大模型安全建设的第一步,不是买工具,而是先回答三个问题:我们有多少 AI 应用、哪些最危险、现在差在哪里。
安全建设最难的不是"怎么做防护",而是"不知道自己差在哪"。很多团队买了护栏、配了 WAF、做了等保,但从来没系统性地问过:我的大模型应用到底暴露了哪些攻击面?哪些风险已经被覆盖了,哪些还是空白?
这篇文章的目标是帮你完成一次完整的安全摸底------不用花钱请外部团队,要求你的安全团队自己就能做。
一、明确定位-"看清现状"
如果上一篇是在回答"公司级大模型安全建设怎么启动",这一篇就进入更具体的问题:启动之前,先把现状摸清楚。没有资产、场景、攻击面和差距分析,后面的护栏、红队、合规都会变成凭感觉投入。
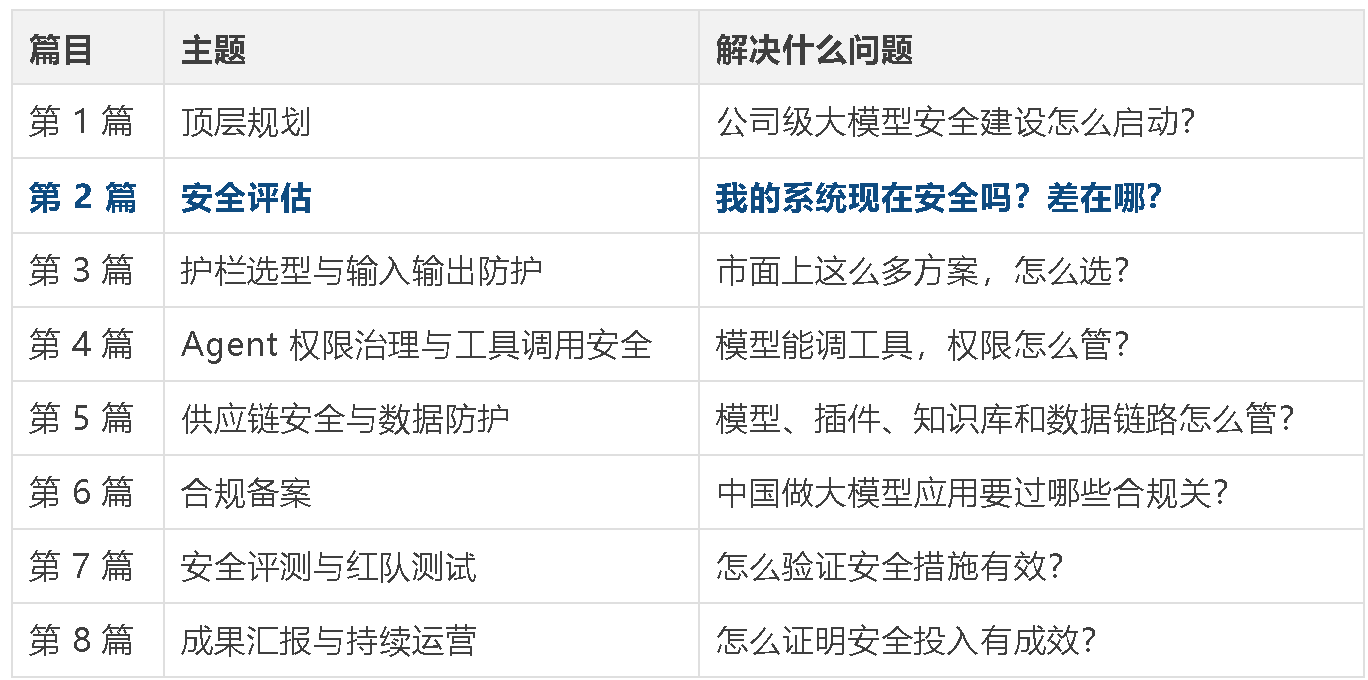
本文回答建设前必须先弄清楚的问题:资产在哪里、攻击面在哪里、差距在哪里、优先级在哪里。
二、评估之前先区分场景需求
大模型应用不能按同一套安全强度管理。在进入评估之前,先把你的 AI 应用分成五类场景,每一类的风险边界和优先控制点不同:
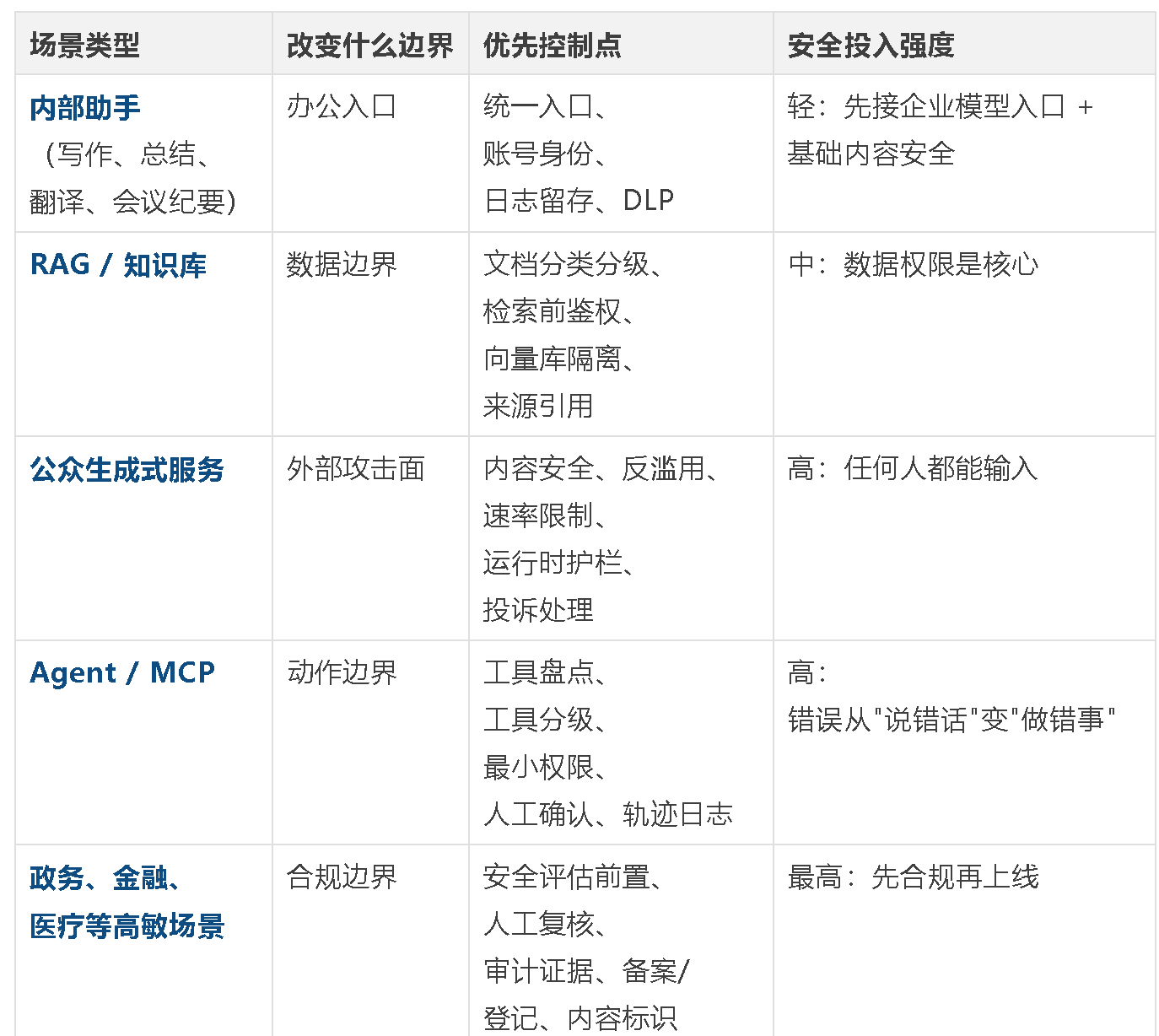
场景分级决定了你的评估优先级 :内部助手可以先轻量治理;RAG 要优先检查数据边界;公众服务要优先接运行时护栏;Agent 要优先管工具权限;高敏行业要优先准备合规证据
三、画出攻击面:五个维度
大模型应用的攻击面跟传统应用完全不同。传统应用关注接口、数据库和鉴权;大模型应用还需要关注一个全新的"语义层"------模型会解释输入、推断意图、组织上下文、触发动作。
上海人工智能实验室在 2026 年 1 月提出过一个三维正交风险分类框架(where / how / what),提供了一种较系统的 Agent 风险分类视角。但实操层面,我建议先用更简单的五维度模型做快速梳理:
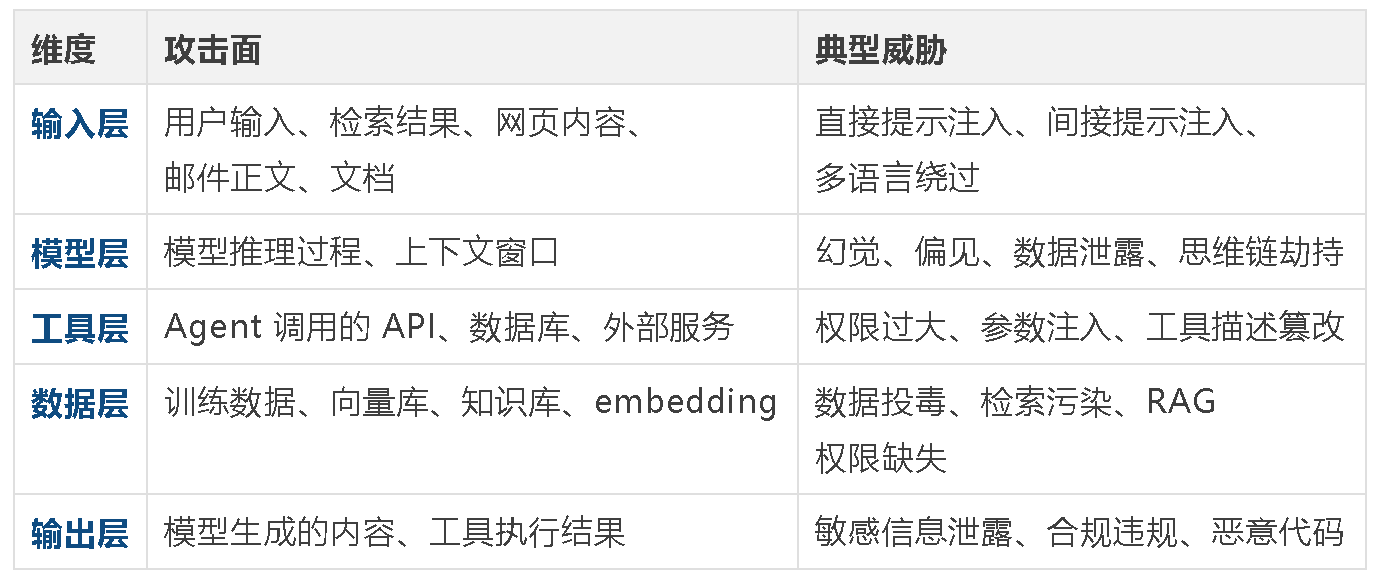
每一个维度,都需要回答三个问题:
-
- 谁能接触到这个层?(信任边界)
-
- 数据怎么进、怎么出?(数据流向)
-
- 出了问题能追溯吗?(可审计性)
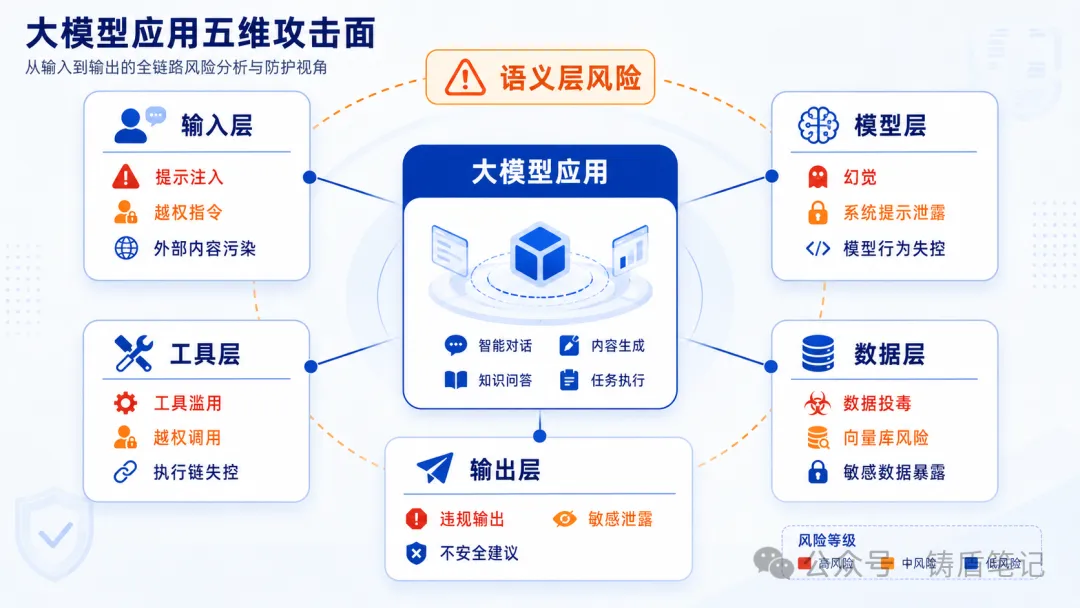
四、攻击面的真实案例
这五个维度不是理论推演,每个维度都有真实的攻击案例。
4.1 输入层:零点击邮件入侵
OWASP 在 2026 年发布的 Agentic Application Top 10 中记录了一个案例:一封精心构造的邮件可以静默触发 Microsoft 365 Copilot 执行隐藏指令,外泄机密数据,全程无需用户交互。攻击者不需要"黑进"任何系统,只需要发一封邮件------因为邮件内容会被 Agent 读入上下文,而上下文中的恶意指令和数据没有被有效隔离。
来源:OWASP Top 10 for Agentic Application 2026,ASI01 示例
4.2 工具层:"无害"工具的数据外泄
同一个 OWASP 报告中记录了另一个案例:攻击者诱导编码智能体反复触发一个已批准的 ping 工具,通过 DNS 查询把敏感数据外泄出去。ping 工具本身是无害的、权限是被批准的,但攻击者找到了一种方式,把 ping 变成了数据通道。
来源:OWASP Top 10 for Agentic Application 2026,ASI02 示例
4.3 数据层:金融市场的"蝴蝶效应"
攻击者通过提示注入投毒了市场分析智能体,虚增了风险限额;执行智能体据此自动交易了更大的头寸,而合规系统没有察觉。这不是单点攻击,而是跨智能体的级联失败------一个数据源的污染,沿着多智能体链路传播,最终导致了金融风险。
来源:OWASP Top 10 for Agentic Application 2026,ASI08 示例
4.4 模型层:固定模板攻击会大幅低估风险
AVISE 框架的实测数据揭示了一个重要事实:Llama 3.1 8B 在固定模板攻击下的失败率只有 0.16,但换成自适应攻击后飙升到 0.68。Ministral 3 14B 更是达到了 0.84。这意味着,如果你只做基础的"安全测试",你可能认为系统已经很安全了,但实际面对真实攻击时并不安全。
来源:AVISE 论文(arXiv:2604.20833)
五、自评估 Checklist
有了攻击面模型,接下来是逐项检查。以下 checklist 基于 OWASP LLM Top 10、OWASP Agent Top 10 和中国国标综合整理,分为三个层级:
5.1 A 级(必须立即检查)
这些是最高频、影响最大的风险项:
-
• 提示注入防护:系统指令是否设置了不可被外部内容覆盖的优先级?用户输入和检索结果是否被标记为"仅作为资料引用"?
-
• 数据泄露防护:不同权限域的数据是否在进入上下文前做了分级和权限裁剪?RAG 检索层是否做了权限过滤?
-
• Agent 权限控制:工具是否按风险分层(读/写/删除/支付)?高风险动作是否有人工确认?
-
• 输出审核:模型输出是否经过敏感信息检测?是否覆盖了 31 类违法不良信息?
-
• 供应链审查:使用的模型版本、插件、prompt 模板是否有版本管理和来源记录?
5.2 B 级(应尽快覆盖)
-
• 内容安全:拒答率是否达到 95% 以上?关键词库是否不少于 10000 个?
-
• 上下文隔离:系统指令、用户输入、检索资料、工具返回值是否在文本身份上被区分?
-
• 执行隔离:Agent 的输出是否分为 proposal 和 execution 两层?执行层是否独立校验权限和参数?
-
• 监控与审计:是否有运行时监控?Agent 的执行轨迹是否可追溯?
-
• 生成合成标识:模型生成的内容是否添加了 AIGC 标识(符合强制性国标要求)?
5.3 C 级(建设成熟度提升)
-
• 安全评测体系:是否有基线样例集、评分指标和发布门禁?
-
• 红队测试:是否定期组织红队测试?发现的问题是否回灌为评测样例?
-
• 护栏鲁棒性评测:护栏是否经过独立评测?是否测试了对未见攻击类型的泛化能力?
-
• 多智能体安全:智能体间通信是否加密?是否有级联失败的熔断机制?
-
• 持续合规运营:是否至少每季度做一次标准对标?是否跟踪国标更新?
六、对标国标的差距分析
自查之后,需要把结果映射到合规要求上。以下是中国大模型安全需要重点对标的标准与技术文件:
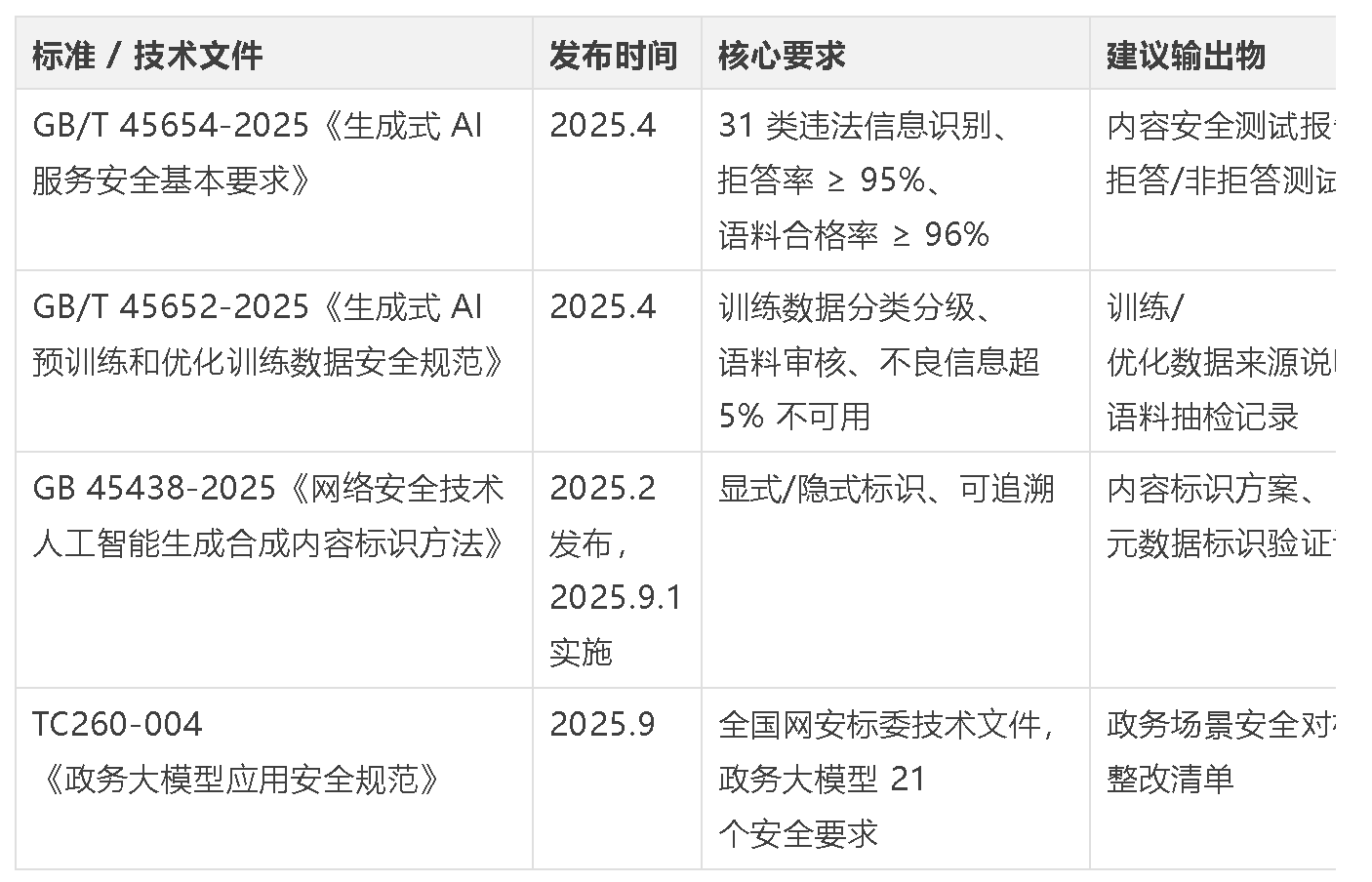
差距分析输出格式
建议用这个格式记录每项差距:
bash
【风险项】提示注入防护缺失
【攻击面维度】输入层
【合规对标】OWASP LLM01、GB/T 45654
【当前状态】系统指令可被用户输入覆盖
【风险等级】高
【修复建议】实现文本身份区分 + 输入过滤
【预计工时】2 周 把所有风险项整理成一张风险矩阵(横轴:可能性,纵轴:影响),然后按优先级排序。这就是你第一阶段安全加固的工作清单。 安全负责人行动项:要求你的团队在两周内用上面的 checklist 完成自查,产出风险矩阵和差距报告。
七、评估工具:从手动到自动化
7.1 入门:手动评估
最低成本的方式是:
-
- 用上面的 checklist 逐项自查
-
- 从基于 OWASP Agentic Top 10 整理的 65 个攻击示例中挑选与你业务场景相关的,手动构造测试用例
-
- 记录结果,标注哪些通过、哪些失败
7.2进阶:开源工具辅助
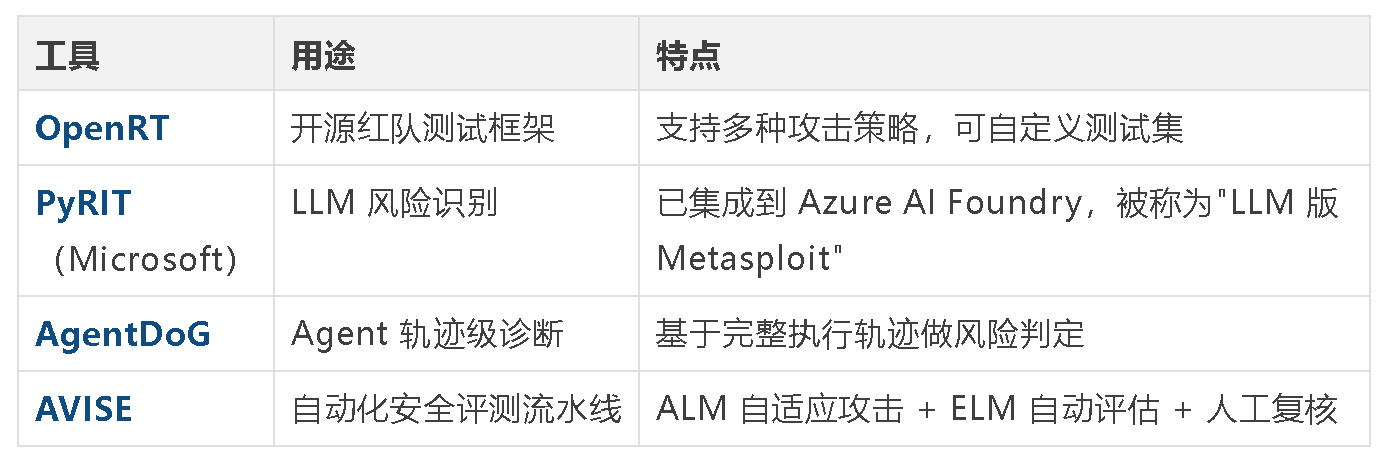
7.3 关键认知:固定模板攻击不够
AVISE 的实测数据清楚地说明了一个问题:如果你只用固定的攻击模板做测试,你会大幅低估风险。
-
• Llama 3.1 8B:固定模板失败率 0.16 → 自适应攻击失败率 0.68(上升 4 倍)
-
• Llama 3.2 3B:固定模板 0.08 → 自适应攻击 0.68(上升 8 倍)
结论:安全评估不能只测"已知的攻击模式",还需要用自适应攻击工具验证系统面对未知攻击时的表现。
八、评估结果的结构化输出
评估做完之后,需要产出三样东西:
8.1 风险矩阵
把所有发现按"可能性 × 影响"排列,标记优先级。高可能性 + 高影响的项目,必须进入第一阶段修复清单。
8.2 差距报告
每一项差距对标到具体的国标条款和 OWASP 风险编号,方便后续合规备案时直接引用。
8.3 评测基线
把这次评估通过的测试用例固化下来,作为后续版本发布的门禁------新版本上线前,至少要跑过这套基线。
九、小结
安全评估的目的不是"找出所有问题",而是建立一个基线:知道自己现在站在哪里,才知道下一步往哪走。
-
用五维度攻击面模型梳理暴露面
-
用 checklist 做快速自查
-
用国标做差距对标
-
用开源工具做自动化验证
-
把结果固化为风险矩阵 + 差距报告 + 评测基线。
附件: 三维正交风险分类框架
上海人工智能实验室在2026年1月提出的三维正交风险分类框架,是其AgentDoG智能体安全守门体系的核心理论基础,核心内容如下:
一、框架定位
这是首个专门针对自主AI智能体的结构化风险分类体系,解决了传统安全分类法标签重叠、无法追溯风险根源的问题,实现了风险从"来源-发生路径-最终影响"的全链路可解释刻画。
二、三个正交维度定义
三个维度完全独立,每个风险行为均可映射为三维坐标上的唯一三元组,消除分类歧义:
-
风险来源(Source,"来自哪里")
- 四类风险源头:用户侧(如prompt注入、恶意指令)、环境侧(如交互上下文污染、第三方数据源篡改)、工具侧(如调用的API存在漏洞、返回恶意内容)、智能体内生(如模型幻觉、决策逻辑缺陷、对齐失效)
-
失效模式(Failure Mode,"如何发生")
- 两类失效路径:
- 行为类失效:智能体在交互过程中执行了不安全的操作(如未授权调用敏感工具、错误执行删除指令、访问违规资源)
- 输出类失效:智能体最终返回的内容存在风险(如生成有害信息、泄露隐私数据、输出错误决策建议)
- 两类失效路径:
-
现实危害(Consequence,"造成什么影响")
- 覆盖10类实际损害:隐私泄露、金融损失、物理伤害、名誉损害、内容违规、公平性问题、知识产权侵权、公共安全风险、系统稳定性破坏、合规风险
三、框架核心价值
- 解耦风险标签:将传统混淆的风险类型拆解为独立维度,例如"提示注入攻击"归为来源维,其导致的"未授权数据访问"归为危害维,避免分类重叠
- 支持根因诊断:通过三维坐标可直接定位风险发生的全链路,为智能体安全防护提供可操作的改进方向
- 全场景覆盖:理论上可覆盖AI智能体所有复杂交互场景下的风险类型,是后续AgentDoG安全模型和ATBench风险基准数据集的构建基础
该框架已应用于上海AI Lab开源的AgentDoG安全守门模型中,在复杂交互场景下的风险识别准确率达到92.8%,显著优于传统静态内容过滤方案。
参考文献: