一. Git 版本控制
在 Linux 开发生态中,GCC 负责底层的编译转化 ,Makefile 负责工程的构建管理 ,Git 赋予了工程版本演进的确定性 ,使开发者具备随时恢复至稳定状态的版本归档能力。GDB 赋予了开发者运行机制的可视化,确保在程序出现非预期崩溃时,能够高效修复逻辑缺陷
1. 什么是版本控制器
在没有版本控制器的年代,程序员的文件夹通常长这样:
-
project_v1.c
-
project_v2_修复了Bug.c
-
project_v3_最终版.c
-
project_v3_最终版_打死不改版.c
这种手动重命名的方式极易出错,且无法协作。版本控制器是一种记录一个或若干文件内容状态,以便将来查阅特定版本修订情况的系统
它的核心价值在于:
-
回溯:随时回到过去的任何版本
-
协作:多人同时修改同一份代码,并能优雅地合并
-
备份:不仅仅是代码,连同修改历史一起备份
基本概念
Git 的核心在于理解文件的三个区域。把握他们的转换关系,就能掌握 Git 的核心机制
-
工作区: 你在电脑上实际看到的文件夹。你在这里码字、删改文件,代码处于自由的状态
-
暂存区:这是一个临时缓冲区,用于存放待提交的内容,便于后续统一处理
-
仓库: Git 存放元数据和对象数据库的地方。一旦执行 commit,你的代码快照就会永久存储在这里,成为版本历史的一部分
2. Git 简史
Git 的诞生颇具戏剧性。2005 年,当 Linux 内核开发所依赖的商业版本控制系统 BitKeeper 突然取消免费授权后,Linux 创始人 Linus Torvalds 毅然决定亲自开发一个替代方案
早期时代:1991-2002
在 Linux 内核诞生的前十年里,这个世界上最庞大的开源项目是靠纯手工维护的。成千上万的参与者通过邮件发送代码补丁,Linus 等核心维护者则负责手动合并、归档。这种原始的模式不仅低效,而且极易出错,严重制约了内核的进化
BitKeeper 时代: 2002-2005
到了 2002 年,为了摆脱手工劳动的局限性,整个项目组开始启用一个专有的分布式版本控制系统 BitKeeper。Linux 内核首次体验到分布式开发的强大优势,显著提升了协作效率。但BitKeeper作为商业软件的这一属性,后来引发了新的问题
2005
2005 年,开发 BitKeeper 的公司与 Linux 开源社区的关系彻底破裂,收回了免费使用权。
面对这种威胁,Linus Torvalds 没有选择妥协。他基于使用 BitKeeper 时的经验教训,决定从零开始,亲手打造一个属于开源社区的版本控制系统。Linus 为这个新系统定下了五个指标:
-
速度:处理补丁不能有任何迟滞
-
简单的设计:逻辑要直观且精悍
-
强力支持非线性开发:必须能支撑成千上万个并行开发的分支
-
完全分布式:不再依赖中央服务器,每个开发者都是一个完整的备份
-
高效管理项目:必须能像管理 Linux 内核这样海量的数据和复杂的历史
现状
自 2005 年问世以来,Git 仅用了短短几年时间就彻底改变了软件开发的面貌。它不仅保留了初期设定的所有性能,更日臻成熟。如今,Git 凭借其令人难以置信的非线性分支管理系统 和飞快的响应速度,成为了全球开发者心中无可争议的行业标准
3. Git 安装与配置
在 Linux (以 Ubuntu 为例) 上安装 Git 非常简单:
bash
sudo apt update
sudo apt install git安装完成后,首先要做的就是配置用户信息。因为 Git 的每一次提交都会记录作者信息
全局用户信息配置
bash
# 配置用户名
git config --global user.name "username"
# 配置邮箱
git config --global user.email "email@example.com"查看配置
bash
git config --list--global 选项意味着这些配置会作用于你电脑上所有的 Git 仓库。如果你在公司仓库想用工作邮箱,在个人仓库想用私人邮箱,可以在对应的项目目录下去掉 --global 单独配置
4. Git 基本操作
在 Git 的日常使用中,这几个命令构成了 90% 的操作场景
**1. 初始化与克隆:**要开始版本管理,首先得有一个仓库
- **git init:**如果在本地已经有一个写好的项目,想用 Git 管理起来:
bash
cd my_project
git init执行后,目录下会生成一个隐藏的 .git 文件夹
- **git clone:**如果想要从远程服务器(如 GitHub/Gitee)拉取代码:
bash
git clone https://github.com/user/repo.git它不仅下载了最新的代码,还完整地拉取了该项目所有的历史提交记录
2. add 与 commit
Git 不会自动追踪你的修改,需要显式地告知它
-
git add <file>: 将修改过的文件从工作区 移动到暂存区
- 常用指令:git add .(追踪当前目录下所有改动)
-
git commit -m "消息": 将暂存区的内容永久存入本地仓库
- 注意:-m 后的描述极其重要。好的提交信息(如 "fix: 修复了用户登录时的内存泄漏")将为后续代码审查和问题追溯提供极大便利
3. push:同步到云端
commit 只是把代码存到了你本地的硬盘里。如需与团队成员共享或防止本地数据丢失,必须将更改推送至远程服务器
-
git push**:上传**
git push origin master # 将本地 master 分支推送到远程 origin 仓库
如果是第一次推送 init 出来的仓库,你需要先关联远程地址:
git remote add origin https://github.com/yourname/repo.git4. status 与 log
当你对当前操作感到困惑时,这两个命令能立即为你理清思路
-
git status**:**查看哪些文件改了没加到暂存区?哪些加了还没提交?就像一个实时监控
-
git log**:**它会列出所有的提交记录,包括作者、日期和提交哈希值
二. GDB 调试工具
在正式开始前,我们先准备一段样例代码 test.c,以便后续实验:
cpp
#include <stdio.h>
int addTo(int n) {
int sum = 0;
for (int i = 1; i <= n; i++) {
sum += i;
}
return sum;
}
int main() {
int target = 100;
int result = 0;
printf("Starting calculation...\n");
result = addTo(target);
printf("The sum from 1 to %d is: %d\n", target, result);
return 0;
}1. 为什么需要调试器
很多初学者习惯用 printf 来定位问题。虽然这种方法直观且亲切,但在面对复杂逻辑时,它有几个致命伤:
-
效率低下:每改一次 printf 都要重新编译、运行,耗时耗力。
-
信息碎片化:只能看到你打印出的那一小部分变量,无法全局审视整个内存状态
-
不可观测性:有些 bug 会导致程序直接崩溃,printf 往往还没来得及输出缓冲区内容,程序就结束了
调试器的核心价值在于:
-
暂停程序:程序执行到断点处暂停,便于逐步排查错误
-
实时观测:无需提前编写打印语句,可随时查看任意变量
-
回溯调用栈:当程序崩溃时,可以清晰地追踪调用关系和时序信息
2. GDB 基本使用
使用 GDB 调试时,首要且关键的一步是让 GCC 在编译时保留调试信息。若未添加 -g 选项,GDB 仅能显示机器指令,无法将这些指令与源代码行号建立对应关系
bash
gcc -g test.c -o test_debug启动调试
直接在终端输入 gdb 加上你的可执行文件名:
bash
gdb test_debug调试三板斧:l、r、q
在深入复杂命令前,先记住这三个最基本的动作:
-
l:查看源代码
-
直接输入 l,GDB 会显示当前位置附近的 10 行代码。连续输入会继续向下翻页
-
用法:l 1(从第 1 行开始看)或 l main(看 main 函数附近)
-
-
r:让程序跑起来
- 在没有设置断点的情况下,输入 r,程序会一口气跑完,直到结束或崩溃
-
q:退出
- 结束调试,回到 Linux 的 Shell 界面
3. GDB 调试流程
一个完整的调试周期通常遵循 编译---加载---断点---运行---观测---追踪的逻辑链条
1. 启动与加载:
进入 GDB 环境并加载目标程序
-
指令:gdb ./test
-
操作:加载后可使用 list (简写 l) 预览源码,确认调试目标
2. 设置断点
通过断点,使程序在运行至特定逻辑位置时自动挂起
-
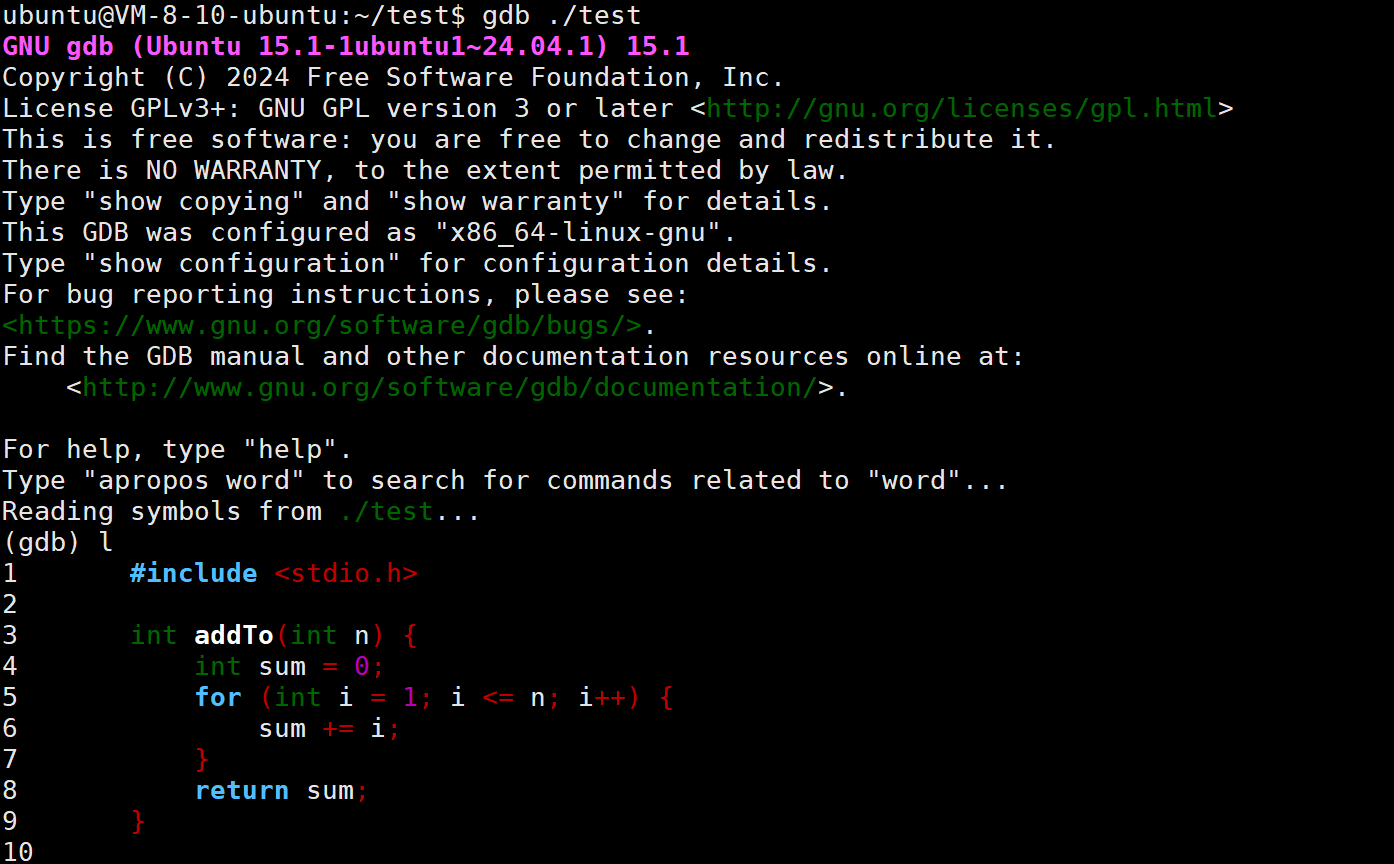
行号断点:b 10(在第 10 行停下)
-
函数断点:b addTo(在进入 addTo 函数的首行停下)
-
查看与管理:使用 info b 查看所有断点,使用 d 编号 删除特定断点
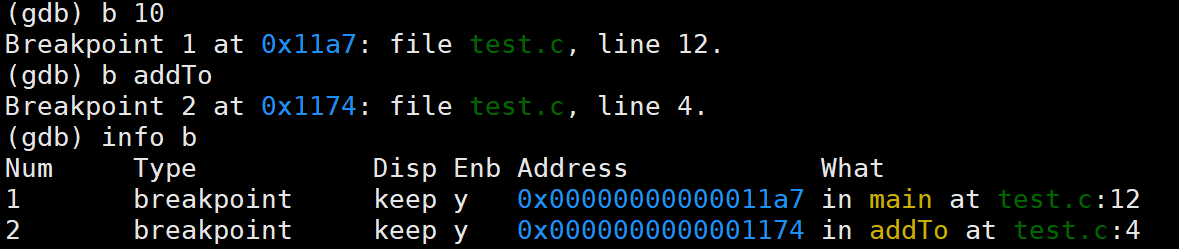
可以看到我们明明是在第 10 行打的断点,但是 info b 却显示断点在 12 行,这是为什么呢
如果第 10 行是空行、注释。CPU 在运行时是不会在这些地方停留的。所以当我们在第 10 行打断点时,GDB 会向下扫描,寻找最近的一行有效执行语句
3. 控制运行流
程序挂起后,开发者需通过控制指令引导程序按预期步进。
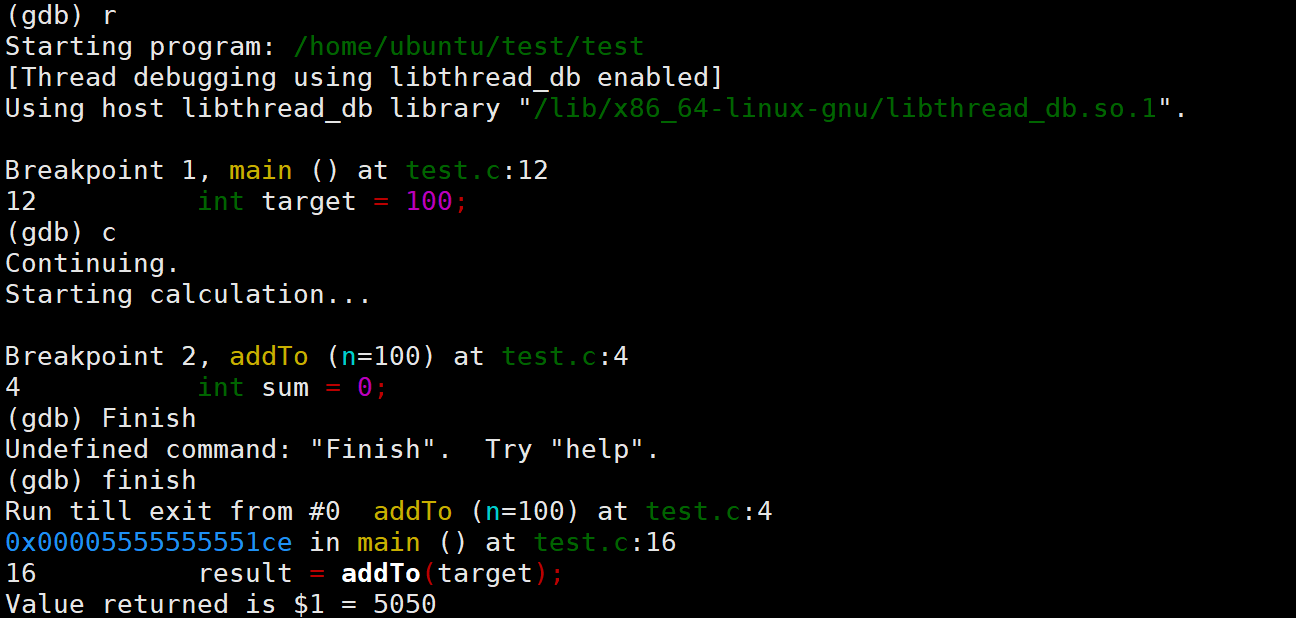
-
Run (r):启动程序。若无断点则运行至结束。
-
Continue (c):从当前断点继续运行,直至遇到下一个断点或程序结束
-
finish:运行完当前函数并停在返回处,用于快速跳出已确认无误的子函数
4. 常见使用
| 命令 | 作用 | 样例 |
|---|---|---|
| list/l | 显示源代码,从上次位置开始,每次列出 10 行 | list/l 10 |
| list/l 函数名 | 列出指定函数的源代码 | list/l main |
| list/l 文件名:行号 | 列出指定文件的源代码 | list/l mycmd.c:1 |
| r/run | 从程序开始连续执行 | run |
| n/next | 单步执行,不进入函数内部,逐过程(对应快捷键 F10) | next |
| s/step | 单步执行,进入函数内部,逐语句(对应快捷键 F11) | step |
| break/b 文件名: 行号 | 在指定行号设置断点 | break 10 break test.c:10 |
| break/b 函数名 | 在函数开头设置断点 | break main |
| info break/b | 查看当前所有断点的信息 | info break |
| finish | 执行到当前函数返回,然后停止 | finish |
| print/p 表达式 | 打印表达式的值 | print start+end |
| p 变量 | 打印指定变量的值 | p x |
| set var 变量 = 值 | 修改变量的值 | set var i=10 |
| continue/c | 从当前位置开始连续执行程序 | continue |
| delete/d breakpoints | 删除所有断点 | delete breakpoints |
| delete/d breakpoints n | 删除序号为 n 的断点 | delete breakpoints 1 |
| disable breakpoints | 禁用所有断点 | disable breakpoints |
| enable breakpoints | 启用所有断点 | enable breakpoints |
| info/i breakpoints | 查看当前设置的断点列表 | info breakpoints |
| display 变量名 | 跟踪显示指定变量的值(每次停止时) | display x |
| undisplay 编号 | 取消对指定编号的变量的跟踪显示 | undisplay 1 |
| until X 行号 | 执行到指定行号 | until 20 |
| backtrace/bt | 查看当前执行栈的各级函数调用及参数 | backtrace |
| info/i locals | 查看当前栈帧的局部变量值 | info locals |
| quit/q | 退出 GDB 调试器 | quit |
5. 高级调试
1. 监视断点(watch)
当某个全局变量莫名被修改,却难以定位具体是哪行代码所为时,单纯设置断点已无法奏效。此时便需要变量监控功能
-
核心逻辑 :监视断点不针对代码行,而是针对内存地址或变量。只要该变量的值发生变化,程序就会立即中断
-
常用指令:
-
watch 变量名:当变量值**被写入(改变)**时中断。
-
rwatch 变量名:当变量值被读取时中断。
-
awatch 变量名:当变量被读取或写入时均中断。
-
-
查看监视点:使用 info watchpoints
2. 运行时干预(set var)
在调试过程中,若发现程序因变量值错误即将进入错误的逻辑分支,无需修改源码并重新编译。使用 set var 命令即可直接调整程序的执行流程
应用场景:
-
跳过已知错误:强制修改标志位,绕过尚未修复的 Bug 环节
-
边界条件测试:直接将循环变量 i 设置为 999,观察循环终止时的表现,跳过自然递增过程
指令语法:
bash
(gdb) set var target = 500
(gdb) set var flag = 0set var 可能会改变程序的预期行为,使用时需确保对逻辑流有清晰的认知
3. 条件断点
假设需要处理一个循环执行 10,000 次的情况,而 Bug 仅在循环变量 i 等于 8888 时才会出现。如果采用常规 n 或 c,我们将陷入无休止的重复操作中
核心逻辑:为断点挂载一个触发条件。只有当表达式为真时,断点才会生效
指令语法:
-
新建时设置: b 行号/函数名 if 条件表达式 示例:b 15 if i == 8888
-
为已有断点添加条件: condition 断点编号 条件表达式 示例:condition 1 sum > 1000
极大地节省了在无关循环中徘徊的时间,实现精准拦截
CGDB 简介
尽管 GDB 功能强大,但其纯命令行界面在查看源码时体验欠佳。CGDB 是一个基于 ncurses 的 GDB 前端,它为开发者提供了一个分屏界面,其上方是高亮显示的源代码窗口,下方是 GDB 命令行。并且代码窗口会随着调试行的跳动实时滚动,并以箭头标记当前执行位置
安装与启动
bash
sudo apt install cgdb
cgdb ./test_debug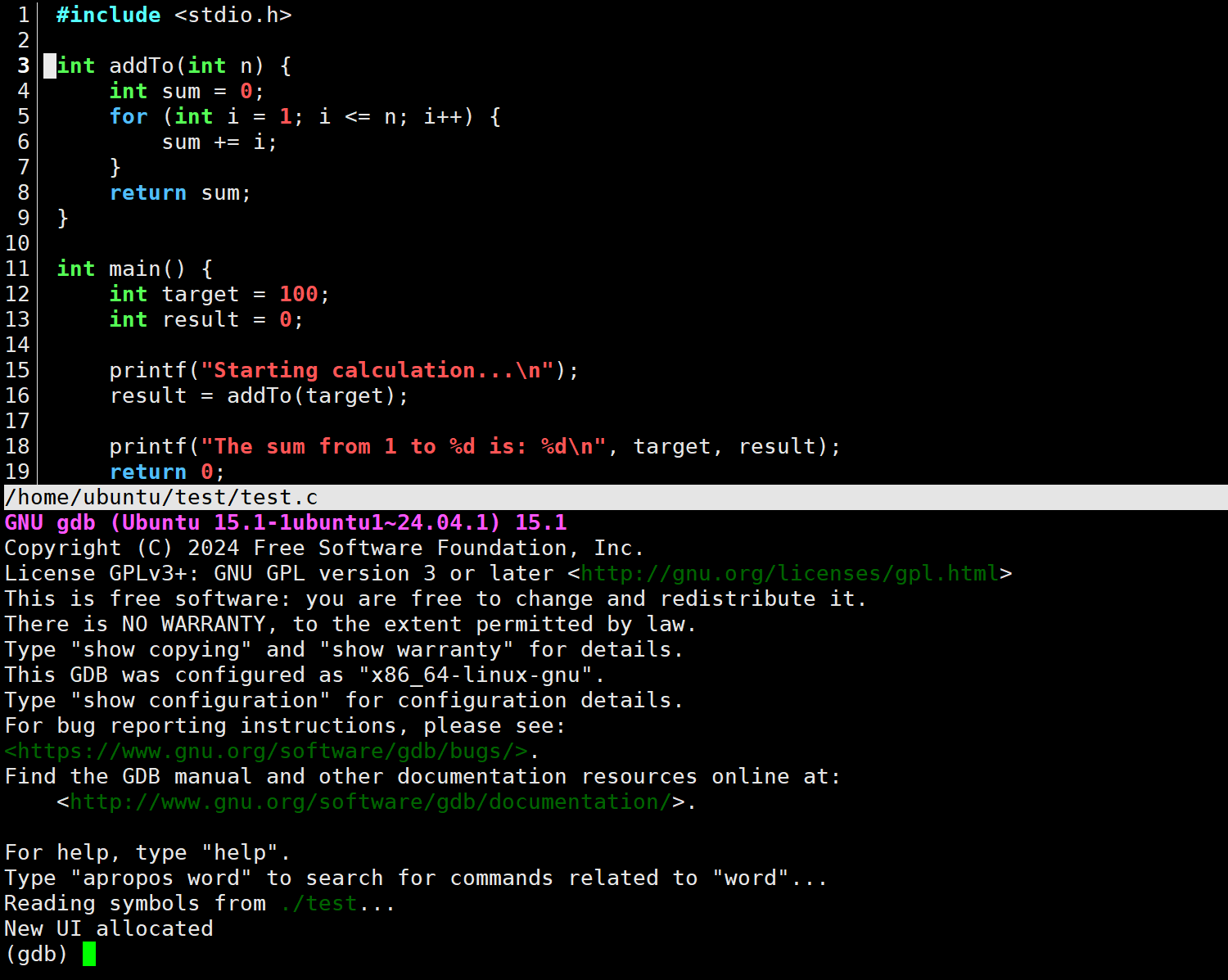
按 i 键进入下方的 GDB 命令行模式,按 ESC 键回到上方的源码浏览模式
总结
在 Linux 开发流程中,Git 与 GDB 分别承担了代码管理 与程序调试的关键角色。通过 Git,我们可以对代码的修改过程进行清晰的记录与回溯,从而提升开发的可控性与协作效率;而借助 GDB,则能够在程序运行过程中深入观察执行状态,定位问题并进行精细调试
从本质上看,Git 解决的是代码在时间维度 上的管理问题,而 GDB 则帮助我们理解程序在运行时的行为。二者相互配合,构成了开发过程中不可或缺的基础工具。
至此,我们已经完成了从 Linux 基础使用到开发工具链的整体搭建。接下来,可以进一步深入系统层面,探索进程管理、内存机制或网络通信等更底层的内容
