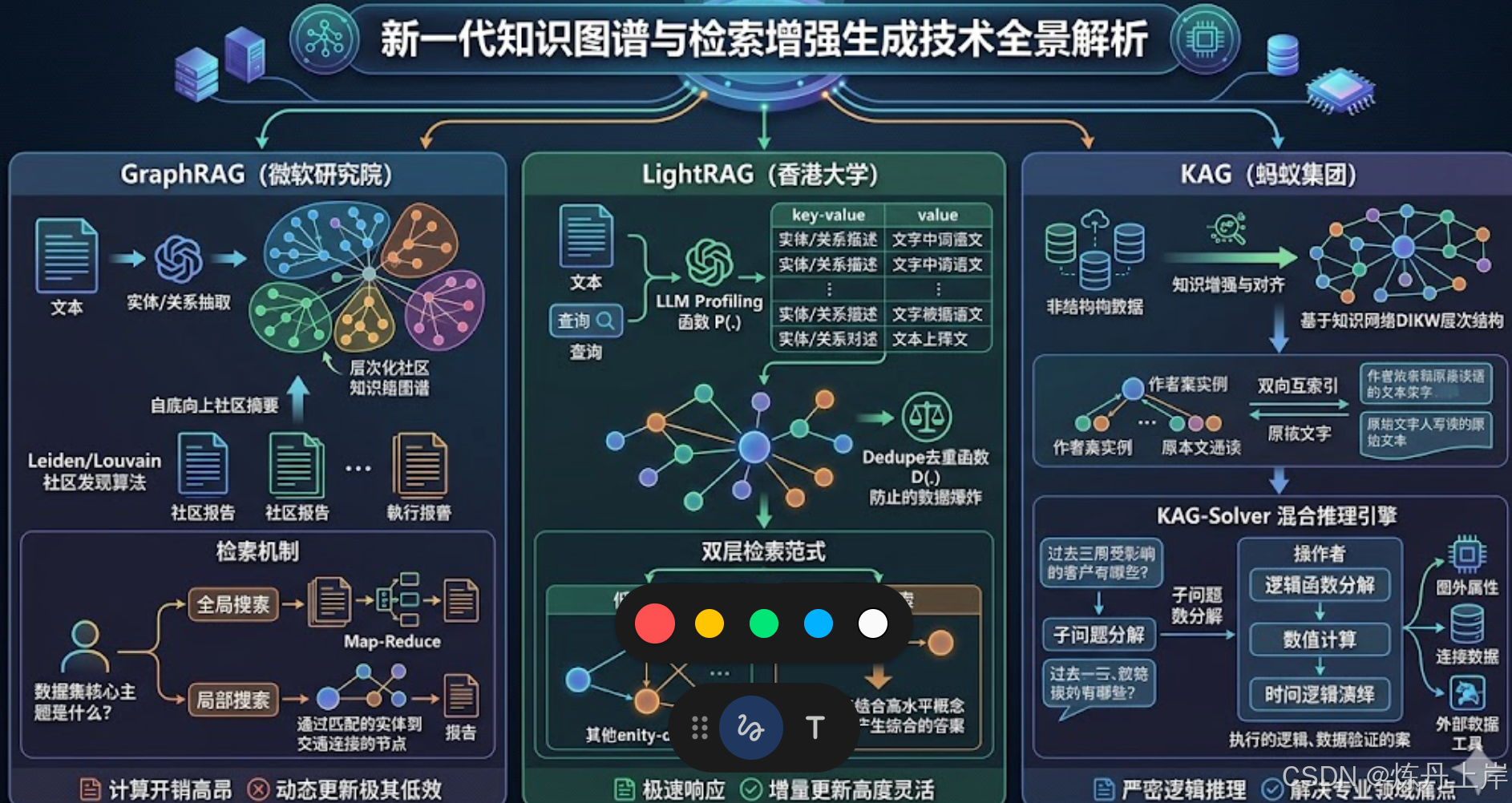
GraphRAG、LightRAG、KAG 原理及本体与 OAG 深度应用
大型语言模型(LLM)在自然语言处理领域取得了突破性进展,但其在处理垂直领域知识、多跳逻辑推理以及防范信息幻觉方面仍存在固有局限。
传统的 RAG(检索增强生成)技术通过将文档切分为离散文本块并利用向量相似度检索,部分缓解了这一问题。然而,面对需要全局上下文理解、复杂实体关系推理或深层抽象聚合的场景时,基于纯文本切块的范式暴露出严重的语义断层。
为突破这一瓶颈,学术界与工业界演化出了 GraphRAG 、LightRAG 、KAG 等新一代架构。同时,**本体(Ontology)**作为核心规范,以及 OAG(开放学术图谱与本体增强生成)的应用,正在重塑智能信息检索与企业级决策系统的边界。
一、 GraphRAG:基于层次化社区发现的全局与局部检索架构
GraphRAG 是由微软研究院提出的端到端系统,核心动机在于解决传统检索系统无法应对的全局性宏观问题(如"该数据集的核心主题是什么?")。
1. 图索引构建与层次化社区发现
- 实体与关系抽取: 利用 LLM 对源文本块进行抽取,提取实体名词短语及其共现关系,并生成精炼的描述摘要。
- 层次化组织: 引入 Leiden 或 Louvain 社区发现算法,通过优化图的模块度,识别内部连接紧密的实体簇。
- 自底向上摘要: 系统指示 LLM 为每个识别出的社区生成自然语言摘要报告。这些报告包含了关键实体、核心关系网络及事实主张,成为全局搜索的核心数据源。
2. 检索机制
- 全局搜索 (Global Search): 针对抽象问题,直接提取特定层级下的所有社区报告,通过类似 Map-Reduce 的机制汇总最终答案。
- 局部搜索 (Local Search): 针对细节查询,以实体为切入点,通过图遍历提取相连实体、关系边及所属社区报告。
- 漂移搜索 (Drift Search): 结合两者优势,利用社区报告启动全局搜索,再利用局部搜索挖掘细节,构建问答推理树。
3. 计算成本与局限性
- 高昂成本: 索引阶段需要海量计算资源生成社区报告;查询阶段可能消耗数十万 Token 并伴随数百次 API 调用。
- 动态更新困难: 依赖全局聚类算法,新数据的加入往往需要重新构建整个图结构,难以适应高频变动的生产环境。
二、 LightRAG:低成本、高效率的双层检索知识图谱网络
香港大学研究团队提出的 LightRAG 旨在保留图谱推理能力的同时,解决计算开销问题。
1. Profiling 机制与图结构去重
- 轻量级索引: LLM 充当 Profiling 函数 P(⋅)P(\cdot)P(⋅),为实体和关系生成简短的结构化文本描述(键值对结构)。
- 严格去重: 引入去重函数 D(⋅)D(\cdot)D(⋅) 合并跨片段的相同元素,形式化为 D^=Dedupe∘Prof(V,E)\hat{D} = Dedupe \circ Prof(V, E)D^=Dedupe∘Prof(V,E),有效缩小图体积。
2. 双层检索范式
- 低级检索: 专注于特定实体及其直接关系,针对事实性查询。
- 高级检索: 针对抽象主题,通过向量相似度直接在全局层面聚合多个相关实体和关系的特征。
3. 增量更新与效率
- 增量更新: 新数据生成局部子图后直接执行并集操作(Union),无需重构全局。
- 极低延迟: 查询 Token 消耗极低,响应延迟约 80 毫秒(优于扁平 RAG 的 120 毫秒),适合高频动态更新场景。
三、 KAG:基于 OpenSPG 的知识增强与逻辑推理框架
蚂蚁集团提出的 KAG 旨在弥合向量相似度与严密逻辑推理之间的鸿沟,适用于医疗、金融等专业领域。
1. DIKW 知识表示与双向互索引
- 知识对齐: 基于数据、信息、知识、智慧(DIKW)层次建模,利用同义词、上位词等概念关系将碎片化知识对齐。
- 双向互索引: 在知识图谱节点与原始文档块之间建立映射,确保在定位到节点后能随时追溯完整的原始段落语境。
2. KAG-Solver:混合推理引擎
- 逻辑形式引导: 将自然语言问题拆解为独立可解的子问题,形式化为逻辑函数。
- 算子调度: 内置规划、推理、检索三大类算子,支持跨实体属性的数值运算和基于时间轴的逻辑演绎。
- 实证表现: 在 2Wiki 上的 F1 分数提升 19.6%,在 HotpotQA 上提升 33.5%。
四、 不同架构的性能维度与选型对比
| 架构特性 | 传统向量 RAG | GraphRAG (Microsoft) | LightRAG (HKUDS) | KAG (Ant Group) |
|---|---|---|---|---|
| 核心数据表示 | 扁平化、无关联文本块 | 分层社区聚类摘要 | 细粒度向量+轻量网络 | DIKW 图谱与语料双向映射 |
| 主导检索机制 | 余弦相似度匹配 | 全局 Map-Reduce | 双层(细节+概念)聚合 | 规划算子驱动的混合检索 |
| 逻辑计算深度 | 极弱 | 强(擅长隐性网络挖掘) | 优(依赖快速跨跳映射) | 极强(支持数学及规则约束) |
| 计算消耗/延迟 | 低成本 / ~120ms | 极大(数十万 Token) | 极省 / ~80ms | 较高(逻辑拆解开销) |
| 动态更新 | 最为简便 | 极其低效(需全局重建) | 高度灵活(增量并集) | 中等(依赖专家 Schema) |
| 最佳实践 | 客服机器人、长文档阅读 | 文学分析、宏观情报挖掘 | 资源受限、高频更新场景 | 金融风控、医疗诊断、政务 |
五、 本体(Ontology)深度解析:知识图谱的结构基石
本体是决定系统是否具备深层推理能力的结构规范。
1. 形式化本体的核心要素
- 类与分类树 (Classes): 核心概念集合(如"教授"是"学术人员"的子类)。
- 属性与关系网络 (Properties): 规范实例间的联系(对象属性)及数值特征(数据属性)。
- 实例对象 (Individuals): 概念的具体化体现(如"清华大学"是"大学"的实例)。
- 公理与逻辑约束 (Axioms): 赋予推理能力(如传递性、域范围限制),强制剥离 LLM 幻觉。
2. 语义网技术栈
- OWL (Web Ontology Language): 具备强描述逻辑表达能力,支持类构造器(交、并、补)。
- 推演引擎: 如 HermiT 或 Pellet,可在运行时执行一致性审查,排查逻辑谬误。
3. 工程化工具
- Protégé: 斯坦福研发的开源编辑器,用于构建层级结构和验证逻辑。
- Owlready2 / RDFlib: Python 后端集成库,支持本体加载、推理及与 Neo4j 数据库的持久化。
六、 OAG 的多维透视:数据底座与系统架构
1. 维度一:数据底座 ------ 开放学术图谱 (Open Academic Graph)
- 定义: 微软研究院与清华大学合作发布,整合了微软学术图谱与 AMiner。
- 价值: 攻克了数十亿级实体消歧难关,涵盖作者、机构、引用网络等多元信息,是图检索算法的极佳试炼场。
2. 维度二:高级系统架构 ------ 本体增强生成 (Ontology-Augmented Generation)
- 定义: 在 Palantir AIP 等平台中,OAG 将 AI 从"文献助手"提升为"决策代理"。
- 能力:
- 感知事实: 封装静态对象。
- 执行决策: 集成逻辑工具(如销量预测、路径优化)。
- 可审计性: 所有推理步骤受本体约束,实现闭环决策(如供应链中断后的自动调配指令)。
总结:构建智能科研代理系统的工程实践
若要融合上述技术,建议路径如下:
- 自顶向下设计: 利用 Protégé 建立学术科研本体(定义实验假设、验证方法等类)。
- 数据驱动索引: 利用 Owlready2 对接 Open Academic Graph 数据集,驱动 LLM 抽取实例。
- 混合检索实现: 融合 LightRAG 的轻量化 Profiling 控制成本,并叠加 KAG 的算子引擎解析复杂逻辑。
- 闭环决策: 通过 OAG 架构打通外部系统,实现从静态查阅到主动科研决策(如自动发送预警、调度算法)的进化。