前言
大语言模型无法直接处理原始字符串,必须先将文本切分为词元(Token);随后结合模型内置的词汇表与嵌入(Embedding)矩阵,将词元数组映射为高维向量序列,作为后续模型推理计算的输入基础。本章将深入探讨大语言模型推理的关键准备环节------词汇表与分词,从基础知识、实验与现象和分析与结论三个方面展开详细的介绍。
目录
- 1 基础知识
- 2 实验与现象
- 3 分析与结论
1 基础知识
词汇表及其关联元数据存储在 GGUF 的 KV 键值对中,通过解析文件头即可提取。而嵌入矩阵存储在张量部分,以gemma-3-1b-it-Q4_K_M.gguf模型为例,通过解析元数据中的gemma3.embedding_length可确定其嵌入维度为1152,解析tokenizer.ggml.tokens则可得到规模为262144的词汇表,因此其对应的嵌入矩阵维度为262144×1152,可通过加载GGUF内部存储的张量权重来获取。
分词环节的核心任务是将用户输入的文本转换为Token ID数组,进而查询嵌入矩阵将其转化为数值张量,为后续大模型进行词元预测提供标准的输入数据。

如上图为分词的流程。UI端输入的"hello"经对话模块标准化后由llama-server接收。系统随后对其进行分词并转换为Token ID数组;在转换过程中,系统会根据模型的KV元数据在序列中添加特殊标识,在本示例中,是在首位添加ID为2的BOS(对话起始)标记,实际操作中也可能涉及EOS(结束)标记,具体机制将在后文详述。最后,通过检索Embedding张量,将该Token ID数组转化为初始输入张量。
2 实验与现象
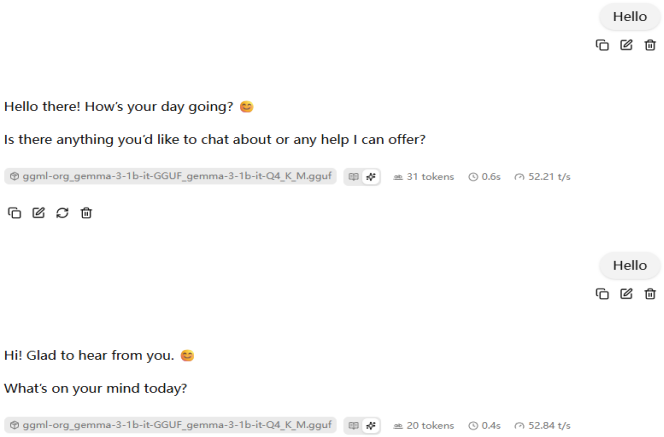
本次实验记录了与大语言模型的两次连续对话,下图详细展示了用户与模型问答的结果:
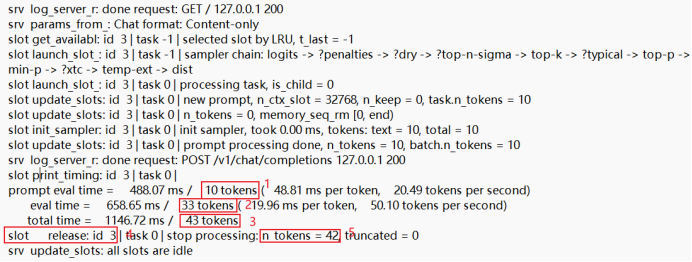
在 UI 界面进行对话交互的同时,后台同步生成了相应的运行日志。下图分别展示了两次交互对应的日志输出,其中核心参数已通过红框及编号进行了重点标注

3 分析与结论
上章(模型加载与初始化(3)-CSDN博客)通过深入剖析源码的形式,阐述了从server_context到llama_model、再到gguf_context与ggml_context的调用路径,清晰还原了GGUF格式的加载与解析流程。而解析得到的llama_model直接包含模型的词汇表llama_vocab,llama_vocab包含tokenize函数,用于处理输入文本的分词任务。
进一步回顾(llama-server - 从命令行到HTTP Server(2)-CSDN博客),server_context(负责大模型推理过程管理)通过server_response_reader将模型推理生成的文本序列(Tokens)传递至server_http_context(负责处理用户交互及结果分发)。同时,server_http_context将用户请求封装为server_task,为后端推理引擎提供输入。在此架构中,server_response_reader充当了server_context与server_http_context之间的通信桥梁,其内部包含的server_queue与server_response分别用于管理推理任务队列与维护推理结果。详细的类图关系如下图所示:
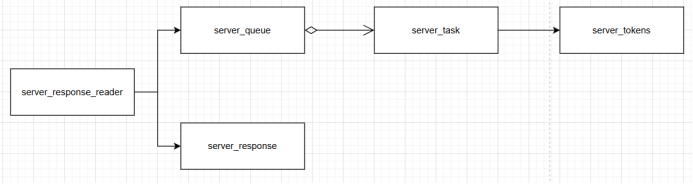
在服务的响应过程中,具体为llama-server服务回调函数post_chat_completions执行的过程中会将接收到的用户输入文本分词为server_tokens,并以server_task的形式放置到任务队列server_queue中,以供模型推理使用。
代码回到server.cpp的309行(模型加载与初始化(3)-CSDN博客中模型加载部分在同一文件的252行处调用load_model函数实现),server_context调用start_loop函数,使模型服务进行循环模式,用于在主线程中轮询处理server_task任务。而本章的重点将集中在将接收到的用户输入文本分词为server_tokens过程。
void server_context::start_loop() {
auto & params = impl->params_base;
impl->queue_tasks.start_loop(params.sleep_idle_seconds * 1000);
}代码回到server-context.cpp的handle_completions_impl函数中的2987行处,此时ctx_server.mctx为NULL,程序会直接调用2987行的tokenize_input_prompts函数执行分词任务。向下调试程序最终会进入到llama-vocab.cpp中的llama_vocab::tokenize函数中:
std::vector<llama_token> llama_vocab::tokenize(
const std::string & raw_text,
bool add_special,
bool parse_special) const {
return pimpl->tokenize(raw_text, add_special, parse_special);
}程序最终进入到llama_vocab::impl::tokenize函数进行分词任务,根据不同的词表类型执行不同的算法,本次调试此表的类型为SPM,所有的此表类型如下。
cpp
enum llama_vocab_type {
LLAMA_VOCAB_TYPE_NONE = 0, // For models without vocab
LLAMA_VOCAB_TYPE_SPM = 1, // LLaMA tokenizer based on byte-level BPE with byte fallback
LLAMA_VOCAB_TYPE_BPE = 2, // GPT-2 tokenizer based on byte-level BPE
LLAMA_VOCAB_TYPE_WPM = 3, // BERT tokenizer based on WordPiece
LLAMA_VOCAB_TYPE_UGM = 4, // T5 tokenizer based on Unigram
LLAMA_VOCAB_TYPE_RWKV = 5, // RWKV tokenizer based on greedy tokenization
LLAMA_VOCAB_TYPE_PLAMO2 = 6, // PLaMo-2 tokenizer based on Aho-Corasick with dynamic programming
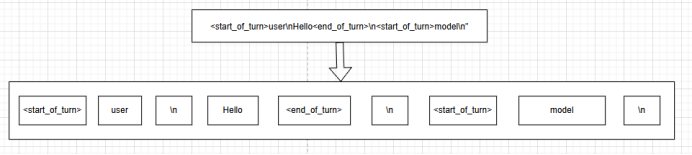
};首先执行tokenizer_st_partition函数,其根据词汇表中所记录的特殊字符,将文本分割为多个部分(fragment),其中<start_of_turn>、user、\n、<end_of_turn>、model为特殊字符。
进入 LLAMA_VOCAB_TYPE_SPM 算法分支,相关实现位于代码第 2961-3011 行。在已知词汇表及其对应分值(即每个 Token 关联的评分)的前提下,文本分词过程被转化为一个得分最大化的优化问题。其核心目标是将文本切分为特定的 Token 序列,使得该序列中所有 Token 的分值之和达到最大。
从源代码实现层面分析,第2970-2974行首先对是否插入起始特殊字符(BOS Token)进行逻辑判定。在当前的调试场景下,该操作被触发执行,且special_bos_id的数值设定为2。随后,程序针对每个文本片段(Fragment)开展分词处理。核心分词算法逻辑被封装在llm_tokenizer_spm_session结构体之中。
分词流程可细分为初始化、种子队列填充、迭代合并、结果输出与重分段四个阶段:
1)初始化阶段:将输入文本解构为最小的 UTF-8 字符单元,并建立各单元间的上下文邻接关系。由于 UTF-8 采用变长编码(Variable-length Encoding)机制,单个字符单元可能由多个字节组成(例如,常用中文字符在 UTF-8 下通常占用三个字节)。
2)种子队列填充阶段:尝试对相邻字符单元进行初步合并。若合并后的子串存在于词汇表中,则将其作为候选项压入种子队列,并记录其字节长度和分数。种子队列采用优先级排序,确保分值(Score)最高的候选项处于队首。
3)迭代合并阶段:基于贪婪策略(Greedy Strategy),按照分值由高到低的顺序依次合并相邻符号。该过程循环执行,直至当前序列中不再存在可进一步合并的有效单元。
4)结果输出与重分段阶段:将最终合并的字符串序列映射为相应的 Token ID。针对无法直接转换的子串,系统将启动重分段(Re-segmentation)机制;在极端回退情况下,系统会将字符拆分为单个原始字节(Byte),从而确保每个字节均能映射到对应的字节级 Token ID。
综上所述,该分词流程本质上是一种基于分值的贪婪合并机制(Score-based Greedy Merging)。其核心逻辑在于:在每一轮合并决策中,系统始终优先选取并合并当前序列中分值收益最高的相邻符号,直至完成最终的词元切分。
回到实验现象,两组输出日志可做如下物理解析:针对第一次对话,输入10个Token(1),模型推理生成33个Token(2),总计处理43个Token(3);推理完成后,3号槽位(4)释放,整个过程共计缓存42个Token(5)。进入第二次对话输入,后端匹配到42个已缓存的Token(6),本次共接收53个token(7),其中11个为新增Token(8);随后推理产生15个Token(9),本轮增量为26个Token(10),至此系统总计缓存达67个Token。每次缓存的Token数为用户输入Token数与模型推理产生Token之和再减一,因为模型推理产生的EOS(推理结束标记)不计入其中。
在第二次会话中,用户输入将与首轮输入及模型推理生成的 Token 进行拼接,并统一传递至模型层。由于拼接处额外引入了 '\n' 换行符,这解释了为何即便两次会话同样输入 'Hello',首轮 Token 计数为 10,而次轮Token量为 11。
文末
本章深入探讨大语言模型推理的关键准备环节------词汇表与分词,从基础知识、实验与现象和分析与结论三个方面展开详细的介绍。本章也存在未深入的知识点,例如,在处理多轮对话时,模型会复用前序对话的缓存数据,这涉及 Slot(即推理引擎中用于隔离和管理不同请求 KV-Cache 的逻辑槽位)的选择与匹配机制,相关内容将在后续章节中深入探讨。在下一章中,我们将继续剖析模型推理前的另一核心准备流程------设备后端(Backend)初始化以及张量从 CPU 到 GPU 的加载过程。