开篇介绍:
hello 大家,其实说实话,对于Linux的学习,是很枯燥的,因为这是我们之前从未接触过的东西,更是大大滴偏向硬件的方向,再换句话来说,我们之前学习C语言,C嘎嘎,其实都是在高楼的楼顶上进行学习,而当我们学习系统,其实就相当于是对这栋大楼的地基进行研究,并且还要想办法自己建一个这样的地基出来,那么各位,难度自然是毋庸置疑。
但是呢,风浪越大鱼越贵,对于难的内容,我们更不应该轻易放弃,因为一句话:他强任他强,清风拂山岗,哈哈哈,所以希望大家,不要放弃,即使很难,但是我们也终将克服。
OK大家,那么在本篇博客中呢,其实我就要给大家讲一讲进程地址空间(虚拟地址空间),这个不可谓不是一个很大的话题,那么对于地址,其实我们之前没少和它打交道,比如指针,那么其实,我们之前接触的地址空间,都是虚拟的,换句话说就是,它不是物理的,真实的,那么这究竟是什么意思呢?不要慌大家,在本篇博客中,我们将初步去探寻虚拟地址空间的奥秘,是的,是初步,这也就代表着,我们以后还会再讲到这个内容,所以,希望大家加油。
OK,话不多说,我们开始啦。
我们从一个生活场景说起,一步步把虚拟地址空间的本质、区域划分、地址转换、动态调整,以及核心管理结构体mm_struct和vm_area_struct讲透 ------ 你可以把它想象成 "每个程序专属的小区 + 超级仓库",操作系统就是这个小区和仓库的 "管理员",而虚拟地址就是这个系统里的 "位置编号"。
一、反常识的起点:同一个 "地址",装着不同的东西
假设你和邻居都收到快递,地址都是 "幸福小区 1 号楼 301",但你打开是苹果,邻居打开是香蕉 ------ 现实中这不可能,计算机里却天天发生。
看这段代码:
int g_val = 0; // 全局变量,像仓库里的"长期货架"
int main() {
pid_t id = fork(); // 父进程"复制"出子进程
if (id == 0) { // 子进程
g_val = 100; // 子进程把"苹果"换成"香蕉"
printf("子进程:g_val=%d,地址=%p\n", g_val, &g_val);
} else { // 父进程
sleep(3); // 等子进程改完再看
printf("父进程:g_val=%d,地址=%p\n", g_val, &g_val);
}
}输出结果让人大跌眼镜:
子进程:g_val=100,地址=0x80497e8
父进程:g_val=0,地址=0x80497e8关键怪事:地址完全相同(0x80497e8),但值却不一样!这说明这个 "地址" 不是真实的物理内存位置,而是操作系统给程序分配的 "虚拟编号"------ 就像 "幸福小区 1 号楼 301" 只是你和邻居各自小区里的门牌号,实际对应的 "仓库货架"(物理内存)完全不同。
二、虚拟地址空间:每个程序的 "专属小区"
每个程序(进程)运行时,操作系统会为它构建一个独立的虚拟地址空间,就像给程序分配了一个 "专属小区":
- 小区里的 "地图"= 虚拟地址(程序只用记这个编号);
- 小区里的 "超级仓库"= 按功能划分的内存区域(程序的所有数据、指令都存在这里)。
程序完全不用关心真实物理内存在哪 ------ 就像你寄快递只需要写小区门牌号,不用管小区在城市的具体位置,操作系统会帮你搞定 "门牌号" 到 "真实地址" 的转换。
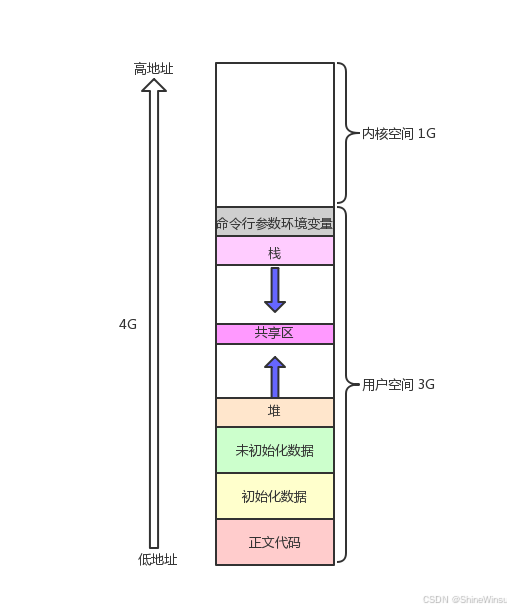
1. 超级仓库的 5 个核心功能区(从低到高地址排列)
这个 "超级仓库" 按功能划分成 5 个区域,每个区域有明确的用途、权限和地址规律,就像仓库分 "操作手册区""长期货架区""临时存储区":
| 区域名称 | 作用(仓库比喻) | 实际例子 | 权限控制 | 代码验证(打印地址) |
|---|---|---|---|---|
| 代码段 | 存放 "操作手册"------ 程序的可执行指令(如 main、printf),不能改(改了手册就乱了) | printf、fork 的执行代码(编译后固定不变) | 只读、可执行(防误改指令崩溃) | printf("代码段(main函数):%p\n", main);(地址最低) |
| 数据段 | 存放 "长期货架"------ 已初始化的全局变量 / 静态变量(如 g_val=0、static int s=10) | 全局变量 g_val、静态变量 static int s_val=10 | 可读写(允许修改变量值) | printf("数据段(g_val):%p\n", &g_val);(在代码段上方) |
| BSS 段 | 存放 "待填充的空货架"------ 未初始化的全局变量 / 静态变量,启动时自动填 0 | 未赋值的全局变量 g_unval、static int temp | 可读写(初始值为 0,和数据段类似) | printf("BSS段(g_unval):%p\n", &g_unval);(在数据段上方) |
| 堆 | 存放 "可扩建的临时存储区"------ 动态申请的内存(如 malloc 分配),需手动申请和释放 | char *p = malloc (10); 分配的 10 字节空间 | 可读写(支持动态扩缩容) | char *heap1 = malloc(10); printf("堆(heap1):%p\n", heap1);(BSS 段上方,地址递增) |
| 栈 | 存放 "自动伸缩的托盘"------ 函数调用时的临时变量、参数、返回地址(如 int i=0),函数结束自动释放 | 函数里的 int i=0、pid_t id=fork () | 可读写(自动扩缩容,有容量限制) | int stack1=0; printf("栈(stack1):%p\n", &stack1);(最高地址,地址递减) |
| 命令行参数 / 环境变量区 | 存放 "仓库入口清单"------ 程序启动参数(如./a.out 123)和环境变量(如 PATH) | 命令行参数 argv 1="123"、环境变量 PATH | 只读为主(一般只读取不修改) | printf("环境变量区(PATH):%p\n", getenv("PATH"));(靠近栈) |
地址规律验证(实际运行后从低到高排序):
代码段(main函数):0x559f3a7c1149
数据段(g_val):0x559f3a9c2010
BSS段(g_unval):0x559f3a9c2018
堆(heap1):0x559f3ab462a0
栈(stack1):0x7ffd1b2d875c
环境变量区(PATH):0x7ffd1b2d8a30 其实这些也已经是我们熟悉到不能再熟悉的内容了。
为什么要划分区域?
- 安全:代码段设为 "只读",避免程序误改指令导致崩溃;数据段、堆、栈设为 "可读写",满足正常变量修改需求。
- 高效:不同区域 "生命周期" 不同(代码段全程不变,栈随函数调用自动回收),分开管理能减少内存浪费。
- 方便编译:编译器编译时就能确定代码段、数据段的虚拟地址(比如 g_val 固定为 0x80497e8),不用关心物理内存位置。
三、虚拟地址怎么找到真实内存?------ 靠 "小箱子 + 对照表 + 管理员"
先焊死比喻:核心对应关系记牢
- 虚拟地址空间 = 你手里的 "个人书单编号"(比如 "我的书单第 5 本""我的书单第 12 本"),编号只对你的书单有用 ------ 别人也可能有 "第 5 本",但对应的书完全不同;
- 物理内存 = 图书馆的 "实体书架区"(全馆共用,每个位置有唯一编号,比如 "B 区 3 排 7 层""C 区 1 排 2 层"),是书真正存放的地方;
- 你的目标 = 按 "个人书单编号"(虚拟地址),找到图书馆书架上的实体书(数据 / 指令)------ 不用管书在哪个书架,有人帮你搞定。
而 "分册 + 借阅登记本 + 图书馆管理员",就是帮你实现这个目标的 "铁三角",全程自动运行,你只管报编号就行!
第一步:分页 ------ 把 "整本书" 拆成 "40 页小分册"(统一规格,找内容不费劲)
你想想:如果一本书厚 1000 页,你想找第 589 页的内容,得抱着整本翻半天,多麻烦?图书馆会干一件事:把所有书都拆成 "每册 40 页的小分册"(行业约定的规格,不大不小刚好)。
-
**规格为啥统一?**太大浪费:比如一篇只有 3 页的短文,非要装成 100 页的分册,剩下 97 页空着,白占书架;太小麻烦:比如一本 800 页的小说,拆成 1 页 1 册,得分成 800 册,找起来像翻字典,累死管理员。
-
**小分册的名字:**你的 "个人书单" 里的分册 = 虚拟分册(比如 "我的分册 3 号""我的分册 7 号")------ 就像你把自己的书单按 40 页一册拆分,每册编号固定;图书馆书架上的分册 = 实体分册(比如 "B 区 3 排 7 层第 2 册""C 区 1 排 2 层第 5 册")------ 图书馆的书也按 40 页一册拆分,和你的分册规格一模一样。
-
关键:虚拟地址的 "拆分技巧"你的 "个人书单编号" 不是一个 "死数字",而是 "分册号 + 分册内页码",就像 "我的分册 3 号 + 第 15 页":
- 虚拟分册号:哪本小分册(比如 "我的分册 3 号"= 书单里的第 3 个 40 页分册);
- 分册内页码:分册里的具体位置(比如 "15 页"= 从第3个40页分册第一页往后数 15 页)。
比如你要找 "一本占 3 页的笔记",虚拟地址是 "我的分册 3 号 + 第 15 页":
- 虚拟分册 3 号 = 告诉你 "这部分笔记在图书馆 B 区 3 排 7 层的实体分册里"(通过借阅登记本查的);
- 分册内 15 页 = 告诉你 "从实体分册的第 15 页开始看";
- 因为笔记占 3 页,所以 15、16、17 页都属于它 ------ 不用记这 3 页的虚拟地址,只记 "分册 3 号 + 15 页" 就行,管理员会自动往后翻 3 页。
- 这个页内偏移是很关键的内容,意思就是说在页表中虚拟内存地址是只存储实际物理内存的第一个地址,假设说物理内存中存储一个整型a,那么我们知道,a占4个字节,比如为0x11223344,那么对应到虚拟空间地址中,只会存储0x111111,那么这个就代表说,哦,我知道你这个虚拟内存对应的物理内存的第一个地址是0x11,那么后面的怎么找呢?其实很简单,因为我们知道a的类型,所以往后偏移该类型所占字节就行。
为啥分册内页码在虚拟分册和实体分册里一样?因为规格统一 ------ 你书单里 "分册 3 号的第 15 页",对应图书馆实体分册的 "第 15 页",直接对得上,不用重新找位置。
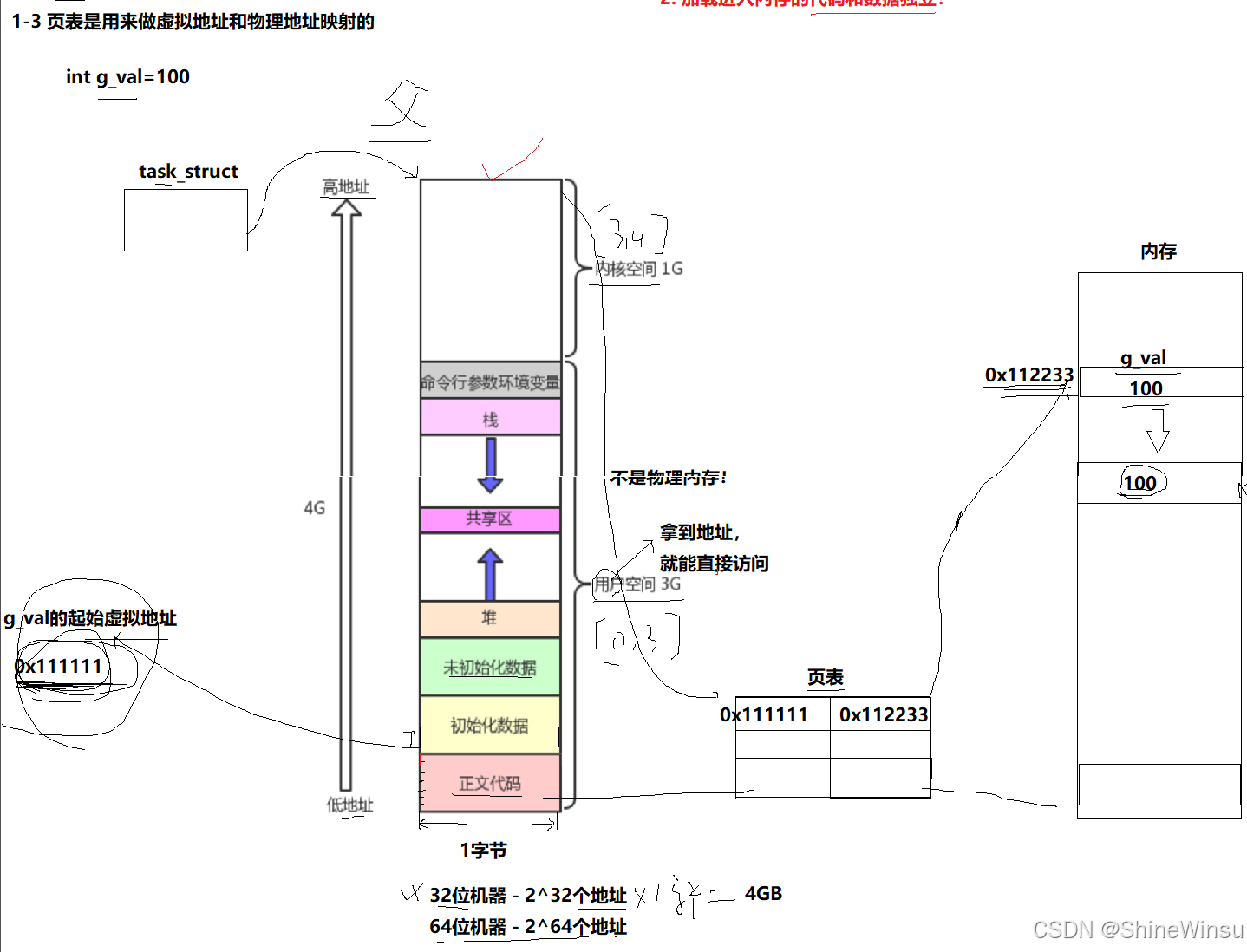
第二步:页表 ------ 你的 "专属借阅登记本"(只记你的分册→实体位置)
每个读者都有一本 "专属借阅登记本",这就是页表------ 相当于你手机里的私密备忘录,只记你的虚拟分册对应图书馆哪个实体分册的位置,别人看不到、用不了,完全独立。
-
登记本长什么样?(就 3 列,一眼看懂)
你的虚拟分册号(虚拟内存) 图书馆实体分册位置(物理内存) 书在不在书架上? 我的分册 1 号 B 区 3 排 7 层第 2 册 在(已上架) 我的分册 2 号 C 区 1 排 2 层第 5 册 在(已上架) 我的分册 3 号 空(没记录) 不在(还在仓库) 我的分册 4 号 A 区 5 排 3 层第 1 册 在(已上架) -
怎么用登记本找书?(3 步走,管理员自动干,你不用管)假设你要查 "我的分册 1 号 + 第 20 页"(对应虚拟地址):
- 管理员先 "拆编号"------ 像你先看登记本的 "分册号",把编号拆成 "我的分册 1 号" 和 "第 20 页",相当于是系统直接通过虚拟空间地址找到了其所对应的实际物理空间地址
- 管理员查你的专属登记本 ------ 找到 "我的分册 1 号" 对应 "B 区 3 排 7 层第 2 册",发现 "书在书架上"(已映射);
- 管理员算真实位置 ------B 区 3 排 7 层第 2 册的起始页(第 1 页) + 第 20 页 = 直接翻到实体分册的第 20 页,给你看内容。
生活例子:你说 "我要查我的分册 1 号第 20 页",管理员翻你的登记本:"分册 1 号在 B 区 3 排 7 层第 2 册",然后去那个位置,直接翻到第 20 页递给你 ------ 精准、不绕路!
在这里大家可能容易忽略一个点,就是以为系统是不知道物理内存的,其实这是不对的,系统在创建虚拟空间地址的时候,就已经把它所对应的物理空间地址给计入页表详细对应了,所以说,系统是完全清楚某一个虚拟空间地址是对应哪一个物理空间地址。
关键提醒:每个读者的登记本都独立!就像你的 "分册 1 号→B 区 3 排",别人的 "分册 1 号→A 区 5 排"------ 这就是为什么父子进程虚拟地址相同,值却不一样,因为它们的 "登记本"(页表)不一样,对应 "实体分册位置"(物理页框)不同!
第三步:缺页中断(重要)
如果登记本上某行是 "空"(比如我的分册 3 号,没对应实体分册位置),说明这部分书还没放上书架,还在图书馆的 "地下仓库"(磁盘的可执行文件或 swap 分区)。这时候 "管理员"(操作系统 + CPU)会出手,这个过程叫 "缺页中断"------ 全程自动,你完全没感觉,就像工作人员去仓库给你调书。
-
缺页中断的完整流程(像工作人员调书,一步不落)假设你要查 "我的分册 3 号" 里的内容(比如一个函数的代码):
- 管理员查你的登记本,发现 "我的分册 3 号→空",立刻喊仓库:"这分册不在书架,调一本过来!"(发缺页中断信号);
- 仓库收到信号,让你的 "查书流程" 暂停(程序暂停),说:"等 1 秒,我去仓库拿!"------ 暂停时间极短,你完全没感觉;
- 仓库找一个空的书架位置(比如 D 区 2 排 4 层第 3 册),确认没人用;
- 仓库去地下仓库,找到 "我的分册 3 号" 对应的书,拆成 40 页的分册,放到 D 区 2 排 4 层第 3 册的位置;
- 仓库更新你的登记本,把 "我的分册 3 号→D 区 2 排 4 层第 3 册" 填上,标上 "在书架上"(已映射);
- 仓库喊管理员:"分册放好了,继续吧!" 你的查书流程恢复;
- 管理员重新查登记本,找到 D 区 2 排 4 层第 3 册,翻到你要的页码,顺利给你看内容。
-
管理员的 3 个 "智能操作"(为啥靠谱?)
- 不浪费书架空间:你刚进图书馆时,不会把所有分册都放上书架,只放当前要看的 ------ 比如你先看小说,就只把小说分册放上架,工具书还在仓库,省出大量书架空间;
- 不打扰你:全程自动暂停、自动恢复,你查书时完全没感觉,就像工作人员转身去仓库拿书,你坐着等 1 秒就行;
- 只服务你:你用 D 区 2 排 4 层的位置,别人不会用,每个读者的书架位置和登记本都是独立的 ------ 不会出现 "你看的书,被别人拿走" 的情况。
-
大家要知道,这个缺页中断是个非常牛波一的设计,它帮助空间能够实现站着茅坑不拉屎的操作,具体是怎么说呢?就是说,系统会先去创建虚拟空间地址,即使这个虚拟空间地址对应的物理空间地址是啥也没有的,那也没事,我先给你创建了,代表你占着这个坑了,然后呢,轮到茅坑管理员检查你的时候,你没东西诶,那怎么办,这样子可是会被赶走被唾骂的,所以,系统就会赶紧去调资源给你这个虚拟空间地址所对应的物理空间地址,这么一来,你就有东西了,你就不用担心上表白墙了,哈哈哈,那么其实这就是缺页中断的一个牛波一之处。
-
那么其实它的真正的用处一般体现在内存爆满的情况下,假设有一堆进程占据着内存,哎呦,内存空间严重不足诶,怎么办怎么办,这个时候用户又非要再来一个进程,但是内存所剩的空间又无法完全容纳那个新进程,但是用户就是要开那一个新进程,霸道总裁,怎么办,诶。缺页中断就派上用场了,哈哈,系统说,bro,你很霸道,我很喜欢,那么我肯定就满足你,诶,你也不想想,我是一个多快的people,来,我就这么干,我给你要的新进程开辟一个虚拟空间地址,你先占着这个坑OK,然后你要用它的时候,我马上给你从硬盘那里调一些资源过去,比如说这个进程一共需要2个G的空间,但是内存中只剩下500MB的空间,系统说没事,我先调500MB的资源过去支撑你这个进程,然后用完之后,我马上再调500MB的资源过去,你就放心使用你的进程吧,我一定会满足你的需求,那么这么一来,就实现了内存爆满仅剩一些空间也能开个新进程,所以大家可以知道,缺页中断确实是一个很好的设计。
-
那么我们再说一下挂起和缺页中断的联系:
缺页中断负责 "按需取货",挂起负责 "暂时腾地方",俩配合起来,能把紧张的内存玩得明明白白。
先明确 "挂起" 是啥:当内存实在不够用,系统会把一些 "不常用的进程" 暂时 "请出内存"------ 也就是把这些进程的物理页(占着内存的实际数据)挪到磁盘的 swap 分区(相当于 "临时仓库"),只留下它们的虚拟地址空间(相当于 "占着的坑位编号"PCB)。这时候进程就进入 "挂起状态",像被暂时关进仓库,不占内存但 "坑位编号" 还在。
那缺页中断和挂起怎么搭伙干活?举个场景:内存已经满了,既有正在运行的进程 A、B,还有刚挂起的进程 C(它的物理页在 swap 分区,虚拟地址还在)。这时候用户又要启动进程 D,内存连 1MB 都挤不出来了 ------
- 挂起先出手腾地方:系统一看,进程 C 最近 10 分钟没怎么动,先把它挂起吧!于是把 C 的物理页全挪到 swap 分区,释放出 500MB 内存。
- 进程 D 启动,缺页中断登场:进程 D 启动时,系统先给它划好 2GB 虚拟地址(占坑),但内存只剩 500MB,不够装全。于是 D 运行时,用到哪部分虚拟地址,缺页中断就触发一次:先从磁盘调 500MB 数据进内存;用完这部分,再调下 500MB......(这部分和之前说的一样,缺页中断负责 "按需取货")。
- 挂起的进程 C 要运行了 :过了一会儿,用户想切回进程 C,这时候 C 的虚拟地址还在,但物理页全在 swap 分区(挂着呢)。当 C 要访问自己的虚拟地址时 ------
- 触发缺页中断:系统发现 "这坑位对应的物理页在仓库(swap)里",赶紧从 swap 分区把 C 的物理页搬回内存(如果内存又满了,可能再挂起一个不常用的进程,比如刚用完的 D 的部分页)。
- 更新页表:把 C 的虚拟地址重新和搬回的物理页绑定,C 从挂起状态恢复运行,仿佛从没被挪走过。
简单说:
- 挂起是 "暂时把不用的货挪到仓库,腾内存给急需的";
- 缺页中断是 "当要用这些挪走的货时,再从仓库搬回来,让进程接着用"。
俩配合起来,就算内存再紧张,系统也能通过 "暂时挂起→按需召回(缺页中断)" 的循环,让更多进程 "看起来都在正常运行"------ 本质上是用磁盘的 "慢空间" 换内存的 "快空间",而用户完全感觉不到这个腾挪的过程,这就是操作系统的 "障眼法" 精髓~
其实这个挂起我应该在上上篇博客就要说到的,但是关联不大,所以我并没有太详细的去说明,但是本质上是不难的,希望大家理解。
总结:完整流程串一遍(一句话记牢)
查虚拟地址→管理员拆成 "虚拟分册号 + 分册内页码"→查专属登记本:
- 若已上架(在书架):实体分册位置 + 页码 = 真实内容,直接看;
- 若未上架(在仓库):触发缺页中断,管理员调书、填登记本,再看。
就像你查自己书单里的内容:先看登记本找书架位置→有就直接翻→没有就喊管理员从仓库调,全程不用你管书在哪个仓库、怎么上架,只管记你的书单编号就行!
四、区域的动态调整:仓库如何 "扩建" 或 "收缩"
咱们把虚拟地址空间比作 "南北分治的大营地",用 "三八线" 的核心逻辑 ------"明确分界、各管一块、按需调整",把区域划分和动态调整讲得明明白白。
先定核心规则:营地的 "三八线体系"
整个虚拟地址空间就是一个 "长方形大营地",从营地最南边(低地址)到最北边(高地址),用几条 "类似三八线的分界线",划成 5 个 "功能专属区"。每个区有自己的 "管理规则"(能不能改、要不要手动管),就像南北营地各有职责,绝不越界乱搞:
| 营地区域(对应虚拟内存区域) | 位置(从南到北) | 功能(营地职责) | 管理规则(类似 "区规") |
|---|---|---|---|
| 1. 命令手册区(代码段) | 最南边(低地址) | 存 "营地行动指令"(比如 "早上 8 点集合、先查物资再报数") | 只读!不能改(改了指令全营乱套) |
| 2. 常备物资区(数据段) | 手册区北边 | 存 "提前备好的固定物资"(比如 "10 箱水、5 袋米",对应初始化的全局变量) | 可改(物资能换,但位置固定) |
| 3. 待补空库区(BSS 段) | 常备区北边 | 存 "空的物资架"(没提前备物资,对应未初始化的全局变量) | 自动补 0(空架先清干净,可改) |
| 4. 临时搭建区(堆) | 待补区北边 | 存 "临时申请的物资棚"(比如突然要放 2 箱急救包,对应 malloc 申请的内存) | 手动搭 / 拆(申请就搭棚,不用就拆棚) |
| 5. 任务托盘区(栈) | 最北边(高地址) | 存 "临时任务的托盘"(比如执行 "查岗" 任务时,放记录本、笔,对应函数临时变量) | 自动叠 / 收(任务来叠托盘,任务完收托盘) |
重点:这 5 个区之间的 "分界线" 是固定的 "虚拟三八线"------ 比如手册区和常备区之间、常备区和待补区之间,都有明确 "边界",绝不混放东西。比如不能把 "命令手册" 塞到 "任务托盘区",也不能把 "临时物资" 堆到 "命令手册区",保证营地不乱。
关键:区域能 "按需调整"------ 像营地临时扩缩地盘
"三八线" 是 "功能分界",不是 "死边界"------ 如果某个区不够用,能在 "不越其他区边界" 的前提下,往 "空白方向" 扩;用完了再缩回来,就像营地临时扩地盘,不影响其他区的正常运作。
1. 临时搭建区(堆):手动 "扩棚 / 拆棚"(对应 malloc/free)
堆是 "需要手动申请的临时物资棚",只能往 "北边空白处" 扩(从低地址往高地址增长),就像南边的临时搭建区,只能往北扩,不能往南占常备物资区的地。
场景 1:申请 10 箱急救包(malloc (1024),扩棚)
- 现状:当前临时搭建区的棚子只到 "北纬 0x559f3ab47000"(已放 3 箱物资),10 箱放不下;
- 算新边界:10 箱对应 1KB(0x400 字节),新棚子尽头设到 "北纬 0x559f3ab47000 + 0x400 = 0x559f3ab47400";
- 扩棚:营地管理员(操作系统)把搭建区的范围从 "南纬 0x559f3ab46000~ 北纬 0x559f3ab47000",扩到 "南纬 0x559f3ab46000~ 北纬 0x559f3ab47400"(往北多搭一块棚子);
- 给地址:告诉你新棚子的起点是 "北纬 0x559f3ab47000"(原棚子尽头),直接把急救包放这就行。
场景 2:用完急救包(free (p),拆棚)
- 若拆的是 "中间的棚子"(比如 "北纬 0x559f3ab46500" 的棚子):只在棚子上贴 "空闲" 标签,不拆整个棚(拆中间的棚会把其他物资挤乱),搭建区范围不变;
- 若拆的是 "最北边的棚子"(比如 "北纬 0x559f3ab47000" 的棚子):直接把棚子拆了,搭建区尽头缩回到 "北纬 0x559f3ab47000",把空地还给营地。
2. 任务托盘区(栈):自动 "叠托盘 / 收托盘"(对应函数调用 / 返回)
栈是 "临时任务的托盘区",只能往 "南边空白处" 扩(从高地址往低地址增长),就像北边的托盘区,只能往南叠托盘,不能往北占其他区的地。
场景 1:执行 "查岗" 任务(调用 func (a,b),叠托盘)
- 任务需要:放 "查岗名单(参数 a)、记录笔(参数 b)、任务完成后回哪(返回地址)、临时记录纸(变量 x)"------ 这些都要放托盘上;
- 自动叠托盘:原来托盘区的最南边在 "南纬 0x7ffd1b2d876c",现在往南叠了 4 个托盘(0x10 字节),最南边降到 "南纬 0x7ffd1b2d875c";
- 注意:托盘不能叠太多!如果超过营地规定的 "最大托盘高度"(比如 8MB),托盘会塌(栈溢出),任务直接失败。
场景 2:"查岗" 任务结束(函数返回,收托盘)
- 自动收托盘:把刚才叠的 4 个托盘全收走(参数、变量、返回地址全清);
- 恢复原位:托盘区的最南边回到 "南纬 0x7ffd1b2d876c",和任务前一模一样,像没叠过托盘。
3. 新增临时协作区(mmap):临时划 "跨区协作地"
如果需要和外部单位(比如磁盘里的文件 test.txt)合作,还能在营地中间 "空白处" 临时划一块 "协作区",就像南北营地之间临时开辟 "共同物资区",用完就收回。
比如要处理 1MB 的 "外部物资清单"(test.txt):
- 管理员(操作系统)在营地中间找一块空地方,划一个 1MB 的协作区,范围是 "南纬 0x559f3ac00000~ 北纬 0x559f3ac10000";
- 你要查清单时,管理员自动从外部(磁盘)把清单内容搬到这个协作区;
- 用完后,喊 "munmap" 就能收回这块地,协作区消失,营地恢复原样。
总结:用 "三八线逻辑" 理解虚拟内存
虚拟地址空间的 "区域划分",本质是用 "类似三八线的分界线",让代码、数据、临时变量各占一块地,不乱混、不越权(比如代码区只读,防止乱改);而 "区域调整",就是在 "不越界" 的前提下,按需扩缩地盘(堆手动扩、栈自动扩、新增临时区)------ 既保证营地(程序)不乱,又能灵活用空间,这就是虚拟内存高效又安全的核心。
五、管理工具:mm_struct(小区总台账)和 vm_area_struct(区域档案卡)
堆、栈的范围怎么记录?区域权限怎么管理?新增区域怎么追踪?靠操作系统的两个核心结构体:
1. mm_struct:每个进程的 "小区总台账"
每个进程只有一本 "总台账",记录虚拟地址空间的全局信息,方便快速掌握整体情况:
| mm_struct 核心字段 | 含义(小区总台账类比) | 实际作用举例 |
|---|---|---|
| pgd | 页表的 "总目录索引"------ 指向页表根节点(查物理地址的入口) | 程序访问 g_val 时,通过 pgd 快速找到对应的页表 |
| start_code/end_code | 代码段的 "起始 / 结束虚拟地址"(如 "操作手册区 1 号楼 101-199") | start_code=0x559f3a7c1149,end_code=0x559f3a7c2000(对应 main 函数区域) |
| start_data/end_data | 数据段的 "起始 / 结束虚拟地址"(如 "长期货架区 2 号楼 101-199") | start_data=0x559f3a9c2010,end_data=0x559f3a9c2014(对应 g_val 区域) |
| start_brk/brk | 堆的 "初始结束地址" 和 "当前结束地址"(brk 是堆当前边界) | 堆初始 start_brk=0x559f3ab46000,brk=0x559f3ab47000(初始大小 4KB) |
| start_stack | 栈的 "起始虚拟地址"(栈从高地址往低增长,只记起点) | start_stack=0x7ffd1b2d876c(对应 main 函数里 stack1 的初始地址) |
| mmap | 指向所有区域 "档案卡" 的链表头(台账的 "档案卡索引") | 通过 mmap 能快速找到堆、栈等所有区域的详细信息 |
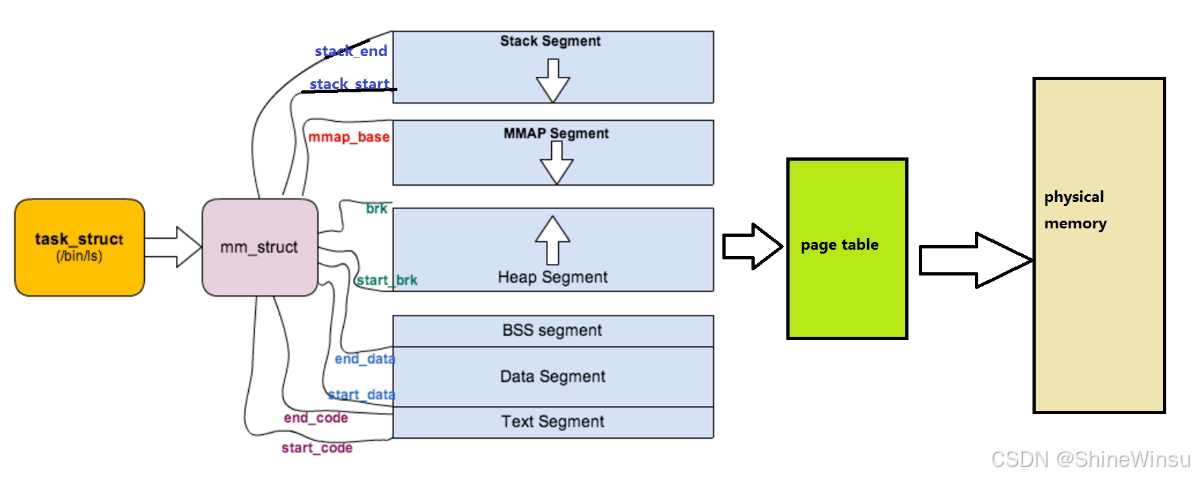
为什么需要 mm_struct?
- 快速查全局:堆当前大小 = brk - start_brk;确认虚拟地址属于哪个区域,先看 mm_struct 锁定大致范围;
- 一键回收:进程结束时,销毁 mm_struct 和关联档案卡,就能回收所有内存。
2. vm_area_struct:每个区域的 "详细档案卡"
每个功能区(代码段、堆、栈等)都有一张 "档案卡",记录区域的具体细节。这些档案卡通过vm_next连成链表,挂在 mm_struct 的mmap字段下,形成 "总台账→档案卡链表" 的管理体系:
| vm_area_struct 核心字段 | 含义(仓库分区档案卡类比) | 代码段档案卡举例 | 堆档案卡举例 |
|---|---|---|---|
| vm_start | 区域的 "起始虚拟地址"(如 "本区域从门牌号 XX 开始") | vm_start=0x559f3a7c1149(代码段起始) | vm_start=0x559f3ab46000(堆起始) |
| vm_end | 区域的 "结束虚拟地址"(如 "到门牌号 XX 结束") | vm_end=0x559f3a7c2000(代码段结束,2KB) | vm_end=0x559f3ab47000(堆初始结束,4KB) |
| vm_page_prot | 区域的 "权限设置"(如 "本区域只读、可执行") | vm_page_prot=PROT_READ|PROT_EXEC(只读 + 可执行) | vm_page_prot=PROT_READ|PROT_WRITE(可读写) |
| vm_flags | 区域的 "特殊标记"(如 "可动态扩展") | vm_flags=VM_READ|VM_EXEC(可读可执行) | vm_flags=VM_READ|VM_WRITE|VM_GROWSUP(可读写 + 向上扩展) |
| vm_next | 下一张档案卡的地址(如 "下一个区域档案卡在 XXX") | 指向数据段的 vm_area_struct | 指向栈的 vm_area_struct |
| vm_ops | 区域的 "管理函数集"(如 "扩容流程→调用 XXX 函数") | 包含 "读取指令" 函数 | 包含 "扩容(expand)""释放(free)" 函数 |
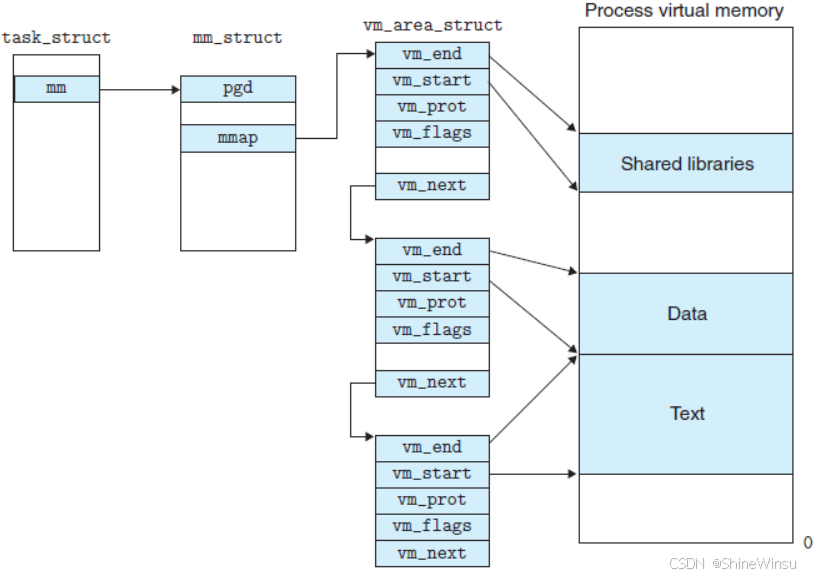
堆的 vm_area_struct 档案卡实例(初始范围 0x559f3ab46000~0x559f3ab47000):
vm_start = 0x559f3ab46000; // 堆起始地址
vm_end = 0x559f3ab47000; // 堆当前结束地址
vm_page_prot = PROT_READ | PROT_WRITE; // 可读写权限
vm_flags = VM_READ | VM_WRITE | VM_GROWSUP; // 允许向上扩展
vm_next = 0x7ffd1b2d876c; // 下一张是栈的档案卡
vm_ops = { expand: 堆扩容函数, free: 堆释放函数 }; // 堆管理操作3. 两个结构体的配合(以堆扩容为例)
当用malloc(1024)申请内存时,协作流程:
- 查总台账(mm_struct):通过
start_brk和brk知道堆当前范围,发现空间不足; - 查堆的档案卡(vm_area_struct):通过
mmap找到堆的档案卡,确认vm_flags允许扩容(VM_GROWSUP),权限符合; - 计算新边界:新 brk = 原 brk+1024=0x559f3ab47400;
- 更新档案卡和总台账:
- 堆的 vm_area_struct 的
vm_end改成 0x559f3ab47400; - mm_struct 的
brk改成 0x559f3ab47400;
- 堆的 vm_area_struct 的
- 分配完成,返回新地址。
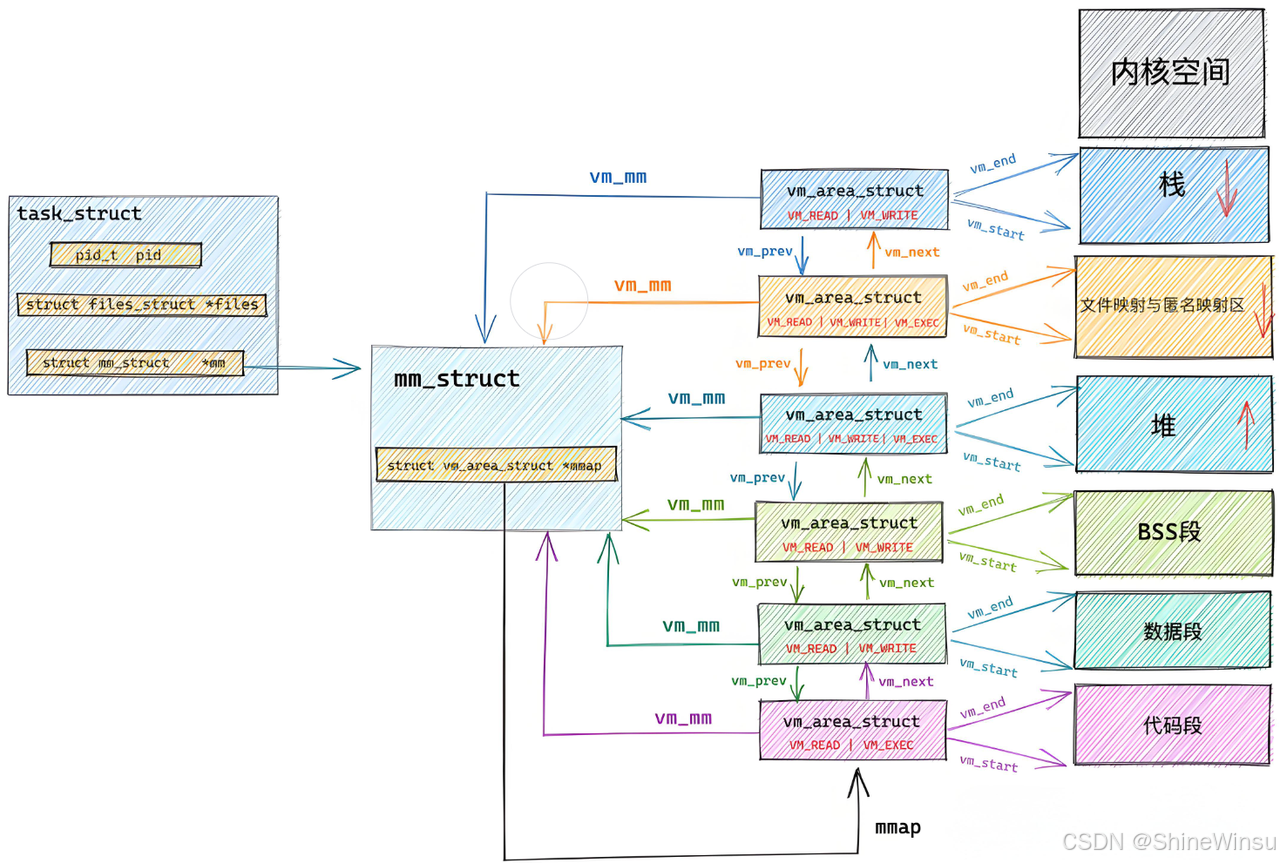
补充:是否冲突?
大家可能会好奇mm_struct有记载空间的起始和结束位置,而vm_area也有记载,这不是重复了吗?
我用大家比较习惯的例子来讲解一下:
先给俩结构体定 "奶茶店角色"
- mm_struct:奶茶店的 "前台总台账"------ 就一张纸,记店里几个核心区域的 "大概在哪",方便前台快速指路。
- vm_area_struct:奶茶店每个区域的 "专属小黑板"------ 每个区域(比如操作台、储物间、等待区)都挂一块,记这个区域 "精确到厘米的位置 + 怎么用",方便店员干活。
为啥 "起止地址" 不重复?看 3 个生活场景
- 记的 "粗" 和 "细" 完全不一样
mm_struct 的 "起止地址" 是 **"大概范围"**,像台账上写:"操作台:在店里左边区域;储物间:在店后面角落"------ 不用写具体从哪到哪,只要知道 "大概方位" 就行。
vm_area_struct 的 "起止地址" 是 **"精确到厘米"**,像操作台的小黑板上写:"操作台范围:从左墙 1 米处到左墙 3 米处(宽 2 米),左边放奶茶机(占 0.5 米),右边放果糖机(占 0.3 米)"------ 必须精确,不然设备放错地方就挤不下了。
比如奶茶店想加个新设备,先看台账:"哦,操作台在左边,有空地";再看小黑板:"操作台从 1 米到 3 米,中间还剩 1.2 米,够放新设备"------ 前者给 "大方向",后者给 "精确位置",缺一不可。
- 用途不一样:"快速指路" vs "管具体干活"
mm_struct 记起止地址,是为了 **"快速判断'东西在哪'"**。比如客人问 "吸管在哪?",前台看台账:"吸管在前台区域"------ 不用翻其他记录,1 秒就能指方向,不用管前台里吸管具体放左边还是右边。
vm_area_struct 记起止地址,是为了 **"管好这个区域的细节"**。比如前台的小黑板写:"吸管盒:前台台面上从左 0.2 米到 0.4 米处,每天补 3 次货"------ 店员补货时,按这个精确位置找,不会乱翻;还要按 "补 3 次货" 的规则操作,这都是小黑板的活,台账不管。
- 记的 "区域数量" 不一样:"只记核心区" vs "所有区都记"
mm_struct 的台账只记店里最核心的几个区,比如 "操作台、前台、储物间"------ 像 "垃圾桶区、客人等待区" 这种 "非核心区",台账根本不写,写了反而乱。
vm_area_struct 的小黑板所有区域都有------ 哪怕是 "垃圾桶区",也会挂个小黑板:"垃圾桶:店门口右侧 0.5 米到 1 米处,每天 6 点倒";"等待区:店中间 2 米到 4 米处,放 4 张凳子"。
比如店里要清洁,清洁工看小黑板:所有区域的精确位置和清洁规则都有;要是只看台账,连垃圾桶在哪都不知道,根本没法干活。
总结:俩结构体是 "前台指路" 和 "区域干活" 的配合
mm_struct 的 "起止地址" 是 "大方向路标"------ 帮你快速找到 "大概在哪";vm_area_struct 的 "起止地址" 是 "精确操作指南"------ 帮你管好 "具体怎么用"。
就像奶茶店:前台靠台账快速给客人指路,店员靠小黑板精确干活,俩东西分工不同,根本不重复,少了哪个都不行,希望大家理解。
六、如何 "看到" 这些管理工具的内容?
操作系统把 mm_struct 和 vm_area_struct 的信息暴露在/proc/[进程号]/maps文件里。比如运行 g_val 程序(进程号 1234),执行cat /proc/1234/maps会看到:
08048000-0804a000 r-xp 00000000 08:01 123456 /a.out # 代码段(vm_start-vm_end;权限r-xp=只读+可执行)
0804a000-0804b000 rw-p 00002000 08:01 123456 /a.out # 数据段(权限rw-p=可读写)
0804b000-0804c000 rw-p 00000000 00:00 0 # BSS段(权限rw-p)
0804c000-0804e000 rw-p 00000000 00:00 0 # 堆(权限rw-p,可扩展)
bffff000-c0000000 rw-p 00000000 00:00 0 # 栈(权限rw-p)
7f000000-7f001000 r--p 00000000 08:01 789012 /test.txt # mmap映射区(权限r--p=只读)这些内容直接来自 vm_area_struct:
- 第一列 "08048000-0804a000"=vm_start-vm_end;
- 第二列 "r-xp"=vm_page_prot 的权限(r = 读,x = 执行,p = 私有);
- mm_struct 里的
start_code"08048000"、end_code"0804a000",和代码段范围完全一致。
这个大家可以先不用在乎。
七、回到开头的代码:为什么地址相同,值却不同?
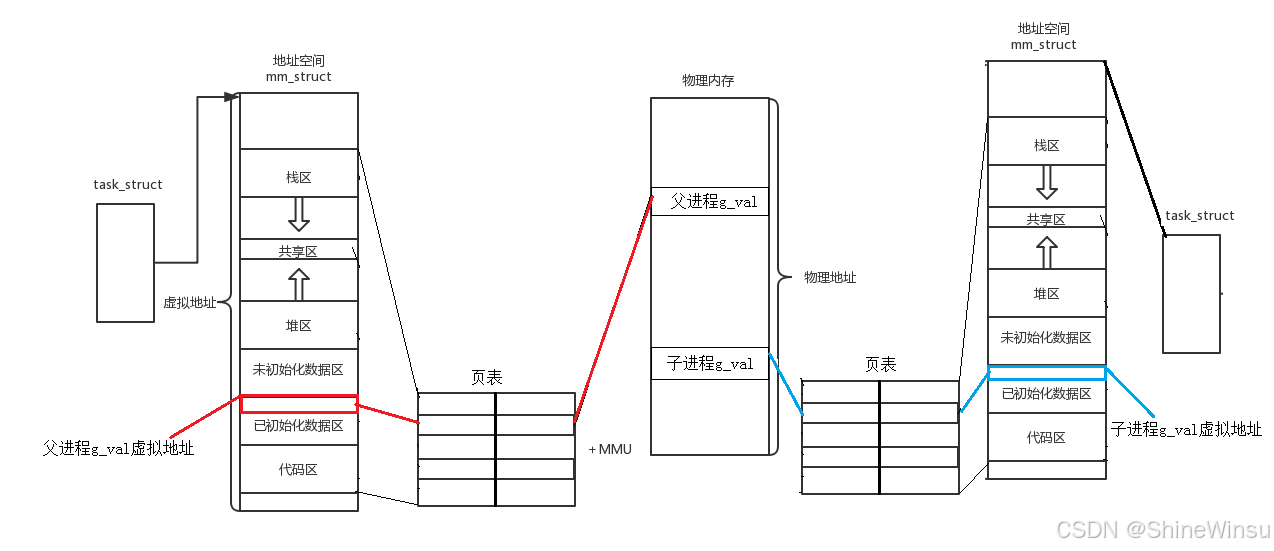
这个问题的核心是 "虚拟地址不变,物理内存映射在子进程修改时分离":
阶段 1:父进程单独运行时 ------ 虚拟地址绑定唯一物理内存
父进程启动后,操作系统分配了独立的虚拟地址空间、页表和物理内存:
- 虚拟地址:g_val 的虚拟地址固定为 0x80497e8(编译器编译时确定);
- 物理内存:第一次访问 g_val 触发缺页中断,操作系统从磁盘把 g_val 加载到 "5 号页框"(物理地址 = 5 号页框起始地址 + 0x7e8),存着 g_val=0;
- 页表映射:父进程页表中,"虚拟页 1"(0x80497e8 所在页)对应 "物理页框 5",权限为 "可读写"(数据段允许修改)。
此时关系:父进程虚拟地址0x80497e8 → 父进程页表(1→5,可读写) → 物理页框5(g_val=0)
阶段 2:子进程刚创建(fork 后)------ 共享物理内存,页表权限悄悄改
fork的核心是 "复制" 父进程资源,但为了高效,采用 "写时拷贝(Copy-On-Write)" 策略:不立即复制物理内存,只复制 mm_struct、vm_area_struct 和页表,同时修改页表权限:
- 虚拟地址:子进程复制了父进程的虚拟地址空间规则,g_val 的虚拟地址还是 0x80497e8;
- 物理内存:暂时共享父进程的 "5 号页框"(g_val=0),不新建物理页(节省内存);
- 页表映射:子进程页表复制了 "虚拟页 1→物理页框 5",但权限改成 "只读"------ 这是写时拷贝的关键:监控谁会先修改数据。
此时关系:父进程虚拟地址0x80497e8 → 父进程页表(1→5,只读) → 物理页框5(g_val=0)``子进程虚拟地址0x80497e8 → 子进程页表(1→5,只读) → 物理页框5(g_val=0)
此时父子进程读 g_val 都是 0,地址相同。
阶段 3:子进程修改 g_val=100------ 触发写时拷贝,物理内存分离
当子进程执行g_val=100时,试图往 "只读" 的物理页框 5 写数据,触发 "页错误"(CPU 发现权限不匹配),操作系统处理流程:
- 分配新物理页:从空闲物理内存分配 "6 号页框";
- 复制数据:把 "5 号页框" 的 g_val=0 完整复制到 "6 号页框";
- 更新子进程页表:
- 把 "虚拟页 1" 的映射改成 "物理页框 6";
- 恢复权限为 "可读写"(数据段本应允许修改);
- 执行写入:子进程把 "6 号页框" 的 g_val 改成 100;
- 父进程不受影响:父进程页表仍为 "虚拟页 1→5 号页框",权限只读,g_val 还是 0。
此时关系彻底分离:父进程虚拟地址0x80497e8 → 父进程页表(1→5,只读) → 物理页框5(g_val=0)``子进程虚拟地址0x80497e8 → 子进程页表(1→6,可读写) → 物理页框6(g_val=100)
核心结论
- 虚拟地址相同:因为父子进程复制了相同的 mm_struct 和 vm_area_struct,虚拟地址空间规则一致,门牌号(0x80497e8)不变;
- 值不同:子进程修改数据触发写时拷贝,操作系统给它分配了新的物理页框,且只更新子进程的页表映射 ------ 同一个门牌号,对应不同的真实货架。
虚拟地址空间的作用:
我依旧是给大家举例子来分析:
先聊:直接用物理内存,就像 "小区仓库没规矩",问题一堆
早期计算机直接用物理内存,就像小区里只有一个大仓库,所有住户(进程)的东西都往里面堆,没任何管理规则 ------ 这日子没法过,具体坑在哪?
坑 1:安全风险 ------"谁都能翻别人的东西,还能拆仓库"
如果直接用物理内存,每个程序(住户)能直接访问仓库的任意角落(物理地址)。
- 比如你存了个私密文件在仓库的 "3 号货架",隔壁程序(恶意住户)能直接跑到 3 号货架,把你的文件删了、改了;
- 更要命的是,仓库管理员(操作系统)的 "管理手册"(核心数据)也在仓库里,要是被恶意程序找到,直接改了 "开门时间""收费规则",整个小区(计算机)就瘫痪了。
这就像小区仓库不上锁,谁都能进,还能随便动别人的东西,甚至砸仓库的承重墙 ------ 太危险了!
坑 2:地址不确定 ------"每次放东西的位置都不一样,自己都找不到"
程序编译好后,就像你打包了一箱快递,想放到仓库里。但如果直接用物理内存,每次放的位置都不确定:
- 第一次用这个程序时,仓库是空的,你的快递被放在 "1 号货架";
- 第二次用的时候,仓库已经堆了别人的东西,你的快递可能被放在 "100 号货架";
- 但程序里的代码是 "死的"------ 比如代码里写着 "去 1 号货架拿数据",结果第二次运行时数据在 100 号货架,程序直接懵了,跑不起来。
这就像你每次寄快递,收件地址都被快递员随便改,你写的 "家门口取件",结果快递员放了小区门口、超市、垃圾桶旁...... 你永远不知道去哪找,程序自然就乱了。
坑 3:效率低下 ------"搬家必须搬全家,累死"
物理内存不够时,需要把暂时不用的程序 "搬到磁盘的交换区"(相当于小区仓库满了,把不用的东西挪到远处的储藏室)。但直接用物理内存时,程序是 "一整块" 存在仓库里的:
- 比如一个 1GB 的程序,哪怕只有 100MB 在被使用,剩下 900MB 都闲着,搬家时也得把 1GB 全挪走;
- 从仓库到储藏室(内存到磁盘)搬 1GB 数据,耗时特别长,电脑会卡顿半天。
这就像你家只暂时不用客厅的沙发,却被要求把整个房子的家具(卧室的床、厨房的锅)全搬到储藏室 ------ 纯属折腾,效率低到离谱。
再看:虚拟地址空间 + 分页机制,就是给仓库立规矩,完美填坑
虚拟地址空间的核心是:给每个程序(住户)一套 "自己家的抽屉编号"(虚拟地址),再用 "对照表"(页表)映射到仓库的实际货架(物理内存),由管理员(操作系统)全程盯着 ------ 三个坑全解决!
解决安全风险:"每家抽屉独立,管理员把门"
- 每个程序只能看到自己的 "抽屉编号"(虚拟地址),比如你家只有 "客厅抽屉 1 号""卧室抽屉 3 号",永远看不到别人家的抽屉;
- 程序想访问数据时,必须通过管理员(OS)查 "对照表"(页表),管理员只允许它访问自己对应的仓库货架(物理内存),别人的货架根本碰不到;
- 管理员的 "管理手册"(核心数据)有单独的 "禁区抽屉",普通程序的对照表里根本没有这个抽屉的映射,想访问?门都没有!
就像小区给每家发了独立的带锁抽屉,钥匙只有管理员和你有,别人打不开你的抽屉,更碰不到管理员的办公室 ------ 安全多了!
解决地址不确定:"自家抽屉编号不变,管理员负责找仓库位置"
- 程序编译时,就确定了自己要用的 "抽屉编号"(虚拟地址),比如代码里永远是 "去客厅抽屉 1 号拿数据";
- 实际运行时,管理员(OS)会找仓库里的空闲货架(物理内存),用 "对照表" 把 "客厅抽屉 1 号" 映射到任意货架(比如第一次映射到 5 号货架,第二次映射到 8 号货架);
- 程序不用管仓库货架在哪,它只认自己的抽屉编号,管理员会自动把抽屉里的东西 "同步" 到实际货架 ------ 程序永远觉得 "我的东西就在自家抽屉里",运行起来稳稳的。
这就像你永远用 "自家客厅抽屉 1 号" 收快递,快递员(OS)会把快递放进仓库的任意货架,然后在你家的对照表上写 "客厅抽屉 1 号→仓库 5 号货架"------ 你不用管仓库在哪,打开自家抽屉(虚拟地址)就能拿到东西,地址永远确定。
解决效率低下:"只搬不用的小箱子,不用搬全家"
- 分页机制把内存切成 4KB 的 "小箱子"(虚拟页和物理页框),程序的数据被拆成一个个小箱子;
- 内存不够时,管理员只把 "暂时不用的小箱子"(比如你半年没碰的旧文件)搬到储藏室(磁盘),常用的小箱子(比如你正在看的文档)还留在仓库;
- 搬一个 4KB 的小箱子,比搬 1GB 的整块数据快太多,电脑几乎不卡顿。
这就像你家的东西被分成一个个小收纳盒,暂时不用的 "旧书盒""过冬衣服盒" 被搬到储藏室,常用的 "牙刷盒""手机充电器盒" 留在家里 ------ 搬家只搬几个小盒子,效率高到飞起!
还有个隐藏好处:"先占坑,后交钱"(延迟分配)
虚拟地址空间还有个贴心设计:你用 malloc/new 申请内存时,管理员只是在你家的 "抽屉系统" 里划一个新抽屉(分配虚拟地址),但仓库里暂时不给你货架(不分配物理内存);只有当你真正往这个抽屉里放东西(访问内存)时,管理员才会找个空闲货架,把抽屉和货架映射起来(填页表)。
这就像你先在自家墙上画个 "未来的书架"(占坑),什么时候买了书,管理员再给你找个仓库格子放书 ------ 不浪费空间,灵活又高效。
总结:虚拟地址空间就是 "给内存加了层规矩"
直接用物理内存 = 无规矩的混乱仓库,安全没保障、地址乱变、效率低;虚拟地址空间 + 分页 = 有规矩的智能仓库,每家独立抽屉(安全)、自家地址不变(稳定)、按需搬小箱子(高效)。
写时拷贝的好处:
那么在最后,我再给大家补充一下写时拷贝的好处:
写时拷贝(Copy-on-Write,COW)的好处,用 "共用笔记本" 的例子一讲就透 ------ 它就像两个同学共用一本笔记,平时一起看,谁要改才自己抄一页,既省时间又省纸,核心是 "不浪费、高效率"。
先看没有写时拷贝的 "坑":复制整本笔记太费劲
假设父进程是 "小明",他有一本 100 页的笔记(内存数据)。子进程 "小红" 是小明的复制体(比如用 fork 创建)。
如果没有写时拷贝,系统会直接给小红 "抄一本一模一样的 100 页笔记"------ 哪怕小红从头到尾一页都没改,也要花时间抄、花纸存。
- 费时间:抄 100 页笔记要 10 分钟,小红想开始学习(运行),必须等 10 分钟抄完,效率极低;
- 费空间:两本一模一样的笔记,占了两倍的纸(内存),明明大部分内容都一样,纯属浪费。
写时拷贝的 "聪明操作":先共用,改的时候再抄
写时拷贝的核心逻辑是:"不着急抄,先一起用,谁改哪页就抄哪页"。
小明和小红共用同一本笔记(内存页共享),笔记上每一页都标着 "两人共用,未修改"。
- 如果两人都只看不动笔(读内存):永远共用这一本,不用抄,省时间也省纸;
- 一旦有人要改某一页(写内存):比如小红想改第 30 页,系统会立刻把第 30 页抄一份给小红,小红改自己的副本,小明的原页不变;其他没改的页继续共用。
具体好处:3 个 "省" 字总结
1. 省内存空间 ------ 不浪费 "重复纸"
大部分情况下,子进程创建后并不会修改父进程的所有数据(比如小红可能只改笔记的 3 页,其他 97 页和小明一样)。写时拷贝只复制 "被修改的页",没改的页继续共享,避免了 "复制整本笔记" 的内存浪费。比如 100 页的笔记,小红只改 3 页,总共只用 100+3=103 页的纸,而不是 200 页 ------ 内存利用率直接翻倍。
2. 省时间 ------ 创建子进程 "秒启动"
没有写时拷贝时,创建子进程要等 "整本笔记抄完" 才能运行;有了写时拷贝,创建时不用抄任何内容,直接共享,子进程 "瞬间启动"。比如抄 100 页要 10 分钟,现在 0 分钟就能让小红开始看笔记(读操作),只有改的时候才花几秒钟抄一页 ------ 进程创建速度极大提升。
3. 省操作 ------ 避免 "无用功"
很多场景下,子进程创建后会立刻执行新程序(比如用 exec 系列函数),此时子进程会完全丢弃父进程的内存数据。如果一开始就复制父进程的所有内存,这些复制操作就成了 "无用功"(刚抄完就扔)。写时拷贝则完美避开这种浪费:子进程创建时不复制,等 exec 执行时直接丢弃共享页,全程没做一点无用的复制。
总结:写时拷贝是 "按需复制" 的智慧
它的核心是 "不提前浪费资源,只在必要时付出成本"------ 就像共用笔记时 "不预抄、改才抄",既高效又节俭。这也是现代操作系统(比如 Linux)在进程创建时(fork)必须用写时拷贝的原因:能在多进程场景下,把内存和时间的浪费降到最低。
结语:在抽象的地基上,建起属于自己的高楼
敲下最后一个字符时,窗外的天已经暗了。回头看这篇关于进程地址空间的文字,突然想起第一次调试那段父子进程打印全局变量的代码 ------ 当看到相同地址却输出不同值时,我盯着屏幕愣了十分钟,像撞见了编程语言的 "灵异事件"。后来才知道,那不是灵异,而是虚拟地址空间给初学者的第一个 "下马威":它用一层精妙的抽象,把物理内存的复杂藏了起来,却也在代码的表象下,悄悄埋下了理解操作系统的钥匙。
其实学习 Linux 的过程,就像在拆一台精密的钟表。一开始,你只看到表盘上的指针在动(比如printf输出结果、malloc拿到地址),觉得 "不过如此";可当你想拆开外壳看看齿轮怎么转时(比如追问 "这个地址到底存在哪""内存不够时系统在干嘛"),才发现里面的结构远比想象中复杂:齿轮套着齿轮(虚拟地址→页表→物理内存),弹簧连着杠杆(缺页中断→磁盘交换→页表更新),任何一个小零件的原理都能让人琢磨半天。
就像我们花了这么多篇幅聊的 "虚拟地址空间",它明明是 "假的"------ 没有一块物理内存真的按 "代码段在下、栈在上" 的顺序排列,可它又是 "真的"------ 每个进程都坚信自己拥有这样一片连续的地址空间,并且能安全、稳定地在上面运行。这种 "假作真时真亦假" 的抽象能力,正是操作系统最了不起的智慧。
你看,它用 "虚拟地址" 解决了 "物理地址不确定" 的难题:让编译器在编译时就能给变量、函数 "预定门牌号",不用管这些门牌号最终对应哪块物理内存,程序跑起来时,操作系统会拿着 "页表" 这个对照表,帮它找到真正的 "货架"。
它用 "区域划分" 解决了 "内存管理混乱" 的难题:代码段只读防篡改,堆手动申请释放,栈自动伸缩,就像给仓库分了 "操作手册区""临时存储区""自动托盘区",每个区域有自己的规矩,各司其职又互不干扰。
它用 "分页 + 缺页中断" 解决了 "内存效率低下" 的难题:程序启动时不用一股脑把所有数据塞进内存,像搬家时先把常用的锅碗瓢盆拿出来,换季的衣服暂时留在箱子里,等需要时再打开 ------ 这种 "按需加载" 的思路,让有限的物理内存能同时 "装下" 比它大得多的程序。
还有那些藏在背后的管理工具:mm_struct像小区总台账,记下核心区域的大致范围;vm_area_struct像每个区域的档案卡,精确到字节地记录边界、权限和操作规则。它们一个管全局,一个管细节,配合得天衣无缝,让内存的动态调整(堆扩容、栈伸缩、mmap 新增区域)能有条不紊地进行。
而写时拷贝则更像一种 "精打细算的智慧":父子进程共用内存页,谁修改谁复制,既避免了创建子进程时的 "全量复制" 浪费,又保证了数据独立性。这种 "不提前浪费资源,只在必要时付出成本" 的设计,像极了生活中 "按需点菜" 的智慧 ------ 既不委屈自己,也不铺张浪费。
这些知识,初看时确实枯燥。那些十六进制的地址(0x559f3ab47000)、绕来绕去的映射关系(虚拟页→物理页框→页内偏移)、长得像 "密码" 的结构体字段(vm_start、pgd),像一堆零散的拼图,让人不知道从哪下手。可当你慢慢把它们拼起来,看到 "虚拟地址空间" 这张完整的图景时,会突然有种 "原来如此" 的通透感:
原来fork创建子进程时,不是真的 "复制" 了一整个进程,而是用页表耍了个 "小聪明";原来malloc申请内存时,可能只是在虚拟地址空间里 "画了个圈",物理内存要等真正用的时候才会分配;原来程序崩溃时的 "段错误",多半是操作系统在保护内存 ------ 不允许你访问没有权限的区域,就像小区保安拦住试图闯进别人家门的陌生人。
这让我想起开篇说的那句话:学 C 语言像在高楼楼顶玩耍,学操作系统像在研究地基。楼顶的风景固然精彩(写出炫酷的功能、实现复杂的算法),可只有看懂了地基的构造(内存管理、进程调度、文件系统),你才知道这栋楼为什么能站稳,为什么能盖那么高。
或许你现在还会觉得这些知识 "没用"------ 写业务代码时,谁会天天惦记 "页表有没有命中""堆是怎么扩容的"?但就像建筑师必须懂力学,医生必须懂解剖学,当你想写出更高效、更健壮的程序,想排查那些诡异的内存泄漏、性能瓶颈时,这些藏在底层的知识,会成为你最有力的武器。
我至今记得第一次通过/proc/[pid]/maps文件,看到进程地址空间的真实布局时的兴奋:代码段的r-xp权限、堆的连续地址范围、栈的高地址分布,和课本里画的图一模一样。那一刻,那些抽象的概念突然有了具体的模样,就像隔着屏幕摸到了操作系统的脉搏。
学习 Linux 的路,注定不会轻松。你会遇到很多 "想不通" 的时刻:为什么free后指针还能访问?为什么栈溢出会导致程序崩溃?为什么多线程共享地址空间却有独立的栈?这些问题就像路上的石头,会硌得你脚疼,但每搬开一块,你就离底层逻辑更近一步。
别害怕 "暂时不懂"。操作系统的设计是几十年计算机科学家智慧的结晶,凭什么我们看几遍就能完全吃透?重要的是保持好奇,多问 "为什么":看到malloc,就想它背后调用了什么系统调用;看到进程切换,就想 CPU 的上下文存在了哪里;看到内存泄漏,就想哪些区域的内存没有被正确释放。
就像虚拟地址空间用 "抽象" 简化了程序对内存的使用,我们也可以用 "拆解" 简化学习的难度:先记住 "虚拟地址→页表→物理内存" 这个大框架,再慢慢填进 "分页""缺页中断""写时拷贝" 这些细节;先理解 "堆和栈的生长方向不同",再去探究brk系统调用和栈溢出保护的原理。
最后想对你说:当你觉得难的时候,恰恰是在进步。那些对着页表映射图抓头发的夜晚,那些为了理解mm_struct和vm_area_struct的关系画了又擦的草稿,那些在调试器里一步步跟踪内存变化的耐心,都不会白费。它们会像虚拟地址空间里的 "页表" 一样,把你学到的零散知识,映射成一套完整的认知体系。
或许有一天,你会在调试一个棘手的 bug 时,突然想起 "写时拷贝" 的机制,瞬间明白为什么父子进程的数据会出现差异;或许你会在优化程序性能时,因为懂了 "缺页中断" 的开销,而有意识地减少随机内存访问。到那时,你会感谢现在这个愿意沉下心来啃硬骨头的自己。
Linux 的世界很大,进程地址空间只是其中一块拼图。但当你真正理解了它,你会发现自己看待程序的眼光已经不一样了 ------ 你不再只看到代码的表面,更能看透它运行时的底层逻辑,就像学会了 "透视眼",能看到那些藏在屏幕背后的内存流动、地址转换和权限校验。
所以,别着急,慢慢来。把每个抽象的概念落地到具体的例子里(就像我们用 "小区仓库""共用笔记本" 来理解虚拟地址和写时拷贝),把每个复杂的机制拆成一步步的流程(就像我们拆解 "虚拟地址转物理地址" 的三步法)。只要方向对了,每一步都算数。
风浪越大,鱼越贵。学习底层知识的过程,就像在深海里捕鱼,初期可能只有零星的收获,甚至会呛几口海水,但当你潜得足够深,总能捕到属于自己的 "大鱼"。
愿你在探索 Linux 的路上,既能享受拆解难题的乐趣,也能收获看透本质的通透。我们下一个知识点再见。