开篇
周末时间,继续来学习下安全领域的论文,今天要介绍的这篇名为《一种基于关联挖掘的智能PE恶意软件检测系统》,2008年发布,属于上古时期的产物了。
之所以介绍这篇论文,只是因为其思路极其简单,一句话就能说明白。就是提取PE文件中导入的外部dll中的API序列,使用OOA(Objective-Oriented Association,面向目标的关联挖掘)算法,生成恶意样本的API频繁项集,用来检测未知二进制样本。而且这套检测系统的研究成果也被被集成到那个时期的金山毒霸的扫描工具中。
所以,这篇文章重点不在于介绍检测思路,而在于介绍OOA关联挖掘这个算法,看看它在恶意软件检测领域可以被如何使用。
好了,接下来我们就来一起学习下吧。
OOA算法在恶意软件检测中的应用
我们先从OOA算法开始,把这个算法讲清楚,然后再理解论文的检测思路就易如反掌了。
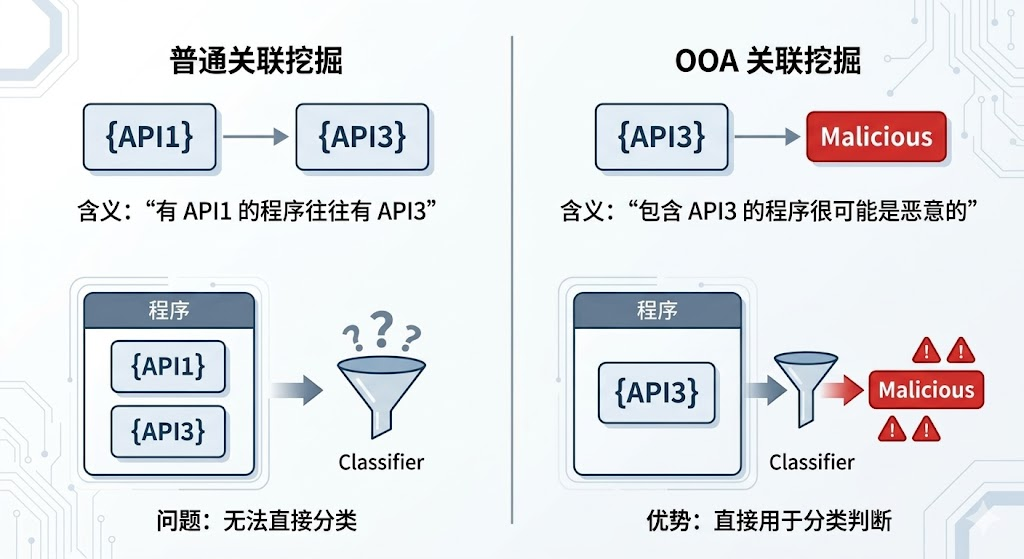
对于关联挖掘,首先想到的就是那个最经典的场景:买了啤酒的人往往也会买尿布。也就是说,关联挖掘是为了在所有项中找到某些项之间的共同出现规律。
而在这篇论文的恶意软件检测场景中,"购物篮"变成了程序调用的 API 集合,"买了什么"变成了"调用了什么 API"。
举个例子,假设我们有 8 个程序样本:

肉眼扫一遍就能发现:API3 出现的地方全是恶意程序。这就是关联挖掘要自动发现的规律。
普通关联挖掘是"无目标"的------它只会找所有项之间的共现规律,比如"调用了 API1 的程序往往也会调用 API5"。这类规则对区分二进制样本的恶意和正常没有直接帮助。
但OOA 在挖掘之前就锁定了一个目标 (Objective):找出"哪些 API 组合和恶意标签强相关"。这让算法从一开始就朝着分类的方向搜索。
两个核心指标:支持度和置信度
OOA 用两个数字来衡量项之间的每个组合的质量:
- 支持度(Support):support = 这组 API 出现在恶意样本中的次数 ÷ 全部样本总数
- 置信度(Confidence):confidence = 这组 API 出现在恶意样本中的次数 ÷ 这组 API 出现在所有样本中的次数
用 {API3} 举例:API3 出现在样本 2、4、5 中,全部是恶意的,共 3 个。全部样本共 8 个。
所以 support = 3/8 = 37.5%(在全体数据中有一定的普遍性),confidence = 3/3 = 100%(包含 API3 的程序中,100% 是恶意的)。
支持度衡量的是"这个规律有多常见",置信度衡量的是"这个规律有多准确"。一个好的检测规则需要两者都高------既常见(能覆盖足够多的病毒),又准确(不会误判正常程序)。
论文中设定了两个阈值:最小支持度 mos = 25%,最小置信度 moc = 65%。只有同时超过两个阈值的规则才会被保留。
三种 OOA 挖掘算法
OOA_Apriori:从小到大逐层搜索
Apriori 是最经典的关联挖掘算法,思路非常直观:从最小的单项集开始,逐层向上扩展,每一层都把不够"频繁"的组合淘汰掉。算法的核心依赖一个先验性质------如果一个集合不频繁,那么包含它的所有更大集合也不可能频繁。这叫做 Apriori 剪枝原理,也是算法效率的关键。
想象你在调查哪些食材组合会引起过敏。如果"花生"单独就不达标(出现次数太少),那么"花生 + 牛奶"、"花生 + 鸡蛋 + 牛奶"这些更大的组合你都不用再查了------因为它们的出现次数只可能更少,不可能更多。
下面我们用上面的示例数据(8 个样本、5 种 API),以目标 Obj1 = Malicious、mos = 25%(即至少出现 2 次)、moc = 65% 为阈值,完整走一遍 OOA_Apriori 的每一步。
第一轮:扫描单个 API(频繁 1-项集)
算法首先遍历整个数据集,统计每个 API 在恶意样本中出现的次数。注意,这里的"出现在恶意样本中"就是 OOA 的目标约束------普通 Apriori 会数所有样本,OOA 只数属于目标类别(恶意)的样本。
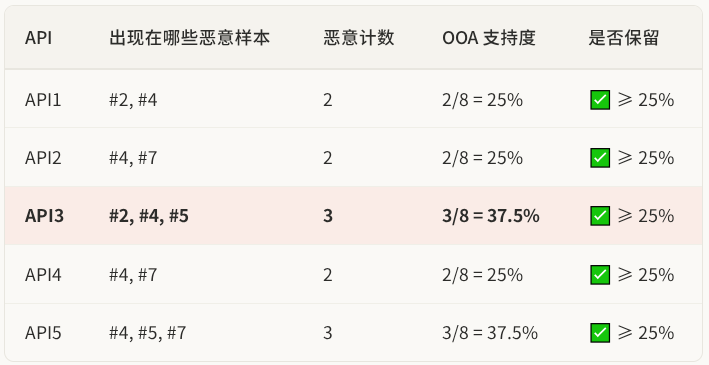
5 个 API 全部通过了最小支持度阈值,都成为频繁 1-项集。如果某个 API 在恶意样本中只出现了 1 次(支持度 12.5%),它就会在这一轮被淘汰,后续所有包含它的组合也不需要再检查------这就是 Apriori 剪枝在第一轮的体现。
第二轮:两两组合(频繁 2-项集)
把第一轮保留的 5 个频繁 API 两两配对,生成候选 2-项集。5 个元素的两两组合共有 C(5,2) = 10 对。然后再次扫描整个数据集 ,逐一统计每对 API 同时出现在恶意样本中的次数。
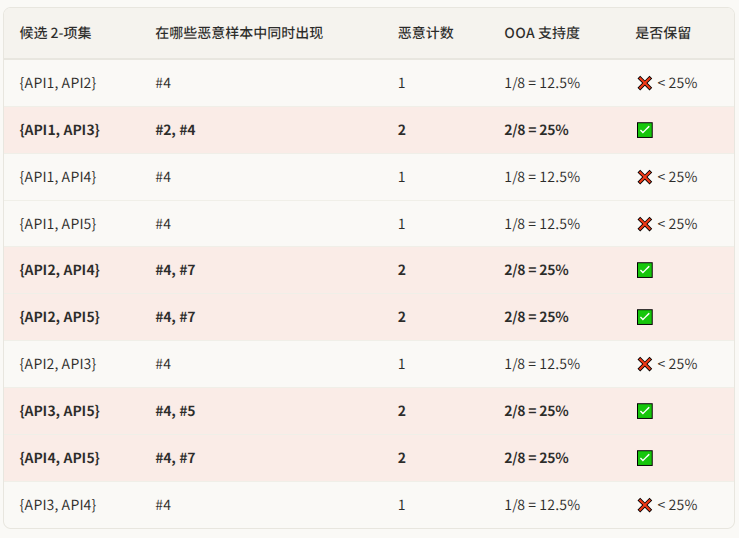
10 个候选对中,只有 5 个通过了支持度阈值。被淘汰的 5 对有一个共同特征:它们都只在样本 #4 中同时出现。样本 #4 是一个调用了全部 5 个 API 的"超级样本",很多组合只靠它一个撑着,自然不够频繁。
第二轮的关键启示:虽然 API1 单独看在恶意样本中出现了 2 次(通过了第一轮),但它和 API2、API4、API5 的组合都只出现了 1 次,全部被淘汰。这说明 API1 虽然在恶意程序中有一定存在感,但它和其他 API 的"协同出现"模式并不突出------它更像是一个通用 API,恶意和正常程序都在用。唯一保留的是 {API1, API3},因为 API3 本身就是一个强恶意指标。
第三轮:三三组合(频繁 3-项集)
现在要从 5 个频繁 2-项集中合并出候选 3-项集。合并规则是:两个 2-项集如果共享一个相同的 API,就可以合并。例如 {API2, API4} 和 {API2, API5} 共享 API2,合并为 {API2, API4, API5}。
但这里还有一步重要的Apriori 剪枝检查:合并出候选集后,要验证它的所有子集是否都是上一轮的频繁项集。如果有任何一个子集不在上一轮的结果中,这个候选集直接淘汰,不需要去数据库中验证。
以 {API2, API4, API5} 为例:它的三个 2-项子集分别是 {API2, API4}、{API2, API5} 和 {API4, API5},三个都在第二轮的频繁项集中,所以保留为候选集。
而像 {API1, API3, API5} 这样的组合,虽然 {API1, API3} 和 {API3, API5} 都是频繁的,但 {API1, API5} 在第二轮中被淘汰了(支持度只有 12.5%)。根据 Apriori 原理,{API1, API5} 不频繁意味着任何包含它的超集也不可能频繁,所以 {API1, API3, API5} 直接被剪掉,无需扫描数据验证 。

最终只有 {API2, API4, API5} 一个三元组通过了检查。
由于只剩一个频繁 3-项集,无法再合并出 4-项候选集,算法在此停止扩展。
第四轮:检查置信度,生成最终规则
前三轮找到的是所有"频繁"的 API 组合------它们在恶意样本中出现得足够多。但频繁不等于有用:一个 API 组合可能在恶意程序中出现了很多次,但在正常程序中也出现了同样多次,那它对区分两者毫无帮助。
置信度就是用来检验"区分能力"的:confidence = 该 API 组合在恶意样本中的出现次数 ÷ 该组合在所有样本中的出现次数。只有置信度超过 moc = 65% 的才保留。
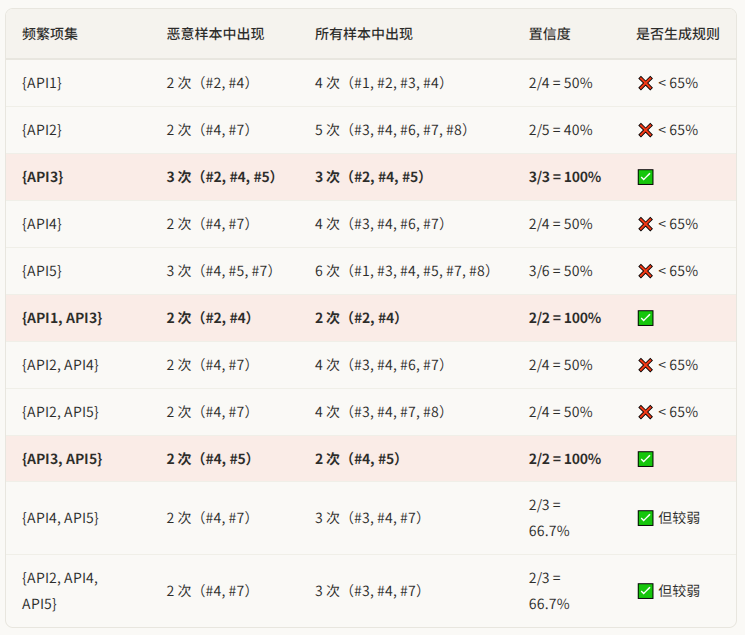
最终生成 5 条规则。其中最强的 3 条置信度高达 100%:
- 规则 1:{API3} → Malicious(支持度 37.5%,置信度 100%)
- 规则 2:{API1, API3} → Malicious(支持度 25%,置信度 100%)
- 规则 3:{API3, API5} → Malicious(支持度 25%,置信度 100%)
Apriori 的效率瓶颈:在上面的例子中只有 8 个样本和 5 种 API,算法要进行 3 轮扫描,检查 5 + 10 + 3 = 18 个候选项集。看起来不多,但在论文的真实数据中有 5,611 个样本和成百上千种 API,候选项集数量呈指数增长。每一轮都需要全量扫描数据集来计数,当支持度阈值较低时(意味着更多组合能通过筛选),计算量暴增。论文实验中,在最低支持度设置下,Apriori 直接跑不完。
OOA_FP-Growth:用树结构压缩数据
Apriori 最大的问题是"反复扫描"------每扩展一层就要把整个数据集重新过一遍。当数据量大、支持度阈值低的时候,这种做法就像每次查字典都要从第一页翻起,效率极低。
FP-Growth(Frequent Pattern Growth)换了一种思路:把数据集本身压缩成一棵树,然后在树上直接挖掘频繁模式。整个过程只需要扫描原始数据两次------第一次统计每个项的频率,第二次把每条记录插入树中。之后所有的频繁模式提取都在内存中的树上完成,不再碰原始数据。
OOA 版本在此基础上增加了一个前置步骤:在建树之前先按目标类别筛选数据。既然我们的目标是找"与恶意相关的 API 组合",那就只把恶意样本拿来建树,正常样本直接忽略。这是"面向目标"(Objective-Oriented)在 FP-Growth 中的具体体现。
OOA_Fast_FP-Growth:进一步优化的树结构
标准 FP-Growth 在支持度很低时会递归生成大量"条件子树",消耗大量内存和时间。Fast_FP-Growth 对树结构做了两个优化:
第一,使用有向路径,去掉了从根到叶子的回溯指针,减少了内存占用。
第二,节点存储的是 API 的频率排序编号而非 API 名称,加速了查找操作。
算法对比
在论文的实际实验中(5,611 个样本),每个实验的支持度阈值和置信度阈值不同,三种算法的效率对比非常明显:

Fast_FP-Growth 的速度几乎是 FP-Growth 的 2 倍,是 Apriori 的 6 倍以上。在支持度阈值较低时(实验 3、4),Apriori 根本无法完成计算,而 Fast_FP-Growth 仍然可以在合理时间内给出结果。
真实规则长什么样
论文在真实数据上挖掘出了这样一条规则:
bash
{OpenProcess, CopyFileA, CloseHandle, GetVersionExA, GetModuleFileNameA, WriteFile}
→ Malicious (support = 29.7%, confidence = 99.3%)翻译一下就是,如果一个程序同时执行了"打开别的进程 → 复制文件 → 获取系统版本信息 → 获取自身路径 → 写入文件 → 关闭句柄"这组操作,那么它有 99.3% 的概率是恶意软件。这组操作出现在 1,665 个恶意样本中,仅出现在 11 个正常样本中。
这就是一个典型的木马下载器行为特征------它先探查系统环境,然后把恶意文件复制到目标位置。单独看每个 API 都是正常操作,但组合在一起就构成了强烈的恶意信号。这正是关联挖掘的价值所在。
如何用规则做分类
挖出规则后,论文使用 CBA(Classification Based on Association)分类器来判断新程序。过程很直观:
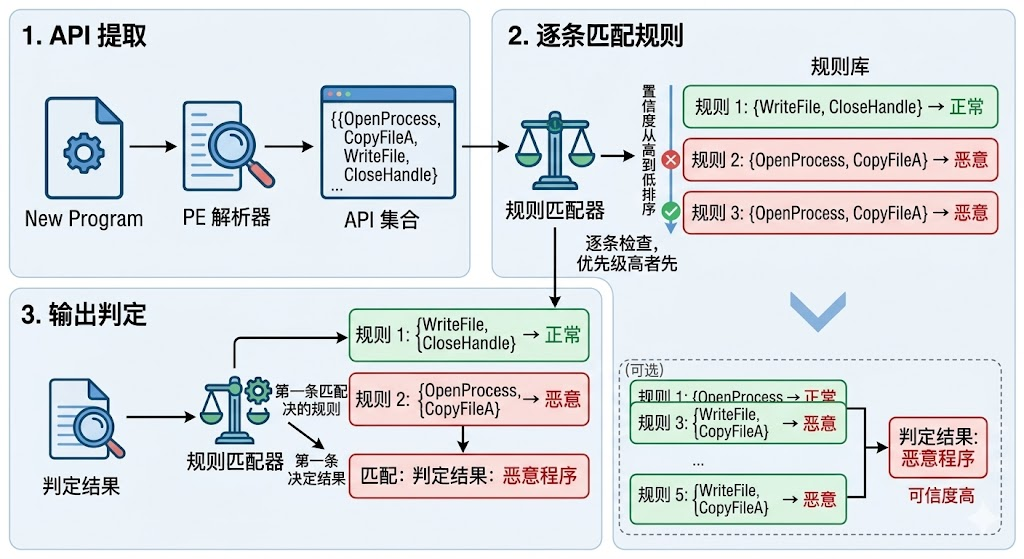
需要注意的局限
数据比例敏感。OOA 支持度的分母是全部样本数。如果大量增加正常样本,所有恶意规则的支持度会被"稀释",可能导致有价值的规则被错误剪掉。在实际使用中需要注意数据集的黑白样本比例。
不考虑 API 调用顺序。OOA 把每个程序的 API 调用当作无序集合处理,只关心"调用了哪些",不关心"按什么顺序调用"。然而调用顺序可能包含重要的行为信息。论文作者在未来工作中也提到了这个改进方向。
无法检测动态加载的 API。如果恶意程序通过 LoadLibrary + GetProcAddress 在运行时动态获取 API 地址,这些调用不会出现在静态分析的导入表中,从而逃过检测。
规则需要随数据更新。随着新型恶意软件的出现,旧规则可能不再有效,需要定期用新数据重新挖掘和调参。
总结
OOA 关联挖掘的核心思想可以概括为一句话:从大量已知样本中,自动发现哪些 API 调用组合是恶意程序的"行为指纹"。
它比传统特征码方法更灵活(病毒变形后 API 调用模式不变),比黑箱机器学习模型更可解释(每条规则都能翻译成具体的行为含义),在论文的实验中也比朴素贝叶斯、SVM、决策树等方法取得了更高的检测率(97.19%)和准确率(93.07%)。
这篇 2008 年的论文虽然已有年头,但它提出的"用关联规则做恶意软件分类"的思路至今仍有影响力,后续很多工作都在此基础上引入了 API 调用序列、依赖关系、动态行为等更丰富的特征。