在日志审计场景中,敏感信息检测是保障数据安全的核心环节。传统正则匹配虽能快速定位固定格式的敏感内容(如身份证号、手机号),但面对非结构化日志中的语义化信息(如人名、地名、组织机构)时,往往显得力不从心。Inspectio工具的NLP敏感实体检测模块,基于spaCy框架的命名实体识别(NER)能力,完美弥补了正则检测的短板,实现了非结构化日志中敏感语义信息的自动识别,与正则检测形成互补,大幅提升日志审计的全面性与准确性。
本文将从实现原理、预定义敏感实体类型、误报处理机制三个核心维度,结合实操方案,带大家全面掌握该模块的使用方法,助力高效完成日志审计工作。
一、NLP检测原理:spaCy驱动的智能识别
1.1 技术基座:spaCy NER模型加持
Inspectio的NLP敏感实体检测模块,核心依赖于工业级NLP框架spaCy及其预训练深度学习模型en_core_web_trf。命名实体识别(NER)作为NLP的基础任务,旨在从文本中提取具有特定意义的实体,如人名、地名、组织机构等,这也是该模块能够解析日志自然语言文本的核心能力来源。
与spaCy的轻量模型相比,en_core_web_trf模型虽占用资源较高(约1GB),但在实体识别的准确率和语义理解能力上更具优势,能够更好地适配日志文本中复杂的语义场景,精准提取指定类别的敏感实体。
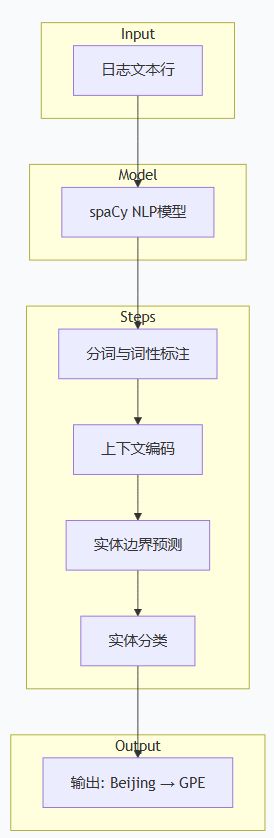
1.2 完整工作流程
该模块的工作流程清晰易懂,从日志输入到结果输出,共分为5个关键步骤,形成闭环处理:
-
日志输入:读取待审计的非结构化日志文本(如系统日志、应用日志),支持批量处理多种格式的日志文件;
-
模型加载:初始化spaCy框架,加载en_core_web_trf预训练模型,完成模型预热;
-
实体识别:通过spaCy的NER能力,对日志文本进行词法分析、句法分析,自动识别并提取文本中的实体及对应类型;
-
结果融合:将NLP检测到的敏感实体,与传统正则检测的结果进行合并、去重处理,避免重复告警;
-
结果输出:生成结构化检测报告,标注敏感实体的位置、类型及对应日志内容,方便审计人员核查。
1.3 与传统正则检测的核心区别
NLP检测与传统正则检测并非替代关系,而是互补关系------正则负责"刚性匹配",NLP负责"柔性识别",两者结合才能实现日志审计的全覆盖。具体区别如下表所示:
| 对比维度 | 传统正则检测 | NLP检测 |
|---|---|---|
| 判断依据 | 精确字符串模式匹配 | 词语语义角色与上下文 |
| 处理示例 | 正则匹配身份证号、手机号 | 识别文本中的人名、地名、组织机构 |
| 核心优势 | 快速、精确匹配固定格式内容,资源消耗低 | 识别非结构化、格式多变的语义实体 |
| 核心劣势 | 无法识别非预设模式的敏感内容 | 资源消耗较高(模型约1GB),存在少量误报 |
二、预定义敏感实体类型:聚焦日志审计核心需求
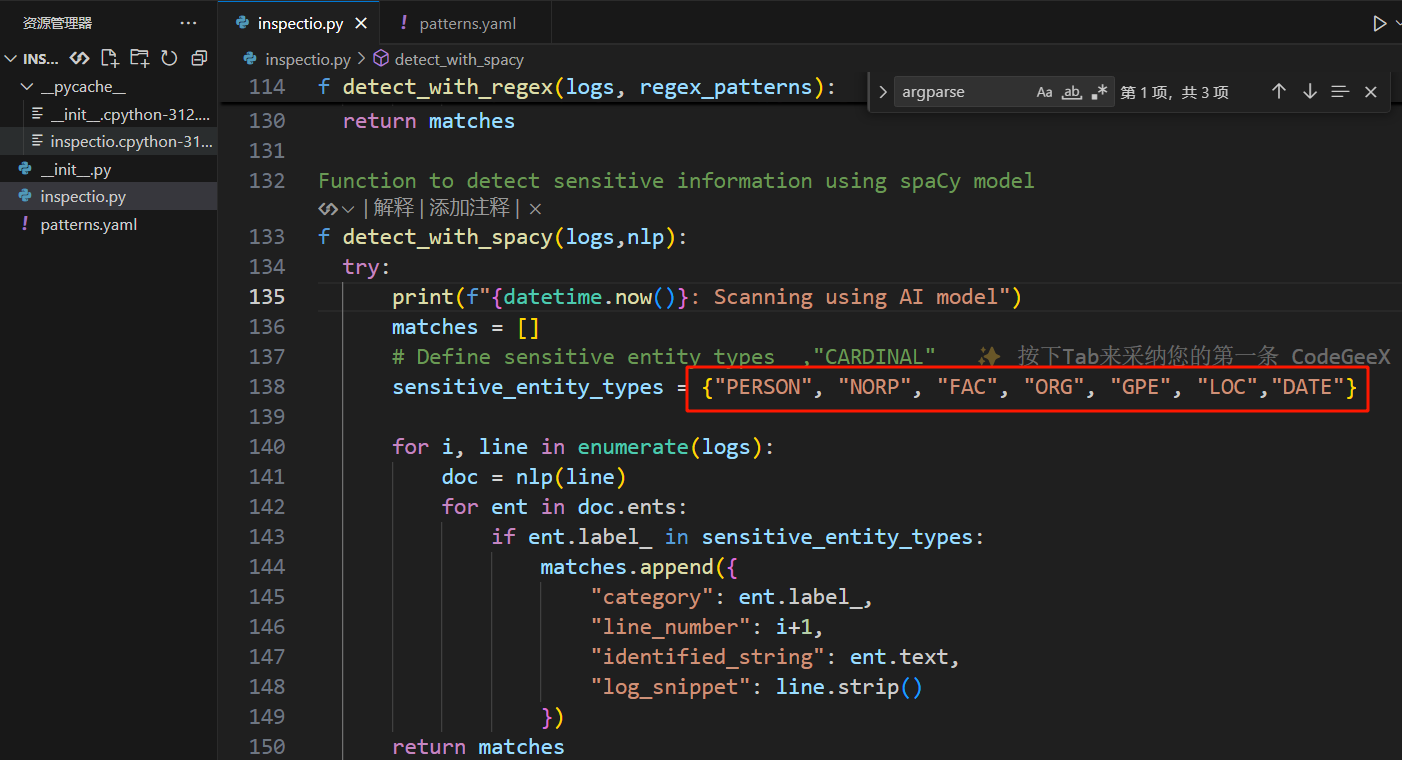
spaCy框架本身支持18种实体类型,但其中部分类型(如MONEY、PERCENT、TIME等)与日志审计场景无关,若全部保留会产生大量无关告警,增加审计成本。因此,Inspectio通过sensitive_entity_types集合,从spaCy全量实体类型中筛选出8类高频敏感实体,精准聚焦日志审计的核心需求。
2.1 实体类型定义代码
以下代码可直接查看或修改Inspectio的预定义敏感实体类型,适配不同场景的审计需求:
sensitive_entity_types = {"PERSON", "NORP", "FAC", "ORG", "GPE", "LOC", "DATE", "CARDINAL"}
2.2 实体类型详细说明
8类预定义敏感实体的具体含义、说明及示例如下,方便大家快速理解各类实体的覆盖范围:
| 实体类型 | 英文说明 | 中文含义 | 示例 |
|---|---|---|---|
| PERSON | Person | 人名(真实/虚构) | John Smith、张三 |
| NORP | Nationalities/Religious/Political groups | 国籍、宗教、政治团体 | Chinese、Buddhists、民主党 |
| FAC | Facilities | 人造设施(建筑、机场、公路等) | JFK Airport、故宫、京哈高速 |
| ORG | Organizations | 组织机构(公司、政府、高校等) | Google、中国政府、北京大学 |
| GPE | Geopolitical Entity | 地理政治实体(国家、城市、省份) | Beijing、中国、广东省 |
| LOC | Location | 自然地理区域(山脉、河流、海洋) | Rocky Mountains、长江、太平洋 |
| DATE | Date | 绝对/相对日期、日期范围 | 2025-12-01、last Monday、近3天 |
| CARDINAL | Cardinal | 通用基数词 | 8080(端口号)、3(数量)、100(金额) |
2.3 注意事项
Inspectio刻意未使用spaCy全部18种实体类型,核心目的是过滤无关告警------例如MONEY(金额)、PERCENT(百分比)、TIME(时间)等类型,在多数日志审计场景中不属于敏感信息,保留后会增加审计人员的核查负担,因此默认剔除。
三、误报处理机制:精准规避干扰,提升审计效率
由于NLP模型依赖语义理解,受日志文本的复杂性、歧义性影响,难免会出现误报。常见的误报分为两类:一是非敏感内容被错误识别(如普通数字、私有IP误判为CARDINAL);二是实体类型分类错误(如Apple误标为GPE而非ORG)。
针对以上误报,Inspectio提供了4种适配不同场景的处理方案,从简单到复杂,兼顾效率与灵活性,大家可根据自身需求选择。
3.1 方法一:忽略模式文件(-i 参数,推荐)
这是最便捷、零代码的误报处理方式,通过内置忽略规则文件,在输出检测结果前过滤误报条目,快速生效,适合处理常见的、批量出现的误报。
3.1.1 操作步骤
创建忽略规则文件ignore_patterns.txt,写入需要过滤的误报模式(支持正则表达式),示例如下:
# 过滤私有IP段(误报为CARDINAL)
192\.168\.\d{1,3}\.\d{1,3}
# 过滤长数字ID(误报为CARDINAL)
id[=:]\s*\d{5,}
# 过滤时间戳数字(误报为CARDINAL)
\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}
# 过滤测试数据(避免测试内容误报)
test|demo|example|sample
# 过滤本地地址(误报为GPE)
localhost|127\.0\.0\.1执行扫描命令,通过-i参数指定忽略规则文件,生成过滤后的审计报告:
inspectio -l /var/log/auth.log -i ignore_patterns.txt -f html -o report.html
3.1.2 工作原理
Inspectio内置ignore_patterns_from_file()函数,该函数会遍历所有NLP检测结果,将匹配到忽略规则文件中模式的条目直接移除,不输出至最终报告,从而实现误报过滤。
3.2 方法二:spaCy EntityRuler 源头纠正
若存在固定词汇反复误标的场景(如Apple始终被误标为GPE、localhost被误标为ORG),可通过spaCy的EntityRuler组件修改模型识别规则,从源头纠正实体分类,一劳永逸解决同类误报。
3.2.1 实现代码
import spacy
from spacy.pipeline import EntityRuler
# 加载spaCy预训练模型
nlp = spacy.load("en_core_web_trf")
# 添加EntityRuler组件至pipeline(需放在NER之前,确保规则优先生效)
ruler = nlp.add_pipe("entityRuler", before="ner")
# 定义实体纠正规则(label为正确的实体类型,pattern为误标词汇)
patterns = [
{"label": "ORG", "pattern": "Apple"}, # 纠正Apple为ORG(组织机构)
{"label": "ORG", "pattern": "GitHub"}, # 纠正GitHub为ORG
{"label": "GPE", "pattern": [{"LOWER": "localhost"}], "overwrite": True} # 强制纠正localhost为GPE
]
# 加载纠正规则
ruler.add_patterns(patterns)
# 测试纠正效果
doc = nlp("User connected to Apple from localhost")
for ent in doc.ents:
print(ent.text, ent.label_) # 输出:Apple ORG、localhost GPE3.2.2 集成方式
将上述代码逻辑,添加到Inspectio工具的detect_with_spacy()函数中(在spacy.load()加载模型后添加),重新运行工具即可生效。
3.3 方法三:模型微调(不推荐)
若日志文本与spaCy通用语料差异极大(如行业专属日志、自定义格式日志),导致误报率超过30%,可考虑使用自有标注数据微调spaCy NER模型,从底层优化识别效果。
需注意该方法的适用条件与风险:
-
适用条件:日志与通用语料差异极大,常规误报处理方法无法解决;
-
成本要求:需要准备数百条标注好的日志数据,且需具备一定的计算资源和模型训练经验,耗时较长;
-
核心风险:容易出现模型"灾难性遗忘",即微调后模型虽能适配自定义日志,但丢失了原有的通用实体识别能力。
3.4 方法四:修改Inspectio,忽略特定实体
若某类实体在当前审计场景中均不属于敏感内容(如DATE日期类型),可直接修改Inspectio的敏感实体类型集合,移除该类实体,从源头避免误报:
1.找到Inspectio工具中定义sensitive_entity_types的代码文件;
2.删除集合中不需要的实体类型(如删除"DATE"),修改后如下:
sensitive_entity_types = {"PERSON", "NORP", "FAC", "ORG", "GPE", "LOC", "CARDINAL"}
3.保存修改后重启工具,该类实体将不再被检测和上报。
四、方案对比与实践建议
为帮助大家快速选择合适的误报处理方案,结合实施成本、处理效果、适用场景,对4种方案进行对比,同时给出实践建议:
4.1 误报处理方案对比
| 误报处理方案 | 实施成本 | 处理方式 | 适用场景 |
|---|---|---|---|
| -i 忽略文件 | ⭐ 极低(零代码) | 输出结果过滤 | 常见误报、批量误报,快速排查 |
| EntityRuler 源头纠正 | ⭐⭐ 中等(少量代码) | 模型识别源头修正 | 固定词汇反复误标,同类误报频繁 |
| 模型微调 | ⭐⭐⭐⭐ 高(数据+资源+经验) | 模型本身优化 | 日志与通用语料差异极大,误报率>30% |
| 修改敏感实体类型 | ⭐ 极低(少量代码修改) | 源头关闭某类实体检测 | 某类实体在当前场景中均非敏感 |
4.2 实践建议
-
优先使用"-i 忽略文件"方案,快速处理常见误报,降低审计成本;
-
若存在固定词汇反复误标,补充使用"EntityRuler 源头纠正",一劳永逸解决同类问题;
-
谨慎选择"模型微调",仅在常规方案无法解决、误报率极高时使用,且微调前需备份原始模型,避免模型遗忘;
-
日常审计中,可结合"修改敏感实体类型",根据场景需求灵活调整敏感实体范围,减少无关告警。
五、附录:常用命令与术语解释
5.1 常用命令速查
最常用的日志审计命令(带误报过滤,生成HTML报告):
inspectio -l 日志路径 -i 忽略文件路径 -f html -o 报告输出路径
示例:扫描/var/log/auth.log日志,使用ignore_patterns.txt过滤误报,生成HTML报告并保存至当前目录:
inspectio -l /var/log/auth.log -i ignore_patterns.txt -f html -o report.html
5.2 术语解释
-
NER:命名实体识别(Named Entity Recognition),NLP的基础任务,旨在从文本中提取具有特定意义的实体(如人名、地名、组织机构);
-
spaCy:工业级自然语言处理框架,支持命名实体识别、词性标注、句法分析等多任务,提供预训练模型,可灵活定制;
-
EntityRuler:spaCy的规则化实体匹配组件,可自定义实体匹配规则,优先级高于默认NER模型,用于纠正实体识别错误。
总结
Inspectio工具的NLP敏感实体检测模块,通过spaCy的NER能力,完美解决了传统正则检测无法识别非结构化语义实体的痛点,与正则检测形成互补,大幅提升了日志审计的全面性与准确性。
在实际使用中,大家可根据自身日志场景,灵活选择误报处理方案------优先使用简单高效的忽略文件方案,针对特殊场景补充使用EntityRuler或模型微调,同时结合敏感实体类型的自定义调整,最大化提升日志审计效率。