文章目录
- 一.Redis的数据类型有哪些?
- [二. String](#二. String)
- [三. List](#三. List)
- [三. Hash](#三. Hash)
- [四. Set](#四. Set)
- [五. Zset](#五. Zset)
- 三.特殊数据类型
一.Redis的数据类型有哪些?
常数据类型包括:
- 5种基本数据类型:String(字符串) List(列表) Set(集合) Hash(散列) Zset(有序集合)
- 5种特殊数据类型: HyperLogLog(基数统计) Bitmap(位图) Geospital(地理位置) bitfield(位域) Stream(流)
二. String
String是Redis的最基本的数据类型,Redis是以<K,V>键值对为单位进行存储的,所有的key均是String类型;
1)常用指令
| 命令 | 介绍 |
|---|---|
| set key value | 设置指定 key 的值 |
| setnx key value | 只有在 key 不存在时设置 key 的值 |
| get key | 获取指定 key 的值 |
| mset key1 value1 key2 value2 ... | 设置一个或多个指定 key 的值 |
| mget key1 key2 ... | 获取一个或多个指定 key 的值 |
| strlen key | 返回 key 所储存的字符串值的长度 |
| incr key | 将 key 中储存的数字值增一 |
| decr key | 将 key 中储存的数字值减一 |
| exists key | 判断指定 key 是否存在 |
| del key(通用) | 删除指定的 key |
| expire key seconds(通用) | 给指定 key 设置过期时间 |
2)String的应用场景
1.计数功能
许多应用都会使用Redis作为计数工具,其可以实现快速计数;例如:记录视频网站的观看次数,用户每看一次,视频播放数+1;
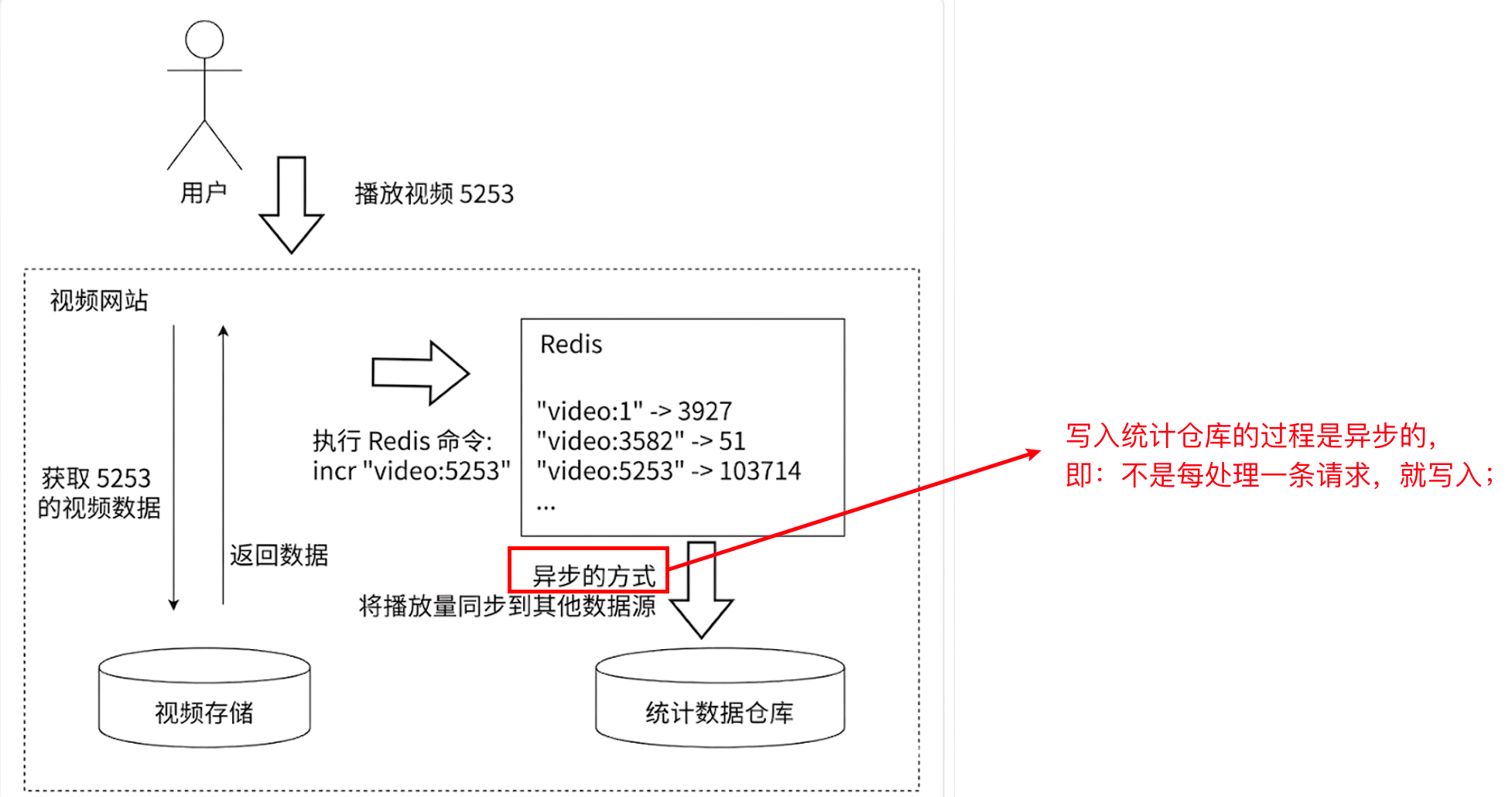
- Redis可以进行计数,但其并不擅长统计数据(如找播放量前100)
- 像mysql这种数据库就可以很轻松的进行数据统计,计数的目的是用于统计,因此最终还要将结果放入到用于统计的数据库中;
2.短信验证码

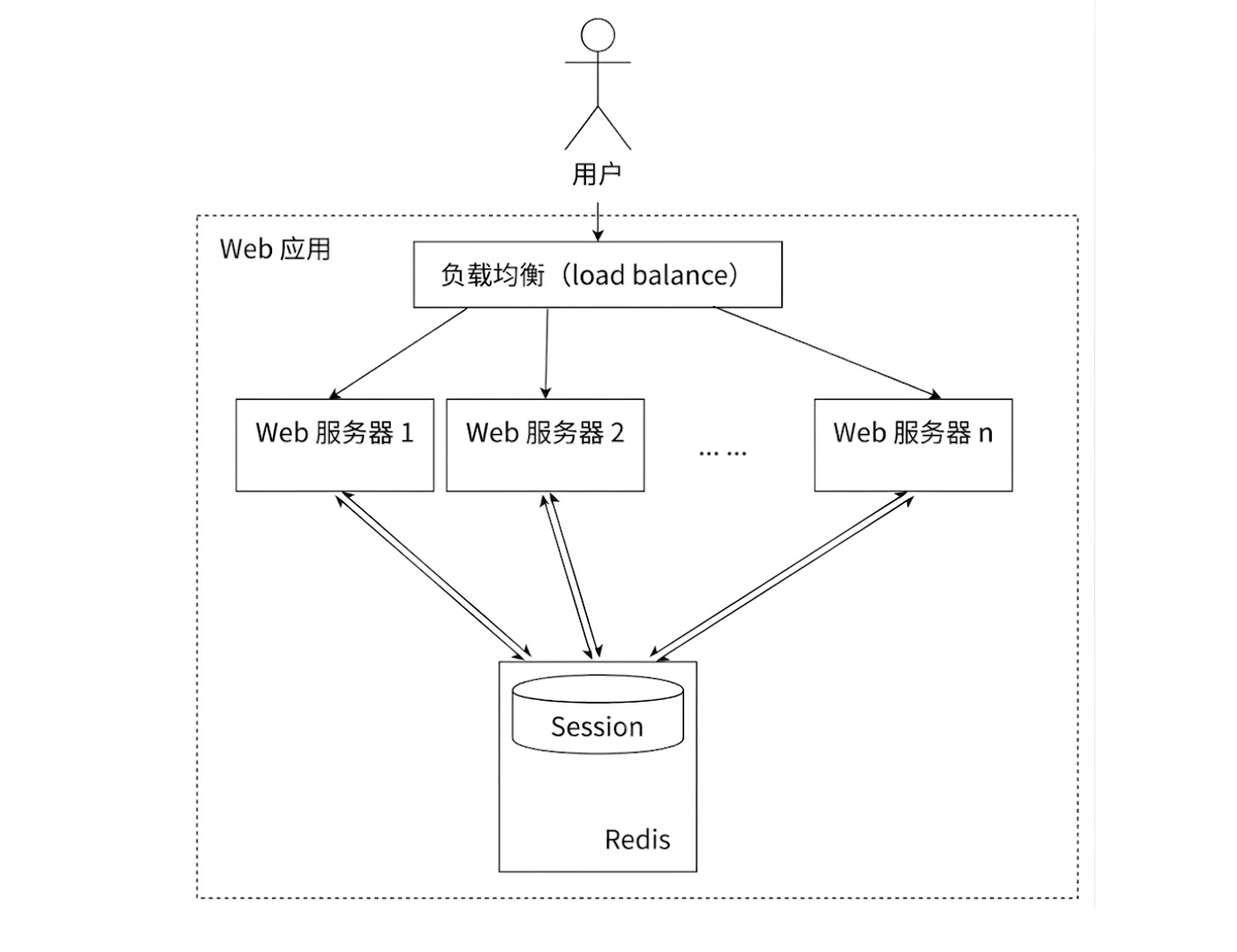
3.共享会话
分布式系统中,一般每个Web服务器都会保存自己的Session信息,但请求会被负载均分发到不同的服务器上,而该服务器可能没有该用户的Session,导致用户需要重新登录;
=》因此,可以使用Redis将用户信息集中进行管理;
4.缓存
缓存常规数据,Token,图片地址,序列化后的对象(相比较于 Hash 存储更节省内存)等;
三. List
List相当于数组或顺序表;列表中允许有重复元素;其底层实现类似于"双端队列";
1) 常用指令
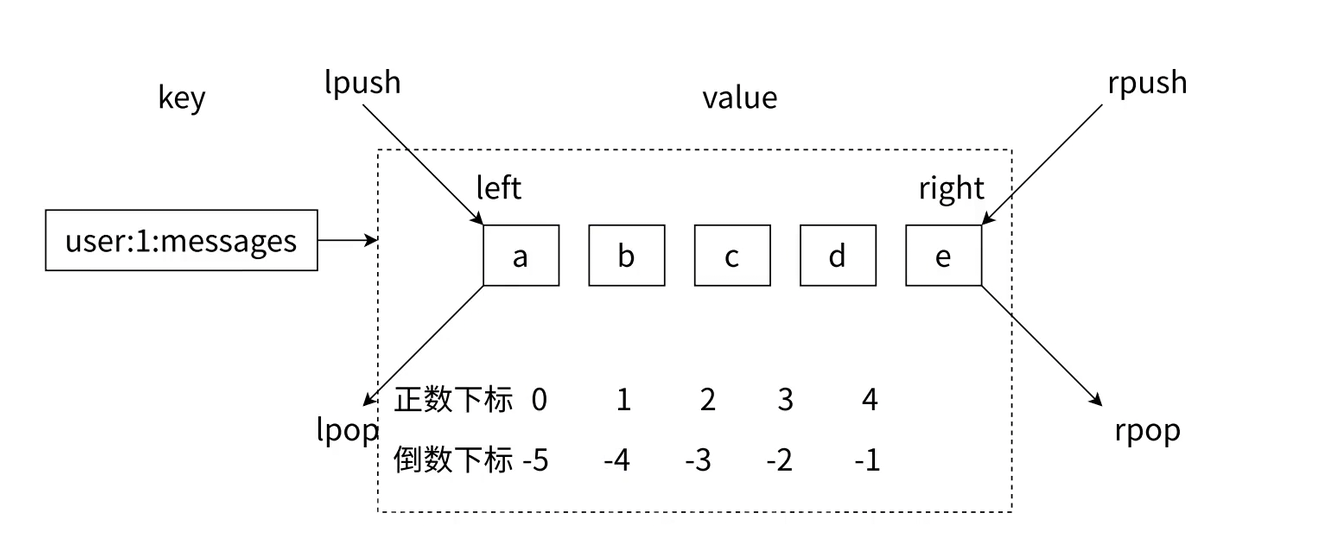
| 命令 | 介绍 |
|---|---|
| rpush key value1 value2 ... | 在指定列表的尾部(右边)添加一个或多个元素 |
| lpush key value1 value2 ... | 在指定列表的头部(左边)添加一个或多个元素 |
| lset key index value | 将指定列表索引 index 位置的值设置为 value |
| lpop key | 移除并获取指定列表的第一个元素(最左边) |
| rpop key | 移除并获取指定列表的最后一个元素(最右边) |
| llen key | 获取列表元素数量 |
| lrange key start end | 获取列表 start 和 end 之间的元素 |
2)应用场景
1.消息队列
List可以作为消息队列,只不过功能较为简单且存在缺陷,Redis5.0引入的Stream类型更加适合;
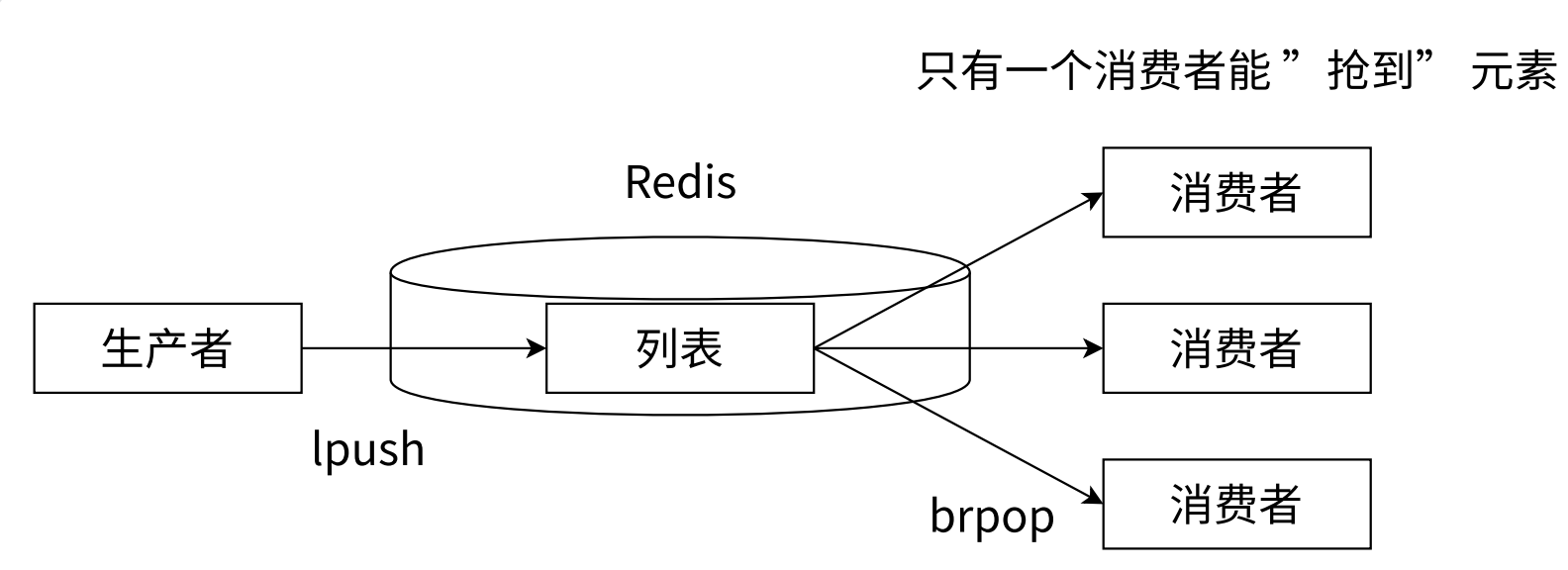
2.信息流展示
举例:最新文章,最新动态;
三. Hash
1) 常用指令
| 命令 | 介绍 |
|---|---|
| hset key field value | 设置指定哈希表中指定字段的值 |
| hsetnx key field value | 只有指定字段不存在时设置指定字段的值 |
| hmset key field1 value1 field2 value2 ... | 同时将一个或多个 field-value(域-值对)设置到指定哈希表中 |
| hget key field | 获取指定哈希表中指定字段的值 |
| hmget key field1 field2 ... | 获取指定哈希表中一个或者多个指定字段的值 |
| hgetall key | 获取指定哈希表中所有的键值对 |
| hexists key field | 查看指定哈希表中指定的字段是否存在 |
| hdel key field1 field2 ... | 删除一个或多个哈希表字段 |
| hlen key | 获取指定哈希表中字段的数量 |
| hincrby key field increment | 对指定哈希表中的指定字段做运算操作(正数为加,负数为减) |
2)应用场景
1.存储结构化数据
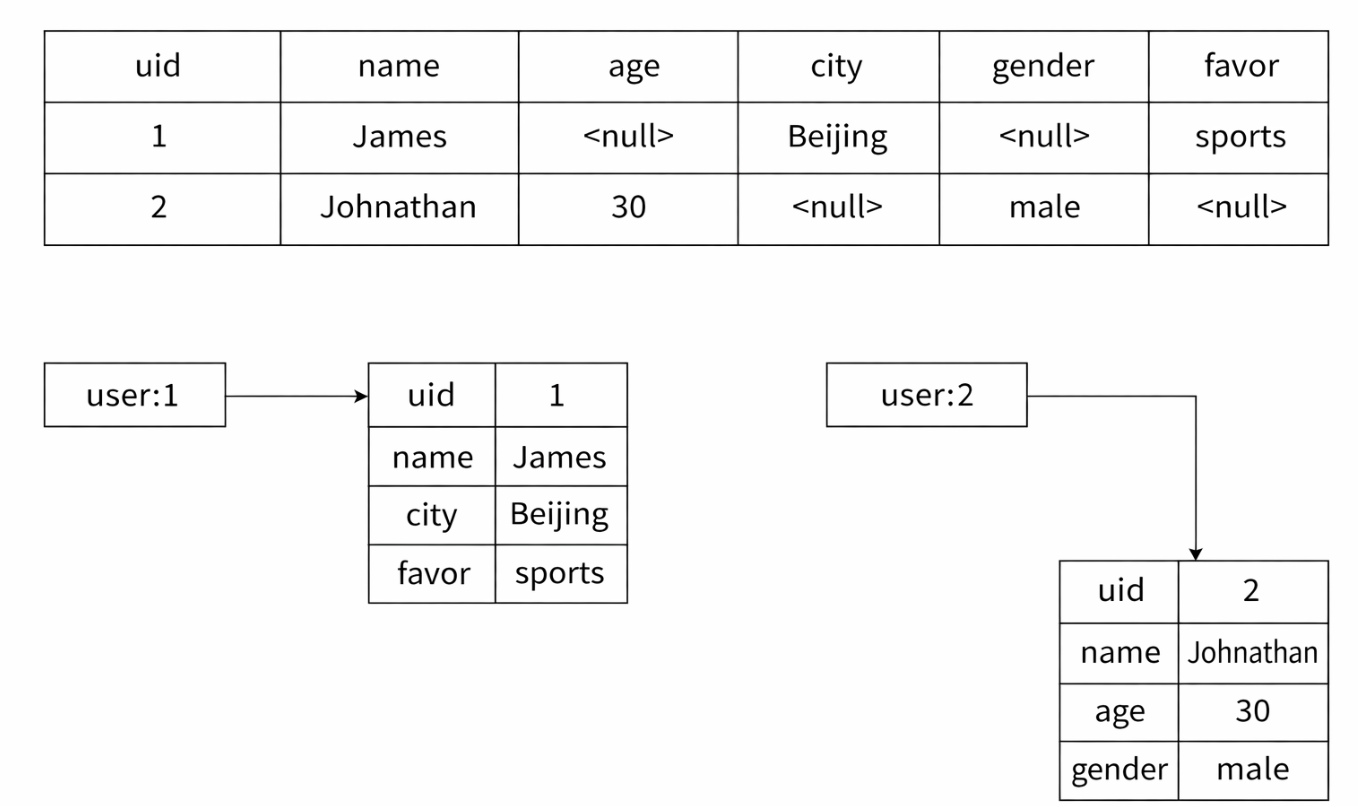
举例:用户信息,商品信息,购物车信息...
由前文可知,String+Json也可以达到Hash的效果,那么两者该如何选取呢?
- 一般对象使用String+Json进行存储;
- 对象中如果有频繁变化的属性那么就需要使用Hash来存储;
四. Set
- Set也是用来保存多个字符串元素的,其于列表不同,集合中的元素是不允许重复的并且是无序的;
- Set除了支持集合内的增删查改,还支持取并集,交集,差集,该类型可以处理许多现实问题;
1) 常用指令
| 命令 | 介绍 |
|---|---|
| sadd key member1 member2 ... | 向指定集合添加一个或多个元素 |
| smembers key | 获取指定集合中的所有元素 |
| scard key | 获取指定集合的元素数量 |
| sismember key member | 判断指定元素是否在指定集合中 |
| sinter key1 key2 ... | 获取给定所有集合的交集 |
| sinterstore destination key1 key2 ... | 将给定所有集合的交集存储在 destination 中 |
| sunion key1 key2 ... | 获取给定所有集合的并集 |
| sunionstore destination key1 key2 ... | 将给定所有集合的并集存储在 destination 中 |
| sdiff key1 key2 ... | 获取给定所有集合的差集 |
| sdiffstore destination key1 key2 ... | 将给定所有集合的差集存储在 destination 中 |
| spop key count | 随机移除并获取指定集合中一个或多个元素 |
| srandmember key count | 随机获取指定集合中指定数量的元素 |
2)应用场景
Set比较典型的应用场景就是"标签",下面的许多场景都是根据"标签"进行考量的;
- 每个用户一般会被刻画为一个个"用户画像";
- 用户画像,即描述个人的"特征",通过这些特征(性别,年龄,爱好...),来投其所好;
- 这些所谓的"特征"就会转换为"标签";
1.需要获取多个数据源交/并/差集的场景
例如:求公共好友,公共粉丝,共同关注,好友推荐等场景;
2.随机获取元素的场景
例如:抽奖,随机点名等;
- key为活动名,value为用户名;Set有去重功能,可以保证同一用户不会被中将两次;
五. Zset
- zset与set大多数内容都是相同的;
- 其比set多了一个排序属性score,即存储的元素均由两个值组成,一个是有序集合的元素值,一个是排序值;
- zset中,member是唯一的,但score是可以重复的;
1) 常用指令
| 命令 | 介绍 |
|---|---|
| zadd key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
| zcard key | 获取指定有序集合的元素数量 |
| zscore key member | 获取指定有序集合中指定元素的 score 值 |
| zinterstore destination numkeys key1 key2 ... | 将给定所有有序集合的交集存储在 destination 中,对相同元素的 score 进行 sum 聚合,numkeys 为集合数量 |
| zunionstore destination numkeys key1 key2 ... | 求并集,和 zinterstore 类似 |
| zdiffstore destination numkeys key1 key2 ... | 求差集,和 zinterstore 类似 |
| zrange key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
| zrevrange key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到低) |
| zrevrank key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
2)编码方式
Zset底层数据结构由压缩列表和跳表实现;在Redis7.0中,压缩列表已经被放弃,由跳表实现;
- 当zset元素个数<A&&元素长度<B时,其会压缩列表存储,以减少内存使用;
- 当不再满足如上要求,就会采用跳表来实现;
3)应用场景
zset的典型场景,就是排行榜,例如:成绩排行榜,游戏积分排行榜,视频播放排行榜,销量排行榜...
三.特殊数据类型
1.HyperLogLog
该类型的运用场景只有一个,即**"估算"**集合中的元素个数;
- set有一个应用场景:统计服务器的UV(用户访问次数);使用set虽然可以统计,但当数据量特别大时,set会消耗更多的内存空间;
- HyperLogLog不存储元素内容,而是记录元素"特征",新增元素时,能知道当前元素是已经存在的还是第一次出现的;
- HyperLogLog虽可以用于计数,但其并不知道具体有哪些数,其实现的核心是"位运算",因此其判断会存在一定误差(发生误判);
假设Set存储userId,一个userId8字节,1亿个UV =》8亿字节 0.8G=》800MB
- 虽然800MB并不大,但是HyperLogLog可以最多使用12KB空间,实现上述效果;
2.BitMap
即使用bit位来表示整数;
- 假设有8个bit位的数据:00001101,则每个比特位表示该位代表的数据是否存在,存在位1,不存在位0;
- 具体每个比特位代表的数可以自己进行映射,比如如上的8位可以表示0-7的数是否存在;
3.Stream
Stream本质就是一个队列(阻塞队列),因此其是redis作为消息队列的重要支持;
4.Geospatial
用于存储坐标(经纬度);
存储一些点后,可以让用户给点一个坐标,然后从存储的点中查找,因此可以应用在"地图"功能中;
5.bitfield
位域,也叫位段,其和C语言中的位域非常相似;
c
struct User {
unsigned int gender : 1; // 1 bit
unsigned int age : 7; // 7 bit
unsigned int level : 4; // 4 bit
};其含义表示用若干比特位来表示一个字段值;位域本质是让我们精确进行位操作的一种方法;
相较于使用String,其空间占用更小,因此其可以作为数据压缩的一种方式;