文章目录
概述 :一种基于Transformer编码器架构的预训练语言模型,通过结合Tokenization、Embedding和特定任务的输出层,能够捕捉文本的双向上下文信息。
工作原理:在大量未标注数据上执行预训练任务,然后再表注数据中进行微调,使其称为专用模型。
模型整体架构
从模型结构来说,没有太大创新点,都是基于Transformer架构改编而来,与GPT模型不同的是,BERT是双向的,GPT是单向的。
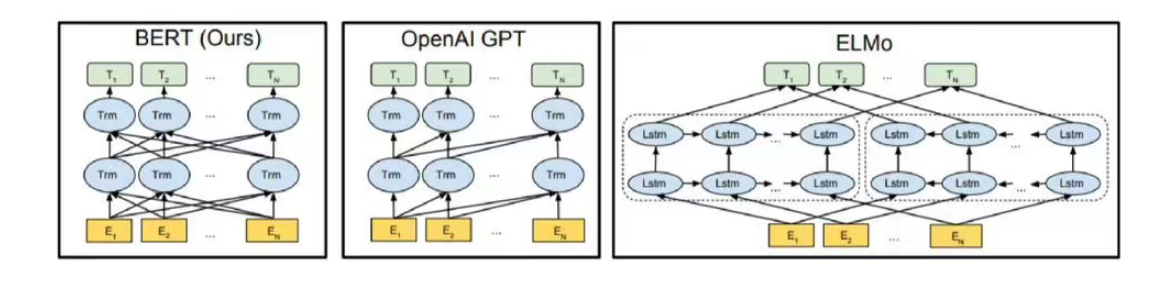
从BERT的模型结构来看,小编感觉他独特地方在于输入与词嵌入两个模块,参考xhs大神图片。
模型架构细节
输入张量
BERT的输入是一个原始的文本序列,可以由单个句子,也可以是两个句子,如问答。
输入张量需要经过<font style="color:rgb(6, 10, 38);">transformers</font> 库的 tokenizer(如 <font style="color:rgb(6, 10, 38);">BertTokenizer</font>)处理而来。
案例API使用(参考qwen)
python
# 设置分词器,不同词参数不同(选用不同标准分词)
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
# 单句
out = tokenizer("Hello world!")
# 句子对
out = tokenizer("Question?", "Answer.")
# 批量 + 张量
batch_out = tokenizer(
["I like apples.", "She runs fast."],
padding=True,
truncation=True,
max_length=64,
return_tensors="pt" # or "tf", "np"
)
# batch_out.input_ids.shape 含有CLS等字符结束标志tokenizer的返回值挺多的,需要注意一下。
| 字段名 | 说明 |
|---|---|
input_ids |
token 对应的词汇表 ID 序列(含 [CLS] 和 [SEP]) |
token_type_ids |
段 ID 序列(0 或 1) |
attention_mask |
指明哪些 token 是真实内容(1) vs padding(0) |
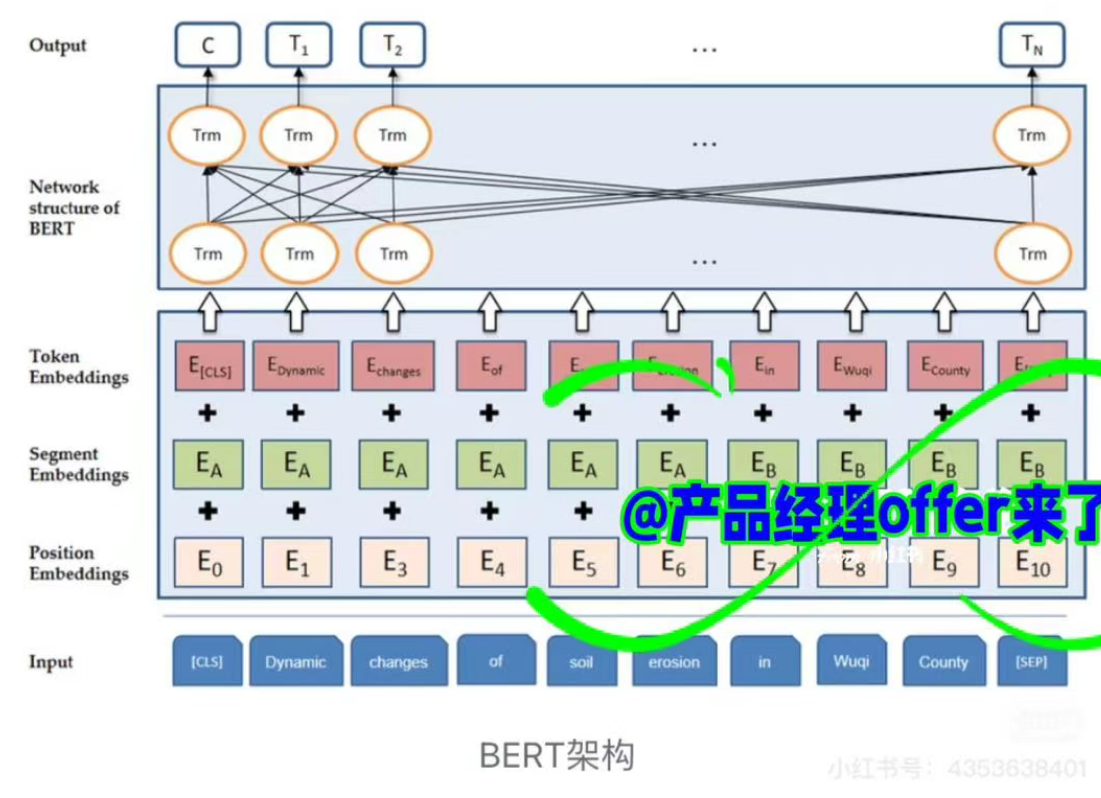
输入层
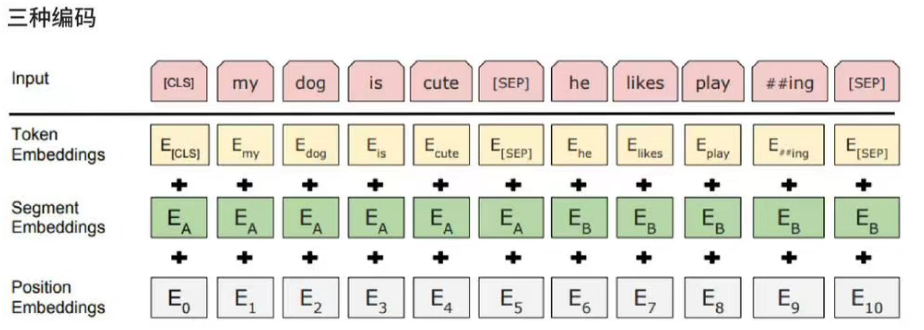
输入层有三个部分组成,Token Embedding、Segment Embedding、Position Embedding。**Token Embedding->Segment Embedding->Position Embedding.**
Token Embedding
Token Embedding也称"词嵌入"层。
输入文本首先通过**分词器"WordPiece"**将文本切割为**<font style="background-color:#FBDE28;">subword tokens</font>**,这一步通常含有文本转小写,去除标点等作用。
BERT提出的特殊标记:
[CLS]: 在序列开头,用于分类任务,代表整个句子的聚合表示。[SEP]: 用于分割 两个句子或者标记单句的结束。
python
[CLS] 我 爱 你 。 [SEP] 你 喜 欢 我 吗 ? [SEP]Segment Embedding
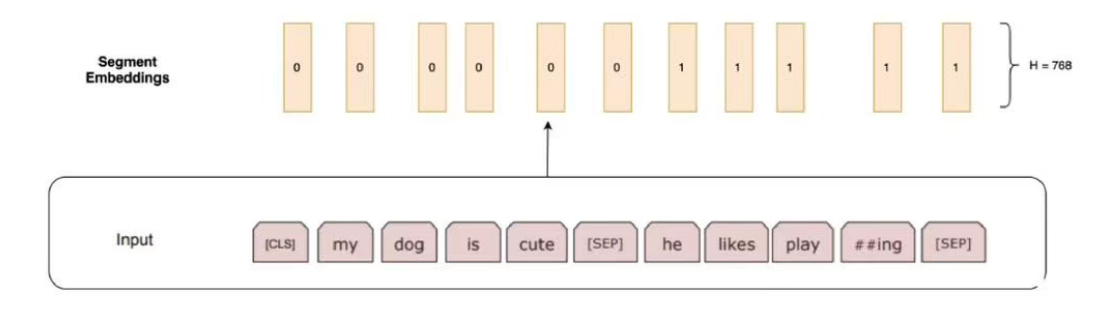
这一部分称为"段嵌入",主要用于区分不同句子 。
Position Embedding
这一部分称为"位置嵌入",主要用于表示每个token在序列中的位置 。
最后讲三个部分相加,得到嵌入层最总输出。
BERT网络结构
BERT的核心是transformer的编码器,每个编码器都包含:自注意力机制、前馈神经网络、残差连接和归一化,这个和transformer一致 。
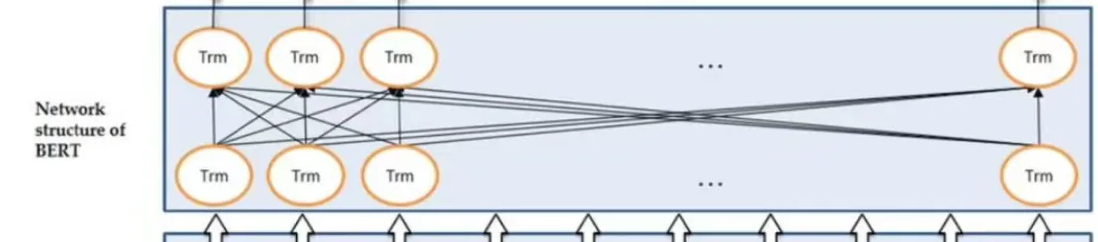
- 自注意力机制:允许模型在处理序列的时候关注来着不同位置的token,并且计算不同token之间的权重,从而捕捉不同序列中的依赖关系。
- 前馈神经网络:对自注意力机制的输出进一步进行特征提取。
- 残差和归一化:提高模型的稳定性,防止模型退化。
输出层
这一部分取决于不同任务。
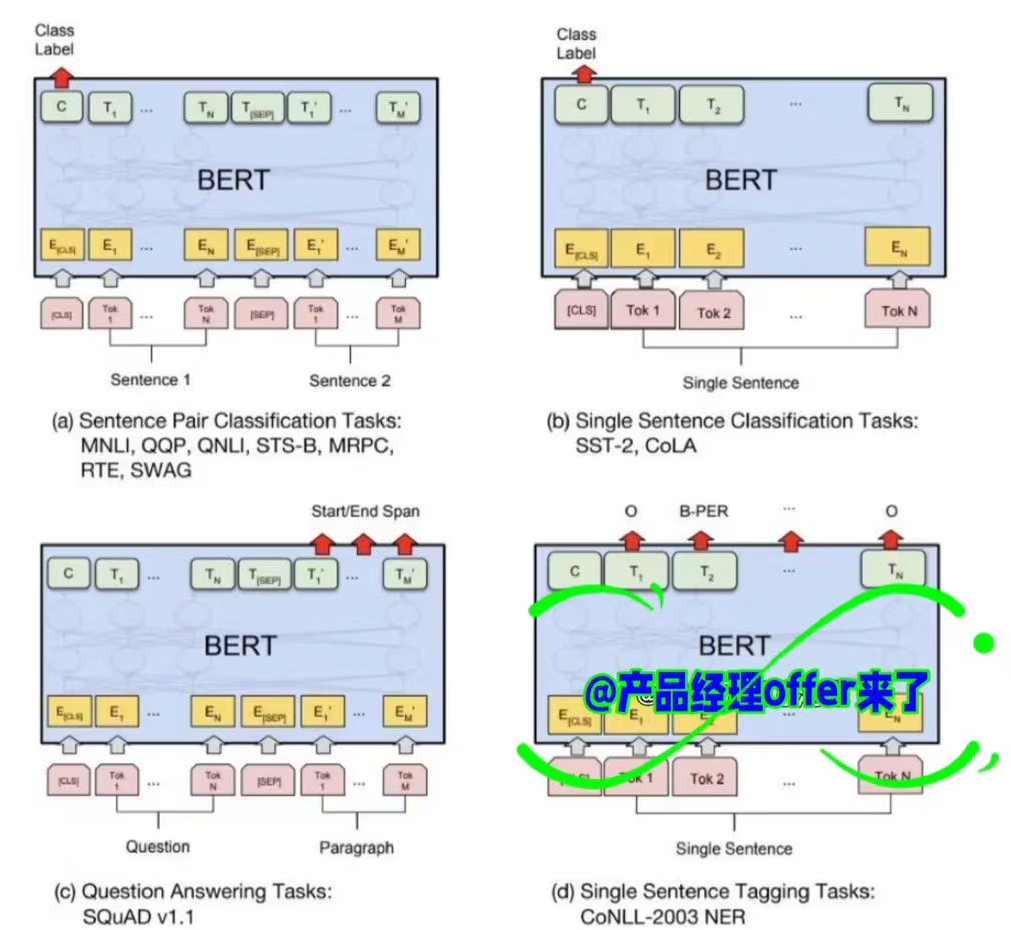
- a. 句子对分类
- b. 单句分类
- c. 问答
- d. 序列标志,如:输出每个Token的标签
预训练两种模型
BERT在预训练的时候采用两种任务:
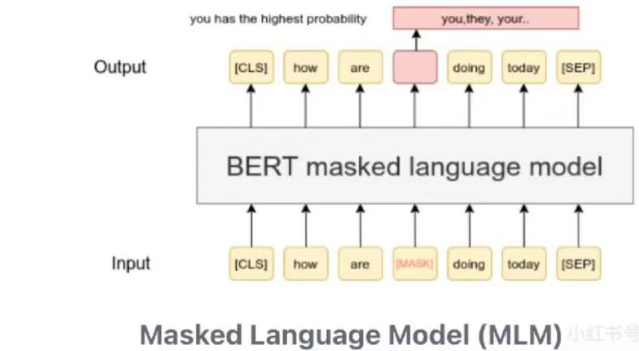
Masked Language Model(MLM)
- 任务 :在文本输入中,随机的遮蔽或者替换一些词汇,并要求模型预测这些被遮掩或者替换的词汇。
- **实现方法:**在预训练过程中,BERT随机选择文中15%的Token进行遮盖,其中80%的概率用【mask】进行标记替换,10%用随机词汇替换,10%保持不变。
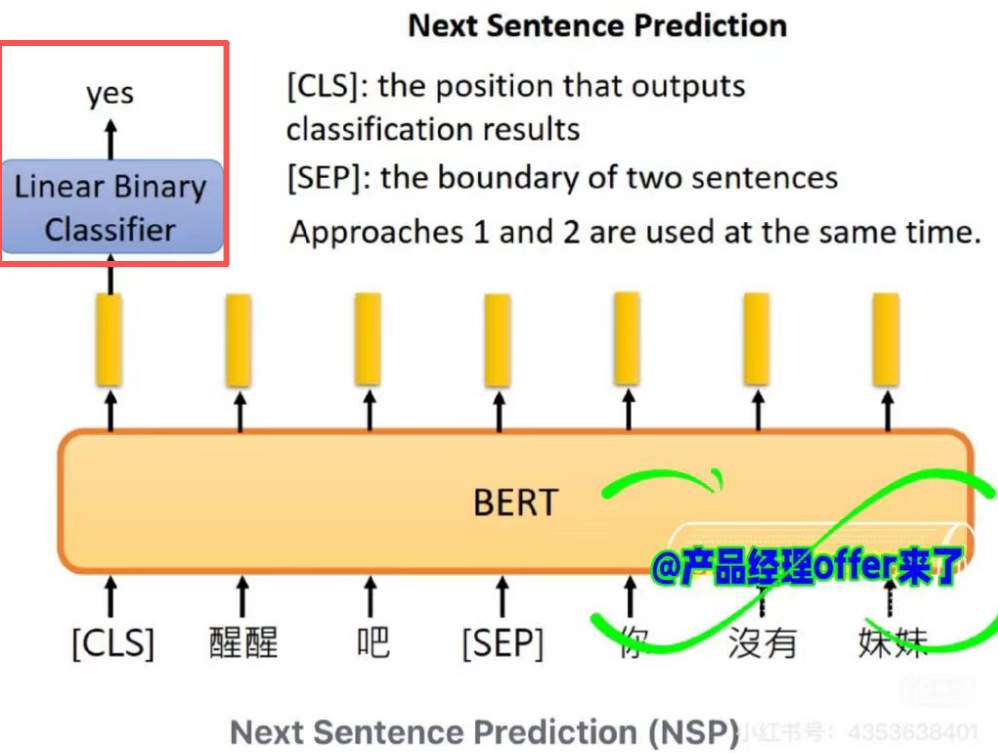
Next Sentence Prediction(NSP)
- 任务:给定一个句子,判断第二个句子是否为第一个句子的后续句子。
- 实现 :在预训练过程中,BERT构造了一恶搞二分类任务,其中50%的概率B是A真正的后续句子,标签为IsNext,50%概率为随机选择的句子,标签为NotNect,最后通过CLS标记的输出进行预测分类。