文章目录
-
- [1. 引言:神经网络训练中的梯度流](#1. 引言:神经网络训练中的梯度流)
- [2. 梯度大小:稳定性的基础](#2. 梯度大小:稳定性的基础)
- [3. 梯度稳定性:超越大小的一致性](#3. 梯度稳定性:超越大小的一致性)
-
- [3.1 梯度稳定的内涵](#3.1 梯度稳定的内涵)
- [3.2 大小与稳定的关系](#3.2 大小与稳定的关系)
- [4. 梯度不稳定的表现形式](#4. 梯度不稳定的表现形式)
-
- [4.1 训练过程中的可见迹象](#4.1 训练过程中的可见迹象)
- [4.2 梯度统计量的异常表现](#4.2 梯度统计量的异常表现)
- [4.3 可视化示例:稳定与不稳定的训练对比](#4.3 可视化示例:稳定与不稳定的训练对比)
- [5. 实例演示:梯度问题的可视化](#5. 实例演示:梯度问题的可视化)
-
- [5.1 设置简单实验](#5.1 设置简单实验)
- [5.2 可视化梯度变化](#5.2 可视化梯度变化)
- [5.3 梯度稳定性的监控](#5.3 梯度稳定性的监控)
- [6. 应对策略:从基础到进阶](#6. 应对策略:从基础到进阶)
-
- [6.1 基础策略:控制梯度大小](#6.1 基础策略:控制梯度大小)
- [6.2 进阶策略:优化梯度稳定性](#6.2 进阶策略:优化梯度稳定性)
- [6.3 优化器选择的影响](#6.3 优化器选择的影响)
- [7. 实践建议与检查清单](#7. 实践建议与检查清单)
-
- [7.1 训练前检查](#7.1 训练前检查)
- [7.2 训练中监控](#7.2 训练中监控)
- [7.3 调试策略](#7.3 调试策略)
- [8. 总结](#8. 总结)
- 参考文献
1. 引言:神经网络训练中的梯度流
在深度学习的训练过程中,梯度下降算法是驱动模型优化的核心动力。梯度不仅决定了参数更新的方向,还决定了更新的步长。然而,梯度的大小和稳定性这两个相互关联但有所区别的概念,常常成为训练成功与否的关键因素。
本文将深入探讨梯度大小与稳定性之间的关系,揭示梯度不稳定的表现形式,并通过实际示例展示这些现象及其解决方法。
2. 梯度大小:稳定性的基础
2.1 梯度大小的重要性
梯度的大小直接决定了参数更新的幅度。我们可以将梯度比作下山时的步长:
- 步长过大:可能越过山谷,在两侧来回震荡
- 步长过小:下山速度极慢,甚至停滞不前
在神经网络中,这对应着两种极端情况:
梯度爆炸
当梯度值过大时,参数更新会剧烈震荡,导致损失函数无法收敛,甚至出现数值溢出(NaN)。
梯度消失
当梯度值过小时,参数更新几乎停滞,网络浅层参数几乎得不到更新,训练速度极慢甚至完全停止。
2.2 数学表达
梯度稳定性常用梯度统计量来衡量。一个常用的稳定性指标是梯度的变异系数(Coefficient of Variation):
CV = σ_g / μ_g其中,μ_g 是梯度的均值,σ_g 是梯度的标准差。CV 值越小,表示梯度分布越稳定。
3. 梯度稳定性:超越大小的一致性
3.1 梯度稳定的内涵
梯度稳定性不仅要求梯度大小在合理范围内,还要求梯度的统计分布保持相对一致。这意味着:
- 不同批次数据产生的梯度方向和大小不应有剧烈变化
- 训练过程中梯度统计量(均值、方差)不应大幅波动
- 各层梯度分布应相对协调
3.2 大小与稳定的关系
我们可以将二者的关系总结为:
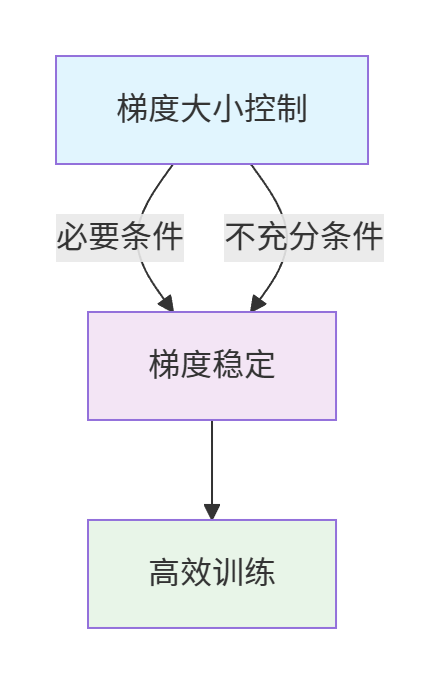
关键洞察 :梯度大小合适是梯度稳定的必要但不充分条件。即使梯度大小被控制在一定范围内,梯度方向剧烈变化仍会导致训练不稳定。
4. 梯度不稳定的表现形式
4.1 训练过程中的可见迹象
| 现象 | 描述 | 可能原因 |
|---|---|---|
| 损失剧烈震荡 | 损失曲线出现频繁大幅波动 | 学习率过大、梯度爆炸 |
| 收敛缓慢 | 损失下降极其缓慢 | 梯度消失、学习率过小 |
| 验证性能不稳定 | 验证指标在相邻 epoch 间大幅跳动 | 过拟合、梯度方向不一致 |
| 超参数敏感 | 学习率稍变就导致训练失败 | 网络结构问题、初始化不当 |
4.2 梯度统计量的异常表现
# 监控梯度统计量的伪代码示例
def monitor_gradients(model, dataloader, epoch):
gradient_norms = []
gradient_means = []
gradient_stds = []
for batch in dataloader:
# 前向传播和反向传播
loss = forward_pass(model, batch)
loss.backward()
# 收集梯度统计信息
total_norm = 0
for param in model.parameters():
if param.grad is not None:
grad = param.grad.data
total_norm += grad.norm().item() ** 2
gradient_means.append(grad.mean().item())
gradient_stds.append(grad.std().item())
gradient_norms.append(total_norm ** 0.5)
# 计算稳定性指标
mean_grad = np.mean(gradient_means)
std_grad = np.mean(gradient_stds)
stability_ratio = mean_grad / (std_grad + 1e-8) # 避免除以0
return gradient_norms, stability_ratio4.3 可视化示例:稳定与不稳定的训练对比
稳定训练:
Epoch 1: Loss: 2.31 → 2.15 → 2.02 → 1.91 → 1.82
Epoch 2: Loss: 1.75 → 1.68 → 1.62 → 1.57 → 1.52
Epoch 3: Loss: 1.48 → 1.45 → 1.42 → 1.39 → 1.36
不稳定训练(梯度爆炸):
Epoch 1: Loss: 2.31 → 1.85 → 3.24 → 0.92 → 4.51
Epoch 2: Loss: 1.23 → 5.67 → 0.45 → 8.92 → 0.21
不稳定训练(梯度消失):
Epoch 1: Loss: 2.31 → 2.30 → 2.29 → 2.29 → 2.28
Epoch 2: Loss: 2.28 → 2.28 → 2.28 → 2.28 → 2.285. 实例演示:梯度问题的可视化
5.1 设置简单实验
让我们创建一个简单的全连接网络,演示梯度消失和爆炸问题:
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
class SimpleNetwork(nn.Module):
def __init__(self, num_layers, init_scale=1.0, activation='tanh'):
super().__init__()
self.layers = nn.ModuleList()
# 创建多层网络
for i in range(num_layers):
self.layers.append(nn.Linear(10, 10))
# 模拟初始化不当:权重过大或过小
with torch.no_grad():
if i % 2 == 0: # 偶数层使用大权重
self.layers[-1].weight.data.normal_(0, init_scale)
else: # 奇数层使用小权重
self.layers[-1].weight.data.normal_(0, init_scale/100)
self.activation = nn.Tanh() if activation == 'tanh' else nn.ReLU()
def forward(self, x):
for i, layer in enumerate(self.layers):
x = layer(x)
if i < len(self.layers) - 1:
x = self.activation(x)
return x
def analyze_gradients(model, num_layers, init_scale, activation='tanh'):
"""分析不同初始化对梯度的影响"""
model = SimpleNetwork(num_layers, init_scale, activation)
# 生成随机输入
x = torch.randn(32, 10)
target = torch.randn(32, 10)
# 前向传播
output = model(x)
loss = nn.MSELoss()(output, target)
# 反向传播
loss.backward()
# 收集梯度信息
gradient_norms = []
for i, layer in enumerate(model.layers):
if layer.weight.grad is not None:
grad_norm = layer.weight.grad.norm().item()
gradient_norms.append(grad_norm)
return gradient_norms5.2 可视化梯度变化
def visualize_gradient_problems():
"""可视化梯度消失和爆炸问题"""
# 测试不同网络深度和初始化
configs = [
{'num_layers': 5, 'init_scale': 1.0, 'label': '正常初始化'},
{'num_layers': 10, 'init_scale': 2.0, 'label': '大权重导致爆炸'},
{'num_layers': 10, 'init_scale': 0.1, 'label': '小权重导致消失'},
]
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
for idx, config in enumerate(configs):
# 分析梯度
gradient_norms = analyze_gradients(
SimpleNetwork,
config['num_layers'],
config['init_scale']
)
# 绘制梯度范数
ax = axes[idx // 2, idx % 2]
ax.plot(range(len(gradient_norms)), gradient_norms,
marker='o', linewidth=2)
ax.set_xlabel('网络层')
ax.set_ylabel('梯度范数')
ax.set_title(f"{config['label']} (深度={config['num_layers']})")
ax.grid(True, alpha=0.3)
# 添加对数坐标
if max(gradient_norms) / min(gradient_norms) > 1000:
ax.set_yscale('log')
ax.set_ylabel('梯度范数(对数)')
plt.tight_layout()
plt.show()
# 运行可视化
visualize_gradient_problems()5.3 梯度稳定性的监控
def train_with_monitoring(model, train_loader, num_epochs=10, lr=0.01):
"""训练并监控梯度稳定性"""
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
losses = []
gradient_stats = []
for epoch in range(num_epochs):
epoch_gradients = []
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = nn.CrossEntropyLoss()(output, target)
loss.backward()
# 收集梯度统计信息
grad_norms = []
for param in model.parameters():
if param.grad is not None:
grad_norm = param.grad.data.norm().item()
grad_norms.append(grad_norm)
# 计算梯度稳定性指标
if grad_norms:
mean_grad = np.mean(grad_norms)
std_grad = np.std(grad_norms)
stability = mean_grad / (std_grad + 1e-8)
epoch_gradients.append({
'mean': mean_grad,
'std': std_grad,
'stability': stability
})
# 梯度裁剪(防止爆炸)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
losses.append(loss.item())
# 记录每个epoch的梯度统计
if epoch_gradients:
avg_stability = np.mean([g['stability'] for g in epoch_gradients])
gradient_stats.append(avg_stability)
print(f"Epoch {epoch}: 损失={np.mean(losses[-len(train_loader):]):.4f}, "
f"梯度稳定性={avg_stability:.4f}")
return losses, gradient_stats6. 应对策略:从基础到进阶
6.1 基础策略:控制梯度大小
| 技术 | 原理 | 适用场景 |
|---|---|---|
| 梯度裁剪 | 限制梯度范数的最大值 | 防止梯度爆炸,特别是 RNN/LSTM |
| 权重初始化 | 使用 Xavier/He 初始化 | 确保前向/反向传播中信号稳定 |
| 批归一化 | 标准化每层输入分布 | 缓解内部协变量偏移,稳定训练 |
| 残差连接 | 提供梯度直连通道 | 缓解深度网络中的梯度消失 |
# 梯度裁剪示例
def train_with_gradient_clipping(model, dataloader, clip_value=1.0):
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for batch in dataloader:
optimizer.zero_grad()
loss = compute_loss(model, batch)
loss.backward()
# 梯度裁剪:防止梯度爆炸
torch.nn.utils.clip_grad_norm_(
model.parameters(),
max_norm=clip_value
)
optimizer.step()6.2 进阶策略:优化梯度稳定性
| 技术 | 原理 | 效果 |
|---|---|---|
| 自适应优化器 | 为每个参数调整学习率 | 缓解梯度大小和方向的不稳定 |
| 梯度累积 | 多个小批次累积梯度 | 提高梯度估计的稳定性 |
| 学习率预热 | 初始阶段逐渐增加学习率 | 避免训练初期的不稳定 |
| 梯度噪声注入 | 为梯度添加随机噪声 | 提高模型鲁棒性,避免尖锐最小值 |
6.3 优化器选择的影响
不同的优化器在梯度稳定性方面表现不同:
def compare_optimizers():
"""比较不同优化器的稳定性"""
optimizers = {
'SGD': torch.optim.SGD,
'SGD+Momentum': lambda params: torch.optim.SGD(params, lr=0.01, momentum=0.9),
'Adam': torch.optim.Adam,
'AdamW': torch.optim.AdamW,
}
stability_results = {}
for opt_name, opt_class in optimizers.items():
model = SimpleNetwork(5, 1.0)
optimizer = opt_class(model.parameters(), lr=0.01)
stability_metrics = []
for _ in range(100): # 模拟多个训练步骤
# 模拟训练步骤
loss = simulate_training_step(model, optimizer)
# 计算梯度稳定性
grad_stability = compute_gradient_stability(model)
stability_metrics.append(grad_stability)
stability_results[opt_name] = {
'mean': np.mean(stability_metrics),
'std': np.std(stability_metrics)
}
return stability_results7. 实践建议与检查清单
7.1 训练前检查
-
权重初始化检查
- 使用合适的初始化方法(Xavier/He)
- 验证初始激活值的分布
- 检查梯度在初始状态的大小
-
架构设计检查
- 深度网络考虑残差连接
- 适当使用归一化层
- 避免激活函数饱和区域
7.2 训练中监控
-
实时监控指标
# 训练循环中的监控 for epoch in range(num_epochs): for batch in train_loader: # ... 训练步骤 ... # 每N步监控一次 if step % monitor_freq == 0: monitor_metrics = { 'loss': loss.item(), 'grad_norm': compute_gradient_norm(model), 'grad_stability': compute_stability_ratio(model), 'param_update_ratio': compute_update_ratio(model) } log_metrics(monitor_metrics) -
预警信号
- 梯度范数 > 1000 或 < 1e-7
- 相邻批次损失变化 > 100%
- 稳定性指标剧烈波动
7.3 调试策略
| 问题现象 | 可能原因 | 调试方法 |
|---|---|---|
| 损失剧烈震荡 | 学习率太大,梯度爆炸 | 减小学习率,添加梯度裁剪 |
| 损失不下降 | 学习率太小,梯度消失 | 增大学习率,检查初始化,添加残差连接 |
| 训练后期发散 | 梯度方向不稳定 | 使用自适应优化器,添加动量 |
| 验证集性能波动 | 批次间梯度差异大 | 增大批次大小,使用梯度累积 |
8. 总结
梯度大小和梯度稳定性是神经网络训练中相互关联但又有所区别的两个关键概念。通过本文的分析,我们可以得出以下核心结论:
- 梯度大小合适是梯度稳定的必要基础:没有合理的梯度大小,就谈不上训练稳定性。梯度爆炸和梯度消失是训练失败的最直接原因。
- 梯度稳定性是更高层次的要求:在控制梯度大小的基础上,我们需要进一步确保梯度分布的统计一致性,包括方向和相对大小的一致性。
- 监控和调整是实践关键:通过实时监控梯度统计量,我们可以及时发现问题并采取相应措施,如梯度裁剪、调整优化器参数、修改网络结构等。
- 优化器的设计本质是追求稳定性:现代优化器(如 Adam)通过自适应学习率和动量机制,同时解决了梯度大小和方向稳定的问题。
在实际训练中,我们应该:
- 首先确保梯度大小合理(无爆炸/消失)
- 在此基础上追求梯度统计分布的稳定性
- 通过综合使用初始化、归一化、优化器选择等技术实现稳定训练
- 持续监控梯度相关指标,建立早期预警机制
梯度稳定性的追求不仅是技术问题,更是理解深度学习优化本质的窗口。通过深入理解梯度行为,我们不仅能解决训练中的实际问题,还能为设计更高效、更稳定的神经网络架构提供指导。
参考文献
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Pascanu, R., Mikolov, T., & Bengio, Y. (2013). On the difficulty of training recurrent neural networks. ICML.
- Glorot, X., & Bengio, Y. (2010). Understanding the difficulty of training deep feedforward neural networks. AISTATS.
- Kingma, D. P., & Ba, J. (2015). Adam: A method for stochastic optimization. ICLR.