地区表d_area

parent_id 父亲id 为 1 表示自己为省/自治区
type 1 为省 type 2 为市
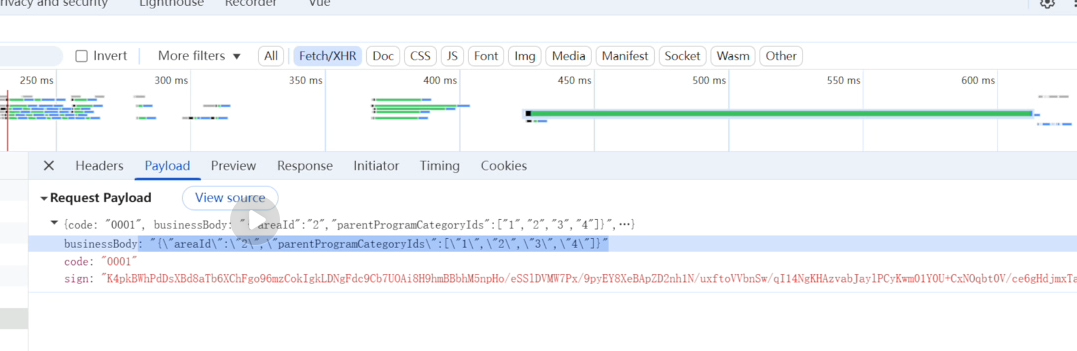
普通的 HTTP 请求中,容易被中间人篡改(比如把 areaId 从 2 改成 99)。为了防止这种情况,系统在 Gateway(API 网关) 层做了一道安全拦截
前端使用一套约定好的算法(通常是 RSA 非对称加密或 HMAC 算法)和密钥,对 businessBody 的内容计算出一个独一无二的"签名串"。
前端在请求中带上 code: "0001"。这相当于告诉服务器:"我是编号为 0001 的客户端(PC 网站)"。
请求并没有直接到达后端的业务服务器,而是先被 Gateway(网关) 拦截。
网关看到 code: "0001",就会去数据库里查找 0001 对应的公钥。
网关使用查到的公钥,对传过来的 sign 和 businessBody 进行验签。
结果判定:如果验签通过,说明数据在传输过程中绝对没有被篡改过,且确实是合法前端发来的。网关才会放行,把请求转发给后面的业务微服务;如果失败,网关直接返回错误,保护后端。
手机号 邮箱登录分表:
为了保证不全查询用户通过手机号,使得手机号成为mobile表的分片键 查询在1库0mobile表 查询到用户id 再通过id 找用户信息
全路由查询:
手机号不是分片键【通过id将数据分布在数据库中】没有分片键 定位不到哪个库 哪个表 全部库 全部表查询 mobile 通过手机号分片键 查询到某个库某个表找到对应用户id 查到用户信息
d_ticket_user_1
购票人 信息
d_program_0
节目表
sql
-- auto-generated definition
create table d_program_0
(
id bigint not null comment '主键id'
primary key,
program_group_id bigint not null comment '节目分组id',
prime tinyint(1) default 1 not null comment '当属于同一个节目分组时 是否为主要节目 0:否 1:是',
area_id bigint not null comment '所在区域id',
program_category_id bigint not null comment '节目类型表id',
parent_program_category_id bigint not null comment '父节目类型表id',
title varchar(512) not null comment '标题',
actor varchar(256) null comment '艺人',
place varchar(100) null comment '地点',
item_picture text null comment '项目图片',
pre_sell tinyint(1) default 0 not null comment '预售 1:是 0:否',
pre_sell_instruction varchar(256) null comment '预售说明',
important_notice varchar(100) null comment '重要通知',
detail text not null comment '项目详情',
per_order_limit_purchase_count int default 6 null comment '每笔订单最多购买数量',
per_account_limit_purchase_count int default 6 null comment '每个账号最多购买数量',
refund_ticket_rule varchar(512) null comment '退票/换票规则',
delivery_instruction varchar(512) null comment '配送信息说明',
entry_rule varchar(512) null comment '入场规则',
child_purchase varchar(512) null comment '儿童购票',
invoice_specification varchar(512) null comment '发票说明',
real_ticket_purchase_rule text null comment '实名购票规则',
abnormal_order_description text null comment '异常排单说明',
kind_reminder text null comment '温馨提示',
performance_duration varchar(100) null comment '演出时长',
entry_time varchar(512) null comment '入场时间',
min_performance_count int null comment '最低演出曲目',
main_actor varchar(100) null comment '主要演员',
min_performance_duration varchar(100) null comment '最低演出时长',
prohibited_item text null comment '禁止携带物品',
deposit_specification varchar(512) null comment '寄存说明',
total_count bigint null comment '大麦网初始开售时全场可售门票总张数',
permit_refund tinyint(1) default 0 not null comment '是否允许退款 0:不支持退 1:条件退 2:全部退',
refund_explain varchar(512) null comment '退款说明',
rel_name_ticket_entrance tinyint(1) default 0 not null comment '实名制购票和入场 1:是 0:否',
rel_name_ticket_entrance_explain varchar(512) null comment '实名制购票和入场说明',
permit_choose_seat tinyint(1) default 0 not null comment '是否允许选座 1:允许选座 0:不允许选座',
choose_seat_explain varchar(512) null comment '选座说明',
electronic_delivery_ticket tinyint(1) default 1 not null comment '电子票/快递票 0:都没有1:电子票 2:快递票',
electronic_delivery_ticket_explain varchar(512) null comment '电子票说明',
electronic_invoice tinyint(1) default 1 not null comment '电子发票 1:是 0:不是',
electronic_invoice_explain varchar(512) null comment '电子发票说明',
high_heat tinyint(1) default 0 not null comment '高热度节目 0:否 1:是',
program_status tinyint(1) default 1 not null comment '节目状态 1:上架 0:下架',
issue_time datetime null comment '上架发行时间',
create_time datetime not null comment '创建时间',
edit_time datetime not null comment '编辑时间',
status tinyint(1) default 1 not null comment '1:正常 0:删除'
)
comment '节目表';
create index issue_time_idx
on d_program_0 (issue_time);
create index program_group_id_idx
on d_program_0 (program_group_id);节目目录表 program_category_id :

网站
parent_id: 节目的种类也有 父类型
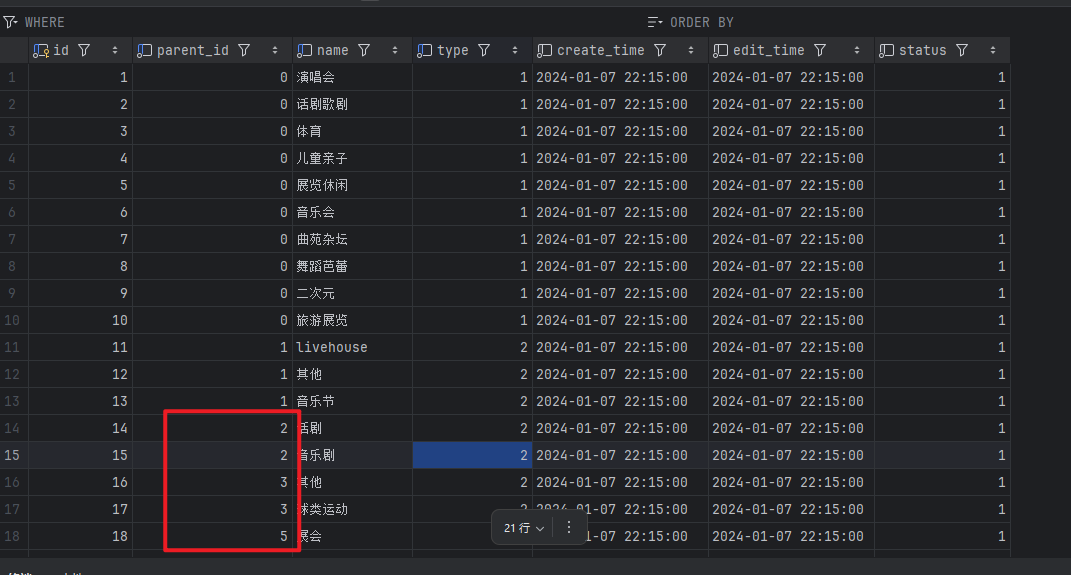
音乐节 livehouse 的父节目种类 为 演唱会
音乐剧父节目种类为话剧歌剧
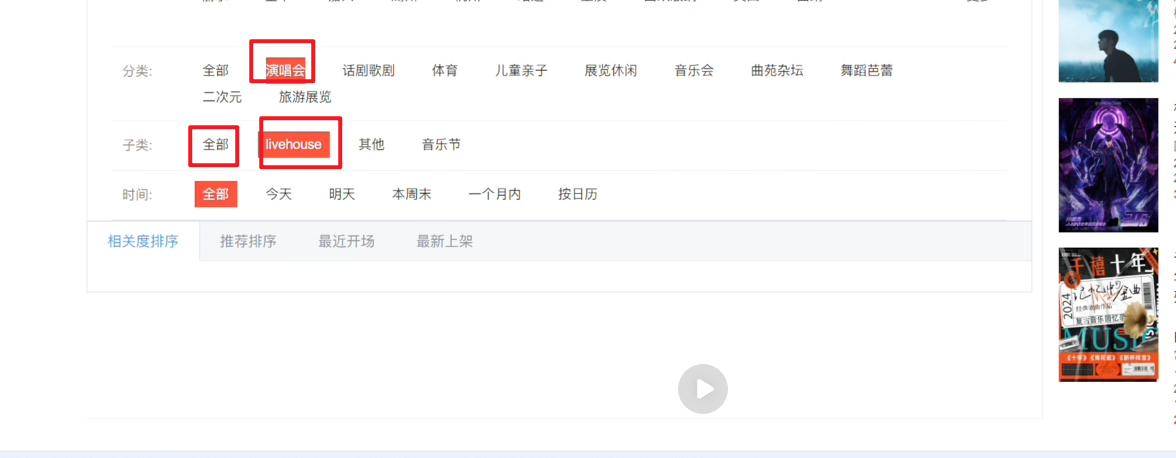
网站体现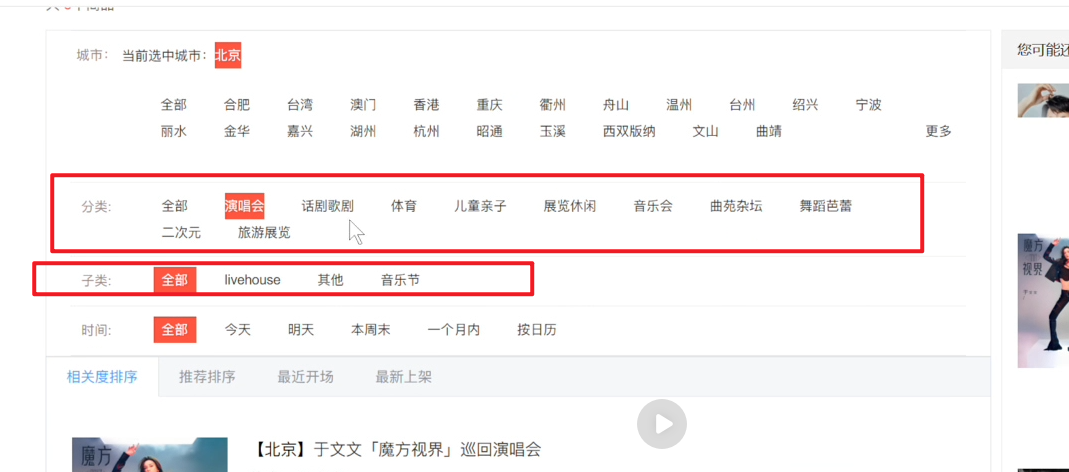
查类型下节目
查全部则父类型id 负责 子类型id
sql
per_order_limit_purchase_count int default 6 null comment '每笔订单最多购买数量',
per_account_limit_purchase_count int default 6 null comment '每个账号最多购买数量',program_group_id 表 相同明星 不同城市 节目记录为同一组

program_group_id: 相同明星的演唱会为同一组
为什么要用数组json存储相同明星不同场馆/时间
本质: json存储为了快
传统设计: 需要先查 program_group 表,再 JOIN 关联查询 program 表获取所有场次,甚至还要关联 area 表获取城市名字(北京、深圳等)。
JSON 存储: 只需要单表查询 program_group 这一行数据,直接把对应的 JSON 丢给前端,前端就能立刻渲染出"北京 | 沈阳 | 长春 | 哈尔滨 | 深圳"的城市切换 Tab 栏。减少了数据库的连表计算和 I/O 消耗,这在应对高并发(比如演唱会开票瞬间或大流量浏览)时极其重要。
d_program_show_time_0表
为了es 特意拆开演出时间存储
es可能通过天/星期排序?
sql
show_time datetime not null comment '演出时间',
show_day_time datetime null comment '演出时间(精确到天)',
show_week_time varchar(64) not null comment '演出时间所在的星期',es 直接通过 show_day_time 查询
mysql 查询使用函数会失效
sql
-- 查找所有在周五的演出
SELECT * FROM program
WHERE DATE_FORMAT(show_time, '%w') = 5;增加show_week_time 查询周五的演出
sql
-- 查找所有在周五的演出
SELECT * FROM program
WHERE show_week_time = '星期五';为什么节目演出时间和节目信息拆开? TODO
节目表修改可能? 节目演出时间可能修改 但是 节目的其他信息很难修改;
d_program_0
d_program_show_time_0
分库分表数据太庞大了 如果修改节目演出时间 节目表中**二级索引节目演出时间d_program_show_time **索引也要改变
"频繁更新的字段,绝对不要建立索引!"
聚集索引
id对应着记录
非聚集索引
二级索引对应着id
通过二级索引查询 第一步查询id 第二步回表 通过聚集索引查询;
d_ticket_category_0 票档表
sql
-- auto-generated definition
create table d_ticket_category_0
(
id bigint not null comment '主键id'
primary key,
program_id bigint not null comment '节目表id',
introduce varchar(256) not null comment '介绍',
price decimal not null comment '价格',
total_number bigint not null comment '总数量',
remain_number bigint not null comment '剩余数量',
create_time datetime not null comment '创建时间',
edit_time datetime not null comment '编辑时间',
status tinyint(1) default 1 not null comment '1:正常 0:删除'
)
comment '节目票档表';不同演唱会不同票档【价格 票名】 属于同一个id
total_number remain_number 总共票数量 剩余票数量; 保证在普通所 VIP票加锁 而不是节目加锁
d_seat_1 座位票
sell_status 座位售卖状态: 1未售卖 2锁定 3已售卖
sql
create table d_seat_1
(
id bigint auto_increment comment '主键id'
primary key,
program_id bigint not null comment '节目表id',
ticket_category_id bigint not null comment '节目票档id',
row_code int not null comment '排号',
col_code int not null comment '列号',
seat_type int not null comment '座位类型 详见seatType枚举',
price decimal not null comment '座位价格',
sell_status int default 1 not null comment '1未售卖 2锁定 3已售卖',
create_time datetime not null comment '创建时间',
edit_time datetime not null comment '编辑时间',
status tinyint(1) default 1 not null comment '1:正常 0:删除'
)
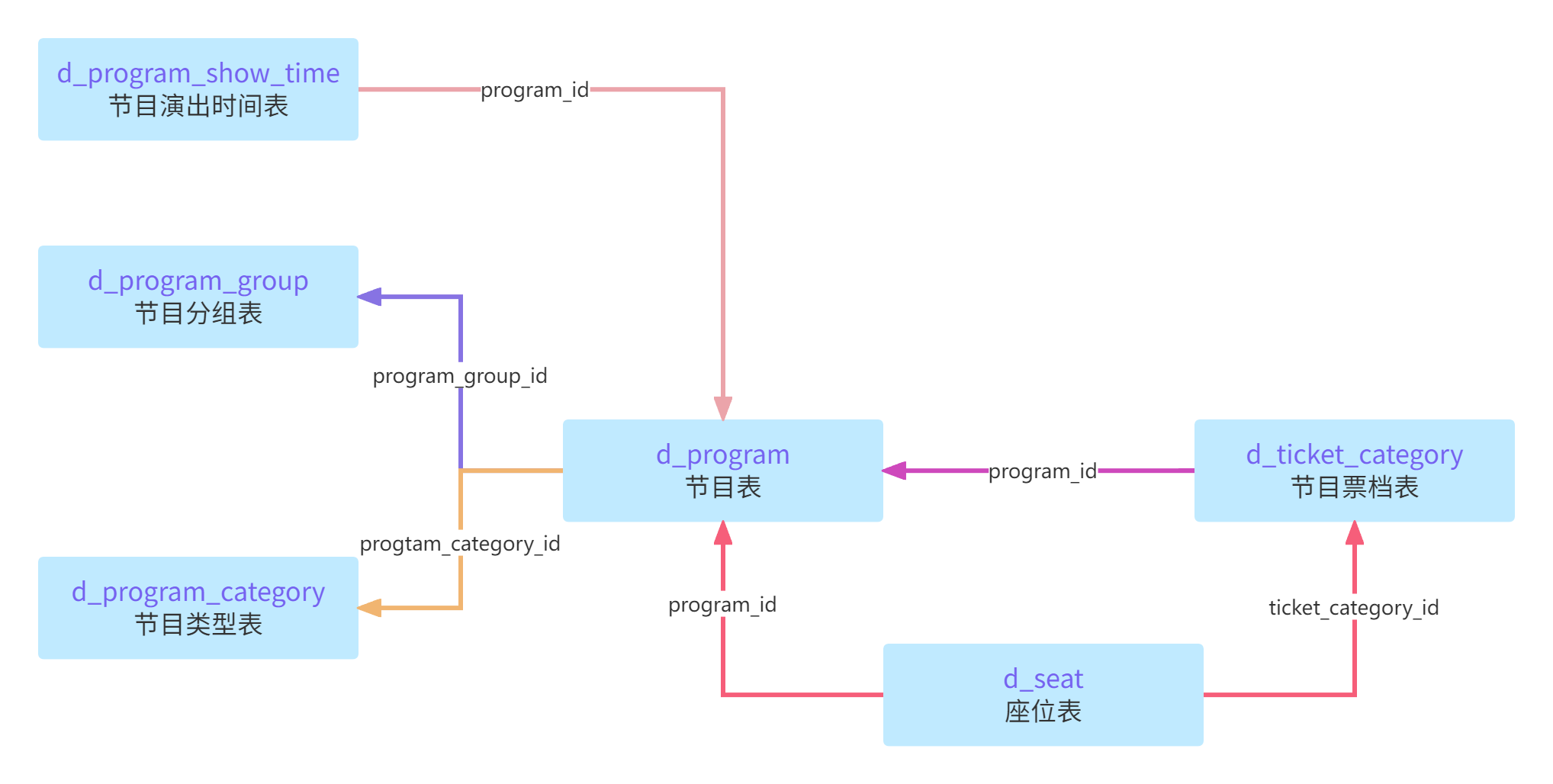
comment '座位表';表关系结构
订单表 d_order_0 记录订单基本信息
identifier_id : comment '记录id',
系统引入了一个"取餐小票(identifier_id)"机制。当用户请求发来 先生成一个全局唯一的 identifier_id
第一步 Redis 扣库存并记录 ID(防重发/幂等性)
请求带着 identifier_id 来到 Redis。Redis 不仅要执行"库存 -1",还要把这个 identifier_id 存下来
第二步 异步通知订单服务生成订单
Redis 扣减成功后,系统会把这个 identifier_id 和用户信息打包,丢到消息队列(MQ)里。订单服务慢慢从队列里取数据,去 MySQL 生成真正的订单。
关键点: 生成的 MySQL 订单表中,必须有一个字段叫 identifier_id(也就是你看到的那个字段),并且把刚才那个 88273619283 存进去。
第三步 对账与异常恢复(最终一致性)
如果发生了服务器断电(场景 B),后台会有一个"对账定时任务"在跑:
它拿着 Redis 里存下来的那些 identifier_id,去 MySQL 订单表里找。
如果在 Redis 里找到了 ID=88273619283,但在 MySQL 订单表里没找到(说明订单没生成成功)。
系统就可以拿着这个 identifier_id 进行补偿:要么重新触发生成订单,要么去 Redis 里把库存"+1"加回来,把票释放给其他用户。
**reconciliation_status:**对账状态?
d_order_ticket_user_0 购票人订单
你 你女朋友 两个购票人 生成订单;每个购票人订单都对应着一个基本订单的基本信息 ;购票人订单记录座位号
支付表 d_pay_bill_0
pay_scene: 本地/测试/上线 哪个环境
pay_channel: 微信/支付宝