ElasticSearch安装及介绍
- es详解
- 安装
- 一、安装前提
- 二、服务器环境准备
-
- [2.1 检查系统环境](#2.1 检查系统环境)
- [2.2 创建专用用户(重要)](#2.2 创建专用用户(重要))
- 三、安装方式选择
- 四、方式一:Docker安装(推荐快速上手)
-
- [4.1 安装Docker](#4.1 安装Docker)
- [4.2 安装Elasticsearch 7.6.2](#4.2 安装Elasticsearch 7.6.2)
- [4.3 安装Kibana 7.6.2](#4.3 安装Kibana 7.6.2)
- [4.4 安装IK分词器(Docker方式)](#4.4 安装IK分词器(Docker方式))
- 五、方式二:压缩包安装(生产环境推荐)
-
- 下载安装包
- [5.2 修改配置文件](#5.2 修改配置文件)
- [5.3 修改系统配置](#5.3 修改系统配置)
- [5.4 修改权限并启动](#5.4 修改权限并启动)
- [5.5 安装IK分词器](#5.5 安装IK分词器)
- [5.6 安装Kibana](#5.6 安装Kibana)
- 六、验证安装
-
- [6.1 验证Elasticsearch](#6.1 验证Elasticsearch)
- [6.2 验证IK分词器](#6.2 验证IK分词器)
- [6.3 验证Kibana](#6.3 验证Kibana)
- [6.4 防火墙配置](#6.4 防火墙配置)
- [七、Spring Boot配置](#七、Spring Boot配置)
-
- [7.1 application.yml配置](#7.1 application.yml配置)
- 八、常见问题
- 九、服务管理脚本
- 中文分词器的原理
- es基础概念
- 索引语法
- 参考链接
es详解
简介
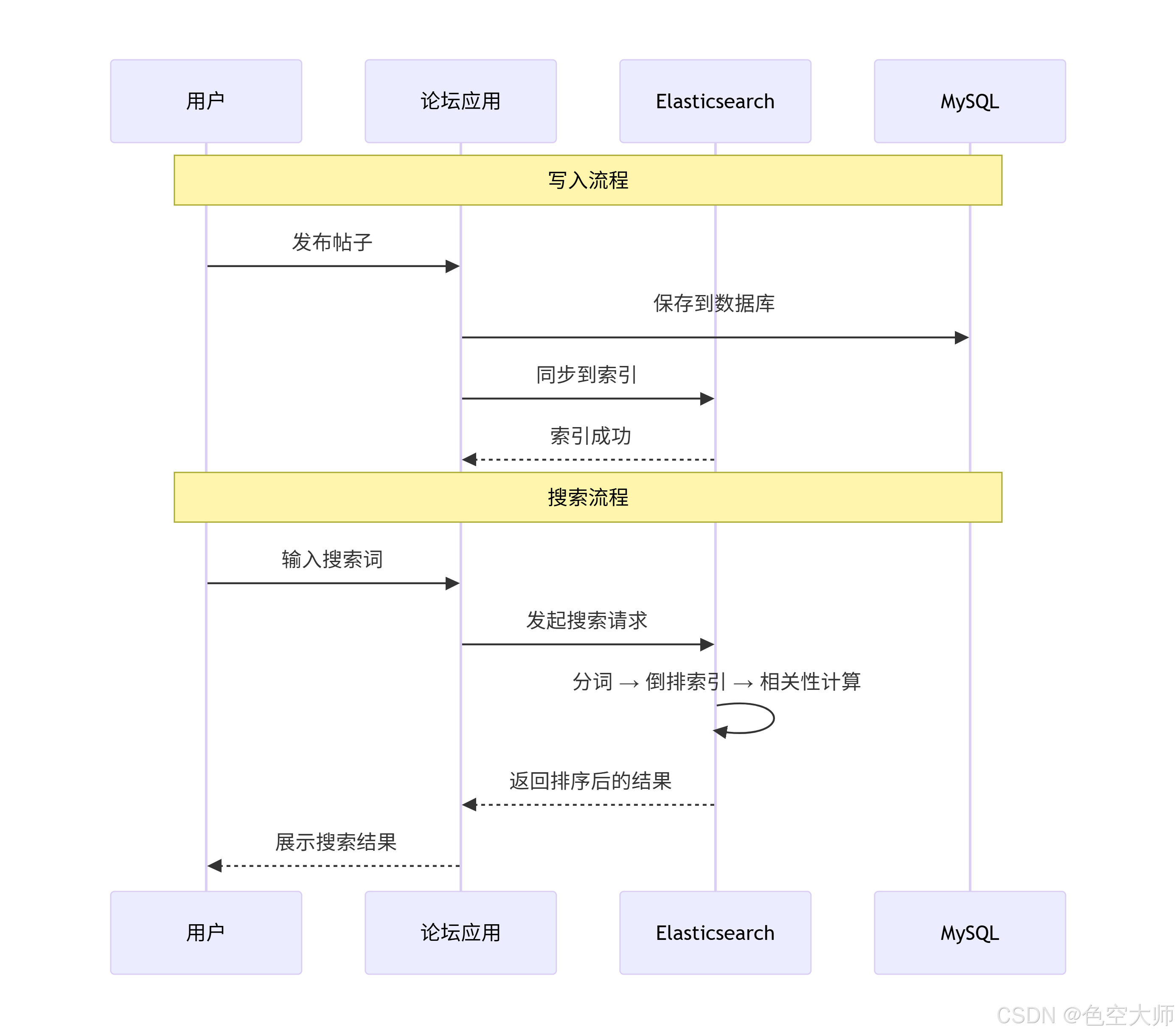
Elasticsearch是一个开源的分布式搜索和分析引擎,最初由Elastic公司开发。它构建在Apache Lucene搜索引擎库之上,提供了一个强大的全文搜索和分析引擎,它结合kibana、Logstash、Beats,是一整套技术栈,被叫做ELK,适用于各种用例,包括文本搜索、日志分析、实时数据分析、监控和报警等。
问题:为什么使用es
对大量数据进行模糊查询,如果使用数据库就成了全表查询,索引失效。需要使用专门的搜索引擎。
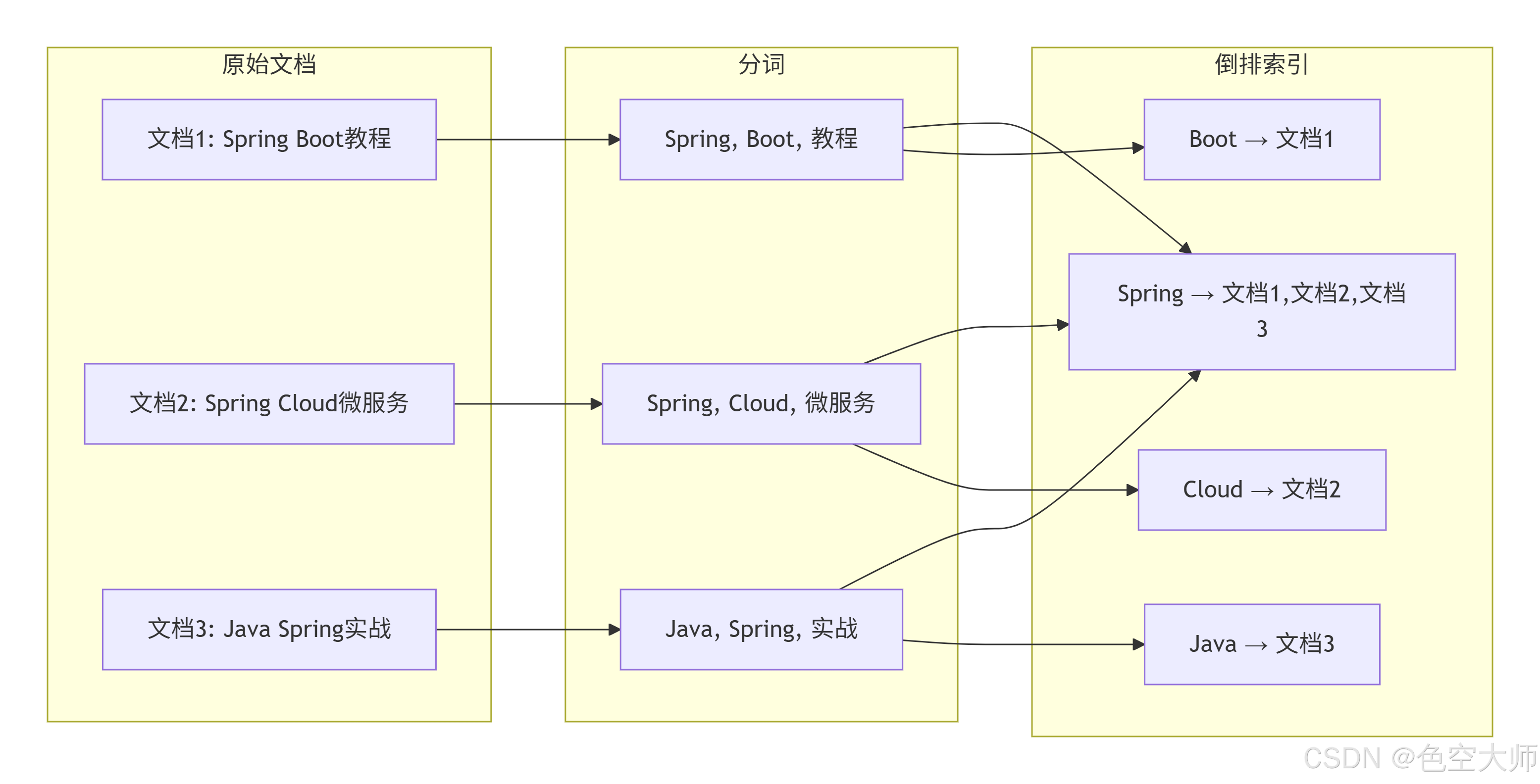
倒排原理
Elasticsearch 搜索流程
安装
安装说明
为什么需要三个一起安装?
简单答案:它们是一个完整的搜索分析系统,缺一不可,各自解决不同的问题。
打个比方:
-
Elasticsearch = 图书馆的书库(存储所有书籍,并能快速查找)
-
Kibana = 图书馆的阅览室+管理台(可视化查看数据,管理书库)
-
IK分词器 = 图书馆的中文分词机(把中文句子切分成有意义的词语)
各自的核心功能
1. Elasticsearch(核心搜索引擎)
一句话概括:负责存储数据、建立索引、执行搜索的核心引擎。
主要功能:
-
✅ 数据存储:像数据库一样保存文档数据(JSON格式)
-
✅ 全文检索:支持快速搜索文本内容(毫秒级响应)
-
✅ 倒排索引:建立词→文档的映射,加速搜索
-
✅ 聚合分析:对数据进行统计、分组、计算(如销售额统计)
-
✅ 分布式架构:支持海量数据(PB级)和高并发
实际例子:
java
// ES中存储的商品数据
{
"name": "iPhone 15 Pro Max",
"description": "苹果公司最新旗舰手机,A17芯片",
"price": 9999
}
// 搜索"苹果手机",ES快速找到这条记录2. Kibana(可视化平台)
一句话概括:为Elasticsearch提供图形化界面,让你不用敲命令就能查看和分析数据。
主要功能:
-
✅ 数据可视化:生成柱状图、折线图、地图等图表
-
✅ 实时监控:展示ES集群健康状态、性能指标
-
✅ Dev Tools:提供控制台直接执行ES命令(类似数据库的SQL工具)
-
✅ 仪表盘:组合多个图表,构建数据大屏
-
✅ 日志分析:实时查看、搜索、分析日志数据
实际例子:
bash
# 没有Kibana:你需要敲curl命令查看数据
curl -X GET "localhost:9200/logs/_search?q=error"
# 有了Kibana:在网页上直接搜索"error",还能看到漂亮的图表和统计3. IK分词器(中文分词插件)
一句话概括:让Elasticsearch能够正确理解中文,而不是把一个汉字当一个词。
为什么需要它?
ES默认的分词器对英文友好(按空格切分),但对中文会逐字切分,导致搜索结果不准确。
对比演示:
java
// 原文:"我喜欢吃苹果"
// 默认分词器(错误):
["我", "喜", "欢", "吃", "苹", "果"]
// IK分词器(正确):
["我", "喜欢", "吃", "苹果"]主要功能:
- ✅ ik_max_word:最细粒度切分,召回率高(适合搜索)
java
"中华人民共和国" → ["中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "共和国", "共和"]- ✅ ik_smart:粗粒度切分,准确率高(适合索引)
java
"中华人民共和国" → ["中华人民共和国"]- ✅ 词典扩展:支持添加自定义词汇(如"王者荣耀"、"ChatGPT")
三者协作流程
java
用户搜索"苹果手机"
↓
Kibana界面(输入关键词)
↓
发送请求到 Elasticsearch
↓
ES使用IK分词器处理"苹果手机"
"苹果手机" → ["苹果", "手机", "苹果手机"]
↓
ES在倒排索引中查找包含这些词的文档
↓
找到商品:iPhone 15、小米手机、苹果MacBook
↓
返回结果给 Kibana(展示成漂亮的列表)
↓
用户看到搜索结果实际应用场景
| 场景 | ES作用 | IK作用 | Kibana作用 |
|---|---|---|---|
| 电商搜索 | 存储商品,快速检索 | 正确切分"充电宝"、"数据线" | 展示搜索热词、点击率图表 |
| 日志分析 | 存储海量日志 | 分析日志中的中文错误信息 | 实时监控错误数量趋势 |
| 知识库 | 存储文档 | 理解中文问题(如"怎么重置密码") | 提供搜索界面和管理后台 |
| 内容推荐 | 存储用户行为 | 分析文章关键词 | 展示用户画像统计图 |
一、安装前提
- 原则:宁可SpringBoot低一点,也要保证ES版本新且稳。
- 铁律 :ES、Kibana、IK三位一体,版本号必须完全一致
需要安装跟springboot匹配的版本
版本确认
| 方案 | SpringBoot 版本 | Spring Data Elasticsearch | 推荐 Elasticsearch | 对应 Kibana | 对应 IK 分词器 | 适用场景 |
|---|---|---|---|---|---|---|
| 新项目首选 | 3.2.x / 3.3.x | 5.2.x | 8.13.0 或 8.17.0 | 8.13.0 / 8.17.0 | 8.13.0 / 8.17.0 | 新项目,AI/向量检索支持更好 |
| 稳定维护版 | 2.7.x | 4.2.x | 7.17.6 | 7.17.6 | 7.17.6 | 生产环境主流,生态最成熟 |
| 保守存量版 | 2.5.x | 4.0.x | 7.10.2 | 7.10.2 | 7.10.2 | 低版本SpringBoot兼容 |
| 保守存量版 | 2.5.x | 4.0.x | 7.10.2 | 7.10.2 | 7.10.2 | 低版本SpringBoot兼容 |
| 我的项目版本 | 2.3.x | 7.6.2 | 7.6.2 | 7.6.2 | 7.6.2 | |
| 我的版本是2.3.x,所以要安装7.6.2版本。 |
二、服务器环境准备
2.1 检查系统环境
bash
# 查看操作系统版本
cat /etc/os-release
# 检查Java版本(需要JDK 8+)
java -version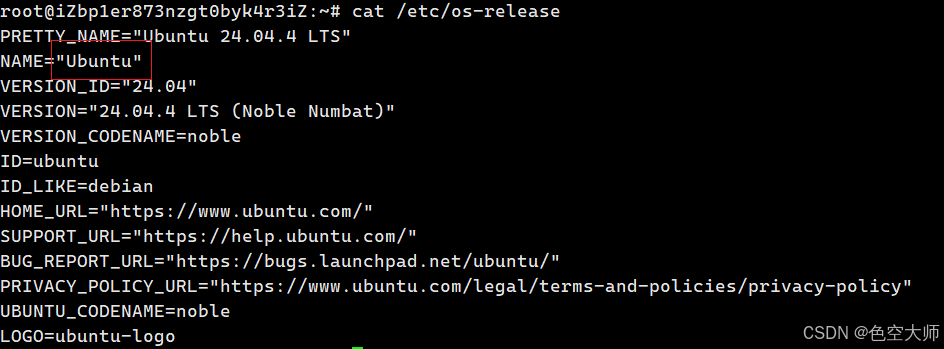
我的是ubantu
2.2 创建专用用户(重要)
ES 不能使用 root 用户运行,必须创建普通用户:
bash
# 创建用户组和用户
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
# 设置密码(可选)
passwd elsearch三、安装方式选择
阿里云服务器上推荐两种安装方式,根据需求选择:
| 方式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Docker安装 | 快速部署、测试环境 | 简单快捷、隔离性好 | 需要了解Docker |
| 压缩包安装 | 生产环境 | 可控性强、便于调优 | 步骤较多 |
四、方式一:Docker安装(推荐快速上手)
4.1 安装Docker
centos系统
bash
# 安装依赖
yum install -y yum-utils
# 添加阿里云镜像源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装Docker
yum -y install docker-ce
# 启动并设置开机自启
systemctl start docker
systemctl enable dockerubantu系统
bash
# 1. 安装依赖(更新包索引并安装所需工具)
sudo apt update
sudo apt install -y apt-transport-https ca-certificates curl software-properties-common
# 2. 添加阿里云Docker镜像源(使用GPG密钥)
# 添加Docker官方GPG密钥
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 添加阿里云Docker源(Ubuntu版本对应)
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 3. 安装Docker
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
# 4. 启动并设置开机自启
sudo systemctl start docker
sudo systemctl enable docker4.2 安装Elasticsearch 7.6.2
bash
# 拉取镜像
docker pull elasticsearch:7.6.2
# 创建数据目录
mkdir -p /mydata/elasticsearch/{data,plugins,logs,config}
chmod -R 777 /mydata/elasticsearch
# 启动容器
docker run -d \
--name elasticsearch \
--restart=always \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-v /mydata/elasticsearch/logs:/usr/share/elasticsearch/logs \
elasticsearch:7.6.2参数说明:
-
-p 9200:9200:HTTP API端口(应用连接用)
-
-p 9300:9300:集群内部通信端口
-
discovery.type=single-node:单节点模式
-
ES_JAVA_OPTS:限制内存使用(阿里云服务器内存通常较小)
4.3 安装Kibana 7.6.2
bash
# 拉取镜像
docker pull kibana:7.6.2
# 启动容器
docker run -d \
--name kibana \
--restart=always \
-p 5601:5601 \
--link elasticsearch:elasticsearch \
-e "ELASTICSEARCH_HOSTS=http://elasticsearch:9200" \
kibana:7.6.24.4 安装IK分词器(Docker方式)
方法一:进入容器安装
bash
# 方法一:进入容器安装
docker exec -it elasticsearch /bin/bash
# 在线安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
# 退出并重启
exit
docker restart elasticsearch方法二:离线安装
bash
# 方法二:离线安装(如果网络问题)
# 1. 下载插件包到宿主机
cd /mydata/elasticsearch/plugins
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
# 2. 解压
mkdir ik
unzip elasticsearch-analysis-ik-7.6.2.zip -d ik
rm -f elasticsearch-analysis-ik-7.6.2.zip
# 3. 重启容器
docker restart elasticsearch五、方式二:压缩包安装(生产环境推荐)
下载安装包
bash
# 创建安装目录
mkdir -p /data/ELK
cd /data/ELK
# 下载Elasticsearch(使用国内镜像更快)
wget https://mirrors.huaweicloud.com/elasticsearch/7.6.2/elasticsearch-7.6.2-linux-x86_64.tar.gz
# 解压
tar -zxf elasticsearch-7.6.2-linux-x86_64.tar.gz
mv elasticsearch-7.6.2 elasticsearch
# 创建数据、日志、配置目录
mkdir -p /data/ELK/elasticsearch/{data,logs,conf}5.2 修改配置文件
编辑配置文件:/data/ELK/elasticsearch/config/elasticsearch.yml
bash
# 集群名称
cluster.name: forum-cluster
# 节点名称
node.name: node-1
# 数据存储路径
path.data: /data/ELK/elasticsearch/data
path.logs: /data/ELK/elasticsearch/logs
# 网络配置(重要:阿里云需要配置内网IP)
network.host: 0.0.0.0
http.port: 9200
# 集群发现配置(单节点)
discovery.type: single-node
# 跨域配置(如需使用head插件)
http.cors.enabled: true
http.cors.allow-origin: "*"修改JVM内存配置:/data/ELK/elasticsearch/config/jvm.options
bash
# 根据服务器内存调整(阿里云2G内存建议512m)
-Xms512m
-Xmx512m5.3 修改系统配置
bash
# 1. 修改文件描述符限制
echo "elsearch soft nofile 65536" >> /etc/security/limits.conf
echo "elsearch hard nofile 65536" >> /etc/security/limits.conf
# 2. 修改虚拟内存区域
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
# 3. 修改进程限制
echo "elsearch soft nproc 4096" >> /etc/security/limits.d/20-nproc.conf5.4 修改权限并启动
bash
# 修改目录所有者
chown -R elsearch:elsearch /data/ELK/elasticsearch
# 切换到es用户启动
su - elsearch
cd /data/ELK/elasticsearch
# 前台启动(测试用)
./bin/elasticsearch
# 后台启动
./bin/elasticsearch -d5.5 安装IK分词器
bash
# 切换到es用户
su - elsearch
cd /data/ELK/elasticsearch
# 在线安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
# 重启ES
pkill -f elasticsearch
./bin/elasticsearch -d5.6 安装Kibana
bash
# 下载Kibana
cd /data/ELK
wget https://mirrors.huaweicloud.com/kibana/7.6.2/kibana-7.6.2-linux-x86_64.tar.gz
tar -zxf kibana-7.6.2-linux-x86_64.tar.gz
mv kibana-7.6.2-linux-x86_64 kibana
# 修改配置
vi /data/ELK/kibana/config/kibana.yml配置文件
bash
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]修改权限并启动
bash
# 修改权限并启动
chown -R elsearch:elsearch /data/ELK/kibana
su - elsearch
cd /data/ELK/kibana
./bin/kibana &
# 后台运行
nohup ./bin/kibana > /dev/null 2>&1 &六、验证安装
6.1 验证Elasticsearch
bash
# 检查服务状态
curl http://localhost:9200
# 预期返回
# {
# "name" : "node-1",
# "cluster_name" : "forum-cluster",
# "version" : {"number" : "7.6.2", ...}
# }6.2 验证IK分词器
bash
# 测试中文分词
curl -X POST "http://localhost:9200/_analyze" -H "Content-Type: application/json" -d'
{
"analyzer": "ik_max_word",
"text": "论坛系统中文搜索"
}'6.3 验证Kibana
浏览器访问:http://你的服务器IP:5601
6.4 防火墙配置
bash
# 阿里云安全组需要开放端口:9200、5601
# 如果使用firewalld
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --zone=public --add-port=5601/tcp --permanent
firewall-cmd --reload七、Spring Boot配置
7.1 application.yml配置
bash
spring:
elasticsearch:
rest:
uris: http://你的服务器IP:9200
connection-timeout: 5s
read-timeout: 30s7.2 添加依赖
java
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>八、常见问题
| 问题 | 解决方案 |
|---|---|
| can not run elasticsearch as root | 必须使用普通用户启动 |
| max virtual memory areas vm.max_map_count | 执行 sysctl -w vm.max_map_count=262144 |
| max file descriptors | 修改 /etc/security/limits.conf |
| 9200端口无法访问 | 检查阿里云安全组规则 |
| IK分词器不生效 | 确认版本完全匹配7.6.2,重启ES |
九、服务管理脚本
bash
#!/bin/bash
# /etc/init.d/elasticsearch
# 启动
su - elsearch -c "/data/ELK/elasticsearch/bin/elasticsearch -d"
# 停止
ps aux | grep elasticsearch | grep -v grep | awk '{print $2}' | xargs kill -9
# 查看日志
tail -f /data/ELK/elasticsearch/logs/forum-cluster.log中文分词器的原理
1.单字分词
2.二分法分词
3.词库分词
单字分词
单字分词:就是按照中文一个字一个字分词。比如"我们是中国人",分词效果就是"我","们","是","中","国","人"
二分法分词:
词库分词
网上的工具,如https://www.sojson.com/analyzer
es基础概念
1.索引(Index)(数据库)
2.类型(types)(表)
3.文档(Document)
4.字段(fields)(列)
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系 :
索引(indices)--------------------------------Databases 数据库
类型(type)------------------------------------Table 数据表
文档(Document)----------------------------Row 行
字段(Field)-----------------------------------Columns 列
详细说明
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引, |
| 类型(type) | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 映射配置(mappings) | 字段的数据类型、属性、是否索引、是否存储等特性 |
索引语法
创建索引
java
PUT /test
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}test:索引名称
settings:索引库的设置
number_of_shards:分片数量
number_of_replicas:副本数量
查看索引
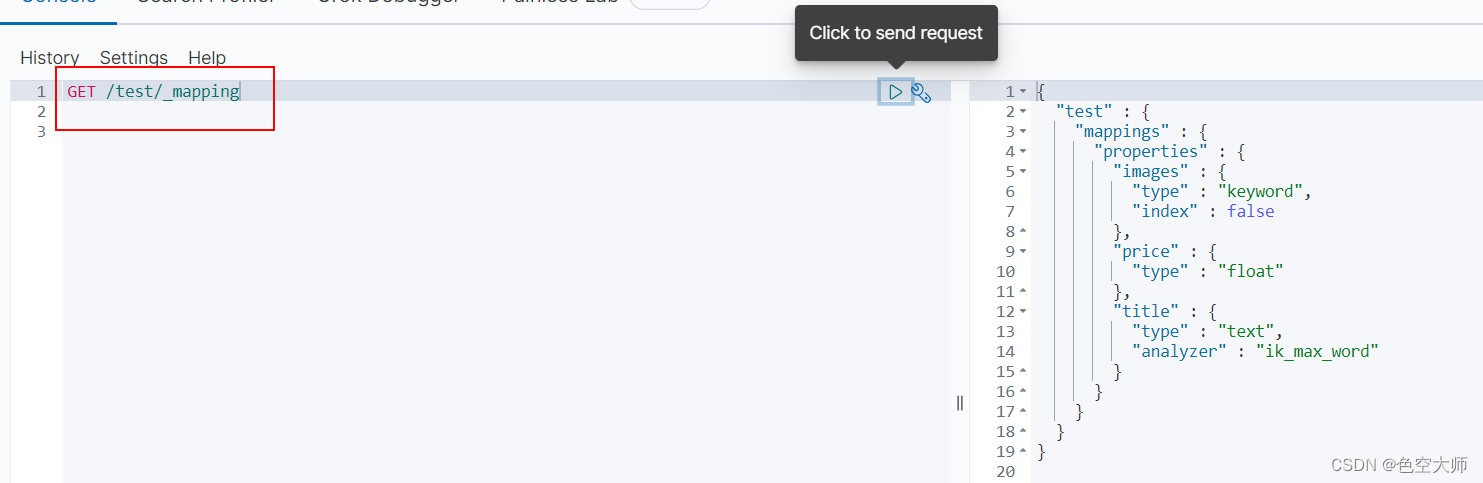
语法:GET /索引库名,如
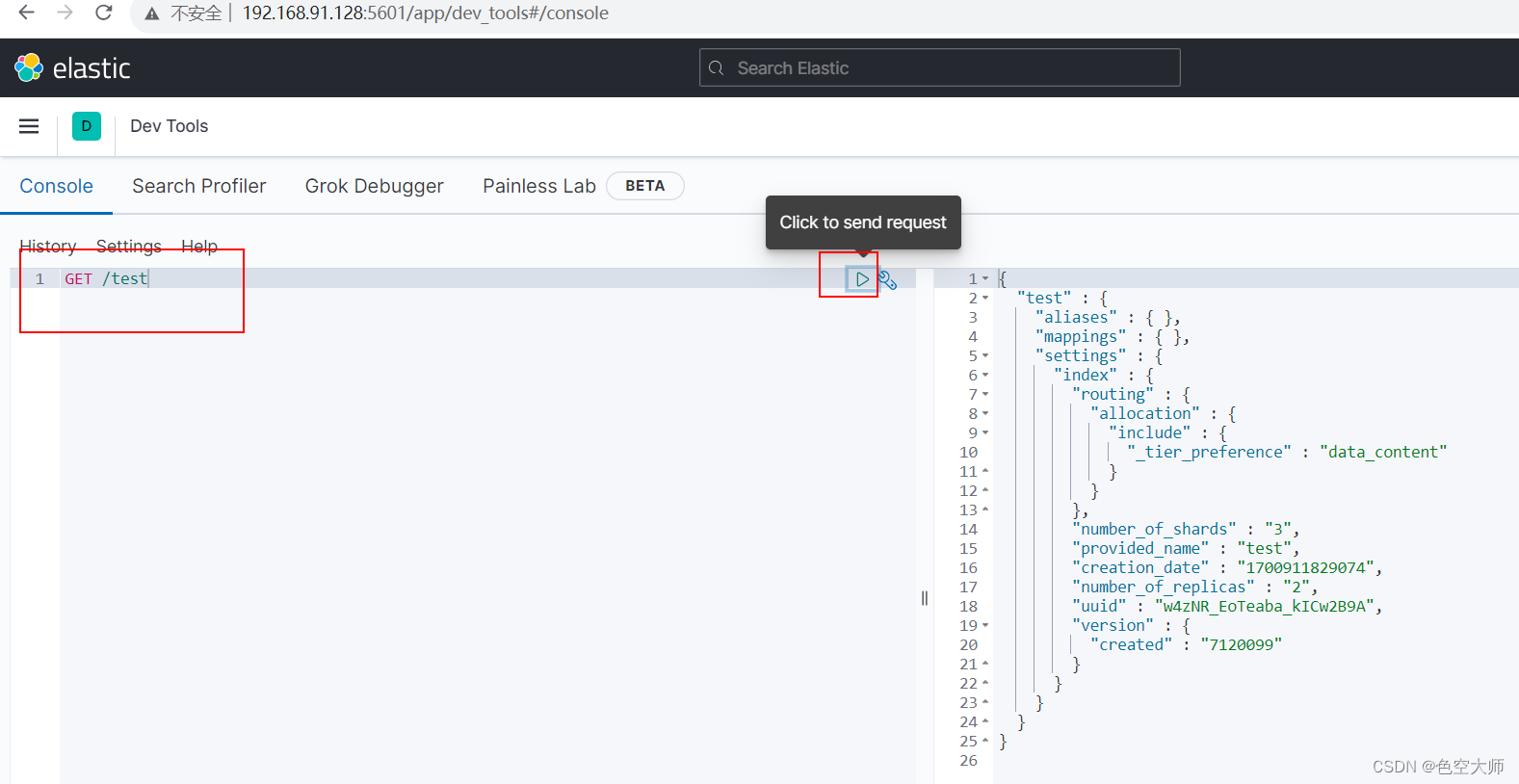
查看索引库是否存在
语法:HEAD /索引库名,存在则返回200,不存在返回404
HEAD /test
删除索引
语法:DELETE /索引 库名
DELETE /test
配置映射
创建映射字段
语法:PUT /索引名称/_mapping/类型名称

比如:
java
POST /test/_mapping/items?include_type_name=true
{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word"
},
"price":{
"type":"float"
},
"images":{
"type":"keyword",
"index":false
}
}
}注意:es7后需要加入include_type_name=true参数
type中的keyword代表关键词,不能被分词
查看映射
相当于查看表的信息
语法 GET /索引库名/_mapping
比如 GET /test/_mapping