class Solution {
public:
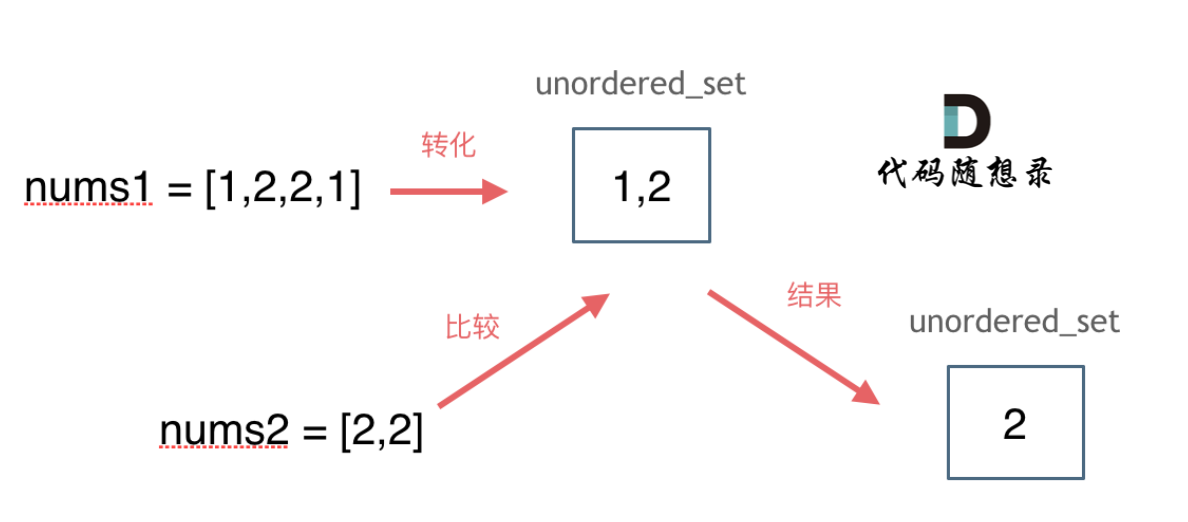
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
对应python代码如下:
python复制代码
# (版本一) 使用字典和集合
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
# 使用哈希表存储一个数组中的所有元素
table = {}
for num in nums1:
table[num] = table.get(num, 0) + 1
# 使用集合存储结果
res = set()
for num in nums2:
if num in table:
res.add(num)
del table[num]
return list(res)
# (版本二) 使用数组
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
count1 = [0]*1001
count2 = [0]*1001
result = []
for i in range(len(nums1)):
count1[nums1[i]]+=1
for j in range(len(nums2)):
count2[nums2[j]]+=1
for k in range(1001):
if count1[k]*count2[k]>0:
result.append(k)
return result
# (版本三) 使用集合
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
return list(set(nums1) & set(nums2))
class Solution {
public:
// 取数值各个位上的单数之和
int getSum(int n) {
int sum = 0;
while (n) {
sum += (n % 10) * (n % 10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
while(1) {
int sum = getSum(n);
if (sum == 1) {
return true;
}
// 如果这个sum曾经出现过,说明已经陷入了无限循环了,立刻return false
if (set.find(sum) != set.end()) {
return false;
} else {
set.insert(sum);
}
n = sum;
}
}
};
// 时间复杂度: O(logn)
// 空间复杂度: O(logn)
python代码:
python复制代码
# (版本一)使用集合
class Solution:
def isHappy(self, n: int) -> bool:
record = set()
while True:
n = self.get_sum(n)
if n == 1:
return True
# 如果中间结果重复出现,说明陷入死循环了,该数不是快乐数
if n in record:
return False
else:
record.add(n)
def get_sum(self,n: int) -> int:
new_num = 0
while n:
n, r = divmod(n, 10)
new_num += r ** 2
return new_num
# (版本二)使用集合
class Solution:
def isHappy(self, n: int) -> bool:
record = set()
while n not in record:
record.add(n)
new_num = 0
n_str = str(n)
for i in n_str:
new_num+=int(i)**2
if new_num==1: return True
else: n = new_num
return False
# (版本三)使用数组
class Solution:
def isHappy(self, n: int) -> bool:
record = []
while n not in record:
record.append(n)
new_num = 0
n_str = str(n)
for i in n_str:
new_num+=int(i)**2
if new_num==1: return True
else: n = new_num
return False
# (版本四)使用快慢指针
class Solution:
def isHappy(self, n: int) -> bool:
slow = n
fast = n
while self.get_sum(fast) != 1 and self.get_sum(self.get_sum(fast)):
slow = self.get_sum(slow)
fast = self.get_sum(self.get_sum(fast))
if slow == fast:
return False
return True
def get_sum(self,n: int) -> int:
new_num = 0
while n:
n, r = divmod(n, 10)
new_num += r ** 2
return new_num
# (版本五)使用集合+精简
class Solution:
def isHappy(self, n: int) -> bool:
seen = set()
while n != 1:
n = sum(int(i) ** 2 for i in str(n))
if n in seen:
return False
seen.add(n)
return True
# (版本六)使用数组+精简
class Solution:
def isHappy(self, n: int) -> bool:
seen = []
while n != 1:
n = sum(int(i) ** 2 for i in str(n))
if n in seen:
return False
seen.append(n)
return True
class Solution {
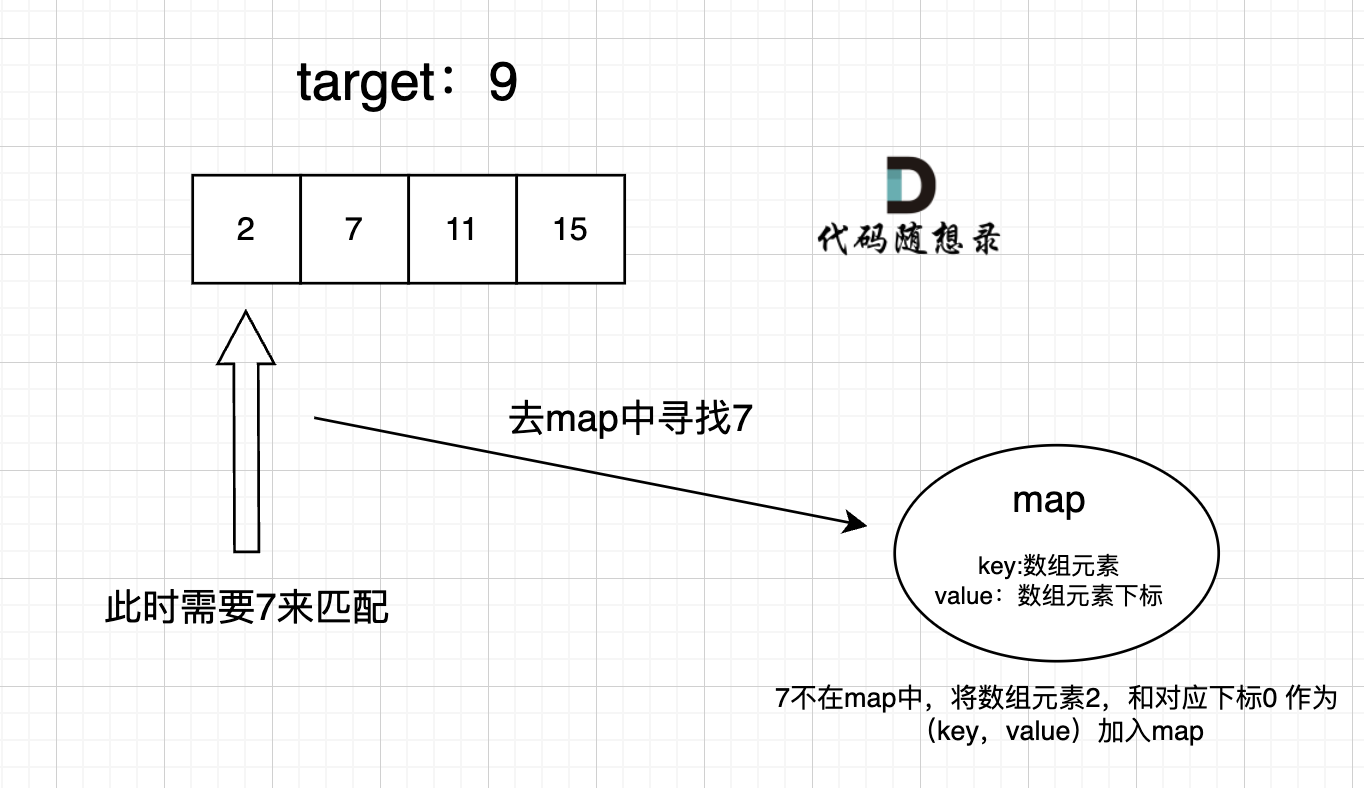
public:
int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {
unordered_map<int, int> umap; //key:a+b的数值,value:a+b数值出现的次数
// 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
for (int a : A) {
for (int b : B) {
umap[a + b]++;
}
}
int count = 0; // 统计a+b+c+d = 0 出现的次数
// 再遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
for (int c : C) {
for (int d : D) {
if (umap.find(0 - (c + d)) != umap.end()) {
count += umap[0 - (c + d)];
}
}
}
return count;
}
};
// 时间复杂度: O(n^2)
// 空间复杂度: O(n^2),最坏情况下A和B的值各不相同,相加产生的数字个数为 n^2
python代码:
python复制代码
#(版本一) 使用字典
class Solution(object):
def fourSumCount(self, nums1, nums2, nums3, nums4):
# 使用字典存储nums1和nums2中的元素及其和
hashmap = dict()
for n1 in nums1:
for n2 in nums2:
if n1 + n2 in hashmap:
hashmap[n1+n2] += 1
else:
hashmap[n1+n2] = 1
# 如果 -(n1+n2) 存在于nums3和nums4, 存入结果
count = 0
for n3 in nums3:
for n4 in nums4:
key = - n3 - n4
if key in hashmap:
count += hashmap[key]
return count
#(版本二) 使用字典
class Solution(object):
def fourSumCount(self, nums1, nums2, nums3, nums4):
# 使用字典存储nums1和nums2中的元素及其和
hashmap = dict()
for n1 in nums1:
for n2 in nums2:
hashmap[n1+n2] = hashmap.get(n1+n2, 0) + 1
# 如果 -(n1+n2) 存在于nums3和nums4, 存入结果
count = 0
for n3 in nums3:
for n4 in nums4:
key = - n3 - n4
if key in hashmap:
count += hashmap[key]
return count
#(版本三)使用 defaultdict
from collections import defaultdict
class Solution:
def fourSumCount(self, nums1: list, nums2: list, nums3: list, nums4: list) -> int:
rec, cnt = defaultdict(lambda : 0), 0
for i in nums1:
for j in nums2:
rec[i+j] += 1
for i in nums3:
for j in nums4:
cnt += rec.get(-(i+j), 0)
return cnt
# (版本一)使用数组
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
ransom_count = [0] * 26
magazine_count = [0] * 26
for c in ransomNote:
ransom_count[ord(c) - ord('a')] += 1
for c in magazine:
magazine_count[ord(c) - ord('a')] += 1
return all(ransom_count[i] <= magazine_count[i] for i in range(26))
#(版本二)使用defaultdict
from collections import defaultdict
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
hashmap = defaultdict(int)
for x in magazine:
hashmap[x] += 1
for x in ransomNote:
value = hashmap.get(x)
if not value:
return False
else:
hashmap[x] -= 1
return True
(版本三)使用字典
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
counts = {}
for c in magazine:
counts[c] = counts.get(c, 0) + 1
for c in ransomNote:
if c not in counts or counts[c] == 0:
return False
counts[c] -= 1
return True
(版本四)使用Counter
from collections import Counter
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
return not Counter(ransomNote) - Counter(magazine)
(版本五)使用count
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
return all(ransomNote.count(c) <= magazine.count(c) for c in set(ransomNote))
(版本六)使用count(简单易懂)
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
for char in ransomNote:
if char in magazine and ransomNote.count(char) <= magazine.count(char):
continue
else:
return False
return True
八、三数之和
例题:
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
注意: 答案中不可以包含重复的三元组。
示例:
给定数组 nums = -1, 0, 1, 2, -1, -4,
满足要求的三元组集合为: \[-1, 0, 1, -1, -1, 2 ]
1、思路
两层for循环就可以确定 两个数值,可以使用哈希法来确定 第三个数 0-(a+b) 或者 0 - (a + c) 是否在 数组里出现过,其实这个思路是正确的,但是我们有一个非常棘手的问题,就是题目中说的不可以包含重复的三元组。
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
// 找出a + b + c = 0
// a = nums[i], b = nums[left], c = nums[right]
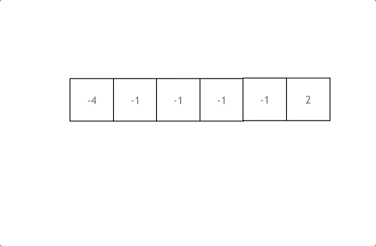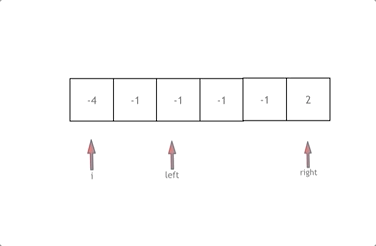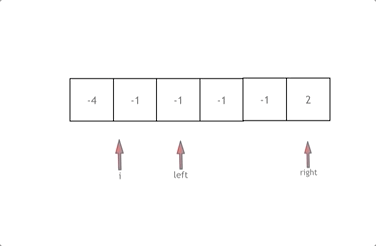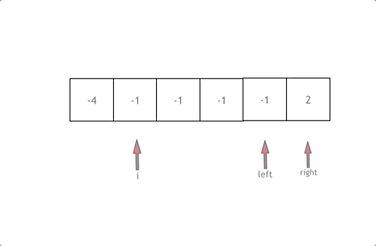
for (int i = 0; i < nums.size(); i++) {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
if (nums[i] > 0) {
return result;
}
// 错误去重a方法,将会漏掉-1,-1,2 这种情况
/*
if (nums[i] == nums[i + 1]) {
continue;
}
*/
// 正确去重a方法
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// 去重复逻辑如果放在这里,0,0,0 的情况,可能直接导致 right<=left 了,从而漏掉了 0,0,0 这种三元组
/*
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
*/
if (nums[i] + nums[left] + nums[right] > 0) right--;
else if (nums[i] + nums[left] + nums[right] < 0) left++;
else {
result.push_back(vector<int>{nums[i], nums[left], nums[right]});
// 去重逻辑应该放在找到一个三元组之后,对b 和 c去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
return result;
}
};
python代码:
python复制代码
# (版本一) 双指针
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
result = []
nums.sort()
for i in range(len(nums)):
# 如果第一个元素已经大于0,不需要进一步检查
if nums[i] > 0:
return result
# 跳过相同的元素以避免重复
if i > 0 and nums[i] == nums[i - 1]:
continue
left = i + 1
right = len(nums) - 1
while right > left:
sum_ = nums[i] + nums[left] + nums[right]
if sum_ < 0:
left += 1
elif sum_ > 0:
right -= 1
else:
result.append([nums[i], nums[left], nums[right]])
# 跳过相同的元素以避免重复
while right > left and nums[right] == nums[right - 1]:
right -= 1
while right > left and nums[left] == nums[left + 1]:
left += 1
right -= 1
left += 1
return result
#(版本二) 使用字典
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
result = []
nums.sort()
# 找出a + b + c = 0
# a = nums[i], b = nums[j], c = -(a + b)
for i in range(len(nums)):
# 排序之后如果第一个元素已经大于零,那么不可能凑成三元组
if nums[i] > 0:
break
if i > 0 and nums[i] == nums[i - 1]: #三元组元素a去重
continue
d = {}
for j in range(i + 1, len(nums)):
if j > i + 2 and nums[j] == nums[j-1] == nums[j-2]: # 三元组元素b去重
continue
c = 0 - (nums[i] + nums[j])
if c in d:
result.append([nums[i], nums[j], c])
d.pop(c) # 三元组元素c去重
else:
d[nums[j]] = j
return result
九、四数之和
例题:
题意:给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
而四数相加是四个独立的数组,只要找到Ai + Bj + Ck + Dl = 0就可以,不用考虑有重复的四个元素相加等于0的情况,所以相对于本题还是简单了不少!
我们来回顾一下,几道题目使用了双指针法。
2、求解
c++代码:
cpp复制代码
class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
for (int k = 0; k < nums.size(); k++) {
// 剪枝处理
if (nums[k] > target && nums[k] >= 0) {
break; // 这里使用break,统一通过最后的return返回
}
// 对nums[k]去重
if (k > 0 && nums[k] == nums[k - 1]) {
continue;
}
for (int i = k + 1; i < nums.size(); i++) {
// 2级剪枝处理
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {
break;
}
// 对nums[i]去重
if (i > k + 1 && nums[i] == nums[i - 1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
// nums[k] + nums[i] + nums[left] + nums[right] > target 会溢出
if ((long) nums[k] + nums[i] + nums[left] + nums[right] > target) {
right--;
// nums[k] + nums[i] + nums[left] + nums[right] < target 会溢出
} else if ((long) nums[k] + nums[i] + nums[left] + nums[right] < target) {
left++;
} else {
result.push_back(vector<int>{nums[k], nums[i], nums[left], nums[right]});
// 对nums[left]和nums[right]去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
}
return result;
}
};
python代码:
python复制代码
#(版本一) 双指针
class Solution:
def fourSum(self, nums: List[int], target: int) -> List[List[int]]:
nums.sort()
n = len(nums)
result = []
for i in range(n):
if nums[i] > target and nums[i] > 0 and target > 0:# 剪枝(可省)
break
if i > 0 and nums[i] == nums[i-1]:# 去重
continue
for j in range(i+1, n):
if nums[i] + nums[j] > target and target > 0: #剪枝(可省)
break
if j > i+1 and nums[j] == nums[j-1]: # 去重
continue
left, right = j+1, n-1
while left < right:
s = nums[i] + nums[j] + nums[left] + nums[right]
if s == target:
result.append([nums[i], nums[j], nums[left], nums[right]])
while left < right and nums[left] == nums[left+1]:
left += 1
while left < right and nums[right] == nums[right-1]:
right -= 1
left += 1
right -= 1
elif s < target:
left += 1
else:
right -= 1
return result
#(版本二) 使用字典
class Solution(object):
def fourSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[List[int]]
"""
# 创建一个字典来存储输入列表中每个数字的频率
freq = {}
for num in nums:
freq[num] = freq.get(num, 0) + 1
# 创建一个集合来存储最终答案,并遍历4个数字的所有唯一组合
ans = set()
for i in range(len(nums)):
for j in range(i + 1, len(nums)):
for k in range(j + 1, len(nums)):
val = target - (nums[i] + nums[j] + nums[k])
if val in freq:
# 确保没有重复
count = (nums[i] == val) + (nums[j] == val) + (nums[k] == val)
if freq[val] > count:
ans.add(tuple(sorted([nums[i], nums[j], nums[k], val])))
return [list(x) for x in ans]