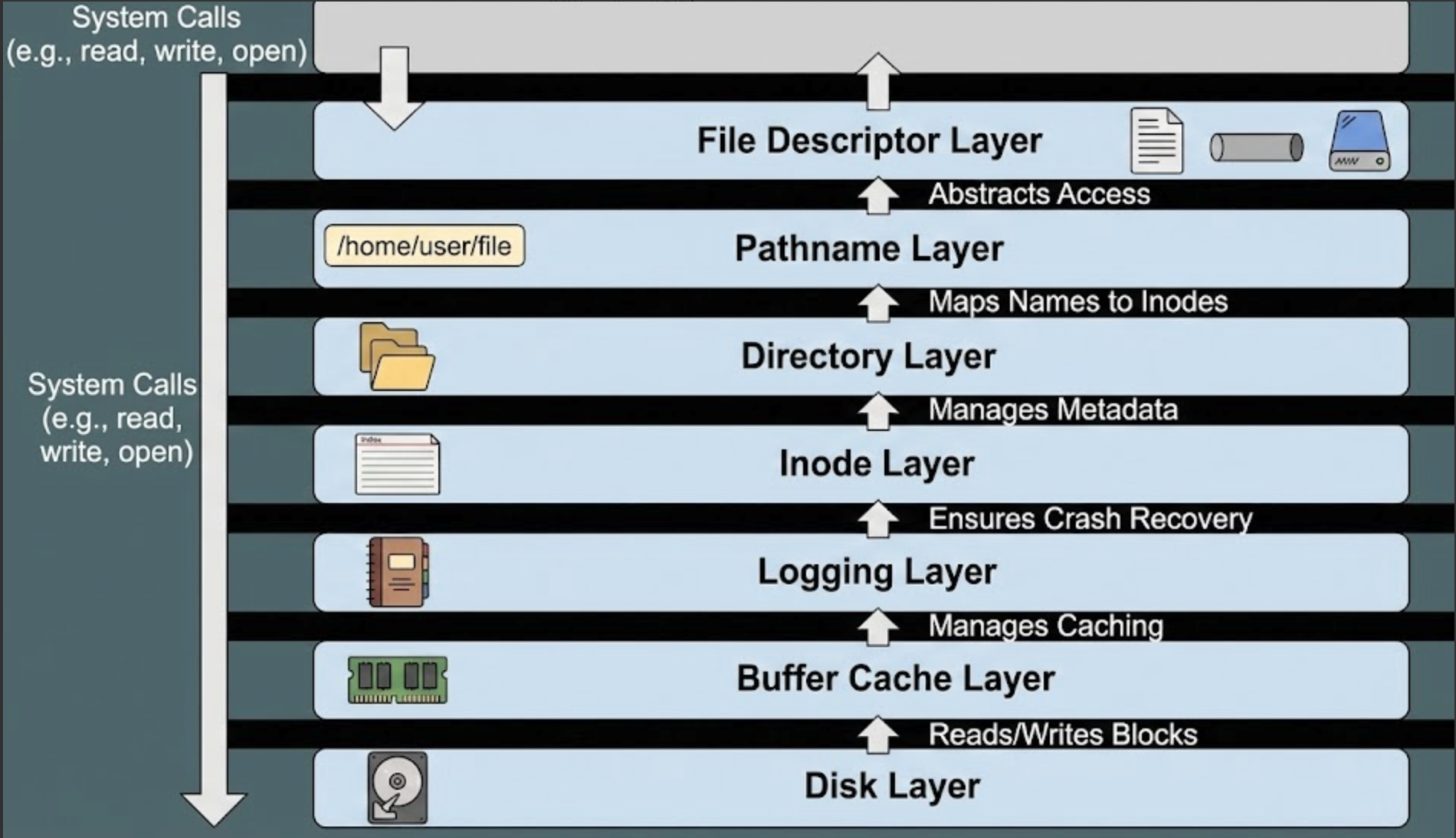
Disk
磁盘(Disk)是这个分层结构中的最底层基石,上层的所有复杂机制(缓存、日志以及Inode)本质上都是为了解决磁盘的一个核心问题:机械磁盘太慢了,而且只能按照块Block 读写。

将inode 映射到数据块的关键。addrs 数组大小通常是13(NDIRECT=12, +1 Indirect).
a. 直接察引(Direct Blocks,addrs0~addrs11):0-11表示数据块的块号,比如要读取文件的前1KB(这里假设每一块都是1KB),直接找 addrs0 指向的块
b. 间接索引(Indirect Block,addrs12):这种情况主要是处理文件超过了12个块,addrs12 指向一个特殊的数据块。这个数据块里装的不是用户数据,而是一堆块号(Block Numbers)。

当你执行 1s 命令时,xv6读取当前目录对应的inode的数据块,然后将数据块里面的二进制解析成一个个dirent,如果 inum不为0,则打印出name。这也是为什么文件名不存储在inode里,而是存储在父目录的数据块里的原因。
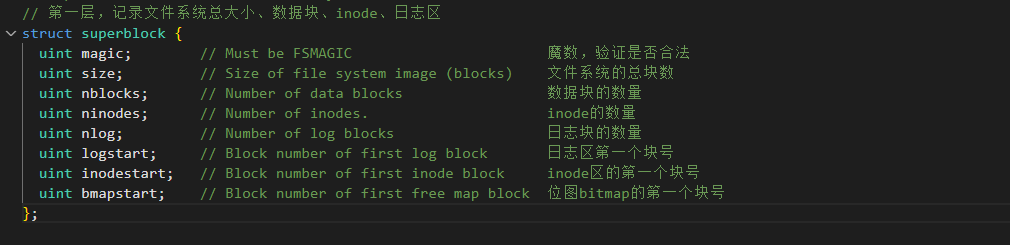
bmp实现从逻辑地址映射到物理地址
xv6文件系统的生命周期
-
首先宿主机上会运行mkfs 程序,这个程序会创建一个空的镜像文件,然后按照上述的布局将 Superblock,Inodes,Bitmap 写入文件;
-
当xv6启动时,会去读取Block1(Superblock)里的数据,这个块记录了各个区域的大小和偏移量;
-
然后扫描 Inode 区找到空闲位置分配 inode,并且在父目录的数据块中写入 dirent
-
扫描Bitmap 区找到空闲块,使用balloc 分配数据块,将数据块号填入inode的addrs 数组中
-
最后通过磁盘驱动将数据写入 DataBlock 分区
xv6 磁盘管理的精髓:静态的布局,通过inode将离散的物理块虚拟成连续的逻辑文件,并通过Bitmap高效管理空闲空间。
Buffer Cache
Buffer Cache 位于 Disk 层之上,Logging 层下。对于下层磁盘层,屏蔽了磁盘读写的具体细节,对于Inode 及以上的层级来说,磁盘就是一个无数 Block 组成的数组;对于上层Logging 它提供了一些列的API,上层的 Inode,Directory 不需要关心所需要的数据到底是在内存还是在磁盘上,更不需要关心是否会有其他线程来修改这个 Block。
简单来说 Buffer Cache 有2个主要作用:
负责缓存,因为IO操作与内存的访问的速度差距是很大的,解决这个访问速度不一致的常规方法就是将一部分数据块直接读取在内存里面,只有当缓存MISS时才会读取磁盘数据。
负责同步:Buffer Cache 还必须要确保同一时刻只有一个内核进程可以对操作磁盘,进行修改等操作。
核心数据结构
struct buf 缓冲块头,这个缓冲头 buf 负责存放 Block 存放在内存中的一些信息,例如设备号dev、块
号blockno 等。换句话说,这个buf 就是每一个磁盘块在内存中的容器。
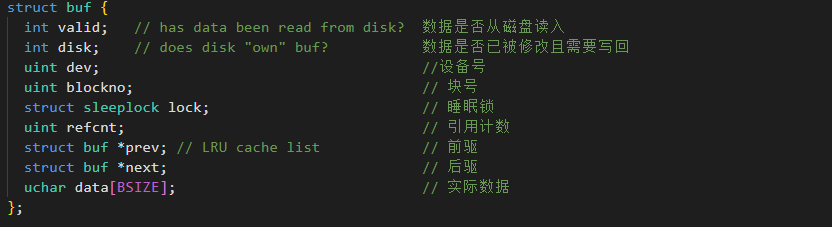
(1)这里使用的是 sleep lock 睡眠锁,而不是用的自选锁的原因是因为:磁盘I0是很慢的,如果有一
个进程在等待磁盘I0完成时应该让出CPU时间片,进入休眠,而不是一直空转。
(2)prev和next这两个指针把所有的buffer串成一个链表,xv6使用这个链表来实现LRU的淘汰策略。
(3)dataBSIZE 才是存放的实际数据
struct bcache是一个全局缓冲管理器

bcache 中的 lock(即bcache.lock)是一个全局的自旋锁,也就是说任何想要对这个链表结构进行访问、修改等操作都需要获取这把锁,保证了链表结构不被恶意破坏。
初始化函数binit(),在系统启用时调用这个函数,把静态数组 bufNBUF 变成一个动态的双向循环链
表。
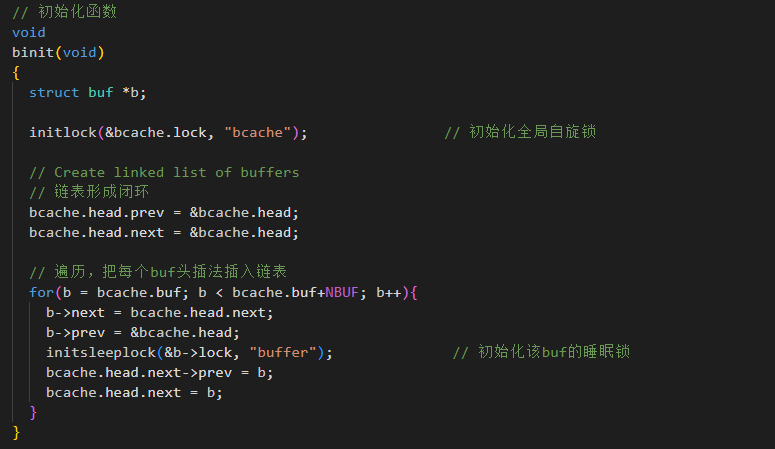
缓冲块的分配与回收
经过binit()之后,所有的缓冲块已经被添加到双线循环链表中。bget(buffer get)和 brelse (BufferRelease)控制数据块在内存中的获取与归还,并维护着至关重要的LRU(最近最少使用)替换策略。
bget()

bget()的参数分别是:dev(设备)blockno(块号);根据这两个参数就可以检索到所指定的设备的所指定的盘块。首先会去检查是否有线程的块,如果有直接返回对应的块并把引用计数+1,如果没有则需要通过LRU的方式来分配一个新的块,标注了设备和块号对应的映射关系之后返回这个块,但是此时b->valid=0,等真正需要数据的时候调用 bread 进行读取时装载。
brelse()
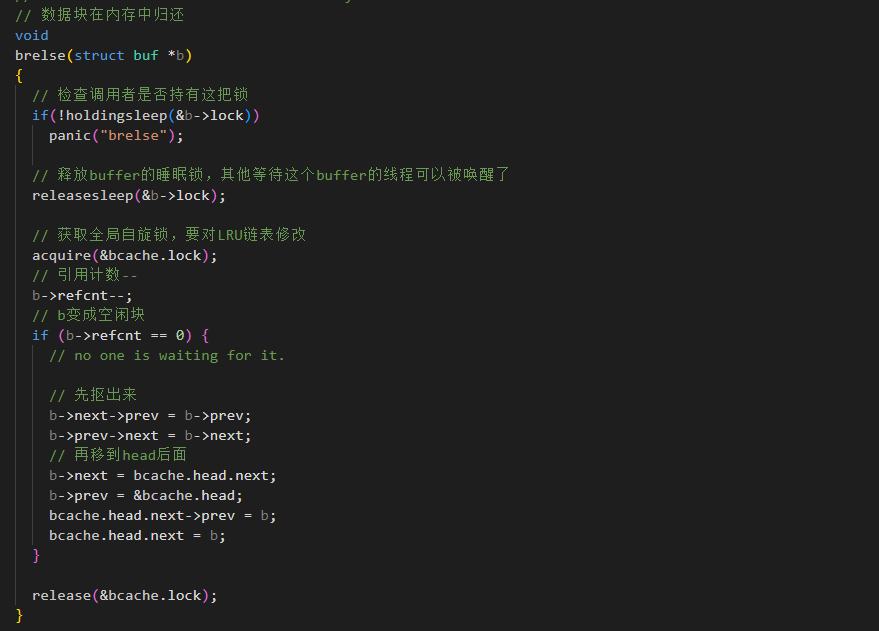
只有当 refcnt == 0 时说明没有进程在使用它了,那么这个时候就空闲了,就需要抠出来放到head 的后面,这样就是最近使用。
这里begt()和brelse()配合,实现了经典的LRU算法。
1.brelse(释放):当一个buffer用完释放时,代码会把它移动到链表的头部(bcache.head.next)。这意味着:链表头部是最近刚被用过的(MRU),链表尾部是很久没用的(LRU)。
2.bget(获取):当需要分配新块时,它从链表尾部(bcache.head.prev)开始反向扫描。这样它就能第一时间找到那个"最久没人用"的buffer进行回收。
这里特别注意锁的顺序:
· 总是先拿bcache. lock(全局自旋锁)找到目标。
· 释放 bcache.lock 后,再拿 b->lock(个体睡眠锁)操作数据。不要持有bcache.lock 的时候去 sleep,这样会死锁整个文件系统。
refcnt 除了记录有多少进程在引用buf 块之外,还有一个作用就是防止防止关键数据被意外回收,充当一个安全锁定的标志作用。
bpin()

· bpin()(加锁):如果文件系统正在修改这个托盘上的数据,需要确保在数据安全地写回磁盘之前,这个托盘绝不能被回收或挪作他用。这时,文件系统会调用 bpin 额外增加一个引用计数。这个计数不是因为有进程正在读写,而是充当一个"安全锁定"标记。bget 不会回收:只要 refcnt 不为0(即使是 bpin 带来的计数),bget 在寻找空托盘时就永远不会选择它。
bunpin()

bunpin()(解锁):只有当数据被安全地写入日志层或磁盘后,文件系统才会调用 bunpin来解除这个安全锁定。
bread与bwrite
这两个函数是xv6操作系统中读写缓存块的重要接口。这2个函数用于管理内存中的数据块(struct buf),实现对磁盘I/O的缓存,提高效率。
bread
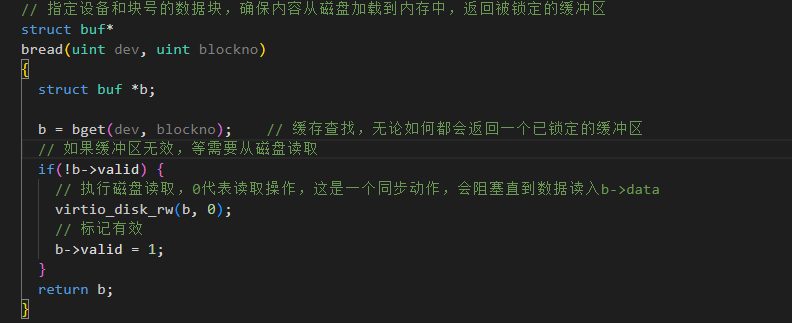
获取指定设备和块号的数据块,并确保其内容已从磁盘加载到内存中,然后返回一个被锁定的缓冲区。
缓存命中与未命中(Cache Hit/Miss):通过 bget实现了缓存查找。如果找到且 valid 为真,则缓存命中,避免了代价磁盘I/O。如果未命中或valid 为假,则缓存未命中,导致一次磁盘IO读取。
同步与互斥:缓冲区由睡眠锁保护,确保同一时间只有一个进程可以访问或修改缓冲区的内容和状态,防止竞态条件。
惰性加载:只有在缓存未命中且数据无效时才真正执行磁盘读取,这是典型的按需加载策略。
bwrite

将缓冲区b 中的内容写入到对应的磁盘位置。
同步写入:xv6的bwrite是一个同步操作,它会等待数据真正写入磁盘后才返回,确保数据的持久性。
保障写操作的原子性:由于调用前强制要求缓冲区必须被锁定,保证了在写入磁盘的整个过程中,没有其他进程可以修改缓冲区的数据,确保了写入的完整性和一致性。
Logging Layer
作用
简单来说,Logging layer 的作用就是:要么所有的修改都完整的发生在磁盘上,要么就一个都不发生,是xv6文件系统中保持崩溃-致性的关键机制。
核心机制
在之前的分层架构图中已经知道 Logging layer 在 Inode layer 之下,在Buffer Cache Layer 之上。日志层的上层不会直接调用 bwrite,而是调用 log_write 先把修改意图告诉日志层,然后日志层调用bwrite 将数据刷入磁盘。
xv6 所有的文件系统写操作(FileSystem System Calls)都遵循以下规则:
++1. 不直接写入磁盘的最终位置:所有的修改首先在内存缓冲区(Buffer Cache)中进行。
2. Log Write(commit):当所有并发的系统调用都完成后,将这些修改过的块先写入磁盘的一个特定区域---Log区++
++3. Commit Point:只有当Log区的数据完全写好,并且Log Header(记录了有哪些块)写入磁盘后,这个事务才算"提交成功"。++
++4. Install:提交成功后,再把Log区的数据复制到磁盘原本应该存储的位置(Home Location)。++
++5. Clean:最后清空 Log Header。++
核心数据结构
logheader

存储在磁盘Log区的第一个块中,其中成员变量n 表示当前 Log 中有多少个有效块,block\[\] 数组记录了每个Log块对应的原本磁盘的哪个位置,也就是扇区号。
struct log

工作流程
工作流程总结下来就是三个步骤:首先是开始事务、然后记录修改最后结束事务(提交事务)。
首先开始事务 begin_op()
每个文件系统调用(如 sys_write,sys_creat)开始调用此函数
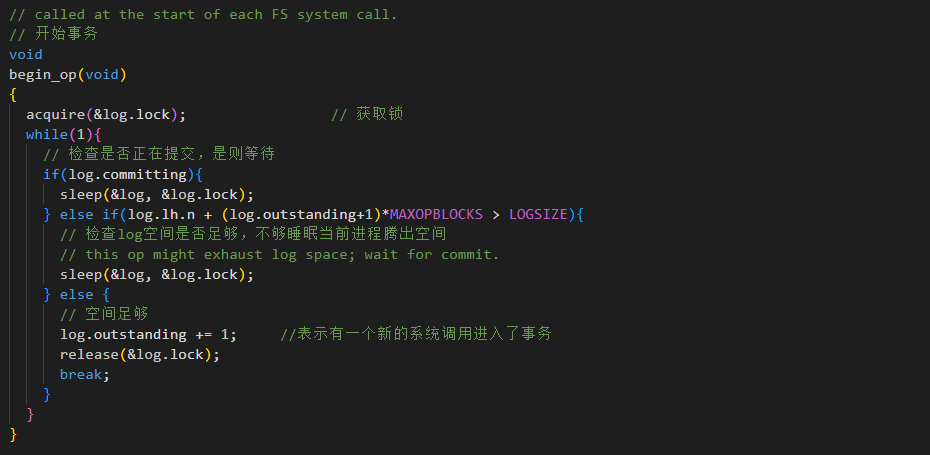
检查是否正在committing,是则睡眠等待
检查Log空间是否足够(log.lh.n+ .... >LOGSIZE)。如果不够,睡眠等待当前事务提交腾出空间
如果条件允许,log.outstanding += 1,表示有一个新的系统调用进入了事务。
记录修改 log_write(struct buf *b)
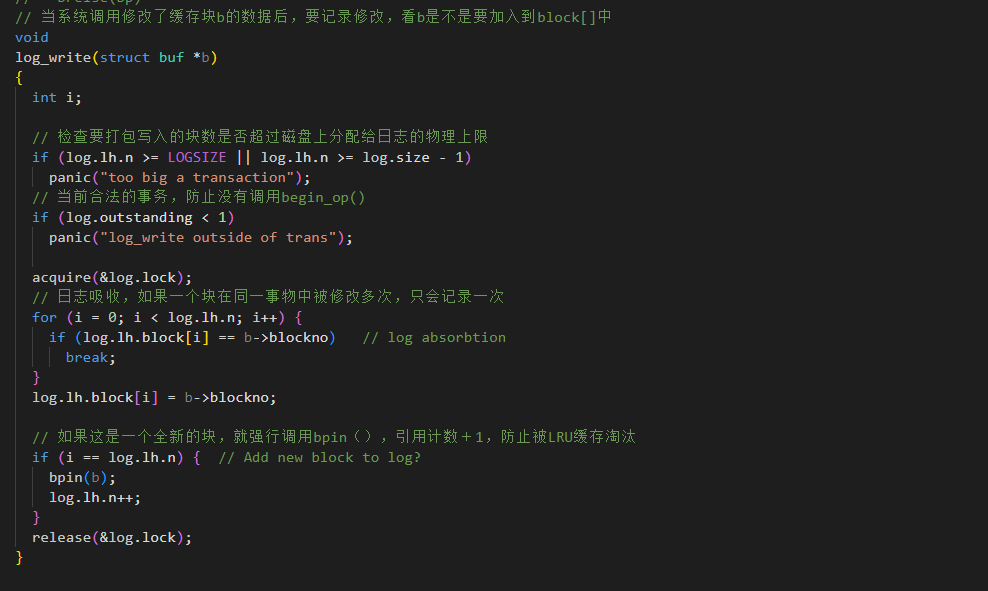
当系统调用修改了缓存块 b 的数据后,调用这个函数。
不会立即写磁盘。
将该块的块号记录在内存的 log.lh.block\[\] 数组中。
Log Absorption(日志吸收):如果同一个块在同一个事务中被修改多次,只会记录一次。
调用 bpin(b):将该块在缓存中"钉住",防止LRU缓存置换算法把它挤出内存(因为我们还没写入Log)
结束事务:end_op()
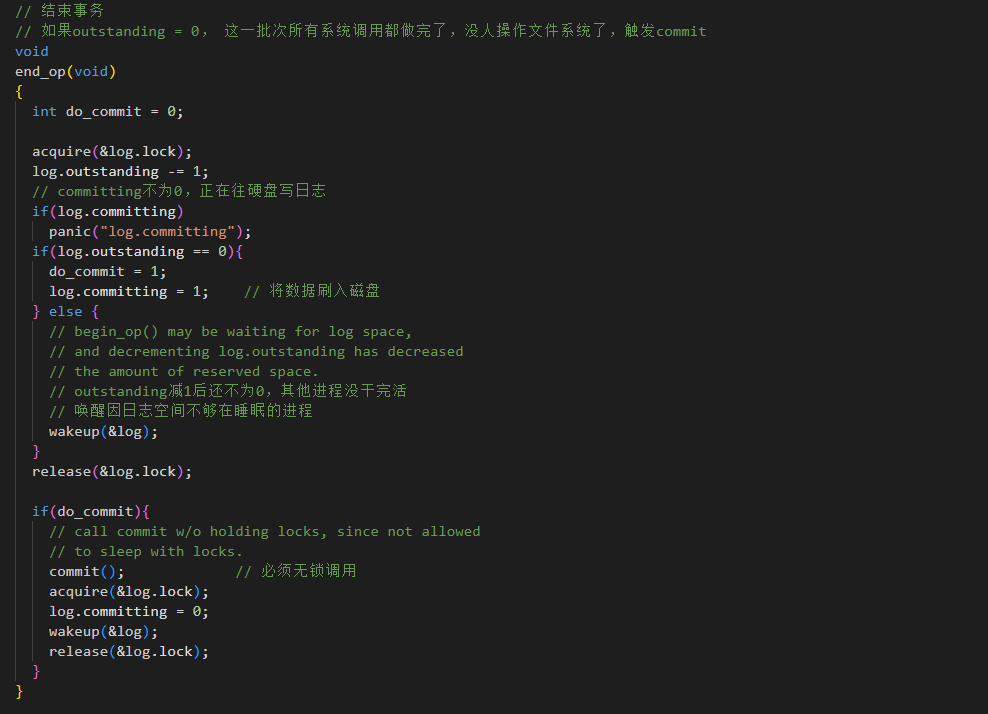
当系统调用结束了,调用这个函数。
log.outstanding -= 1.
如果outstanding减为0,说明当前这一批次的所有系统调用都做完了,没有人在操作文件系统了。
此时触发commit() 。
核心的事务提交函数:commit()
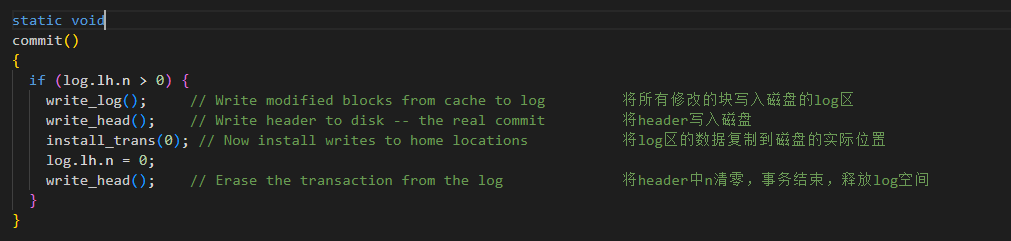
write_log():将所有修改过的缓存块(pinned blocks)写入磁盘的Log区域。
write_head():将Log Header写入磁盘。这是一次原子性的"提交点"。
install_trans(0):将Log区的数据复制到磁盘的实际位置(Home Location)。
write_head():将磁盘上的 Log Header的计数n清零。表示事务结束,释放Log空间。
崩溃恢复机制recover_from_log

Inode layer
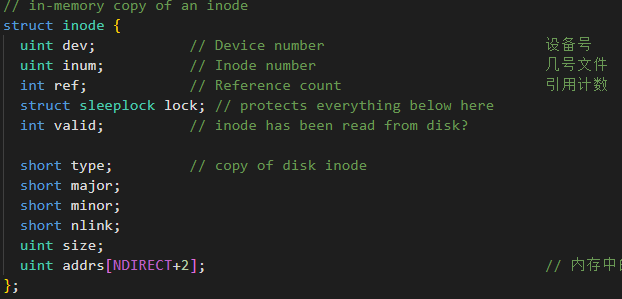
核心数据结构
Inode 是xv6文件的"灵魂",inode 除了文件的名字以外的所有信息都存放在这里。在磁盘中是dinode 在内存中是 inode,主要包含了这些内容:
inode如何使用logging layer
创建"文件",ialloc函数
当我们在代码中调用 create 时,必须分配一个新的Inode
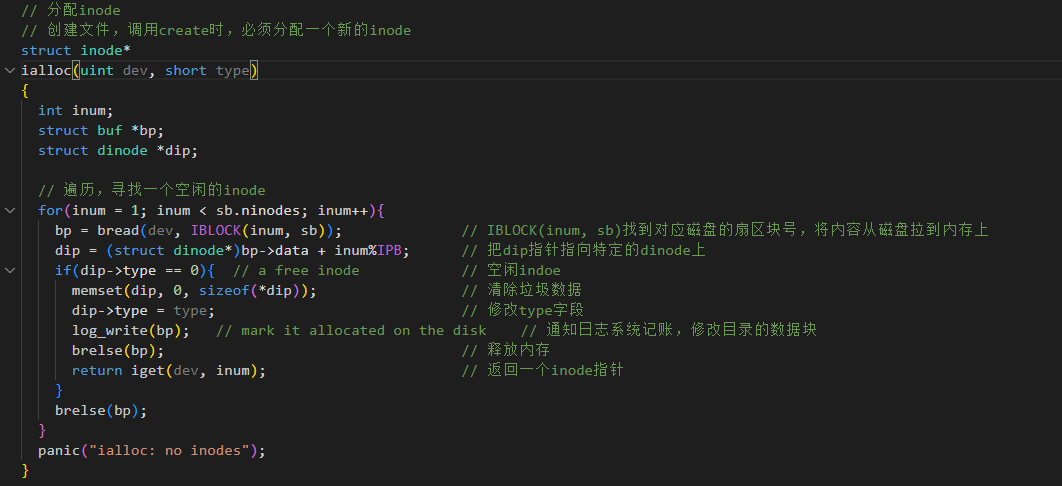
a. 首先读磁盘上的Inode块,寻找一个空闲的Inode
b. 其次修改Inode块,将这个空闲的Inode的 type 字段设置为非0
c. 然后修改目录的数据块,将新文件加入目录的数据块中
d. 最后修改目录的Inode块,更新目录Inode的size 字段
更新元数据 iupdate 函数
当我们在内存中对 inode 的结构体内容进行修改,比如说write增加了文件大小,这个时候需要同步给处于磁盘的 dinode 结构体中。

截断文件 itrunc 以及删除文件 iput

xV6基于日志层的Inode完整流程
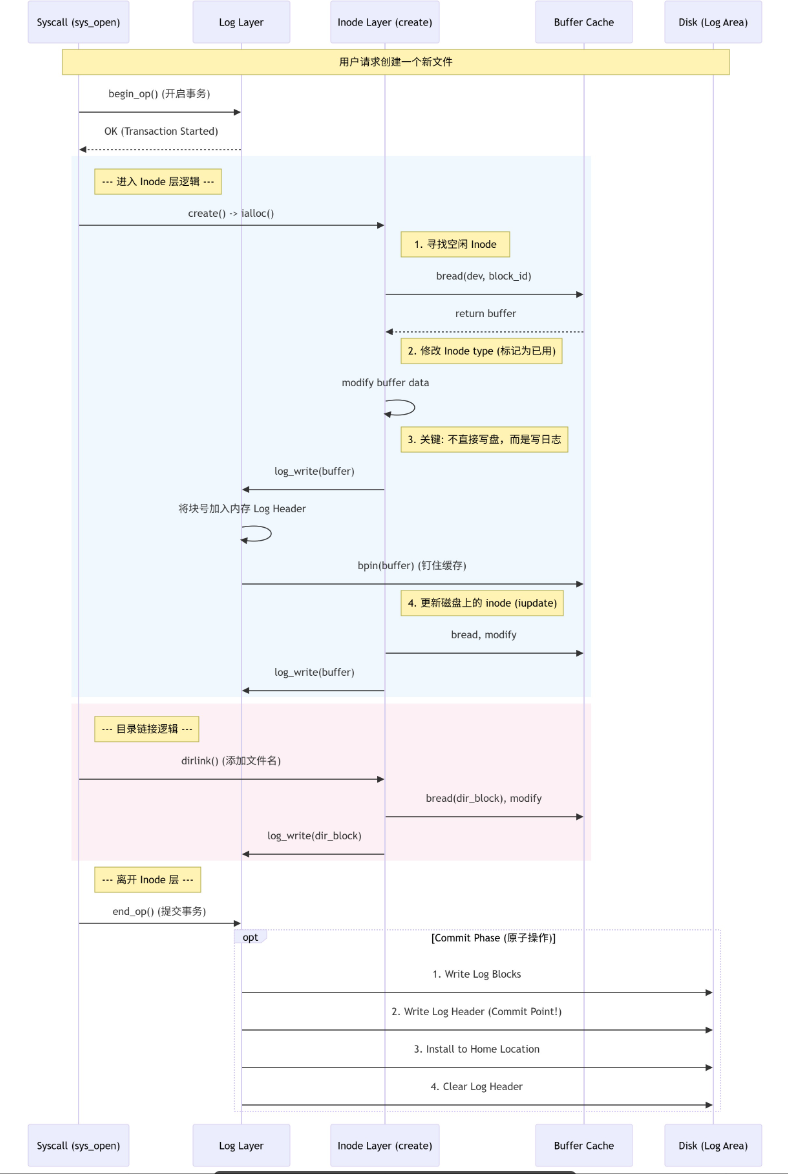
Inode层的设计原则

Directory layer
目录总结下来就有以下三个特点:
-
Inode 层面:目录的Inode 类型是T_DIR
-
数据层面:普通文件的数据块里存的是用户写的文本或二进制;目录文件的数据块里存的是一系列struct dirent
读写方式:内核使用与读写普通文件完全相同的接口(readi和writei)来读取或修改目录的内容。
核心数据结构

在xv6系统中,DIRSIZ 是14,所以 name是14字节,inum 是2字节,一共16字节。一个标准的数据块(之前提到过是1024字节)刚好就可以容纳 1024/16=64个目录。如果成员变量inum=0 表示这个目录槽是空闲的,可以被新文件使用。
主要功能
Directory 层主要提供查找(dirlookup)和 添加链接(dirlink)两个功能。
- 查找(dirlookup)
假如执行一条命令 open("/home/cat", ... )时,路径名解析层会逐层查找。当解析到home目录时,需要在 home的数据块中查找名为"cat"的条目。
dirlookup采用线性扫描。对于包含成千上万个文件的目录,这会非常慢。但是现代文件系统(如ext4,NTFS)使用 B-Tree或 哈希表 来存储目录项,将查找复杂度降低到0(log N)或o(1).
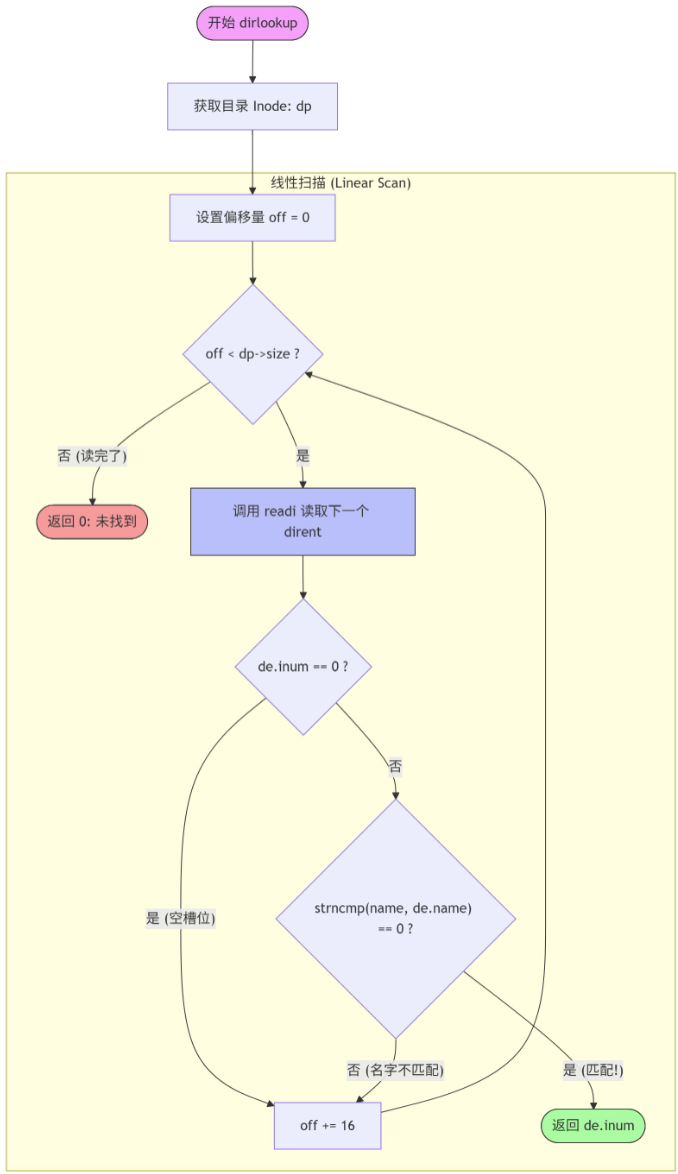
- 添加链接(dirlink
创建一个新文件(create)或者创建一个硬链接(link)时,需要在父目录中写入一个新的 dirent
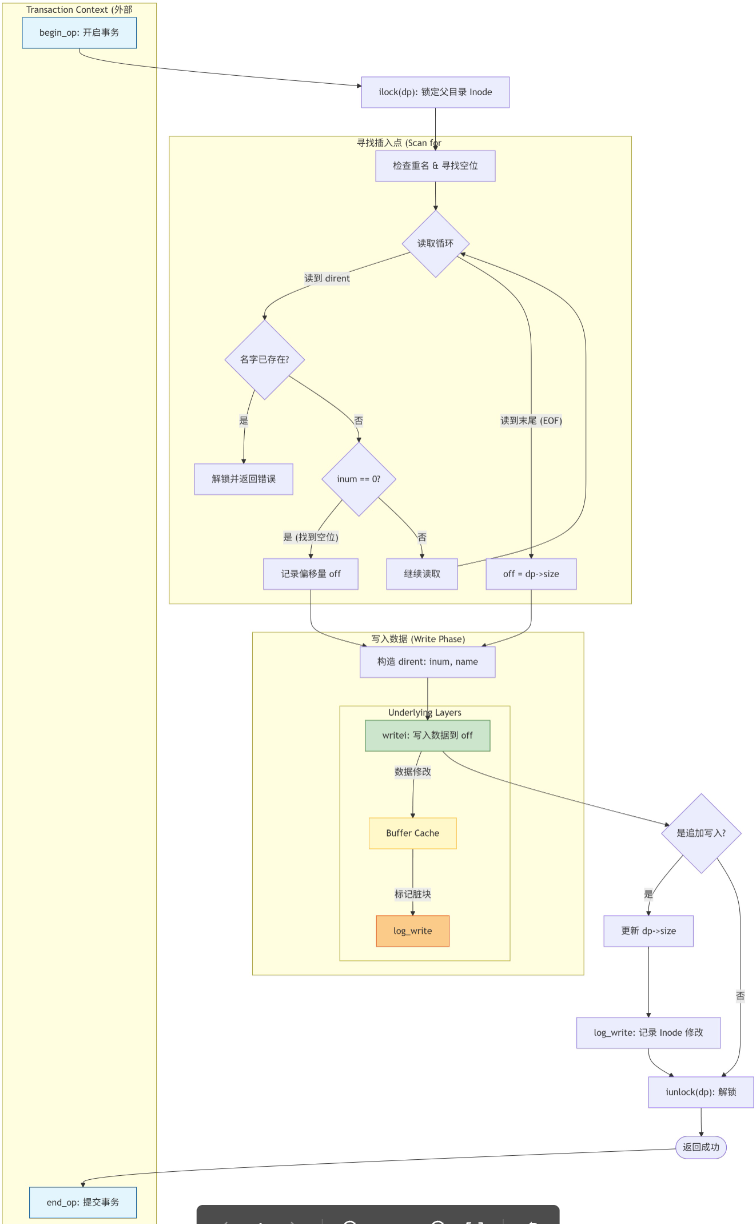
与下层的交互
我在这里直接给一个例子,我们通过这例子来看目录层和Inode层怎么交互的。
在目录dir下创建一个名为file的文件
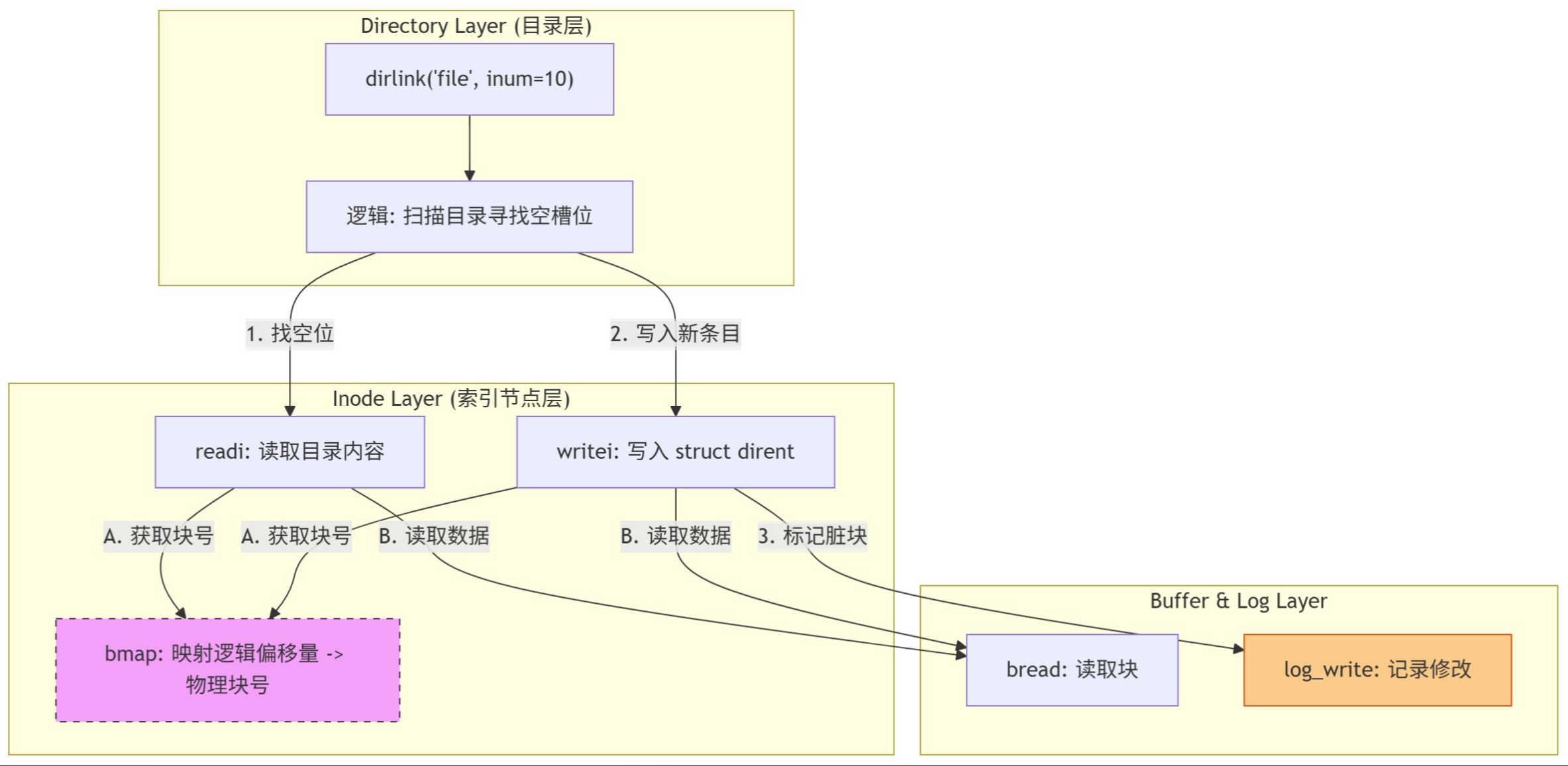
目录层总结

Pathname layer
前面介绍过 Buffer Cache 负责搬运,Logging负责记录日志,Inode 记录除了文件名之外的所有元数据,Directory记录文件名,通过文件名找到对应的inode 编号。
Ptahname层是路径名层,它的作用就是解析路径名,然后找到对应的Inode
核心函数
核心函数是namei
cpp
// 从路径中解析下一个文件名,存入name
// 返回值指向剩余的路径指针,路径结束返回0
static char*
skipelem(char *path, char *name)
{
char *s;
int len;
// 跳过前导的/
while(*path == '/')
path++;
// 路径结束
if(*path == 0)
return 0;
// 记录文件名的开始位置
s = path;
// 向后移动,直到遇到下一个斜杠或字符串结束
while(*path != '/' && *path != 0)
path++;
// 计算当前文件名的长度
len = path - s;
// 将文件名复制到name缓冲区
if(len >= DIRSIZ)
memmove(name, s, DIRSIZ);
else {
memmove(name, s, len);
name[len] = 0; // 添加字符串结束符
}
// 再次跳过后续的斜杠,准备下一次解析
while(*path == '/')
path++;
return path;
}
// Look up and return the inode for a path name.
// If parent != 0, return the inode for the parent and copy the final
// path element into name, which must have room for DIRSIZ bytes.
// Must be called inside a transaction since it calls iput().
// 路径解析
// 解析的路径 模式 接收最后一个文件名
static struct inode*
namex(char *path, int nameiparent, char *name)
{
struct inode *ip, *next;
// 确定起点,路径以'/'开始,从根目录开始
if(*path == '/')
ip = iget(ROOTDEV, ROOTINO);
else
// 从当前进程的工作目录开始
ip = idup(myproc()->cwd);
// 循环解析路径中每一个分量,skipelem来不断剥离文件名
while((path = skipelem(path, name)) != 0){
ilock(ip); // 锁定当前目录
// 检查当前inode为目录,如果不是目录,且路径没有结束,说明路径非法
if(ip->type != T_DIR){
iunlockput(ip); // 解锁并释放引用
return 0;
}
// 处理nameiparent模式
// 如果path为空字符串,说明当前name是路径的最后一个分量
// 且我们需要父目录,现在的ip就是要找的父目录
if(nameiparent && *path == '\0'){
// Stop one level early.
iunlock(ip);
return ip;
}
// 在当前目录ip中查找name的条目
// dirlookup会遍历目录数据块,找到返回inode指针
if((next = dirlookup(ip, name, 0)) == 0){
// 没找到
iunlockput(ip);
return 0;
}
// 交替加锁
// 我们现在有了当前目录ip和下一级inode next
// 我们先释放ip,然后才能处理next
// 因为我们已经拿到了next指针,ip任务完成
// 不能同时锁两个inode(除非有严格顺序),否则容易死锁
iunlockput(ip); // 解除ip,引用计数-1
ip = next; // 指针下移,当前next变为下一轮ip
}
// 处理nameiparent的情况
// 循环结束,说明路径解析完了
// 如果要求解析父目录,但代码跑到这里
// 说明没能提前在循环里返回,错误
if(nameiparent){
iput(ip);
return 0;
}
return ip;
}
// 解析路径,返回对应的inode
struct inode*
namei(char *path)
{
char name[DIRSIZ];
// 调用namex,模式为0(查找目标文件本身)
return namex(path, 0, name);
}
// 解析路径,返回其父目录的inode,将最后的文件名拷入name
// 用于创建新文件活(sys_open)或删除文件(sys_unlink)
struct inode*
nameiparent(char *path, char *name)
{
// 调用namex,模式1(查找父目录)
return namex(path, 1, name);
}交替加锁(Hand-over-Hand Locking)

File Descriptor layer
核心数据结构
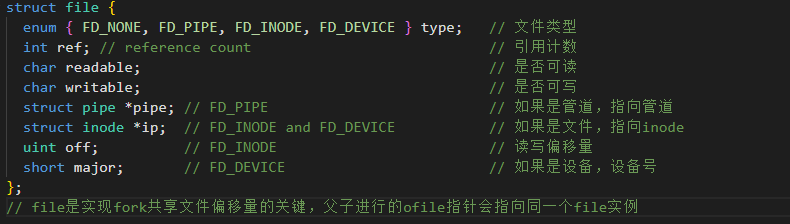
type:决定了read()到底调用底层的哪个函数(是读磁盘 readi,还是读管道piperead)。
off(偏移量):请注意,偏移量是保存在struct file 里的,而不是struct inode 里的!这意味着多个进程打开同一个文件,各自有独立的进度条(除非它们是通过fork 或dup共享的)。
映射关系
本层有三个关键的表,分别是进程级文件表(proc->ofile)、系统级打开文件表(ftable)以及底层资源
Inode/pipe ).
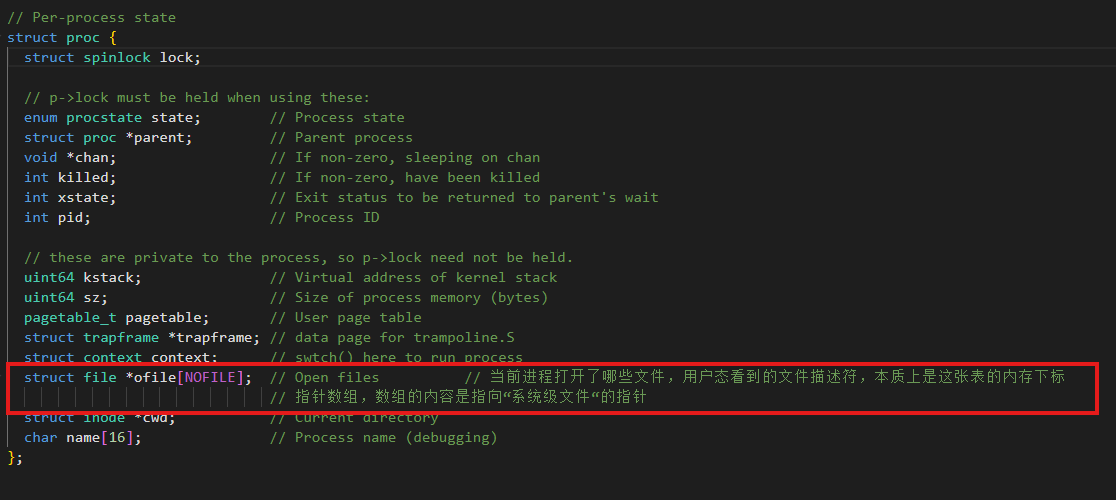
程级文件表(proc->ofile)
此表是初始的,每个进程都有一个。它定义了"当前进程打开了哪些文件"。我们在用户态看到的fd(整数0,1,2 ... ),本质上就是这张表的内存下标。
当调用 read(3,...)时,内核通过 current_proc()->ofile3找到对应的struct file*指针。
系统级打开文件表(ftable)
这个表是全局的(Global),整个操作系统只有一份。存放了所有进程打开的文件的动态状态。
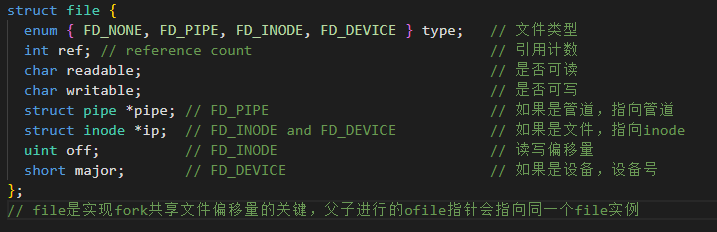

struct file 是实现fork 共享文件偏移量的关键。父子进程的ofile 指针会指向同一个struct file实例。
底层资源
该表代表了物理文件本身。它存储文件的元数据(大小、磁盘位置等)。无论有多少个进程打开同一个文件,对应的Inode在内存中只有一个。

struct file 通过 ip 指针指向 struct inode.
核心代码
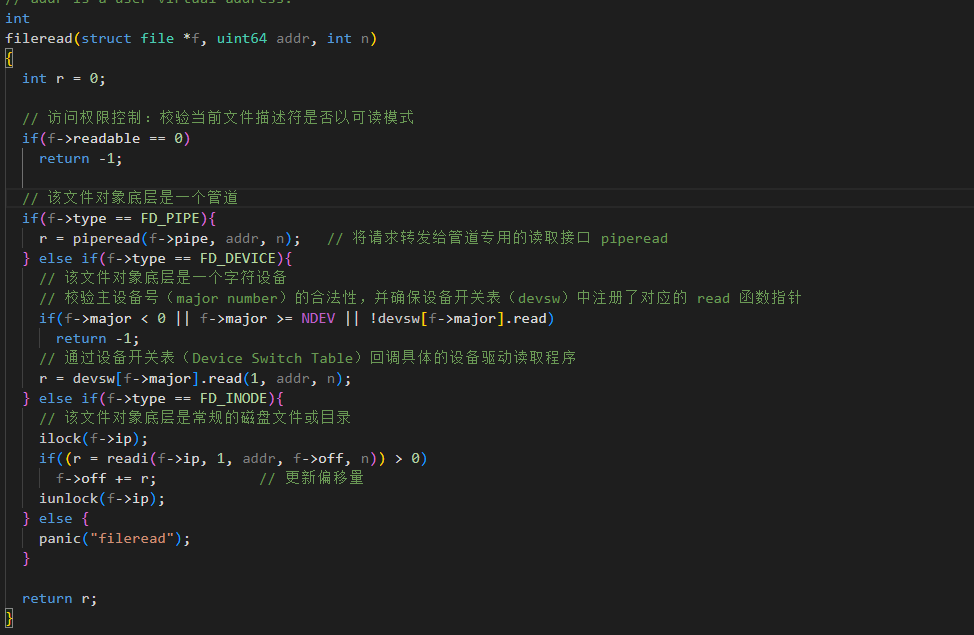
fileread
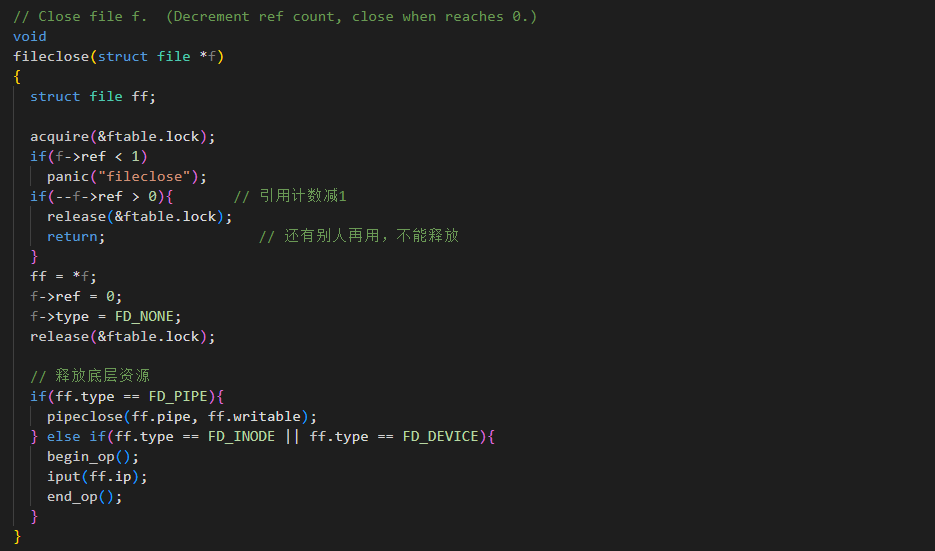
fileclose
Large files

核心解决方案就是将旧结构:12个直接块+1个单重间接块。容量=12+256=268
更新为新的结构:11个直接块+1个单重引用块+1个双重引用块。
双重链接块的原理:
· inode的第13个地址指向一个"一级索引块"。
·"这个一级索引块"里存储了256个地址,每个地址都指向一个"二级索引块"。
·每个"二级索引块"里存储了256个数据块地址。
· 容量增量=256*256=65536。
· 总容量=11+256+65536=65803
第一步
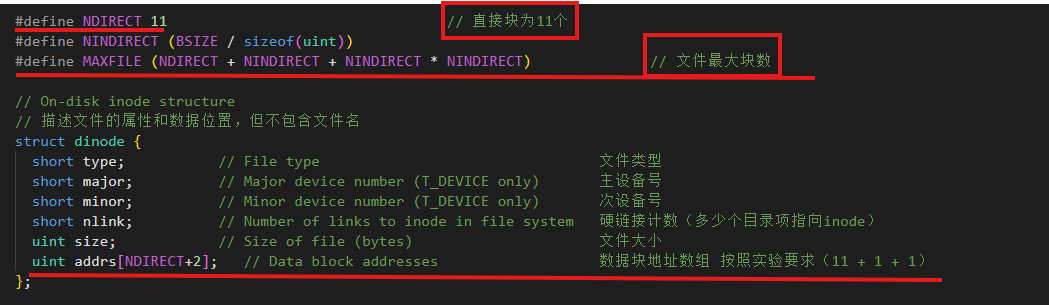
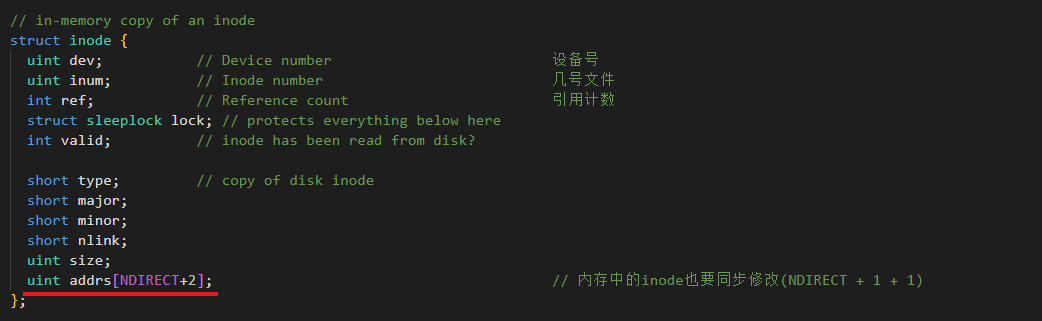
修改文件系统的参数,原来为12个直接索引+1个间接索引,现在为11个直接索引+1个一重间接索引+1个二重间接索引
磁盘上的inode要修改,内存上的inode也要修改(防止内存越界问题)
第二步
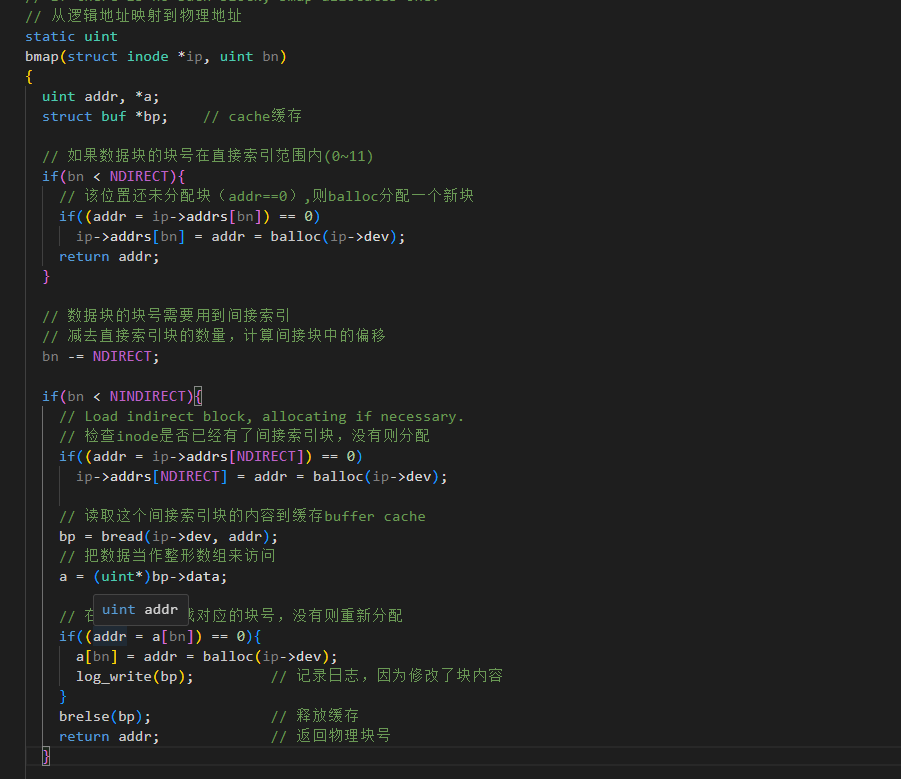
修改bmap,之前是输入一个逻辑块号,输出这个数据块在硬盘上的真实物理块号,但现在新增了许多数据块,如果这个物理块还没有分配,就要线程分配一个物理块
cpp
// 从逻辑地址映射到物理地址
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp; // cache缓存
// 如果数据块的块号在直接索引范围内(0~11)
if(bn < NDIRECT){
// 该位置还未分配块(addr==0),则balloc分配一个新块
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
// 数据块的块号需要用到间接索引
// 减去直接索引块的数量,计算间接块中的偏移
bn -= NDIRECT;
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
// 检查inode是否已经有了间接索引块,没有则分配
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
// 读取这个间接索引块的内容到缓存buffer cache
bp = bread(ip->dev, addr);
// 把数据当作整形数组来访问
a = (uint*)bp->data;
// 在整形数组里找对应的块号,没有则重新分配
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp); // 记录日志,因为修改了块内容
}
brelse(bp); // 释放缓存
return addr; // 返回物理块号
}
// 处理二级间接块
bn -= NINDIRECT;
if (bn < NINDIRECT * NINDIRECT) {
if ((addr = ip->addrs[NDIRECT + 1]) == 0) {
ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);
}
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
uint l1_idx = bn / NINDIRECT;
if((addr = a[l1_idx]) == 0){
a[l1_idx] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp); // 释放一级索引块
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
// 逻辑块号对 256 取模获取其在二级索引中的槽位
uint l2_idx = bn % NINDIRECT;
if((addr = a[l2_idx]) == 0){
a[l2_idx] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp); // 释放二级索引块
return addr;
}
panic("bmap: out of range");
}-
减去前两部分的配额:让逻辑块号
bn先减去NDIRECT,再减去NINDIRECT。如果剩下的bn小于NINDIRECT * NINDIRECT,说明它落在了二级间接块的管辖范围内。 -
定位一级目录(树干): 用
bn / 256算出它在一级目录树里的索引。如果没有这层目录,现场balloc分配一个物理块,并记录到ip->addrs[12]。 -
定位二级目录(树枝): 用
bn % 256算出它在二级目录树里的索引。如果没有这层目录,再分配一个物理块。 -
返回最终拿到的真实物理块号。
第三步
既然文件变大了,当用户执行 rm 删除文件,或者清空文件时,你必须把刚才建的双重索引也释放掉
cpp
void
itrunc(struct inode *ip)
{
int i, j, k;
struct buf *bp, *bp2;
uint *a, *a2;
// 1. 释放直接块
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
// 2. 释放一级间接块及其挂载的数据块
if(ip->addrs[NDIRECT]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
// 3. 释放二级间接块的完整树状结构
if(ip->addrs[NDIRECT+1]){
bp = bread(ip->dev, ip->addrs[NDIRECT+1]); // 读入一级索引块
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j]){
bp2 = bread(ip->dev, a[j]); // 读入对应的二级索引块
a2 = (uint*)bp2->data;
for(k = 0; k < NINDIRECT; k++){
if(a2[k]){
bfree(ip->dev, a2[k]); // 释放最底层的真实数据块
}
}
brelse(bp2);
bfree(ip->dev, a[j]); // 释放该二级索引块自身
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT+1]); // 释放最顶层的一级索引块自身
ip->addrs[NDIRECT+1] = 0;
}
ip->size = 0;
iupdate(ip); // 更新 inode 的磁盘状态
}Symbolic links
创建符号链接的本质就是创建一个文件,之前介绍过普通文件的Inode类型是T_FILE,目录是T_DIR,所以这里添加一个符号链接 T_SYMLINK;而且普通文件存放用户数据,符号链接存放目标路径的字符串。
第一步
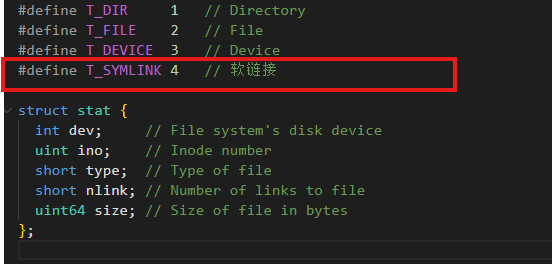
操作系统需要一种机制来区分"这只是一个普通的数据文件"和这是一个符号链接,所以我们需要在在
kernel/stat.h 中添加Inode类型 T_SYMLINK。当操作系统读到一个Inode时,首先检查它的 type。如
果是 T FILE,它就直接读数据;如果是T SYMLINK,它知道数据块里存的不是内容,而是另一个路径。
第二步
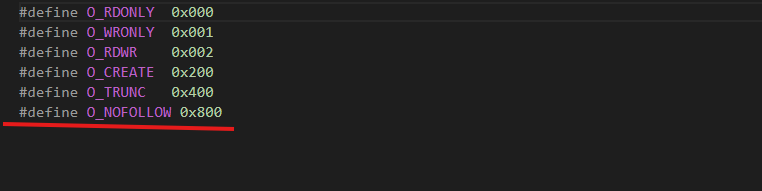
定义不追踪标记。 打开kernel/fcntl.h,增加一个宏 #define O_NOFOLLOW 0x800(我就想打开快捷方式本身去看看或修改,而不是顺着快捷方式去打开原文件)

第三步
完成sys_symlink系统调用
a.获取用户传入的target(指向的目标路径)和path(新建的软链接文件路径)
b. 涉及创建文件和写入数据,必须包裹在begin_op()和end_op()之间
c. 调用create函数创建一个类型为T_SYMLINK的新 Inode
d. 将target路径字符串直接写入这个新Inode的数据块中

第四步
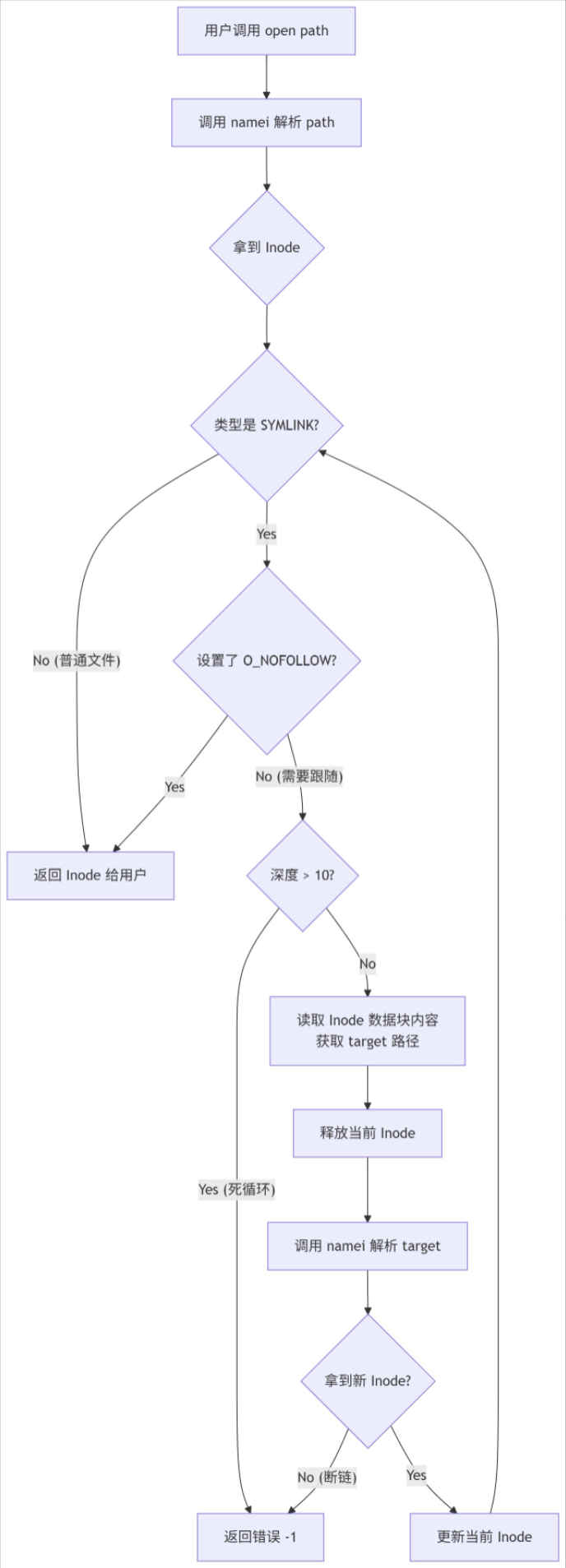
在软链接中对打开文件的核心逻辑是:
初始查找:调用namei (path)找到对应的inode。
符号链接循环(Symlink Loop):
触发条件:如果 inode类型是T_SYMLINK且没有设置0_NOFOLLOW 标志。
死循环保护:使用 depth计数器,一旦超过10层,视为死循环,报错返回。
读取链接:使用readi读取 inode数据块中的目标路径。
释放旧锁:iunlockput当前 inode。
查找新目标:namei查找目标路径,更新 inode指针。
递归:锁定新inode,回到循环开头再次检查(因为新目标可能还是个软链接)。
cpp
uint64
sys_open(void)
{
char path[MAXPATH];
int fd, omode;
struct file *f;
struct inode *ip;
int n;
if((n = argstr(0, path, MAXPATH)) < 0 || argint(1, &omode) < 0)
return -1;
begin_op();
if(omode & O_CREATE){
ip = create(path, T_FILE, 0, 0);
if(ip == 0){
end_op();
return -1;
}
} else {
if((ip = namei(path)) == 0){
end_op();
return -1;
}
ilock(ip);
if(ip->type == T_DIR && omode != O_RDONLY){
iunlockput(ip);
end_op();
return -1;
}
}
// 2. 软链接解析核心逻辑 (新增部分)
// 当文件类型为 T_SYMLINK,且未指定 O_NOFOLLOW 标志时,执行解析
int depth = 0;
while(ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)){
// 防御机制 1:限制最大递归深度为 10,防止 A -> B -> A 循环链接导致内核死机
if(depth++ >= 10){
iunlockput(ip);
end_op();
return -1;
}
// 防御机制 2:检查软链接内存储的路径长度是否超出系统上限
if(ip->size >= MAXPATH){
iunlockput(ip);
end_op();
return -1;
}
// 从软链接的数据块中读取目标路径字符串,覆盖当前的 path 数组
if(readi(ip, 0, (uint64)path, 0, ip->size) != ip->size){
iunlockput(ip);
end_op();
return -1;
}
// 手动添加字符串结束符,防止越界
path[ip->size] = '\0';
// 释放当前软链接的 inode,因为我们要去寻找新路径的 inode 了
iunlockput(ip);
// 根据新读取到的目标路径,重新查找 inode
if((ip = namei(path)) == 0){
end_op();
return -1;
}
// 给新找到的 inode 加锁,进入下一轮 while 判断(因为它可能依然是个软链接)
ilock(ip);
}
if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){
iunlockput(ip);
end_op();
return -1;
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
if(f)
fileclose(f);
iunlockput(ip);
end_op();
return -1;
}
if(ip->type == T_DEVICE){
f->type = FD_DEVICE;
f->major = ip->major;
} else {
f->type = FD_INODE;
f->off = 0;
}
f->ip = ip;
f->readable = !(omode & O_WRONLY);
f->writable = (omode & O_WRONLY) || (omode & O_RDWR);
if((omode & O_TRUNC) && ip->type == T_FILE){
itrunc(ip);
}
iunlock(ip);
end_op();
return fd;
}