《智能的理论》全书转至目录****
不同AGI的研究路线对比简化版:《AGI(具身智能)路线对比》,欢迎各位参与讨论、批评或建议。
一.奖励类型
奖励通常分为两种,初级奖励和次级奖励。初级奖励不需要学习(22-5:动机到行动,强化学习),它们服务于人和动物生存和繁殖的基本需求,例如食物、水和性;次级奖励(条件刺激)是需要我们在后天通过学习掌握和认识其价值的(例如金钱和他人的认可)。
二.阈上奖励和阈上奖励
奖励作为一种满意刺激物,能够诱发出个体的积极情绪或者更高水平的动机强度,使得个体在执行任务的过程中更倾向于投入额外的努力,进而提高了个体的任务绩效。
通常情况下,在决定是否追求奖励时,个体常常需要权衡三个方面的信息:奖励价值、获取奖励的可能性、以及能够获取奖励的条件(个体需要付出的努力)(Eccles和Wigfeld,2002)。研究者认为个体对以上信息的综合分析需要意识的参与,因为这个过程需要综合价值和信息综合等高级的认知功能。这些能被意识到的奖励也即阈上呈现。然而,也有研究发现,这一过程也可以在没有意识参与的情况下完成,即阈下呈现的奖励(Custers和Aarts,2010)
1.阈上奖励
(1)影响方式
阈上奖励主要能从以下几个方面对个体产生影响:(a)努力程度,当可能获取更高的奖励时,被试更可能选择困难任务(Theeuwes和Belopolsky,2012);(b)生理状态,当个体面对奖励信息时会出现肾上腺素分泌水平提高,瞳孔放大,心脏射血前期反应等一系列生理状态的变化(Richter,2010,Richter和Gendolla,2009);(c)注意,奖励会影响个体的注意偏向,个体对和高奖励线索相关联的刺激的搜索更快(Kiss,Driver和Eimer,2009);(d)认知过程,奖励影响认知控制,研究发现,金钱启动使个体对奖励产生期待,使个体将注意力集中在对任务相关信息的处理上,降低无关信息的干扰,从而降低干扰效应(Malessa,Gendolla,Steinberg和Schmitt等人,2010),促使认知稳定性的保持(Mueller,Dreisbach,Goschke和Hensch等人,2010)。
(2)有无奖励的影响
Padmala和Pessoa(2011)采用选择性注意任务,实验呈现建筑物或房屋的图像刺激,执行该任务时需要忽略图像刺激上方不一致的单词(例如图像刺激为建筑物,但上方出现房屋的单词)。在每次实验试次之前呈现有无奖励的线索,在有奖励条件下,告诉被试若在该试次快速且正确的反应即可获得相应的任务奖励。研究结果表明,与无奖励试次相比,个体在执行奖励试次上的错误率与反应时都显著减小,同样也观察到减小的干扰效应,表明奖励的引入使得个体选择性地减弱无关干扰物对注意力和反应的影响。
(3)高低奖励的影响
当奖励值大小有差异时,个体会根据期望的奖励值大小来调整自身的努力程度,奖励值越大则动机越强(Pessiglione,Schmidt,Draganski和Kalisch等人,2007)。研究者通过实时的生理学指标------瞳孔扩张大小,来研究个体对奖励刺激的反应。瞳孔大小变化可以表明个体完成一项任务所需要认知的资源量,瞳孔越大反映了个体在这项任务中的资源投入量更多。该实验结果表明,高奖励条件下的个体比低奖励条件下的平均瞳孔扩张更大(Bijleveld,Custers和Aarts,2009)。
但并不是所有的高奖励都会促进个体的行为表现,也可能起抑制作用,需视具体情境而定。研究者关于奖励对个体行为的抑制作用主要有两种理论解释,(a)分心理论,个体在对任务进行加工的时候也会对奖励信息进行加工,个体需要将一部分资源分给奖励信息加工,而注意资源是有限的,因此个体原本用于加工目标任务的资源就减少了,从而影响了任务绩效;(b)外显监控理论,在高奖励条件下,个体会背负外在压力,当压力达到一定水平时反而会损害个体的行为(Nideffer,1992;Carver和Scheier,1987)。
2.阈下奖励(郑艳,2016)
(1)实证
在Pessiglione等人(Pessiglione,Schmidt,Draganski和Kalisch等人,2007)的研究中,研究者提出一种新的实验范式------奖励启动范式。该范式采用高奖励和低奖励的两种金钱图片奖励线索,同时控制金钱图片的呈现时间,当呈现时间为17ms时奖励属于阈下方式呈现,当呈现时间为300ms时奖励属于阈上方式呈现。实验的流程是,首先阈上或阈下的硬币图片,然后要求被试按压握力器,按压的力量越大,被试能得到的奖励就越多。结果表明,奖励阈下呈现时,相对于低奖励线索,在高奖励线索条件下被试更倾向于用更大的力按压握力器。
(2)行为表现
在动物低级的脑结构中,它们能完成对奖励价值、获取奖励的可能性和获取奖励所需投入等这些信息的整合(Phillips,Walton和Jhou,2007)。根据这个结论,Biileveld等假设人类也可以在阈下水平将奖励刺激的三方面信息进行整合(Bijleveld,Custers和Aarts,2009)。Bijleveld等人在研究中采用了金钱启动范式,任务要求被试记忆数字,分为高难度(要求被试记忆5个数字)任务和低难度(要求被试记忆3个数字)任务,在任务过程中记录被试的瞳孔大小。结果表明,无论奖励是阈上还是阈下呈现,只有在高难度的任务中,被试在高奖励情况下才会投入更多的精力以期获得奖励,表现为瞳孔直径更大。这一结果说明阈下奖励不仅能像阈上奖励一样提高被试的努力程度,即使在阈下奖励条件下也能综合任务要求和奖励价值来提高努力程度以获得奖励。
在另一些需要被试在不同的策略中选择最优解的任务中,阈下奖励则并不能像阈上奖励一样促进个体的任务表现。Bileveld等人(Biileveld,Custer和Aarts,2010)的一项研究中,要求被试解决算术题,且要求他们同时考虑速度与准确性。在正确反应的前提下,反应时间越短奖励越多,回答错误则没有奖励。结果表明,当金钱奖励下呈现时,被试不会因为奖励的高低而改变任务策略(无论奖励高或低,被试均又快又准地完成任务),而当金钱奖励阈上呈现时,被试则会根据奖励的高低来调整任务策略,即高奖励下,被试倾向于选择降低速度以提高准确性的策略。因此,只有奖励刺激处于被试加工的阈上水平时,个体才能做出策略选择,阈下奖励不能对个体的策略选择产生影响。
(3)神经机制
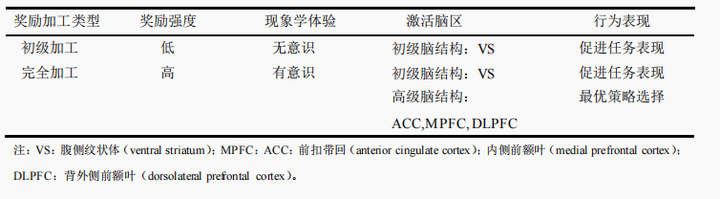
Bijleved等人(Biileveld,Custers和Aarts,2012)提出一个理论框架用以解释人对奖励信息的加工,他们认为个体对奖励信息的加工可以分为两个阶段,奖励的初级加工阶段和奖励的完全加工阶段。奖励首先在原始的纹状体中得到加工,纹状体在特定情况下对每个可能的行动进行精确评估,并根据评估的潜在价值选择最佳行动方案,同时促使个体通过多付出努力来获取奖励。另外,纹状体的腹侧和背侧部分具有不同的作用(Roesch和Olson,2003),背侧纹状体可能在奖励的评价和与这些奖励相关的行为之间传递信息,有助于控制奖励导向行为,而腹侧纹状体的激活与奖励的预测有关(Berns,McClure,Pagnoni和Montague,2001)。由于纹状体加工是不需要意识参与的,因此这里的初级加工是对奖励的阈下的无意识加工;之后,大脑再继续对奖励信息进行完全加工。在此阶段,负责高级认知功能的脑区就参与进来,使个体意识到奖励信息。
有研究发现,向可卡因上瘾者阈下呈现可卡因相关的图片时,纹状体就能被激活(Childress,Ehrman,Wang和Li等人,2008)。这表明,尽管处于较低水平,但纹状体仍能被极微弱的奖励输入激活,对个体的行为产生影响。
(4)小结
基于此,可将上述研究总结为下表1(Biileveld,Custers和Aarts,2012)。
表1
三.调节途径(胡晓雯,2020)
奖励主要通过任务前的奖励线索,任务中的刺激-奖励联结,任务反应后的奖励反馈三种途径对认知功能及行为表现进行调节。
1.任务前的奖励线索
通过提前呈现奖励线索,提示被试在该任务试次上是否存在奖励或者奖励的大小,可影响被试在任务中的表现。Engelmann和Pessoa(2007)采用奖励影响下的注意力研究范式,通过在实验开始前给予个体奖赏线索的提示,发现个体检索目标的能力随着任务奖励价值的提高而增强,这说明奖赏线索能够提高个体的注意力,诱发个体的任务准备状态。
2.任务中的刺激-奖励联结
通过将奖励与任务刺激直接联结,当特定的任务刺激出现时,被试在正确反应之后将会得到相应的奖励,从而影响刺激编码和反应选择。Krebs等人(Krebs,Boehler和Woldorff,2010)采用色-词stroop任务,在实验开始前提示被试对红色或蓝色的字进行即快又准的反应将会获得相应的额外奖励,而对黄色或绿色的字进行即快又准的反应没有额外的奖励。实验结果发现,在奖赏条件下个体对红色或蓝色的字进行按键反应时,其按键速度更快,反应时更短,更少冲突效应。这是因为奖励相关的刺激能够在任务执行加工过程中获得更多的注意资源,优先编码加工,进而促进个体的行为反应。
3.任务反应后的奖励反馈
实验会在被试完成每个试次之后给予被试奖赏信息的反馈。在这种操纵下,个体会根据奖赏预期误差动态调整行为。个体在执行某一反应之后,若得到了意外的奖励,则会产生正性的预期误差(即实际获得的奖励大于预期获得的奖励),同时强化刺激与反应之间的联结;相反,若是被试在执行反应之后未得到预期的奖励,那么个体会产生负性的预期误差(即实际获得的奖励小于预期获得的奖励),那么刺激与反应之间的联结会逐渐消退。Hickey,Kaiser 和Peelen(2010)采用了奖赏反馈的方法进行研究。在视觉搜索任务中,目标刺激为特定颜色的特定形状,分心物为同一颜色不同形状的刺激以及不同颜色不同形状的刺激。被试需要辨别目标形状内的直线方向,在执行反应之后,会给予相应的奖励反馈。结果发现,与低奖励反馈后相比,在高奖励反馈后当前任务试次的目标颜色较上一试次重复出现时,个体的反应时更快。而当前任务试次的目标颜色较上一试次互换时,观察到相反的模式。这说明,在高奖励反馈后个体的注意力更容易分配到先前的目标颜色,奖励反馈使刺激更能捕获注意资源,进而促进刺激加工。
四.机制
1.双重控制理论
双重控制理论(16-5:判断与决策)的一个中心假设是,情境因素的变化将导致主动性控制和被动控制之间的权重发生变化。作为典型的刺激线索,奖励可以改善个体自上而下的准备状态,调整后续目标的注意力,使个体偏向于主动性控制,进而提升随后的行为表现。有实验比较了有无奖励对被试记忆能力的影响,在被试表现优于基线条件时会提供25美分作为奖励,结果显示金钱奖励下被试偏向主动性控制,增强了被试的表现(Locke & Braver,2008)。
2.注意系统与奖励系统
研究者认为完成目标导向的认知行为任务,需要注意系统与奖励系统的相互作用。奖励相关信息通过影响个体的注意定向系统(该系统将个体的注意力指向行为相关的刺激位置)与再定向系统(该系统将注意力分散,使得个体注意力重新定向到与行为相关的刺激),有效地引导个体的视觉注意,使得个体优先注意到奖励相关的任务刺激,进而加工该任务信息(Bucker和Theeuwes ,2014)。而奖励系统负责定义行为目标,编码奖励信息,并引导注意系统确定相关行为目标,推动目标任务的执行(Botvinick和Braver,2015)。
3.至上而下加工和至下而上加工
奖励对注意选择的加工机制存在多种观点,第一种观点认为奖励对注意选择的影响是通过自上而下的注意机制起作用,动机突显性理论(Berridge和Robinson,1998)认为和奖励相关的多巴胺系统增强了与奖励联结刺激的知觉表征突显性,使个体有意识的增加了选择该刺激的概率,进而影响了注意选择过程。第二种观点认为奖励对注意选择的作用是通过自下而上的注意加工机制起作用,因为奖励和刺激的联结增加了刺激的突显性从而使该刺激自动地捕获了注意(Andersonetal.,2011b)。
4.心理成分
奖励可以影响个体的认知加工和行为,源于其三种心理成分,这三种成分分别对应了心理学的三种主要研究领域,认知、动机和情绪(Berridge和Robinson,2003):(a)奖励的学习性成分,即强化,指学习刺激和行为的结果之间的关系,而且不论这种联系是外显的还是内隐的;(b)动机性成分,指奖励诱发个体内隐的"想要"体验和目标导向的行为驱力;(c)情感性成分,指当人们获得奖励时产生的喜欢和积极感受。
五.控制期望价值理论(EVC模型)(司双庆,周思宏,袁加锦和杨倩,2024)
Shenhav等人(Shenhav,Botvinick和Cohen,2013)提出了控制的预期价值模型(EVC模型),用于解释基于价值的决策过程。该模型认为,个体在执行任务时,会根据奖励相关信息权衡成本(认知资源消耗伴随的消极代价)与收益(实现任务目标所带来的积极奖励),以此实现奖励对认知控制的调节作用。具体来说,个体通过预期价值最大化的计算来调节控制强度。预期价值指投入认知控制可能带来的预期奖励与代价间的差值(即奖励-代价)。如图1所示,随着控制强度的增加,预期奖励呈"S"型单调增加,而预期代价单调递增。综合预期奖励与代价(最大化预期奖励,最小代价)来控制的预期价值------二者的差值,最大差值对应最优的控制强度, 称为EVC值(如点a)。奖励与代价作为EVC模型两个关键因素,下面将详细介绍。
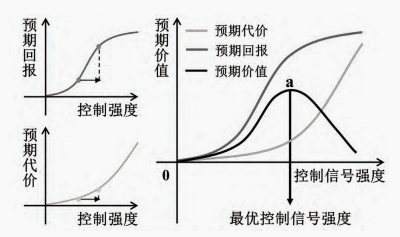
图1
1.奖励
任务奖励是调控认知控制的一个重要因素,包括外在奖励(食水、金钱等)与内在奖励(好奇心的满足、自主感、乐趣等)两种。
(1)外在奖励
在以人类为被试的研究中,外在奖励多指与当前任务表现相关或无关的金钱奖赏。通过直接操纵金钱奖赏,研究者们比较了不同奖赏条件下个体的任务表现差异,以此探究外在奖励对认知控制的影响。大量实证研究表明,与任务表现相关的金钱奖赏在多数情境下可以提升认知控制,表现为任务准确性提升和反应时缩短。在转换任务中,金钱奖赏降低了任务转换代价(Bahlmann,Aarts和D'Esposito,2015),体现了认知灵活性的增强;在反应抑制相关任务中,金钱奖赏降低了冲突任务中的不一致效应(Aarts,Wallace,Dang和Jagust等人,2014),也降低了go/nogo任务与停止信号任务中的犯错率(Boehler,Hopf,Stoppel和Krebs,2012;Dixon和Christot,2012),表明抑制控制能力的提升。
根据EVC模型,若认知代价固定不变,上述外在奖励提升时,奖励曲线也随之上升,从而影响预期价值(如图2),随着外在奖励的增加,奖励曲线上移(奖励:深灰色虚线→深灰色实线;预期价值:黑色虚线→黑色实线;EVC值:a→b),进而促进认知控制和行为表现。
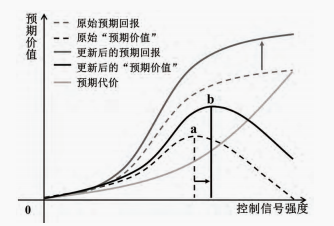
图2
(2)内在奖励
类似于外在奖励,内在奖励同样可以通过评估"预期价值"来影响认知控制的实施。Huskeyeta等人认为个体在追求内在奖励时会产生积极的主观情绪体验(Huskey,Craighead,Miller和Weber,2018),因此可以根据积极情绪等的差异来探究内在奖励对认知控制的影响(Otto,Braem,Silvetti和Vassena,2022)。相关研究发现,在冲突任务中,相比于一致试次,被试在成功解决任务难度更高的不一致试次(冲突)后,报告了更多的积极情绪(Schouppe,Braem,De Houwer和Silvetti等人,2015),表明被试在此条件下获得了更多的内在奖励。
2.代价
认知控制代价在不同任务情境中的表现形式不同,包括放弃其他认知任务所能获得的奖励的机会成本、与调整有关的调整代价、实施控制所投入的认知努力的努力代价等(司双庆,周思宏,袁加锦和杨倩,2024)。其中,努力代价可能是导致个体减少认知控制投入的根本原因(André,Audiffren和Baumeister,2019),主要表现为个体对高控制需求任务的回避及对预期价值主观评估的降低。
(1)努力代价导致认知回避
最少心理努力原则认为,在其他条件相等的情况下,个体倾向于选择那些能够最大程度减少认知努力付出的任务(Botvinick,2007)。例如,在面对高低冲突水平(80%不一致VS 20% 不一致)的Stroop任务时,被试会更多地选择低冲突水平条件任务(Schouppe,Demanet,Boehler和Ridderinkhof等人,2014);在转换任务中,被试倾向于选择"重复"而非"转换"任务(Arrington和Logan,2004);在高频或低频的转换任务间做选择时,他们也更偏好低频的任务转换(Kool,McGuire,Rosen和Botvinick,2010)。上述与努力回避有关的现象均反映了努力代价的存在。
(2)努力代价降低预期价值
努力投入通常伴随负性情绪(如厌恶)的产生(Kurzban,2016),皱眉肌作为负性情绪的敏感性指标,其活动可以间接表征努力投入所产生的代价(Dreisbach和Fischer,2012),反映个体对努力代价的主观价值的评估。在Westbrook等人(Westbrook,Kester和Braver,2013)的实验中,被试需在预期价值不断变化的"高奖赏-困难任务"和"低奖赏-简单任务"之间进行选择。结果发现,被试更多地选择了低奖赏-简单任务,因为高奖赏-困难任务的主观价值随所需努力投入的增加而降低。在此过程中,被试倾向于降低外在奖励并主观夸大了努力的代价,以此回避努力投入,产生了努力折扣(易伟,梅淑婷和郑亚,2019)。
3."奖励-代价"权衡的可能机制
奖励与代价对认知控制的影响并非独立,而是通过"奖励-代价"权衡的方式共同调节认知控制过程。例如,在算术任务中,表征努力代价的皱眉肌活动在预期要解决更复杂的算术问题时增强(皱眉肌作为负性情绪的敏感性指标,其活动可以间接表征努力投入所产生的代价(Dreisbach和Fischer,2012));而当解决这些问题可以获得更高的奖赏时,皱眉肌活动又显著降低(Devine,Vassena和Otto,2023)。
计算认知控制的奖励-代价权衡之所以受到主体因素的影响。一方面,在努力投入前,代价会削弱努力投入可能获得奖励的预期价值。从而削弱了努力投入,降低认知控制;另一方面,努力本身具有价值(如沉没成本的影响),而且在努力投入后,个体往往赋予努力奖励更多的价值。使个体更愿意投入到任务中(曹思琪,汤晨晨,伍海燕和刘勋,2022)。
努力本身具有价值,个体对努力的评价受到个体对努力投入的主观偏好的综合影响,即更看重努力产生的代价(负性评价)还是更看重努力带来的奖励(正性评价)。DPOWER模型构建了关于努力投入与努力结果的主观价值的函数关系。具体来说,当个体对努力投入呈正性评价时,主观价值随努力投入的增加而增加;当个体对努力投入呈负性评价时,主观价值随努力投入的增加而降低。由于个体对努力结果的偏好可能会因努力需求而改变,如若个体最初对努力呈负性评价,当努力值达到一定水平后,随着努力投入的持续增加,他们对努力的偏好逐渐由代价变为奖励,评价随之由负性转为正性,价值函数相应地由单减转为单增;反之,若个体最初对努力呈正性评价,当努力值达到阈限后,随着努力投入的持续增加,他们对努力的偏好逐渐由奖励变为代价,评价随之由正性转为负性,价值函数由单增转为单减(Marcowski,Winkielman和Białaszek,2023),如图3。
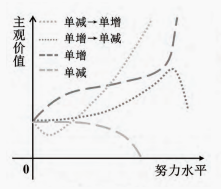
图3