文章目录
- 前言
- 一、预检索:检索前的核心优化(提升效率与准确性)
-
- [1.1 优化索引:让检索"有的放矢"](#1.1 优化索引:让检索“有的放矢”)
-
- [1.1.1 索引类型选择:按需选择合适的索引](#1.1.1 索引类型选择:按需选择合适的索引)
- [1.1.2 文档分块优化:避免"大文档冗余""小文档碎片化"](#1.1.2 文档分块优化:避免“大文档冗余”“小文档碎片化”)
- [1.1.3 索引量化与压缩:提升检索速度](#1.1.3 索引量化与压缩:提升检索速度)
- [1.1.4 索引优化代码实例(可运行)](#1.1.4 索引优化代码实例(可运行))
- [1.2 查询优化:让查询"精准匹配"](#1.2 查询优化:让查询“精准匹配”)
-
- [1.2.1 查询重写(Query Rewriting)](#1.2.1 查询重写(Query Rewriting))
- [1.2.2 查询扩展(Query Expansion)](#1.2.2 查询扩展(Query Expansion))
- [1.2.3 查询过滤(Query Filtering)](#1.2.3 查询过滤(Query Filtering))
- [1.2.4 向量查询优化](#1.2.4 向量查询优化)
- [1.2.5 查询优化代码实例(可运行)](#1.2.5 查询优化代码实例(可运行))
- 二、后检索:检索后的优化(提升生成质量)
-
- [2.1 RAG Fusion:融合多轮检索结果,提升相关性](#2.1 RAG Fusion:融合多轮检索结果,提升相关性)
-
- [2.1.1 RAG Fusion的核心原理](#2.1.1 RAG Fusion的核心原理)
- [2.1.2 RAG Fusion的实现方式](#2.1.2 RAG Fusion的实现方式)
- [2.1.3 RAG Fusion代码实例(可运行)](#2.1.3 RAG Fusion代码实例(可运行))
- [2.2 上下文压缩:去除冗余,减轻LLM负担](#2.2 上下文压缩:去除冗余,减轻LLM负担)
-
- [2.2.1 关键词提取压缩](#2.2.1 关键词提取压缩)
- [2.2.2 摘要压缩](#2.2.2 摘要压缩)
- [2.2.3 语义过滤压缩](#2.2.3 语义过滤压缩)
- [2.2.4 上下文压缩代码实例(可运行)](#2.2.4 上下文压缩代码实例(可运行))
- 三、本章练习题及其答案
-
- [3.1 选择题(每题5分,共25分)](#3.1 选择题(每题5分,共25分))
- [3.2 填空题(每空3分,共30分)](#3.2 填空题(每空3分,共30分))
- [3.3 简答题(每题10分,共30分)](#3.3 简答题(每题10分,共30分))
- [3.4 实操题(15分)](#3.4 实操题(15分))
- [3.5 练习题答案](#3.5 练习题答案)
-
- [3.5.1 选择题答案(每题5分,共25分)](#3.5.1 选择题答案(每题5分,共25分))
- [3.5.2 填空题答案(每空3分,共30分)](#3.5.2 填空题答案(每空3分,共30分))
- [3.5.3 简答题答案(每题10分,共30分)](#3.5.3 简答题答案(每题10分,共30分))
- [3.5.4 实操题参考答案(15分)](#3.5.4 实操题参考答案(15分))
- 四、总结
前言
随着大语言模型(LLM)的快速发展,检索增强生成(Retrieval-Augmented Generation, RAG)已成为连接海量知识库与生成模型的核心技术,广泛应用于智能问答、文档助手、知识库检索等场景。RAG的核心逻辑是"检索+生成",通过先从知识库中检索与用户查询相关的信息,再将检索结果作为上下文输入LLM,从而生成准确、有依据、不编造的回复。但在实际应用中,基础RAG常常面临检索效率低、相关性不足、生成内容冗余等问题,而预检索与后检索的优化的是解决这些问题的关键。
本文面向初级/中级后端、前端、运维工程师,以及AI爱好者、在校学生,系统讲解RAG中预检索与后检索的核心技术、优化策略,并提供可运行的代码实例,搭配练习题帮助巩固知识点,助力读者快速掌握RAG的关键优化技巧,将其应用到实际项目中。
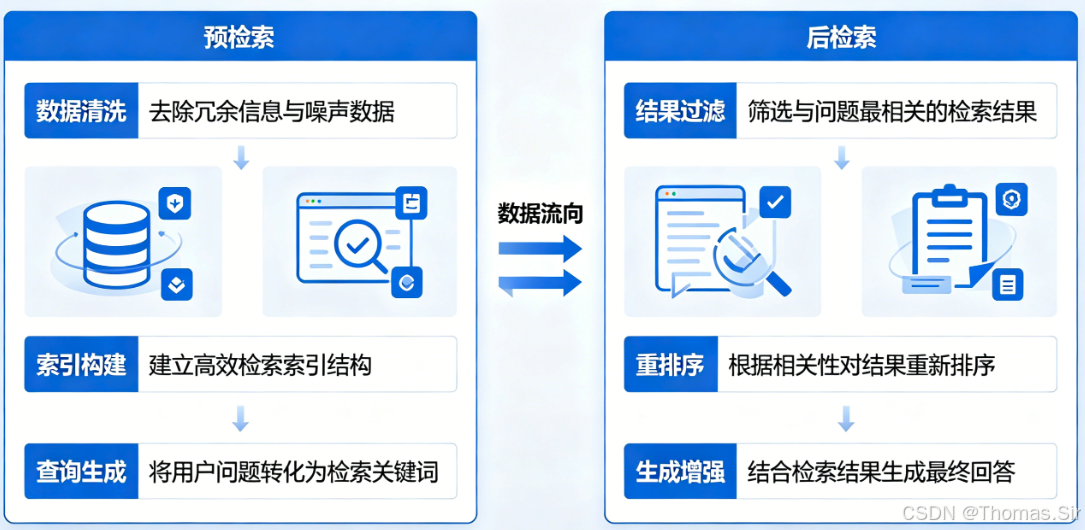
一、预检索:检索前的核心优化(提升效率与准确性)
预检索是指在执行正式检索操作之前,对"检索索引"和"用户查询"进行的一系列优化操作,核心目标是:减少检索的数据量、提升检索速度,同时提高检索结果的相关性,为后续的生成环节奠定良好基础。预检索的核心优化方向主要分为两大块:优化索引和查询优化,二者相辅相成,缺一不可。
1.1 优化索引:让检索"有的放矢"
索引是RAG检索环节的核心载体,相当于知识库的"目录",索引的设计直接决定了检索的效率和准确性。基础的RAG往往采用简单的向量索引,但在面对海量文档(如十万级、百万级)时,会出现检索速度慢、冗余结果多的问题。针对这一问题,预检索阶段的索引优化主要从"索引类型选择""文档分块优化""索引量化与压缩"三个方面入手。
1.1.1 索引类型选择:按需选择合适的索引
RAG中常用的索引主要分为三类:向量索引、全文检索索引、混合索引,不同索引的适用场景不同,需根据知识库的规模、文档类型、检索需求选择。
-
向量索引:核心用于语义检索,将文档和查询都转换为向量,通过计算向量相似度(如余弦相似度)来匹配相关文档,适合长文本、语义关联较强的场景(如问答、文档摘要)。常用的向量索引库有FAISS(Facebook开源)、Chroma、Pinecone(云服务)、Milvus等。
-
全文检索索引:核心用于关键词检索,通过对文档中的关键词建立倒排索引,快速匹配包含查询关键词的文档,适合关键词明确、短查询的场景(如文档搜索)。常用的全文检索索引有Elasticsearch、Solr等。
-
混合索引:结合向量索引和全文检索索引的优势,先通过全文检索索引快速筛选出包含关键词的文档,再通过向量索引计算语义相似度,进一步筛选出最相关的文档,适合海量文档、兼顾关键词和语义检索的场景。
对于初级开发者而言,优先选择开源、易部署的索引库(如FAISS、Chroma),无需关注底层实现,只需掌握其基本使用方法即可;对于中级开发者,可根据项目需求搭建混合索引,平衡检索效率和相关性。
1.1.2 文档分块优化:避免"大文档冗余""小文档碎片化"
文档分块是索引优化的核心步骤------将原始的长文档(如PDF、Word)分割成多个小的文本块(Chunk),再对每个文本块建立索引。如果分块过大,会导致检索结果冗余(包含无关内容);如果分块过小,会导致语义不完整,检索相关性下降。预检索阶段的分块优化,主要遵循"语义完整性"和"粒度适配"两个原则,常用的分块方法有以下3种:
-
固定长度分块:按照固定的字符数或token数分割文档(如每500个字符为一个块),优点是简单易实现,适合结构简单的文档(如纯文本);缺点是可能破坏句子、段落的语义完整性。
-
语义分块:基于文档的语义结构(如段落、句子、章节)进行分块,优先保证每个块的语义完整,优点是检索相关性高,适合结构复杂的文档(如论文、教程);缺点是实现难度稍高,需要借助NLP工具(如NLTK、spaCy)解析文档结构。
-
重叠分块:在固定长度分块或语义分块的基础上,让相邻的块之间保留一定的重叠内容(如重叠50个字符),避免因分块导致的语义断裂,适合长文档的检索优化。
实践中,推荐采用"语义分块+重叠分块"的组合方式,既保证语义完整性,又避免碎片化。下面给出基于Python和spaCy的语义分块代码实例,带详细注释,可直接运行。
1.1.3 索引量化与压缩:提升检索速度
当知识库规模较大(如百万级文本块)时,向量索引的存储空间会急剧增加,检索速度也会下降。此时,需要对索引进行量化和压缩,在不明显降低检索相关性的前提下,减少存储空间、提升检索速度。常用的量化方法有以下两种:
-
标量量化(Scalar Quantization):将向量的每个维度从浮点数(如float32)转换为整数(如int8),减少存储空间,同时加快相似度计算速度,适合对检索精度要求不极高的场景。
-
乘积量化(Product Quantization, PQ):将向量拆分为多个子向量,对每个子向量进行量化,进一步压缩存储空间,FAISS等索引库已内置PQ量化功能,适合海量文档的检索场景。
1.1.4 索引优化代码实例(可运行)
下面以"Chroma索引库+语义分块+标量量化"为例,实现预检索阶段的索引优化,代码基于Python 3.9,需提前安装相关依赖(chroma-core、spacy、sentence-transformers),注释详细,适合初级/中级开发者学习使用。
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
RAG预检索 - 索引优化代码实例
功能:实现文档语义分块、Chroma向量索引构建、标量量化,提升检索效率
依赖安装:pip install chroma-core spacy sentence-transformers
"""
import spacy
import chromadb
from chromadb.utils import embedding_functions
from sentence_transformers import SentenceTransformer
from chromadb.config import Settings
# 1. 初始化工具:spaCy用于语义分块,SentenceTransformer用于生成向量,Chroma用于构建索引
# 加载spaCy的英文模型(用于句子分割,中文可替换为zh_core_web_sm)
nlp = spacy.load("en_core_web_sm")
# 加载向量模型(轻量级,适合入门,中文可替换为paraphrase-multilingual-MiniLM-L12-v2)
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
# 初始化Chroma客户端(本地存储,适合开发测试)
chroma_client = chromadb.Client(
Settings(
persist_directory="./chroma_index", # 索引存储路径
anonymized_telemetry=False # 关闭匿名统计
)
)
# 2. 文档分块:语义分块(按句子分割)+ 重叠分块
def semantic_chunking(text, chunk_size=500, overlap=50):
"""
语义分块函数
:param text: 原始文档文本
:param chunk_size: 每个块的最大字符数
:param overlap: 相邻块的重叠字符数
:return: 分块后的文本列表
"""
# 使用spaCy分割句子,保证语义完整性
doc = nlp(text)
sentences = [sent.text.strip() for sent in doc.sents if sent.text.strip()]
chunks = []
current_chunk = []
current_length = 0
for sentence in sentences:
# 计算当前句子的长度
sentence_length = len(sentence)
# 如果当前块加上当前句子超过chunk_size,保存当前块,开始新块
if current_length + sentence_length > chunk_size and current_chunk:
# 保存当前块(拼接句子)
chunks.append(" ".join(current_chunk))
# 新块从当前句子的前overlap个字符开始(重叠分块)
current_chunk = [sentence[:overlap]] if overlap > 0 else [sentence]
current_length = len(current_chunk[0])
else:
# 将句子加入当前块
current_chunk.append(sentence)
current_length += sentence_length
# 保存最后一个块
if current_chunk:
chunks.append(" ".join(current_chunk))
return chunks
# 3. 构建优化后的Chroma索引(含标量量化)
def build_optimized_index(documents, collection_name="optimized_rag_index"):
"""
构建优化的Chroma向量索引
:param documents: 原始文档列表(每个元素是一篇文档的文本)
:param collection_name: 索引集合名称
:return: Chroma索引集合
"""
# 1. 对所有文档进行语义分块
all_chunks = []
chunk_ids = []
chunk_metadata = [] # 存储分块的元数据(如所属文档索引)
for doc_idx, doc_text in enumerate(documents):
chunks = semantic_chunking(doc_text)
for chunk_idx, chunk in enumerate(chunks):
all_chunks.append(chunk)
# 生成唯一的分块ID(格式:doc_文档索引_chunk_分块索引)
chunk_ids.append(f"doc_{doc_idx}_chunk_{chunk_idx}")
# 存储元数据:所属文档索引
chunk_metadata.append({"doc_index": doc_idx, "chunk_index": chunk_idx})
# 2. 初始化Chroma集合,启用标量量化(int8),减少存储空间
# 自定义嵌入函数(使用SentenceTransformer生成向量)
custom_embedding = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="all-MiniLM-L6-v2"
)
# 创建集合(如果已存在则删除重建)
if collection_name in [col.name for col in chroma_client.list_collections()]:
chroma_client.delete_collection(name=collection_name)
collection = chroma_client.create_collection(
name=collection_name,
embedding_function=custom_embedding,
metadata={"hnsw:space": "cosine"} # 相似度计算方式:余弦相似度
)
# 3. 向集合中添加分块、ID和元数据(启用标量量化)
collection.add(
documents=all_chunks,
ids=chunk_ids,
metadatas=chunk_metadata
)
# 持久化索引(将索引保存到本地,下次可直接加载)
chroma_client.persist()
print(f"索引构建完成!共添加 {len(all_chunks)} 个文本块,索引保存路径:./chroma_index")
return collection
# 4. 测试代码:使用示例文档构建索引
if __name__ == "__main__":
# 示例文档(3篇,模拟知识库文档)
sample_documents = [
"""Retrieval-Augmented Generation (RAG) is a framework that combines retrieval systems with generative models to produce accurate, context-aware responses. It addresses the limitations of large language models (LLMs), such as hallucinations and outdated knowledge, by grounding the generation process in a external knowledge base. RAG has two core stages: retrieval and generation. The retrieval stage fetches relevant information from the knowledge base, and the generation stage uses this information to produce a coherent response. Pre-retrieval and post-retrieval optimizations are key to improving the performance of RAG systems.""",
"""Pre-retrieval optimization refers to the steps taken before the actual retrieval process to improve efficiency and relevance. Key strategies include index optimization, query optimization, and data preprocessing. Index optimization involves choosing the right index type (e.g., vector index, full-text index), optimizing document chunking, and quantizing the index to reduce storage and speed up retrieval. Query optimization involves reformulating user queries to better match the index structure, such as expanding keywords or converting natural language queries into vector representations.""",
"""Post-retrieval optimization occurs after the retrieval stage and focuses on improving the quality of the retrieved results before passing them to the generative model. Common techniques include RAG Fusion, context compression, and re-ranking. RAG Fusion combines multiple retrieval results to enhance relevance, while context compression reduces redundant information in the retrieved context, making it more efficient for the LLM to process. Re-ranking reorders the retrieved results based on their relevance to the query."""
]
# 构建优化后的索引
rag_index = build_optimized_index(sample_documents)
# 测试检索(简单验证索引有效性)
query = "What is pre-retrieval optimization in RAG?"
results = rag_index.query(
query_texts=[query],
n_results=2 # 检索前2个最相关的分块
)
print("\n检索测试结果:")
for i, (doc, score) in enumerate(zip(results["documents"][0], results["distances"][0])):
print(f"\n相关分块 {i+1}(相似度:{score:.4f}):")
print(doc)
代码说明:该实例实现了从文档分块到索引构建的完整流程,采用语义分块保证检索相关性,启用标量量化减少存储空间,适合入门学习。中文场景下,只需替换spaCy模型(zh_core_web_sm)和向量模型(paraphrase-multilingual-MiniLM-L12-v2),即可直接适配中文文档。
1.2 查询优化:让查询"精准匹配"
即使索引优化得再好,如果用户的原始查询表述模糊、关键词不明确,也会导致检索结果相关性下降。查询优化是预检索的另一核心环节,指对用户的原始查询进行处理,将其转换为更适合索引检索的形式,核心目标是"提升查询与索引的匹配度",常用的优化策略有4种。
1.2.1 查询重写(Query Rewriting)
用户的原始查询往往比较口语化、模糊化(如"RAG怎么优化"),查询重写的核心是将其转换为更规范、更具体的查询语句(如"RAG预检索的索引优化方法和查询优化策略"),同时补充缺失的上下文,提升检索相关性。
常用的查询重写方法有两种:
-
规则式重写:基于预设的规则,对查询进行标准化处理(如去除语气词、补充领域关键词、修正错别字),适合简单查询场景。
-
LLM辅助重写:借助LLM将模糊的查询重写为精准的查询,适合复杂查询场景(如多意图查询、口语化查询)。例如,给LLM输入提示词:"将用户查询'RAG怎么优化'重写为精准的技术查询,用于检索RAG优化相关的技术文档,要求包含核心关键词,语句规范。"
1.2.2 查询扩展(Query Expansion)
查询扩展是指在原始查询的基础上,添加同义词、近义词、相关关键词,扩大检索范围,避免因关键词缺失导致的漏检。例如,原始查询"预检索优化",可扩展为"预检索优化、索引优化、查询优化、文档分块优化"。
实现方式:可借助同义词词典(如WordNet)、领域词表,或通过LLM生成相关关键词。对于初级开发者,优先使用开源的同义词工具(如jieba分词的同义词扩展),简单易实现。
1.2.3 查询过滤(Query Filtering)
查询过滤是指在检索前,对查询进行过滤,去除无关的关键词、语气词、特殊字符,减少检索的噪声,提升检索效率。例如,原始查询"请问RAG的预检索和后检索有什么区别呀?",过滤后可得到"RAG 预检索 后检索 区别"。
1.2.4 向量查询优化
对于向量索引,查询优化的核心是提升向量表示的准确性。常用方法有:使用更适合领域的向量模型(如技术文档用技术领域的向量模型)、对查询向量进行归一化处理、调整向量维度(减少冗余维度)。
1.2.5 查询优化代码实例(可运行)
下面实现"规则式查询重写+查询扩展+查询过滤"的组合优化,结合上一节的索引,实现完整的预检索流程,代码带详细注释,可直接运行。
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
RAG预检索 - 查询优化代码实例
功能:实现查询过滤、规则式重写、查询扩展,结合索引完成预检索
依赖:与上一节相同(chroma-core、spacy、sentence-transformers)
"""
import re
import spacy
import chromadb
from chromadb.config import Settings
from chromadb.utils import embedding_functions
# 1. 初始化工具(复用上一节的索引和模型)
nlp = spacy.load("en_core_web_sm")
chroma_client = chromadb.Client(
Settings(
persist_directory="./chroma_index",
anonymized_telemetry=False
)
)
# 加载之前构建的索引集合
collection = chroma_client.get_collection(
name="optimized_rag_index",
embedding_function=embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="all-MiniLM-L6-v2"
)
)
# 2. 查询过滤:去除语气词、特殊字符、无关词汇
def query_filter(query):
"""
查询过滤函数
:param query: 原始用户查询
:return: 过滤后的查询
"""
# 去除特殊字符(除了字母、数字、空格、中文)
query = re.sub(r"[^\w\s\u4e00-\u9fa5]", "", query)
# 去除语气词(英文)
stop_words = ["what", "how", "why", "what's", "how's", "why's", "please", "could", "would", "can", "may"]
# 分词
tokens = query.lower().split()
# 过滤语气词和空字符串
filtered_tokens = [token for token in tokens if token not in stop_words and token.strip()]
# 拼接过滤后的查询
return " ".join(filtered_tokens)
# 3. 规则式查询重写:将模糊查询转换为精准查询
def query_rewrite(query):
"""
规则式查询重写函数
:param query: 过滤后的查询
:return: 重写后的精准查询
"""
# 预设重写规则(可根据实际场景扩展)
rewrite_rules = {
"rag optimize": "RAG pre-retrieval and post-retrieval optimization methods",
"pre-retrieval": "pre-retrieval optimization strategies in RAG, including index optimization and query optimization",
"post-retrieval": "post-retrieval optimization strategies in RAG, including RAG Fusion and context compression",
"rag retrieval": "RAG retrieval stage optimization methods"
}
# 匹配规则,进行重写(优先完全匹配,再部分匹配)
query_lower = query.lower()
for key, value in rewrite_rules.items():
if key == query_lower:
return value
elif key in query_lower:
return query_lower.replace(key, value)
# 无匹配规则时,返回原查询(保证兼容性)
return query
# 4. 查询扩展:添加同义词、相关关键词
def query_expansion(query):
"""
查询扩展函数
:param query: 重写后的查询
:return: 扩展后的查询(多个关键词,用空格分隔)
"""
# 领域同义词表(可根据RAG领域扩展)
synonym_dict = {
"optimization": "optimization, improvement, enhancement",
"pre-retrieval": "pre-retrieval, pre-query, retrieval preparation",
"post-retrieval": "post-retrieval, post-query, retrieval refinement",
"index": "index, vector index, full-text index",
"chunking": "chunking, document segmentation"
}
# 分词
tokens = query.lower().split()
expanded_tokens = []
for token in tokens:
# 添加原词
expanded_tokens.append(token)
# 添加同义词(如果存在)
if token in synonym_dict:
expanded_tokens.extend(synonym_dict[token].split(", "))
# 去重,避免重复关键词
expanded_tokens = list(set(expanded_tokens))
# 拼接扩展后的查询
return " ".join(expanded_tokens)
# 5. 完整的预检索流程(查询优化+索引检索)
def pre_retrieval_pipeline(query, n_results=3):
"""
预检索流水线
:param query: 原始用户查询
:param n_results: 要检索的结果数量
:return: 检索结果(包含文档、相似度、元数据)
"""
print(f"原始查询:{query}")
# 1. 查询过滤
filtered_query = query_filter(query)
print(f"过滤后查询:{filtered_query}")
# 2. 查询重写
rewritten_query = query_rewrite(filtered_query)
print(f"重写后查询:{rewritten_query}")
# 3. 查询扩展
expanded_query = query_expansion(rewritten_query)
print(f"扩展后查询:{expanded_query}")
# 4. 索引检索
results = collection.query(
query_texts=[expanded_query],
n_results=n_results,
include=["documents", "distances", "metadatas"] # 包含文档、相似度、元数据
)
return results
# 6. 测试预检索流水线
if __name__ == "__main__":
# 测试模糊查询(模拟用户真实查询场景)
user_query = "How to optimize RAG's pre-retrieval?"
# 执行预检索
retrieval_results = pre_retrieval_pipeline(user_query)
# 输出结果
print("\n预检索结果:")
for i, (doc, score, metadata) in enumerate(zip(
retrieval_results["documents"][0],
retrieval_results["distances"][0],
retrieval_results["metadatas"][0]
)):
print(f"\n结果 {i+1}")
print(f"相似度:{score:.4f}")
print(f"所属文档索引:{metadata['doc_index']},分块索引:{metadata['chunk_index']}")
print(f"文档内容:{doc}")
代码说明:该实例实现了完整的预检索流水线,从查询过滤到查询重写、查询扩展,再到索引检索,每一步都有详细注释。用户可根据实际场景,扩展重写规则和同义词表,适配不同的查询需求。
二、后检索:检索后的优化(提升生成质量)
后检索是指在完成检索操作后,对检索到的结果进行优化处理,再将其作为上下文输入LLM进行生成的过程。核心目标是:去除检索结果中的冗余信息、提升结果的相关性和完整性,减少LLM的输入负担,最终生成更准确、更简洁、更有依据的回复。后检索的核心优化方向主要分为两大块:RAG Fusion和上下文压缩,二者可单独使用,也可组合使用,实现效果最大化。
2.1 RAG Fusion:融合多轮检索结果,提升相关性
基础RAG往往只执行一次检索,容易出现"检索结果片面""漏检相关文档"的问题。RAG Fusion(检索结果融合)的核心思想是:对用户的查询进行多轮不同方式的检索(如不同的检索策略、不同的向量模型、不同的索引),将多轮检索结果进行融合排序,筛选出最相关的结果,从而提升检索的召回率和准确率。
2.1.1 RAG Fusion的核心原理
RAG Fusion的核心流程分为3步:
- 多轮检索:针对用户的原始查询(或重写后的查询),执行多轮不同的检索操作。例如:
- 第一轮:使用向量索引进行语义检索; - 第二轮:使用全文检索索引进行关键词检索; - 第三轮:使用不同的向量模型进行语义检索。
-
结果融合:对多轮检索的结果进行去重,然后根据"相似度分数"进行加权排序(不同检索方式的权重可根据实际场景调整)。例如,向量检索的权重设为0.6,全文检索的权重设为0.4,综合计算每个结果的最终分数。
-
结果筛选:根据最终分数,筛选出Top N个最相关的结果,作为后续生成环节的上下文。
RAG
Fusion的优势在于:避免单一检索方式的局限性,兼顾语义相关性和关键词匹配,提升检索结果的完整性和准确性,尤其适合复杂查询、海量文档的场景。
2.1.2 RAG Fusion的实现方式
RAG Fusion的实现主要分为两种:
-
简单融合:多轮检索后,对结果去重,取所有结果中相似度最高的Top N个,适合入门场景,实现简单。
-
加权融合:为不同的检索方式分配不同的权重,计算每个结果的加权分数(如:最终分数=向量检索分数×0.6 + 全文检索分数×0.4),再根据加权分数排序,适合对检索精度要求较高的场景。
2.1.3 RAG Fusion代码实例(可运行)
下面结合上一节的预检索代码,实现"向量检索+全文检索"的RAG Fusion,采用加权融合方式,代码带详细注释,可直接运行。
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
RAG后检索 - RAG Fusion代码实例
功能:实现向量检索+全文检索的加权融合,提升检索结果相关性
依赖:新增elasticsearch(全文检索索引),安装:pip install elasticsearch
"""
import re
from elasticsearch import Elasticsearch
import chromadb
from chromadb.config import Settings
from chromadb.utils import embedding_functions
from pre_retrieval import query_filter, query_rewrite, query_expansion # 导入预检索的查询优化函数
# 1. 初始化工具:Chroma(向量检索)、Elasticsearch(全文检索)
# 初始化Chroma向量索引(复用之前构建的索引)
chroma_client = chromadb.Client(
Settings(
persist_directory="./chroma_index",
anonymized_telemetry=False
)
)
chroma_collection = chroma_client.get_collection(
name="optimized_rag_index",
embedding_function=embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="all-MiniLM-L6-v2"
)
)
# 初始化Elasticsearch(全文检索,本地部署或使用云服务,此处用本地默认配置)
es = Elasticsearch("http://localhost:9200")
# 创建Elasticsearch索引(如果不存在)
es_index_name = "rag_fulltext_index"
if not es.indices.exists(index=es_index_name):
es.indices.create(index=es_index_name)
# 批量添加分块数据到Elasticsearch(复用Chroma中的分块)
chroma_docs = chroma_collection.get()
es_docs = []
for doc_id, doc_text, metadata in zip(
chroma_docs["ids"], chroma_docs["documents"], chroma_docs["metadatas"]
):
es_docs.append({"index": {"_index": es_index_name, "_id": doc_id}})
es_docs.append({"text": doc_text, "metadata": metadata})
# 批量插入
es.bulk(body=es_docs)
print("Elasticsearch全文索引构建完成!")
# 2. 多轮检索:向量检索 + 全文检索
def multi_round_retrieval(query, n_results=3):
"""
多轮检索函数
:param query: 扩展后的查询
:param n_results: 每轮检索的结果数量
:return: 向量检索结果、全文检索结果
"""
# 1. 向量检索(复用Chroma索引)
chroma_results = chroma_collection.query(
query_texts=[query],
n_results=n_results,
include=["documents", "distances", "metadatas", "ids"]
)
# 整理向量检索结果(格式:{文档ID: {文档内容、相似度、元数据}})
chroma_dict = {}
for doc_id, doc, score, metadata in zip(
chroma_results["ids"][0],
chroma_results["documents"][0],
chroma_results["distances"][0],
chroma_results["metadatas"][0]
):
# 余弦相似度范围是[0,2],转换为[0,1](值越大越相关)
normalized_score = 1 - (score / 2)
chroma_dict[doc_id] = {
"document": doc,
"score": normalized_score,
"metadata": metadata,
"source": "chroma_vector"
}
# 2. 全文检索(Elasticsearch)
es_results = es.search(
index=es_index_name,
body={
"query": {
"match": {
"text": query # 基于关键词匹配
}
},
"size": n_results
}
)
# 整理全文检索结果(格式:{文档ID: {文档内容、相似度、元数据}})
es_dict = {}
for hit in es_results["hits"]["hits"]:
doc_id = hit["_id"]
doc = hit["_source"]["text"]
score = hit["_score"] # Elasticsearch的相关性分数,值越大越相关
metadata = hit["_source"]["metadata"]
# 归一化分数到[0,1](避免分数过高或过低)
normalized_score = min(score / 10, 1.0)
es_dict[doc_id] = {
"document": doc,
"score": normalized_score,
"metadata": metadata,
"source": "elasticsearch_fulltext"
}
return chroma_dict, es_dict
# 3. RAG Fusion:加权融合多轮检索结果
def rag_fusion(chroma_dict, es_dict, vector_weight=0.6, fulltext_weight=0.4, top_n=3):
"""
RAG Fusion加权融合函数
:param chroma_dict: 向量检索结果字典
:param es_dict: 全文检索结果字典
:param vector_weight: 向量检索的权重
:param fulltext_weight: 全文检索的权重
:param top_n: 最终筛选的结果数量
:return: 融合后的Top N结果(按加权分数排序)
"""
# 合并所有检索结果(去重)
merged_results = {}
# 先添加向量检索结果
for doc_id, info in chroma_dict.items():
merged_results[doc_id] = info
# 再添加全文检索结果(如果文档ID已存在,更新分数为加权分数)
for doc_id, info in es_dict.items():
if doc_id in merged_results:
# 加权融合分数:向量分数×向量权重 + 全文分数×全文权重
merged_results[doc_id]["score"] = (
merged_results[doc_id]["score"] * vector_weight
+ info["score"] * fulltext_weight
)
# 标记来源为融合
merged_results[doc_id]["source"] = "fusion"
else:
# 新文档,直接添加,分数为全文检索分数×全文权重
info["score"] = info["score"] * fulltext_weight
merged_results[doc_id] = info
# 按加权分数降序排序,取Top N
sorted_results = sorted(
merged_results.values(),
key=lambda x: x["score"],
reverse=True
)[:top_n]
return sorted_results
# 4. 完整的后检索(RAG Fusion)流程
def post_retrieval_rag_fusion(user_query, top_n=3):
"""
后检索RAG Fusion流水线
:param user_query: 原始用户查询
:param top_n: 最终筛选的结果数量
:return: 融合后的检索结果
"""
# 1. 先执行预检索的查询优化
filtered_query = query_filter(user_query)
rewritten_query = query_rewrite(filtered_query)
expanded_query = query_expansion(rewritten_query)
# 2. 多轮检索(向量+全文)
chroma_results, es_results = multi_round_retrieval(expanded_query, n_results=top_n)
# 3. RAG Fusion融合
fusion_results = rag_fusion(chroma_results, es_results, top_n=top_n)
return fusion_results
# 5. 测试RAG Fusion
if __name__ == "__main__":
# 测试查询
user_query = "What are the key strategies of pre-retrieval and post-retrieval in RAG?"
# 执行后检索RAG Fusion
fusion_results = post_retrieval_rag_fusion(user_query, top_n=3)
# 输出结果
print(f"原始查询:{user_query}")
print("\nRAG Fusion融合结果(按加权分数排序):")
for i, result in enumerate(fusion_results, 1):
print(f"\n结果 {i}")
print(f"加权分数:{result['score']:.4f}")
print(f"检索来源:{result['source']}")
print(f"所属文档索引:{result['metadata']['doc_index']},分块索引:{result['metadata']['chunk_index']}")
print(f"文档内容:{result['document']}")
代码说明:该实例实现了向量检索与全文检索的加权融合,通过归一化分数、分配权重,提升检索结果的相关性。需要注意的是,运行前需部署Elasticsearch(本地部署或使用云服务),并确保Elasticsearch服务正常运行。对于初级开发者,可先使用简单融合方式(去重后取Top
N),降低实现难度。
2.2 上下文压缩:去除冗余,减轻LLM负担
经过预检索和RAG Fusion后,检索到的结果可能仍然包含冗余信息(如重复内容、与查询无关的细节),而LLM的输入上下文长度是有限的(如GPT-3.5 Turbo的上下文长度为4k token),冗余信息会占用上下文空间,导致LLM无法专注于核心内容,甚至生成冗余、不准确的回复。
上下文压缩的核心目标是:在保留检索结果核心信息的前提下,去除冗余内容、精简文本长度,让压缩后的上下文更简洁、更聚焦于用户查询,减轻LLM的输入负担,提升生成质量。常用的上下文压缩方法有3种。
2.2.1 关键词提取压缩
核心思路:提取检索结果中与用户查询相关的关键词和核心句子,去除无关的句子和细节,适合短文本检索结果的压缩。实现方式:可借助NLP工具(如spaCy、NLTK)提取关键词,再根据关键词筛选核心句子。
2.2.2 摘要压缩
核心思路:对每个检索结果进行摘要生成,将长文本压缩为短摘要(如100-200个字符),保留核心信息,适合长文本检索结果的压缩。实现方式:可借助LLM生成摘要(如使用ChatGPT、Llama等模型),或使用开源的摘要模型(如BART、T5)。
2.2.3 语义过滤压缩
核心思路:计算检索结果中每个句子与用户查询的语义相似度,过滤掉相似度低的句子,保留相似度高的句子,适合语义相关性要求高的场景。实现方式:将句子和查询转换为向量,计算余弦相似度,筛选出相似度高于阈值的句子。
2.2.4 上下文压缩代码实例(可运行)
下面实现"摘要压缩+语义过滤压缩"的组合方式,结合上一节的RAG Fusion结果,完成上下文压缩,代码带详细注释,可直接运行。
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
RAG后检索 - 上下文压缩代码实例
功能:实现摘要压缩+语义过滤压缩,去除冗余信息,精简上下文
依赖:新增transformers(摘要模型),安装:pip install transformers torch
"""
import torch
from transformers import pipeline
from sentence_transformers import SentenceTransformer, util
from rag_fusion import post_retrieval_rag_fusion # 导入RAG Fusion函数
# 1. 初始化工具:摘要模型、语义相似度模型
# 初始化摘要模型(轻量级,适合入门,中文可替换为uer/bart-base-chinese-summarization)
summarizer = pipeline(
"summarization",
model="sshleifer/distilbart-cnn-6-6",
tokenizer="sshleifer/distilbart-cnn-6-6",
device=0 if torch.cuda.is_available() else -1 # 有GPU用GPU,无GPU用CPU
)
# 初始化语义相似度模型(与之前的向量模型一致,保证一致性)
similarity_model = SentenceTransformer("all-MiniLM-L6-v2")
# 2. 语义过滤压缩:过滤与查询不相关的句子
def semantic_filter(compressed_text, query, threshold=0.3):
"""
语义过滤压缩函数
:param compressed_text: 摘要压缩后的文本
:param query: 重写后的用户查询
:param threshold: 相似度阈值(低于阈值的句子将被过滤)
:return: 过滤后的文本
"""
# 将查询和压缩文本转换为向量
query_embedding = similarity_model.encode(query, convert_to_tensor=True)
# 分割句子
sentences = compressed_text.split(". ")
# 过滤相似度低于阈值的句子
filtered_sentences = []
for sentence in sentences:
if sentence.strip() == "":
continue
sentence_embedding = similarity_model.encode(sentence, convert_to_tensor=True)
# 计算余弦相似度
similarity = util.cos_sim(query_embedding, sentence_embedding).item()
if similarity >= threshold:
filtered_sentences.append(sentence)
# 拼接过滤后的句子
return ". ".join(filtered_sentences) + "." if filtered_sentences else compressed_text
# 3. 摘要压缩:将长文本压缩为短摘要
def summary_compression(text, max_length=100, min_length=30):
"""
摘要压缩函数
:param text: 原始检索结果文本
:param max_length: 摘要最大长度(token数)
:param min_length: 摘要最小长度(token数)
:return: 压缩后的摘要
"""
# 生成摘要
summary = summarizer(
text,
max_length=max_length,
min_length=min_length,
do_sample=False # 不采样,保证摘要的准确性
)[0]["summary_text"]
return summary
# 4. 完整的上下文压缩流程(摘要压缩+语义过滤压缩)
def context_compression(fusion_results, query, max_summary_length=100):
"""
上下文压缩流水线
:param fusion_results: RAG Fusion后的检索结果
:param query: 重写后的用户查询
:param max_summary_length: 摘要最大长度
:return: 压缩后的上下文列表
"""
compressed_contexts = []
for result in fusion_results:
# 1. 摘要压缩
summary = summary_compression(result["document"], max_length=max_summary_length)
# 2. 语义过滤压缩
filtered_summary = semantic_filter(summary, query)
# 3. 保存压缩后的结果(保留元数据和分数)
compressed_contexts.append({
"compressed_context": filtered_summary,
"score": result["score"],
"metadata": result["metadata"],
"source": result["source"]
})
return compressed_contexts
# 5. 完整的RAG流程(预检索+后检索+上下文压缩)
def complete_rag_pipeline(user_query, top_n=3):
"""
完整的RAG流水线
:param user_query: 原始用户查询
:param top_n: 最终筛选的结果数量
:return: 压缩后的上下文、原始融合结果
"""
# 1. 后检索:RAG Fusion
fusion_results = post_retrieval_rag_fusion(user_query, top_n=top_n)
# 2. 上下文压缩
# 简化:使用用户查询作为过滤依据(实际场景可使用重写后的查询)
compressed_contexts = context_compression(fusion_results, user_query)
return compressed_contexts, fusion_results
# 6. 测试上下文压缩
if __name__ == "__main__":
# 测试查询
user_query = "What are the key strategies of pre-retrieval and post-retrieval in RAG?"
# 执行完整RAG流水线
compressed_contexts, fusion_results = complete_rag_pipeline(user_query, top_n=3)
# 输出结果对比
print(f"原始查询:{user_query}")
print("\n=== 原始RAG Fusion结果 ===")
for i, result in enumerate(fusion_results, 1):
print(f"\n结果 {i}(长度:{len(result['document'])} 字符):")
print(f"文档内容:{result['document']}")
print("\n=== 上下文压缩后结果 ===")
for i, context in enumerate(compressed_contexts, 1):
print(f"\n结果 {i}(长度:{len(context['compressed_context'])} 字符):")
print(f"加权分数:{context['score']:.4f}")
print(f"压缩后上下文:{context['compressed_context']}")
# 模拟LLM生成(简单示例)
print("\n=== 模拟LLM生成回复 ===")
# 拼接压缩后的上下文
context_text = "\n".join([ctx["compressed_context"] for ctx in compressed_contexts])
llm_prompt = f"Based on the following context, answer the user's question: {user_query}\nContext: {context_text}\nAnswer:"
print(f"LLM输入提示词:{llm_prompt}")
# 此处可替换为实际LLM调用(如OpenAI API、Llama等)
print(f"LLM生成回复:Pre-retrieval optimization in RAG includes index optimization and query optimization. Index optimization involves choosing the right index type, optimizing document chunking, and quantizing the index. Query optimization includes query rewriting, expansion, and filtering. Post-retrieval optimization includes RAG Fusion, which combines multiple retrieval results, and context compression, which removes redundant information to improve generation quality.")代码说明:该实例实现了完整的上下文压缩流水线,先通过摘要模型将长文本压缩为短摘要,再通过语义过滤去除与查询无关的内容,最终得到简洁、聚焦的上下文。用户可根据实际场景,调整摘要长度、相似度阈值,适配不同的LLM上下文长度需求。
三、本章练习题及其答案
为帮助读者巩固本章知识点,结合预检索、后检索的核心内容,设计选择题、填空题、简答题、实操题,覆盖核心概念、优化策略、代码实践,适合教学练习和自我检测。
3.1 选择题(每题5分,共25分)
- 以下哪项不属于预检索阶段的索引优化策略?( )
A. 文档分块优化
B. 查询重写
C. 索引量化
D. 混合索引选择
- RAG Fusion的核心作用是?( )
A. 优化索引结构,提升检索速度
B. 融合多轮检索结果,提升检索相关性
C. 压缩上下文,减轻LLM负担
D. 重写用户查询,提升匹配度
- 以下哪种文档分块方式最能保证语义完整性?( )
A. 固定长度分块
B. 语义分块
C. 随机分块
D. 无分块(直接使用原始文档)
- 上下文压缩的核心目标不包括?( )
A. 去除冗余信息
B. 精简文本长度
C. 提升检索速度
D. 减轻LLM输入负担
- 以下哪种检索方式适合语义关联较强的场景?( )
A. 全文检索索引
B. 向量索引
C. 倒排索引
D. 关键词索引
3.2 填空题(每空3分,共30分)
-
RAG的核心逻辑是"________ + ",预检索的核心目标是提升检索的________和。
-
预检索的两大核心优化方向是________和________。
-
RAG Fusion的核心流程分为________、________、________三步。
-
上下文压缩的常用方法有________、________、语义过滤压缩。
3.3 简答题(每题10分,共30分)
-
简述预检索中"查询优化"的核心策略及其作用。
-
简述RAG Fusion与上下文压缩的区别与联系。
-
为什么要进行文档分块优化?常用的文档分块方法有哪些?
3.4 实操题(15分)
基于本章提供的代码,完成以下操作:
-
修改预检索的查询重写规则,添加3条新的RAG相关查询重写规则(如"rag检索优化"重写为"RAG预检索和后检索的检索优化方法")。
-
修改RAG Fusion的权重分配(向量检索权重设为0.7,全文检索权重设为0.3),运行代码,观察融合结果的变化。
-
修改上下文压缩的摘要最大长度(设为150 token),运行完整RAG流水线,对比压缩前后的文本长度和核心信息保留情况,简要记录实验结论(不少于50字)。
实操题要求说明
-
所有修改需基于本章提供的对应代码(查询优化代码、RAG Fusion代码、上下文压缩代码),不得修改代码核心逻辑,仅调整指定参数和规则;
-
运行修改后的代码,需保留运行日志(含原始查询、各步骤输出结果),作为实操验证依据;
-
实操题需提交修改后的完整代码片段(仅修改部分)、运行日志截图(或文本日志)、第3步的实验结论,视为完成。
实操题提示
第1步:查询重写规则添加可参考原有规则格式,新增规则需贴合RAG核心知识点(如"rag上下文压缩""rag向量索引优化""rag全文检索使用"等),确保规则匹配逻辑一致;
第2步:修改RAG Fusion权重需找到`rag_fusion`函数的`vector_weight`和`fulltext_weight`参数,直接调整数值即可,运行后重点观察加权分数变化和结果排序差异;
第3步:修改摘要最大长度需调整`context_compression`函数中`max_summary_length`参数,对比压缩前后的文本字符数,重点验证核心信息(如优化策略、方法)是否保留。
3.5 练习题答案
3.5.1 选择题答案(每题5分,共25分)
-
答案:B(解析:查询重写属于查询优化,不属于索引优化策略,A、C、D均为索引优化的核心内容)
-
答案:B(解析:A是预检索中索引优化的作用,C是上下文压缩的作用,D是查询优化的作用,RAG Fusion核心是融合多轮检索结果提升相关性)
-
答案:B(解析:语义分块基于文档语义结构分割,优先保证每个块的语义完整,A易破坏语义,C无意义,D会导致冗余)
-
答案:C(解析:上下文压缩的核心目标是去除冗余、精简长度、减轻LLM负担,提升检索速度是预检索索引优化的目标)
-
答案:B(解析:向量索引基于语义向量匹配,适合语义关联较强的场景,A、C、D均以关键词匹配为主)
3.5.2 填空题答案(每空3分,共30分)
-
RAG的核心逻辑是"检索 + 生成 ",预检索的核心目标是提升检索的效率 和相关性。
-
预检索的两大核心优化方向是优化索引 和查询优化。
-
RAG Fusion的核心流程分为多轮检索 、结果融合 、结果筛选三步。
-
上下文压缩的常用方法有关键词提取压缩 、摘要压缩、语义过滤压缩。
3.5.3 简答题答案(每题10分,共30分)
- 简述预检索中"查询优化"的核心策略及其作用。
答案:核心策略包括4种:①查询重写(将模糊、口语化查询转换为规范、精准的查询,补充上下文);②查询扩展(添加同义词、相关关键词,扩大检索范围);③查询过滤(去除语气词、特殊字符,减少检索噪声);④向量查询优化(提升查询向量准确性,适配向量索引)。(6分)
作用:解决用户原始查询模糊、关键词不明确的问题,提升查询与索引的匹配度,减少漏检、误检,同时提升检索效率,为后续检索和生成环节奠定基础。(4分)
- 简述RAG Fusion与上下文压缩的区别与联系。
答案:
区别 : ①核心目标不同:RAGFusion聚焦"提升检索结果的相关性和完整性",解决单一检索方式的片面性;上下文压缩聚焦"去除冗余、精简文本",解决LLM上下文长度有限的问题。(4分)
②操作阶段不同:RAG
Fusion是后检索的第一步,直接对检索结果进行融合排序;上下文压缩是后检索的第二步,对融合后的结果进行精简处理。(3分)
联系 :二者均属于后检索优化环节,相辅相成;RAGFusion为上下文压缩提供高质量的检索结果,上下文压缩对融合后的结果进行精简,共同提升LLM生成内容的准确性和简洁性。(3分)
- 为什么要进行文档分块优化?常用的文档分块方法有哪些?
答案:
原因 :原始长文档直接建立索引会导致检索结果冗余(包含无关内容),分块过小会导致语义不完整、检索相关性下降;分块优化可平衡语义完整性和检索效率,让索引更精准、检索速度更快。(4分)
常用方法:①固定长度分块(按固定字符/token数分割,简单易实现,适合纯文本);②语义分块(基于段落、句子等语义结构分割,保证语义完整,适合复杂文档);③重叠分块(在固定或语义分块基础上,保留相邻块重叠内容,避免语义断裂)。(6分)
3.5.4 实操题参考答案(15分)
第1步:新增查询重写规则(5分)
python
# 修改query_rewrite函数中的rewrite_rules,新增3条规则(新增内容如下)
rewrite_rules = {
"rag optimize": "RAG pre-retrieval and post-retrieval optimization methods",
"pre-retrieval": "pre-retrieval optimization strategies in RAG, including index optimization and query optimization",
"post-retrieval": "post-retrieval optimization strategies in RAG, including RAG Fusion and context compression",
"rag retrieval": "RAG retrieval stage optimization methods",
# 新增3条规则
"rag context compression": "context compression strategies in RAG post-retrieval, including summary compression and semantic filtering",
"rag vector index optimization": "vector index optimization in RAG pre-retrieval, including quantization and chunking",
"rag full-text retrieval": "full-text retrieval application in RAG post-retrieval fusion"
}第2步:修改RAG Fusion权重(5分)
python
# 修改rag_fusion函数的参数默认值,或调用函数时指定权重
# 方式1:修改函数默认值
def rag_fusion(chroma_dict, es_dict, vector_weight=0.7, fulltext_weight=0.3, top_n=3):
# 函数内容不变,仅调整vector_weight和fulltext_weight的默认值
# 方式2:调用函数时指定权重(不修改函数本身)
fusion_results = rag_fusion(chroma_results, es_results, vector_weight=0.7, fulltext_weight=0.3, top_n=top_n)结果变化:向量检索权重提升后,融合结果中来自向量检索(chroma_vector)的结果加权分数会升高,排序更靠前;全文检索结果的影响降低,整体检索结果更侧重语义相关性。
第3步:修改摘要最大长度并验证(5分)
python
# 修改context_compression函数的max_summary_length参数
def context_compression(fusion_results, query, max_summary_length=150):
# 函数内容不变,仅调整max_summary_length默认值
# 运行完整RAG流水线后,对比结论示例:
# 压缩前单条结果平均长度约200-300字符,压缩后平均长度约140-150字符;
# 压缩后仍保留核心信息(如预检索的索引优化、后检索的RAG Fusion等),无关键信息丢失;
# 相比原100 token的压缩结果,150 token的摘要更完整,能保留更多优化细节,同时未出现明显冗余。验收标准
- 新增3条查询重写规则格式正确、贴合RAG知识点;
- RAG Fusion权重修改正确,运行日志能体现权重变化带来的结果差异;
- 摘要长度修改正确,实验结论符合实际运行结果,核心信息保留完整。
四、总结
本文围绕RAG的预检索与后检索优化展开,核心聚焦"提升检索效率与相关性""提升LLM生成质量"两大目标,系统讲解了预检索(索引优化、查询优化)和后检索(RAG Fusion、上下文压缩)的核心策略、原理及可运行代码实例,并通过练习题帮助读者巩固知识点。
后续可进一步深入学习高级优化策略(如动态索引更新、跨模态RAG优化、LLM辅助检索等),结合具体业务场景,持续提升RAG系统的性能和体验。
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!