深入探究可迁移的对抗样本与黑盒攻击
闫培刘*,陈心韵* 上海交通大学
刘畅,宋 dawn 加州大学伯克利分校
摘要
深度神经网络的一个有趣特性是存在对抗样本,这些样本可以在不同架构之间迁移。这些可迁移的对抗样本可能会严重阻碍基于深度神经网络的应用。先前的工作大多使用小规模数据集研究可迁移性。在这项工作中,我们首次在大规模数据集上对大型模型进行可迁移性的广泛研究,并且也是首次研究带有目标标签的针对性对抗样本的可迁移性。我们研究了非针对性和针对性对抗样本,并表明虽然可迁移的非针对性对抗样本很容易找到,但使用现有方法生成的针对性对抗样本几乎从不随其目标标签迁移。因此,我们提出了新的基于集成的生成可迁移对抗样本的方法。使用这些方法,我们首次观察到有相当大比例的针对性对抗样本能够随其目标标签一起迁移。我们还进行了一些几何研究以帮助理解可迁移的对抗样本。最后,我们展示了使用基于集成的方法生成的对抗样本可以成功攻击 Clarifai.com,这是一个黑盒图像分类系统。
1 引言
最近的研究表明,对于深度架构,很容易生成对抗样本,这些样本与原始样本非常接近,但会被深度架构错误分类 (Szegedy et al. (2013); Goodfellow et al. (2014))。这种对抗样本的存在可能会产生严重后果,阻碍基于视觉理解的应用,例如自动驾驶。这些研究大多需要明确知道底层模型。如何有效地为黑盒模型找到对抗样本仍然是一个悬而未决的问题。
一些工作已经证明,为一个模型生成的一些对抗样本也可能被另一个模型错误分类。这种属性被称为可迁移性,可用于执行黑盒攻击。该属性已被用于构建黑盒模型的替代模型,并针对替代模型生成对抗实例来攻击黑盒系统 (Papernot et al. (2016a;b))。然而,到目前为止,可迁移性主要是在小型数据集上检验的,如 MNIST (LeCun et al. (1998)) 和 CIFAR-10 (Krizhevsky & Hinton (2009))。在大规模数据集(如 ImageNet (Russakovsky et al. (2015)))上的可迁移性还有待更好地理解。
在这项工作中,我们首次对应用于不同最先进模型(这些模型在大规模数据集上训练)的不同对抗实例生成策略的可迁移性进行了广泛研究。我们特别研究了两种类型的对抗样本:(1) 非针对性对抗样本,可以被网络错误分类,无论错误分类的标签是什么;(2) 针对性对抗样本,可以被网络分类为目标标签。我们检验了几种基于单个模型搜索对抗样本的现有方法。虽然非针对性对抗样本更容易迁移,但我们观察到很少有针对性对抗样本能够随其目标标签迁移。
我们进一步提出了一种新的策略,使用多个模型的集成来生成可迁移的对抗图像。在我们的评估中,我们观察到这种新策略可以生成非针对性对抗实例,其可迁移性优于本文检验的其他方法。同时,我们首次观察到有相当大比例的针对性对抗样本能够随其目标标签迁移。
我们研究了评估中模型的几何特性。特别是,我们展示了不同模型的梯度方向彼此正交。我们还展示了不同模型的决策边界彼此对齐良好,这在一定程度上解释了为什么对抗样本可以迁移。
最后,我们研究了生成的对抗图像是否可以攻击 Clarifai.com,这是一家提供最先进图像分类服务的商业公司。我们不知道 Clarifai.com 使用的训练数据集和模型类型;同时,Clarifai.com 的标签集与 ImageNet 的标签集有很大不同。我们展示了即使在这种情况下,非针对性和针对性对抗图像都能迁移到 Clarifai.com。这是首个记录为黑盒最先进在线图像分类系统(其模型和训练数据集对攻击者未知)成功生成非针对性和针对性对抗样本的工作。
贡献与组织结构。我们总结主要贡献如下:
对于 ImageNet 模型,我们展示了虽然现有方法能有效生成可迁移的非针对性对抗样本(第 3 节),但现有方法生成的针对性对抗样本中,只有极少数能够迁移(第 4 节)。我们提出了新的基于集成的方法来生成对抗样本(第 5 节)。我们的方法首次使得大部分针对性对抗样本能够在多个模型之间迁移。我们首次展示了为在 ImageNet 上训练的模型生成的针对性对抗样本可以迁移到黑盒系统,即 Clarifai.com,其模型、训练数据和标签集对我们都是未知的(第 7 节)。特别是,Clarifai.com 的标签集与 ImageNet 的标签集非常不同。我们对在 ImageNet 上训练的大型模型进行了首次几何特性分析(第 6 节),结果揭示了一些有趣的发现,例如不同模型的梯度方向彼此正交。
在下文中,我们首先讨论相关工作,然后在第 2 节介绍背景知识和实验设置。然后,我们在上述相应章节中介绍我们的每个实验和结论。
相关工作。对抗样本的可迁移性首先由 Szegedy et al. (2013) 检验,他们研究了 (1) 在同一数据集上训练的不同模型之间,以及 (2) 在同一或不同模型在数据集的不相交子集上训练之间的可迁移性;然而,Szegedy et al. (2013) 只研究了 MNIST。
对可迁移性的研究随后由 Goodfellow et al. (2014) 跟进,他们将可迁移性现象归因于对抗扰动与模型的权重向量高度对齐。同样,这个假设是在 MNIST 和 CIFAR-10 数据集上测试的。我们展示了对于在 ImageNet 上训练的模型,情况并非如此。
Papernot et al. (2016a;b) 研究了构建替代模型来攻击黑盒目标模型。为了训练替代模型,他们开发了一种技术,合成一个训练集,并通过查询目标模型获取标签来对其进行标注。他们证明,使用这种方法,对 Amazon、Google 和 MetaMind 托管的机器学习服务进行黑盒攻击是可行的。此外,Papernot et al. (2016a) 研究了深度神经网络与其他模型(如决策树、kNN 等)之间的可迁移性。
我们的工作与 Papernot et al. (2016a;b) 在三个方面不同。首先,在这些工作中,只有模型和训练过程是黑盒,但训练集和测试集由攻击者控制;相比之下,我们攻击 Clarifai.com,其模型、训练数据、训练过程甚至测试标签集对攻击者都是未知的。其次,这些工作中研究的数据集是小规模的,即 MNIST 和 GTSRB (Stallkamp et al. (2012));在我们的工作中,我们研究了更大模型和更大数据集(即 ImageNet)上的可迁移性。第三,为了攻击黑盒机器学习系统,我们自己不查询系统来构建替代模型。
在一个并行且独立的工作中,Moosavi-Dezfooli et al. (2016) 展示了每个模型都存在一个通用扰动,该扰动可以跨不同图像迁移。他们还展示了使用这些通用扰动生成的对抗图像可以在 ImageNet 上跨不同模型迁移。然而,他们只检验了非针对性的可迁移性,而我们的工作研究了 ImageNet 上的非针对性和针对性可迁移性。
2 对抗深度学习与可迁移性
2.1 对抗深度学习问题
我们假设一个分类器 fθ(x)f_{\theta}(x)fθ(x) 输出一个类别(或标签)作为预测。给定一个原始图像 xxx,其真实标签为 yyy,对抗深度学习问题是为分类器 fθ(x)f_{\theta}(x)fθ(x) 寻找对抗样本。具体来说,我们考虑两类对抗样本。一个非针对性对抗样本 x∗x^{*}x∗ 是一个接近 xxx 的实例,此时 x∗x^{*}x∗ 应与 xxx 具有相同的真实标签,而 fθ(x∗)≠yf_{\theta}(x^{*}) \neq yfθ(x∗)=y。为了使问题非平凡,我们无妨假设 fθ(x)=yf_{\theta}(x) = yfθ(x)=y。一个针对性对抗样本 x∗x^{*}x∗ 接近 xxx 并满足 fθ(x∗)=y∗f_{\theta}(x^{*}) = y^{*}fθ(x∗)=y∗,其中 y∗y^{*}y∗ 是攻击者指定的目标标签,且 y∗≠yy^{*} \neq yy∗=y。
2.2 生成对抗样本的方法
在这项工作中,我们考虑三类生成对抗样本的方法:基于优化的方法、快速梯度方法和快速梯度符号方法。每一类都有非针对性和针对性版本。
2.2.1 生成非针对性对抗样本的方法
形式化地,给定一个图像 xxx 及其真实标签 y=fθ(x)y = f_{\theta}(x)y=fθ(x),搜索非针对性对抗样本可以建模为搜索满足以下约束的实例 x∗x^{*}x∗:
fθ(x∗)≠yd(x,x∗)≤B(1) \begin{array}{r} f_{\theta}(x^{*})\neq y \\ d(x,x^{*})\leq B \end{array} \quad (1) fθ(x∗)=yd(x,x∗)≤B(1)
其中 d(⋅,⋅)d(\cdot,\cdot)d(⋅,⋅) 是量化原始图像与其对抗版本之间距离的度量,BBB 称为失真,是此距离的上界。不失一般性,我们考虑模型 fff 由一个网络 Jθ(x)J_{\theta}(x)Jθ(x) 组成,该网络输出每个类别的概率,因此 fff 输出概率最高的类别。
基于优化的方法。一种方法是近似求解以下优化问题:
argminx∗λd(x,x∗)−ℓ(1y,Jθ(x∗))(3) \mathbf{argmin}{x^{*}}\lambda d(x,x^{*}) - \ell (\mathbf{1}{y},J_{\theta}(x^{*})) \quad (3) argminx∗λd(x,x∗)−ℓ(1y,Jθ(x∗))(3)
其中 1y\mathbf{1}_{y}1y 是真实标签 yyy 的独热编码,ℓ\ellℓ 是衡量预测与真实标签之间距离的损失函数,λ\lambdaλ 是用于平衡约束 (2) 和 (1) 的常数,凭经验确定。这里,损失函数 ℓ\ellℓ 用于近似约束 (1),其选择会影响搜索对抗样本的有效性。在这项工作中,我们选择 ℓ(u,v)=log(1−u⋅v)\ell (u,v) = \log (1 - u\cdot v)ℓ(u,v)=log(1−u⋅v),Carlini & Wagner (2016) 证明其有效。
快速梯度符号 (FGS) 。Goodfellow et al. (2014) 提出了快速梯度符号 (FGS) 方法,该方法只需计算一次梯度即可生成对抗样本。FGS 可用于生成满足 L∞L_{\infty}L∞ 范数约束的对抗图像。形式化地,非针对性对抗样本构造如下:
x∗←clip(x+Bsgn(∇xℓ(1y,Jθ(x)))) x^{*}\leftarrow \mathrm{clip}(x + B\mathrm{sgn}(\nabla_{x}\ell (\mathbf{1}{y},J{\theta}(x)))) x∗←clip(x+Bsgn(∇xℓ(1y,Jθ(x))))
这里,clip(x)\mathrm{clip}(x)clip(x) 用于将 xxx 的每个维度裁剪到像素值范围,即本文中的 0,2550, 2550,255。我们做了一个小改动,选择 ℓ(u,v)=log(1−u⋅v)\ell (u,v) = \log (1 - u\cdot v)ℓ(u,v)=log(1−u⋅v),与基于优化的方法相同。
2.2.2 生成针对性对抗样本的方法
一个针对性对抗图像 x⋆x^{\star}x⋆ 与非针对性类似,但约束 (1) 被替换为
fθ(x⋆)=y⋆(4) f_{\theta}(x^{\star}) = y^{\star} \quad (4) fθ(x⋆)=y⋆(4)
其中 y⋆y^{\star}y⋆ 是攻击者指定的目标标签。对于基于优化的方法,我们通过求解以下对偶目标来近似解:
argminx⋆λd(x,x⋆)+ℓ′(1y⋆,Jθ(x⋆))(5) \mathbf{argmin}{x^{\star}}\lambda d(x,x^{\star}) + \ell^{\prime}(\mathbf{1}{y^{\star}},J_{\theta}(x^{\star})) \quad (5) argminx⋆λd(x,x⋆)+ℓ′(1y⋆,Jθ(x⋆))(5)
在这项工作中,我们选择标准的交叉熵损失 ℓ′(u,v)=−∑iuilogvi\ell^{\prime}(u,v) = -\sum_{i}u_{i}\log v_{i}ℓ′(u,v)=−∑iuilogvi。
对于 FGS 和 FG,我们如下构造对抗样本:
x⋆←clip(x−Bsgn(∇xℓ′(1y⋆,Jθ(x))))x⋆←clip(x−B∇xℓ′(1y⋆,Jθ(x))∣∣∇xℓ′(1y⋆,Jθ(1y⋆))∣∣) x^{\star}\leftarrow \mathrm{clip}(x - B\mathbf{sgn}(\nabla_{x}\ell^{\prime}(\mathbf{1}{y^{\star}},J{\theta}(x)))) \\ x^{\star}\leftarrow \mathrm{clip}(x - B\frac{\nabla_{x}\ell^{\prime}(\mathbf{1}{y^{\star}},J{\theta}(x))}{||\nabla_{x}\ell^{\prime}(\mathbf{1}{y^{\star}},J{\theta}(\mathbf{1}_{y^{\star}}))||}) x⋆←clip(x−Bsgn(∇xℓ′(1y⋆,Jθ(x))))x⋆←clip(x−B∣∣∇xℓ′(1y⋆,Jθ(1y⋆))∣∣∇xℓ′(1y⋆,Jθ(x)))
其中 ℓ′\ell^{\prime}ℓ′ 与基于优化的方法使用的相同。
2.3 评估方法
在论文的其余部分,我们专注于检验在 ImageNet (Russakovsky et al. (2015)) 上训练的最先进模型之间的可迁移性。在本节中,我们详细说明要检验的模型、要评估的数据集以及使用的度量。
模型 。我们检验五个网络:ResNet-50、ResNet-101、ResNet-152 (He et al. (2015))1、GoogLeNet (Szegedy et al. (2014))2 和 VGG-16 (Simonyan & Zisserman (2014))3。我们在线检索了每个网络的预训练模型。这些模型在 ILSVRC 2012 (Russakovsky et al. (2015)) 验证集上的性能见附录(表 7)。我们选择这些模型来研究同构架构(即 ResNet 模型)和异构架构之间的可迁移性。
数据集 。检验一个对抗图像在两个模型之间的可迁移性如果这两个模型都不能正确分类原始图像,则意义不大。因此,从 ILSVRC 2012 验证集中,我们随机选择了 100 张能被我们检验的所有五个模型正确分类的图像。这 100 张图像构成了我们的测试集。为了执行针对性攻击,我们为每张图像手动选择一个目标标签,使其语义远离真实标签。我们评估中使用的图像和目标标签可以在网站上找到4。
衡量可迁移性。给定两个模型,我们通过计算为一个模型生成的对抗样本能被另一个模型正确分类的百分比来衡量非针对性可迁移性。我们将此百分比称为准确率。较低的准确率意味着更好的非针对性可迁移性。我们通过计算为一个模型生成的对抗样本被另一个模型预测为目标标签的百分比来衡量针对性可迁移性。我们将此百分比称为匹配率。较高的匹配率意味着更好的针对性可迁移性。为清晰起见,报告的结果仅基于 top-1 准确率。top-5 准确率的对应结果可在附录中找到。
3 非针对性对抗样本
在本节中,我们检验了生成非针对性对抗图像的不同方法。
失真 。除了可迁移性,另一个重要因素是对抗图像与原始图像之间的失真。我们通过均方根偏差(RMSD)来衡量失真,计算公式为 d(x∗,x)=∑i(xi∗−xi)2/Nd(x^{*},x) = \sqrt{\sum_{i}(x_{i}^{*} - x_{i})^{2} / N}d(x∗,x)=∑i(xi∗−xi)2/N ,其中 x∗x^{*}x∗ 和 xxx 分别是对抗图像和原始图像的向量表示,NNN 是 xxx 和 x∗x^{*}x∗ 的维度,xix_{i}xi 表示 xxx 第 iii 维的像素值,范围在 0,2550, 2550,255 内,xi∗x_{i}^{*}xi∗ 类似。
3 非针对性对抗样本
在本节中,我们检验了生成非针对性对抗图像的不同方法。
3.1 基于优化的方法
为了将基于优化的方法应用于单个模型,我们将 x∗x^{*}x∗ 初始化为 xxx,并使用 Adam 优化器 (Kingma & Ba (2014)) 优化目标 (3)。我们发现,通过调整 Adam 的学习率和 λ\lambdaλ,我们可以调整 RMSD。我们发现,对于每个模型,我们可以使用小的学习率生成具有小 RMSD(即 <2< 2<2)的对抗图像,与 λ\lambdaλ 无关。事实上,我们发现当用 xxx 初始化 x∗x^{*}x∗ 时,即使我们将 λ\lambdaλ 设为 0(即不限制 x∗x^{*}x∗ 和 xxx 之间的距离),Adam 优化器也会在 xxx 附近搜索对抗样本。因此,在本文的所有使用基于优化方法的实验中,我们将 λ\lambdaλ 设为 0。尽管这些具有小失真的对抗样本可以成功欺骗目标模型,但它们不能很好地迁移到其他模型(详见附录表 15 和 16)。
我们增加学习率以允许优化算法搜索具有更大失真的对抗图像。具体来说,我们将学习率设为 4。我们运行 Adam 优化器 100 次迭代以生成对抗图像。我们观察到损失在 100 次迭代后收敛。另一种产生类似结果的基于优化的方法见附录。
非针对性对抗样本的迁移。我们在一个网络上生成非针对性对抗样本,但在另一个网络上评估它们,结果如表 1 面板 A 所示。从表中我们可以观察到:
对角线包含所有 0 值。这意味着为一个模型生成的所有对抗图像都能欺骗同一个模型。使用基于优化的方法为一个模型生成的大部分非针对性对抗图像可以迁移到另一个模型。尽管三个 ResNet 模型具有相似的架构,仅在超参数上有所不同,但针对一个 ResNet 模型生成的对抗样本不一定比针对其他非 ResNet 模型生成的对抗样本更好地迁移到另一个 ResNet 模型。例如,针对 VGG-16 生成的对抗样本在 ResNet-50 上的准确率低于针对 ResNet-152 或 ResNet-101 生成的对抗样本。
3.2 基于快速梯度的方法
然后我们检验基于快速梯度的方法的有效性。基于快速梯度的方法的一个良好特性是,所有生成的对抗样本都位于一个一维子空间中。因此,我们可以轻松地近似这个子空间中两个模型之间可迁移对抗样本的最小失真。在下文中,我们首先控制 RMSD 来研究基于快速梯度的方法的有效性。其次,我们研究了基于快速梯度方法的可迁移最小失真。
3.2.1 基于快速梯度方法的有效性和可迁移性
由于失真 BBB 与生成对抗图像的 RMSD 高度相关,我们可以选择这个超参数 BBB 来生成具有给定 RMSD 的对抗图像。在表 1 面板 B 中,我们使用 FG 生成对抗图像,使得平均 RMSD 与使用基于优化方法生成的几乎相同。我们观察到对角线上的值都是正的,这意味着 FG 不能完全欺骗模型。一个潜在的原因是,FG 可以看作是优化的近似,但为了速度而牺牲了准确性。
另一方面,表中的非对角线单元格值对应于为一个模型生成但在另一个模型上评估的对抗图像的准确率,与基于优化方法中的对应值相当或更低。这表明由 FG 生成的非针对性对抗样本也具有可迁移性。
我们还评估了 FGS,但生成图像的可迁移性比使用 FG 或基于优化方法生成的差。结果见附录(表 19 和 20)。结果表明,当 RMSD 约为 23 时,FGS 生成的对抗图像的准确率高于 FG 的对应值。我们假设 FGS 可迁移性较差的原因与此事实有关。
3.2.2 具有最小可迁移 RMSD 的对抗图像
对于一个图像 xxx 和两个模型 M1,M2M_{1},M_{2}M1,M2,我们可以近似沿着方向 δ\deltaδ 的最小失真 BBB,使得为 M1M_{1}M1 生成的 xB=x+Bδx_{B} = x + B\deltaxB=x+Bδ 对 M1M_{1}M1 和 M2M_{2}M2 都是对抗的。这里 δ\deltaδ 是方向,对于 FGS 是 sgn(∇xℓ)\mathbf{sgn}(\nabla_{x}\ell)sgn(∇xℓ),对于 FG 是 ∇xℓ/∣∣∇xℓ∣∣\nabla_{x}\ell /||\nabla_{x}\ell ||∇xℓ/∣∣∇xℓ∣∣。
我们将使用 FG(或 FGS)从 M1M_{1}M1 到 M2M_{2}M2 的最小可迁移 RMSD 定义为使用 FG(或 FGS)从 M1M_{1}M1 到 M2M_{2}M2 具有最小可迁移失真 BBB 的可迁移对抗样本 xBx_{B}xB 的 RMSD。最小可迁移 RMSD 可以说明失真与可迁移性之间的权衡。
在下文中,我们通过每 0.1 步采样 BBB 的线性搜索来近似最小可迁移 RMSD。我们选择线性搜索方法而不是二分搜索方法来确定最小可迁移 RMSD,因为从原始图像生成的对抗样本可能来自多个区间。实验见附录(图 6)。
使用 FG 和 FGS 的最小可迁移 RMSD 。图 1 绘制了使用非针对性 FG(图 1a)和 FGS(图 1b)从 VGG-16 到 ResNet-152 的最小可迁移 RMSD 的累积分布函数 (CDF)。从图中我们观察到,FG 和 FGS 都可以找到 100%100\%100% 可迁移的对抗图像,其 RMSD 分别小于 80.91 和 86.56。此外,FG 方法可以生成比 FGS 具有更小 RMSD 的可迁移攻击。一个潜在的原因是,FGS 最小化失真的 L∞L_{\infty}L∞ 范数,而 FG 最小化其 L2L_{2}L2 范数,后者与 RMSD 成正比。
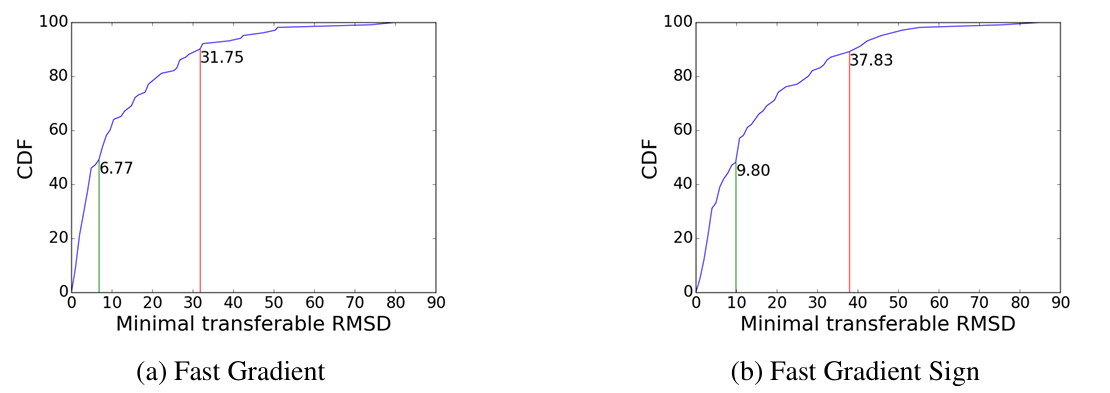
图 1 :使用 FG (a) 和 FGS (b) 从 VGG-16 到 ResNet-152 的最小可迁移 RMSD 的 CDF。绿线标记中位数最小可迁移 RMSD,红线标记达到 90%90\%90% 百分比的最小可迁移 RMSD。
表 2 :使用基于优化的方法生成的针对性对抗图像的匹配率。第一列表示生成对抗图像的平均 RMSD。单元格 (i,j)(i,j)(i,j) 表示针对模型 iii(行)生成的针对性对抗图像在模型 jjj(列)上评估时的匹配率。top-5 结果见附录(表 12)。

3.3 与随机扰动的比较
我们还评估了在测试集中的 100 张图像上添加高斯噪声时的测试准确率。具体结果见附录,我们得出的结论是,这种方法的"可迁移性"明显差于基于优化的方法或基于快速梯度的方法。
4 针对性对抗样本
在本节中,我们检验了针对性对抗图像的可迁移性。表 2 展示了使用基于优化方法的结果。我们观察到:(1) 当在用于生成对抗样本的同一模型上评估时,针对性对抗图像的预测可以与目标标签匹配;但是 (2) 针对性对抗图像很少被不同的模型预测为目标标签。我们称后者为目标标签不迁移。即使我们增加失真,我们也没有观察到目标标签迁移的改善。一些结果见附录(表 17)。即使我们基于 top-5 准确率计算匹配率,最高匹配率也只有 10%10\%10%。结果见附录(表 18)。
我们还检验了由基于快速梯度的方法生成的针对性对抗图像,我们观察到目标标签同样不迁移。结果推迟到附录(表 25)。事实上,大多数针对性对抗图像无法欺骗用于生成它们的模型来预测目标标签,无论使用多大的失真。我们将其归因于基于快速梯度的方法仅在一维子空间中搜索攻击。在这个子空间中,所有可能的预测可能只包含所有标签的一个小子集,该子集通常不包含目标标签。在第 6 节中,我们研究了关于这个问题的决策边界。
我们还评估了如第 3.3 节所述添加高斯噪声的图像的匹配率。然而,我们观察到 5 个模型中任何一个的匹配率都是 0%0\%0%。因此,我们得出结论,通过添加高斯噪声,攻击者根本无法生成成功的针对性对抗样本,更不用说针对性可迁移性了。
5 基于集成的方法
我们假设如果一个对抗图像对多个模型仍然具有对抗性,那么它也更有可能会迁移到其他模型。我们开发了为多个模型生成对抗图像的技术。基本思想是为模型的集成生成对抗图像。形式化地,给定 kkk 个具有 softmax 输出 J1,...,JkJ_{1},\ldots,J_{k}J1,...,Jk 的白盒模型,一个原始图像 xxx 及其真实标签 yyy,基于集成的方法求解以下优化问题(针对针对性攻击):
argminx⋆−log((∑i=1kαiJi(x⋆))⋅1y⋆)+λd(x,x⋆)(6) \mathbf{argmin}{x\star} - \log \left((\sum{i = 1}^{k}\alpha_{i}J_{i}(x^{\star}))\cdot \mathbf{1}_{y^{\star}}\right) + \lambda d(x,x^{\star}) \quad (6) argminx⋆−log((i=1∑kαiJi(x⋆))⋅1y⋆)+λd(x,x⋆)(6)
其中 y⋆y^{\star}y⋆ 是攻击者指定的目标标签,∑αiJi(x⋆)\sum \alpha_{i}J_{i}(x^{\star})∑αiJi(x⋆) 是集成模型,αi\alpha_{i}αi 是集成权重,∑i=1kαi=1\sum_{i = 1}^{k}\alpha_{i} = 1∑i=1kαi=1。注意 (6) 是针对性目标。非针对性目标可以类似推导。这样做,我们希望生成的对抗图像对额外的黑盒模型 Jk+1J_{k + 1}Jk+1 仍然具有对抗性。
我们评估了基于集成方法的有效性。对于五个模型中的每一个,我们将其视为要攻击的黑盒模型,并为其余四个模型的集成生成对抗图像,这四个模型被视为白盒。我们评估生成的对抗图像在所有五个模型上的表现。在本文的其余部分,我们将第 3 节和第 4 节中评估的方法称为使用单个模型的方法,将本节讨论的基于集成的方法称为使用集成模型的方法。
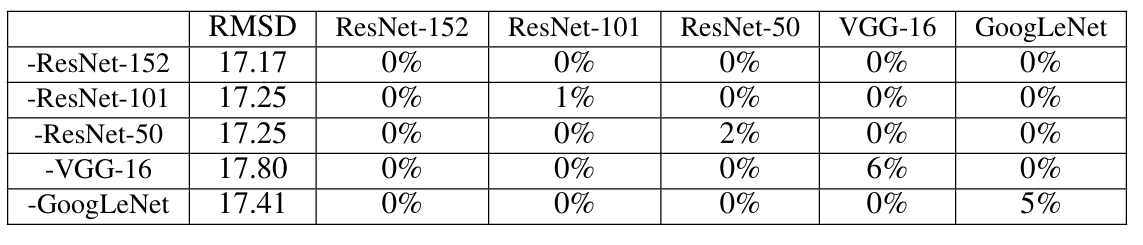
基于优化的方法。我们使用 Adam 优化目标 (6),集成中所有模型具有相等的集成权重,以生成针对性对抗样本。具体来说,我们将每个模型的 Adam 学习率设为 8。在每次迭代中,我们计算每个模型的 Adam 更新,将四个更新求和,并将聚合添加到图像上。我们运行 100 次更新迭代,并观察到损失在 100 次迭代后收敛。通过这样做,我们首次观察到很大一部分针对性对抗图像的目标标签可以迁移。结果如表 3 所示。我们观察到并非所有针对性对抗图像都能被集成中使用的模型错误分类为目标标签。这表明在搜索集成模型的对抗样本时,没有直接的监督来欺骗集成中的任何单个模型预测目标标签。此外,从表的对角线数字中,我们观察到,当针对除目标模型之外的所有模型生成对抗样本时,对 ResNet 模型的可迁移性优于对 VGG-16 或 GoogLeNet 的可迁移性。
我们还评估了由基于集成的方法生成的非针对性对抗图像。我们观察到生成的对抗图像几乎具有完美的可迁移性。我们使用与针对性版本相同的过程,除了生成对抗图像的目标不同。我们评估生成的对抗图像在所有模型上的表现。结果如表 4 所示。生成的对抗图像的 RMSD 都约为 17,低于使用单个模型的基于优化方法的 22 到 23(见表 1 进行比较)。当对抗图像在未用于生成攻击的模型上评估时,准确率不超过 6%6\%6%。作为参考,第 3 节中评估的所有使用单个模型的方法的相应准确率至少为 12%12\%12%。我们的实验表明,基于集成的方法可以生成几乎完美可迁移的对抗图像。
表 3 :使用基于优化的方法生成的针对性对抗图像的匹配率。第一列表示生成对抗图像的平均 RMSD。单元格 (i,j)(i,j)(i,j) 表示针对除模型 iii(行)之外的四个模型的集成生成的针对性对抗图像被模型 jjj(列)预测为目标标签的百分比。在每一行中,减号"−^{-}−"表示该行的模型在生成攻击时未被使用。top-5 匹配率结果见附录(表 13)。

表 4 :使用基于优化的方法生成的非针对性对抗图像的准确率。第一列表示生成对抗图像的平均 RMSD。单元格 (i,j)(i,j)(i,j) 表示使用除模型 iii(行)之外的四个模型的集成生成的非针对性攻击在模型 jjj(列)上评估时的准确率。在每一行中,减号"−^{-}−"表示该行的模型在生成攻击时未被使用。top-5 准确率结果见附录(表 14)。
基于快速梯度的方法。将非针对性基于快速梯度的方法应用于集成的结果见附录(表 21、22、23 和 24)。我们观察到对角线值不为零,这与我们在将 FG 和 FGS 应用于单个模型时观察到的结果相同。我们假设一个潜在的原因是,集成中不同模型的梯度方向彼此正交,我们将在第 6 节中说明。在这种情况下,集成的梯度方向几乎与集成中每个模型的梯度方向正交。因此,沿着这个方向搜索可能需要很大的失真才能达到对抗样本。
表 5 :在图3所述同一平面中,每个模型所有可能预测标签的数量

对于使用基于集成模型的 FG 和 FGS 生成的针对性对抗样本,它们的可迁移性并不比使用单个模型生成的好。结果见附录(表 28、29、30 和 31)。我们假设同样的原因可以解释这一点:在一维子空间中总共只有少数可能的目标标签。
6 不同模型的几何特性
在本节中,我们展示了一些模型的几何特性,以尝试更好地理解可迁移的对抗样本。先前的工作也试图从理论上 (Fawzi et al. (2016)) 或经验上 (Goodfellow et al. (2014)) 理解对抗样本的几何特性。在这项工作中,我们检验了在具有 1000 个标签的大规模数据集上训练的大型模型,这些模型的几何特性以前从未被检验过。这使我们能够做出新的观察,以更好地理解模型及其对抗样本。
我们评估中不同模型的梯度方向几乎彼此正交。我们研究了不同模型的对抗方向是否彼此对齐。我们计算了不同模型梯度方向之间角度的余弦值,结果见附录(表 33)。我们观察到所有非对角线值都接近 0,这表明对于大多数图像,它们相对于不同模型的梯度方向彼此正交。
使用单个模型的非针对性方法的决策边界 。我们研究了不同模型的决策边界,以理解为什么对抗样本可以迁移。我们选择两个归一化的正交方向 δ1,δ2\delta_{1}, \delta_{2}δ1,δ2,一个是 VGG-16 的梯度方向,另一个是随机选择的。这个二维平面中的每个点 (u,v)(u, v)(u,v) 对应于图像 x+uδ1+vδ2x + u \delta_{1} + v \delta_{2}x+uδ1+vδ2,其中 xxx 是原始图像的像素值向量。对于每个模型,我们绘制了每个点对应的图像标签,得到图 3,使用了图 2 中的图像。

图2 :用于研究决策边界的示例图像。其在 ILSVRC 2012 验证集中的 ID 为 49443,真实标签为"海葵鱼"。
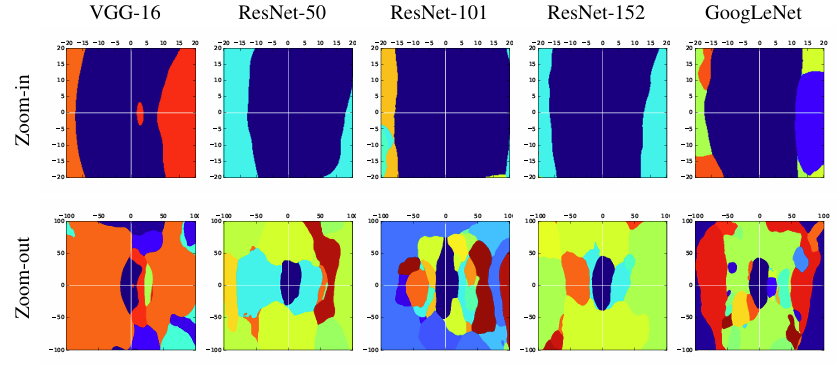
图3:不同模型的决策区域。所有子图选取相同的两个方向:一个是 VGG-16 的梯度方向(x轴),另一个是随机的正交方向(y轴)。平面上的每个点显示通过向原始图像添加噪声生成的图像的预测标签(例如,原点对应原始图像的预测标签)。两个轴的单位均为1个像素值。所有子图使用相同颜色表示相同标签。图像为图2中的图像。
我们可以观察到,对于所有模型,每个模型能正确预测图像的区域仅限于中心区域。此外,沿着梯度方向,分类器很快被误导。一个有趣的发现是,沿着这个梯度方向,三个 ResNet 模型(对应于浅绿色区域)第一个被错误分类的标签是"橙色"。更详细的研究见附录(表 9、表 26 和 27)。当我们看放大的图时,然而,远离原始图像的图像的标签对于不同的模型是不同的,即使在 ResNet 模型之间也是如此。
另一方面,在表 5 中,我们展示了每个平面中区域的总数。事实上,对于每个平面,所有平面中最多有 21 个不同的区域。与 ImageNet 中的 1000 个总类别相比,这仅占所有类别的 2.1%2.1\%2.1%。这意味着,对于所有其他 97.9%97.9\%97.9% 的标签,每个平面中都不存在针对性对抗样本。这种现象部分解释了为什么基于快速梯度的方法很难找到针对性对抗图像。
此外,在图 4 中,我们在如上所述的同一平面上绘制了所有模型的决策边界。我们可以观察到:
- 边界彼此对齐得非常好。这部分解释了为什么非针对性对抗图像可以在模型之间迁移。
- 沿梯度方向的边界直径小于沿随机方向的直径。一个潜在的原因是,沿其梯度方向移动变量可以显著改变损失函数(即真实标签的概率)。因此,沿着梯度方向,移出真实标签区域所需的步数比随机方向要少。
- 一个有趣的发现是,即使我们沿着 x 轴向左移动(这相当于最大化真实标签的预测概率),它也远比沿随机方向移动更快地到达边界。我们将其归因于损失函数的非线性:当失真较大时,梯度方向也会发生巨大变化。在这种情况下,沿着原始梯度方向移动不再增加预测真实标签的概率(参见附录图 7)。
- 对于 VGG-16 模型,在对应真实标签的区域内部有一个小孔。这可能部分解释了为什么存在具有小失真的非针对性对抗图像,但不能很好地迁移。这个小孔在其他模型的决策平面中不存在。在这种情况下,这个小孔中的非针对性对抗图像不会迁移。
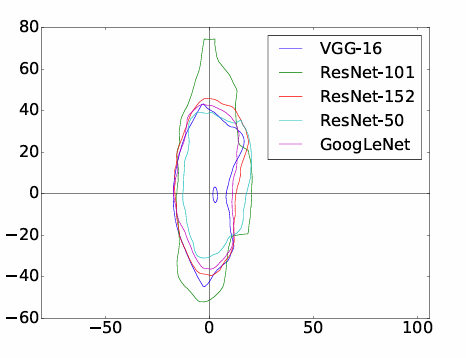
图4 :区分真实标签区域(由每条闭合曲线包围)与其他区域的决策边界。平面与图3所述相同。坐标原点对应原始图像。两个轴的单位均为1个像素值。
针对性基于集成方法的决策边界。此外,我们选择了除 ResNet-101 之外所有模型的集成的针对性对抗方向和一个随机的正交方向,并在由这两个方向向量张成的平面上绘制了决策边界,得到图5。
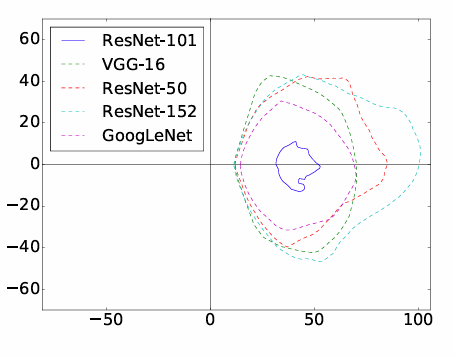
图5:区分目标标签区域(由每条闭合曲线包围)与其他区域的决策边界。平面由针对性对抗方向和一个随机正交方向张成。针对性对抗方向计算为图2中原始图像与针对集成(包含除 ResNet-101 外的所有模型)生成的对抗图像之间的差异。坐标原点对应原始图像。两个轴的单位均为1个像素值。
我们观察到,对于集成中的四个模型,被预测为目标标签的区域对齐得很好。然而,对于未用于生成对抗图像的模型(即 ResNet-101),它也有一个非空区域使得预测成功被误导到目标标签,尽管该区域的面积小得多。同时,每个模型的每个闭合曲线内的区域几乎具有相同的中心。
7 真实世界示例:针对 CLARIFAI.COM 的对抗样本
Clarifai.com 是一家提供最先进图像分类服务的商业公司。我们对 Clarifai.com 背后的数据集和模型类型一无所知,除了我们可以黑盒访问其服务。Clarifai.com 返回的标签也不同于 ILSVRC 2012 中的类别。我们将所有 100 张原始图像提交给 Clarifai.com,根据主观度量,返回的标签是正确的。
我们还总共提交了 400 张对抗图像,其中 200 张是针对性对抗样本,其余 200 张是非针对性对抗样本。对于 200 张针对性对抗图像,其中 100 张是使用基于优化的方法基于 VGG-16 生成的(与表 2 中评估的相同),其余 100 张是使用基于优化的方法基于除 ResNet-152 之外所有模型的集成生成的(与表 3 中评估的相同)。200 张非针对性对抗样本以类似方式生成(与表 1 和 4 中评估的相同)。
对于非针对性对抗样本,我们观察到,无论是使用 VGG-16 生成的还是使用集成生成的,大多数都能迁移到 Clarifai.com。
更重要的是,我们的很大一部分针对性对抗样本也能被 Clarifai.com 错误分类。我们观察到,使用 VGG-16 生成的针对性对抗样本中有 57%57\%57%,以及使用集成生成的针对性对抗样本中有 76%76\%76%,能够欺骗 Clarifai.com 预测与真实标签无关的标签。
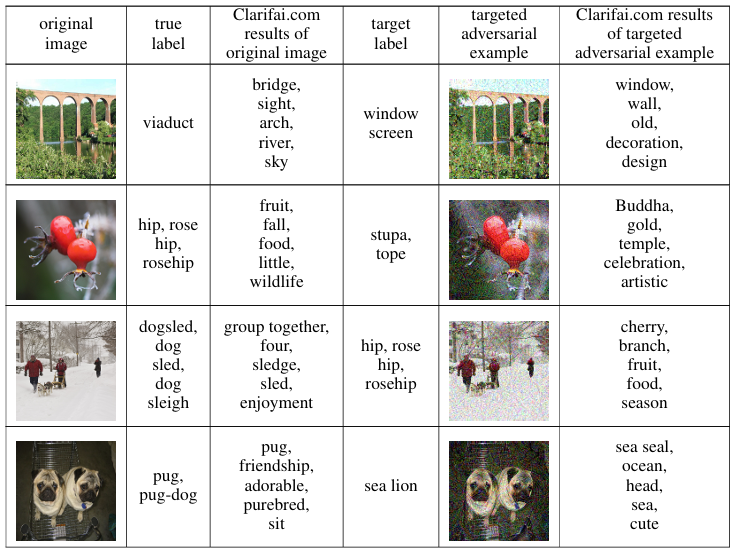
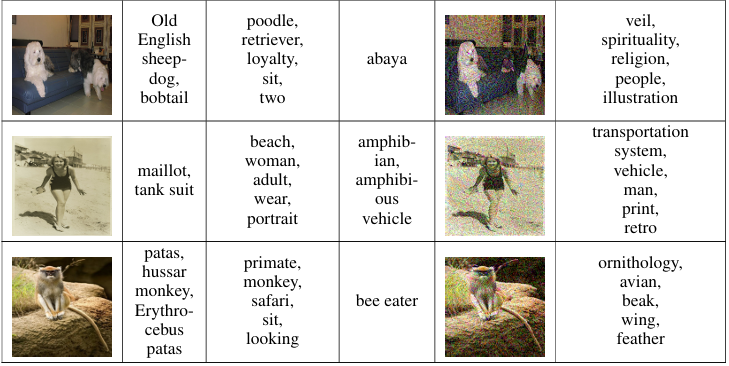
此外,我们的实验表明,对于针对性对抗样本,使用集成模型生成的样本中有 18%18\%18% 能够被 Clarifai.com 预测为接近目标标签的标签。使用 VGG-16 生成的针对性对抗样本的相应数字是 2%2\%2%。考虑到在攻击 Clarifai.com 的情况下,目标模型给出的标签与我们模型给出的标签不同,令人相当惊讶的是,当使用基于集成的方法时,仍然有相当一部分我们的针对性对抗样本能够欺骗这个黑盒模型,做出与我们的目标标签语义相似的预测。所有这些数字都是基于主观度量计算的,我们在表 6 中包含了一些示例。更多示例见附录(表 34)。
表 6:在 Clarifai.com 上评估的原始图像和对抗图像。对于 Clarifai.com 返回的标签,我们首先按稀有度对标签进行排序:一个标签在 Clarifai.com 对所有对抗图像和原始图像的结果中出现的次数,其次按置信度。只提供前 5 个标签。
8 结论
在这项工作中,我们首次对使用不同方法在大型模型和大规模数据集上生成的非针对性和针对性对抗样本的可迁移性进行了广泛研究。我们的结果证实,即使在大型模型和大规模数据集上,非针对性对抗样本的可迁移性也是显著的。另一方面,我们发现使用现有方法很难生成其目标标签可以迁移的针对性对抗样本。我们开发了新颖的基于集成的方法,并证明它们可以以高成功率生成可迁移的针对性对抗样本。同时,这些新方法在生成非针对性可迁移对抗样本方面表现出比先前工作更好的性能。我们还展示了使用我们的新方法生成的非针对性和针对性对抗样本都可以成功攻击 Clarifai.com,这是一个黑盒图像分类系统。此外,我们研究了一些几何特性以更好地理解可迁移的对抗样本。
致谢
本材料部分基于美国国家科学基金会资助的工作,资助号为 TWC-1409915。本文中表达的任何意见、发现、结论或建议均为作者个人观点,并不一定反映美国国家科学基金会的观点。