内容参考于:图灵AI大模型全栈
Token是大模型通用的货币,这个货币是个什么东西?如下图某大模型的Token的收费

它有两个说法,上行流量和下行流量,比如根据xxx生成一个文章,这个就是上行流量,消耗输入Token,给我的文章内容就是下行流量,消耗输出Token
Token的真实样子
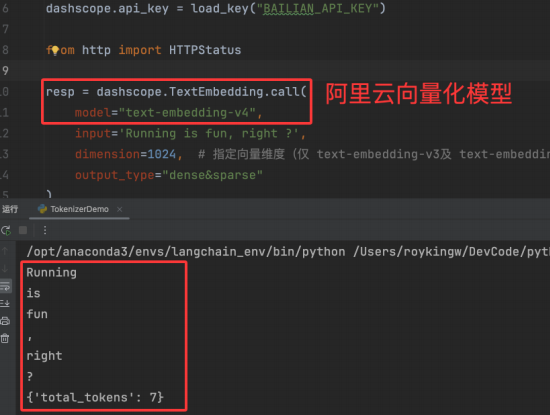
如下图一个测试Token的大模型,我们输入的是Running is fun, right ?这句话,它返回的是有7个Token,并且把我们输入的内容拆分成了Running、is、fun、,、right、?
然后它把我们的话拆分成了6个,它是怎么来的7个Token呢?原因是大模型在处理我们输入的内容时,大模型里面会给我添加我们看不到的隐藏文字,比如大模型会推理那么怎么才算推理完成了,比如我喜欢,大模型可能会通过我喜欢这三个字推断出,我喜欢玩游戏这句话,那么大模型是怎么知道推断完成的?怎么就是我喜欢玩游戏这句话?为什么不能是我喜欢玩游戏玩游戏这样呢?这里有一个EOS的东西就是当大模型检测到EOS了就说明推断完成了,不需要再继续推断了,EOS就是一个大模型里面配置的结束符,比如我喜欢玩游戏---END这样当检测到---END后,大模型就认为推断结束了,这个第7个Token可能就会是EOS,多出的Token就是大模型中隐藏的文字
Token就是大模型根据我们输入的内容拆分出来的最小语言,不同大模型的训练不一样,Token拆分的最小语言就不一样,那么这个Token怎么来的?
Token的来源
现代大模型Token的来源是通过学习来的,就是大模型会把整个互联网所有公开的文本,比如新闻、小说、百科、代码等,所有东西都会有人整理出来喂给大模型去读,大模型读的时候会用统计学,自己去想出哪些是Token,比如在读了很多内容后,发现香蕉这个词经常会一起出现,这时大模型会把香蕉两个字搞成一个Token,然后给它一个数字编号,比如111,然后放到大模型它自己的字典里,这样慢慢的搞,大模型就可以形成自己的专属字典
大模型通过Token理解语言
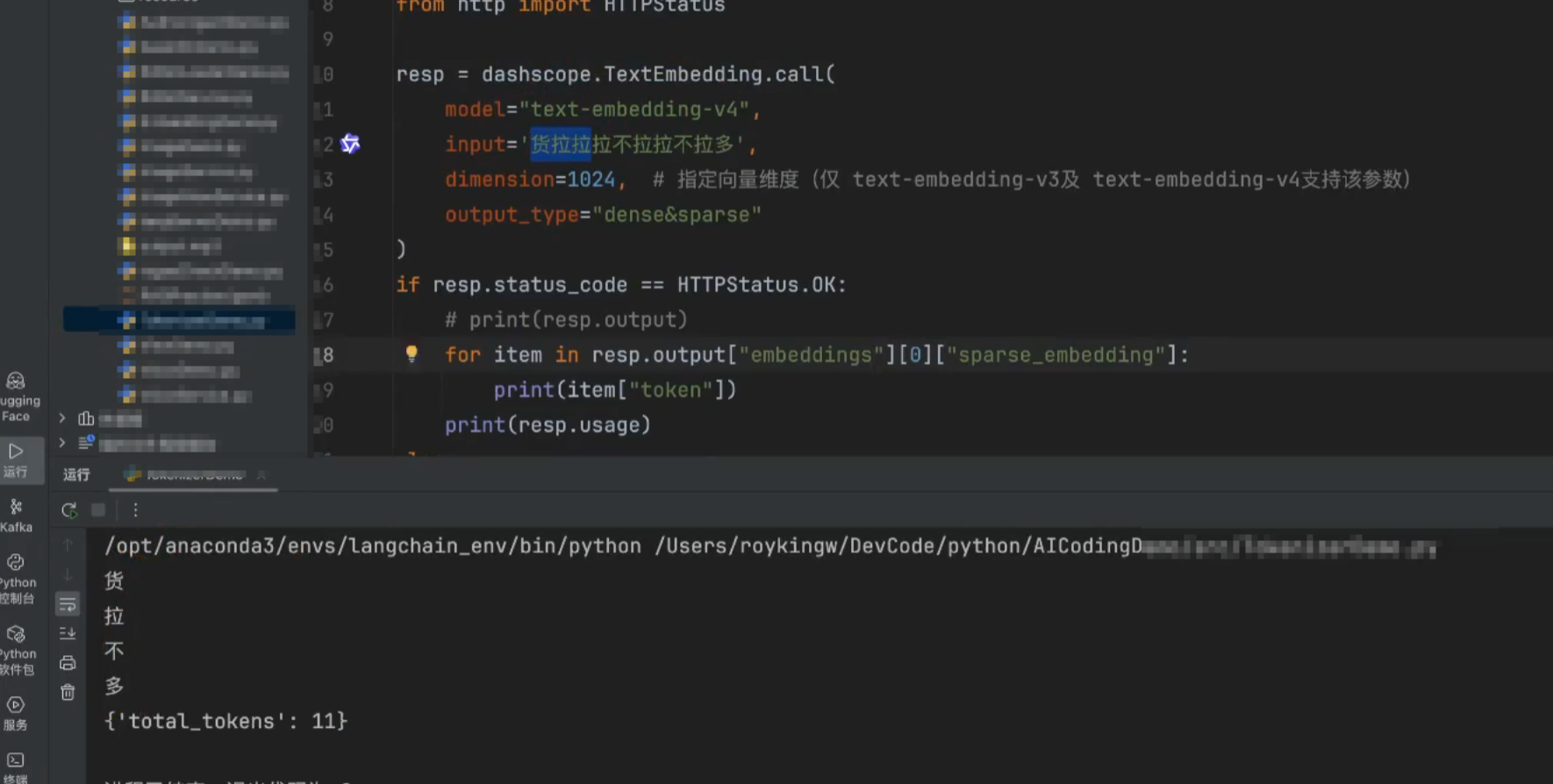
大模型通过海量的内容生成的字典,但是这个字典里面的字是什么意思它不懂,也就说这个Token的意思它不懂,如下图货拉拉拉不拉拉不拉多,我们的意思是货拉拉 拉不拉 拉不拉多,如下图它的Token是货、拉、不、多这四个,大模型是怎么理解的呢?它是通过上下文来理解的,继续往下看
大模型理解文字-向量
我们人看到的文字,比如可乐、米饭,但是大模型眼里是没有汉字的,只有一串串数字(向量),比如可乐,我们规定1、2、3这三个数字组成一个可乐,然后米饭使用5、6、7来组成,这些数字就是特征,1、2、3就是可乐的特征,5、6、7就是米饭的特征,然后大模型怎么理解呢,怎么给一个没见过可乐的人描述可乐呢,就是跟它说可乐的特征,比如黑色、很甜、很辣,也就是1(黑色百分比)、2(甜度的百分比)、3(辣度的百分)这样通过描述可乐的特征,没见过可乐的人就可以知道可乐是什么东西,1、2、3和5、6、7做一个计算,会得到一个差值,这个差值越大它们俩越不相似,差值越小就越相似,就是说意思越相近的词,就是通过对特征的计算来理解语言,向量数字越像;意思八竿子打不着,数字差别巨大

向量的训练过程
一开始可乐、米饭向量都是差不多的,通过读海量的文本慢慢的调整这些文字特征数字的大小,比如看到可乐经常跟无糖、有糖、去冰一起出现,那就把糖率、冰饮率调高,看到可乐很少跟可以飞、可以变身一起出现,那就把这些无关紧要的数字(率)变小,训练完后,特征一样的肯定都会在一个维度,这样大模型就可以理解了,到这就可以很清晰的认识Token了,Token就是大模型的字典,根据不同的训练Token也不一样,无法预测无法掌控
大模型推理过程,下发是ai生成的很好理解
第一步:你输入一句话
比如:夏天我喜欢喝
大模型看不懂汉字,第一件事:
把「夏天、我、喜欢、喝」每一个词,全都转换成自己的向量数字。
再把这一整串向量拼在一起,变成整句话的专属数字特征。
相当于模型拿着一张数字版的 "句子画像"。
第二步:靠向量比对,猜下一个该接什么词
模型拿着「夏天我喜欢喝」的整句向量,
去和它脑子里所有词语的向量挨个做对比:
- 和奶茶的向量:相似度特别高
- 和咖啡的向量:相似度次之
- 和果汁的向量:也有点像
- 和篮球的向量:几乎完全不搭,差得老远
模型就按向量相似度高低,排好名次:
奶茶 > 咖啡 > 果汁 > 篮球
然后优先挑相似度最高的,先接上奶茶。
现在句子变成:夏天我喜欢喝奶茶
第三步:循环套娃,一个词一个词往外蹦
关键来了:
模型不会一次性写完所有话,它只会每次只猜下一个词。
- 把新句子「夏天我喜欢喝奶茶」重新转成新的整句向量
- 再拿这个新向量,去比对所有词语的向量
- 算出相似度最高的词是加,直接接上
- 句子更新为:夏天我喜欢喝奶茶加
- 再转向量、再比对、再猜下一个词→珍珠
就这样:
转向量 → 比对相似度 → 选下一个词 → 拼成新句子 → 再转向量
无限重复,直到模型觉得话说完了,就停下。
第四步:为啥它不像计算器,答案不唯一?
计算器 1+1 只能 = 2,是固定死的。
但看向量就懂了:
「夏天我喜欢喝」这句的向量,
不只是和奶茶贴近,和咖啡、果汁的向量也很贴近。
好几个词的相似度都很高,不是只有唯一一个匹配。
所以它可以选奶茶,也可以选咖啡,不是只能有一个答案。
而篮球的向量差太远,正常情况下根本轮不到它被选中。
第五步:三个参数,其实就是控制「向量选词的规矩」
全大白话,绑定向量+奶茶例子,每个都加具体示例,这三个值怎么设置没有固定的,可以问ai让ai推荐,一看就懂:
1. Temperature(温度)------控制"脑洞大小"(最常用)
核心:控制"要不要选向量相似度没那么高的词",数值越低越老实,越高越放飞。
示例1:温度调得低(比如0.1,几乎不脑洞)
模型只认「向量相似度最高」的词,别的再接近也不选。
输入「夏天我喜欢喝」,它只看向量排名第一的「奶茶」,直接接上,不会选咖啡、果汁------就像你认真答题,只说最标准、最常见的答案,不瞎猜。
示例2:温度调得高(比如0.8,脑洞拉满)
模型允许选「向量相似度一般」的词,不局限于第一名。
输入「夏天我喜欢喝」,它可能不选奶茶,反而选向量相似度排第四的「气泡水」,甚至偶尔选「冰粥」(只要向量有点贴近)------就像你和朋友瞎聊,随口说个不常见但合理的答案,有点创意,也可能有点离谱。
2. Top-K------控制"选词的名额"
核心:直接规定"只从向量相似度排名前K个词里挑",剩下向量差得远的,直接拉黑不许选(K就是名额数)。
示例1:Top-K设为3
模型只看向量排名前3的词:奶茶、咖啡、果汁,剩下的气泡水、篮球(排名4、5及以后),不管向量多贴近(气泡水其实也合理),都不许选。
输入「夏天我喜欢喝」,只能从奶茶、咖啡、果汁里挑一个,不会出现气泡水、篮球这种"冷门选项",避免乱编。
示例2:Top-K设为1
模型只选向量相似度排名第一的词------也就是奶茶,和"温度调0.1"效果差不多,极度死板,永远只说最常见的答案。
3. Top-P(也叫 Nucleus Sampling)------控制"选词的靠谱程度"
核心:不按"排名名额",按"相似度总和",把所有向量相似度够格的词圈成一个小圈子,只在圈子里选词,既不呆板也不瞎跑偏。
示例1:Top-P设为0.8(最常用,靠谱又灵活)
模型先算所有词的向量相似度总和,然后从最高的开始加,加到0.8就停,把这些词圈成"靠谱圈子"。
比如:奶茶相似度0.4、咖啡0.25、果汁0.15,加起来刚好0.8------那圈子里就只有奶茶、咖啡、果汁,气泡水(相似度0.08)、篮球(0.02)加进去也到不了0.8,就被排除。
输入「夏天我喜欢喝」,只在这三个词里挑,既不会只死磕奶茶(像Top-K=1那样),也不会选气泡水、篮球(避免离谱)。
示例2:Top-P设为0.5(靠谱到死板)
只把向量相似度加起来够0.5的词圈进去,大概率只有奶茶(相似度0.4)+ 咖啡(0.25),加起来0.65够0.5,果汁(0.15)加进去多余,就被排除。
输入「夏天我喜欢喝」,只能在奶茶、咖啡里挑,比Top-P=0.8更死板一点。
一句话终极总结
大模型理解语言、生成回答,全程就靠向量:
文字变向量 → 用向量比相似度 → 每次挑最匹配的下一个词 → 循环接龙成一整段话,三个参数就是给"挑词"定规矩,控制它是老实答题还是创意发挥。
