一、研究背景
在机器学习分类任务中,支持向量机(SVM)是一种性能优异的模型,但其分类精度高度依赖于惩罚参数 c 和核函数参数 g(如RBF核的带宽)。传统网格搜索或随机搜索效率低且难以找到全局最优参数。牛顿-拉夫逊优化算法(Newton-Raphson-Based Optimizer, NRBO)是一种新型元启发式优化算法,模拟牛顿-拉夫逊迭代法的数值寻优思想,具有收敛速度快、全局搜索能力强的特点。将该算法用于SVM参数自动调优,可提升分类模型的准确率与泛化能力。同时,代码引入SHAP(Shapley Additive Explanations)方法对模型决策进行可解释性分析,帮助理解各特征对预测结果的贡献。
二、主要功能
- 数据预处理:读取Excel数据集,随机打乱,按类别分层划分训练集(70%)和测试集(30%)。
- SVM参数优化 :使用NRBO算法自动搜索最优的SVM惩罚参数 c 和核参数 g。
- SVM训练与预测:基于最优参数训练SVM模型,对训练集和测试集进行预测。
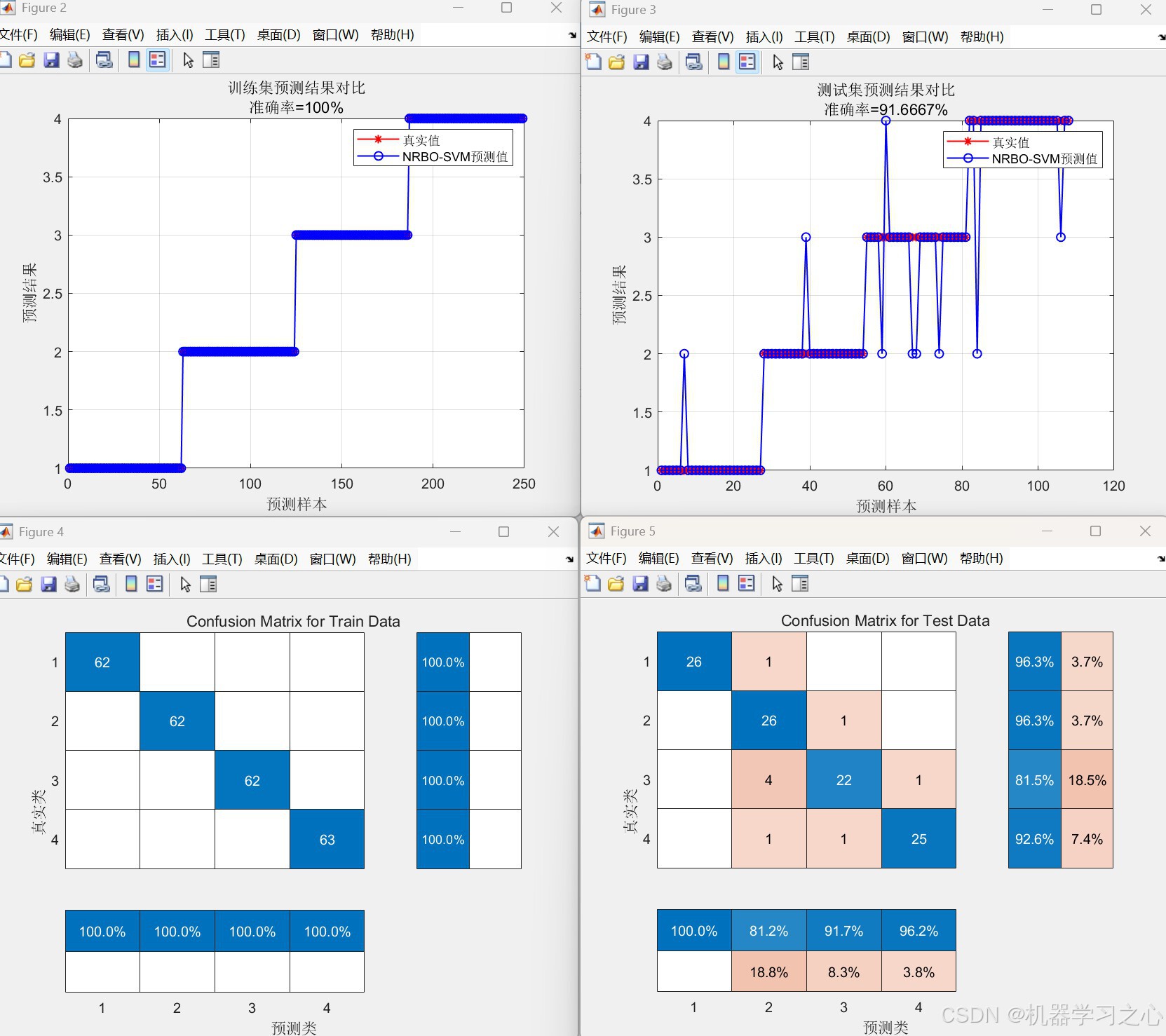
- 性能评估:计算训练/测试准确率,绘制预测结果对比图、混淆矩阵。
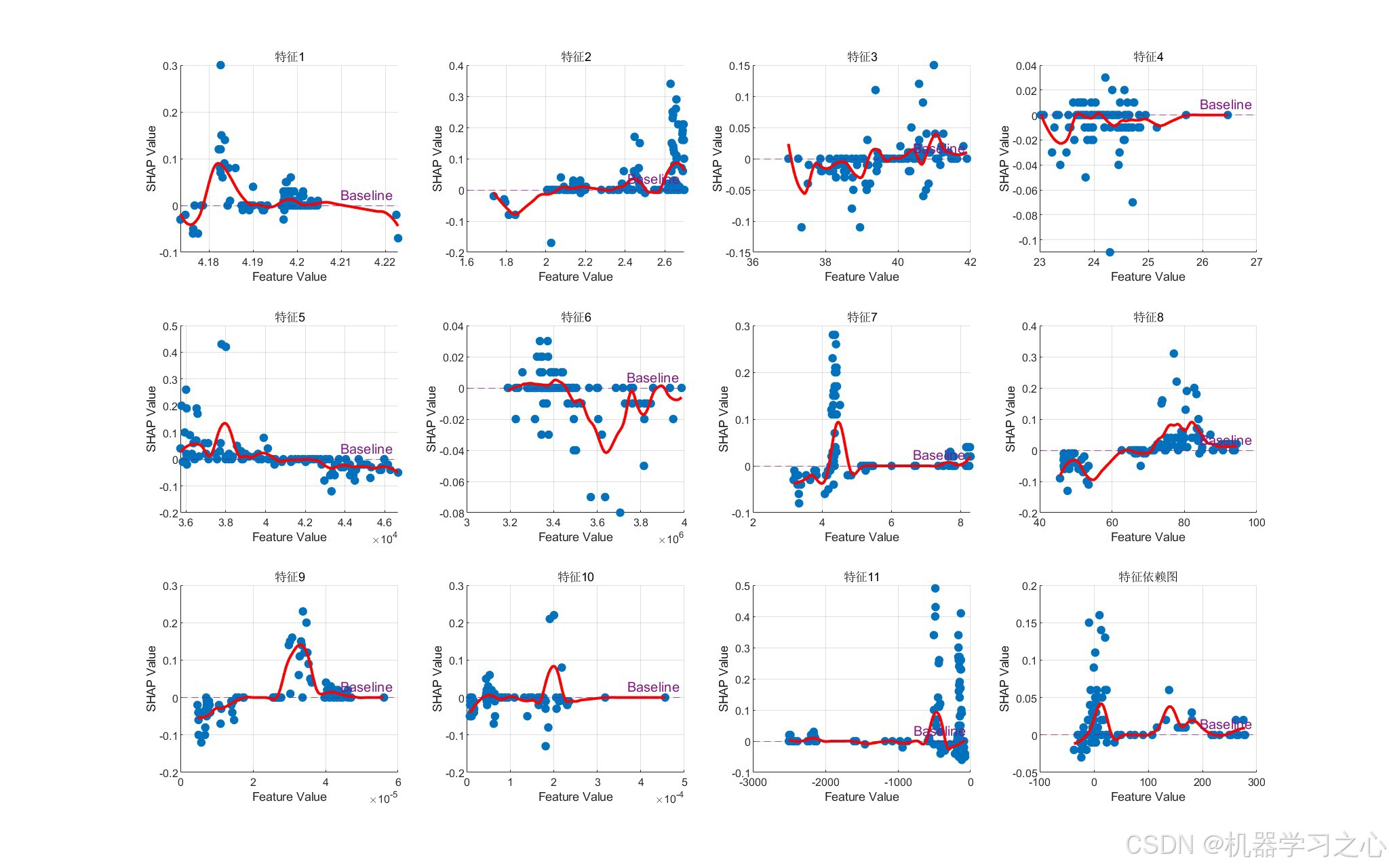
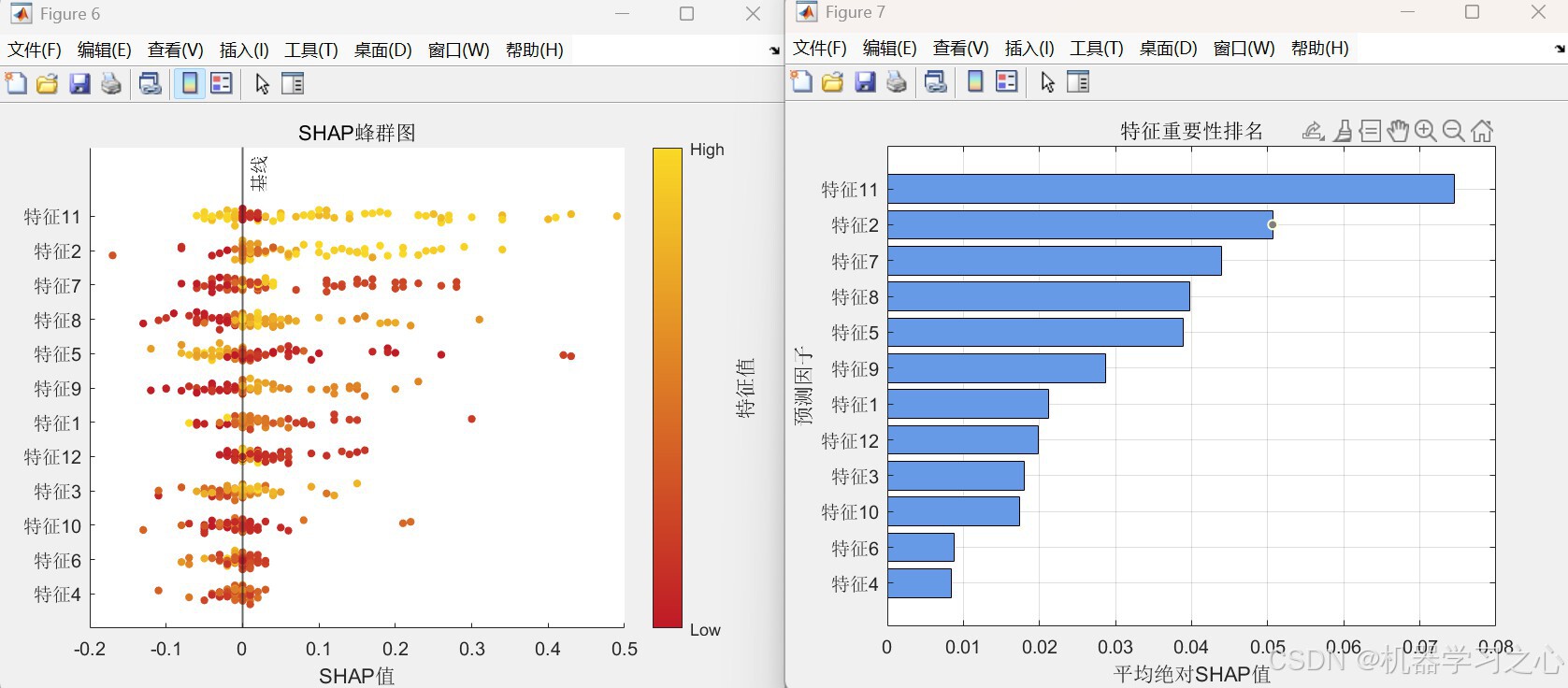
- 模型解释:利用SHAP值分析特征重要性,绘制摘要图、条形图和特征依赖图。
三、算法步骤
-
数据准备
- 读取
数据集.xlsx,最后一列为类别标签。 - 随机打乱样本顺序,按类别分层抽取70%作为训练集,30%作为测试集。
- 对训练集输入特征进行0,1归一化,并用相同参数归一化测试集。
- 读取
-
NRBO优化SVM参数
- 设定种群数量
pop=10,最大迭代次数Max_iteration=10。 - 优化变量为(c, g),搜索范围:c∈10⁻³, 10³,g∈1, 2⁸。
- 适应度函数
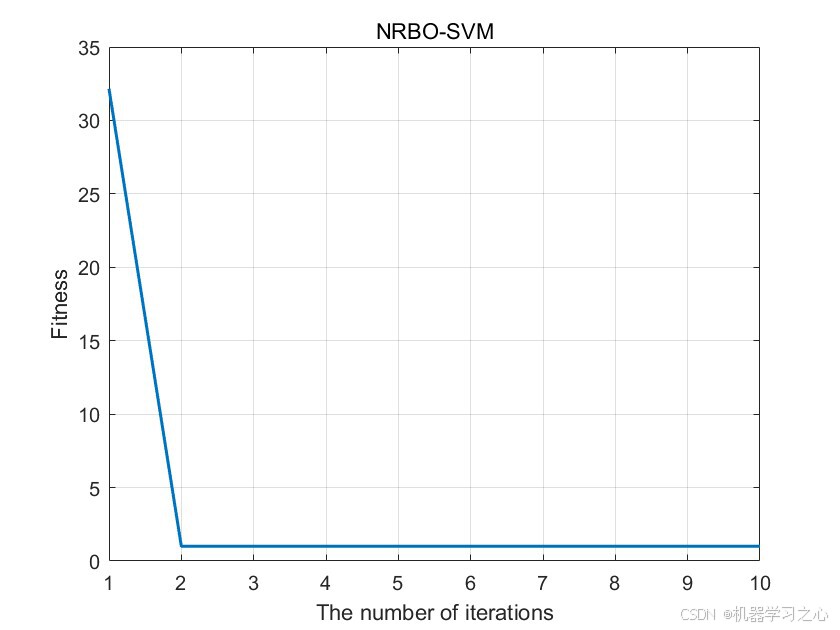
getObjValue(未给出完整代码,通常为SVM在训练集上的交叉验证错误率或分类错误率)。 - NRBO迭代寻优,输出最优(c, g)及收敛曲线。
- 设定种群数量
-
训练最终SVM模型
- 使用最优(c, g)配置libsvm参数:
-s 0 -t 2(C-SVC,RBF核)。 - 在训练集上训练SVM模型。
- 使用最优(c, g)配置libsvm参数:
-
预测与评价
- 对训练集和测试集分别预测,计算准确率,绘制真实值与预测值的对比折线图及混淆矩阵。
-
SHAP分析(对测试集)
- 选取测试集全部样本(或自定义数量)计算SHAP值。
- 以训练集特征均值为参考值,调用
shapley_1函数计算每个样本各特征的SHAP值。 - 绘制SHAP摘要图(散点图+颜色映射)、特征重要性条形图(平均绝对SHAP值)、特征依赖图。
四、技术路线
Excel原始数据 → 分层采样划分训练/测试集 → 特征归一化
↓
NRBO算法初始化种群(c,g)
↓
计算适应度(SVM交叉验证误差)
↓
更新种群(牛顿-拉夫逊搜索机制)
↓
满足终止条件? → 输出最优(c,g)
↓
训练最终SVM模型 → 预测与评估
↓
SHAP可解释性分析(特征重要性、依赖关系)五、公式原理
1. NRBO(牛顿-拉夫逊优化算法)
NRBO模拟牛顿-拉夫逊迭代公式进行种群位置更新。牛顿-拉夫逊法用于求解方程 f(x)=0 的根,迭代公式为:
xn+1=xn−f(xn)f′(xn) x_{n+1} = x_n - \frac{f(x_n)}{f'(x_n)} xn+1=xn−f′(xn)f(xn)
NRBO将其扩展至多维优化问题,利用当前种群个体的梯度信息(或差分近似)引导搜索方向,同时引入随机扰动和边界处理策略,实现全局与局部搜索的平衡。其核心更新公式可概括为:
Xnew=Xcurrent−f(Xcurrent)f′(Xcurrent)+随机项 X_{\text{new}} = X_{\text{current}} - \frac{f(X_{\text{current}})}{f'(X_{\text{current}})} + \text{随机项} Xnew=Xcurrent−f′(Xcurrent)f(Xcurrent)+随机项
其中 f 为适应度函数,f' 通过差分或邻域信息估计。
2. SVM分类模型
采用C-SVC(分类类型),RBF核函数:
K(xi,xj)=exp(−γ∥xi−xj∥2),γ=g K(x_i, x_j) = \exp(-\gamma \|x_i - x_j\|^2), \quad \gamma = g K(xi,xj)=exp(−γ∥xi−xj∥2),γ=g
优化目标为:
minw,b,ξ12∥w∥2+C∑i=1nξi \min_{w,b,\xi} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^n \xi_i w,b,ξmin21∥w∥2+Ci=1∑nξi
s.t. yi(wTϕ(xi)+b)≥1−ξi,ξi≥0y_i (w^T \phi(x_i) + b) \ge 1 - \xi_i, \xi_i \ge 0yi(wTϕ(xi)+b)≥1−ξi,ξi≥0
其中 C=c 为惩罚参数,g 控制核函数宽度。
3. SHAP值
SHAP基于博弈论中的Shapley值,将每个特征视为一个"玩家",预测值视为总收益。特征 i 的SHAP值计算公式为:
ϕi=∑S⊆F∖{i}∣S∣!(∣F∣−∣S∣−1)!∣F∣!fS∪{i}(xS∪{i})−fS(xS) \phi_i = \sum_{S \subseteq F \setminus \{i\}} \frac{|S|! (|F|-|S|-1)!}{|F|!} \left f_{S \\cup \\{i\\}}(x_{S \\cup \\{i\\}}) - f_S(x_S) \\right ϕi=S⊆F∖{i}∑∣F∣!∣S∣!(∣F∣−∣S∣−1)!fS∪{i}(xS∪{i})−fS(xS)
其中 F 为所有特征的集合,S 为不包含 i 的特征子集,f_S 表示仅使用特征子集 S 时的模型预测输出。代码中通过近似方法(如Kernel SHAP)计算每个样本各特征的SHAP值。
六、参数设定
| 参数名 | 值/范围 | 说明 |
|---|---|---|
num_size |
0.7 | 训练集比例 |
pop |
10 | NRBO种群规模 |
Max_iteration |
10 | NRBO最大迭代次数 |
lb |
1e-3, 1 | 优化变量下界 (c, g) |
ub |
1e3, 2\^8=256 | 优化变量上界 (c, g) |
cmd |
-s 0 -t 2 |
SVM类型:C-SVC,核函数:RBF |
flag_conusion |
1 | 是否绘制混淆矩阵 |
numShapSamples |
N(测试集样本数) | SHAP分析的样本数量 |
七、运行环境
- 软件:MATLAB(建议2023b及以上版本)
- 数据文件 :
数据集.xlsx需与脚本在同一目录或提供正确路径
八、应用场景
该代码适用于中小规模的多分类或二分类问题,特别是当特征数量适中(代码示例中特征数为12)。典型应用包括:
- 医学诊断:基于生理指标(血压、血糖等)预测疾病类型。
- 工业故障诊断:根据传感器数据(振动、温度)识别设备故障模式。
- 金融信用评分:利用客户属性(收入、负债等)评估信用等级。
- 图像分类(特征已提取):如手写数字识别、物体分类。
- 生物信息学:基因表达数据分类(如肿瘤亚型识别)。