修改一个蓝图并点击 Compile 时,引擎后台会发生一件很重的事情:类默认对象(CDO, Class Default Object)的重建。
在虚幻引擎(Unreal Engine)的开发语境下,
"worst offenders" (最严重的违规者/罪魁祸首)通常是指对游戏性能负面影响最大、最耗费硬件资源的因素。
规避(workarounds)"这些"offenders"
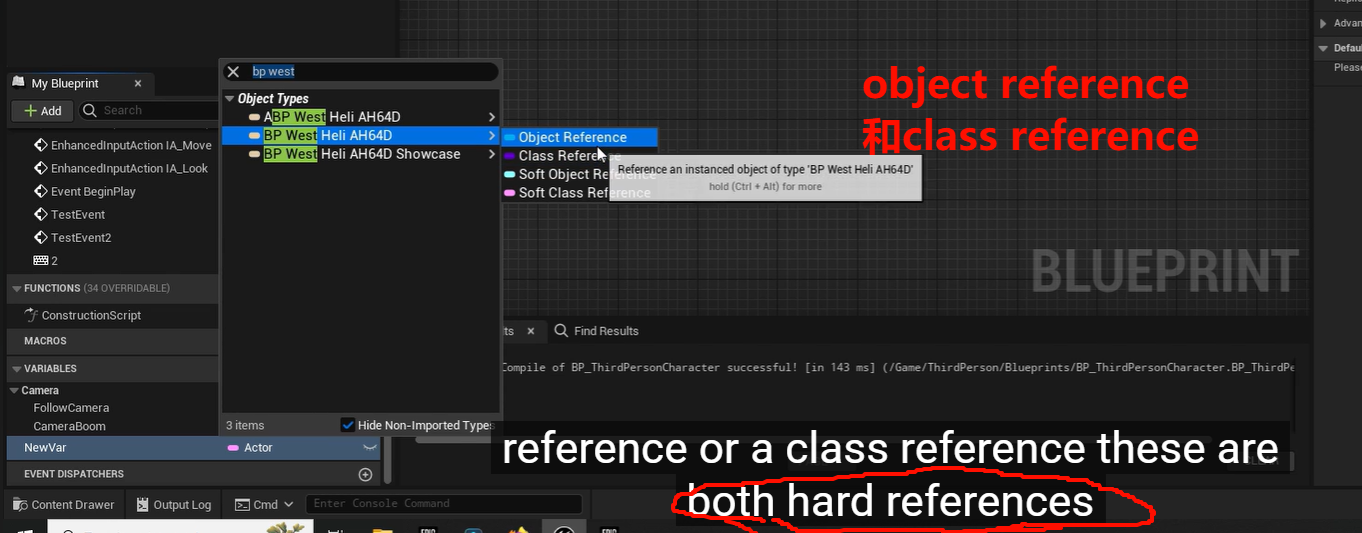
也是很荒谬,只是这个,,不对,也不是这么说,这是应该的,只是我没有意识到引用----"资源带入了 内存里",一个资产放到场景里,内存发生的改变-----
这是streamload的单位吗,这样的硬联系应该是一次性的全部带上
streamload 不是这个层级的----我编辑器的体验是最优先,自己都不用的自在,玩家自在也没意思了
从《自卑与超越》 的视角看,极度的羞辱可能转化为一种强烈的补偿动力。如果一个人能从"自卑感"中转化出超越的力量,那么这种羞辱就成了逼迫其产生深刻自我觉醒的"仁慈"5。
- 如果"仁慈"是以摧毁对方的自尊和基本安全感为代价,那它往往演变为纯粹的霸凌。
"Tough Love"(严厉的爱) 的极端变体,或者与 "Humility"(谦卑) 的哲学逻辑相关。
"Humiliation"(羞辱)和 "Humility"(谦卑)拥有相同的拉丁词根 humus (土地)。Merriam-Webster 指出,被"羞辱"意味着被贬低到尘土里,而"谦卑"则是保持脚踏实地。
- "To be humbled" :这是一个正向的表达。当一个人遭受挫败或羞辱后,如果能产生深刻的自我反省,英国人会说他被 "humbled" 了。这正是"羞辱转化成仁慈(成长)"的过程。
- "Eat humble pie" :这个地道的成语意为"不得不低头认错"或"承受羞辱"。虽然过程痛苦,但其结果通常被视为一种道德上的纠偏。
在英文讨论中,"Tough Love" 与 "Abuse"(虐待) 只有一线之隔。真正的 "Tough Love" 应该旨在让对方 "see their potential"(看到潜力) ,而不是 "inflict lasting emotional wounds"(造成持久心理创伤)。
- 清教徒传统(Puritan Legacy) :在英美文化的底层逻辑中,存在一种"苦难促成得救"的观念。在这种视角下,羞辱被视为一种 "sanctification"(成圣) 的开始。它强迫个体剥离自傲,回到诚实的起点。
- 职场中的 "Put someone in their place" :这是一个常见的表达,意为"让某人认清自己的位置"。虽然这通常带有贬义,但在管理学语境下,它有时被视为一种防止更大的系统性灾难的必要手段。
如果要在英文中表达类似的意思,可以使用以下说法:
- "Cruel to be kind":最接近的表达。出自莎士比亚的《哈姆雷特》,意为"为了仁慈而不得不表现得残忍"。
- "A wake-up call":侧重于"羞辱"带来的警醒作用。
- "Stripping away the ego":侧重于"羞辱"瓦解虚荣心,带来真实认知的过程。
在现代西方职场和心理学语境(尤其是 2020 年后的多元包容文化)下,"Humiliation" 极度容易被定性为 "Toxic"(有毒的) 。除非有极强的信任基础或特定的成长语境(如竞技体育),否则公开主张"羞辱是仁慈"可能会面临巨大的公关风险或法律指控。
sort 源自拉丁语 sors(份额、地位)。最初它是一个严谨的动词或名词,指"将事物按类别放置"。"这就是那一类事物(This is a sort of...)"降低精确度(Approximation)委婉与谦逊(Hedging)填充词(Filler word)
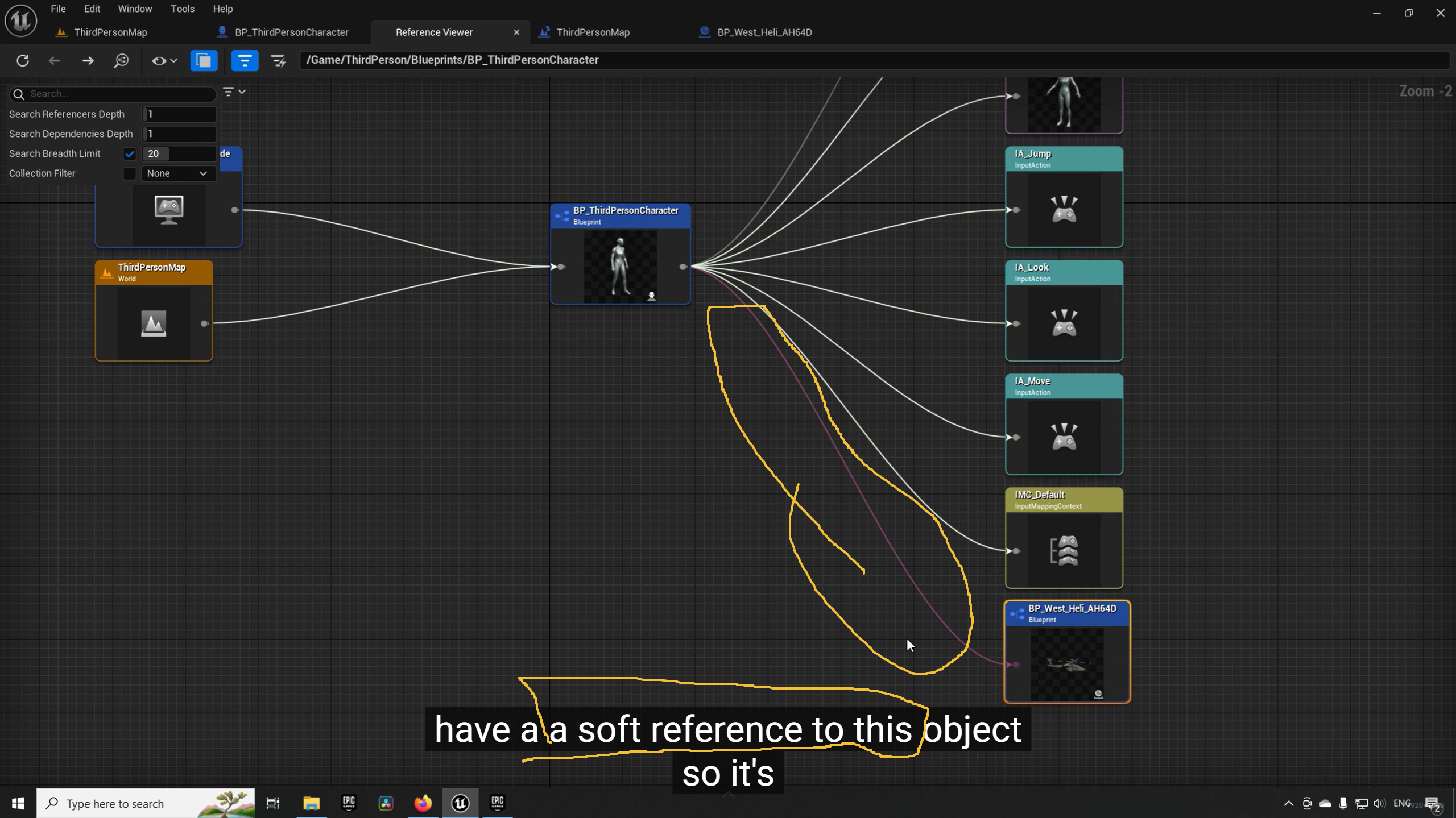
在虚幻引擎(Unreal Engine)中,
Soft Reference(软引用) 的核心价值确实就在于支持 异步加载(Async Loading)。
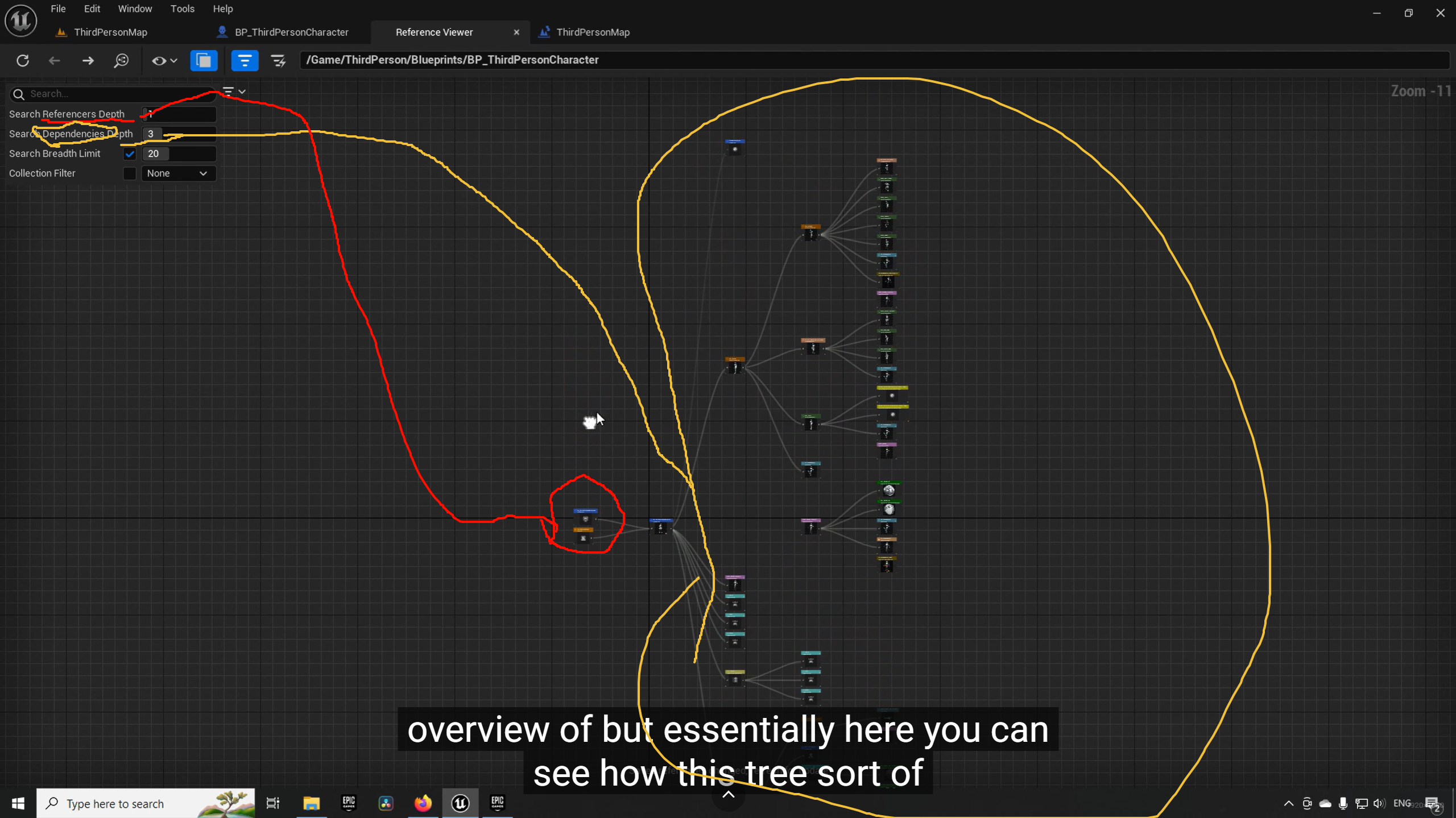
Reference Viewer(引用查看器) 截图来看,BP_ThirdPersonCharacter 指向 BP_West_Hell_AH64D 的那条红色虚线,正代表了这是一个软引用。
按需加载(Soft Reference 的作用):
软引用本质上只是一个路径字符串。
软引用真正需要用到它时,必须调用 Async Load Asset 节点。
完成后,
得到一个具体的对象指针,
才能在场景中生成(Spawn)

韩语并非像中文一样每个音节(字)都自带独立含义。韩语是
拼音文字,绝大多数情况下必须组合成词才有意思。只有汉字词的单字才有独立意思,但现代韩语多将词汇组合使用。
- 拼音结构(必须组合): 韩语由字母组合成方块状的音节(如 ㅎ+ㅏ+ㄴ=한, ㄱ+ㅜ+ㄱ=국),这些音节拼在一起才形成具有特定含义的词汇(如 한국 - 韩国)。单个音节本身通常没有实际定义,除非它是汉字词。
- 汉字词(有单字意思): 韩语约 60%-70% 词汇来自汉字(汉字词 ),这些词的一个韩文字对应一个汉字,具有独立意思(如 학 - 学, 생 - 生),通常组合使用,如 학생(学生)。
- 固有词(无单字意思): 韩语本土词汇通常由两个或更多音节构成才能表达完整意思,单个音节无法独立表达(如 아버지 - 爸爸)。


https://creatrip.com/zh-CN/news/8536
In Chinese, characters are usually written as a single block. But in the Korean character "아" (A), you see two parts because of how the Korean alphabet (Hangul) works:
- The Left Side (ㅇ): This is the consonant part. In Korean, every syllable must start with a consonant. When a word starts with a vowel sound (like "Ah"), the circle "ㅇ" is used as a silent placeholder to fill the spot.
like "오" (O) or "우" (U),
안 한
These two follow the same "Lego" building principle, but they add a
third part at the bottom called a Batchim (final consonant).
안 (An)
This is a "left-right-bottom" structure:
- Top Left (ㅇ): The silent placeholder (since the sound starts with a vowel).
- Top Right (ㅏ): The vowel "Ah."
- Bottom (ㄴ): The final consonant "n" sound.
- Result: ㅇ + ㅏ + ㄴ = 안 (An)
어 by itself cannot be pronounced as "seo."
"seo " sound is written as 서
없 is pronounced as "eops" (or "eop") .
This character is a great example of a "three-story" building with a double final consonant at the bottom. Here is how it breaks down:
- Top Left (ㅇ): The silent placeholder.
- Top Right (ㅓ): The vowel "eo" (sounds like uh).
- Bottom (ㅄ): This is a special double consonant called a layer . It combines ㅂ (b/p) and ㅅ (s).
By itself: If you say the word alone (like in 없다 - eop-da ), you usually only hear the "p" sound: "Eop." The "s" stays silent.
-
With a vowel: If the next syllable starts with a vowel (like in 없어 - eop-seo ), the "s" sound "jumps" over to the next spot. That's when it sounds exactly like "eop-seo."
-
虽然你在蓝图中使用了异步加载,但在编辑器模式下,引擎的资源管理器(Asset Registry)已经维护了一套完整的引用关系,加载过程往往只是在内存中完成指针的连接,而非真正的磁盘 I/O。
从 Player Mode(尤其是独立进程或打包后)启动时,引擎必须经历完整的生命周期初始化:
而在编辑器内,这些基础环境是常驻内存的,
过
软引用(Soft Reference) 这种方式来替代 强引用(Hard Reference),从而极大提升了编辑器内点击"Compile"按钮的速度。
编译器在编译当前蓝图时,必须同时加载并验证被引用的蓝图及其所有依赖项。如果你的直升机蓝图又引用了武器系统,武器系统又引用了特效......这会产生极其恐怖的递归加载。
软引用(图中方式) :你使用的是 Async Load Class Asset ,它对应的输入是一个软路径(Soft Object Path)。对于编译器来说,这只是一个"字符串地址"。它不需要去打开或校验那个庞大的直升机资产,
软引用下 :点击 Compile 几乎是秒过(编译器的验证负担极小)
A 引用 B,B 引用 A,导致编译器反复校验。
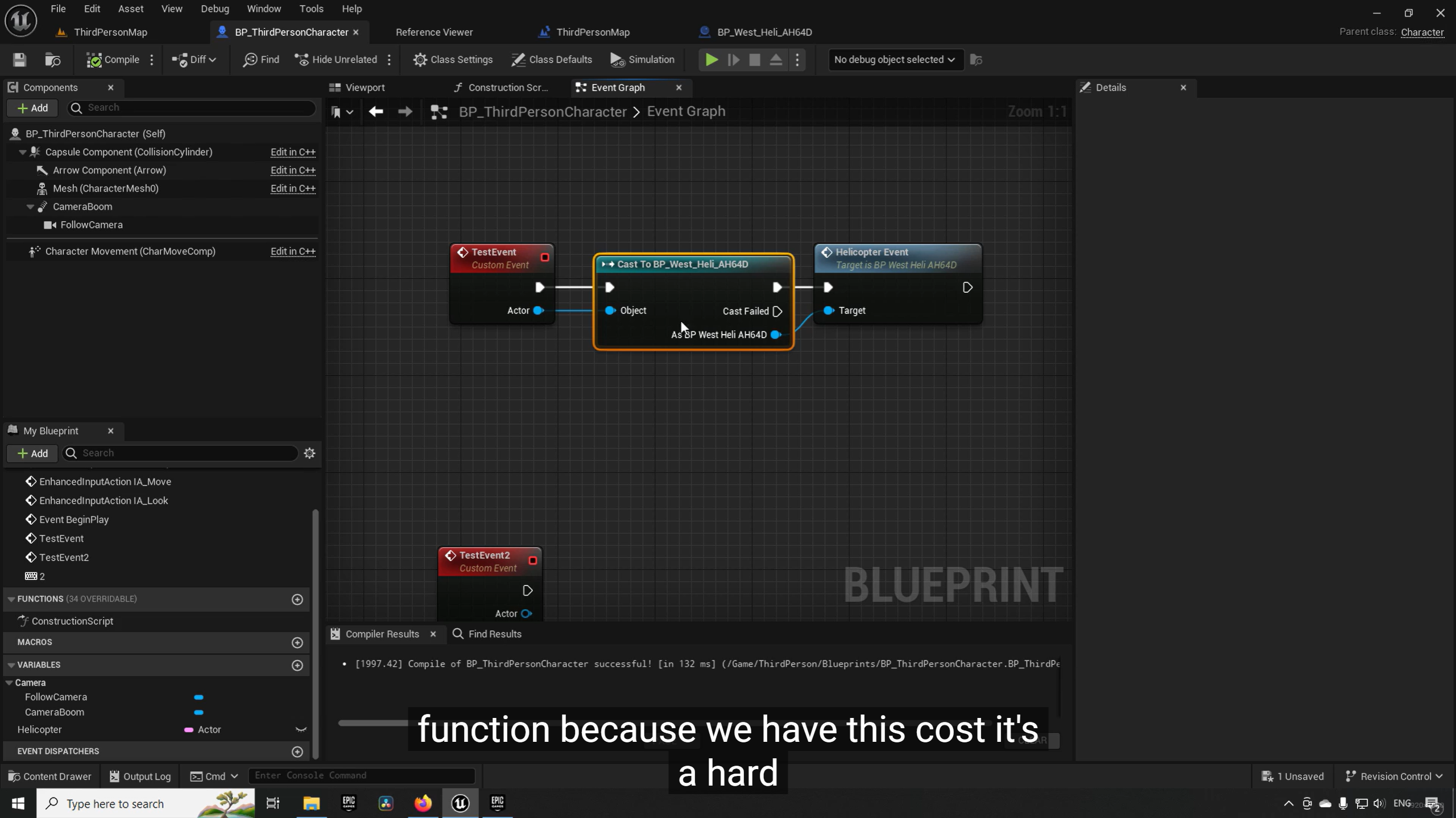
虚幻引擎中,Cast(类型转换)
Cast 是一种"强耦合"
当你放置一个 Cast To BP_West_Heli_AH64D 节点时,你是在告诉编译器:"这个 BP_ThirdPersonCharacter 必须知道 BP_West_Heli_AH64D 的所有细节。"
如果你想保持编辑器内极速的编译体验,通常会用以下两种方式替代直接 Cast:
- Blueprint Interface(蓝图接口):最推荐的方法。你只需要向物体发送一个"开火"指令,不管它是不是直升机,这样编译时完全没有依赖。
避开这种直接指向具体子类蓝图的 Cast,是保持 Editor 丝滑的核心技巧。
Cast<T>() 用于 安全地将 UObject 转换为子类 ,失败返回 nullptr,避免崩溃。
内部使用 IsA() 检查继承关系 ,比 dynamic_cast<> 更快。
在 GAS 里,用于获取 AbilitySystemComponent 和 AttributeSet 。
StaticCast<> 不进行检查 ,适合已知类型 的转换。
DynamicCast<> 适用于 普通 C++ 类 ,但不适用于 UObject。
蓝图虚拟机 与 C++ 原生编译 之间的区别。
纯 C++ 开发中,如果你只是做一个指针类型的强转(比如 static_cast ),只要你包含了头文件,编译器确实处理得很快。但在 UE 的蓝图系统 中,Cast 节点的行为远不止"类型转换"那么简单,
蓝图的"头文件"是整个资产(Hard Reference)
在 C++ 里,你只需要 #include "Helicopter.h" (头文件通常很小)。
但在蓝图中,没有"头文件"的概念。当你 Cast To BP_Heli 时,等同于你 #include "整个BP_Heli蓝图资产" 。
连锁反应 :如果 BP_Heli 引用了一个 2GB 的网格体、50 个特效、10 个音效,那么当你编译 ThirdPersonCharacter 时,UE 编辑器为了确保这个 Cast 是合法的,必须把 BP_Heli 及其引用的这 2GB 资源全部在后台"静默加载"或校验一遍。
循环依赖的"死锁"(Circular Dependency)
这是 C++ 里不太常见但在蓝图中极易发生的灾难:
- 角色蓝图 Cast 到了 直升机蓝图(为了上飞机)。
- 直升机蓝图 里的某个逻辑又 Cast 回了 角色蓝图(为了获取驾驶员信息)。
- 结果:当你点击编译角色时,它要先验证直升机;验证直升机时,它发现要先验证角色。编辑器会陷入无穷的递归校验中,导致编译进度条卡死,或者引发莫名其妙的编译失败。
在虚幻引擎中,蓝图(Blueprint)需要使用Cast(类型转换/投射)节点的情况通常是为了访问特定蓝图子类中定义的特有变量、函数或事件
玩家角色(Player Character)、游戏模式(Game Mode)或游戏实例(Game Instance)常驻内存,Cast它们来读取关键数据时开销较小。
Cast(类型转换) 的核心作用是验证并访问一个对象的特定子类成员。
当你手头有一个通用对象(如 Actor),但你需要调用它在特定子类(如 BP_Player)中定义的变量或函数时,
通过通用接口(如 GetPlayerCharacter 或碰撞检测 OtherActor )获取对象引用时,引擎只知道它是一个基础类(如 Character 或 Actor)。
修改玩家的 CurrentHealth 变量,但该变量只定义在 BP_MyCharacter 蓝图中,而不在基础的 Character 类中。
操作 :将 Character 引用 Cast 到 BP_MyCharacter ,成功后即可访问该变量。
Cast 可以作为一种逻辑检查,确认某个对象是否属于特定的类型。
子弹碰撞到了一个 Actor,你只想让这个 Actor 在它是"敌人"时才掉血。
:尝试将 OtherActor Cast 到 BP_Enemy 。如果 Cast 成功(执行上方的输出口),说明它是敌人;如果失败(执行 Cast Failed 口),说明它可能是墙壁或装饰物。
使用 GetGameMode 节点后,必须 Cast 到你自定义的 BP_MyGameMode ,才能调用你在里面写的自定义逻辑或获取得分数据。
什么时候不该用 Cast?
如果你发现多个完全不同的蓝图(如"门"、"灯"、"爆炸桶")都需要执行相同的操作(如"被激活"),建议改用 蓝图接口(Blueprint Interface)。接口可以实现解耦,
避免复杂的 Cast 依赖
"Audit" in Chinese is primarily translated as
审计 (shěnjì) for professional, official examinations of financial records. It can also be translated as 查账 (cházhàng - checking books) or 审查 (shěnchá - investigation/review) depending on the context of the audit.
并不是创建任意蓝图都会自动出现对应的Cast To选项,只有被标记为 可实例化的蓝图类(Blueprint Class),才会在 Cast 节点的候选列表中显示专属的Cast To [蓝图名]选项。
哪些蓝图会生成专属Cast To选项?
- 基于 Actor/Pawn/Character/Component 等可实例化类的蓝图
比如你截图里的BP_WestHeiLAH64D(直升机蓝图,基于 Actor/Pawn)、角色蓝图(基于 Character),这类蓝图是 可在场景中创建实例的,引擎会为其生成专属 Cast 节点。 - 蓝图接口(Blueprint Interface)不会生成
接口仅定义函数规范,无实例,因此没有Cast To 接口,而是用Implements Interface?节点判断是否实现接口。 - 蓝图宏库(Blueprint Macro Library)不会生成
宏是逻辑片段的复用,不是类,无实例可 Cast。 - Widget 蓝图会生成
UI 控件蓝图基于UserWidget(可实例化),会有Cast To [Widget蓝图名]选项。
UE 蓝图的「上下文敏感(Context Sensitive)」特性
节点的输出引脚会限定可连接的内容,且右键 / 拖拽引脚时,仅显示与引脚类型匹配的节点、变量、函数等选项
仅显示该蓝图类的成员 :包括其自定义的事件(如helicopter interface Event)、变量(如testHelicopter)、函数;
这个工具(通常是集成了类似 EnableLoopback 的功能)的作用是: 帮你手动解除这个限制,让选中的 UWP 应用能够连上代理。
你需要操作吗?
- 如果你发现 :微软商店打不开、Xbox 登录不上、或者某个从商店下载的应用连不上网,你就需要点击这个 "UWP 工具"。
- 操作步骤 :
- 点击该按钮,会弹出一个应用列表。
- 勾选你想让它走代理的应用(如
Microsoft Store)。 - 点击 Save Changes(保存修改)。
- 重新打开应用,通常就能正常联网了。
总结 :这是专门用来解决"微软商店及其应用无法使用代理"的 一键修复工具。
两边都能实现同样的功能,但对于普通用户来说,左边的 Global Extend Config (Merge) 是官方推荐的最佳方案。
Global Extend Config (使用 YAML 语法)
格式非常固定(就是你之前看到的 prepend-rules )。你只需要列出进程名,Clash 会自动帮你合并到现有的订阅规则里。
Global Extend Script (使用 JavaScript 脚本)
-
性质 :这是编程式配置。
-
操作方式:你需要写一段 JS 代码,去遍历、修改、甚至重组整个配置对象的逻辑。
-
代码长这样(非常复杂) :
javascriptfunction main(config) { config.rules.unshift('PROCESS-NAME,WeChat.exe,DIRECT'); return config; }
- 官方设计初衷:左边就是为了方便用户快速添加"直连/代理"规则而设计的。
- 容错率高:YAML 格式清晰,不容易写错。
两个进程都建议写进去 ,但最关键的是游戏主体进程。
启动器(Launcher)和游戏主体(Game Client)通常是两个独立的进程,Clash 无法通过一个名字控制两个程序。
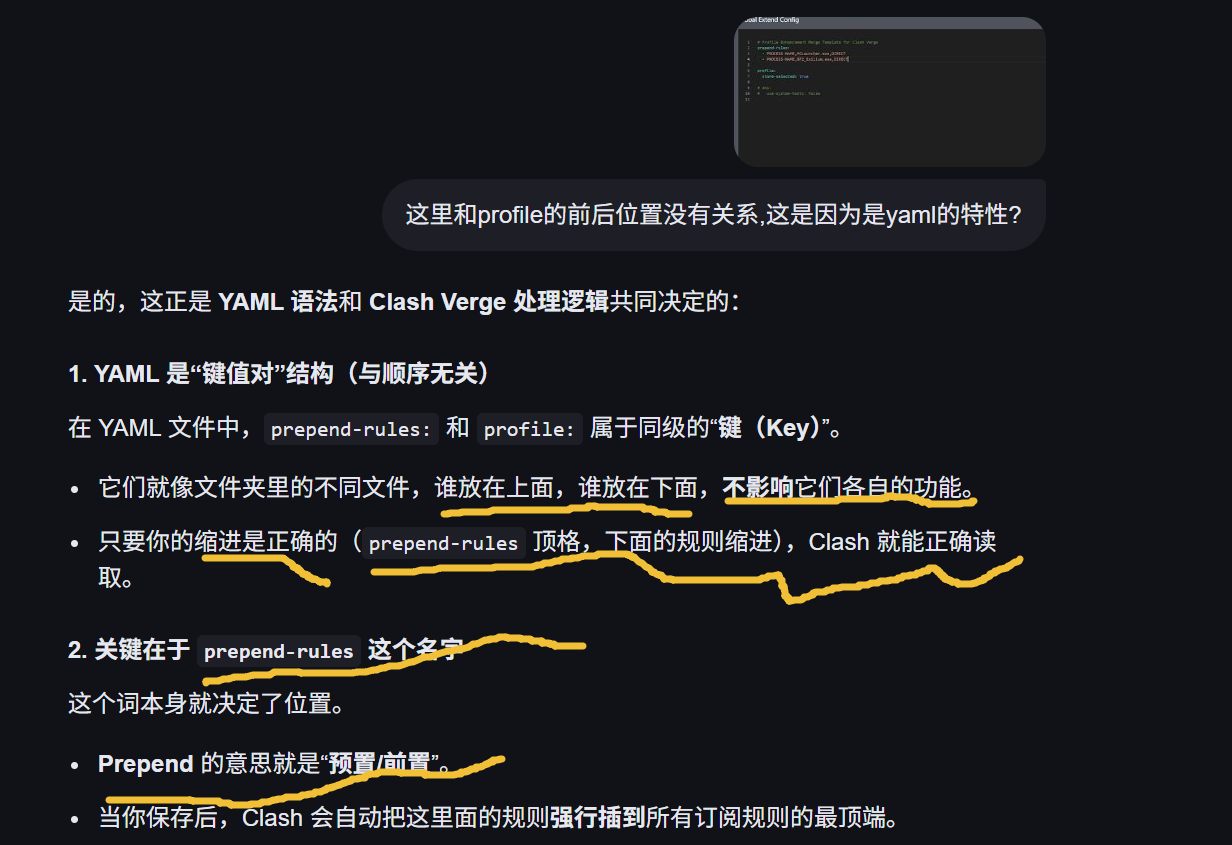
prepend-rules 有时可能因为订阅文件的覆写逻辑而不生效。
如果 Merge(配置合并)无效,改用右边的 Script(扩展脚本) 是最稳妥的办法。脚本可以直接操作配置数组,强制将你的游戏进程插入到规则的最前面。
为什么 Script 比 Merge 更管用?
- 执行顺序 :在 Clash Verge 的处理链中,扩展脚本会在扩展配置之后执行。如果 Merge 里的规则被订阅文件覆盖了,脚本可以再次把它们"捞"回来并强行放在最顶端。
- 直接操控 :脚本模式是直接对最终发给内核的配置对象进行编程。
config.rules.unshift语法保证了你的规则永远是第一顺位被检查的。
return 之后的代码永远不会运行。
只能填
.exe 文件名 (即进程名), 不可以填完整路径。
虽然你想更精确,但 Clash 的内核(Mihomo/Meta)在匹配 PROCESS-NAME 时,逻辑是只检查进程列表里的名称,不识别文件夹路径。
为什么不能填完整路径?
- 内核限制 :Clash 的规则语法中,
PROCESS-NAME对应的是系统任务管理器里的"映像名称"。 - 匹配失败 :如果你填了
D:\Games\...\GF2_Exilium.exe,Clash 会去寻找一个名字就叫这串长路径的进程,
DNS 污染/Fake-IP: 如果开启了 Enhanced-Mode: Fake-IP,Clash 会先给游戏一个虚假 IP。如果此时没有命中任何 DIRECT 规则,流量就会被封装进隧道发往代理服务器。
DOMAIN-KEYWORD (域名关键词)
- 监控对象 :应用访问的 URL/域名。
- 逻辑:只要网址里包含这几个字母,就触发。
- 例子 :
DOMAIN-KEYWORD,gf2,DIRECT- 匹配:
://haoplay.com(包含 gf2) - 匹配:
://sunborngame.com(包含 gf2)
- 匹配:
- 优点:非常轻量,不需要开启 TUN 模式也能生效(系统代理即可)。
- REGEX (正则表达式)
在 Clash 中通常指PROCESS-NAME-REGEX或DOMAIN-REGEX。
- 监控对象 :进程名 (.exe)或复杂的域名结构。
- 逻辑:它不仅仅是包含关系,还可以利用符号进行复杂匹配(如忽略大小写、开头结尾等)。
- 例子 :
PROCESS-NAME-REGEX,.*(?i)gf2.*,DIRECT- 匹配:
GF2_Exilium.exe(包含 gf2,且(?i)强制忽略大小写) - 匹配:
gf2_launcher.exe
- 匹配:
- 区别 :Regex 包含 Keyword 的功能,但更强大。 比如 Keyword 无法做到"忽略大小写"或"必须以某字母开头",但 Regex 可以。
prepend-rules:
- DOMAIN-KEYWORD,gf2,DIRECT # 拦截所有含 gf2 的网址
- PROCESS-NAME-REGEX,.*(?i)gf2.*,DIRECT # 拦截所有名含 gf2 的程序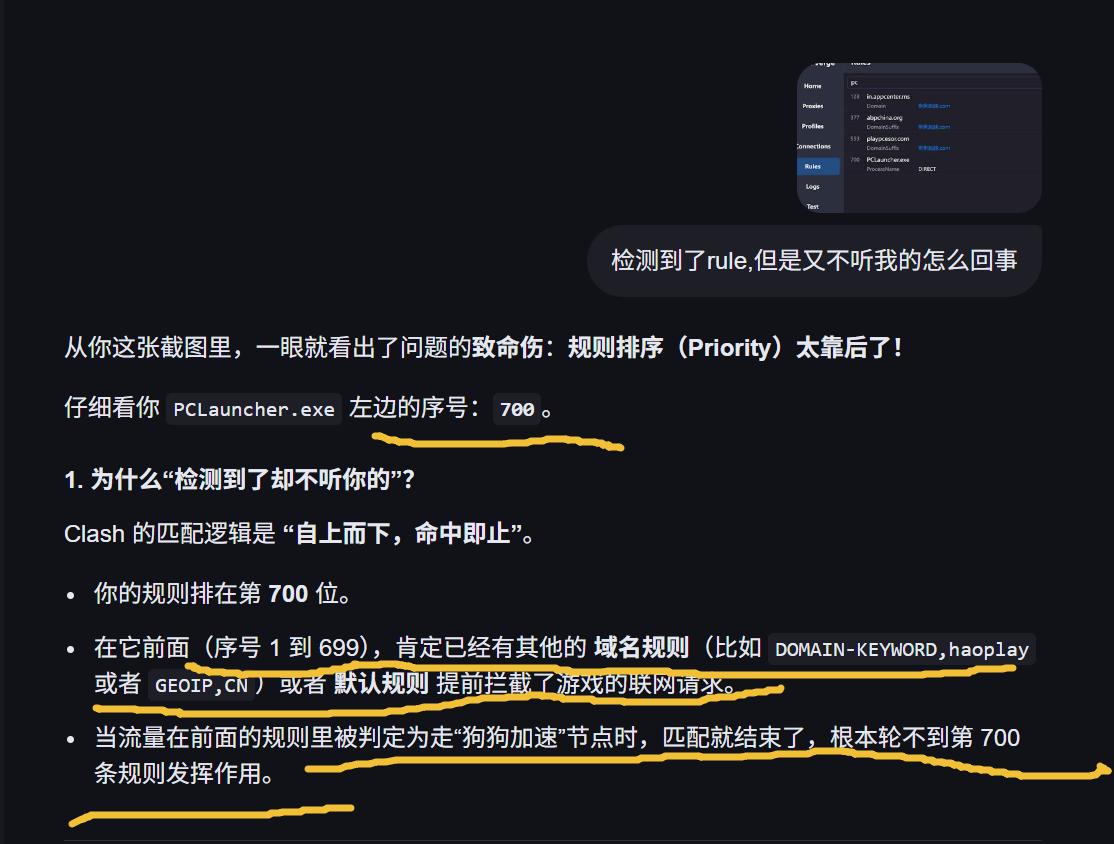
为了消解不主动思考带来的认知失调,意识必须不断生长出更复杂的退行性防御机制(如更精密的自欺逻辑、更稳固的群体认同感)。
我根本没有意识,,这是伪存在。
Like the diffusion,but i always think as organization.
纵欲不是为了获得满足,而是为了维持"寻找满足"的路径。这种"重复"本身就是一种稳态机制。
Same in diffusion, different in start point
Keep game busy in micro step,keep game loosy in long-term step .
在日常语境中,成长隐含着一个预设的"终点"或"完善态"。
"对明天没有规划"这种意识的产出?为何
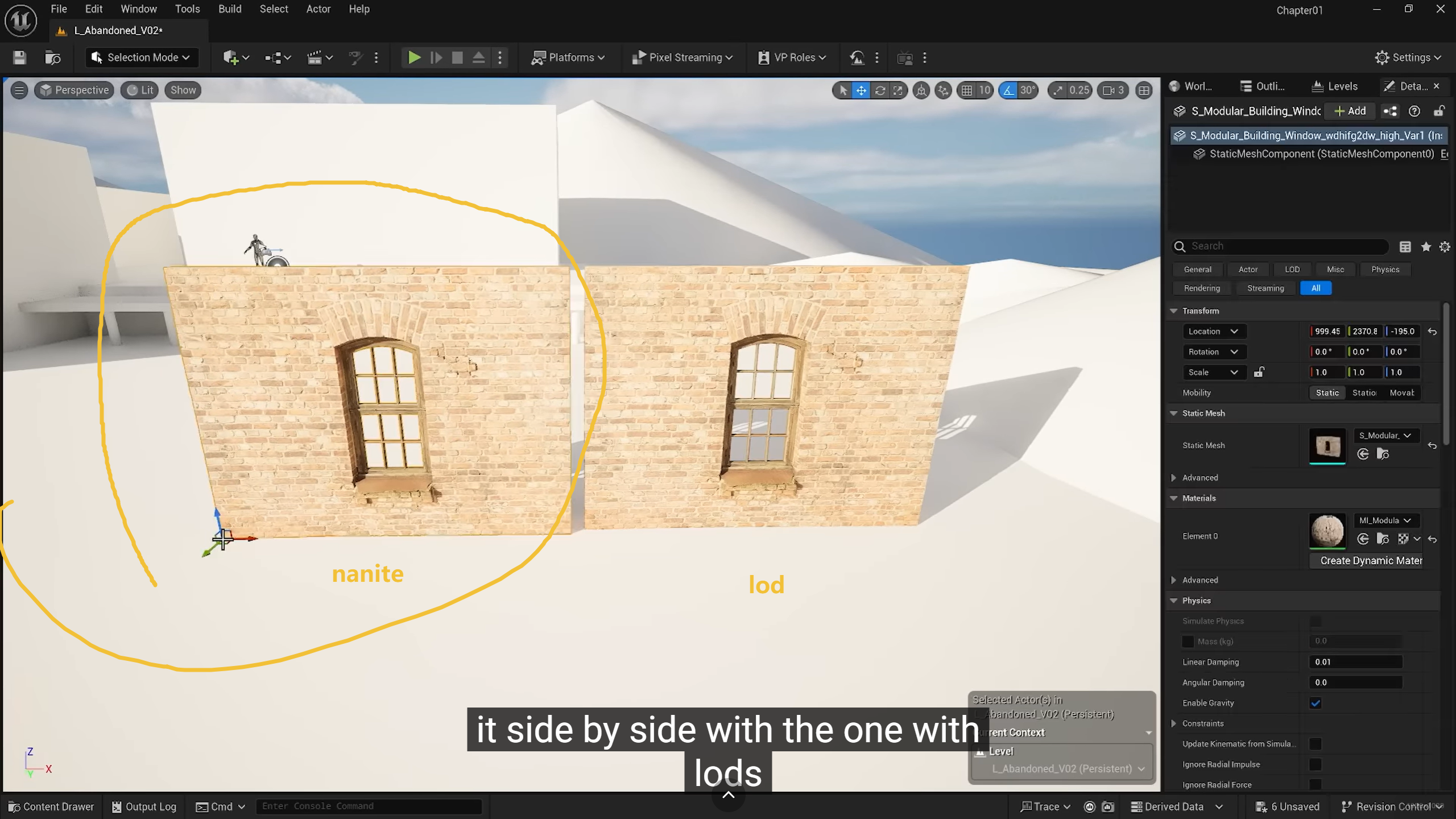
- Nanite 是只读的优化渲染 :Nanite 的核心是将模型预处理成一种特殊的"簇(Cluster)"结构,并根据视口距离实时切换显示的细节。这本质上是一种高度压缩且只读的显示技术。
- DCC 需要实时修改拓扑 :在 Maya 或 Blender 中,你的任务是编辑。当你拉动一个顶点、切割一刀或进行平滑细分时,模型的数据结构必须是原始的、可寻址的。如果用 Nanite 结构存储,每一次编辑都需要重新计算复杂的簇索引和流式数据,这会导致操作产生巨大的延迟,反而更卡。
使用
Nanite 的物体,答案是肯定的:你不再需要手动制作或导入传统层级的 LOD(Level of Detail)了 。
Nanite 的核心本质就是一套自动化的、连续的、像素级的 LOD 系统。
传统 LOD 在切换时会产生瞬间的 CPU 开销,而 Nanite 将这些计算交给了 GPU(Compute Shader)
HLOD (Hierarchical LOD)。
Nanite 目前对半透明材质(如玻璃、水)的支持还在完善中,
CPU 只发一条总指令:"去读这个缓冲区(Buffer)"。
The CPU no longer says: "Draw Tree A at (X,Y), then Draw Tree B at (Z,W)."
Instead, it says: "Here is a massive list (Buffer) of 1 million trees. I'm going to do something else now. You (GPU) figure out which ones to show."
What CPU does: It sends a Resource Descriptor (a pointer) to the GPU. This pointer points to the "Big Buffer" containing all instance data (matrices, material IDs, etc.).
- The "Kick-off": It issues a single
Dispatchcommand to start the Compute Shader and a singleDrawIndirectcommand.
The GPU maintains two types of buffers in its VRAM:
- The Source Buffer (Static): A massive array of every object/cluster in the level.
- The Argument/Index Buffer (Dynamic): A "Work List" that the GPU clears and refills every single frame.
Culling Phase (Compute Shader): Thousands of GPU threads look at the Source Buffer simultaneously. Each thread checks one object: "Are you in the camera frustum? Are you occluded?"
The "Switch" (Parallel Logic): If an object passes the test, the GPU thread performs an Atomic Add to a counter and writes that object's Index into the "Work List" (the dynamic Index Array).
nanite会把整个高模塞入vram?
不会。
Nanite 采用的是虚拟化几何体(Virtualized Geometry)技术,它只会在显存(VRAM)中加载当前画面可见且必要的部分,而不是将整个高模完全塞入显存。
簇流送(Cluster Streaming): Nanite 会将高模分解成无数个小的"簇"(Clusters),每个簇通常包含 128 个三角形。系统会根据摄像机的距离、视角和遮挡情况,只从硬盘流送(Streaming)当前画面所需的特定簇到显存中。
流送池(Streaming Pool) 。它会预测玩家的移动路径,提前向系统发出"申请",把即将用到的****几何数据页(Pages)调入缓存。
只有 SSD 的高随机读取速度才能支撑在玩家转身或快速移动时,瞬间从硬盘加载数以千计的小型数据包而不掉帧。
Nanite 的设计初衷就深度依赖于固态硬盘(尤其是 NVMe SSD)。
瞬间从硬盘加载数以千计的小型数据包而不掉帧。
内存中转: 数据首先从硬盘读入系统内存(RAM),由 CPU 进行简单的解压或初步处理,然后迅速推送到显存中。
DMA (直接内存访问): 现代渲染技术利用了类似 DirectStorage(在主机上则有类似的底层 API)的技术,允许 GPU 绕过 CPU 的繁琐干预,直接从系统内存甚至存储设备中抓取数据。
- CPU/引擎 发现你需要看某个细部,大喊:"我要这几个编号的簇!"
- SSD 迅速响应,把压缩好的数据包扔出来。
- DMA 管道 像高速公路一样把数据送进显存。
- GPU 瞬间解压并把它"贴"在屏幕对应的像素上
流送延迟(看到模糊到清晰的跳变),通常是因为SSD硬盘速度低或者显存池设得太小了
nanite因为需要更多的cluster,所以static mesh资产往往比没用nanite之前的原模型更大
增加了硬盘的存储需求
有了cluster就不需要原膜的存在了,这样的话就和lod是同样的做法
The Korean word 잊 (meaning "forget" stem) is pronounced it when it stands alone or is followed by a consonant, as the 'ㅈ' acts as a 'ㄷ' (t) sound at the end of a syllable. If followed by a vowel, the**'ㅈ' shifts to the next syllable, creating a "j" sound** (e.g., 잊어 -> i-jeo).
按需流送: 只有当前画面需要的页面才会被解压并加载到显存。这意味着 100GB 的原始高模,可能只有几十 MB 的压缩页面正在被流送。
- 精度折损: Nanite 使用**量化(Quantization)**技术将顶点的绝对坐标转换为相对于簇中心的相对坐标 。
- 空间换带宽: 通过减少存储坐标所需的比特数(bit),极大缩小了数据量。
- 无缝衔接: 这种压缩在算法上保证了即使相邻簇的精度不同,边缘也能完美对齐,不会出现裂缝。
显存常驻: 进入显存的数据通常仍处于一种GPU 可直接读取的压缩格式。
可控丢弃: 开发者可以通过 Trim Relative Error 等设置,强制剔除那些人眼难以察觉的微小细节数据。
这能显著降低资产在磁盘和显存中的占用。例如,一个 100 万面数的 Nanite 模型在磁盘上可能仅占 14MB,甚至比一张 4K 贴图(约 22MB)还要小。
| 特性 | 传统高模 (FBX/OBJ) | Nanite 高模 |
|---|---|---|
| 磁盘占用 | 巨大 (数 GB 级别) | 极小 (高度压缩页面) |
| 显存占用 | 全部加载 (容易溢出) | 只加载可见页面 |
| 解压位置 | CPU (预加载时) | GPU (渲染瞬间) |
| LOD 切换 | 明显跳变 (Popping) | 像素级平滑过渡 |
文本格式与冗余数据 (ASCII vs. Binary)
- OBJ 是文本: 很多原始高模是 OBJ 格式,它是纯文本。每一个顶点坐标(如
v 1.234567 2.345678 3.456789)都要占用几十个字节的字符空间。 - 重复信息: 传统格式往往会重复存储顶点信息。如果一个顶点被 6 个三角形共享,某些不规范的导出方式可能会把这个点的数据存 6 遍。
传统高模(如 FBX 或 OBJ 格式)磁盘占用巨大,主要是因为它们的
存储方式非常"老实"且冗余。
缺乏针对性的几何压缩
- 全精度存储: 传统格式通常使用 32 位浮点数 (Float32) 存储每个坐标。对于一个数千万面数的模型,仅仅是位置坐标(XYZ)就会吃掉海量空间。
- Nanite 的对比: Nanite 使用了量化(Quantization) 。它不存储绝对坐标,而是存储相对于物体中心的小整数(比如 12 位或 16 位),空间占用直接减半甚至更多。
Nanite 优化了传统高模包含大量的索引缓冲(Index Buffer),用来告诉显卡哪些点连成三角形。
利用算法动态生成或极度简化了这些拓扑信息。
切成"簇"之后,它不再存绝对坐标,而是存相对于这个簇中心的位移 。因为簇很小,位移数值就很小,可以用 12位甚至更低的定点数 来存。
坐标量化(这是大头)
- 坐标量化(通常指计算机/图像处理):
- 本质: 是"连续到离散"的转换。
- 做法: 把无限精确的坐标点映射到有限的网格(像素)上。比如把 1.234 映射为 1。
- 目的: 为了压缩数据或让计算机能够处理。
- 经济学量化(Quantitative Economics):
- 本质: 是"现象到数学"的转换。
- 做法: 把复杂的经济行为(如消费欲望、通胀预期)变成可计算的指标(CPI、效用函数),并用统计模型(计量经济学)找规律。
- 目的: 为了预测趋势、评估政策或进行高频交易。
相同点:精度损失,但为了更可预测
**量化交易(Quantitative Trading)**就是把"靠感觉炒股"变成"靠数学公式炒股"。
策略数字化(规则化)
- 普通交易者:觉得今天苹果股票跌了不少,该反弹了,买点。
- 量化交易者:写下代码------"如果 5 日均线跌破 20 日均线,且成交量萎缩 20%,则触发买入信号。"
概率获胜(去人性化)
- 人会恐惧和贪婪,量化程序不会。它在全市场几千只股票里,像雷达一样扫射符合条件的信号。
- 它的目标不是抓到大牛股,而是寻找高概率的小机会,通过成千上万次交易,积少成多。
计算驱动(工程化)
- 回测: 在代码运行前,先用过去 10 年的历史数据跑一遍,看看这个逻辑在历史上能不能赚钱。
- 执行: 计算机毫秒级下单,捕捉那些人类反应不过来的价差(比如高频交易)。
Nanite: 在导入切片时,它会识别出哪些"簇"是相似或重复的。它只保留一份基础数据,其他的只是引用。这在重复纹理或结构复杂的工业/建筑模型中效果极其夸张。
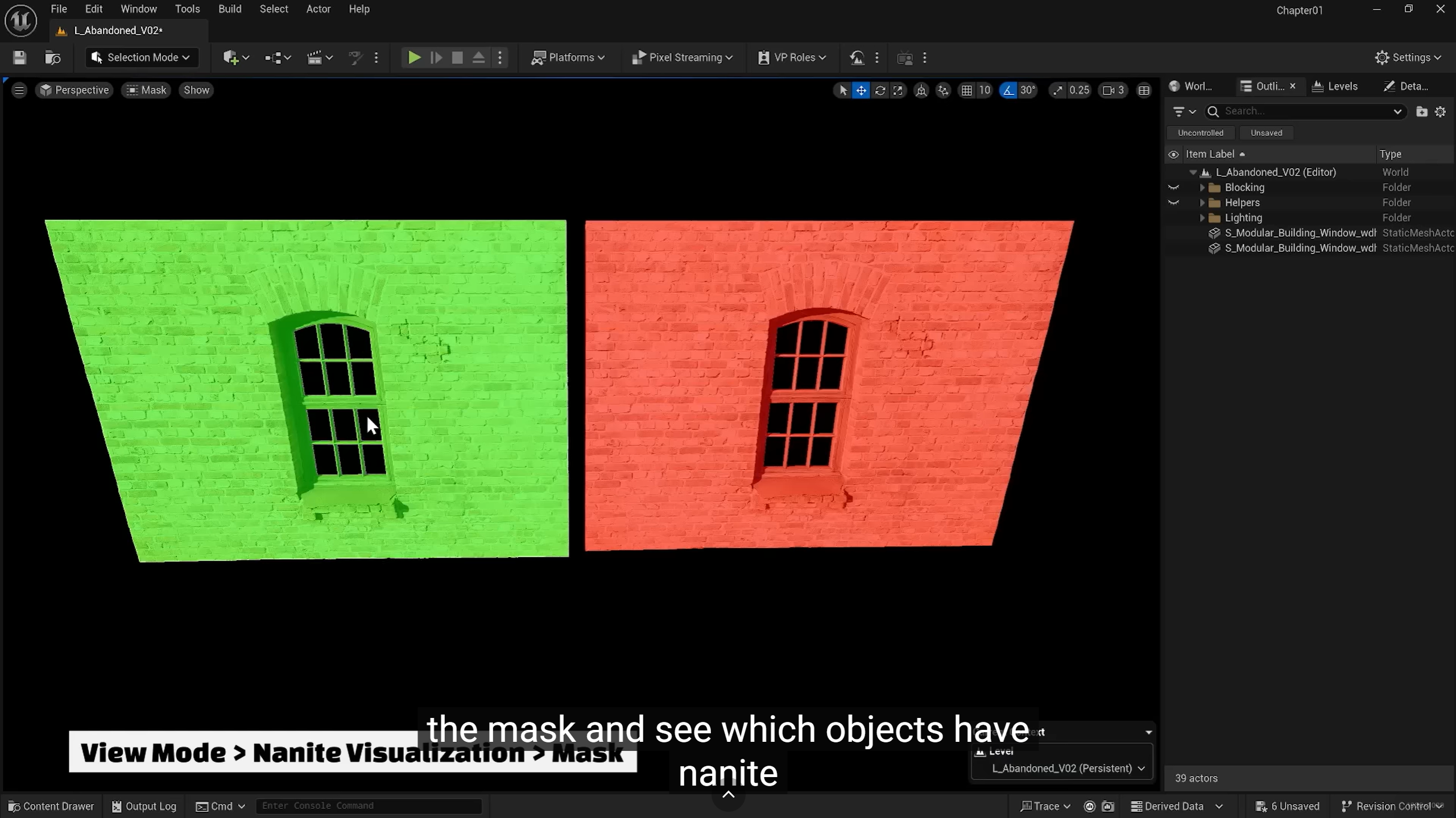
nanite enabled--green
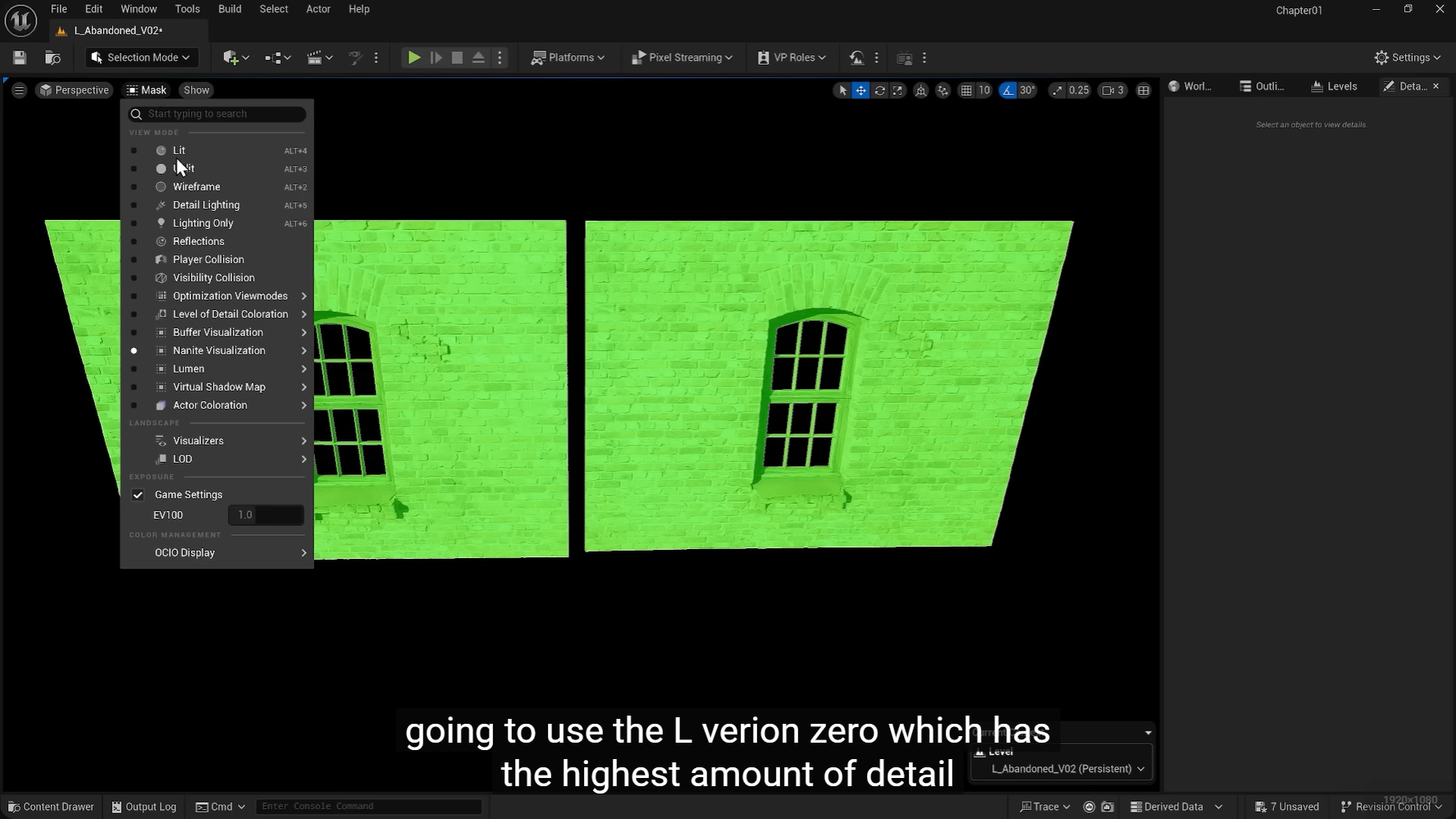
默认用lod0
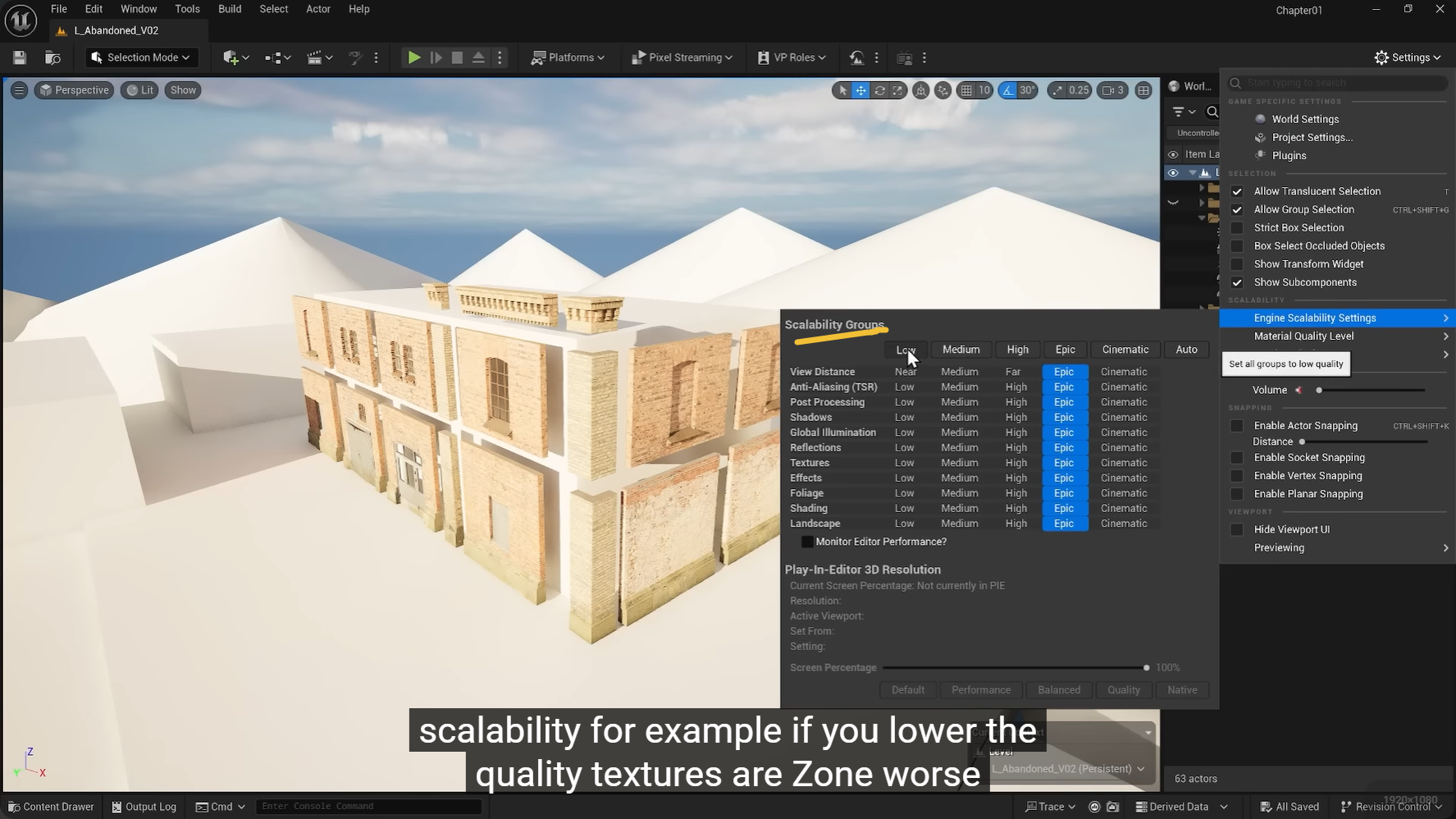
流送池就像是一个"高速缓存区"。当引擎发现你需要看某个高模或高清贴图时,它会从硬盘把数据"流"进这个池子里。
- 如果池子够大: 所有当前可见的细节都能完整显示。
- 如果池子太小: 就会出现图中左上角那行红字 "TEXTURE STREAMING POOL OVER BUDGET"(贴图流送池超出预算)。此时引擎会强制降低贴图分辨率,甚至导致 Nanite 细节加载缓慢。
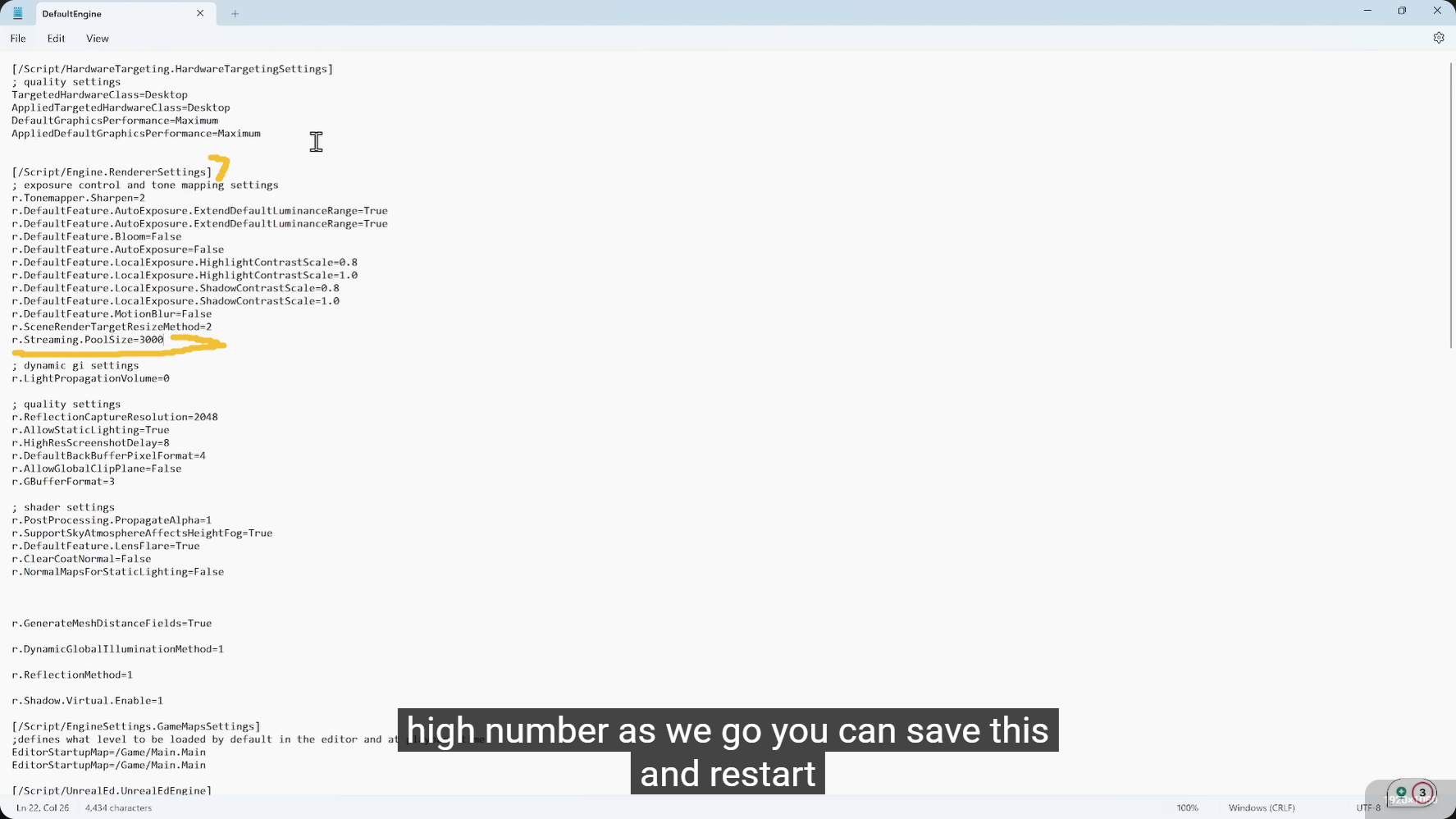
r.Streaming.PoolSize 是一个至关重要的设置,它直接决定了引擎可以拿多少显存(VRAM)来存放流送数据(主要是贴图和 Nanite 资产)。
UE5 默认通常只给 1000MB 左右(视显卡而定)。对于现代高模和 4K/8K 贴图来说,这非常容易爆掉。
开发者通常会根据显卡实际显存来调大它。例如,如果你有 8GB 显存,给它分配 3000 或 4000 是很常见的做法,这样能消除红字警告并保证画质。
Nanite 有自己专门的流送池设置(如 r.Nanite.Streaming.PoolSize ),但通常整体的纹理流送池压力最大。
r.Streaming.PoolSize 4000 (假设你有 8G 以上显存)
这能立刻解决红字问题,让你在编辑器里看到最清晰的模型细节。
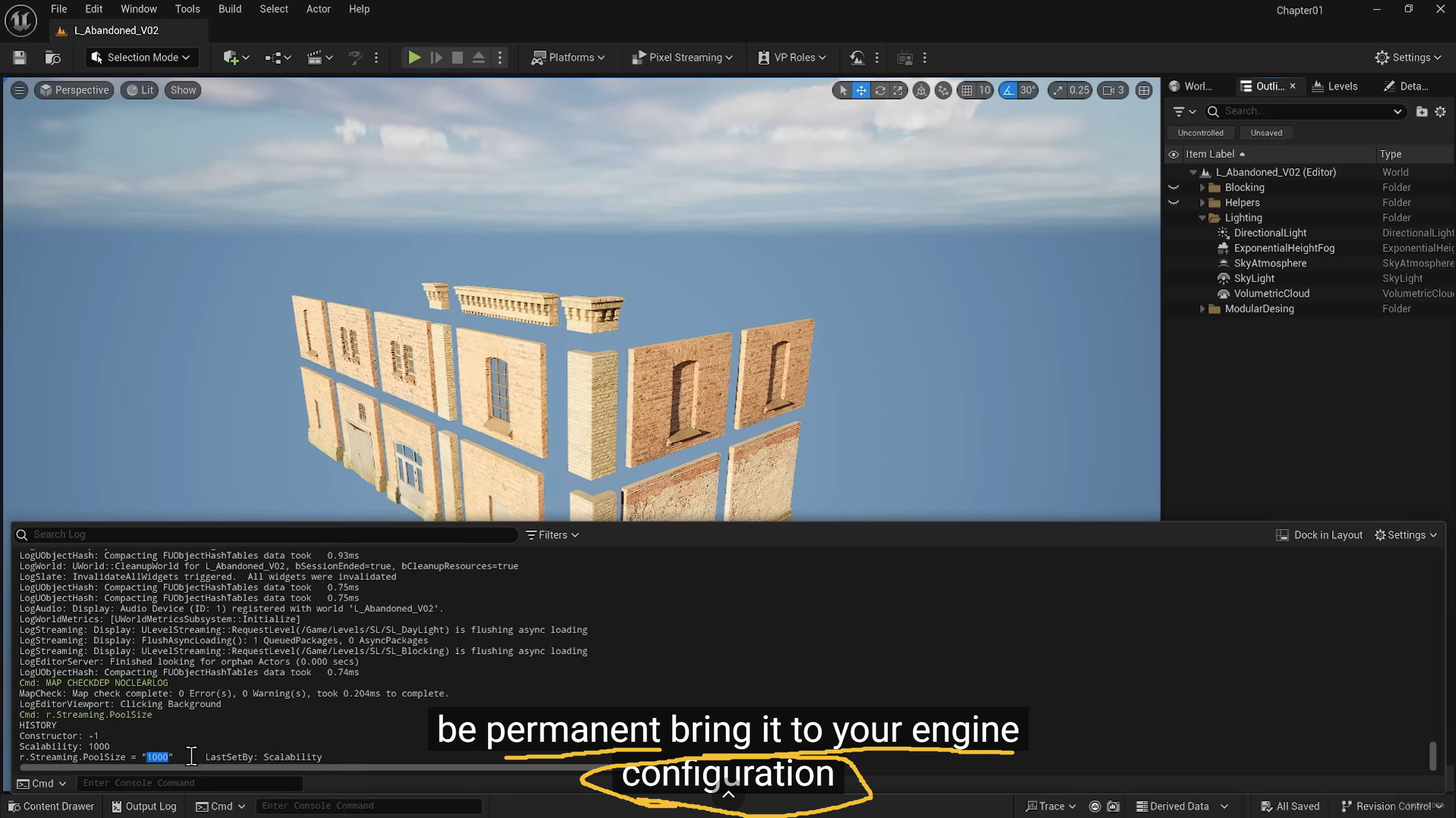
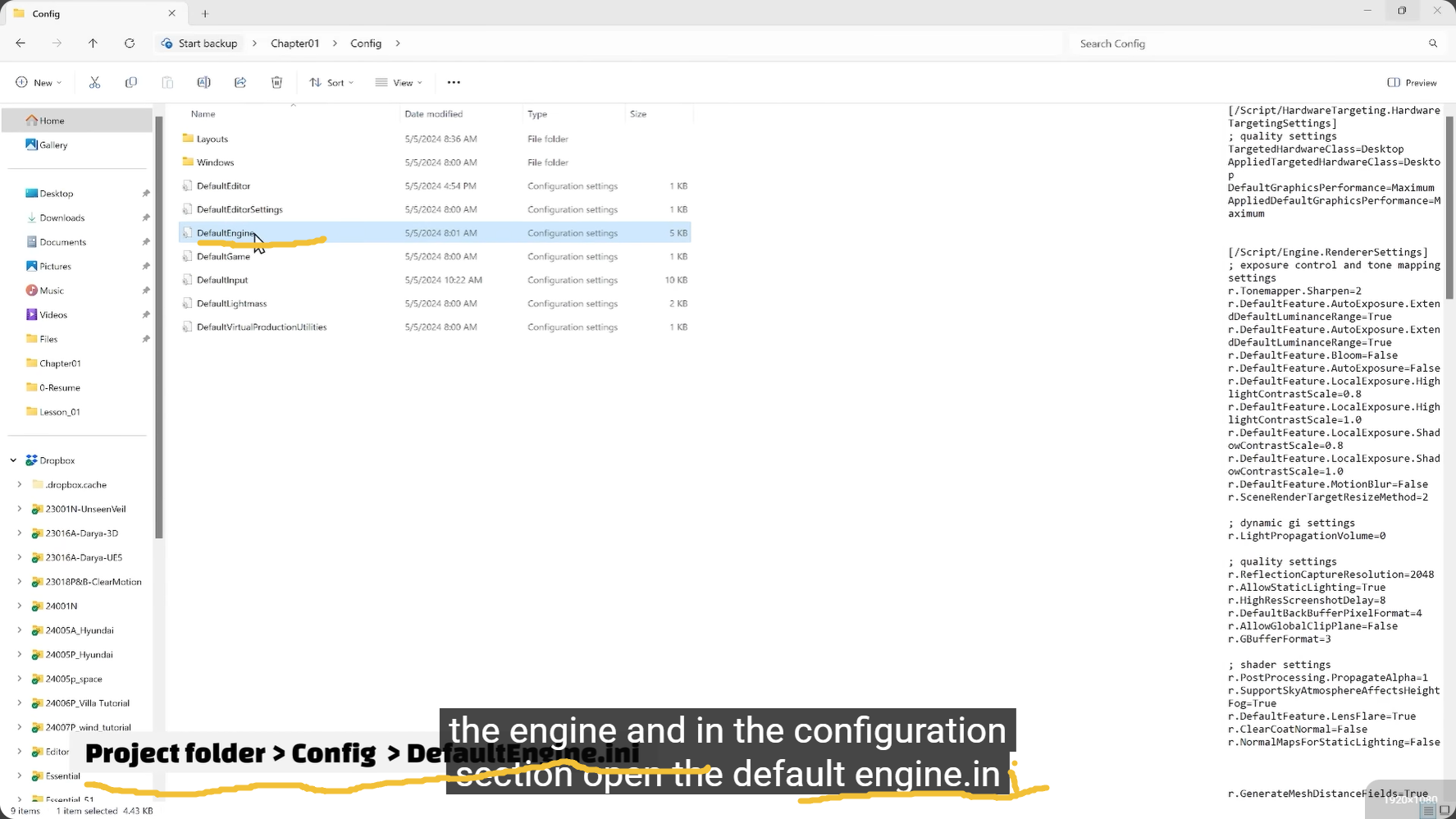
cmd里的命令都暂时,想要长期,engine configuration
Unreal Engine configuration uses
.ini files---such as DefaultEngine.ini and DefaultGame.ini ---organized by bracketed sections and key-value pairs to initialize project settings. These files, located in the Config folder, manage engine, input, and editor defaults, which can also be adjusted via the Project Settings menu in the editor.
很多公司甚至有规定,对于未经请求寄来的详细方案,HR会直接拦截,不发给研发团队看,就是为了避嫌。
还没入职就如此尖锐,入职后如何与负责该设计的原作者和谐共事?
3 https://entrogames.substack.com![]() https://entrogames.substack.com/p/what-if-someone-steals-my-idea
https://entrogames.substack.com/p/what-if-someone-steals-my-idea